
Development of a Model Using Data Mining Technique to Test, Predict and Obtain Knowledge from the Academics Results of Information Technology Students

 , and
, and 
Abstract
:1. Introduction
2. Dataset Description
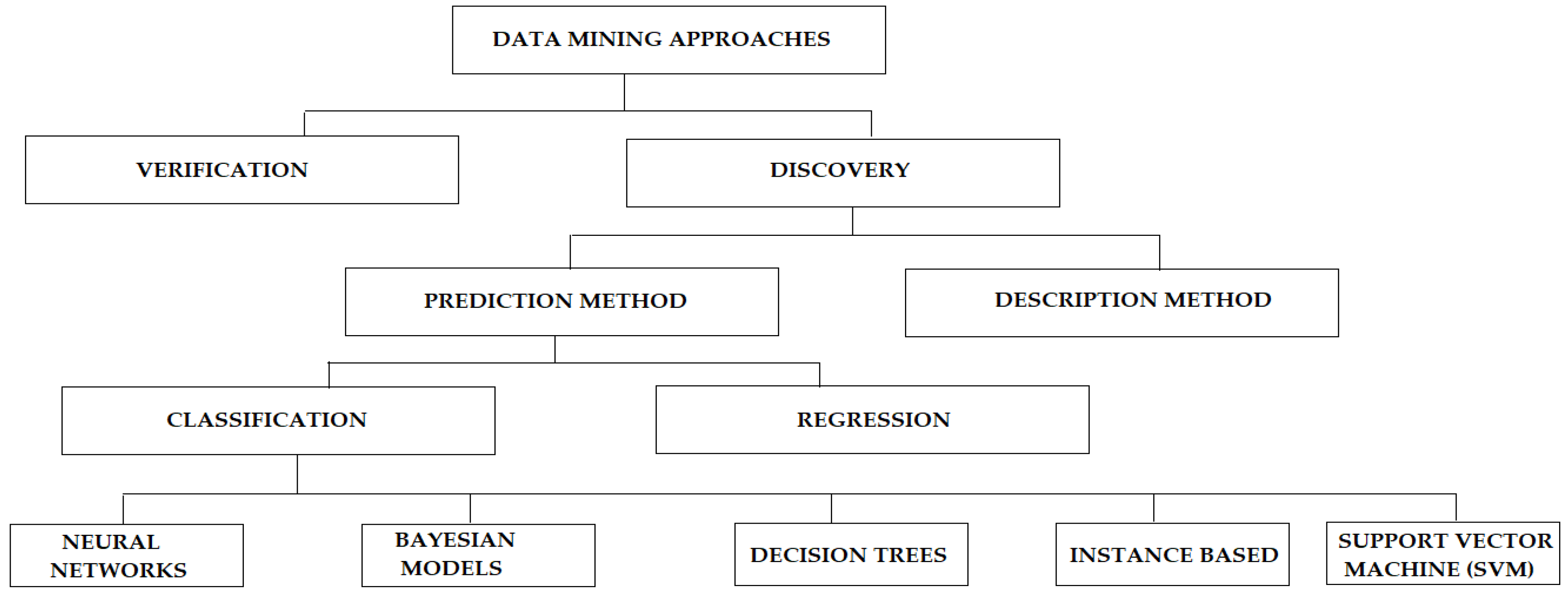
3. Methods
- Stage 1: If an instance belongs to similar class, the leaves are labeled with a similar class;
- Stage 2: For each attribute, the potential data will be figured and the gain in this data will be attained from the test conducted on attribute;
- Stage 3: Finally, the best attribute will be selected in regard to the current selection parameter.
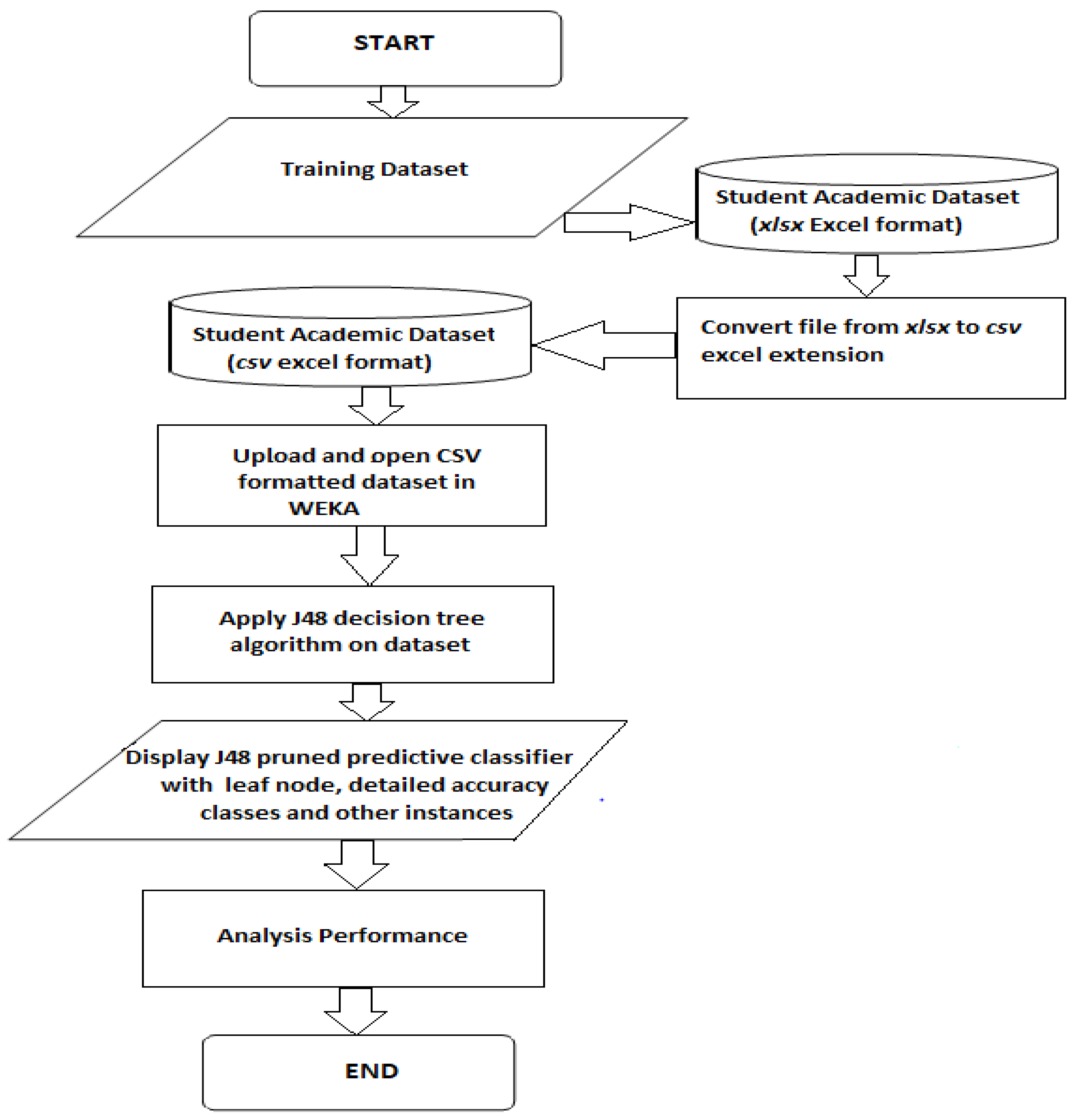
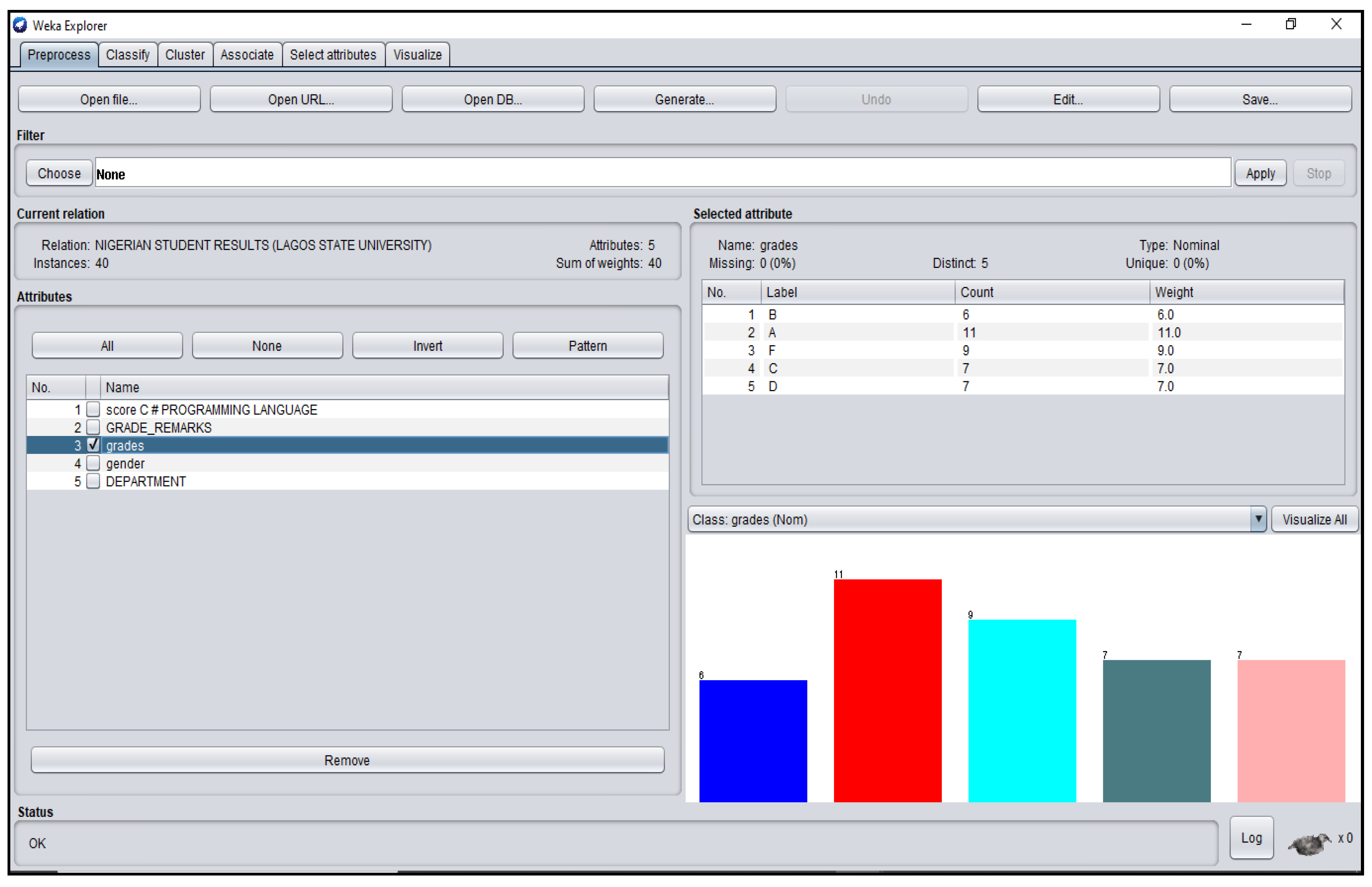
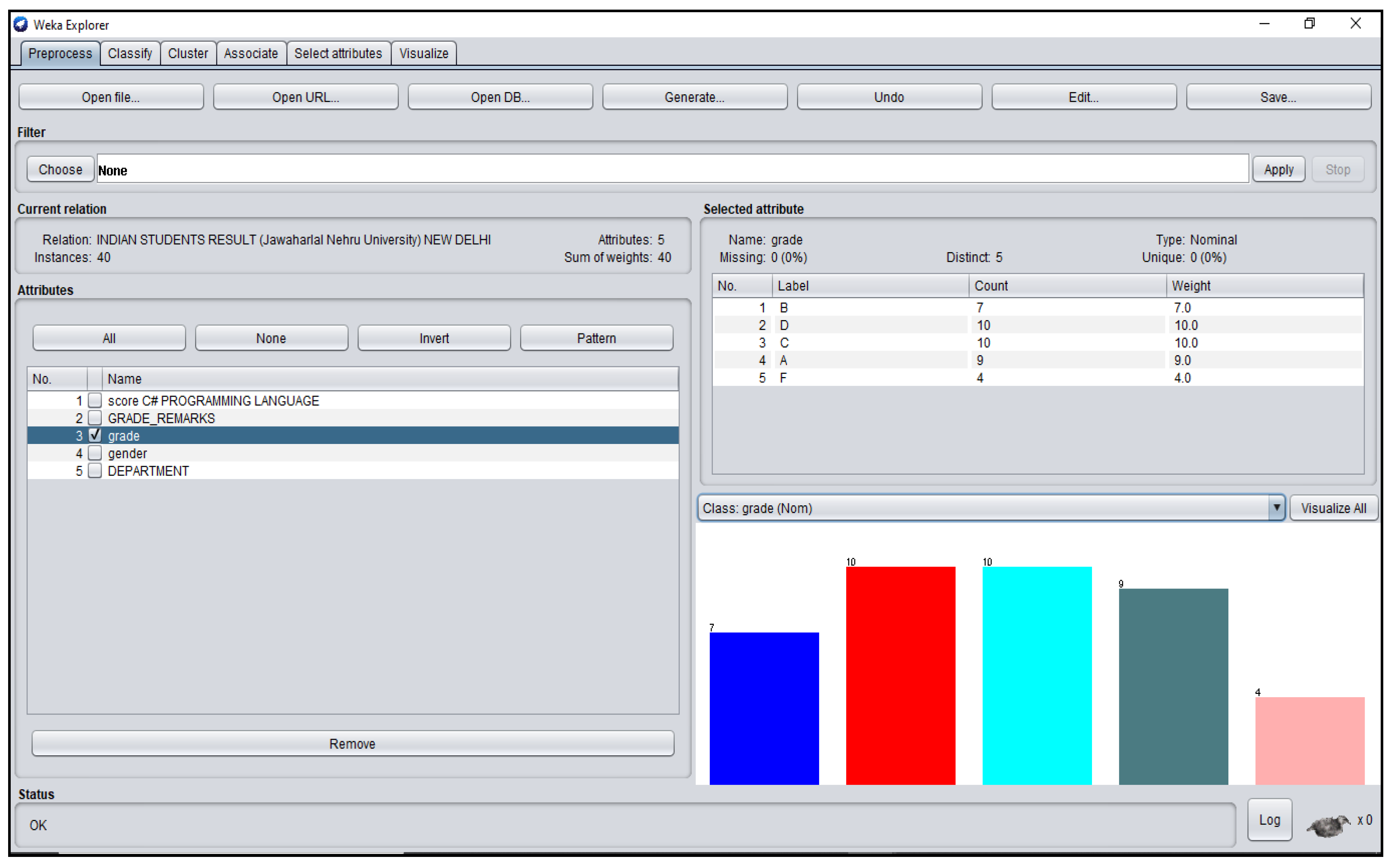
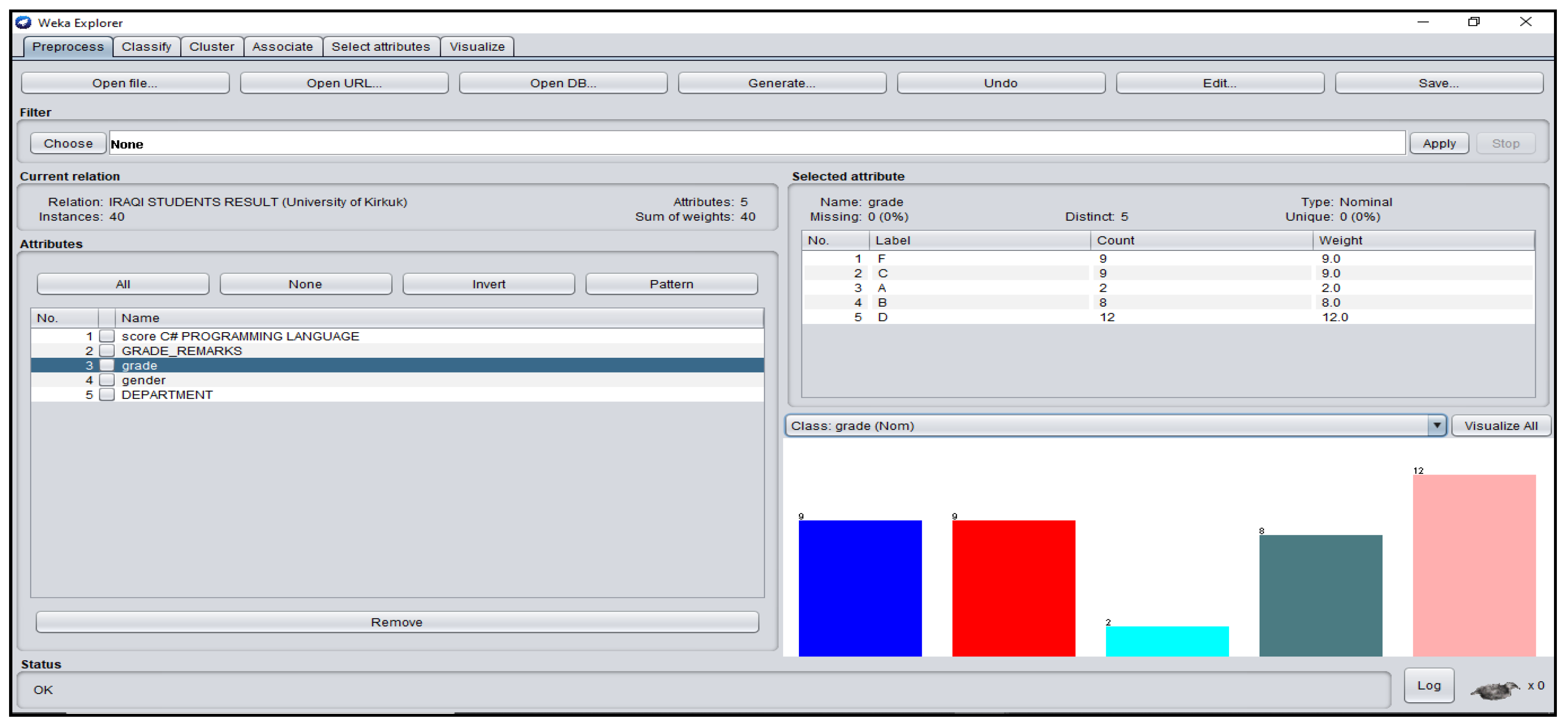
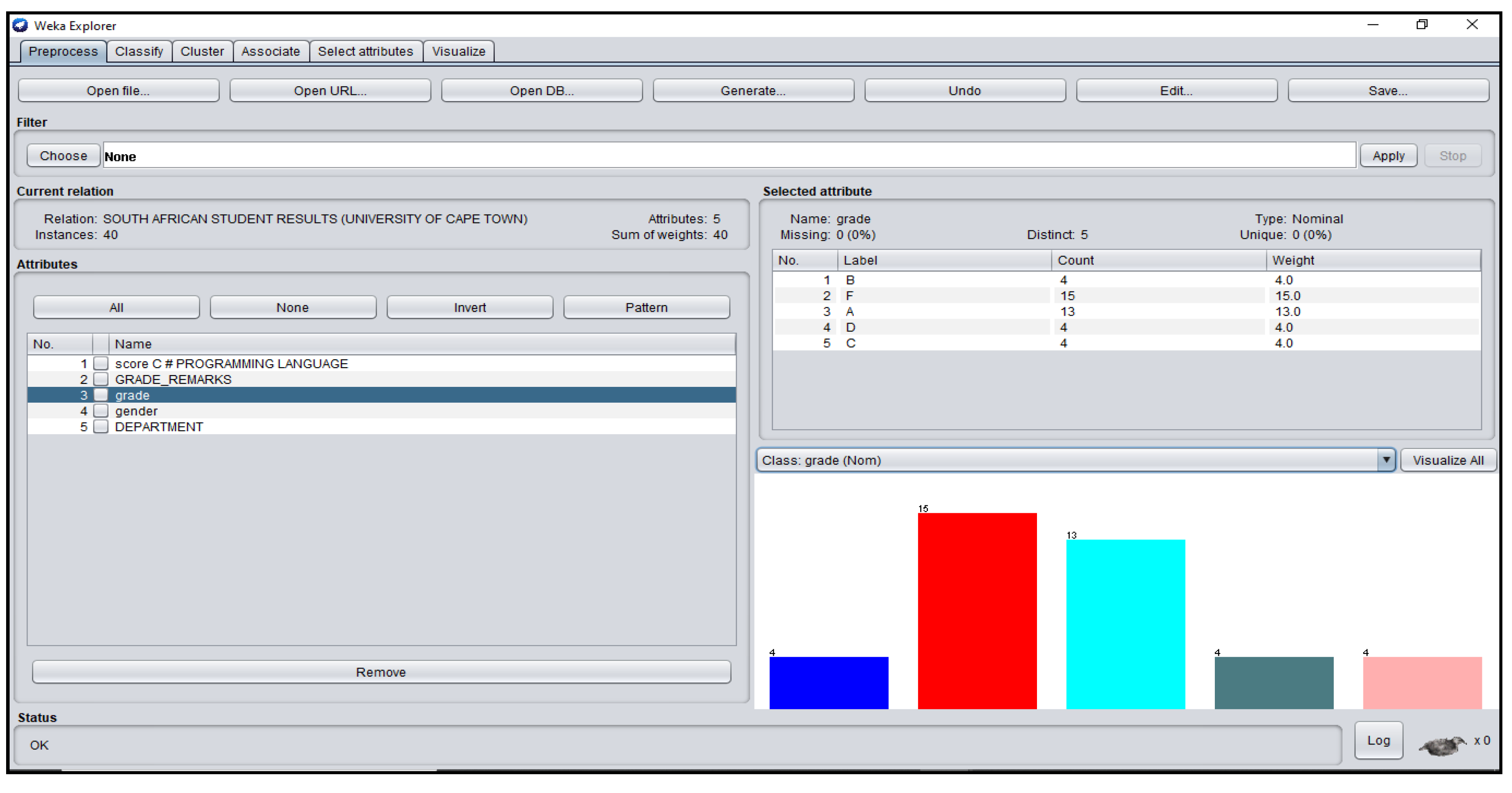
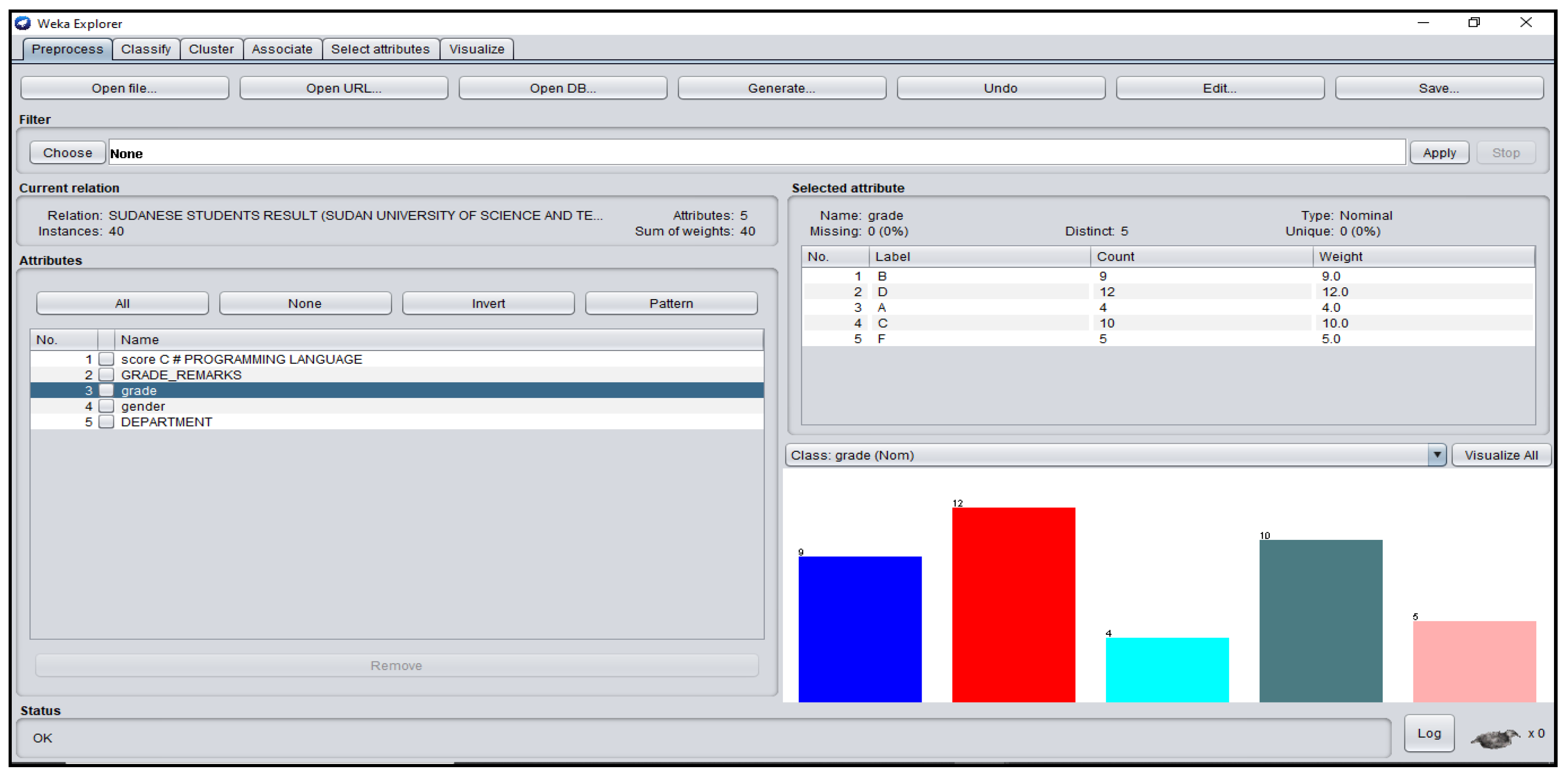
3.1. Students’ Dataset Analysis in WEKA
3.2. Calculations of the Evaluation Measures of the Detailed Accuracy Class Table
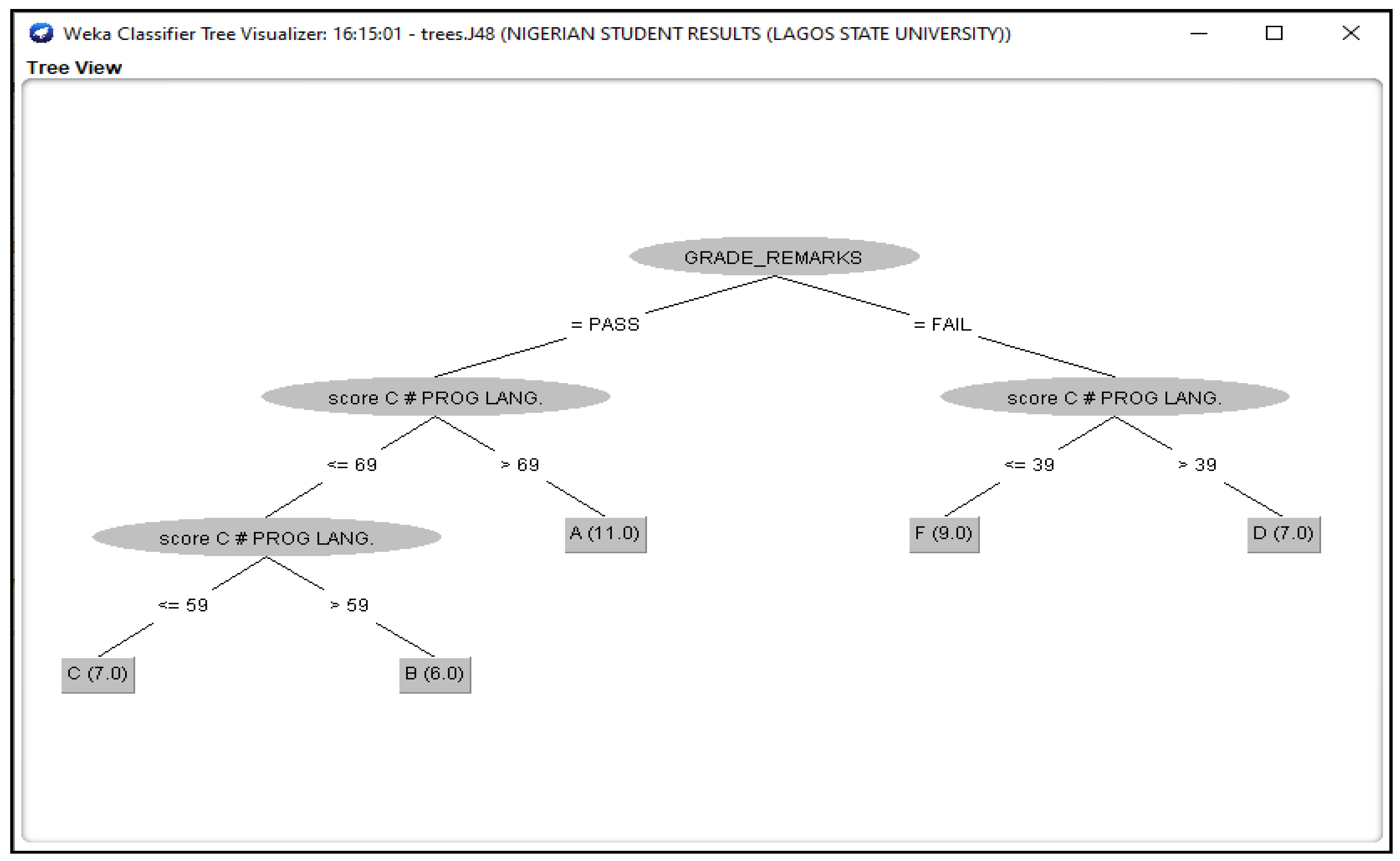
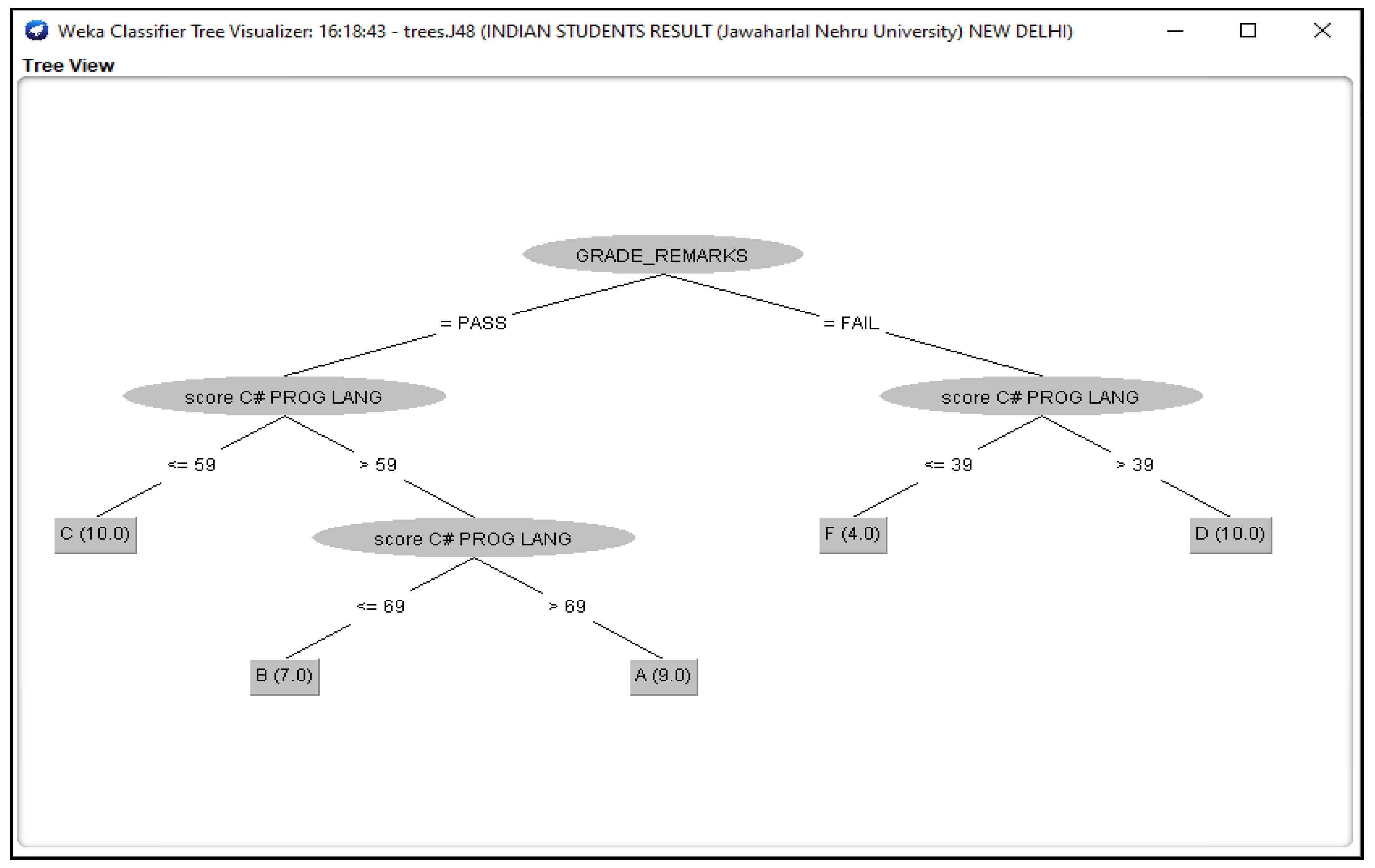
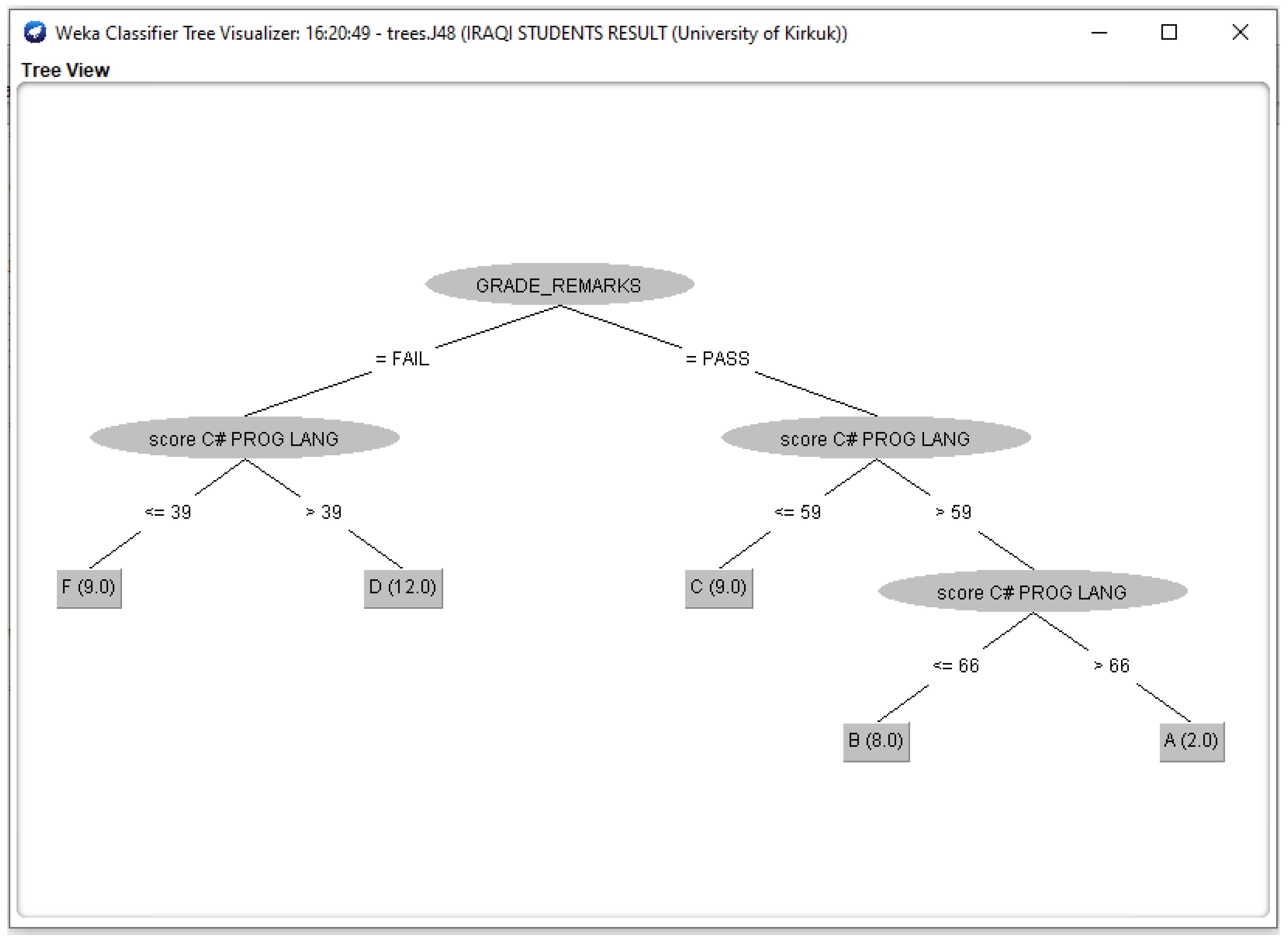
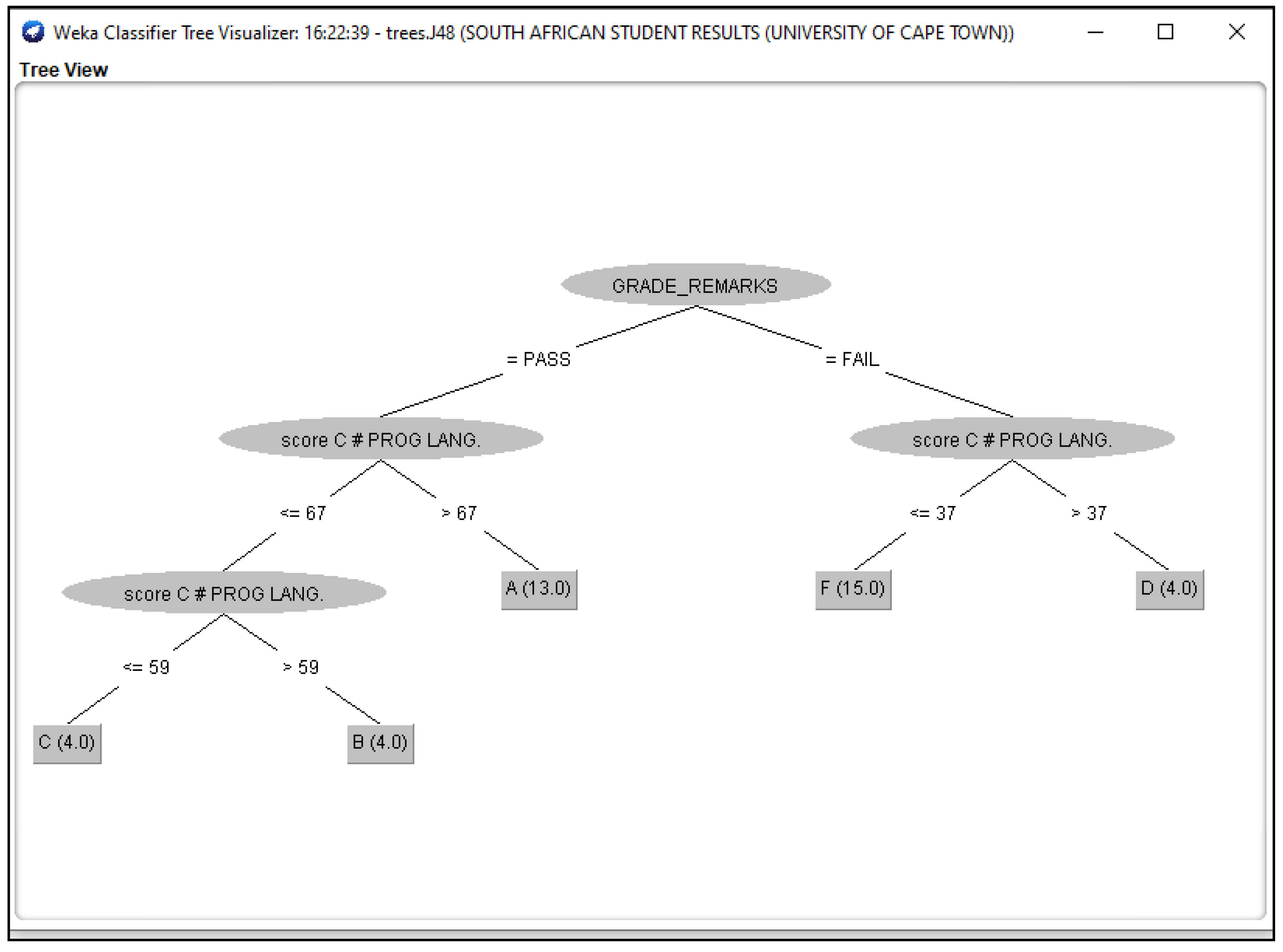
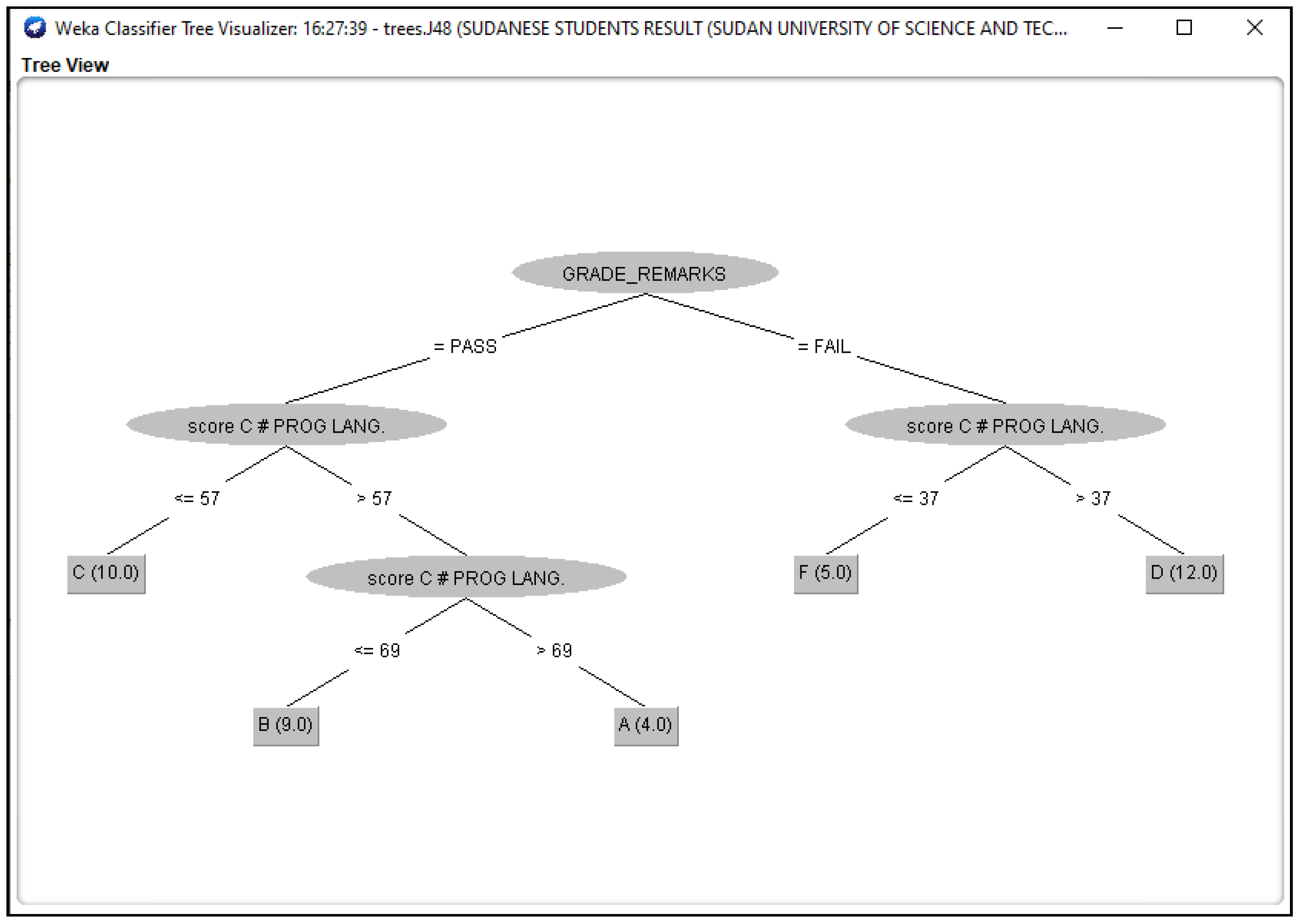
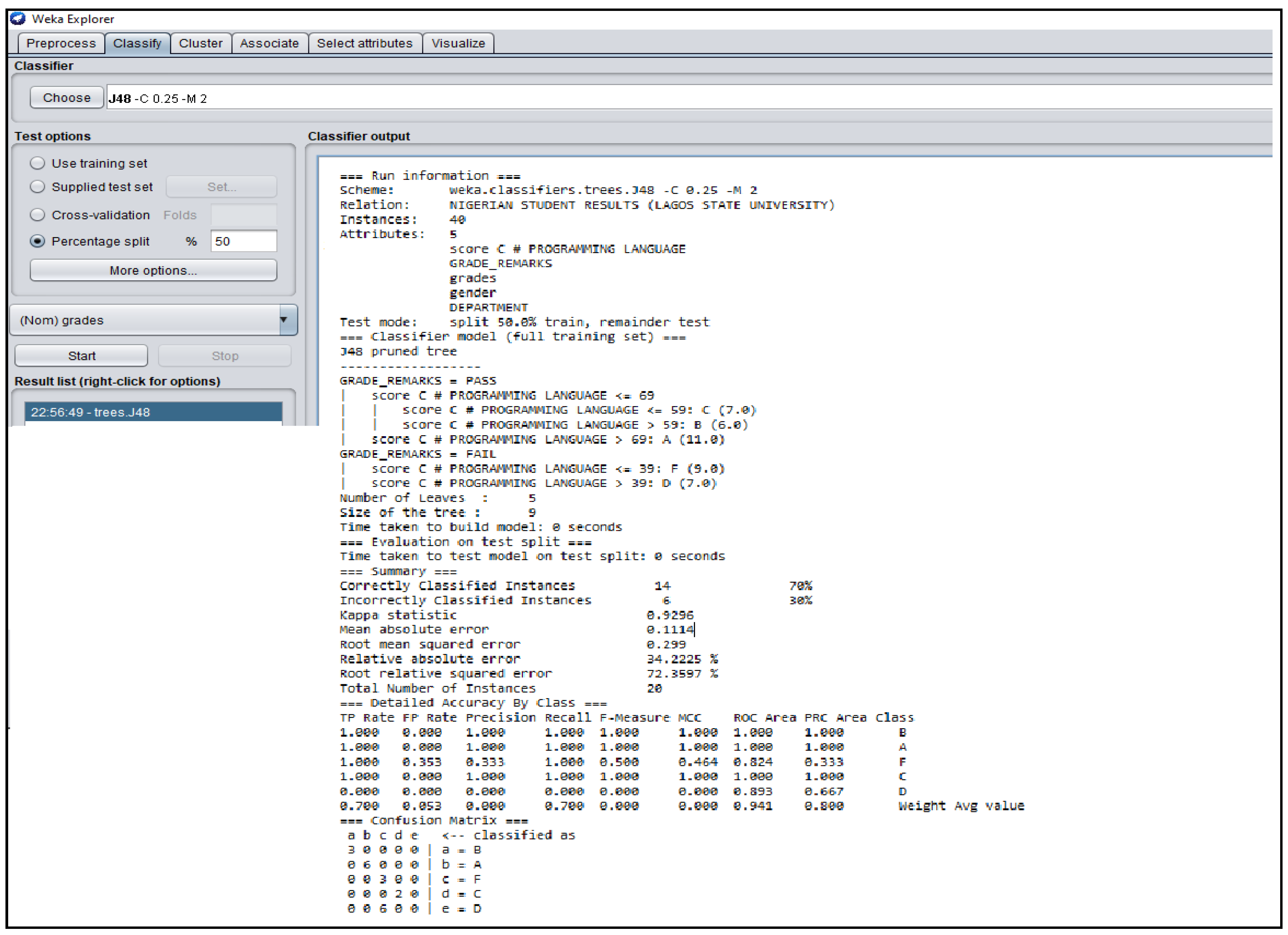
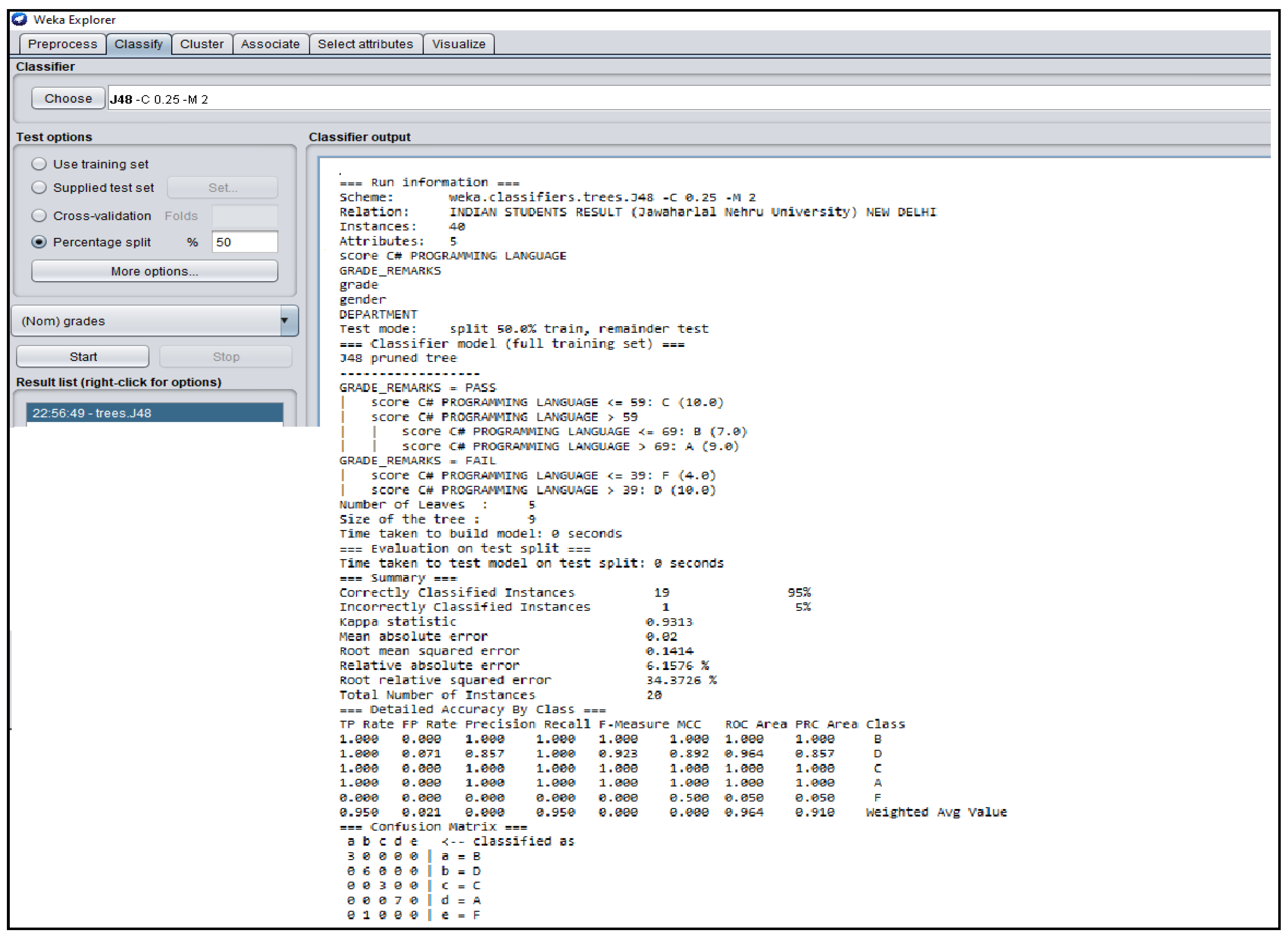
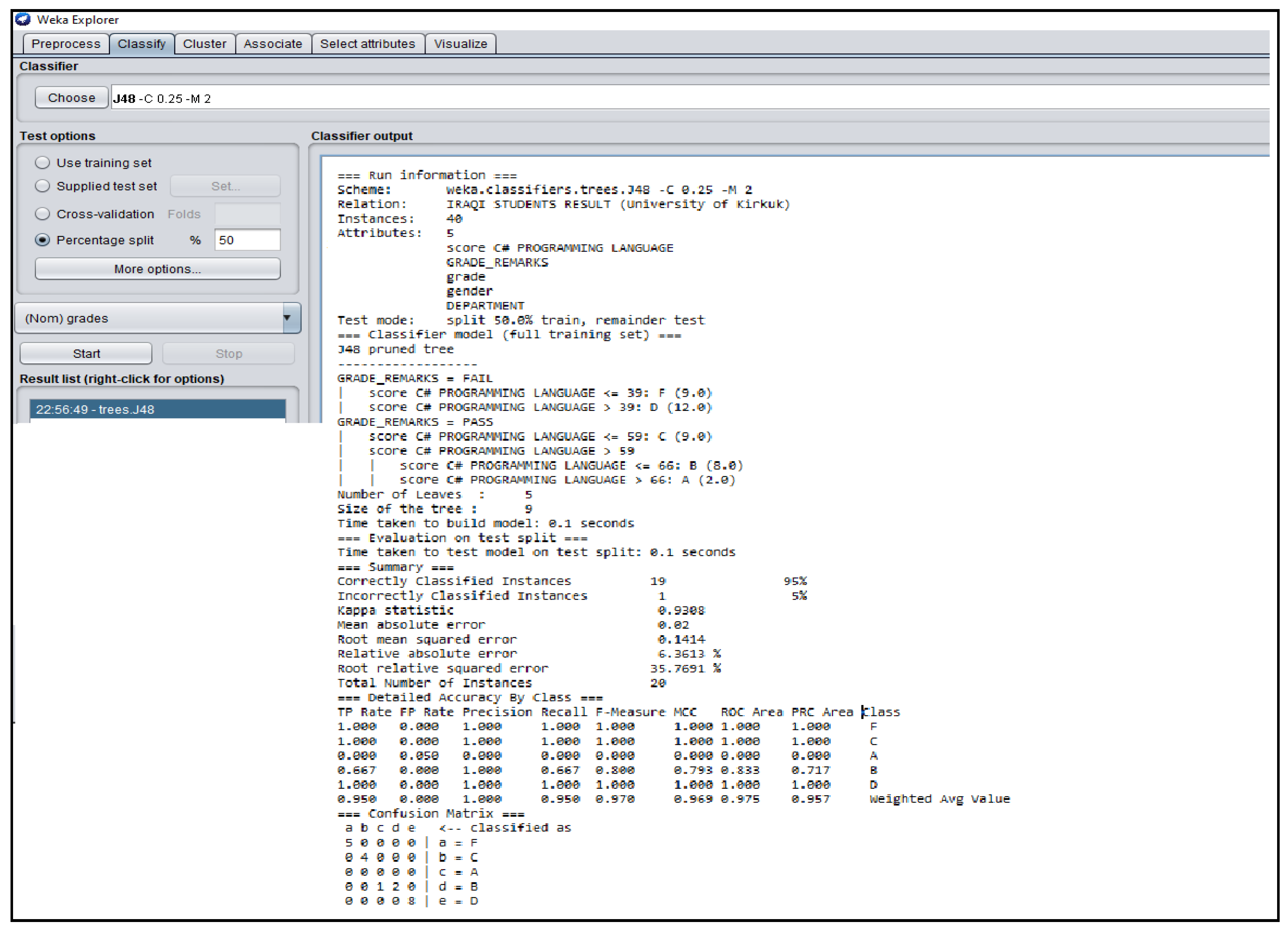
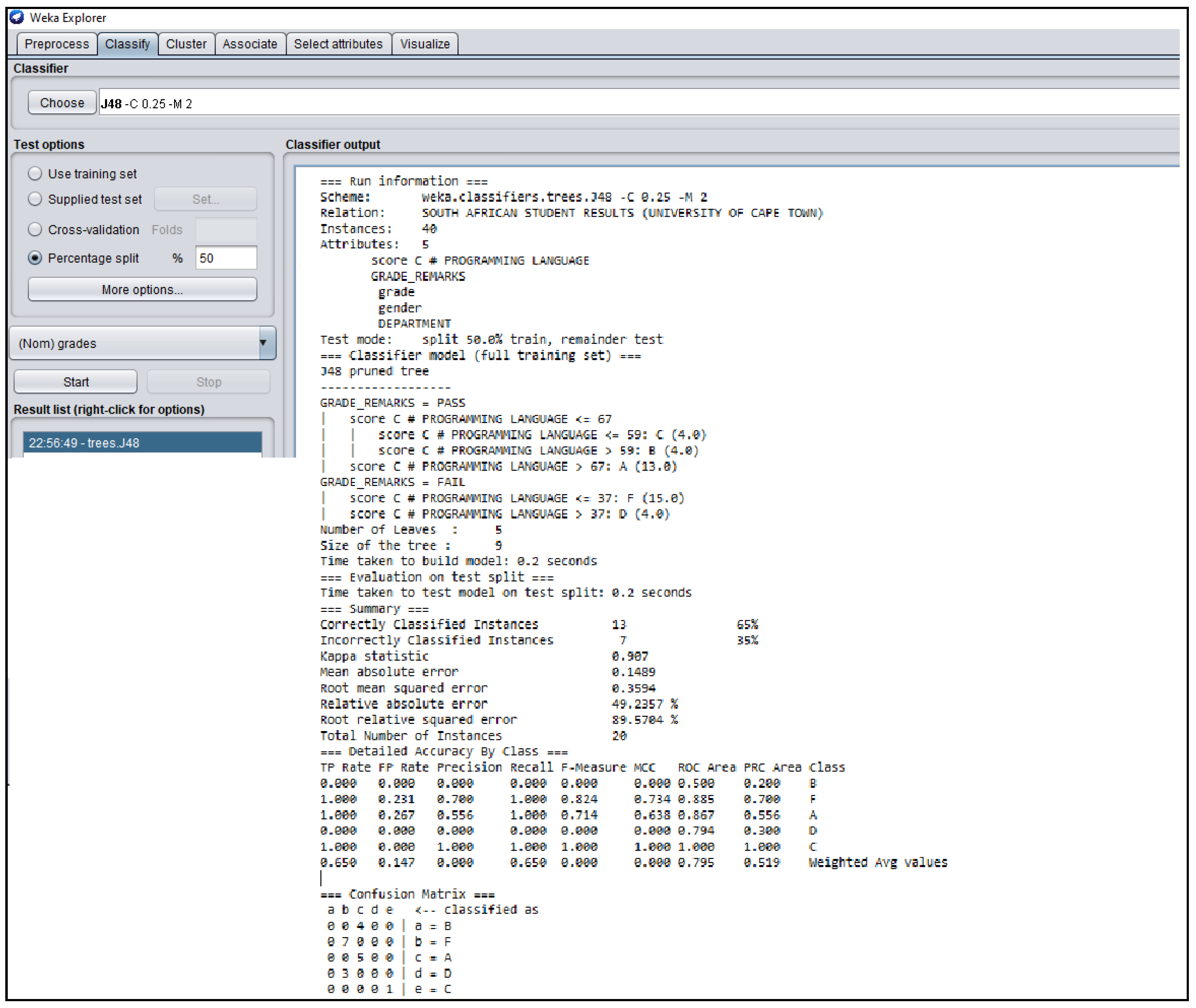
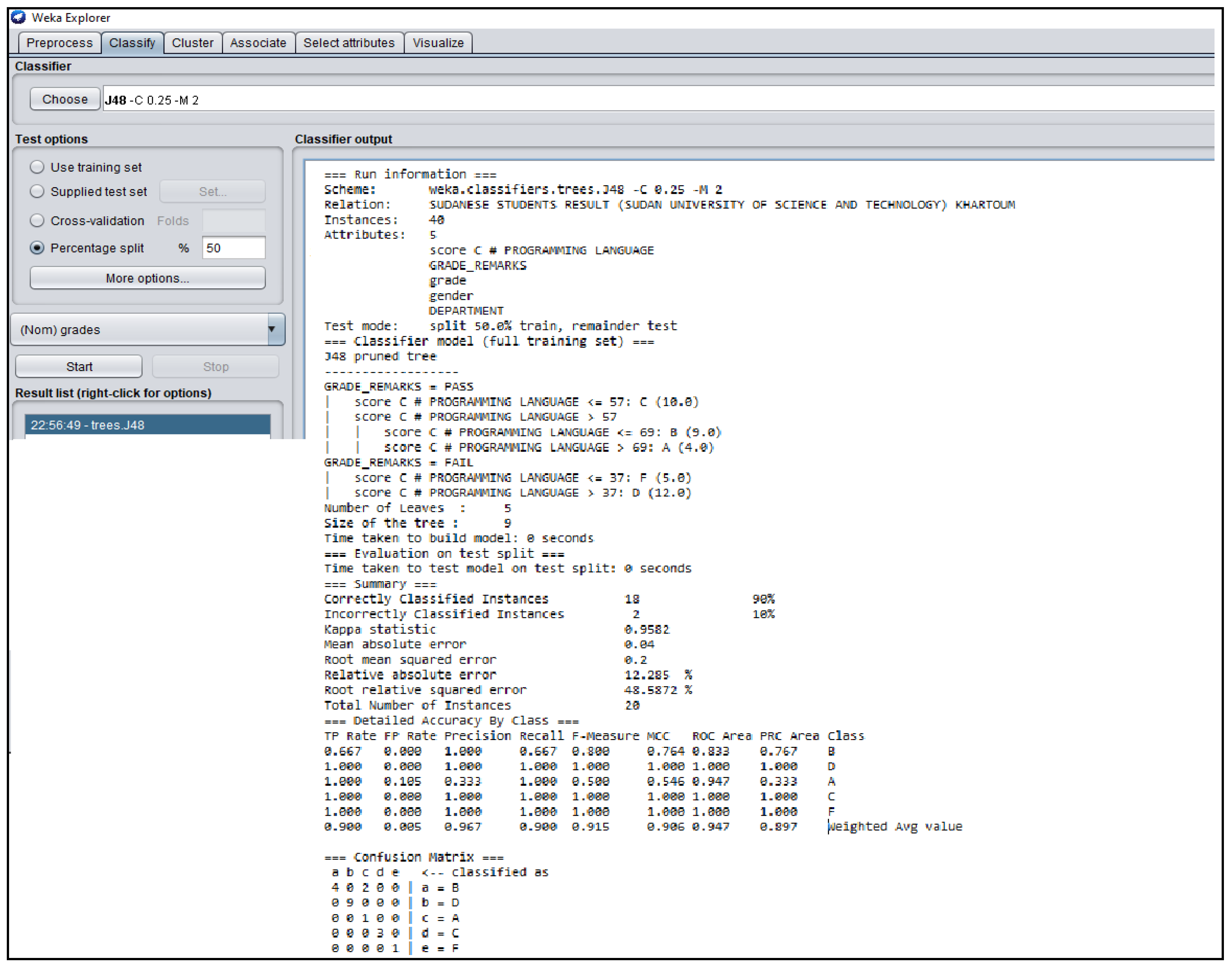
3.3. Outcomes of J48 Decision Tree Generated from Students’ Dataset Analysis
4. Results and Discussion
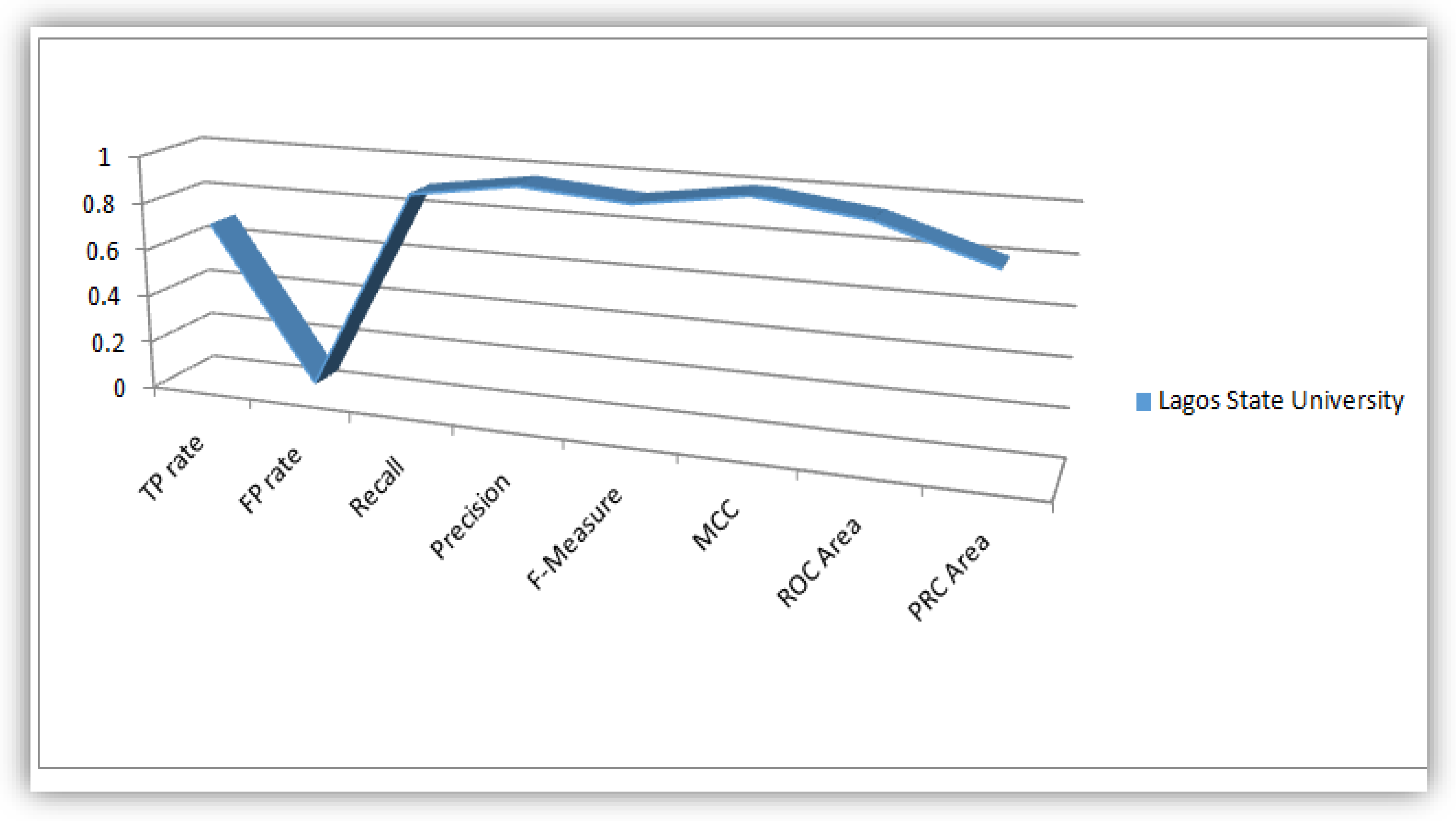
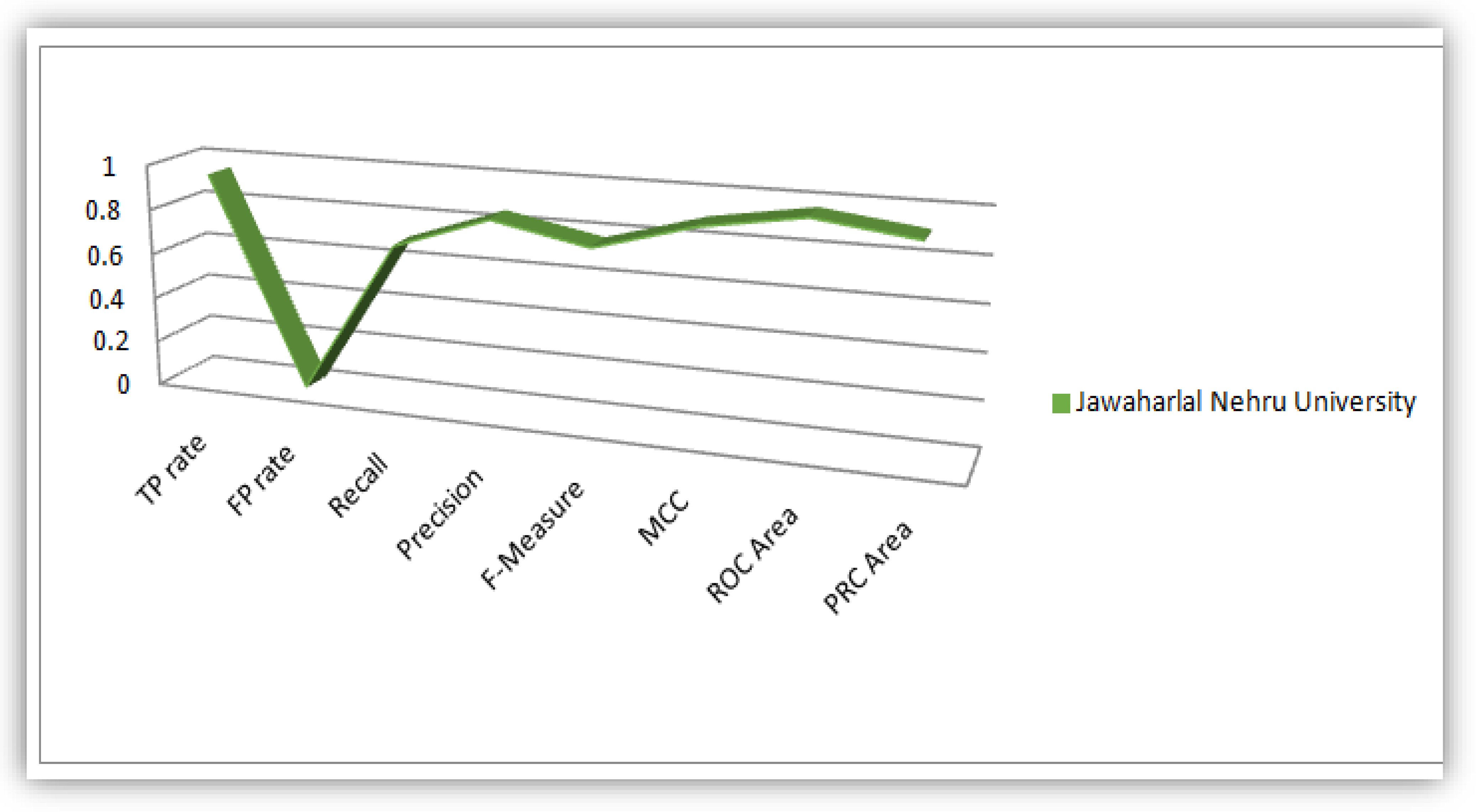
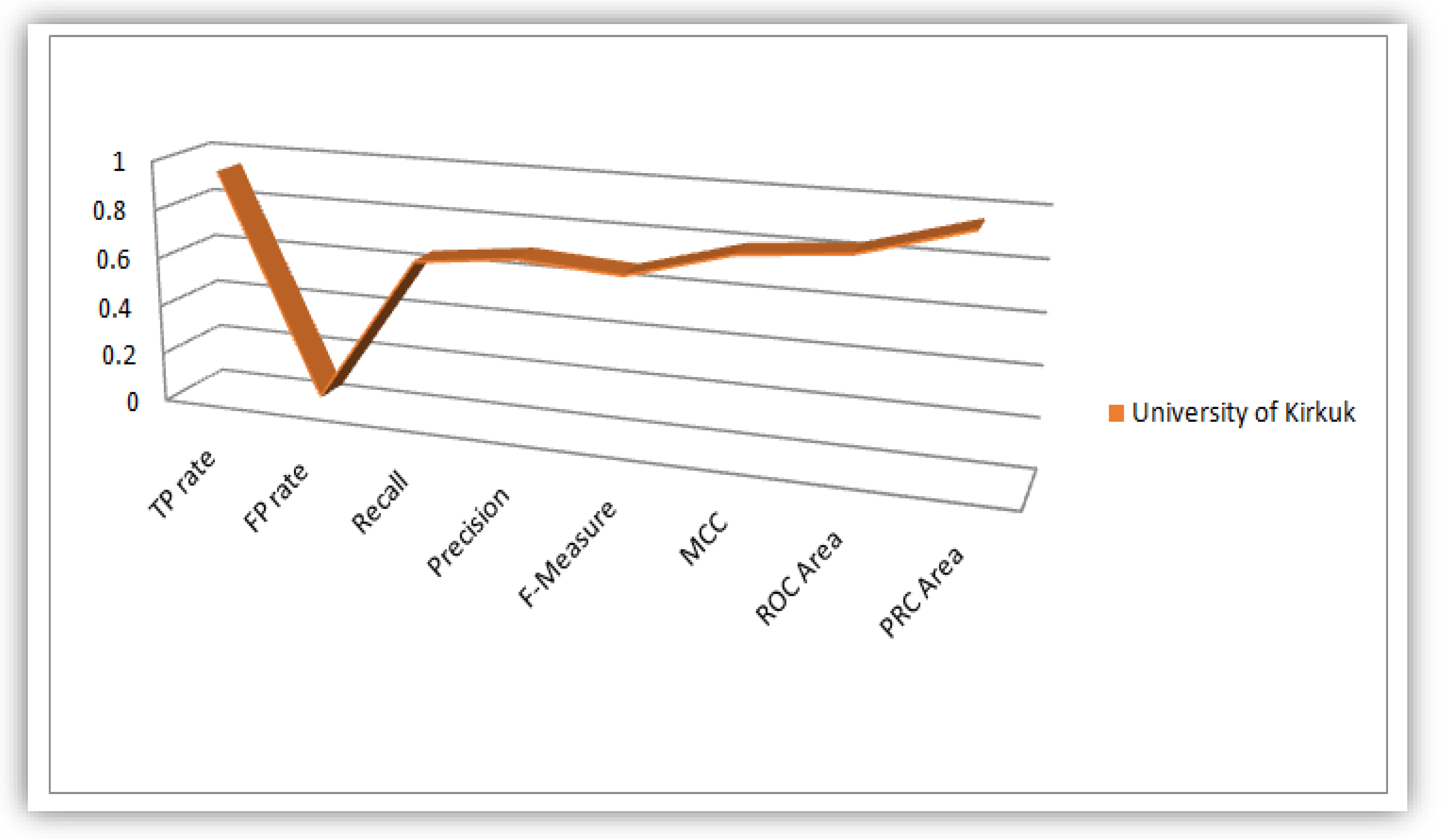
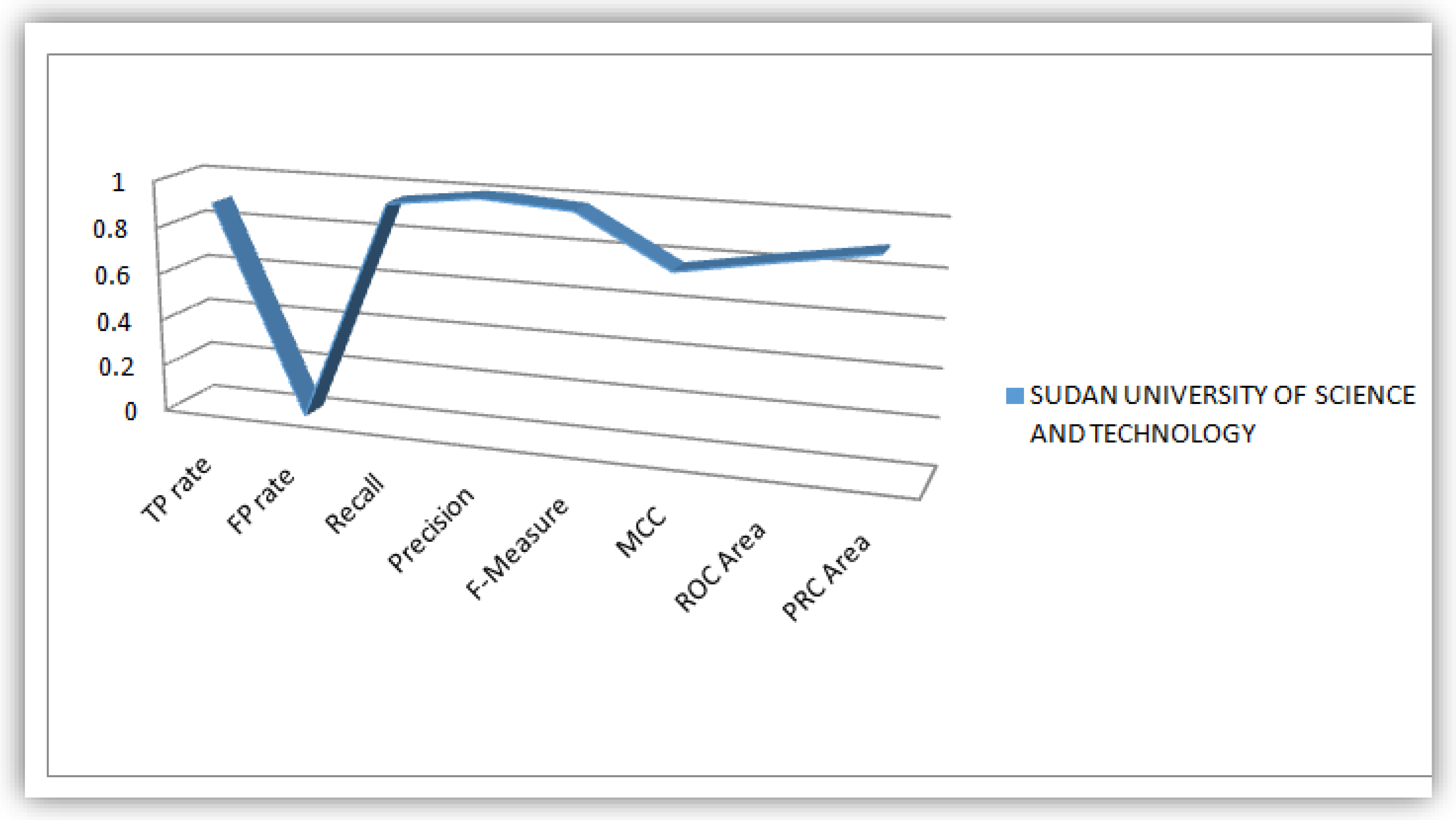
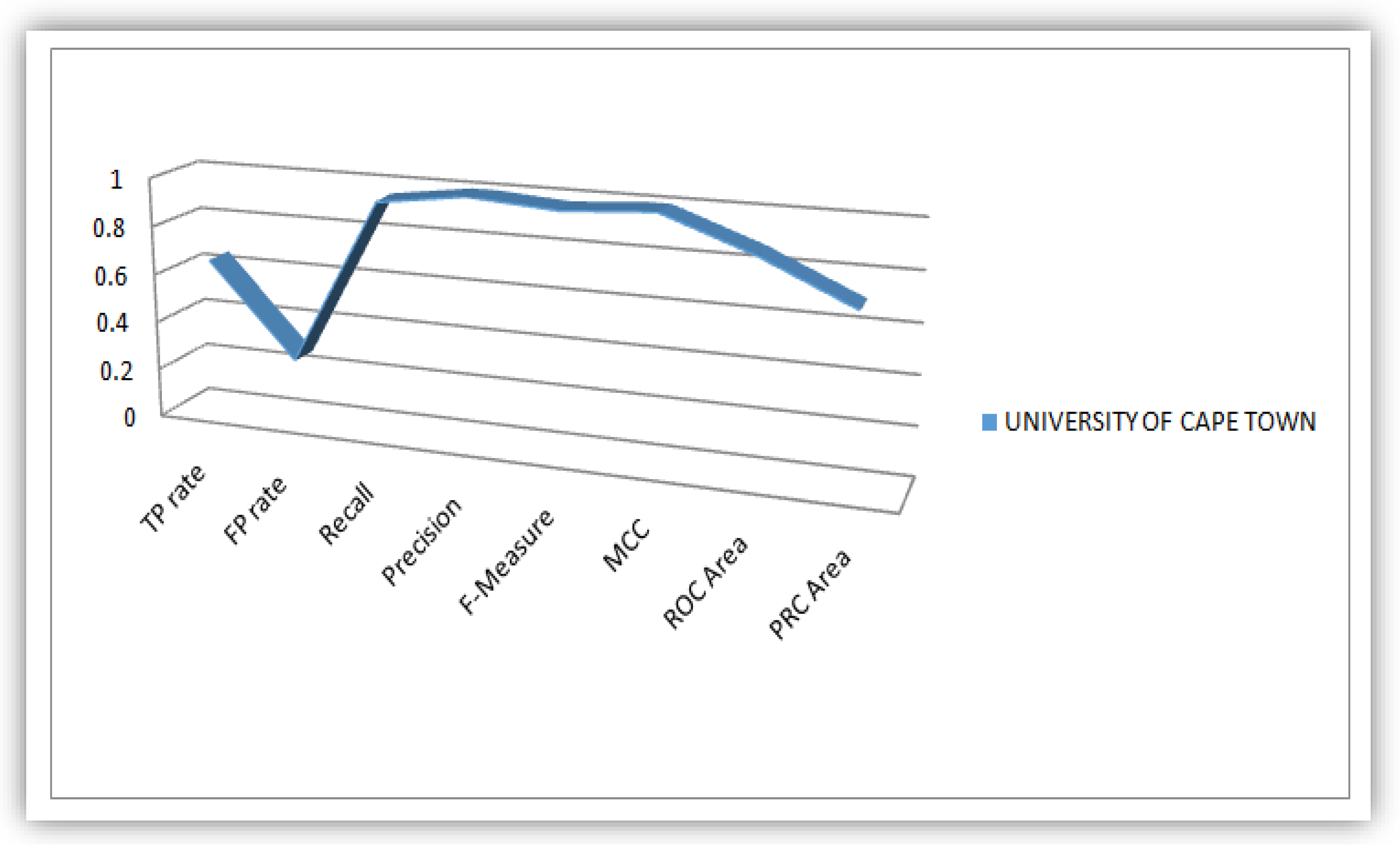
4.1. Plots of Evaluation Parameters from the Analysis Conducted on the Students’ Dataset
4.2. Analysis of J48 Decision Trees Generated in WEKA for the Five Universities
5. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclatures
| TP-rate | True Positive Rate |
| FP-rate | False Positive Rate |
| FN-rate | False Negative Rate |
| ROC Area | Receiver Operating Characteristics Area |
| PRC Area | Precision Recall Curve Area |
| MCC | Matthews Correlation Coefficient |
| PPV | Positive Predictive Value |
| KDD | Knowledge Discovery in Database |
| WEKA | Waikato Environment for Knowledge Analysis |
| EDM/LA | Educational Data Mining and Learning Analytics |
| ID3 | Iterative Dichotomiser 3 |
| J48 | Java 48 |
Appendix A










References
- Tsinidou, M.; Gerogiannis, V.; Fitsilis, P. Evaluation of the factors that determine quality in higher education: An empirical study. Qual. Assur. Educ. 2010, 18, 227–244. [Google Scholar] [CrossRef] [Green Version]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Jiawei, H.; Kamber, M. Data mining: Concepts and Techniques. University of Illinois at Urbana-Champaign, 2001. Available online: http://hanj.cs.illinois.edu/bk2/toc.pdf (accessed on 4 April 2022).
- Aziz, A.A.; Ismail, N.H.; Ahmad, F. Mining Students’ Academic Performance. J. Theor. Appl. Inf. Technol. 2013, 53, 485–495. [Google Scholar]
- Romero, C.; Ventura, S.; Espejo, P.G.; Hervas, C. Data mining algorithms to classify students. In Educational Data Mining; Computer Science Department, Corbora University: Andalusia, Spain, 2008. [Google Scholar]
- Salal, Y.K.; Abdullaev, S.M.; Kumar, M. Educational Data Mining: Student Performance Prediction in Academic. Int. J. Eng. Adv. Technol. IJEAT 2019, 8, 54–59. [Google Scholar]
- Garner, S.R. WEKA: The Waikato Environment for Knowledge Analysis. In Proceedings of the New Zealand Computer Science Research Students Conference, Hamilton, New Zealand, 18–21 April 1995; pp. 57–64. [Google Scholar]
- Maimon, O.; Rokach, L. Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar] [CrossRef]
- Abdullaev, S.M.; Salal, Y.K. An economic deterministic ensemble classifiers with probabilistic output using for robust quantification: Study of unbalanced educational datasets. In Proceedings of the 1st International Scientific and Practical Conference on Digital Economy (ISCDE 2019), Advances in Economics, Business and Management Research, Chelyabinsk, Russia, 7–8 November 2019; Volume 105, pp. 658–665. [Google Scholar] [CrossRef]
- Vranić, M.; Pintar, D.; Skočir, Z. The use of data mining in education environment. In Proceedings of the 9th International Conference on IEEE, Winchester, UK, 8–13 July 2007; pp. 243–250. [Google Scholar]
- Abdullaev, S.M.; Lenskaya, O.Y.; Salal, Y.K. Computer Systems of Individual Instruction: Background and Perspectives. Educ. Sci. 2018, 10, 64–71. [Google Scholar] [CrossRef]
- Sharma, G.M.; Bhargava, N.; Bhargava, R. Decision Tree analysis on J48 algorithm on Educational Data Mining. Proc. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1114–1119. [Google Scholar]
- Anjali, B.; Raut, A.A. Students Performance Prediction Using Decision Tree Technique with J48 algorithm. Int. J. Comput. Intell. Res. 2017, 13, 1735–1741. [Google Scholar]
- Mehta,, S.H.; Ashish, A. Predicting Students’ Performance using J48 Decision Tree. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2019, 4, 122–129. [Google Scholar]
- Algorithm and Flow Chart. Available online: https://faradars.org/wp-content/uploads/2015/07/Algorithm-and-Flow-Chart.pdf (accessed on 4 April 2022).
- Farhad, A.; Sanjay, P. Comparative Study of J48, Naive Bayes and One-R Classification Technique for Credit Card Fraud Detection using WEKA. In Advances in Computational Sciences and Technology; Research India Publications: Rohini, India, 2017; Volume 10, pp. 1731–1743. ISSN 0973-6107. [Google Scholar]
- Ihya, R.; Namir, A.; Sanaa, E.F.; Mohammed, A.D.; Fatima, Z.G. J48 Algorithms of Machine Learning for Predicting User’s the Acceptance of an E-Orientation Systems. In Proceedings of the 4th International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019. [Google Scholar]
- Kaur, G.; Chhabra, A. Improved J48 Classification Algorithm for the Prediction of Diabetes. Int. J. Comput. Appl. 2014, 98, 13–17. [Google Scholar] [CrossRef]
- Adhatrao, K.; Gaykar, A.; Dhawan, A.; Jha, R.; Honrao, V. Predicting Students performance using ID3 extension and C4.5 classification algorithms. Int. J. Data Min. Knowl. Manag. Process IJDKP 2013, 3, 39–52. [Google Scholar] [CrossRef]
- Chen, T.Y.; Kuo, F.C.; Merkel, R. On the Statistical Properties of the F-Measure. In Proceedings of the Fourth International Conference on Quality Software, 2004. QSIC 2004, Braunschweig, Germany, 8–9 September 2004; pp. 46–153. [Google Scholar]
- Srivastava, S.K.; Singh, S.K. Multi-Parameter Based Performance Evaluation of Classification Algorithms. Int. J. Comput. Sci. Inf. Technol. IJCSIT 2015, 7, 115–125. [Google Scholar] [CrossRef]
- Hussain, S.; Dahan, N.A.; Ba-Alwib, F.M.; Ribata, N. Educational Data Mining and Analysis of Students’ Academic Performance Using WEKA. Indones. J. Electr. Eng. Comput. Sci. 2018, 9, 447–459. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Countries | Mean Absolute Error | Kappa | Recall | Precision | F-Measure |
|---|---|---|---|---|---|
| India | 0.02 | 0.9313 | 0.700 | 0.850 | 0.7677 |
| South Africa | 0.1489 | 0.9070 | 0.950 | 1.000 | 0.9744 |
| Sudan | 0.04 | 0.9582 | 0.950 | 1.000 | 0.9744 |
| Iraq | 0.02 | 0.9308 | 0.650 | 0.700 | 0.6741 |
| Nigeria | 0.1114 | 0.9296 | 0.900 | 0.967 | 0.9323 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahim, W.; Abdullaev, S.; Alkattan, H.; Adelaja, O.A.; Subhi, A.A. Development of a Model Using Data Mining Technique to Test, Predict and Obtain Knowledge from the Academics Results of Information Technology Students. Data 2022, 7, 67. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050067
Ibrahim W, Abdullaev S, Alkattan H, Adelaja OA, Subhi AA. Development of a Model Using Data Mining Technique to Test, Predict and Obtain Knowledge from the Academics Results of Information Technology Students. Data. 2022; 7(5):67. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050067
Chicago/Turabian StyleIbrahim, Wisam, Sanjar Abdullaev, Hussein Alkattan, Oluwaseun A. Adelaja, and Alhumaima Ali Subhi. 2022. "Development of a Model Using Data Mining Technique to Test, Predict and Obtain Knowledge from the Academics Results of Information Technology Students" Data 7, no. 5: 67. https://0-doi-org.brum.beds.ac.uk/10.3390/data7050067