
Dataset: Traffic Images Captured from UAVs for Use in Training Machine Vision Algorithms for Traffic Management

 and
and 
Abstract
:1. Introduction
- For the training of algorithms to monitor complex infrastructures such as roundabouts and junctions, etc. The information obtained can be used for V2V and V2I arbitration and communication systems currently under development in the automotive industry, which will improve safety in shared traffic.
- For the training of algorithms that can identify different types of vehicles and can be implemented in autonomous UAVs used for traffic control and safety.
- For the training of algorithms developed for the management of traffic violations monitored using UAVs, increasingly used by traffic agencies in many countries.
- For the training of algorithms developed for emergency services to use UAVs for the rapid response to a traffic accident and to minimize the number of victims by the prompt assistance of emergency services.
- For the training of algorithms developed for organizations in charge of designing and managing new road infrastructures to enable a better design of these infrastructures to improve safety and minimize traffic congestion.
2. Data Description
- Object class: Integer number varying between 0 and N-Classes-1. The two classes that have been incorporated in the model are as follows: 0. Cars, 1. Motorcycles.
- x, y: Decimal values relative to the center of the rectangle containing the labeled object. They vary in the range [0.0 to 1.0].
- Width, height: Decimal values relative to the width and height of the rectangle containing the labeled object. They vary in the range [0.0 to 1.0].
3. Methods
3.1. Obtaining the Dataset
3.1.1. Selection of Locations
3.1.2. Angle and Orientation of the Recordings
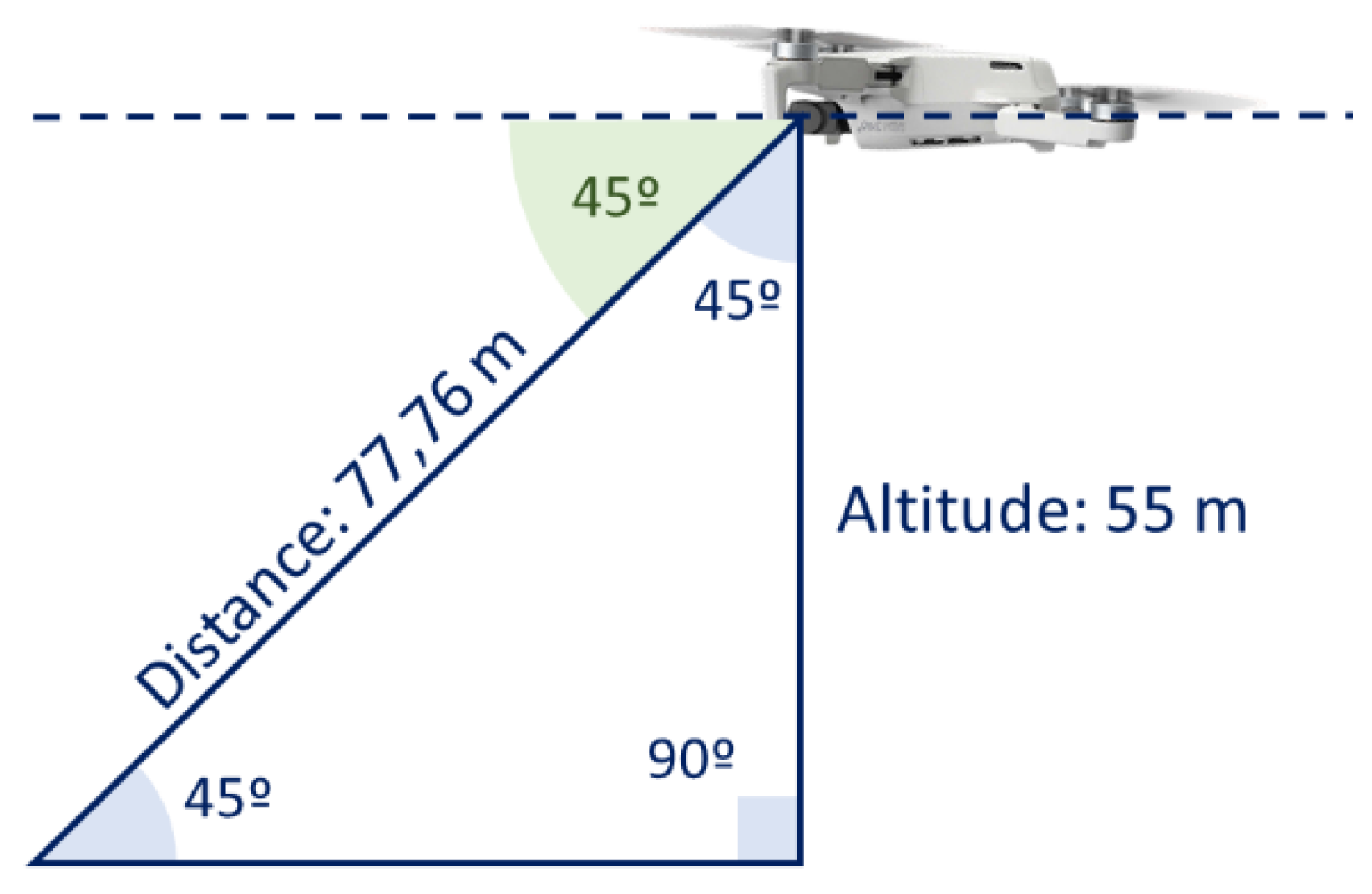
3.1.3. Height of the Recordings
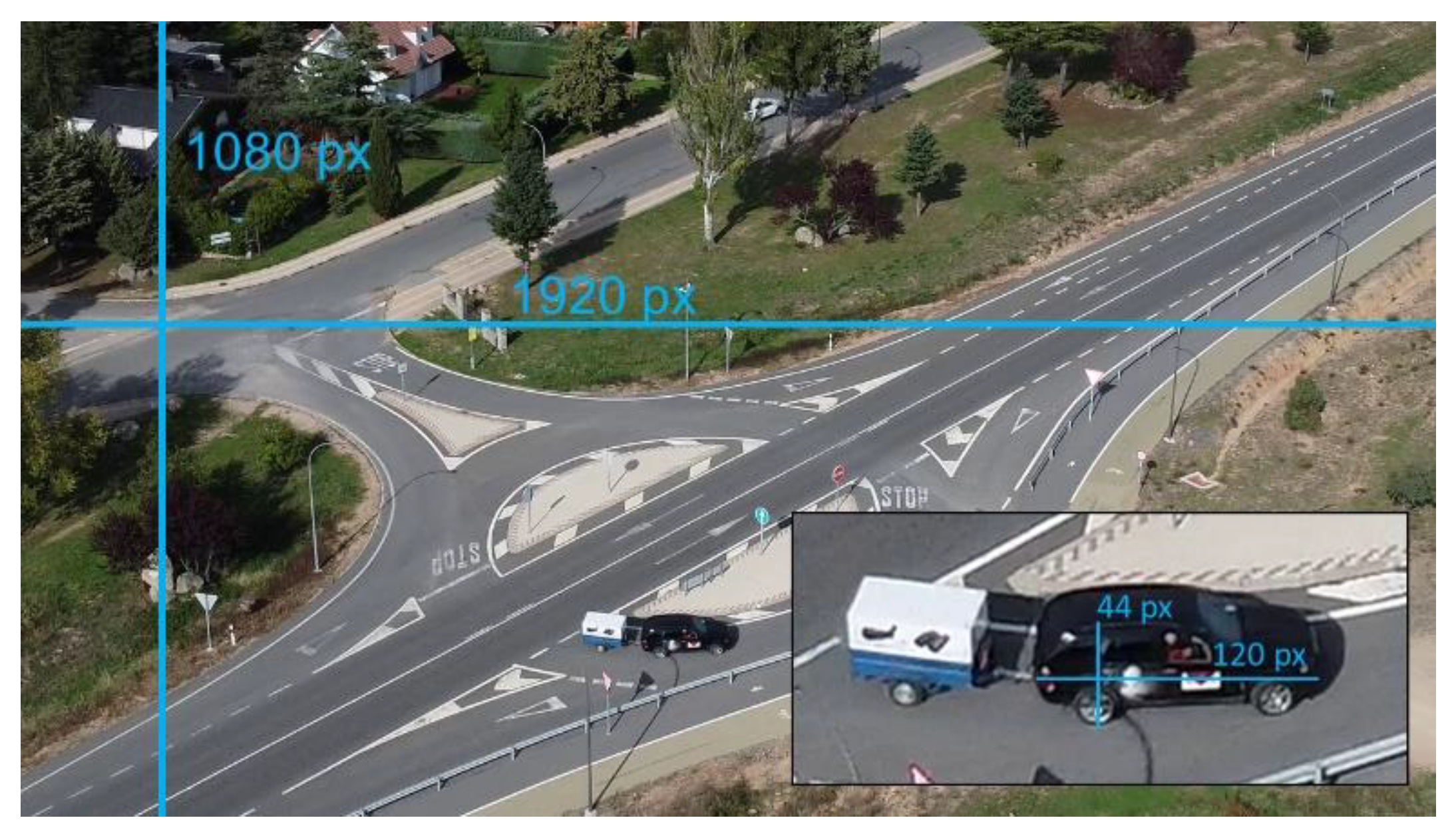
3.1.4. Relationship between Resolution and Recording Height
3.1.5. Planning and Execution of the Missions
3.2. Techniques for Anonymizing the Dataset
3.3. Dataset Processing and Labeling
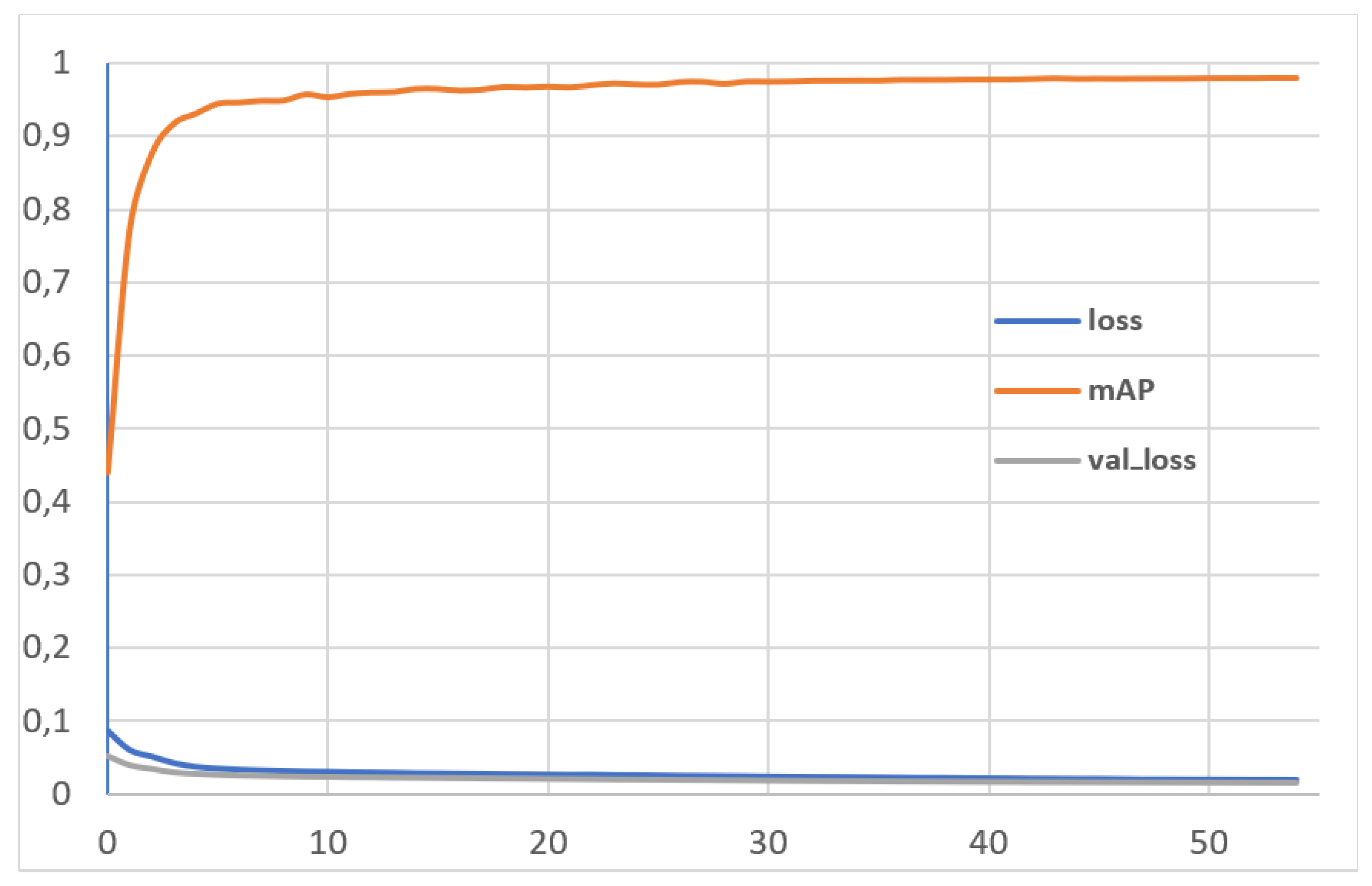
3.4. Dataset Validation
4. User Notes
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Milić, A.; Randjelovic, A.; Radovanović, M. Use of drones in operations in the urban environment. In Proceedings of the 5th International Conference on Information Systems for Crisis Response and Management, Washington, DC, USA, 4–7 May 2008. [Google Scholar]
- Merkert, R.; Bushell, J. Managing the drone revolution: A systematic literature review into the current use of airborne drones and future strategic directions for their effective control. J. Air Transp. Manag. 2020, 89, 101929. [Google Scholar] [CrossRef] [PubMed]
- Hodgkinson, D.; Johnston, R. Aviation Law and Drones: Unmanned Aircraft and the Future of Aviation; Routledge: London, UK, 2018. [Google Scholar]
- Ministerio de Fomento. Plan Estratégico para el Desarrollo del Sector Civil de Los Drones en España 2018–2021|Ministerio de Transportes, Movilidad y Agenda Urbana. Available online: https://www.mitma.gob.es/el-ministerio/planes-estrategicos/drones-espania-2018-2021 (accessed on 1 December 2021).
- Cuenca, L.G.; Sanchez-Soriano, J.; Puertas, E.; Andrés, J.F.; Aliane, N. Machine Learning Techniques for Undertaking Roundabouts in Autonomous Driving. Sensors 2019, 19, 2386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cuenca, L.G.; Puertas, E.; Andrés, J.F.; Aliane, N. Autonomous Driving in Roundabout Maneuvers Using Reinforcement Learning with Q-Learning. Electronics 2019, 8, 1536. [Google Scholar] [CrossRef] [Green Version]
- Pettersson, I.; Karlsson, M. Setting the stage for autonomous cars: A pilot study of future autonomous driving experiences. IET Intell. Transp. Syst. 2015, 9, 694–701. [Google Scholar] [CrossRef]
- Bemposta Rosende, S.; Sánchez-Soriano, J.; Gómez Muñoz, C.Q.; Fernández Andrés, J. Remote Management Architecture of UAV Fleets for Maintenance, Surveillance, and Security Tasks in Solar Power Plants. Energies 2020, 13, 5712. [Google Scholar] [CrossRef]
- Yildiz, M.; Bilgiç, B.; Kale, U.; Rohács, D. Experimental Investigation of Communication Performance of Drones Used for Autonomous Car Track Tests. Sustainability 2021, 13, 5602. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, J.; Lei, J.; Yu, L.; Hwang, J.N. GMNet: Graded-Feature Multilabel-Learning Network for RGB-Thermal Urban Scene Semantic Segmentation. IEEE Trans. Image Process. 2021, 30, 7790–7802. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Guo, Q.; Lei, J.; Yu, L.; Hwang, J.N. IRFR-Net: Interactive Recursive Feature-Reshaping Network for Detecting Salient Objects in RGB-D Images. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Tobías, L.; Ducournau, A.; Rousseau, F.; Mercier, G.; Fablet, R. Convolutional Neural Networks for object recognition on mobile devices: A case study. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 3530–3535. [Google Scholar] [CrossRef]
- Vivek, R.; Vighnesh, B.; Sachin, J.; Pkulzc; Khanh. TensorFlow 2 Detection Model Zoo. Tensorflow. 2021. Available online: https://github.com/tensorflow/models/blob/5ad16f952885c86ca0aa31a8eb3737ab7bb23ee1/research/object_detection/g3doc/tf2_detection_zoo.md (accessed on 19 June 2021).
- Zhou, W.; Wu, J.; Lei, J.; Hwang, J.-N.; Yu, L. Salient Object Detection in Stereoscopic 3D Images Using a Deep Convolutional Residual Autoencoder. IEEE Trans. Multimed. 2021, 23, 3388–3399. [Google Scholar] [CrossRef]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–16 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Tackling the Small Object Problem in Object Detection. Roboflow Blog. 2020. Available online: https://blog.roboflow.com/detect-small-objects/ (accessed on 17 June 2021).
- Unel, F.O.; Ozkalayci, B.O.; Cigla, C. The Power of Tiling for Small Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 582–591. [Google Scholar] [CrossRef]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The highD Dataset: A Drone Dataset of Naturalistic Vehicle Trajectories on German Highways for Validation of Highly Automated Driving Systems. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2118–2125. [Google Scholar] [CrossRef] [Green Version]
- Mutasa, S.; Sun, S.; Ha, R. Understanding artificial intelligence based radiology studies: What is overfitting? Clin. Imaging 2020, 65, 96–99. [Google Scholar] [CrossRef] [PubMed]
- Ministerio de la Presidencia y para las Administraciones Territoriales. Boletín Oficial del Estado 29 December 2017. Available online: https://www.boe.es/boe/dias/2017/12/29/pdfs/BOE-A-2017-15721.pdf (accessed on 1 December 2021).
- Reglamento (UE) 2016/679 del Parlamento Europeo y del Consejo de 27 de Abril de 2016. Available online: https://www.boe.es/doue/2016/119/L00001-00088.pdf (accessed on 1 December 2021).
- Automatic License Plate Recognition using Python and OpenCV. Available online: https://sajjad.in/content/ALPR_paper.pdf (accessed on 22 November 2021).
- Zhang, C.; Tai, Y.; Li, Q.; Jiang, T.; Mao, W.; Dong, H. License Plate Recognition System Based on OpenCV. In 3D Imaging Technologies—Multi-Dimensional Signal Processing and Deep Learning; Smart Innovation, Systems and Technologies; Jain, L.C., Kountchev, R., Shi, J., Eds.; Springer: Singapore, 2021; Volume 234. [Google Scholar] [CrossRef]
- Car License Plate Detection. Available online: https://www.kaggle.com/andrewmvd/car-plate-detection (accessed on 22 November 2021).
- Vehicle Registration Plates of Europe. Available online: https://en.wikipedia.org/wiki/Vehicle_registration_plates_of_Europe (accessed on 22 November 2021).
- Real, E.; Shlens, J.; Mazzocchi, S.; Pan, X.; Vanhoucke, V. YouTube-BoundingBoxes: A Large High-Precision Human-Annotated Data Set for Object Detection in Video. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7464–7473. [Google Scholar] [CrossRef] [Green Version]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; p. 6. [Google Scholar]
- Track Mode (Basics), CVAT. Available online: https://openvinotoolkit.github.io/docs/manual/basics/track-mode-basics/ (accessed on 29 June 2021).
- Anderson, C. Docker [Software Engineering]. IEEE Softw. 2015, 32, 102-c3. [Google Scholar] [CrossRef]
- Lee, Y.H.; Kim, B.; Kim, H.J. Efficient object identification and localization for image retrieval using query-by-region. Comput. Math. Appl. 2012, 63, 511–517. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenes | Frames | Targets | Cars | Motorbikes |
|---|---|---|---|---|
| Regional road | 4500 | 24,858 | 14,577 | 10,281 |
| Urban intersection | 2462 | 10,759 | 10,759 | 0 |
| Rural road | 1292 | 746 | 746 | 0 |
| Split roundabout | 2297 | 3107 | 3107 | 0 |
| Roundabout (far) | 1814 | 71,819 | 64,844 | 6975 |
| Roundabout (near) | 3997 | 44,039 | 43,569 | 470 |
| Total | 15,070 | 155,328 | 137,602 | 17,726 |
| Yuneec Typhoon H (CGO3) | DJI Mavic Mini 2 | |
|---|---|---|
| Resolution | 1920 × 1080 px | 1920 × 1080 px |
| FOV angle | 98° | 83° |
| Focal (35 mm) | 14 mm | 24 mm |
| Aperture | f/2.8 | f/2.8 |
| Aspect ratio | 16:9 | 19:9 |
| Sensor | 1/2.3” CMOS | 1/2.3” CMOS |
| Processor | Intel Core i5-6500TE 2.4 GHz |
| Operating system | Ubuntu 20.04.3 LTS (Focal Fossa) |
| Motherboard | Intel RUBY-D718VG2AR |
| RAM | 64 GB |
| Graphics card | Nvidia RTX 2060 |
| Hard disk | 512 GB SSD |
| Intersection over Union: | 0.5 |
| Learning rate | 0.01 |
| Train/validation split | 90–10% |
| Steps | 3659 |
| Batch size | 4 |
| Total epochs | 55 |
| Total time training | 21.8 h |
| mAP | 0.97946 |
| Class car [mAP] | 0.994 |
| Class motorcycle [mAP] | 0.962 |
| Precision | 0.98456 |
| Recall | 0.95508 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bemposta Rosende, S.; Ghisler, S.; Fernández-Andrés, J.; Sánchez-Soriano, J. Dataset: Traffic Images Captured from UAVs for Use in Training Machine Vision Algorithms for Traffic Management. Data 2022, 7, 53. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050053
Bemposta Rosende S, Ghisler S, Fernández-Andrés J, Sánchez-Soriano J. Dataset: Traffic Images Captured from UAVs for Use in Training Machine Vision Algorithms for Traffic Management. Data. 2022; 7(5):53. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050053
Chicago/Turabian StyleBemposta Rosende, Sergio, Sergio Ghisler, Javier Fernández-Andrés, and Javier Sánchez-Soriano. 2022. "Dataset: Traffic Images Captured from UAVs for Use in Training Machine Vision Algorithms for Traffic Management" Data 7, no. 5: 53. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050053