Multivariate Statistical Approach to Image Quality Tasks
by
 ,
,
Praful Gupta
1,*,† ,
,
Christos G. Bampis
2,
Jack L. Glover
3,4,
Nicholas G. Paulter
3 and
Alan C. Bovik
1,† 1
Department of Electrical and Computer Engineering, The University of Texas at Austin, Austin, TX 78712, USA
2
Netflix Inc., Los Gatos, CA 95032, USA
3
National Institute of Standards and Technology, Gaithersburg, MD 20899, USA
4
Theiss Research, La Jolla , CA 92037, USA
*
Author to whom correspondence should be addressed.
†
Current address: Engr Education and Research Center (EER), The University of Texas at Austin, 2501 Speedway, Austin, TX 78712, USA.
J. Imaging 2018, 4(10), 117; https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging4100117
Submission received: 15 September 2018
/
Revised: 6 October 2018
/
Accepted: 10 October 2018
/
Published: 12 October 2018
(This article belongs to the Special Issue Image Quality)
Abstract
:Many existing natural scene statistics-based no reference image quality assessment (NR IQA) algorithms employ univariate parametric distributions to capture the statistical inconsistencies of bandpass distorted image coefficients. Here, we propose a multivariate model of natural image coefficients expressed in the bandpass spatial domain that has the potential to capture higher order correlations that may be induced by the presence of distortions. We analyze how the parameters of the multivariate model are affected by different distortion types, and we show their ability to capture distortion-sensitive image quality information. We also demonstrate the violation of Gaussianity assumptions that occur when locally estimating the energies of distorted image coefficients. Thus, we propose a generalized Gaussian-based local contrast estimator as a way to implement non-linear local gain control, which facilitates the accurate modeling of both pristine and distorted images. We integrate the novel approach of generalized contrast normalization with multivariate modeling of bandpass image coefficients into a holistic NR IQA model, which we refer to as multivariate generalized contrast normalization (MVGCN). We demonstrate the improved performance of MVGCN on quality-relevant tasks on multiple imaging modalities, including visible light image quality prediction and task success prediction on distorted X-ray images.
1. Introduction
The perceptual quality assessment of visual media has drawn considerable attention in the recent past owing to the millions of images and videos captured and shared daily on social media websites, such as Facebook, Twitter and Instagram. Large-scale video streaming services such as YouTube, Netflix and Hulu contribute heavily to Internet traffic, which continues to expand rapidly as consumer demand for content increases. Reliable assessment of picture quality by large groups of human subjects is an inconvenient, time-consuming task that is very difficult to organize at scale. Thus, objective no-reference (NR) image quality assessment (IQA) models, which do not require any additional information beyond the input image, are often deployed in such settings to predict visual quality automatically and accurately as perceived by an average human subject. These models have also been successfully used to optimize the image capture process perceptually to improve the perceptual quality of the acquired visual signals. In addition, “quality-aware” perceptual strategies are used to compress visual media to deliver high quality content to consumers over constrained network bandwidths [1].
Many NR IQA algorithms have been proposed recently, which for increased clarity, we will broadly classify into three categories. (1) Distortion-specific approaches include algorithms that predict the quality of images afflicted by one or more known distortion types such as blockiness [2], ringing [3] and blur [4,5] artifacts. These models are difficult to generalize to other distortion types. (2) Purely data-driven approaches involve the extraction of low-level image features such as color and texture statistics [6], which are then mapped to subjective image quality scores using regression. More recently, deep learners have been trained to learn large sets of low level image features, which are then used to feed classical regressors that map the features to subjective quality space [7]. The general framework of convolutional neural network-based IQA models involves feeding a pre-processed patch to convolutional layers, which are often followed by pooling layers. The learned features are then fed to a combination of fully-connected layers followed by non-linear activation and dropout layers [8,9]. (3) Natural scene statistics (NSS)-based approaches leverage statistical models of natural images and quantify the severity of distortion by measuring the degree of “unnaturalness” caused by the presence of distortions. The perceptual image quality is measured as a distance of the distorted image from the subspace of natural images [10,11,12,13].
A number of techniques have been devised for general-purpose NR IQA. The generalized Renyi entropy and normalized pseudo-Wigner distribution have been used to model the directionality or anisotropicity of the variance of expected entropy to predict image quality [14]. NSS-based models have been designed to extract quality-aware features under natural image models in the wavelet [13], spatial [12] and discrete cosine transform (DCT) domains [15], achieving high correlations with human opinion scores.
The divisive normalization transform (DNT), which is used to model the nonlinear response properties of sensory neurons, forms an integral component in the density estimation of natural images [16]. A commonly-used parametric form of DNT is:
where denotes a natural image signal that has been processed with a linear bandpass filter and are parameters that can be optimized on an ensemble of natural image data. As shown in [17], when bandpass natural images are subjected to DNT with , they become Gaussianized with reduced spatial dependencies. The underlying Gaussian scale mixture (GSM) [18] model of the marginal and joint statistics of natural (photographic) image wavelet coefficients also implies similar normalization () of neighboring coefficients. In our recent work, we developed a generalized Gaussian scale mixture (GGSM) model of the wavelet coefficients of photographic images, including distorted ones [19]. This new model factors a local cluster of wavelet coefficients into a product of a generalized Gaussian vector and a positive mixing multiplier. The GGSM model demonstrates the hypothesis that the normalized wavelet-filtered coefficients of distorted images follow a generalized Gaussian behavior, devolving into a Gaussian if distortion is not present. A related approach was adopted in [20], where a finite generalized Gaussian mixture model (GGMM) was used as a prior when modeling image patches in an image restoration task.
Here, we build on the above ideas and propose a generalized Gaussian-based local contrast estimator, which we use in conjunction with a multivariate density estimator to extract perceptual quality-rich features in the spatial domain.
NSS models have been well studied on an increasing variety of natural imaging modalities, including visible light (VL), long wavelength infrared (LWIR) [21], fused VL and LWIR [22] and X-ray images [23]. This kind of statistical modeling of these imaging modalities has led to the development of new and interesting applications and are of significance to the design of visual interpretation algorithms. In a like vein, here we explore the effectiveness and versatility of multivariate generalized contrast normalization (MVGCN) by deploying it in applications arising in two different imaging modalities; specifically, blind quality assessment (QA) of VL images and the prediction of technician detection task performance on distorted X-ray images.
The rest of the paper is organized as follows. In Section 2, we describe the generalized contrast normalization technique, which forms the core of MVGCN. We detail the multivariate statistical image model in Section 3 and analyze the effects of distortions on the estimated parameters of the multivariate model. Section 5 describes the first application, whereby MVGCN features are used to predict the detection task performance of trained bomb experts on X-ray images. The second application is explained in Section 4, where the MVGCN model is used to drive an NR IQA algorithm. Finally, Section 6 concludes the paper with possible ideas for future work.
2. Generalized Contrast Normalization
It is well established in the vision science and image quality literature that processing a natural scene by a linear bandpass operation followed by non-linear local contrast normalization has a decorrelating and Gaussianizing effect on the pixel values of the images of these natural scenes [24,25,26]. This kind of processing of visual data mirrors efficient representations computed by neuronal processing that takes place along the early visual pathway. These statistical models of natural (photographic) images have been used effectively in applications ranging from low-level tasks such as image denoising [27,28,29] and image restoration [30,31], as well as higher level processes such as face recognition [32,33], object detection [34,35] and segmentation [36,37].
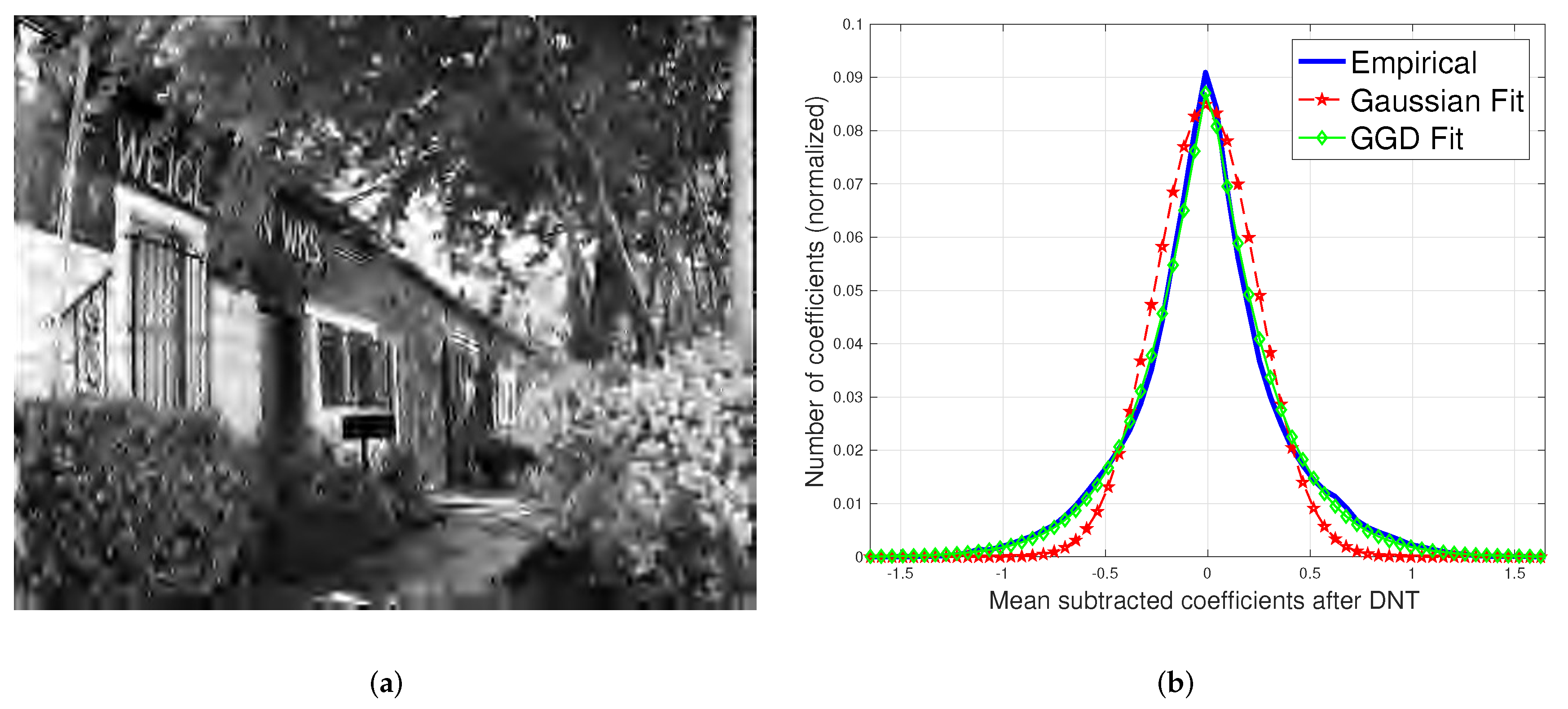
A number of NSS-based IQA algorithms [12,13] operate under the hypothesis that the divisively normalized bandpass responses of a pristine image follow Gaussian behavior and that the presence of distortion renders an image statistically unnatural, whereby the characteristic underlying Gaussianity is lost [17], as depicted in Figure 1, where Gaussianity is a poor fit to the distribution of bandpass, divisively normalized coefficients of a JP2000(JP2K) compressed image. Here, we propose a way of collectively modeling both pristine and distorted images, using a generalized contrast normalization approach that is based on the premise that the divisively normalized bandpass coefficients of both distorted and undistorted images follow a generalized Gaussian distribution. We refer to the processed coefficients as mean subtracted generalized contrast normalized (MSGCN) coefficients.
Given a grayscale image of intensity , the MSGCN coefficients are computed as:
where and are the local weighted mean (the maximum likelihood estimate of the mean of a generalized Gaussian density is given by: Optimizing over each block of size of an image is computationally expensive; thus, we instead use the sample mean of the coefficients given by (3), as used in [12].):
and local contrast fields defined as:
where , are spatial indices and is a 2D isotropic Gaussian kernel normalized to unit volume with and truncated to three standard deviations. C and are small positive constants used to prevent instabilities. is estimated using the popular moment-matching technique detailed in [38]. The generalized Gaussian corresponds to a Gaussian density function when and a Laplacian density function when . MSGCN coefficients behave in a similar manner against different distortion types as do mean subtracted contrast normalized (MSCN) coefficients that are generated under the Gaussian model assumption () [12]. Distortions such as white noise tend to increase the variance of MSGCN coefficients, while distortions such as compression and blur, which increase correlations, tend to reduce variance. The MSGCN model is more generic than the MSCN model and provides an elegant approach to study the statistics of distorted images.
3. Multivariate Image Statistics
In this section, we use the aforementioned MSGCN coefficients to develop a multivariate NSS model and a way to extract quality-rich features. The generalized contrast normalization (GCN) transform is a form of local gain control mechanism that accounts for the non-linear properties of neurons, resulting from the pooled activity of neighboring sensory neurons [39]. These kinds of perceptually-relevant transformations account for the contrast masking effect, which plays an important role in distortion perception [39]. Although the GCN transform, as with other DNTs, reduces redundancies in visual data, the normalized coefficients of natural images may still exhibit dependencies in some form (depending on the image content), as depicted in Figure 2. Distortions such as compression, upscaling and blur, which reduce the amount of complexity of an image and that induce artificial correlations, tend to affect the MSGCN coefficients in a pronounced way. Increased statistical interdependencies are observed to occur between neighboring coefficients with increased distortion strength.
3.1. The Multivariate Generalized Gaussian Distribution
Once the MSGCN map of an input image is computed using (2), a 5D multivariate generalized Gaussian (MVGG) distribution is used to model the joint distribution of five neighboring coefficients as illustrated in Figure 3.
MVGG distributions have been extensively studied in the literature [41,42,43,44]. We utilize the Kotz-type distribution [41], which is a form of zero-mean multivariate elliptical distribution defined as:
where s is a shape parameter that determines the exponential fall-off of the distribution (the higher s, the lower the fall-off rate), is the scale parameter (matrix) that controls the spread of the coefficients along different dimensions, d is the dimension of and is the gamma function:
The MVGG distribution becomes a multivariate Laplace distribution when , a multivariate Gaussian distribution when and a multivariate uniform distribution as .
This form of MVGG distribution has also been used in a reduced-reference IQA framework [45], in an RGB color texture model [46] of the joint statistics of color-image wavelet coefficients, a generalized Gaussian scale mixture (GGSM) model of the conditioned density of a GGSM vector [19] and in a no-reference IQA algorithm [15] to model the joint empirical distribution of extracted DCT features and subjective scores, where a bivariate version of the MVGG is used. The moment-matching scheme [41] used to estimate the shape and scale parameters of an MVGG is detailed in the Appendix A.
3.2. Analysis of the Shape Parameter of the MVGG Distribution
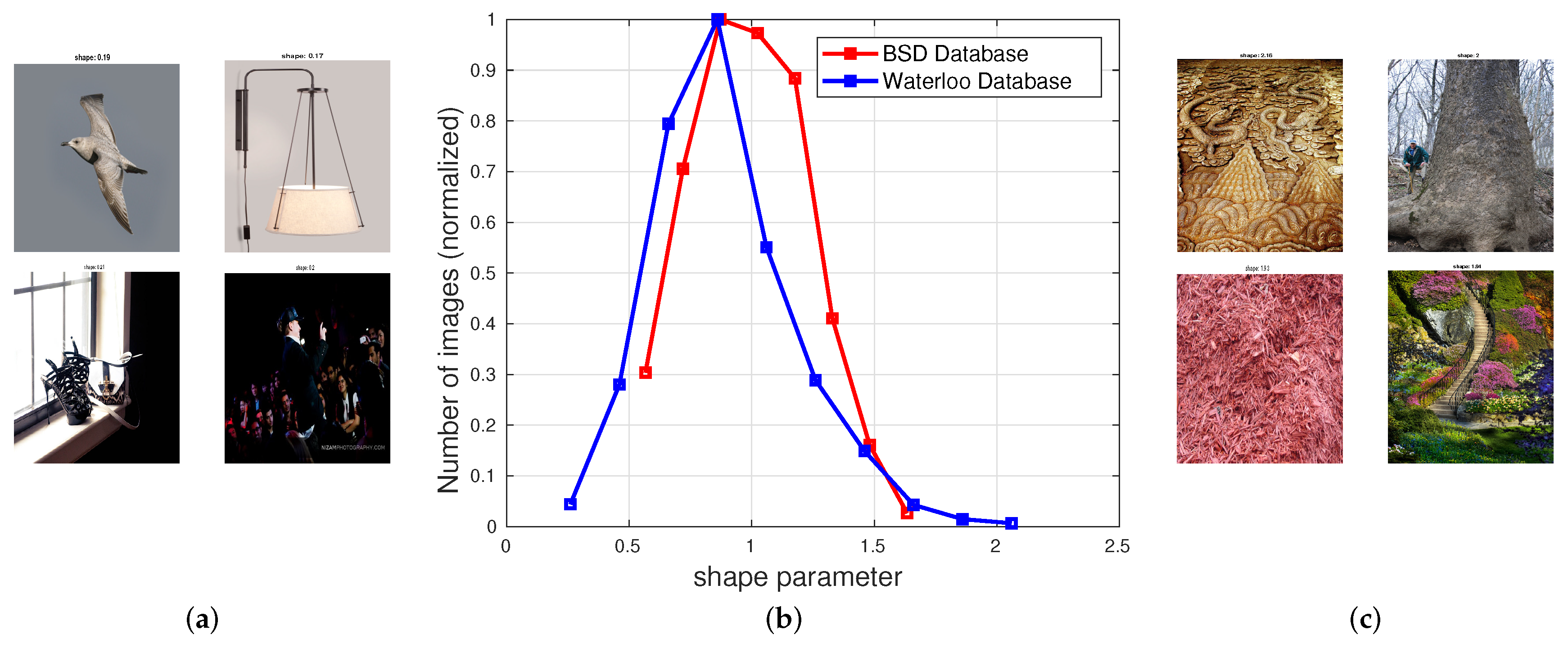
We next analyze how the shape parameter of the MVGG distribution varies when modeling the joint distribution of adjacent MSGCN coefficients of natural, photographic images from two widely used databases: the Waterloo exploration database [47] and the Berkeley Segmentation Database (BSD) [48]. The Waterloo exploration IQA database contains 4744 pristine natural images reflecting a great diversity of real-world content. The Berkeley Segmentation Database was designed to support research on image segmentation and contains 300 training images and 200 test images. In our analysis, we only used ostensibly pristine images to generate MSGCN response maps, toward modeling a five-dimensional joint empirical distribution of neighboring MSGCN coefficients using an MVGG density. Figure 4b plots a histogram of the estimated shape parameter values of the MVGG model. The shape parameter peaked at around the same value () on both databases, suggesting that the joint distribution of MSGCN coefficients of the pristine images may be reliably modeled as a multivariate Gaussian. This outcome may be viewed as a multivariate extension of the well-established Gaussian property of univariate normalized bandpass coefficients [18,24,25,26]. There are, however, a few samples within the studied collection of natural images where the estimated shape parameter deviated from . For example, a few images from the Waterloo exploration database, e.g., those shown in Figure 4a, contain predominantly flat, highly correlated regions that yielded peakier MVGG fits where . Cloudless sky regions (upper left of Figure 4a) are bereft of any objects and cause this effect. The lower two images of Figure 4a have large saturated over/under-exposed areas and may be viewed as substantially distorted. Overall, undistorted non-sky images of this type are rare. Conversely, the images shown in Figure 4c are each almost entirely comprised of heavily textured regions, with less peaky fits (). These kinds of images are also unusual.
3.3. Effect of Distortions on the Shape Parameter
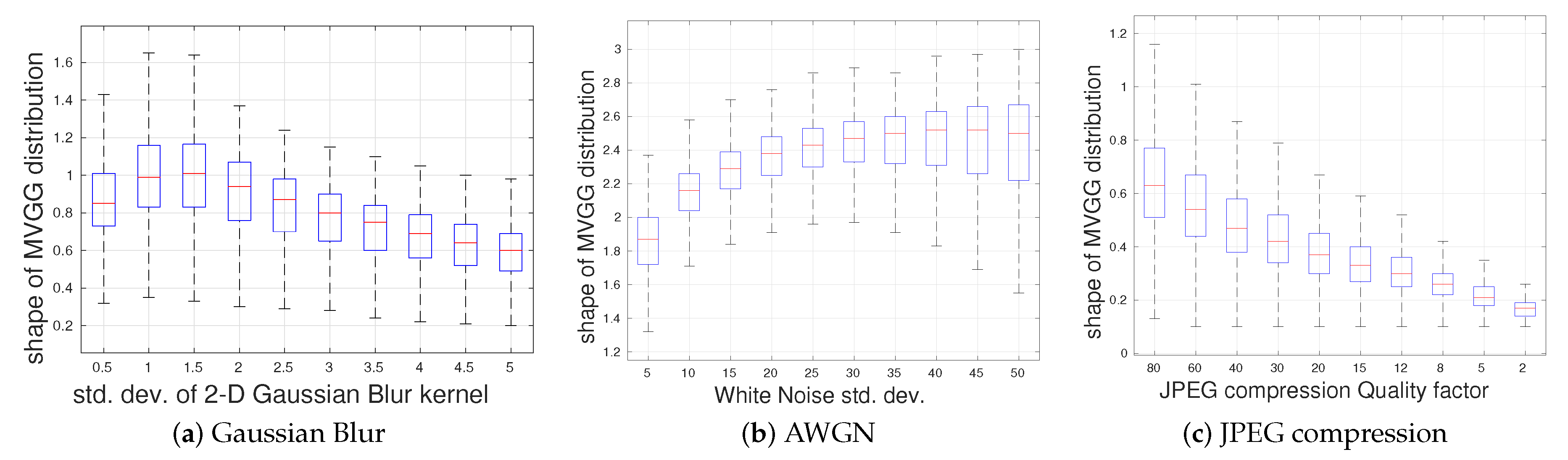
Having established the relevance of the shape parameter of the MVGG and values it assumes on pristine images, we next examine how it behaves in the presence of distortions. In this experiment, we degraded 1000 pristine images from the Waterloo exploration database using three common distortions: JPEG compression, Gaussian blur and additive white Gaussian noise (AWGN), each applied at ten different levels. We then followed a similar modeling procedure as that described in the previous subsection: we fit the 5D empirical joint distribution of MSGCN coefficients of the distorted images with an MVGG distribution. Figure 5 depicts the way the shape parameter characteristically varies in the presence of the different degradation types and levels. Gaussian blur (Figure 5a) and JPEG (Figure 5c) degradations lead to peaky, heavy-tailed MVGG fits and reduced values of s. This effect becomes more pronounced with increasing distortion strength. Conversely, AWGN (Figure 5b) degradations increase the randomness and entropy of an image, leading to larger values of s.
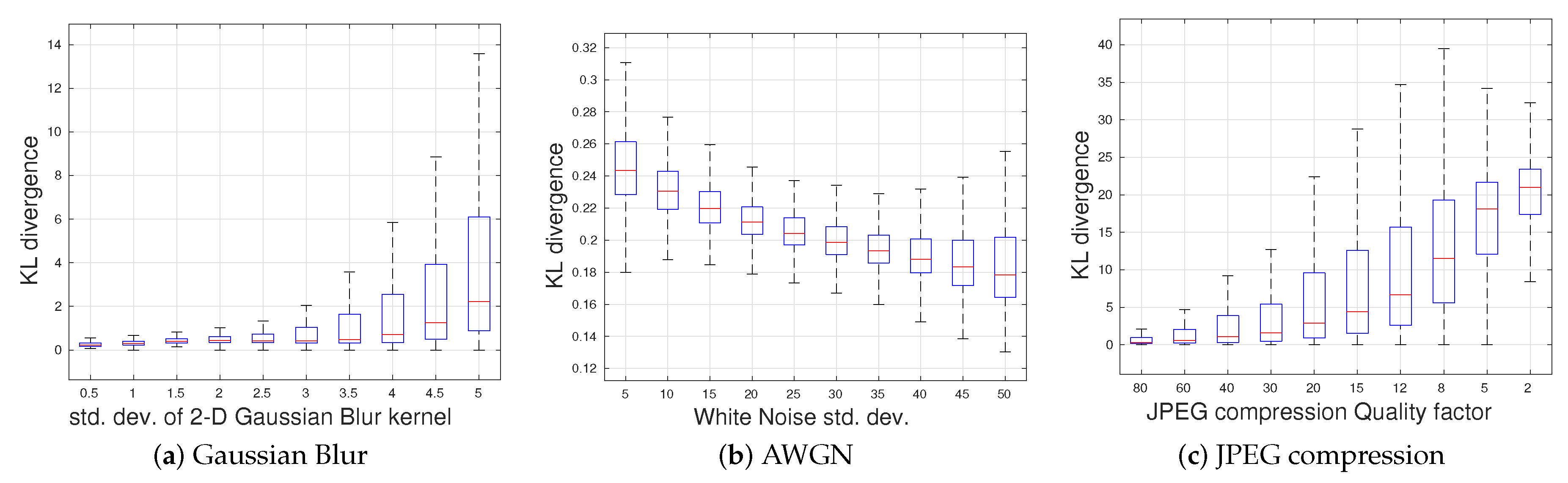
The presence of some degradations deviate the distributions of distorted MSGCN coefficients from multivariate Gaussian behavior. To better understand this effect, we computed the Kullback–Leibler (KL) divergences between the empirical bivariate joint distribution of vertically adjacent MSGCN coefficients and its multivariate Gaussian fit, which are shown in Figure 6. Computing the KL divergence between an empirical 5D joint distribution and its 5D Gaussian fit is computationally expensive for a large sample size; thus, we resorted to only computing a bivariate joint distribution of immediate neighbors. As shown in Figure 6b, increases of the AWGN standard deviation produced a slight decrease in the KL divergence, indicating that the joint distribution of the MSGCN coefficients becomes more similar to Gaussian, which is not unexpected given that the AWGN is Gaussian. Degradations such as blur and JPEG compression, which result in peakier MVGG fits, caused larger KL divergences, which increase with increasing distortion levels.
3.4. Feature Extraction
Given that the MVGG model can be used to characterize distorted image statistical behavior well, we can build feature-driven image quality prediction tools. As a first set of “quality-aware” features, compute the estimated shape parameter s and the five eigenvalues of the estimated covariance (scale) matrix of the MVGG distribution. The premise behind the choice of these features is that the joint distribution of neighboring MSGCN coefficients of pristine images follows a multivariate Gaussian distribution, but the presence of distortion causes deviation from Gaussianity. Since each distortion affects the coefficient distributions in a characteristic manner, it is possible to predict the type and perceptual severity of distortions and, hence, the perceived image quality.
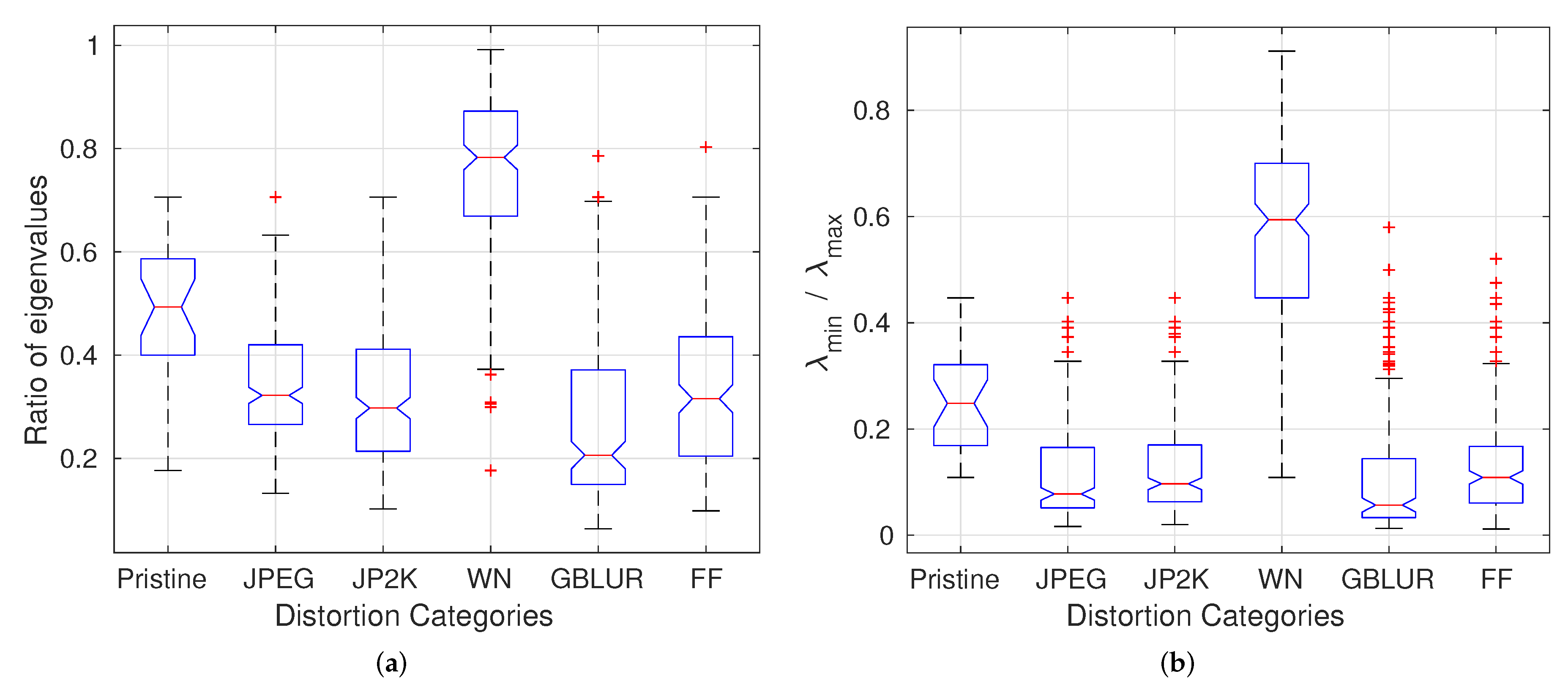
As shown in Figure 2, even after the application of the GCN transform, the MSGCN responses remain correlated on images degraded by correlation-inducing distortions such as compression and blur. Such distortions lead to more polarized eigenvalues of the estimated covariance matrix than do other distortions (AWGN). In order to demonstrate the effect of distortions on the eigenvalues, we use the ratio of the minimum and maximum eigenvalues () of the estimated scale matrix from the best 2D MVGG fit to the vertically adjacent MSGCN coefficients. We also fit a 5D MVGG to the five neighboring coefficients (as shown in Figure 3). Figure 7 shows the boxplots of the ratio over all images from the LIVE database [40], but classified by distortion type. The pattern of variation of the eigenvalues of the estimated covariance matrix in the presence of different distortion types is indicative of the rich perceptual quality information captured by eigenvalues.
The pairwise products of adjacent MSGCN coefficients, like those of MSCN coefficients, also exhibit statistical regularities on natural, photographic images. We follow a similar modeling approach as that described in [12] and use a zero-mode asymmetric generalized Gaussian distribution (AGGD) to fit the pairwise products along four directions whose density is defined as [12]:
where:
and:
The AGGD parameters are estimated using the moment-matching technique described in [49]. In addition to , AGGD mean yields a fourth quality-aware feature. Extracting these four parameters along four orientations () given by:
where and are spatial indices, yields a total of 16 features.
In order to capture even higher-order correlations caused by complex distortions, we model the joint paired-product response map along the four directions () using a four-dimensional MVGG distribution. The eigenvalues of the estimated covariance matrix of the 4D MVGG density are extracted as an additional set of four quality-relevant features. Since all of the features are extracted at two scales, a total of perceptually-relevant quality-aware MVGCN features are computed. A brief summary of all of these features and their methods of computation is laid out in Table 1. In subsequent sections, we study the effectiveness of the MVGCN features by applying them to multiple image quality-relevant tasks.
4. Quality Assessment of Visible Light Images
In order to demonstrate the quality-rich feature extraction capabilities of the MVGCN model, we utilized them for the blind image quality assessment task. We compared the performance of MVGCN against a number of well-known NR IQA algorithms, such as SSEQ [50], CORNIA [51], CNN-IQA [8], BLIINDS [15], NIQE [10], BRISQUE [12] and DIIVINE (to be consistent with other algorithms, we utilized the single step framework of DIIVINE, directly mapping the features to MOS/differential mean opinion scores (DMOS) while skipping the distortion identification stage) [13] (all of which are publicly available) and two full reference (FR) IQA algorithms: PSNR and MS-SSIM [52]. We conducted our experiments on four widely-used IQA databases, namely: LIVE [40], TID08 [53], CSIQ [54] and LIVE in the Wild Challenge [55]. In all of the experiments, each model was trained on of the database while the other was used for testing. A support vector regressor (SVR) was used with the radial basis function (RBF) to map quality features to the DMOS after determining its parameters using five-fold cross-validation on the training set. The train-test splits were carried out in a manner to ensure that the training and test sets would not share reference images, so that the performances of the models would reflect their ability to learn distortions, without bias from overfitting on image content. A total of 100 such splits was performed, and the median Spearman’s rank ordered correlation coefficient (SROCC) and Pearson’s linear correlation coefficient (PLCC) computed between the predicted quality scores and the DMOS are reported in Table 2. The overall results reported in Table 2 were computed by first applying Fisher’s z-transformation [56] given by:
then averaging the transformed correlation scores for each method across each database and finally applying the inverse Fisher’s z-transform.
Learning-based algorithms that involve a training stage to learn optimal parameters are sometimes susceptible to overfitting, especially when trained and tested on the same database, due to similar modeling of distortions, similar experimental conditions and other factors. The main objective of NR IQA algorithms is their ability to generalize well on other datasets. To demonstrate the generalization capabilities, we trained the NR IQA models on one entire database and evaluated their performance on common distortion types from other databases, including: JPEG2000 (JP2K) and JPEG compression, Gaussian blur and AWGN. Table 3 reports the database-independence performance of MVGCN, while Table 4 compares its aggregate performance against other NR IQA models across four leading IQA databases. We used the non-parametric Wilcoxon rank-sum test to conduct the statistical significance analysis (reported in Table 5) between different algorithms across multiple databases. As can be noted from the tables, MVGCN performed better than several leading NSS-based NR IQA algorithms and competed well against CORNIA [51], which uses raw image patches in an unsupervised manner to learn a dictionary of local descriptors. CORNIA extracts a 20,000D feature vector and is much more computationally expensive than MVGCN, as shown in the time complexity analysis results reported in Table 6. Although CNN-IQA performed better than other models on the CSIQ and TID08 databases, it failed to deliver comparable performance on the LIVE Challenge database, which consists of authentic real-world distortions. This raises questions on the practical application of such models and limits their use in real-world scenarios.
5. Predicting Detection Performance on X-Ray Images
In previous work, we studied the natural scene statistics (NSS) of X-ray images and found that the NSS modeling paradigm applies quite well to X-ray image data, although the model is somewhat different from that of visible light (VL) images [23,57]. In prior work, we used a nominal set of X-ray NSS features along with standardized objective image quality indicators (IQIs) to analyze the relationship between X-ray image quality and the task performance of professional bomb technicians who were asked to detect and identify a collection of diverse potential threat objects.
To analyze the effects of image quality on task performance, we conducted a human task performance study in which professional bomb technicians were asked to detect and identify improvised explosive device (IED) components in X-ray images that we created, degraded and presented to them in an interactive viewing environment [58]. Certain commercial equipment, instruments, or materials are identified in this paper in order to specify the experimental procedure adequately. Such identification is not intended to imply recommendation or endorsement by the U.S. government, nor is it intended to imply that the materials or equipment identified are necessarily the best available for the purpose. The degradations included spatially correlated noise, reduced spatial resolution and combinations of these. The NIST-LIVE database of ground truth judgments of bomb experts was then used to evaluate the predictive performance of the objective X-ray image quality features. More details regarding the task performance study protocols can be found in [59].
Given that the MVGCN model provides a powerful NSS-based perceptual image quality feature extractor, we examined its performance against other NSS-based models and also against conventional IEEE/ANSI N42.55 [60] metrics. We hypothesized that the presence of degradations would change the characteristic statistical properties of the MSGCN coefficients of X-ray images, which would allow the MVGCN model to better capture degradations and would better correlate with the outcomes of expert detection and identification tasks conducted on degraded X-ray images.
The models used for comparison are the quality inspectors of X-ray images (QUIX) model [57], the IEEE/ANSI N42.55 standard [60] and combinations of these. QUIX features are a set of simple and efficient NSS-based perceptual quality features that accurately predict human task performance. In [57], QUIX considers only horizontal and vertical correlations while extracting features denoted as ‘pp’ features. In order to be consistent and to have a fair comparison against QUIX, we developed a reduced feature version of MVGCN, which we refer to as MVGCN-X-ray, which does not include the products of diagonal coefficients as part of the paired-product modeling and corresponding MVGG fits. A summary of the MVGCN-X-ray features used and the feature extraction procedure is described in Table 7.
Image quality indicators (IQIs) are a set of standard objective image quality metrics defined in IEEE/ANSI N42.55 [60]. These IQIs are determined by analysis of images of a standard test object under test conditions. In our analysis, we used eight IQIs, including “steel penetration”, “spatial resolution”, “organic material detection”, “dynamic range”, “noise” and three other descriptive features that are extracted from the spectral distribution of the measured modulation transfer function (MTF), noise equivalent quanta (NEQ) and noise power spectrum (NPS).
Given that CORNIA is among the top performing IQA algorithms, albeit much more computationally expensive, as observed in the previous application, we compared its time complexity against MVGCN on X-ray images. CORNIA required about 50-times more time than MVGCN-X-ray did (as reported in Table 8) to extract features from high spatial-resolution (the size of the studied X-ray images is of the order of pixels) X-ray images.
To evaluate performance, we divided the NIST-LIVE database on the basis of component and clutter combinations. The component categories include IED components: “power source”, “detonator”, “load”, “switch” and “metal pipe”, which are labeled by professional bomb technicians, if found in an image, else labeled as not found. Here, we consider the task of measuring the accuracy of objective image quality models to predict the detection performance of experts. We further divided each category into four clutter types: clutter (laptop), shielding (steel plate), clutter with shielding and no clutter. Clutter/shielding was added to some images to make the detection task more challenging.
We then devised a binary classification framework whereby features were mapped to a binary variable indicating whether the component was successfully identified by an expert. We used a logistic regression model to be consistent with [57]. The data from each component-clutter category were divided into an 80% training set to learn logistic function parameters, which were then used to predict on the remaining 20% test set. We used a similar performance evaluation methodology as followed in [57]: generated random disjoint train-test splits and computed median log loss and area-under-the-ROC-curve (AUC) scores over 1000 iterations (reported in Table 9). A smaller value of log loss and a larger value of AUC indicate superior classification performance, implying better correlation with human judgments.
We also demonstrated in [57] that QUIX features and IQIs supply complementary information, which when combined into a single predictor performed better than either of them in isolation. Under a similar premise, we augmented MVGCN-X-ray features with IQIs to obtain similar benefits in performance. As shown in Table 9, the combination of MVGCN-X-ray with IQIs yielded better performance than any of the other features in isolation, while competing well against the combination of QUIX and IQIs. The improvement in performance of the combination can be attributed to the capture of different levels of distortion-sensitive higher-order correlations by the MVGCN-X-ray features and by complementary X-ray image quality information supplied by IQIs.
6. Conclusions
We designed a multivariate approach to NR IQA, which uses generalized contrast normalization, a form of DNT that is more suitable to model degraded image coefficients. We investigated the effect of degradations on the estimated shape and eigenvalues of the estimated covariance matrix of MVGG fit to the joint distribution of neighboring MSGCN coefficients. Further, we demonstrated applications of the MVGCN model to the blind QA of visible light images and on the prediction of threat object detection and identification by trained experts on degraded X-ray images, achieving near state-of-the-art performance in both applications.
There are a number of possible future directions. It is of interest to utilize the MVGCN model to design a spatio-temporal model of normalized bandpass video coefficients for video QA. The aforementioned multivariate modeling approach is also possibly extensible to other NSS models that utilize univariate parametric distributions of bandpass image coefficients. Furthermore, studying the statistics of other imaging modalities such as millimeter-wave, computed tomography (CT) and multi-view X-ray images also is a potential future direction of exploration.
Author Contributions
Conceptualization, P.G., C.G.B. and A.C.B.; Investigation, P.G., J.L.G. and N.G.P.J.; Methodology, P.G. and C.G.B.; Resources, J.L.G., N.G.P.J. and A.C.B.; Supervision, J.L.G., N.G.P.J. and A.C.B.; Validation, P.G.; Visualization, P.G.; Writing—review & editing, P.G., C.G.B., J.L.G., N.G.P.J. and A.C.B.
Funding
This research was funded by National Institute of Standards and Technology under grant number: 70NANB15H270.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
If is distributed as a zero-mean MVGG (5), then the following properties follow [41]:
where and denote multivariate skewness and kurtosis coefficients, respectively. A number of methods have been studied to estimate the shape (s) and scale () parameters of an MVGG distribution, including the recursive maximum likelihood estimation [61], the method of moments [41] and the Fisher scoring algorithm [46]. We utilize the efficient and reliable moment-matching technique described in [41]. Specifically, given a set of N i.i.d. d-dimensional MVGG vectors, , compute the sample multivariate kurtosis coefficient as in [62]:
where is the sample covariance. Equations (A3) and (A4) are used to estimate s, which is then substituted into Equation (A1) to compute , where is replaced by the sample covariance .
References
- Katsavounidis, I. Dynamic Optimizer—A Perceptual Video Encoding Optimization Framework. Available online: https://medium.com/netflix-techblog/dynamic-optimizer-a-perceptual-video-encoding-optimization-framework-e19f1e3a277f (accessed on 10 September 2018).
- Wang, Z.; Bovik, A.; Evans, B. Blind measurement of blocking artifacts in images. Int. Conf. Image Proc. 2000, 3, 981–984. [Google Scholar]
- Feng, X.; Allebach, J.P. Measurement of Ringing Artifacts in JPEG Images; International Society for Optics and Photonics: Bellingham, WA, USA, 2006; Volume 6076, p. 60760A. [Google Scholar]
- Sazzad, Z.P.; Kawayoke, Y.; Horita, Y. No reference image quality assessment for JPEG2000 based on spatial features. Signal Process. Image Commun. 2008, 23, 257–268. [Google Scholar] [CrossRef]
- Zhu, X.; Milanfar, P. A no-reference sharpness metric sensitive to blur and noise. In Proceedings of the 2009 International Workshop on Quality of Multimedia Experience, San Diego, CA, USA, 29–31 July 2009. [Google Scholar]
- Charrier, C.; Lebrun, G.; Lezoray, O. A machine learning-based color image quality metric. In Proceedings of the Conference on Colour in Graphics, Imaging, and Vision, Leeds, UK, 19–22 June 2006; Volume 2006, pp. 251–256. [Google Scholar]
- Kim, J.; Zeng, H.; Ghadiyaram, D.; Lee, S.; Zhang, L.; Bovik, A.C. Deep convolutional neural models for picture-quality prediction: Challenges and solutions to data-driven image quality assessment. IEEE Signal Process. Mag. 2017, 34, 130–141. [Google Scholar] [CrossRef]
- Kang, L.; Ye, P.; Li, Y.; Doermann, D. Convolutional neural networks for no-reference image quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1733–1740. [Google Scholar]
- Bosse, S.; Maniry, D.; Müller, K.R.; Wiegand, T.; Samek, W. Deep neural networks for no-reference and full-reference image quality assessment. IEEE Trans. Image Process. 2018, 27, 206–219. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, Y.; Moorthy, A.K.; Chandler, D.M.; Bovik, A.C. C-DIIVINE: No-reference image quality assessment based on local magnitude and phase statistics of natural scenes. Signal Process. Image Commun. 2014, 29, 725–747. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Moorthy, A.K.; Bovik, A.C. Blind image quality assessment: From natural scene statistics to perceptual quality. IEEE Trans. Image Process. 2011, 20, 3350–3364. [Google Scholar] [CrossRef] [PubMed]
- Gabarda, S.; Cristobal, G. Blind image quality assessment through anisotropy. J. Opt. Soc. Am. A 2007, 24, B42–B51. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Tran. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. Density modeling of images using a generalized normalization transformation. arXiv, 2015; arXiv:1511.06281. [Google Scholar]
- Schwartz, O.; Simoncelli, E.P. Natural signal statistics and sensory gain control. Nat. Neurosci. 2001, 4, 819. [Google Scholar] [CrossRef] [PubMed]
- Wainwright, M.; Simoncelli, E. Scale mixtures of Gaussians and the statistics of natural images. Adv. Neural Inf. Process. Syst. 2000, 12, 855–861. [Google Scholar]
- Gupta, P.; Moorthy, A.K.; Soundararajan, R.; Bovik, A.C. Generalized Gaussian scale mixtures: A model for wavelet coefficients of natural images. Signal Process. Image Commun. 2018, 66, 87–94. [Google Scholar] [CrossRef]
- Deledalle, C.A.; Parameswaran, S.; Nguyen, T.Q. Image restoration with generalized Gaussian mixture model patch priors. arXiv, 2018; arXiv:1802.01458. [Google Scholar]
- Goodall, T.R.; Bovik, A.C.; Paulter, N.G. Tasking on natural statistics of infrared images. IEEE Trans. Image Process. 2016, 25, 65–79. [Google Scholar] [CrossRef] [PubMed]
- Moreno-Villamarín, D.E.; Benítez-Restrepo, H.D.; Bovik, A.C. Predicting the quality of fused long wave infrared and visible light images. IEEE Trans. Image Process. 2017, 26, 3479–3491. [Google Scholar] [CrossRef] [PubMed]
- Gupta, P.; Glover, J.; Paulter, N.G., Jr.; Bovik, A.C. Studying the Statistics of Natural X-ray Pictures. J. Test. Eval. 2018, 46. [Google Scholar] [CrossRef]
- Ruderman, D.L.; Bialek, W. Statistics of natural images: Scaling in the woods. Phys. Rev. Lett. 1994, 73, 814. [Google Scholar] [CrossRef] [PubMed]
- Ruderman, D.L. The statistics of natural images. Netw. Comput. Neural Syst. 1994, 5, 517–548. [Google Scholar] [CrossRef] [Green Version]
- Bovik, A.C. Automatic prediction of perceptual image and video quality. Proc. IEEE 2013, 101, 2008–2024. [Google Scholar]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.Q.; Yang, J. Hyperspectral image denoising via sparse representation and low-rank constraint. IEEE Trans. Geosci. Remote Sens. 2015, 53, 296–308. [Google Scholar] [CrossRef]
- Gupta, P.; Bampis, C.G.; Bovik, A.C. Natural Scene Statistics for Noise Estimation. In Proceedings of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018. [Google Scholar]
- Mairal, J.; Elad, M.; Sapiro, G. Sparse representation for color image restoration. IEEE Trans. Image Process. 2008, 17, 53–69. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Huang, T.Z.; Selesnick, I.W.; Lv, X.G.; Chen, P.Y. Image restoration using total variation with overlapping group sparsity. Inf. Sci. 2015, 295, 232–246. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Lai, J. Sparse and dense hybrid representation via dictionary decomposition for face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1067–1079. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, S.; Roth, D. Learning a sparse representation for object detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 97–101. [Google Scholar]
- Yokoya, N.; Iwasaki, A. Object detection based on sparse representation and Hough voting for optical remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2053–2062. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Discriminative learned dictionaries for local image analysis. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Minaee, S.; Abdolrashidi, A.; Wang, Y. Screen content image segmentation using sparse-smooth decomposition. In Proceedings of the 2015 49th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015; pp. 1202–1206. [Google Scholar]
- Sharifi, K.; Leon-Garcia, A. Estimation of shape parameter for generalized Gaussian distributions in subband decompositions of video. IEEE Trans. Circuits Syst. Video Technol. 1995, 5, 52–56. [Google Scholar] [CrossRef]
- Wainwright, M.J.; Schwartz, O.; Simoncelli, E.P. Natural image statistics and divisive normalization: Modeling nonlinearities and adaptation in cortical neurons. In Statistical Theories of the Brain; MIT Press: Cambridge, Massachusetts, MA, USA, 2002; pp. 203–222. [Google Scholar]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A Statistical Evaluation of Recent Full Reference Image Quality Assessment Algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef] [PubMed]
- Gómez, E.; Gomez-Viilegas, M.; Marin, J. A multivariate generalization of the power exponential family of distributions. Commun. Stat. Theory Methods 1998, 27, 589–600. [Google Scholar] [CrossRef]
- Kwitt, R.; Meerwald, P.; Uhl, A. Color-image watermarking using multivariate power-exponential distribution. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 4245–4248. [Google Scholar]
- Coban, M.; Mersereau, R. Adaptive subband video coding using bivariate generalized Gaussian distribution model. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing, Atlanta, GA, USA, 9 May 1996; IEEE: Piscataway, NJ, USA, 2002; Volume 4, pp. 1990–1993. [Google Scholar]
- Verdoolaege, G.; De Backer, S.; Scheunders, P. Multiscale colour texture retrieval using the geodesic distance between multivariate generalized Gaussian models. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 169–172. [Google Scholar]
- Omari, M.; Abdelouahad, A.A.; El Hassouni, M.; Cherifi, H. Color image quality assessment measure using multivariate generalized Gaussian distribution. In Proceedings of the 2013 International Conference on Signal-Image Technology & Internet-Based Systems, Kyoto, Japan, 2–5 December 2013; pp. 195–200. [Google Scholar]
- Verdoolaege, G.; Scheunders, P. Geodesics on the manifold of multivariate generalized Gaussian distributions with an application to multicomponent texture discrimination. Int. J. Comput. Vis. 2011, 95, 265. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Wu, Q.; Wang, Z.; Yong, H.; Li, H.; Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Trans. Image Process. 2017, 26, 1004–1016. [Google Scholar] [CrossRef] [PubMed]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Lasmar, N.E.; Stitou, Y.; Berthoumieu, Y. Multiscale skewed heavy tailed model for texture analysis. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009. [Google Scholar]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Ye, P.; Kumar, J.; Kang, L.; Doermann, D. Unsupervised feature learning framework for no-reference image quality assessment. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1098–1105. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multi-scale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003. [Google Scholar]
- Ponomarenko, N.; Lukin, V.; Zelensky, A.; Egiazarian, K.; Carli, M.; Battisti, F. TID2008-a database for evaluation of full-reference visual quality assessment metrics. Adv. Mod. Radioelectr. 2009, 10, 30–45. [Google Scholar]
- Larson, E.C.; Chandler, D.M. Most apparent distortion: full-reference image quality assessment and the role of strategy. J. Electron. Imaging 2010, 19, 011006. [Google Scholar]
- Ghadiyaram, D.; Bovik, A.C. Massive online crowdsourced study of subjective and objective picture quality. IEEE Trans. Image Process. 2016, 25, 372–387. [Google Scholar] [CrossRef] [PubMed]
- Corey, D.M.; Dunlap, W.P.; Burke, M.J. Averaging correlations: Expected values and bias in combined Pearson rs and Fisher’s z transformations. J. Gen. Psychol. 1998, 125, 245–261. [Google Scholar] [CrossRef]
- Gupta, P.; Sinno, Z.; Glover, J.; Paulter, N.G., Jr.; Bovik, A.C. Predicting detection performance on security X-ray images as a function of image quality. IEEE Trans. Image Process. submitted.
- X-Ray Toolkit. Available online: http://www.xraytoolkit.com/ (accessed on 1 June 2018).
- Glover, J.L.; Gupta, P.; Bovik, A.C.; Paulter, N.G. Measuring and modeling the detectability of IED components in X-ray images as a function of image quality. In preparation.
- N42.55-2013 - American National Standard for the Performance of Portable Transmission X-Ray Systems for Use in Improvised Explosive Device and Hazardous Device Identification. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/6766644/metrics#metrics (accessed on 11 October 2018).
- Pascal, F.; Bombrun, L.; Tourneret, J.Y.; Berthoumieu, Y. Parameter Estimation For Multivariate Generalized Gaussian Distributions. IEEE Trans. Signal Process. 2013, 61, 5960–5971. [Google Scholar] [CrossRef] [Green Version]
- Mardia, K.V. Applications of some measures of multivariate skewness and kurtosis in testing normality and robustness studies. Indian J. Stat. 1974, 36, 115–128. [Google Scholar]
Figure 1.
(a) JP2K compressed image and (b) its histogram of divisively normalized bandpass coefficients. The difference between the best generalized Gaussian distribution (GGD) and Gaussian fits indicates that the generalized Gaussian-based contrast estimator is more appropriate for distorted coefficients. The computed Kullback–Leibler divergence values of the Gaussian and GGD fits were found to be KLD and KLD, respectively.
Figure 1.
(a) JP2K compressed image and (b) its histogram of divisively normalized bandpass coefficients. The difference between the best generalized Gaussian distribution (GGD) and Gaussian fits indicates that the generalized Gaussian-based contrast estimator is more appropriate for distorted coefficients. The computed Kullback–Leibler divergence values of the Gaussian and GGD fits were found to be KLD and KLD, respectively.

Figure 2.
(a) Reference images from the LIVE database [40], (b) Scatter plot of adjacent pristine MSGCN coefficients, (c) JP2K compressed images and (d) Scatter plot of adjacent distorted MSGCN coefficients. The figure illustrates the dependency of horizontally adjacent mean subtracted generalized contrast normalized (MSGCN) coefficients of exemplar pristine images. The degree of these dependencies increases with the distortion severity. The PLCC (Pearson’s linear correlation coefficient) is used as a dependency measure.
Figure 2.
(a) Reference images from the LIVE database [40], (b) Scatter plot of adjacent pristine MSGCN coefficients, (c) JP2K compressed images and (d) Scatter plot of adjacent distorted MSGCN coefficients. The figure illustrates the dependency of horizontally adjacent mean subtracted generalized contrast normalized (MSGCN) coefficients of exemplar pristine images. The degree of these dependencies increases with the distortion severity. The PLCC (Pearson’s linear correlation coefficient) is used as a dependency measure.

Figure 3.
Set of adjacent MSGCN coefficients used to form the joint distribution model. The additional symmetrically placed samples relative to the coordinate are not included to reduce the model size and since it is likely that distortions along the same orientation will be redundant.
Figure 3.
Set of adjacent MSGCN coefficients used to form the joint distribution model. The additional symmetrically placed samples relative to the coordinate are not included to reduce the model size and since it is likely that distortions along the same orientation will be redundant.

Figure 4.
Empirical distribution (b) of the estimated shape parameter s obtained by fitting the joint MSGCN coefficients of pristine images from the Waterloo exploration and the Berkeley Segmentation Database (BSD) database with an multivariate generalized Gaussian (MVGG). Images yielding values of s at extremities of the distribution ( and ) are shown in (a) and (c), respectively.
Figure 4.
Empirical distribution (b) of the estimated shape parameter s obtained by fitting the joint MSGCN coefficients of pristine images from the Waterloo exploration and the Berkeley Segmentation Database (BSD) database with an multivariate generalized Gaussian (MVGG). Images yielding values of s at extremities of the distribution ( and ) are shown in (a) and (c), respectively.

Figure 5.
Boxplots of the estimated shape parameter s for three different distortions: (a) Gaussian blur, (b) AWGN and (c) JPEG compression (MATLAB’s imwrite function is used to control the degree of JPEG compression by specifying ‘quality’ as the argument in the imwrite function). Outliers were removed from the plots for better visualization.
Figure 5.
Boxplots of the estimated shape parameter s for three different distortions: (a) Gaussian blur, (b) AWGN and (c) JPEG compression (MATLAB’s imwrite function is used to control the degree of JPEG compression by specifying ‘quality’ as the argument in the imwrite function). Outliers were removed from the plots for better visualization.

Figure 6.
Boxplots of the KL divergence between the 2D empirical distributions of MSGCN coefficients and their multivariate Gaussian fits for three different distortions: (a) Gaussian blur, (b) AWGN and (c) JPEG compression. Outliers were removed from the plots for better visualization.
Figure 6.
Boxplots of the KL divergence between the 2D empirical distributions of MSGCN coefficients and their multivariate Gaussian fits for three different distortions: (a) Gaussian blur, (b) AWGN and (c) JPEG compression. Outliers were removed from the plots for better visualization.

Figure 7.
Boxplots of the ratio of the minimum and maximum eigenvalues of the estimated covariance matrix of (a) two-dimensional MVGG fit and (b) five-dimensional MVGG fit over all reference and distorted images from the LIVE database; “WN” is white noise; “GBLUR” is Gaussian blur; and “FF” is fast fading Rayleigh channel.
Figure 7.
Boxplots of the ratio of the minimum and maximum eigenvalues of the estimated covariance matrix of (a) two-dimensional MVGG fit and (b) five-dimensional MVGG fit over all reference and distorted images from the LIVE database; “WN” is white noise; “GBLUR” is Gaussian blur; and “FF” is fast fading Rayleigh channel.


{kind=link}
{kind=link}
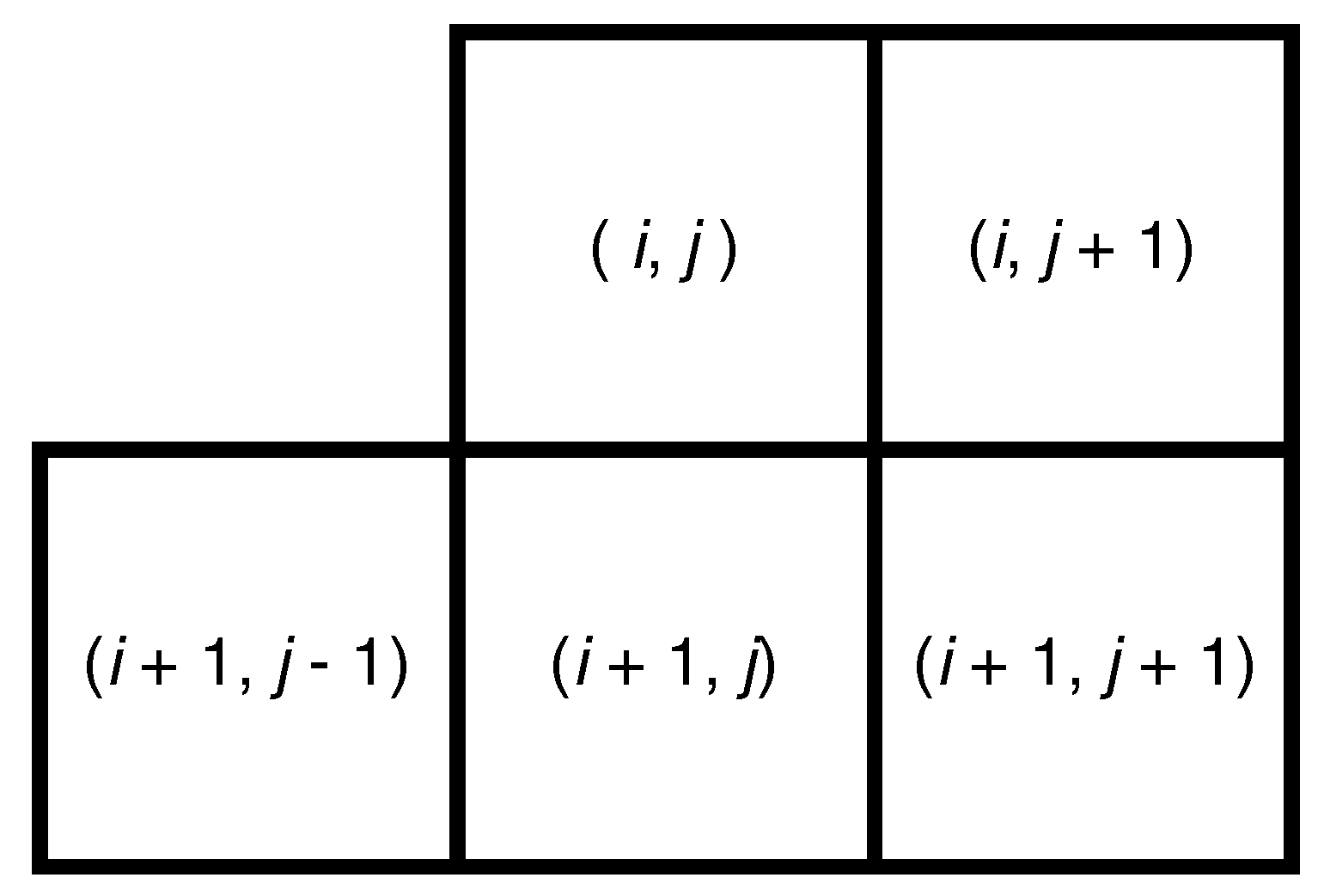{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Feature summary of joint MSGCN(m), paired-products () and joint paired-products (j) coefficients. All features are extracted at two scales.
Table 1.
Feature summary of joint MSGCN(m), paired-products () and joint paired-products (j) coefficients. All features are extracted at two scales.
| Feature ID | Feature Description | Computation Procedure |
|---|---|---|
| shape | 5D MVGG fit to MSGCN coefficients | |
| – | eigenvalues of scale matrix | 5D MVGG fit to MSGCN coefficients |
| – | shape, mean, left variance and right variance | AGGD fit to H pairwise coefficients |
| – | shape, mean, left variance and right variance | AGGD fit to V pairwise coefficients |
| – | shape, mean, left variance and right variance | AGGD fit to D1 pairwise coefficients |
| – | shape, mean, left variance and right variance | AGGD fit to D2 pairwise coefficients |
| – | eigenvalues of scale matrix | 4D MVGG fit to H, V, D1 and D2 ppcoefficients |
Table 2.
Median Spearman’s rank ordered correlation coefficient (SROCC) and Pearson’s linear correlation coefficient (PLCC) across 100 train-test trials on the LIVE, CSIQ, TID08and LIVE Challenge databases. The best two no reference image quality assessment (NR IQA) models are boldfaced and FR IQA models are italicized.
Table 2.
Median Spearman’s rank ordered correlation coefficient (SROCC) and Pearson’s linear correlation coefficient (PLCC) across 100 train-test trials on the LIVE, CSIQ, TID08and LIVE Challenge databases. The best two no reference image quality assessment (NR IQA) models are boldfaced and FR IQA models are italicized.
| DB | LIVE | TID08 | CSIQ | Challenge | Overall | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | SROCC | PLCC | |
| PSNR | 0.892 | 0.883 | 0.561 | 0.571 | 0.803 | 0.800 | - | - | 0.756 | 0.758 |
| MS-SSIM | 0.953 | 0.942 | 0.860 | 0.845 | 0.913 | 0.896 | - | - | 0.894 | 0.888 |
| SSEQ | 0.889 | 0.889 | 0.635 | 0.680 | 0.691 | 0.749 | 0.476 | 0.515 | 0.695 | 0.732 |
| CORNIA | 0.944 | 0.946 | 0.683 | 0.742 | 0.696 | 0.768 | 0.621 | 0.658 | 0.762 | 0.800 |
| BLIINDS | 0.927 | 0.930 | 0.662 | 0.697 | 0.739 | 0.784 | 0.503 | 0.538 | 0.738 | 0.764 |
| NIQE | 0.912 | 0.907 | 0.258 | 0.346 | 0.632 | 0.721 | 0.458 | 0.502 | 0.642 | 0.682 |
| CNN-IQA | 0.946 | 0.948 | 0.722 | 0.750 | 0.854 | 0.878 | 0.575 | 0.556 | 0.820 | 0.832 |
| BRISQUE | 0.940 | 0.943 | 0.600 | 0.654 | 0.738 | 0.758 | 0.602 | 0.636 | 0.741 | 0.768 |
| DIIVINE | 0.897 | 0.897 | 0.594 | 0.636 | 0.737 | 0.751 | 0.600 | 0.623 | 0.713 | 0.732 |
| MVGCN | 0.946 | 0.947 | 0.688 | 0.735 | 0.735 | 0.775 | 0.622 | 0.646 | 0.771 | 0.796 |
Table 3.
SROCC for database independent experiments on MVGCN across multiple IQA databases. Rows: training dataset; columns: testing dataset. The overall performance is calculated for each training database.
Table 3.
SROCC for database independent experiments on MVGCN across multiple IQA databases. Rows: training dataset; columns: testing dataset. The overall performance is calculated for each training database.
| Train/Test | LIVE | TID08 | CSIQ | TID13 | Overall |
|---|---|---|---|---|---|
| LIVE | - | 0.927 | 0.905 | 0.922 | 0.919 |
| TID08 | 0.841 | - | 0.678 | 0.876 | 0.813 |
| CSIQ | 0.787 | 0.801 | - | 0.765 | 0.785 |
| TID13 | 0.839 | 0.955 | 0.662 | - | 0.862 |
Table 4.
Aggregate results of database independent tests for various IQA models. The best two NR IQA models are boldfaced.
Table 4.
Aggregate results of database independent tests for various IQA models. The best two NR IQA models are boldfaced.
| Model | Overall SROCC | Overall PLCC |
|---|---|---|
| SSEQ | 0.810 | 0.833 |
| CORNIA | 0.865 | 0.881 |
| BLIINDS | 0.824 | 0.840 |
| DIIVINE | 0.840 | 0.844 |
| BRISQUE | 0.809 | 0.813 |
| MVGCN | 0.854 | 0.863 |
Table 5.
Results of the statistical significance test performed between SROCC values of different NR IQA algorithms across four databases. The elements in each cell correspond to the following databases (from left to right): LIVE, CSIQ, TID08 and LIVE Challenge. ‘1’ means that the row algorithm is statistically superior to the column algorithm with a confidence of 95%; ‘0’ signifies statistically worse; and ‘-’ means statistical equivalence.
Table 5.
Results of the statistical significance test performed between SROCC values of different NR IQA algorithms across four databases. The elements in each cell correspond to the following databases (from left to right): LIVE, CSIQ, TID08 and LIVE Challenge. ‘1’ means that the row algorithm is statistically superior to the column algorithm with a confidence of 95%; ‘0’ signifies statistically worse; and ‘-’ means statistical equivalence.
| SSEQ | BRISQUE | CORNIA | NIQE | DIIVINE | BLIINDS | MVGCN | |
|---|---|---|---|---|---|---|---|
| SSEQ | ---- | 0010 | 0-00 | 0111 | --10 | 0000 | 0000 |
| BRISQUE | 1101 | ---- | 0100 | 1111 | 1--- | 1-01 | --00 |
| CORNIA | 1-11 | 1011 | ---- | 1111 | 1-11 | 10-1 | ---- |
| NIQE | 1000 | 0000 | 0000 | ---- | 1000 | 0000 | 0000 |
| DIIVINE | --01 | 0--- | 0-00 | 0111 | ---- | 0-01 | 0-00 |
| BLIINDS | 1111 | 0-10 | 01-0 | 1111 | 1-10 | ---- | 0-00 |
| MVGCN | 1111 | --11 | ---- | 1111 | 1-11 | 1-11 | ---- |
Table 6.
Comparison of median time taken per image to extract features by different NR IQA algorithms on a 4-GHz quad-core processor with 32 GBs of RAM. The median is computed over all distorted images from the LIVE database.
Table 6.
Comparison of median time taken per image to extract features by different NR IQA algorithms on a 4-GHz quad-core processor with 32 GBs of RAM. The median is computed over all distorted images from the LIVE database.
| Algorithm | Time (in sec) |
|---|---|
| SSEQ | 0.77 |
| CORNIA | 2.10 |
| BLIINDS | 27.66 |
| DIIVINE | 9.28 |
| BRISQUE | 0.03 |
| MVGCN | 0.08 |
Table 7.
Feature summary for joint MSGCN (m), paired-products () and joint paired-products (j) coefficients for the X-ray application. All features are extracted at two scales.
Table 7.
Feature summary for joint MSGCN (m), paired-products () and joint paired-products (j) coefficients for the X-ray application. All features are extracted at two scales.
| Feature ID | Feature Description | Computation Procedure |
|---|---|---|
| shape | 3D MVGG fit to MSGCN coefficients | |
| – | eigenvalues of scale matrix | 3D MVGG fit to MSGCN coefficients |
| – | shape, mean and right variance | AGGD fit to H pairwise coefficients |
| – | shape, mean and right variance | AGGD fit to V pairwise coefficients |
| – | eigenvalues of scale matrix | 2D MVGG fit to H and V pp coefficients |
Table 8.
The time complexity comparison between CORNIA and MVGCN-X-ray to extract features from an X-ray image of size on a 4-GHz quad-core processor with 32 GBs of RAM.
Table 8.
The time complexity comparison between CORNIA and MVGCN-X-ray to extract features from an X-ray image of size on a 4-GHz quad-core processor with 32 GBs of RAM.
| Algorithm | Time (in s) |
|---|---|
| CORNIA | 542.42 |
| MVGCN-X-ray | 9.61 |
Table 9.
Median log loss and AUC scores across 1000 train-test trials on different component-clutter combinations. The best two feature groups for each component-clutter category are boldfaced. IQI, image quality indicator; QUIX, quality inspectors of X-ray images.
Table 9.
Median log loss and AUC scores across 1000 train-test trials on different component-clutter combinations. The best two feature groups for each component-clutter category are boldfaced. IQI, image quality indicator; QUIX, quality inspectors of X-ray images.
| IQIs | QUIX | MVGCN-X-ray | QUIX + IQIs | MVGCN + IQIs | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Component | Clutter Type | log-loss | AUC | log-loss | AUC | log-loss | AUC | log-loss | AUC | log-loss | AUC |
| Power source | Clutter | 0.485 | 0.867 | 0.489 | 0.831 | 0.500 | 0.820 | 0.451 | 0.877 | 0.503 | 0.863 |
| Power source | Shield | 0.528 | 0.863 | 0.502 | 0.900 | 0.500 | 0.900 | 0.526 | 0.880 | 0.506 | 0.888 |
| Power source | Shield with Clutter | 0.312 | 0.591 | 0.205 | 0.833 | 0.178 | 0.864 | 0.205 | 0.900 | 0.176 | 0.864 |
| Power source | No Clutter | 0.496 | 0.886 | 0.579 | 0.863 | 0.544 | 0.844 | 0.480 | 0.895 | 0.470 | 0.889 |
| Detonator | Clutter | 0.200 | 0.933 | 0.229 | 0.944 | 0.191 | 0.962 | 0.213 | 0.938 | 0.199 | 0.921 |
| Detonator | Shield with Clutter | 0.624 | 0.875 | 0.526 | 0.875 | 0.337 | 0.875 | 0.512 | 0.875 | 0.340 | 0.875 |
| Detonator | No Clutter | 0.455 | 0.944 | 0.395 | 0.944 | 0.407 | 0.944 | 0.346 | 0.944 | 0.344 | 0.944 |
| Load | Clutter | 0.163 | 0.944 | 0.137 | 0.944 | 0.131 | 0.944 | 0.134 | 0.944 | 0.133 | 0.944 |
| Load | No Clutter | 0.505 | 0.852 | 0.622 | 0.883 | 0.561 | 0.861 | 0.592 | 0.861 | 0.559 | 0.889 |
| Switch | Clutter | 0.318 | 0.932 | 0.275 | 0.936 | 0.228 | 0.941 | 0.249 | 0.927 | 0.213 | 0.932 |
| Switch | Shield | 0.369 | 0.932 | 0.311 | 0.936 | 0.350 | 0.941 | 0.326 | 0.927 | 0.351 | 0.932 |
| Switch | No Clutter | 0.414 | 0.928 | 0.506 | 0.872 | 0.476 | 0.872 | 0.407 | 0.907 | 0.406 | 0.920 |
| Metal pipe | Clutter | 0.291 | 1.000 | 0.397 | 0.125 | 0.346 | 0.500 | 0.304 | 1.000 | 0.264 | 0.875 |
| Metal pipe | Shield | 0.394 | 1.000 | 0.511 | 1.000 | 0.477 | 0.462 | 0.478 | 1.000 | 0.453 | 1.000 |
| Metal pipe | Shield with Clutter | 0.432 | 0.905 | 0.472 | 0.905 | 0.443 | 0.917 | 0.363 | 0.952 | 0.375 | 0.952 |
| Weighted Average | 0.402 | 0.881 | 0.414 | 0.874 | 0.382 | 0.870 | 0.373 | 0.912 | 0.357 | 0.906 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gupta, P.; Bampis, C.G.; Glover, J.L.; Paulter, N.G.; Bovik, A.C. Multivariate Statistical Approach to Image Quality Tasks. J. Imaging 2018, 4, 117. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging4100117
AMA Style
Gupta P, Bampis CG, Glover JL, Paulter NG, Bovik AC. Multivariate Statistical Approach to Image Quality Tasks. Journal of Imaging. 2018; 4(10):117. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging4100117
Chicago/Turabian StyleGupta, Praful, Christos G. Bampis, Jack L. Glover, Nicholas G. Paulter, and Alan C. Bovik. 2018. "Multivariate Statistical Approach to Image Quality Tasks" Journal of Imaging 4, no. 10: 117. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging4100117
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.