1. Introduction
The domain of
Remote Sensing (RS) focuses on monitoring the physical characteristics of a target area by measuring the reflected and emitted radiation from a distance, in contrast to in situ observations which require on-site measuring devices. To achieve this objective, airborne and spaceborne
Multispectral (MS) and
Hyperspectral (HS) sensors, capable of observing an extended region of the electromagnetic spectrum, are used in order to detect and classify objects on Earth, exploiting the unique spectral profiles of different materials [
1]. While the acquisition of a large number of observations is critical for Earth observation, as it provides valuable spatial and spectral information, the copious amounts of data collected from high-resolution sensors over extended time periods that can be formulated by means of high-dimensional data structures, known as tensors, introduce considerable challenges in terms of data storage and data transfer [
2]. Especially in RS cases, MS images that are modeled as a third-order tensor defined by two spatial and one spectral variable, are collected on satellites or unmanned aerial vehicles and need to be transferred to the ground-based stations. For that purpose, compression of the acquired MS images is mandatory, in order to reduce bandwidth and increase the system lifetime [
3].
To that end, a number of lossless and lossy compression approaches have been proposed, including transform coding methods, such as the
Discrete Cosine Transform and the
Discrete Wavelet Transform ( DWT) [
4]. While lossless compression schemes are designed so that no information is lost during compression, they typically offer moderate compression rates, in the range of 1.5:1 to 3:1. On the other hand, lossy compression techniques can achieve much higher compression rates, in excess of
, primarily by mapping a range of values to values from discrete sets-a process known as quantization-which can be applied to the original pixels or their representation in some transform domain.
Once the massive amounts of observations acquired by modern instruments, including satellites such as ESA’s Sentinel 2 and NASA’s Landsat, are transferred to ground-station, methodologies that will allow the automation of classification tasks are necessary. To that end, several
Machine Learning (ML) algorithms have been employed by the RS community, including
Support Vector Machines (SVMs) [
5] and
Random Forests (RFs) [
6]. In the past five years,
Deep Learning (DL) and in particular architectures such as
Convolutional Neural Networks (CNN) have attracted considerable attention due to their significant success in various RS analysis tasks, including multi-label classification [
7], land cover classification [
8], object detection [
9] and image retrieval [
10], among others. Specifically, CNNs pass filters, widely known as kernels, over the raw image data aiming to exploit the underlying correlations among existing pixels to design as representative and compact features as possible. Most interestingly, CNNs are not fixed but instead learned through the training process of the network [
11].
Since satellite imagery data depend directly on spacecraft operations, the Launch and Early Orbit Phase (LEOP) of space missions is always treated with great concern and caution. During LEOP, operations staff have to activate, monitor and control the various subsystems of the satellite, including the deployment of any satellite appendages (e.g., antennas, solar array, reflector, etc.), and undertake critical orbit and attitude control maneuvers. Engineering calibration (e.g., platform, instrument, and processor calibration) and geophysical validation (e.g., collection, quality control and archiving of correlative data) are crucial activities associated with this stage. Unfortunately, even though the launch phase is designed to provide high-quality reference data for the training of the ML algorithms, during test phase the online monitoring data are in most cases noise-infected (e.g., compressed) versions of the reference ones. This has an adverse effect on the ML task as the models are tested with data with significantly different statistical distributions than those during training. Motivated by this real-world problem, we conducted the present study with the intention of designing and providing a system capable of mitigating the effects of the quantization and subsampling operations.
In this paper, the effect of compression on the classification task of MS images is tackled via the notion of CNNs using a tensor recovery algorithm. More specifically, a recently released MS dataset is used to train and evaluate the performance of the employed CNN with respect to the crucial parameter of the samples it was trained with. Furthermore, a recovery algorithm of the real-valued measurements on high-dimensional data from its quantized and possibly subsampled values-due to noise or communication failures-is proposed in order to further process more efficiently the observed measurements. In particular, we consider a constrained maximum likelihood estimation of a low-rank tensor, in combination with a quantization and statistical measurement model, taking into account the quantization bin boundaries and the existence of possible noise. Subsequently, we quantify the effects of the aforementioned quantization, subsampling, and recovery processes, solely and in conjunction, in the evaluation process of the network in order to investigate its response under hostile real-world regimes. Experimental results on real satellite MS images demonstrate that when trained with a decent number of samples, CNNs can perform quite well in the MS image classification task. Moreover, direct processing with the quantized or subsampled measurements, rather than recovering their real values, ends up with a significantly higher error, indicating the efficacy of the proposed method.
All in all, the key contributions of this paper can be summarized as follows:
Usage of CNNs (pre-trained and from-scratch models) to tackle the (quantized vs. original) MS image classification task of a recently released dataset.
Investigation of the dataset size with which a CNN should be trained to efficiently classify real satellite MS images.
Exploration of the effect of the quantization and subsampling processes on the MS image classification task.
Provision of a recovery algorithm of the real-valued measurements on high-dimensional data from their quantized and possibly corrupted observations.
Quantification of the classification scheme’s performance on real quantized & subsampled recovered satellite MS images, highlighting the clear merits when it operates on the recovered images vis-à-vis their quantized counterparts.
2. Related Work
In this section, we review the state-of-the-art in terms of quantifying and optimizing the impact of MS/HS compression as well as sampling on subsequent analysis tasks such as classification.
A geometric approach for image classification presented in [
12] can be used to group image patches from different source images into smooth, stochastic and dominant orientation patches, based on the similarity of image geometric structure, such as edge and sharp line information. In addition, different ML methods have also been employed for the analysis of HS observations, such as SVMs and RFs, which have been considered for problems like object detection [
13] and scene classification [
14,
15]. In the past 3–4 years, however, this field has been dominated by deep learning methods including CNNs [
16]. Towards this direction, a recently released, eloquent survey-study concerning cutting-edge DL approaches in RS applications, can be found in [
17].
An interesting work employing patch-based training of CNNs was conducted in [
18], whereas a multi-scale CNN approach was proposed in [
19] for HS image classification purposes. A pioneering work on the field was that in [
20], with specific improvements concerning the model architecture being proposed in [
21]. An early attempt of classifying 3D MS imagery was explored by [
22], where features from each spectral band where interdependently extracted and fused together at a higher level. Extending the notion of convolution from 2 to 3 dimensions, in [
23] is proposed a 3D-CNN for RS image classification, whereas, to address the challenges associated with the limited availability of training examples, works based on the notion of
Transfer Learning were presented in [
24,
25]. Additionally, two quite informative reports on land-use and land-cover classification can be found in [
16,
26].
The above-mentioned cases involve the use of state-of-the-art ML classifiers applied on high-quality noise-free observations. However, due to several reasons, in real-world applications observations are affected by different types of noise, including noise due to the quantization of real-valued measurements, as well as missing observations. The probabilistic model that describes this type of observations was first introduced in [
27], for the case of binary or 1-bit measurements. Under the assumption that the measurement matrix is low-rank, in [
27] is proposed a convex program using maximum likelihood estimation and a nuclear norm to promote a low-rank solution. A similar approach is considered in [
28], but with the max-norm in place of the nuclear norm. Finally, a constrained maximum likelihood estimation based on low-rank factorization is presented in [
29].
An extension to multi-level observations is introduced in [
30,
31], using the same observation model and a constrained maximum likelihood estimator, either calculating the set of quantization bin boundaries from the observed data using an alternating optimization procedure or assuming that the quantization bin boundaries are known. In contrast to the previous observation model, which involves just one matrix, the observation model proposed in [
32] involves a vector of
underlying matrices for
K level observations. Moreover, a maximum likelihood estimation from multi-level quantized observations based on matrix factorization is presented in [
33].
Concerning the case of missing observations, the application of matrix and tensor completion of HS data is considered in [
34] where the authors consider HS observation from mass spectral imaging and remote sensing and conclude that for cases of limited spectral resolution, exploiting the tensor structure of the data is advantageous while for large spectral resolution, matrix completion is preferable. The application of tensor completion for the recovery of missing values in imaging data is also considered in [
35], where the authors proposed three optimization schemes for the recovery of missing values.
An interesting comparison of matrix and tensor-based methods for the recovery of missing environmental data takes place in [
36], where the authors propose the exploitation of higher-order structural information, in favor of matrix-oriented techniques, when randomly distributed measurements are missing. In addition, in [
37] the authors further examine the impact of completing higher-order structural information by matrix and tensor completion methods, both in the task of missing HS measurements’ reconstruction, as well as in that of subsequent classification.
Although numerous algorithms have been presented for the recovery of the real-valued entries of a matrix from its quantized measurements, no prior work has been conducted for the recovery of a tensor from multi-level quantized observations. However, in the case of binary measurements, a maximum likelihood estimator using a nuclear norm constraint on the different matricizations of the underlying tensor is proposed in [
38]. A tensor recovery method from binary measurements is also presented in [
39], which minimizes a loss function that incorporates a generalized linear model with the tensor nuclear norm as a regularization term, using an alternating direction method of multipliers-based algorithm to find the solution. Finally, a tensor-based method that uses the decomposition of the tensor in order to retain its structure, rather than matricization, is proposed in [
40], in which a certain atomic M-norm as a convex proxy for rank is used to approximate low-rank tensors from binary measurements.
The concepts of matrix and tensor completion have also been considered for the efficient on-board compression of HS imagery. Matrix completion is employed for HS compression, targeting the on-board processing of observations in [
41], where the authors propose a new method for the enhancement of the spatio-spectral resolution of hypercubes acquired by snapshot spectral imagers. In [
42] the authors explore the potential of matrix and tensor completion as a compression mechanism with dramatically fewer computational requirements compared to more traditional transform coding schemes like JPEG2000. To fully exploit the spatio-spectral correlations of HS imagery, they consider the group non-overlap sampling scheme and adaptive rank threshold selection, and demonstrate that the proposed scheme offers comparable performance to 3D-JPEG2000 on AVIRIS imagery using less computational resources.
Trying to capitalize on the inherent high dimensionality of HS data, tensor decompositions have also been proven to be a valuable HS image compression tool. In this flavor, the ability to express a 3D tensor encoding both spatial and spectral measurements in more compact forms through tensor decompositions is explored in [
43]. Tensor decomposition of HS image is also explored in [
44], where the authors consider the CANDECOMP/PARAFAC approach in order to express the 3D HS cube as the sum of rank-1 tensors and exploit the sparsity of this representation for compression.
Finally, the impact of compression in the classification task of remote sensing images considered in the proposed scheme has also been examined with different compression and classification techniques. Specifically, the effects of JPEG2000 lossy image compression on the classification of WorldView-2 satellite images are explored in [
45]. The authors consider the
k-Nearest Neighbors (k-NN) and SVM classification methods, and experimentally demonstrate that even at high compression rates (30:1) there is a minimal impact on classification accuracy and in some cases, the results are even better than the original image classification. The same observation is established in [
46] where the impact of lossy compression is investigated on
Principal Component Analysis (PCA)-based spectral unmixing and SVM-based supervised classification using the CCSDS-ICS, TER and JPEG2000 compression schemes on AVIRIS data. However, these results indicate a strange behavior that cannot be completely trusted since very high compression ratios should have an adverse effect on classification accuracy.
Furthermore, the quantification of the impact of compression on the classification accuracy of satellite images is explored in [
47], where a framework based on the
Multiple Kernel Learning algorithm is employed for the prediction of how compression affects the quality of extracted features for classification. Specifically, the authors consider the JPEG2000 compression standard and the subsequent classification of each image into five classes (water, forest, bare land, vegetation and residential area) by two classifiers, namely a maximum likelihood and a pixel-level SVM classifier. However, the prediction performance of their method is evaluated on images with only three bands (near-infrared, red and green bands), from GF2, Landsat 8 and ZY-3.
In a similar vein, the impact of compression on synthetic PROBA-V images was investigated in [
48], where the authors considered two compression schemes—the TER and the CCSDS blue book standard which evolved to the CCSDS-122 standard for lossless and near-lossless MS and HS image compression—and investigated the impact on land-cover estimation. The authors’ conclusion is that compression has a minimal impact on classification, which is more pronounced in regions with multiple boundaries between different land-cover classes. Similar observations were drawn for the case of Landsat 7 Enhanced Thematic Mapper Plus (ETM+) observation compression using JPEG2000, SPIHT and CCSDS 122.0-B-1 and its impact on two important vegetation features, namely
Normalized Difference Vegetation Index and
Normalized Difference Water Index, which are reported in [
49]. Nevertheless, the above methods cannot handle cases of missing observations, due to communication failures or physical obstacles like clouds, in contrast to our method that can efficiently recover the missing values for the subsequent processing using a quantized tensor completion algorithm.
4. Experimental Evaluation
In this section, the dataset on which upcoming experiments are performed is described, as well as the experimental setup followed. Results of the adopted approach under different experimental scenarios, using several configurations in order to quantify the effects of various parameters in the whole MS image classification pipeline, are presented and discussed, to illustrate the performance of the methodologies introduced in this paper.
4.1. Dataset Description
In designing DL solutions and training ML models, the definition of a suitable training and test set is a critical task. Bearing into mind that to achieve decent classification performance, the number of samples comprising the dataset must be sufficiently large, most current land-use and land-cover classification datasets did not meet these expectations. Furthermore, the “distribution” of samples (i.e., images) inside the dataset should be as close to uniform as possible (in order to avoid class imbalance problems), with each class consisting of several thousands of samples to be fed to the NN model.
Fortunately, quite recently, a large MS image dataset (containing RGB images as well) meeting the above requirements was released [
60,
61], where Sentinel 2A MS image data are employed to address land-use and land-cover classification tasks. The dataset comprises image patches measuring
pixels, each one of them corresponding to spatial resolution of 10 meters/pixel, across 13 different spectral bands (in the 443 nm–2190 nm wavelength range). In total, several thousands of sample satellite images are gathered, across 34 different European countries (hence, the EUROSAT dataset name), ending up with 10 different classes.
To have a better sense of the EUROSAT dataset, in
Figure 4 we depict RGB sample images for each one of the dataset’s different classes, by employing spectral bands 04 (Red-665 nm), 03 (Green-560 nm) and 02 (Blue-490 nm). Since in this study we deal with a MS image classification task, in
Figure 5 we demonstrate the various spectral bands (MS datacubes) of the sample images depicted in
Figure 4.
4.2. Experimental Setup
Since the classification task lies in the heart of the present study, two non-overlapping training-test sets had to be defined a priori. In order to avoid class imbalance problems, we employed 20,000 MS sample images from the EUROSAT dataset assuming that each class consists of 2000 samples. With this setup, we split each class into /5% training/test sets (i.e., 1800/100 training/test examples per class, and 18,000/1000 training/test examples in total, respectively), while at the same time another of each class was used for validation purposes during the training process of the network. Training was performed using a constant number of up to 100 epochs with the intention of observing how the prediction accuracy changes by increasing the number of epochs the network is trained for.
To make more clear the above data distribution among the training, validation, and test sets, we summarize in
Table 1 the aforementioned splits for each of the employed classes as well as in total.
To quantify the performance of the proposed system from a ML perspective, we report Classification Accuracy and Classification Loss metrics, accompanied by the required Computational Time as well as the respective Confusion Matrix. Furthermore, Precision and Recall metrics are also computed. However, in order to examine the effect of the quantization on the classification task, we quantized the MS images of our dataset to 2, 4, 6, 8 and 10 bits, as the original MS images use 12 bits per pixel. Then, we compared the classification performance given the original, the quantized and the recovered images via the proposed recovery algorithm. Moreover, we examined the recovery of the real values of the images given the quantized measurements.
The reconstruction quality is evaluated by computing the
Peak-Signal-to-Noise-Ratio (PSNR) between the original and the estimated MS images. Higher PSNR values correspond to a better-quality recovered image. Specifically, PSNR is computed using the expression
where
R is the maximum value of the input image and MSE is the
Mean Square Error, i.e., the average of the squares of the differences between the original and the estimated signal.
Since the training of a DL model is a computational expensive procedure, the employed CNN architectures were developed in Python programming platforms-exploiting the TensorFlow (
https://www.tensorflow.org/) and Keras (
https://keras.io/) libraries. There are two reasons behind such a choice: First, TensorFlow is an open-source ML framework, which when used as the back-end engine for the higher-level DL-specific Keras library, provides support and updates on most state-of-the-art DL models and algorithms. Secondly, and most importantly, both libraries can perform calculations on a GPU, dramatically decreasing the computational time of the training process. In our experiments, we used NVIDIA’s GPU model, Quadro P4000.
On the other hand, since the compression algorithms described earlier do not need a GPU usage for their computations, they were implemented in MATLAB R2019a version.
4.3. Effect of the Training Set Size on the Classification Performance
In a first set of experiments, our objective is to assess the performance of the employed CNN relative to the size of the training set. A random selection of up to 200 training examples per class was initially considered, a number which was augmented by 200 at each step until containing all available training examples of each class (i.e., 2000 per class). The number of test examples was 100 per class (i.e., 1000 in total), as mentioned earlier.
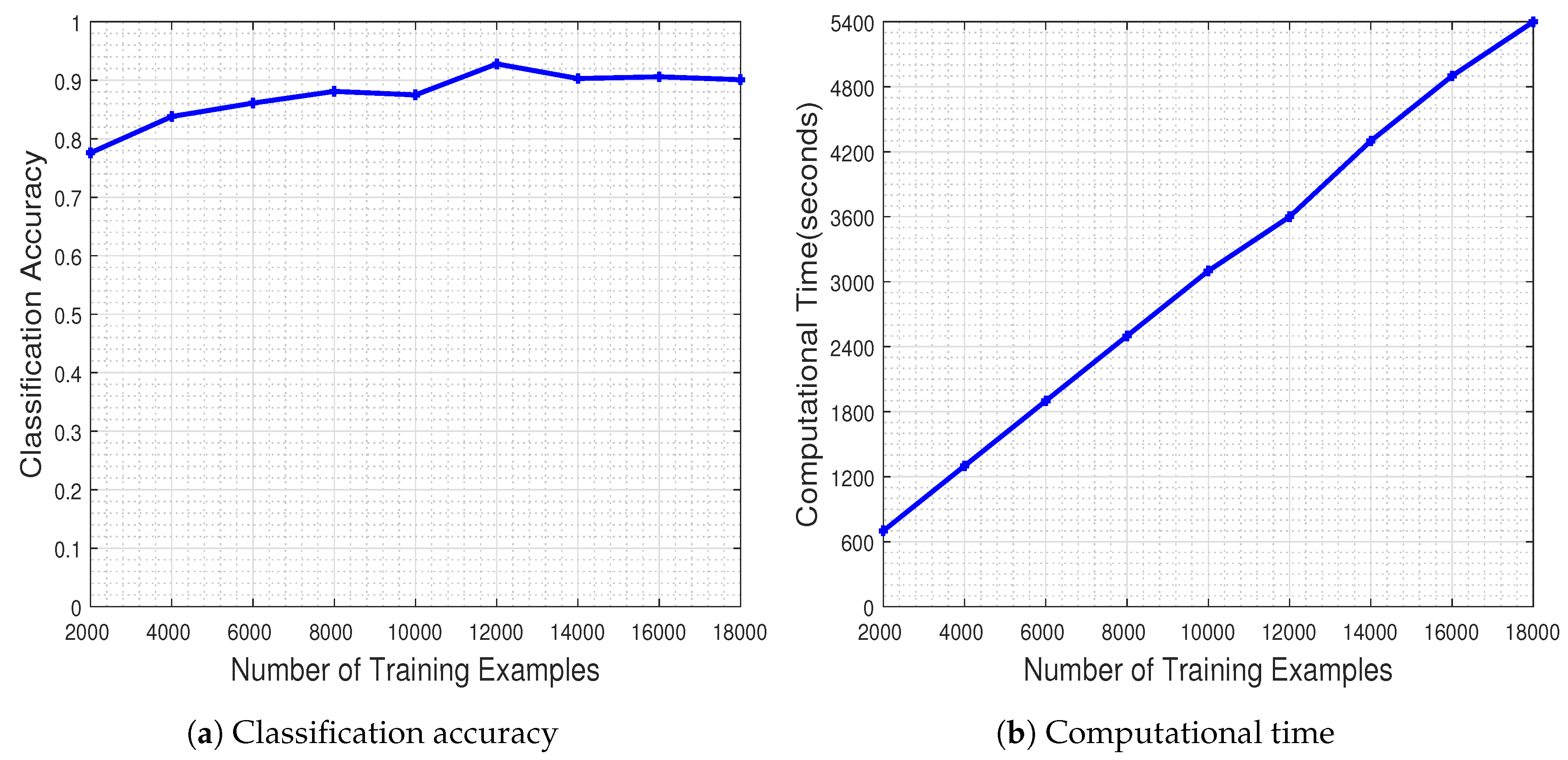
Figure 6 illustrates the performance of the CNN measured as a function of the number of the training examples. The results in
Figure 6a demonstrate that increasing the number of training examples has a positive effect on the generalization capacity of the CNN, as dictated by the theoretical underpinnings. The network has a stable performance when trained with at least 8000 training examples. It should be noted that the CNN classifier achieves the best performance when trained with about 1200 image samples per class (i.e., 12,000 image samples in total), ending up with a classification accuracy equal to
.
Naturally, the improved classification performance of the CNN model does not come for free, as demonstrated by the execution time plots in
Figure 6b. However, one should highlight the fact that on the one hand the time increases by a factor of 600 s as the number of training samples is doubled, while on the other hand the time needed for achieving the best performance at 12,000 training examples, namely 3600 s (i.e., 1 h), is far from being characterized as prohibitive considering typical DL experimental regimes. Overall, the results clearly demonstrate the merits and learning potential of the employed CNN modeling.
To have a better sense of the network’s behavior during the training process, in
Figure 7 we provide the best model accuracy as well as its loss (i.e., for 12,000 training examples), for the training and validation sets, with respect to the number of epochs up to which the network was trained.
The results of this experiment show that the trained CNN model improves its performance in terms of classification accuracy, both in the training as well as in the validation set, as the number of epochs increases. Furthermore, the classification loss in the validation set keeps track, in general, towards that of the training set, showing that the model is capable of generalizing well during the test phase (which is indeed the case, as mentioned earlier in
Figure 6, with the
classification accuracy in the test set).
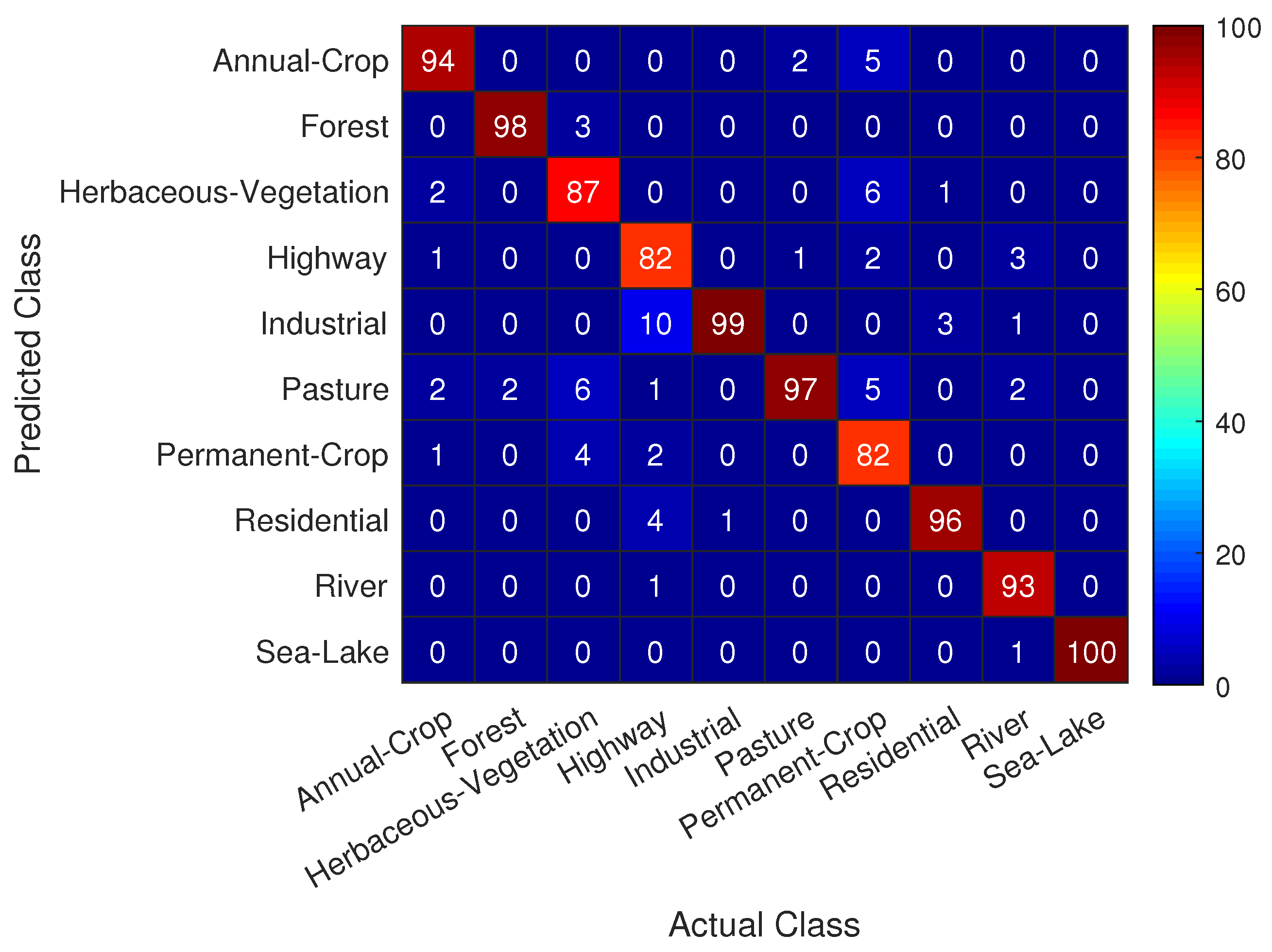
Useful information concerning the classification task at hand can be extracted from the confusion matrix shown in
Figure 8, where we see that the trained CNN achieves quite remarkable performance in predicting correctly nearly all actual classes in the test set with a success rate of over
. A special notice should be given to the classes that appear to be more challenging for correct prediction, namely:
Class Highway is most frequently mistaken with classes Industrial and Residential
Class Permanent Crop is most frequently mistaken with classes Herbaceous Vegetation, Annual Crop and Pasture
Even for these difficult to classify classes in
Figure 4, the trained CNN model achieves a success rate of over
, indicating the efficacy of the proposed approach.
4.4. Effect of the Compression Ratio on the Recovery
As the quantization process can be used for compression purposes, we examined the efficacy of our method for different compression ratios on the MS images of each class, with the results presented in
Table 2. Specifically, in order to compress the data, a lossless coding algorithm, namely Huffman coding, was employed on the quantized MS images, using a dictionary obtained from the images of the training set. The corresponding
Compression Ratio is calculated as the fraction of the number of bits of the uncompressed image over the number of bits of the compressed one, i.e.,
As expected, the smaller the compression ratio, the better the performance of our algorithm. However, efficient recovery with a high compression ratio can still be achieved by our technique.
4.5. Effect of the Number of Quantization Bits on the Recovery
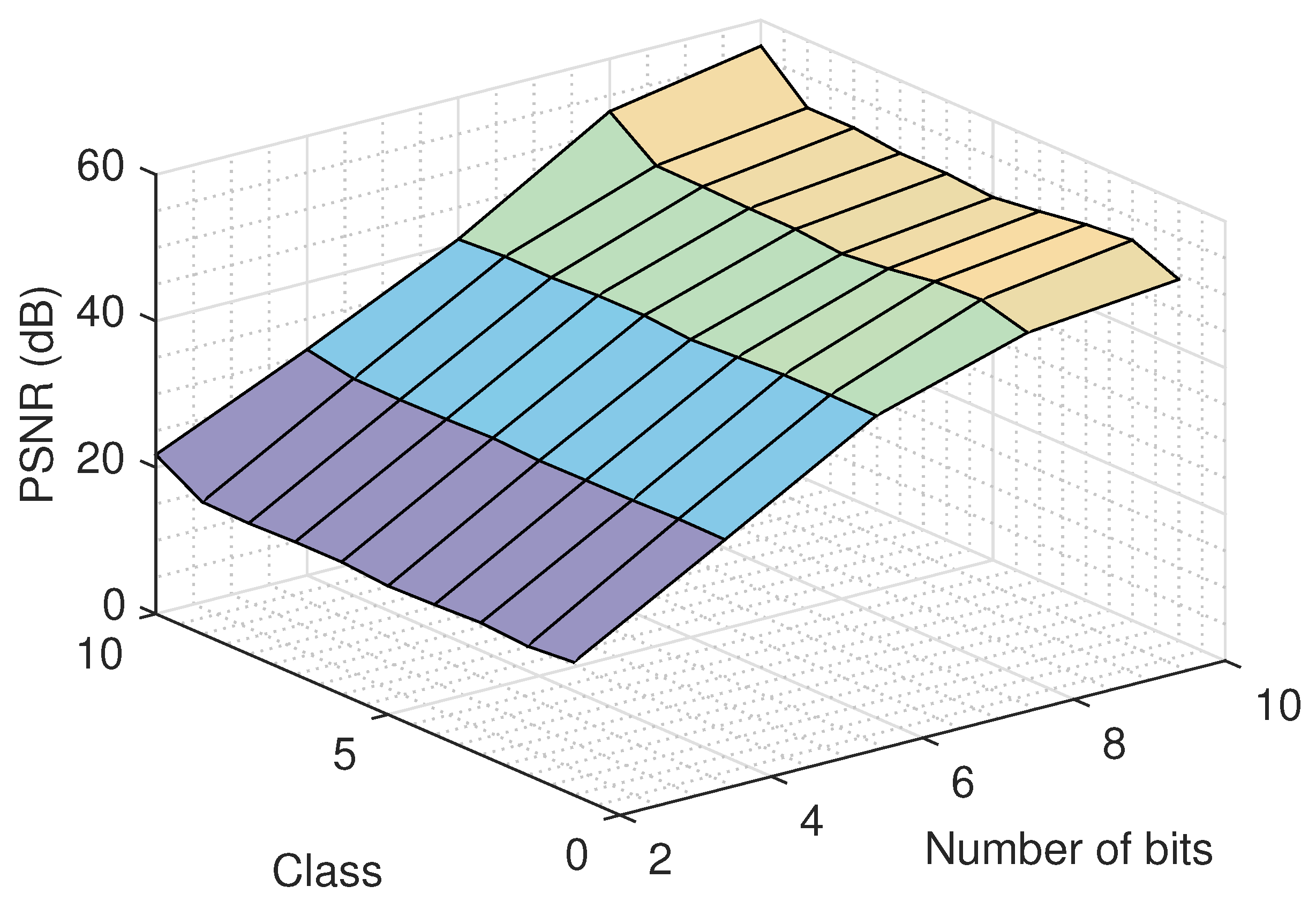
An important issue that must be examined deals with the effect of the number of quantization bits. To study this, we run the proposed recovery algorithm for several quantization bit values and for various classes, using the logistic model, and we report the recovery error in
Figure 9. As it was expected, a bigger number of quantization bits results to a better quality for the recovered images. Similar performance is observed for all classes. Moreover, the recovery improvement in the large number of bits region (8 and 10) is smaller compared to the improvement achieved in the small number of bits region (2 and 4), as more information is retained using more bits for the representation of the signal.
The above observation can be visually verified in
Figure 10 that depicts the second spectral band of a MS image from the
Highway class and the corresponding quantized images using 2, 4 and 6 bits, as well the recovered images for each case, using the logistic model. As we observe, the quality of the recovered images from quantized measurements using 4 and 6 bits is better than the one using 2 bits. In addition, we can observe that using fewer bits, more information of the image is lost, which can be recovered using the proposed algorithm.
Please note that the recovery error for each class and a specific number of bits is calculated as the mean value of the error on the test images for all the experiments. In addition, we observed from our experiments that the performance of the method for the two noise models used was similar, so we kept the logistic model for the following experiments.
4.6. Effect of the Tensor Unfolding and Dynamic Weights on the Recovery
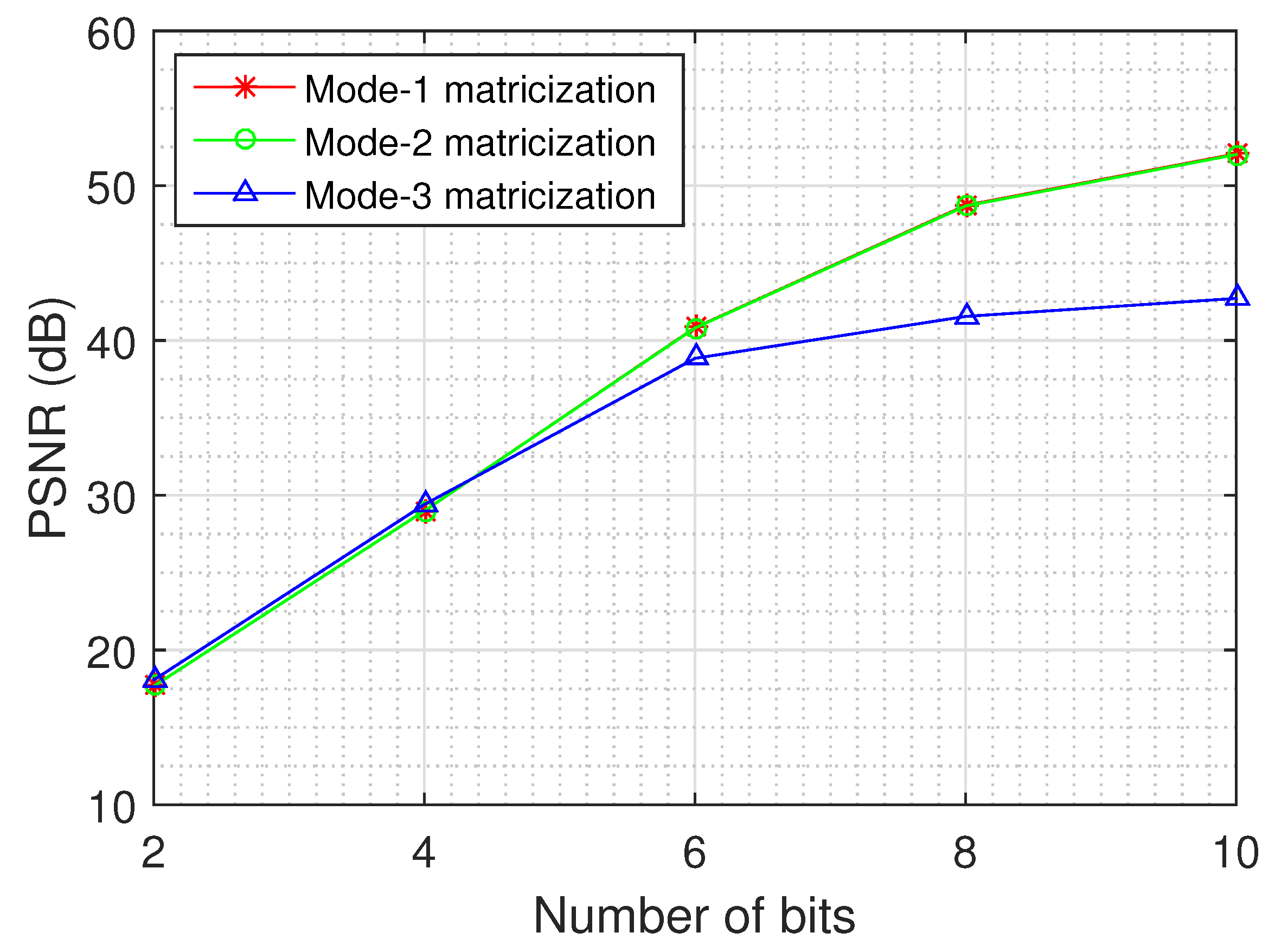
An important issue relates to the quality of the recovery for each unfolding of the tensor data and the impact of the dynamic weights on the recovery.
Figure 11 depicts the recovery error as a function of the number of quantization bits for the different unfoldings of the tensor, using the logistic model and the MS images of the Annual Crop class.
The results demonstrate that the dynamic weights improve the quality of the recovered tensor, as the mode-1 and mode-2 matricizations exhibit a better performance than the mode-3 matricization, especially for large values of quantization bits (8 and 10). In addition, we can deduce from the results that the recovery performance becomes better when the dimensions of the unfolding matrix are more balanced, as the mode-1 and mode-2 matricizations of each MS image have dimensions , while the mode-3 matricization has dimensions .
4.7. Effect of the Quantization on the Classification Performance
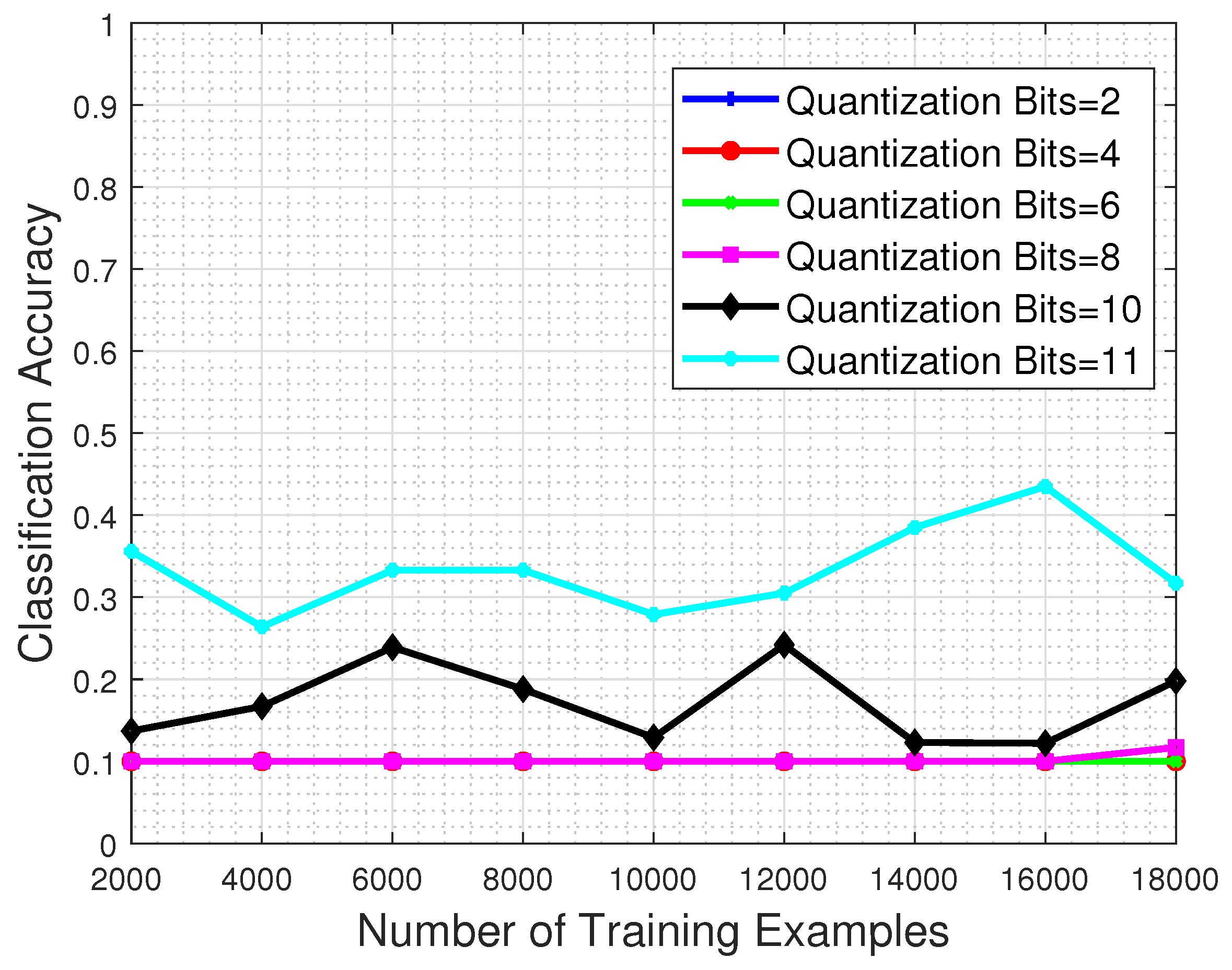
In this set of experiments, we investigate the detrimental effect that the quantization process has in the classification performance of a system. For that purpose, the trained CNN model is evaluated to a test set that has been previously quantized to a specific number of bits, in order to obtain intuition about the system response when faced with corrupted image samples.
Figure 12 shows the performance with respect to the number of training examples and for different quantization bit values imposed on the test set image samples. The results clearly demonstrate that whatever the quantization level, the classification performance clearly suffers even if the system is trained with the maximum permitted number of training examples. Even in the favorable case of 11-bit test images (recall that the nominal bits corresponding to each MS image are 12) the network’s classification performance barely reaches
.
4.8. Effect of the Quantization and the Recovery on the Classification Performance
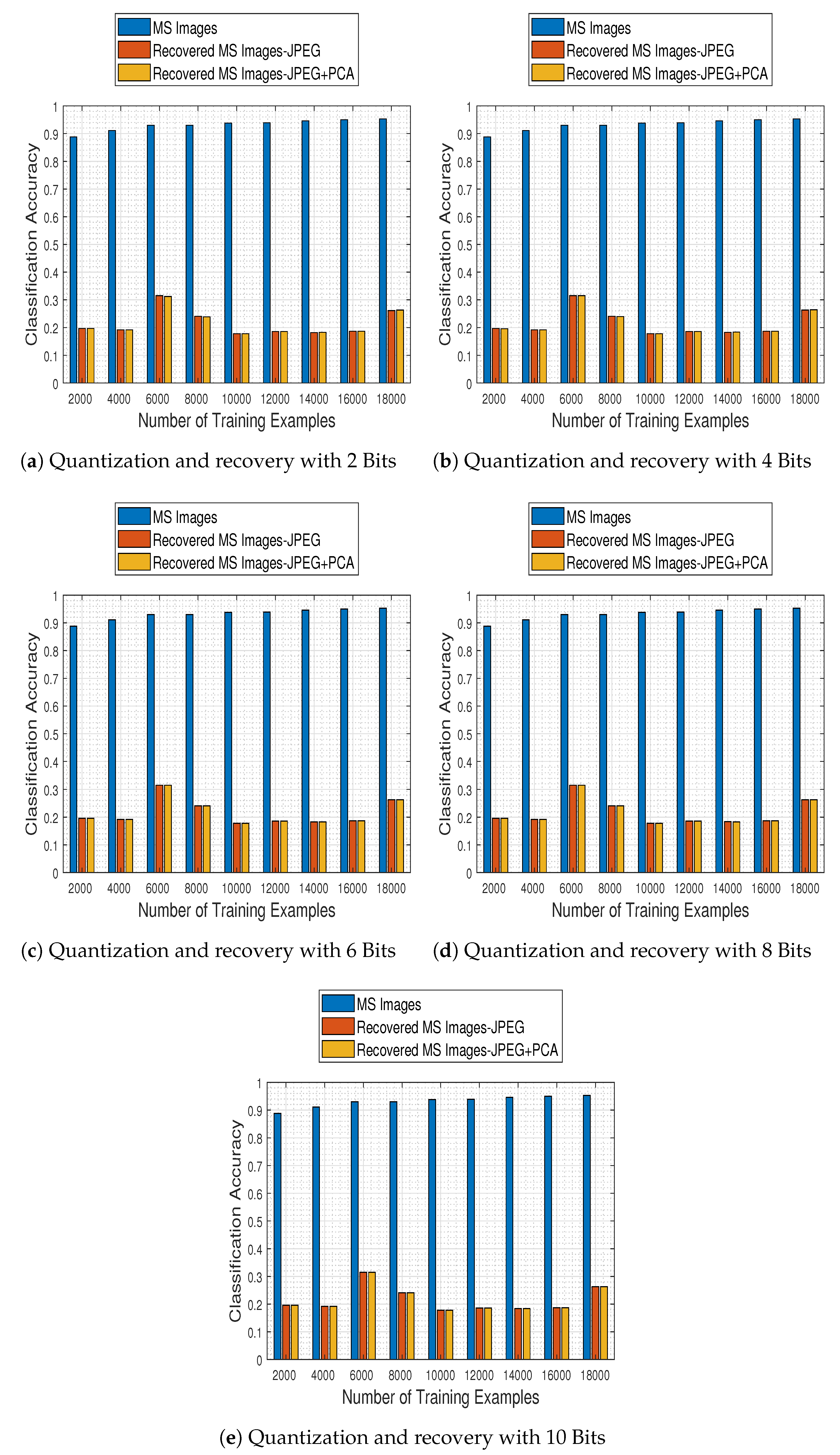
To explore the ability of our CNN model to classify compression-processed MS images, we further investigate the enhancing effect that our proposed recovery process—of previously quantized MS images—has in the classification performance of a system. Towards that goal, the trained CNN model is evaluated using a recovered by our approach test set, which was previously quantized to a specific number of bits.
In
Figure 13 we show the system’s performance as a function of the number of training examples, and for test images quantized to 2, 4, 6, 8, and 10 bits and subsequently recovered using our proposed method. The results clearly show our recovery approach manages to boost the classification accuracy of the system, even when operating with recovered images that were previously quantized using as few as 4 bits.
4.9. Joint Effects of the Quantization and the Recovery on the Classification Performance
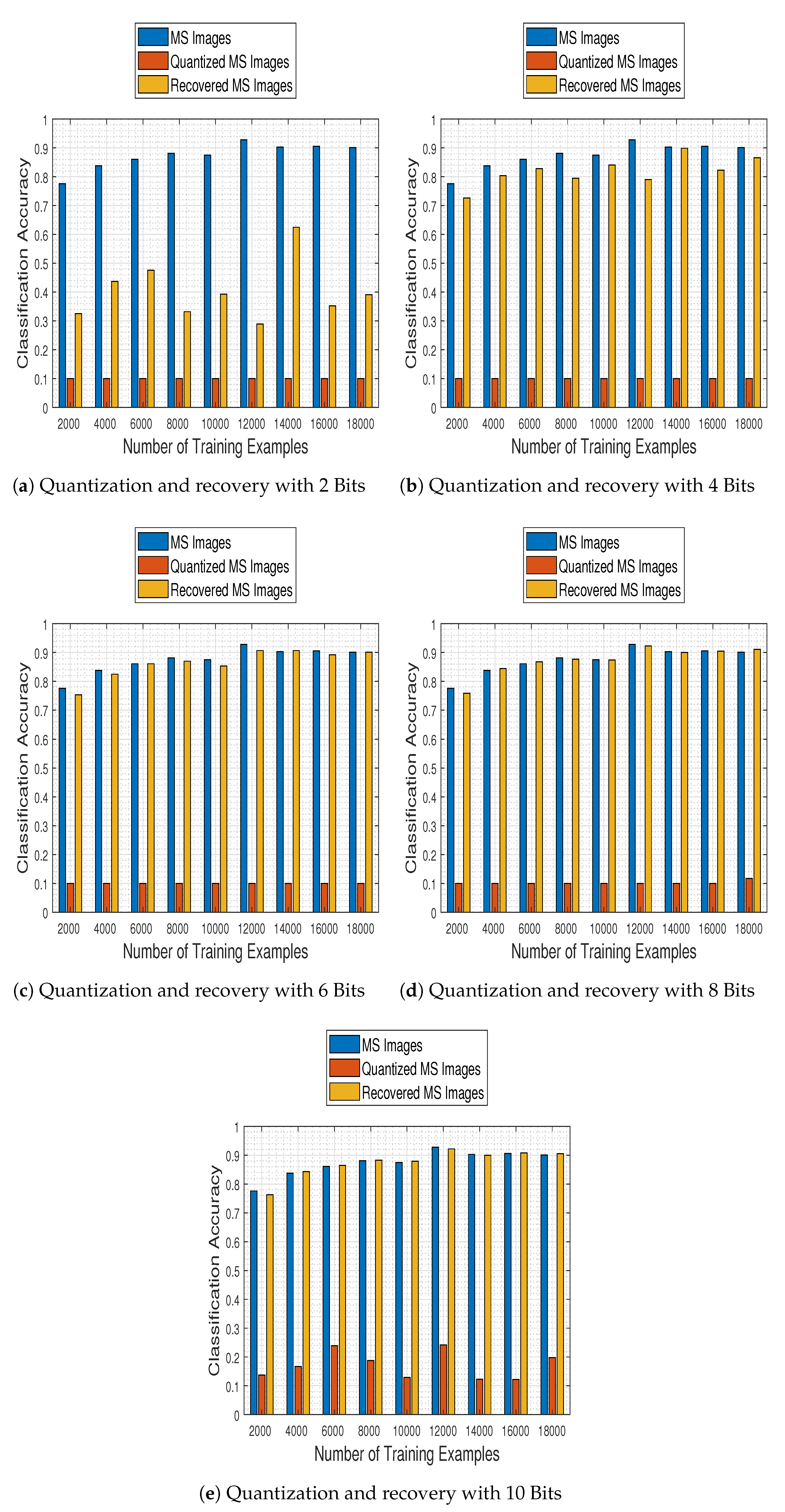
In this set of experiments we make a general comparison of the aforementioned quantization and recovery processes, in order to quantify their effects in the MS image classification task, with respect to the “original” case where none of them is present in the classification pipeline.
Figure 14 contains classification accuracy plot bars for the employed CNN trained with 2000:2000:18,000 samples on original test MS images, their quantized versions (using 2, 4, 6, 8, and 10 bits) and their recovered by our approach estimates. The results make clear that the proposed recovery method not only remedies the effects of quantization, but most interestingly it empowers the CNN model to exhibit a classification performance on par to that obtained when working on the original MS images, nearly from a compression level when the images are quantized to half the bits of their nominal available ones (6 bits).
4.10. Effect of Missing Values on the Recovery
In many cases, noise or other issues in the transmission and acquisition of a signal, lead to unobserved or lost measurements. One such case could be caused by the appearance of clouds in the acquired images. Hence, the issue we address concerns missing pixel patches, within all image spectral bands, a problem more challenging than the incoherent condition usually assumed in tensor completion, where the missing elements must be randomly distributed in the tensor.
To examine the effect of missing values in the data, we randomly selected patches of each test image, imposing missing elements across all spectral bands. In particular, we considered the following sampling scenarios:
10 patches of size 3 × 3 × 13 pixels
20 patches of size 3 × 3 × 13 pixels
10 patches of size 7 × 7 × 13 pixels
20 patches of size 7 × 7 × 13 pixels
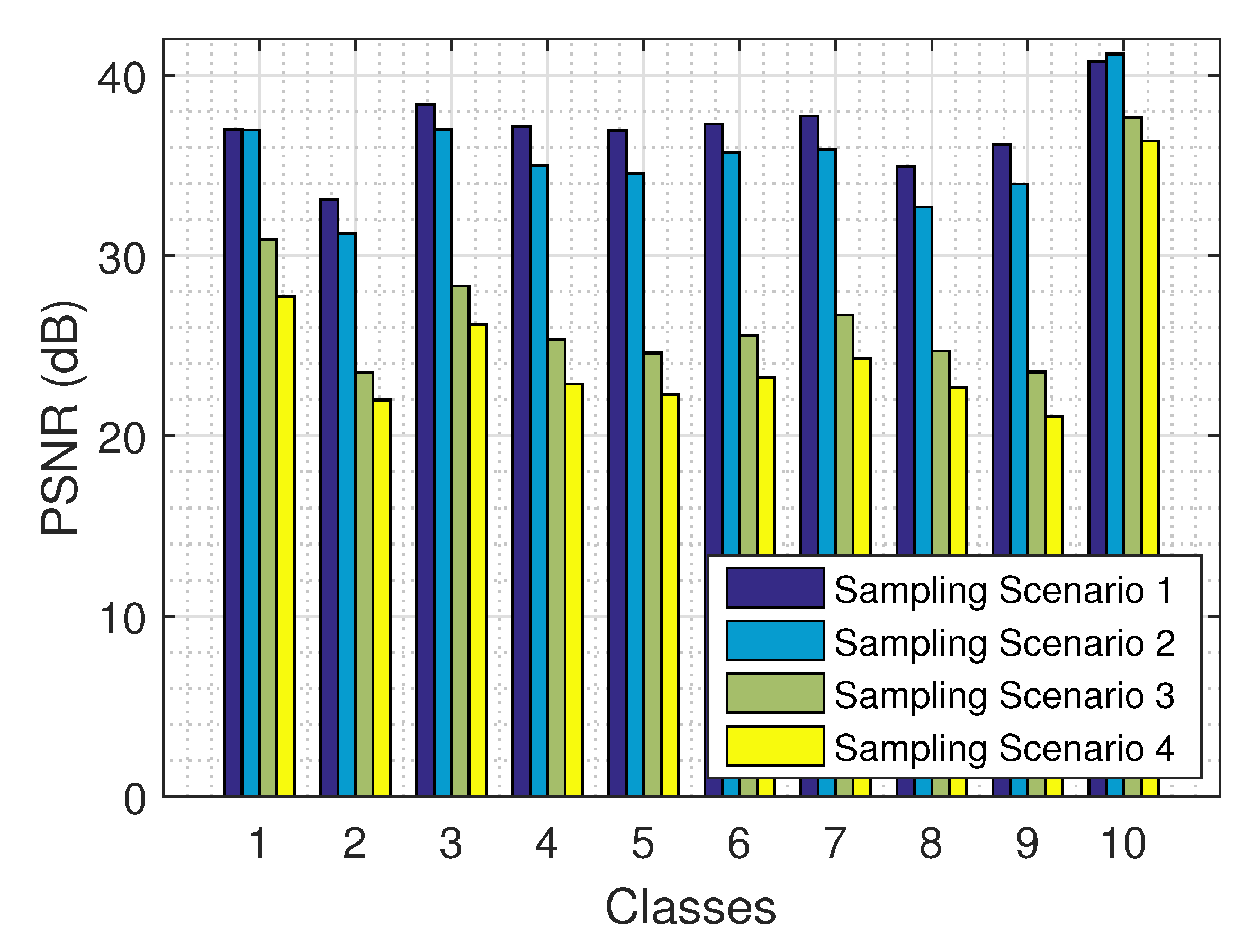
The results on the recovery of a tensor from its partial observations are presented in
Figure 15 for the 4 sampling scenarios and all 10 classes, using the logistic model. As expected, the larger the amount of the observed values (e.g., in sampling scenario 1), the better the performance of our algorithm. The results are fairly consistent across all 10 classes.
4.11. Effect of Missing Values and the Recovery on the Classification Performance
In this set of experiments we are concerned with the scenario where missing measurements occur in environmental sensing data, and we therein explore the beneficial impact of our proposed approach for completing higher-order structural information via tensor modeling on the ensuing classification process. In order to do so, we consider the 4 different missing values scenarios described previously, and we quantify the performance of the trained CNN model in each one of them, in an attempt to illuminate the effect of missing measurements features (e.g., nominal number, spatial size) in the system generalization capability under real-world imperfections.
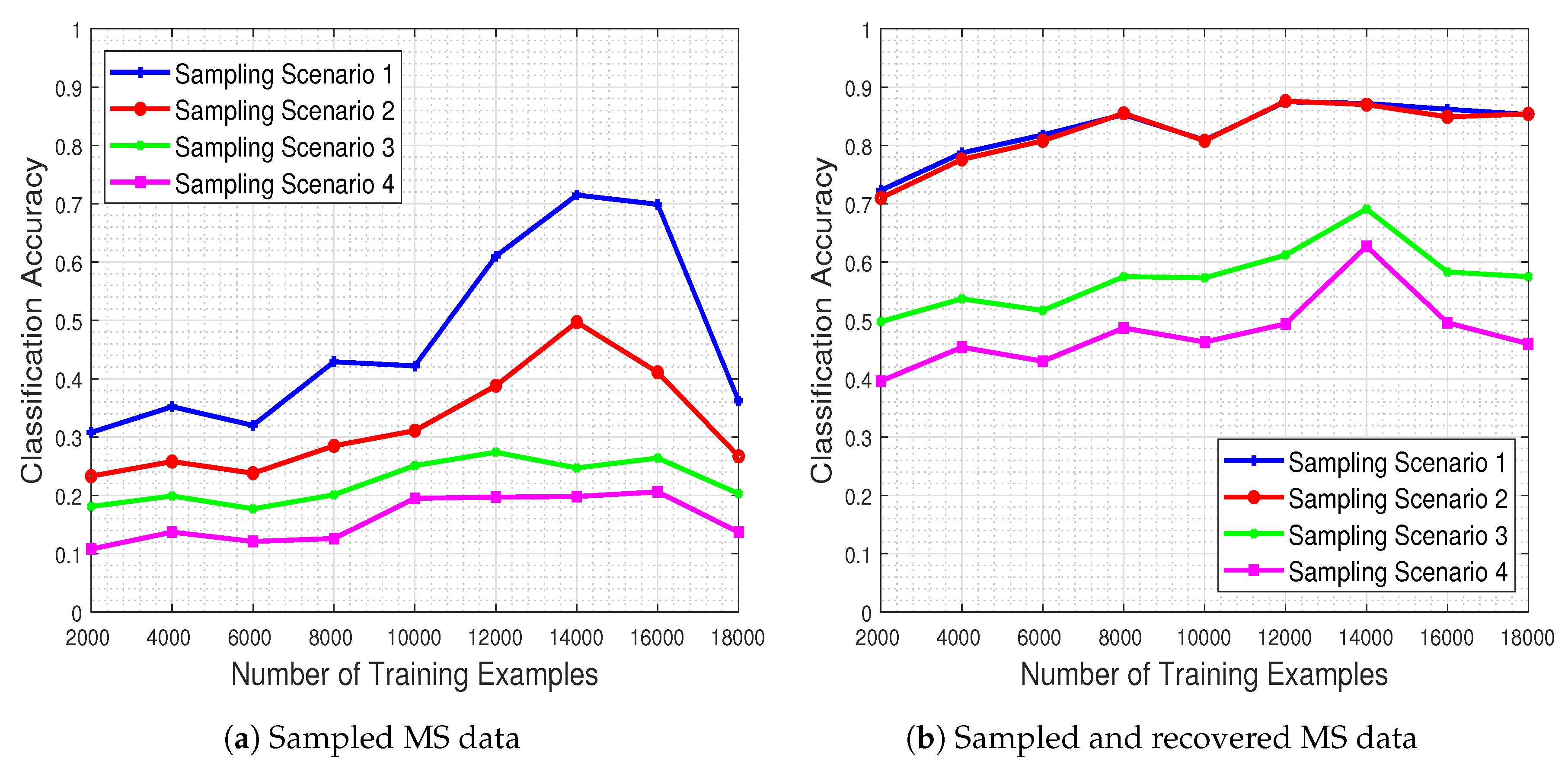
Figure 16 shows the system’s classification performance, in the presence of the missing values (
Figure 16a) and when these missing values are recovered by means of our proposed method (
Figure 16b). The results demonstrate that the CNN’s classification performance improves dramatically when our missing data recovery algorithm is employed for all four scenarios.
4.12. Effect of Missing Values and Quantization on the Recovery
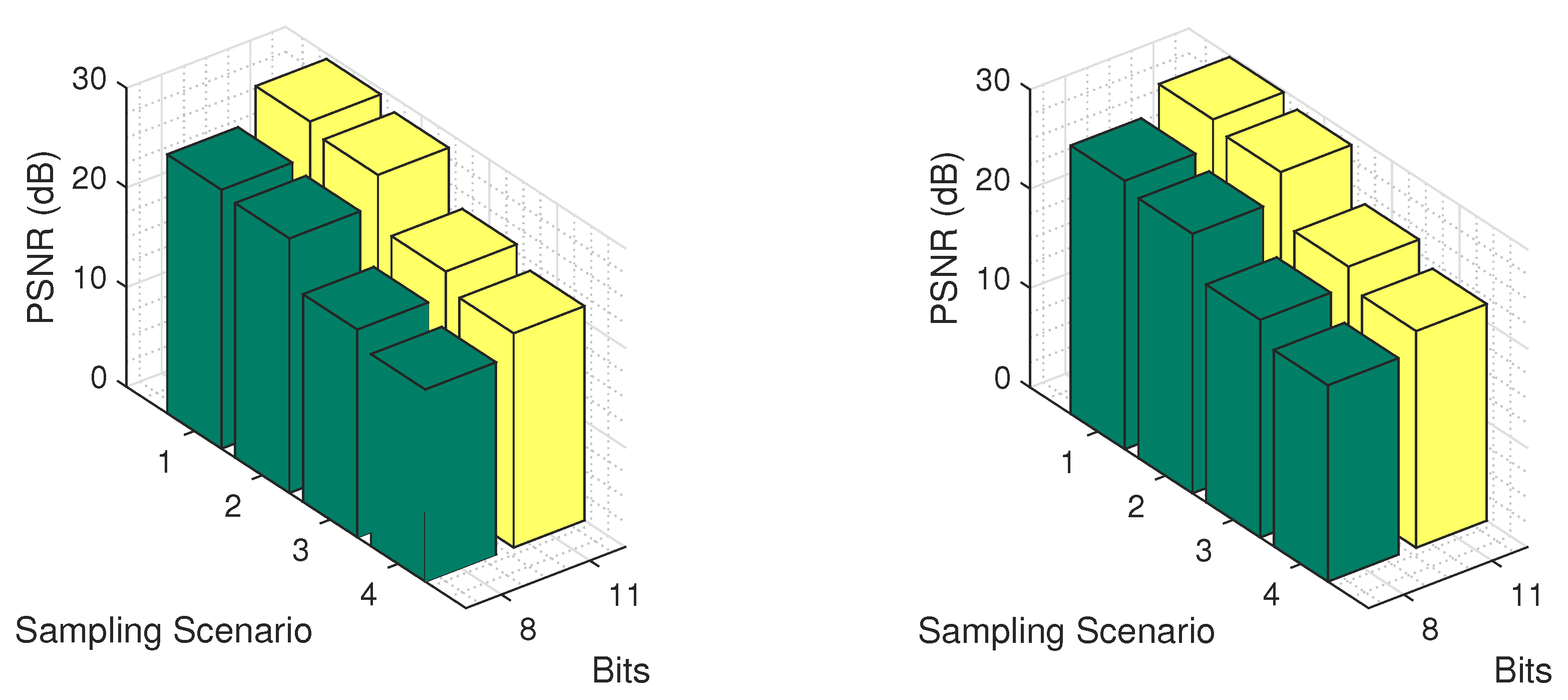
An interesting issue concerns the recovery of the real values of an image from its partial quantized observations. Therefore, in order to examine the effects of both missing values and quantization in the test images, we applied our method for the four missing value scenarios and for two quantization levels, namely for 8 and 11 bits. The results are presented in
Figure 17, for classes
Pasture and
Permanent Crop, using the logistic model. As expected, as the missing values increase, the recovery error increases for both quantization levels. Of course, the more the bits of quantization, the better the performance of our recovery.
In
Figure 18 we show the second spectral band of a MS image from the
Industrial class, and the corresponding quantized and subsampled image using 8 bits of quantization and sampling scenario 1, as well the recovered image using the logistic model. As we observe, the original MS image can be recovered with high fidelity from partial quantized measurements using our proposed algorithm, despite that the missing elements are not randomly distributed in the image.
4.13. Effect of the Quantization & Missing Values on the Classification Performance
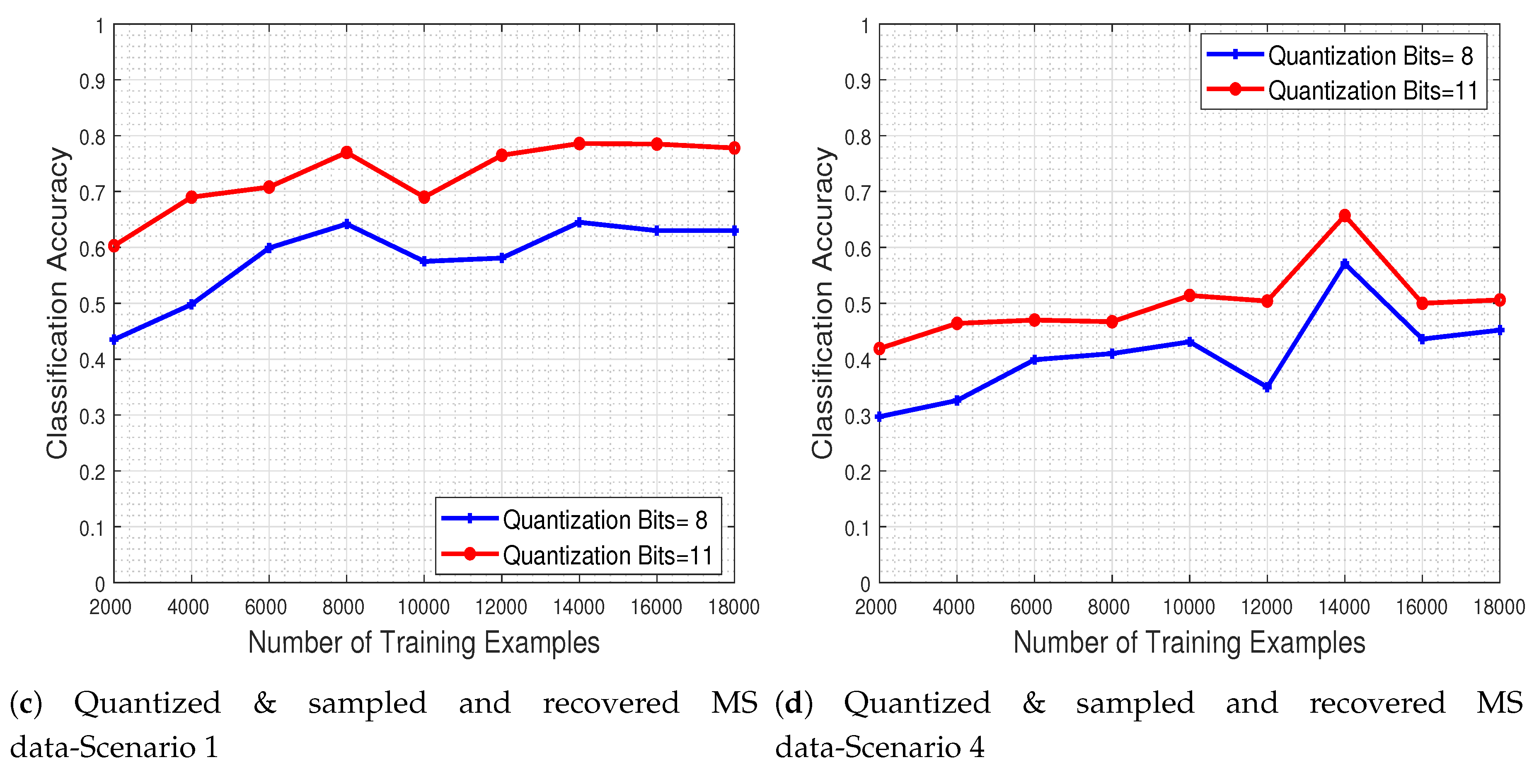
To test the system’s performance in the presence of corrupted MS data (i.e., quantized and subsampled), we evaluated the trained CNN model to a test set that has been quantized to a specific number of bits and subsequently subsampled as well.
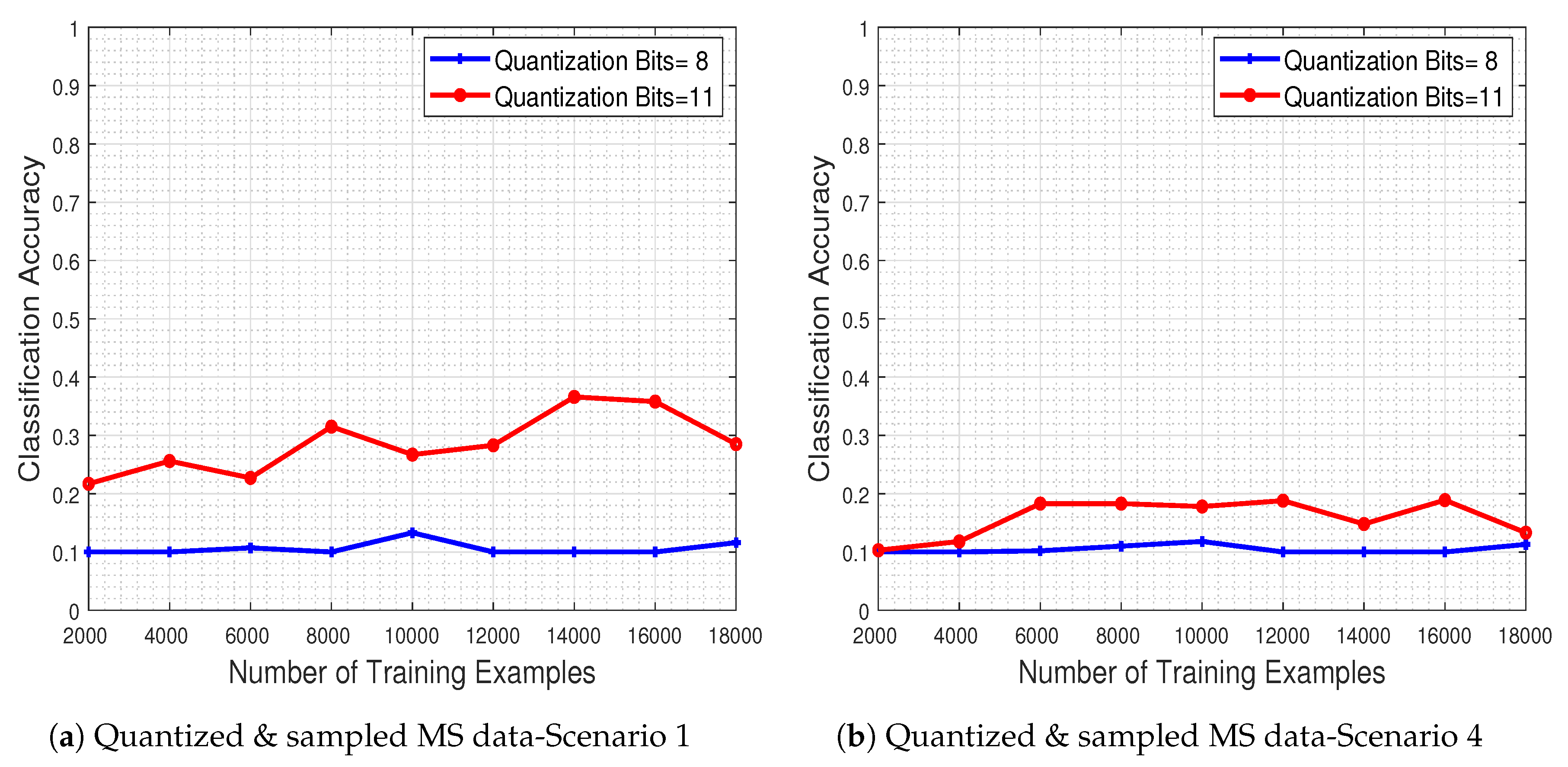
In
Figure 19a,b, we depict the obtained performance as a function of the number of training examples, for two quantization levels (8 and 11 bits) and for the two most extreme missing value scenarios (i.e., scenarios 1 & 4). The results clearly show that the system’s classification accuracy is severely degraded due to the quantization and missing value effects. As expected, when more bits are used for the quantization process the performance improves, while increasing the number of missing pixel patches as well as their spatial size adversely affects the classifier.
4.14. Effect of the Quantization & Missing Values and the Recovery on the Classification Performance
To demonstrate the ability of the CNN system to classify noisy-infected MS images, we further investigate the effect that our recovery process has on the classification of quantized and subsampled MS images. For that purpose, the trained CNN model is evaluated to a test set that has been recovered via our approach from a quantized and subsampled original image.
Figure 19c,d depict the system’s classification accuracy as a function of the number of training examples, for the recovered by our method versions of test images that were quantized in two levels (with 8 and 11 bits) and for missing value scenarios 1 and 4. The results indicate that adopting a quantization scheme with more bits in conjunction with our proposed recovery process leads to enhanced classification accuracy. Our recovery process clearly improves classification accuracy even in the extreme case where the number of missing pixel patches as well as their spatial size is large.
4.15. Joint Effects of Quantization & Missing Values and Recovery on the Classification Performance
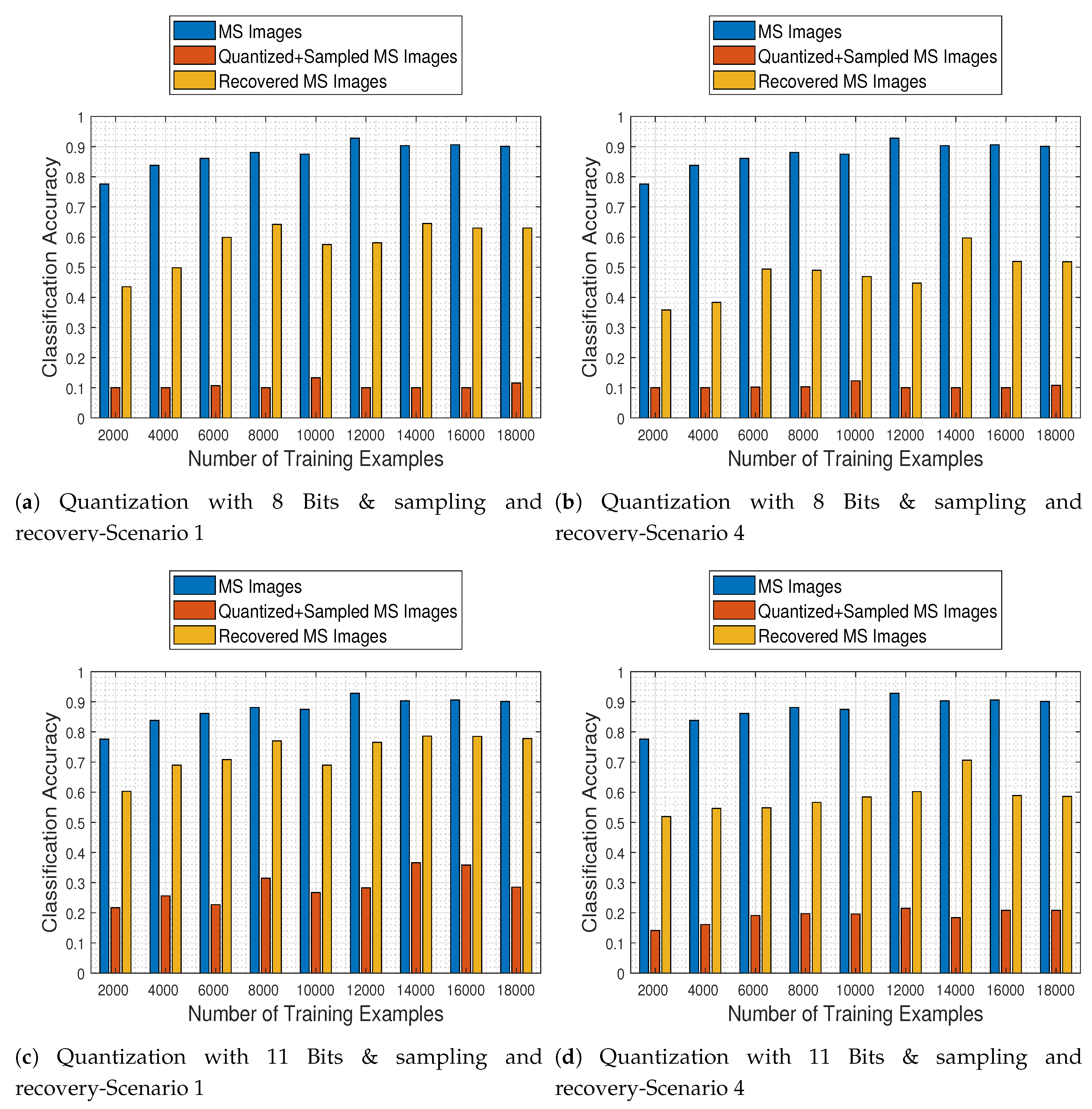
In the final set of experiments, we conduct a general assessment of our proposed recovery process in order to quantify its effects on the MS image classification task operating on the original images and on the recovered images that were previously quantized and corrupted.
Figure 20 depicts the trained CNN performance as a function of the number of image samples it was trained with, when faced with all different kinds of test images (namely original MS, quantized & sampled MS, and recovered MS images), for two quantization levels (8 and 11 bits) and for the two most extreme missing value cases (i.e., scenarios 1 & 4). The results support our claim that the proposed recovery method clearly improves the classification accuracy of the network in all cases, as compared to the CNN being applied directly to the quantized and subsampled images.
4.16. Comparison of the Proposed Scheme with Existing Methods
In this section, we compare our approach with other methods which examine the impact of compression on the classification task [
45,
46,
47]. Existing methods apply JPEG2000 on each spectral band, or JPEG2000 followed by DWT or PCA for spectral decorrelation to compress the data. Subsequently, the decompressed-recovered images are fed to standard k-NN or SVM classifiers to perform the supervised ML task. In our system, we compress the MS images by quantization, and we classify the recovered MS images obtained by the proposed recovery algorithm using the pre-trained ResNet-50 model described above.
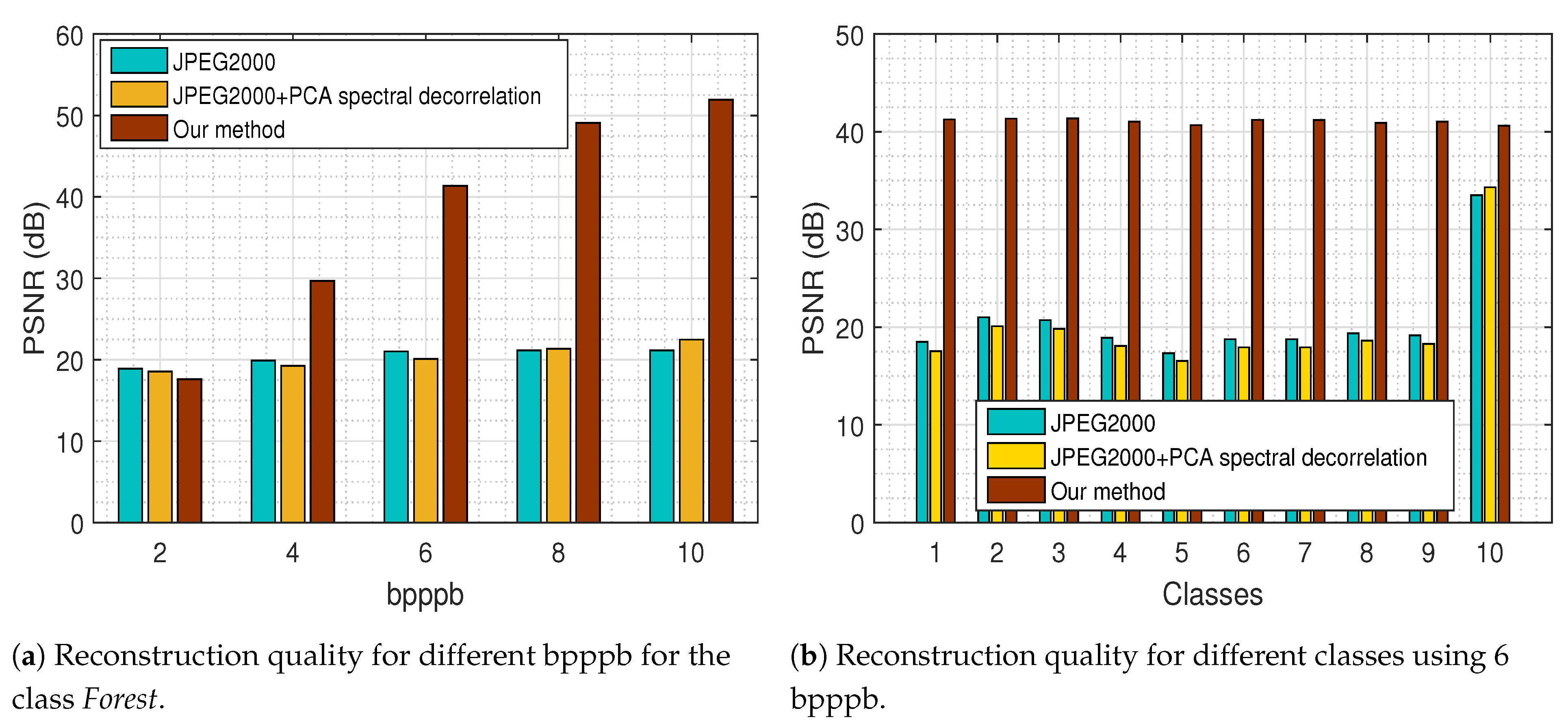
At the compression stage of our method, we compared the recovered MS images via the proposed tensor recovery algorithm with the decompressed images via JPEG2000 on each spectral band and via JPEG2000 followed by PCA for spectral decorrelation. The recovery error as a function of
bits per pixel per band (bpppb) for the class
Forest presented in
Figure 21a, indicates the efficacy of our method since the PSNR increases as the bpppb value gets higher in contrast to the other compression methods that exhibit a fairly constant PSNR behavior even for large values of bpppb.
In addition, we can observe from the results that our approach outperforms existing compression methods, especially for large values of bpppb, as it is demonstrated in
Figure 21b for the HS images of each class, using 6 bpppb.
The classification stage is implemented in two levels: one operating on the original MS images and one operating on the recovered MS images. In order to perform a comparison between the adopted ResNet-50 model architecture at both levels, a competing ML model must be selected at first.
Although existing methods studying the compression impact on classification [
45,
46,
47] adopt specific classifiers such as k-NN or SVM, the examined problem therein is of a different nature: pixel-level classification of a MS image (e.g., for object detection purposes) in contrast to scene classification in our case (i.e., the whole image is classified). Furthermore, following the traditional ML pipeline, feature extraction and feature selection stages must take place before the classification stage. If this is not the case, and one simply treats the MS imagery at hand as “long” feature vectors (of pixels) to be fed to the classifier (e.g., an SVM), the whole task is automatically put in jeopardy mainly for two reasons: possible correlations among the data are not exploited as long as no descriptive features are extracted from them, while the computational burden of such a process may be intractable (these classifiers do not perform computations on GPUs as DL-based CNNs).
Based on the aforementioned reasoning, we did not compare the adopted network with standard ML classifiers, but rather with a CNN model trained from scratch. Apart from the ease of GPU computations, adopting such an approach passes the feature extraction stage directly to the model through its training process.
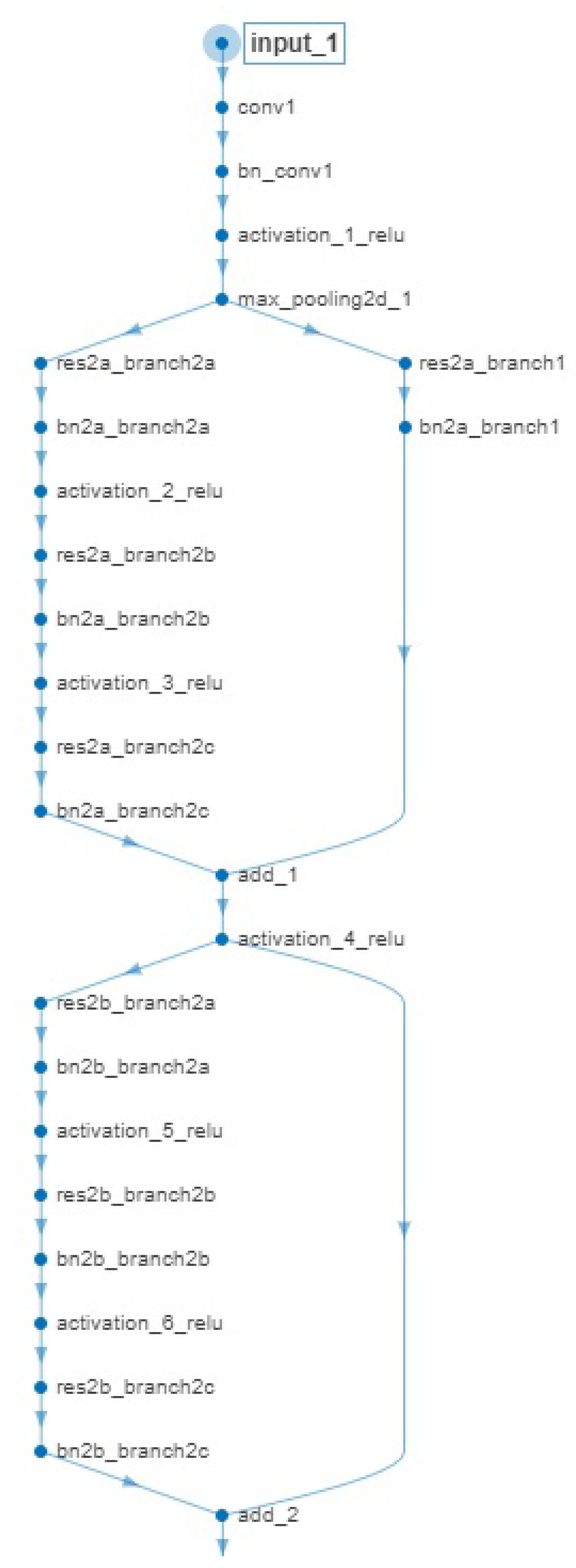
Concerning the architecture of the competing CNN, we adapt a solution involving 3D-CNNs (for tackling human action recognition [
62] and video quality assessment [
63] problems) to their 2D counterparts for our task at hand. More specifically, the network architecture comprises multiple stacks of convolutional, max-pooling, normalization, and activation (i.e., ReLU) layers. The number of stacks of layers employed was 5, where each convolutional layer is always followed by a max-pooling layer, a batch-normalization layer and an activation layer in that order. These layers are then followed by 2 fully connected layers, and a final soft-max layer for the prediction task.
Based on the findings of the aforementioned reference papers (as well as on our own cross-validation results) we employed small receptive fields (e.g., ) for the convolutional filters, rather than larger ones (e.g., ). As far as the number of filters is concerned, we adopted a “doubling-depth” strategy where the filters are doubled from a previous layer to the next one, starting from 32 filters in the first layer and ending up with 512 in the last layer in that way. All max-pooling layers have a size of , which corresponds to reducing the input data by a factor of 4, while the fully connected layers have 512 and 256 units respectively. For fairness of comparison, the Adagrad optimizer was selected along with the categorical cross-entropy as the loss function.
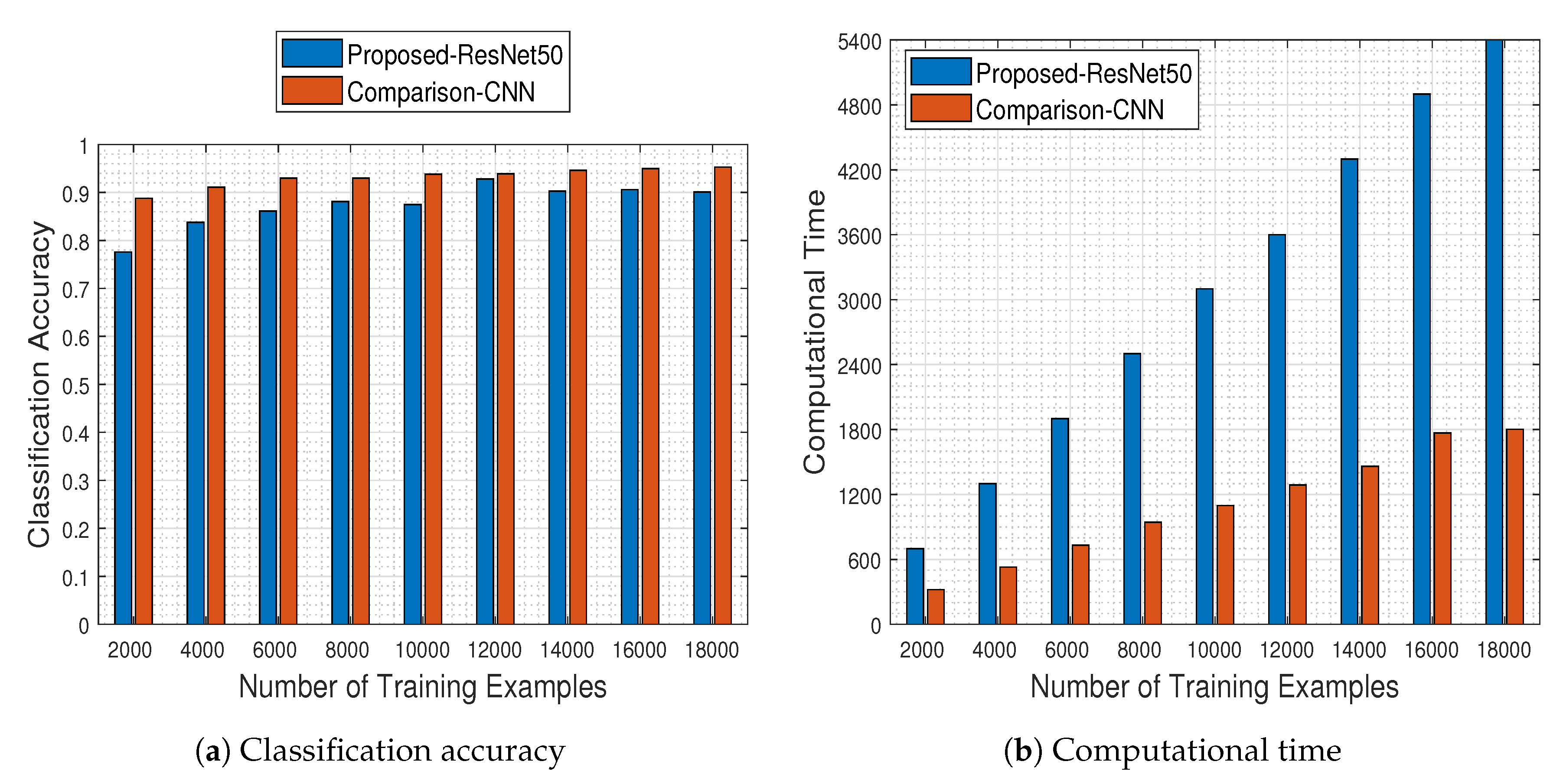
Being aligned with the results presented in
Figure 6, in
Figure 22 we depict the respective results obtained by the
“comparison-CNN” model described above.
As can be seen in
Figure 22a,b, the comparison-CNN model outperforms the pre-trained ResNet-50 model for all cases of training example sizes, a fact that can be attributed mainly to 2 reasons:
The pre-trained ResNet-50 model was originally designed for RGB image recognition (and not for MS one), where its success rate was over (i.e., in the EUROSAT RGB dataset). Adapting it appropriately led to a logical performance drop to , which was to be expected since the problem is of a similar flavor and not exactly the same. In contrast, the comparison-CNN reaches a success rate of up to , indicating that models designed for video processing purposes can scale back well to image processing tasks.
The comparison-CNN model is quite faster than the pre-trained ResNet-50 one, a fact which can be attributed to the number of trainable parameters of each architecture. To that end, in
Table 3 we present the parameters that must be learned by each model.
Of course, as long as the comparison-CNN model was approximately 12 times “lighter” than the ResNet-50 one, the computational time needed for its training was expected to be less, as shown in
Figure 22b.
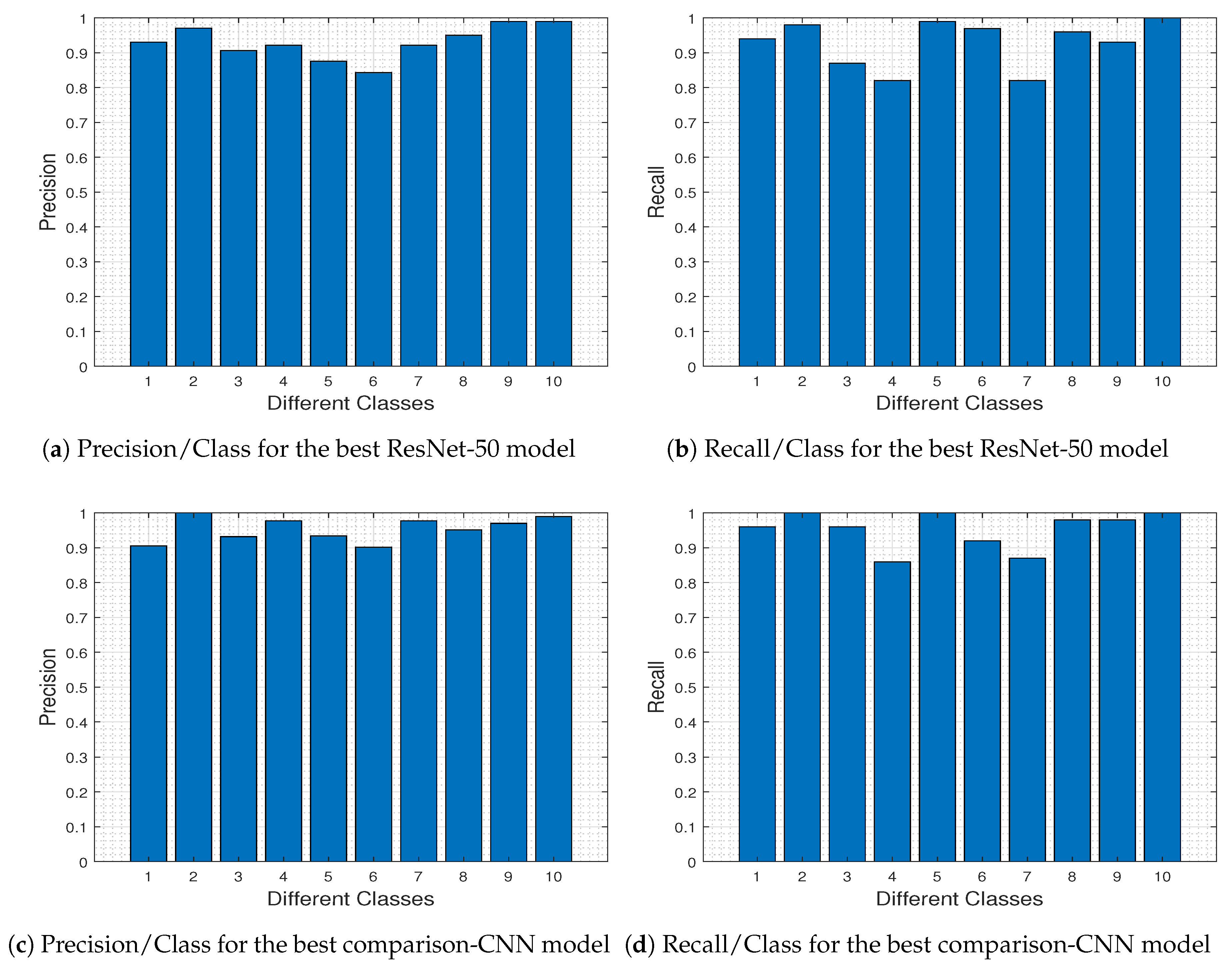
To further investigate the specific differences between the two competing DL models, in
Figure 23 we depict the precision-recall metrics per class obtained by the ResNet-50 model (
Figure 23a,b) and the comparison-CNN model (
Figure 23c,d).
In ML and
Receiver Operating Characteristics (ROC) analysis [
64],
Recall/
Sensitivity/
True Positive Rate refers to the
proportion of Real Positive cases that are correctly Predicted Positive. In contrast,
Precision/
Confidence/
Positive Predicted Value denotes the
proportion of Predicted Positive cases that are correctly Real Positives. Comparing
Figure 23a–c and
Figure 23b–d, we 0 outperforms ResNet-50 for classes 3, 4, and 6 (i.e., Herbaceous Vegetation, Highway and Permanent Crop, respectively). These classes are the most difficult to predict using the pre-trained ResNet-50 model (as dictated from
Figure 8, and discussed therein), and this difficulty explains the fact that the comparison-CNN exhibits an increased accuracy.
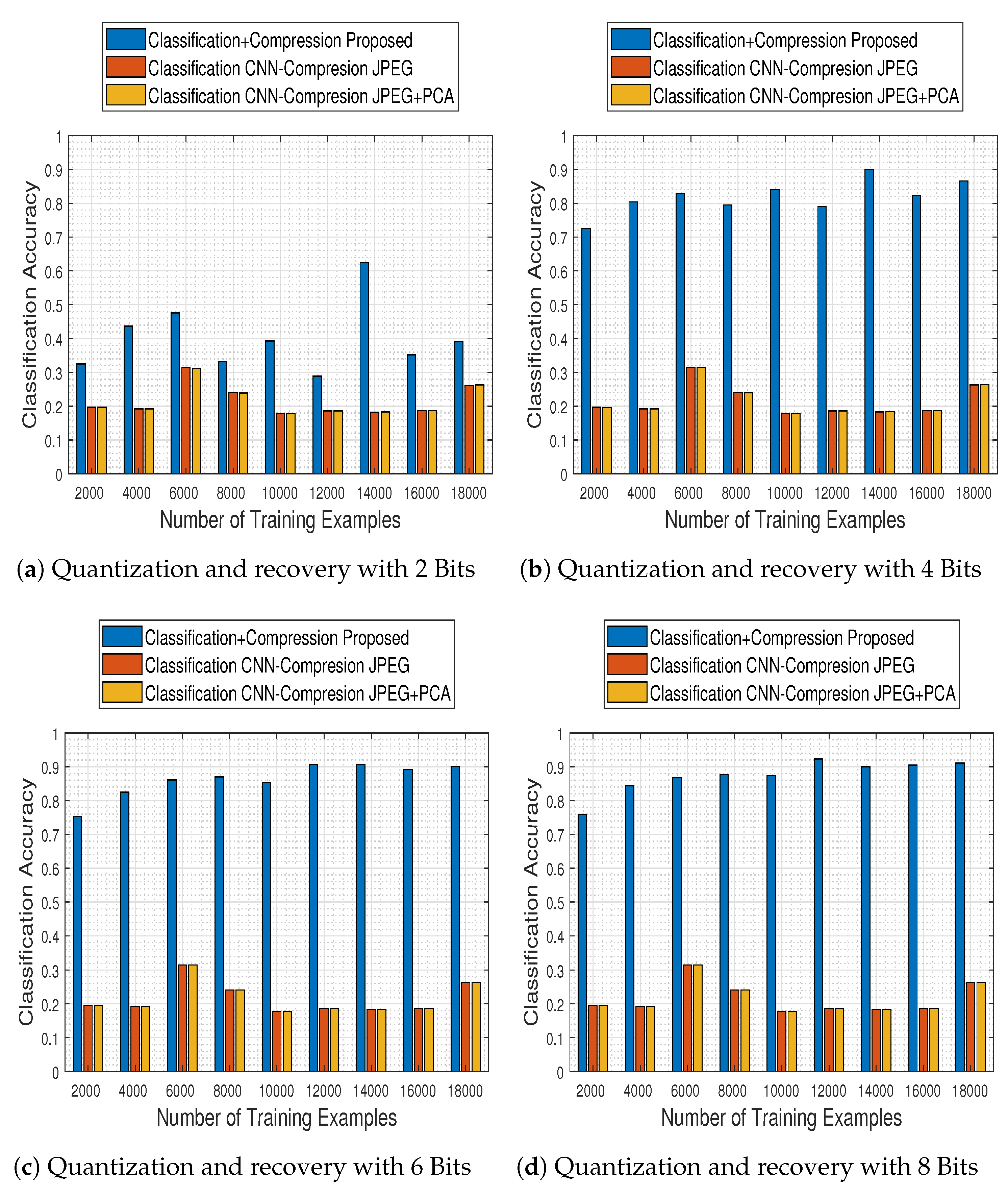
Although the comparison results described above concern the first level of the classification stage, the most important ones concern the second level, in which the trained model is used in conjunction with the compression stage method adopted. To that end, we selected the best model of the comparison-CNN described above (i.e., the one obtained when trained with
training examples and reaching
accuracy) and investigated the effect of compression and recovery via the two schemes mentioned earlier: JPEG2000 and JPEG2000 followed by PCA across the spectral dimension. In
Figure 24 we depict the obtained results for both methods (JPEG stands for JPEG2000), in contrast to those obtained for the compression-free situation portrayed earlier.
The results demonstrate that the alternative quantization schemes have a devastating effect in the system’s performance, which—irrespective to the number of bits to which the images are quantized to—remains nearly fixed to a maximum accuracy of up to .
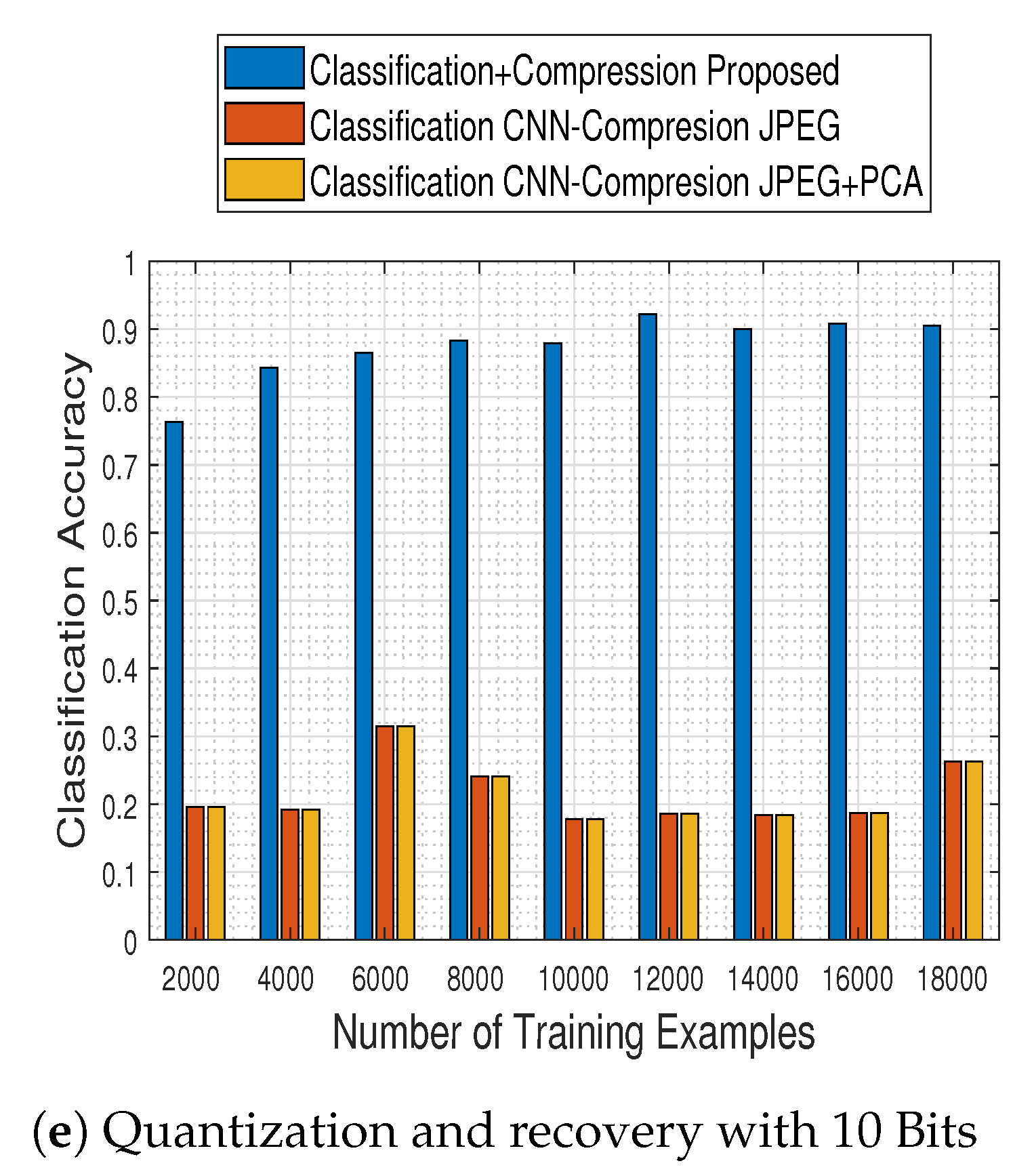
Based on that remark, we subsequently performed the final and most crucial system-to-system comparison, between our proposed one (i.e., ResNet-50 model and tensor recovery) and the competing ones (comparison-CNN and JPEG200 & JPEG200+PCA).
Figure 25 contains classification accuracy results obtained by our system as well as the competing ones, with respect to the number of training examples with which the classification schemes were trained with and the number of bits to which the compression schemes quantized the MS images.
The results clearly imply that the proposed system not only outperforms the competing ones in every examined case, but its performance steadily ameliorates as well. In contrast, its competitors at the same time obtain poor performance results in every case, indicating in that way the efficacy of the proposed approach.

 ,
, 




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}