Detection and Confirmation of Multiple Human Targets Using Pixel-Wise Code Aperture Measurements

 ,
,
Abstract
:1. Introduction
- Although the proposed scheme was not new and had been used by us for some other applications, we were the first ones to apply the PCE measurements to human target detection and confirmation. The SENSIAC database is very challenging in that the human targets are so small and hence difficult to detect and classify. To the best of our knowledge, we are not aware of any papers that deal with human target detection and confirmation by using that database.
- We demonstrated that human target detection and confirmation could indeed be done using coded aperture compressive measurements for long-range low-quality optical and MWIR videos.
2. Methods and Data
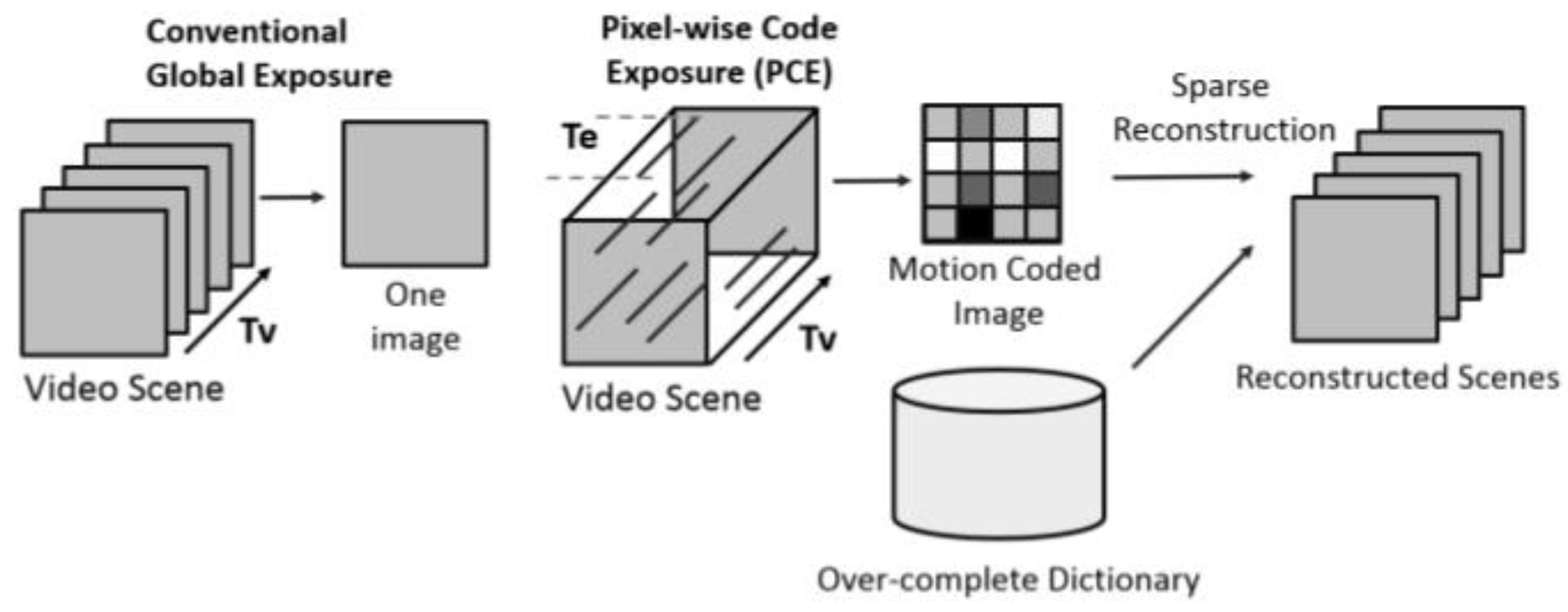
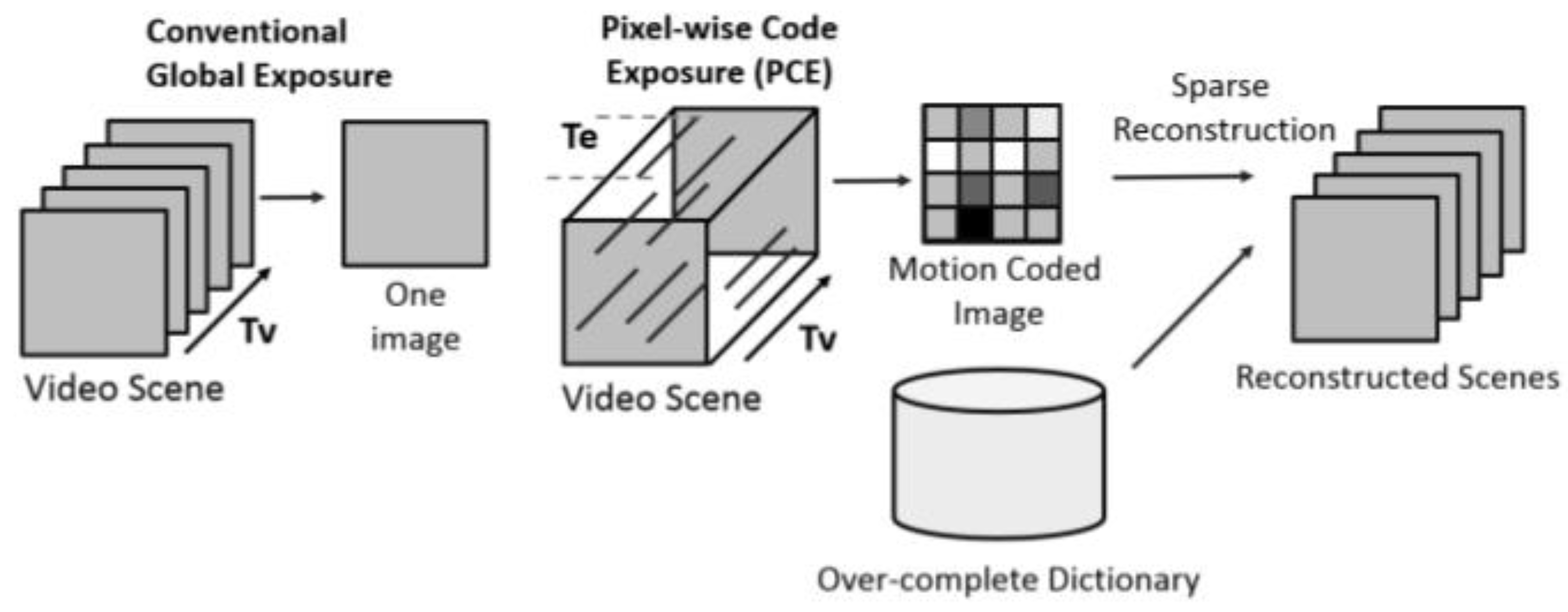
2.1. PCE Imaging and Coded Aperture
2.2. YOLO
2.3. ResNet
2.4. Data
2.5. Performance Metrics
- Center location error (CLE): It is the error between the center of the bounding box and the ground-truth bounding box. Smaller means better. CLE is calculated by measuring the distance between the ground truth center location () and the detected center location (). Mathematically, CLE is given by:
- Distance precision (DP): It is the percentage of frames where the centroids of detected bounding boxes are within 10 pixels of the centroid of ground-truth bounding boxes. Close to 1 or 100% indicates good results.
- Estimates in ground truth (EinGT): It is the percentage of the frames where the centroids of the detected bounding boxes are inside the ground-truth bounding boxes. It depends on the size of the bounding box and is simply a less strict version of the DP metric. Close to 1 or 100% indicates good results.
- Mean area precision (mAP): mAP calculates the amount of area overlap for the estimated and ground truth bounding boxes compared to the total area of the two bounding boxes and returns the result as a value between 0 and 1, with 1 being the perfect overlap. The mAP being used can be computed asAs shown in Equation (3), mAP is calculated by taking the area of intersection of the ground truth bounding box and the estimated bounding box, then dividing that area by the union of those two areas.
- The number of frames with detection: This is the total number of frames that have detection.
3. Detection and Confirmation Results Using PCE Measurements
3.1. Results on Optical Videos
3.1.1. Detection Results
3.1.2. Human Target Confirmation Results
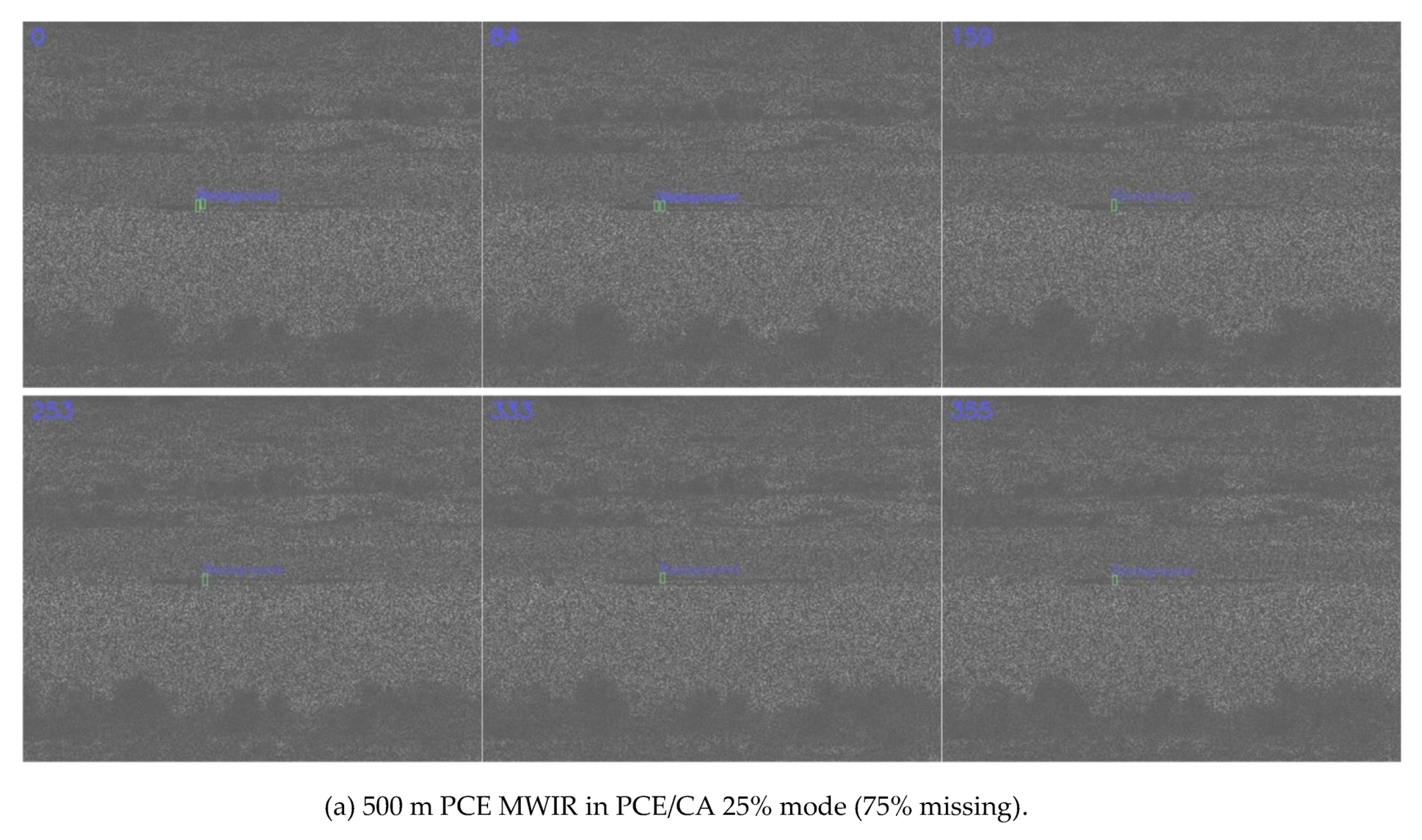
3.2. Results on MWIR Videos
3.2.1. Detection Results
3.2.2. Target Confirmation Results
3.3. Discussion of the Experimental Results
3.3.1. Detection Performance Comparison between Optical and MWIR Imagers
3.3.2. Target Confirmation Performance Comparison between Optical and MWIR Imagers
3.3.3. Target Confirmation Accuracy of ResNet
3.3.4. Comparison with Conventional Reconstruction Methods
3.3.5. Incorporation of Tracking into our Framework
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Candes, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Kwan, C.; Chou, B.; Kwan, L.M. A Comparative Study of Conventional and Deep Learning Target Tracking Algorithms for Low Quality Videos. In 15th International Symposium on Neural Networks; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Tran, T. Compressive object tracking and classification using deep learning for infrared videos. In Proceedings of the SPIE 10995, Pattern Recognition and Tracking (Conference SI120), Baltimore, MD, USA, 13 May 2019. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Tran, T. Target tracking and classification directly in compressive measurement for low quality videos. In Proceedings of the SPIE 10995, Pattern Recognition and Tracking XXX, 1099505, Baltimore, MD, USA, 13 May 2019. [Google Scholar]
- Kwan, C.; Chou, B.; Echavarren, A.; Budavari, B.; Li, J.; Tran, T. Compressive vehicle tracking using deep learning. In Proceedings of the IEEE Ubiquitous Computing, Electronics & Mobile Communication Conference, New York City, NY, USA, 8–10 November 2018. [Google Scholar]
- Kwan, C.; Gribben, D.; Tran, T. Multiple Human Objects Tracking and Classification Directly in Compressive Measurement Domain for Long Range Infrared Videos. In Proceedings of the IEEE Ubiquitous Computing, Electronics & Mobile Communication Conference, New York City, NY, USA, 10 October 2019. [Google Scholar]
- Kwan, C.; Gribben, D.; Tran, T. Tracking and Classification of Multiple Human Objects Directly in Compressive Measurement Domain for Low Quality Optical Videos. In Proceedings of the IEEE Ubiquitous Computing, Electronics & Mobile Communication Conference, New York City, NY, USA, 10 October 2019. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Tran, T. Deep Learning based Target Tracking and Classification Directly in Compressive Measurement for Low Quality Videos. Signal Image Process. Int. J. (SIPIJ) 2019, 10, 9–29. [Google Scholar]
- Zhang, J.; Xiong, T.; Tran, T.; Chin, S.; Etienne-Cummings, R. Compact all-CMOS spatio-temporal compressive sensing video camera with pixel-wise coded exposure. Opt. Express. 2016, 24, 9013–9024. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhang, Y. Alternating direction algorithms for l1-problems in compressive sensing. SIAM J. Sci. Comput. 2011, 33, 250–278. [Google Scholar] [CrossRef]
- Tropp, J.A. Greed is good: Algorithmic results for sparse approximation. IEEE Trans. Inf. Theory 2004, 50, 2231–2242. [Google Scholar] [CrossRef] [Green Version]
- Dao, M.; Kwan, C.; Koperski, K.; Marchisio, G. A joint sparsity approach to tunnel activity monitoring using high resolution satellite images. In Proceedings of the IEEE Ubiquitous Computing, Electronics & Mobile Communication Conference, New York, NY, USA, 19–21 October 2017; pp. 322–328. [Google Scholar]
- Zhou, J.; Ayhan, B.; Kwan, C.; Tran, T. ATR performance improvement using images with corrupted or missing pixels. In Pattern Recognition and Tracking XXIX; SPIE: Bellingham, WA, USA, 2018; Volume 106490, p. 106490E. [Google Scholar]
- Applied Research LLC. Phase 1 Final Report; Applied Research LLC: Rockville, MD, USA, 2016. [Google Scholar]
- Yang, M.H.; Zhang, K.; Zhang, L. Real-Time compressive tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Lohit, S.; Kulkarni, K.; Turaga, P.K. Direct inference on compressive measurements using convolutional neural networks. In Proceedings of the 2016 IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 1913–1917. [Google Scholar]
- Adler, A.; Elad, M.; Zibulevsky, M. Compressed Learning: A Deep Neural Network Approach. arXiv 2016, arXiv:1610.09615v1 [cs.CV]. [Google Scholar]
- Xu, Y.; Kelly, K.F. Compressed domain image classification using a multi-rate neural network. arXiv 2019, arXiv:1901.09983 [cs.CV]. [Google Scholar]
- Wang, Z.W.; Vineet, V.; Pittaluga, F.; Sinha, S.N.; Cossairt, O.; Kang, S.B. Privacy-Preserving Action Recognition Using Coded Aperture Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Vargas, H.; Fonseca, Y.; Arguello, H. Object Detection on Compressive Measurements using Correlation Filters and Sparse Representation. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), Eternal City, Italy, 3–7 September 2018; pp. 1960–1964. [Google Scholar]
- Değerli, A.; Aslan, S.; Yamac, M.; Sankur, B.; Gabbouj, M. Compressively Sensed Image Recognition. In Proceedings of the 7th European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 26–28 November 2018; pp. 1–6. [Google Scholar]
- Latorre-Carmona, P.; Traver, V.J.; Sánchez, J.S.; Tajahuerce, E. Online reconstruction-free single-pixel image classification. Image Vis. Comput. 2019, 86, 28–37. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Target tracking and classification directly using compressive sensing camera for SWIR videos. J. Signal Image Video Process. 2019, 13, 1629–1637. [Google Scholar] [CrossRef]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Target tracking and classification using compressive measurements of MWIR and LWIR coded aperture cameras. J. Signal Inf. Process. 2019, 10, 73–95. [Google Scholar] [CrossRef] [Green Version]
- Kwan, C.; Chou, B.; Yang, J.; Tran, T. Deep Learning based Target Tracking and Classification for Infrared Videos Using Compressive Measurements. J. Signal Inf. Process. 2019, 10, 4, 167–199. [Google Scholar]
- Kwan, C.; Chou, B.; Yang, J.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Deep Learning based Target Tracking and Classification for Low Quality Videos Using Coded Aperture Camera. Sensors 2019, 19, 3702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV 2016. Lecture Notes in Computer Science, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- SENSIAC Dataset. Available online: https://www.news.gatech.edu/2006/03/06/sensiac-center-helps-advance-military-sensing (accessed on 27 May 2020).
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking, computer vision and pattern recognition. IEEE Comput. Soc. Conf. 1999, 2, 2246–2252. [Google Scholar]
- Ullah, M.; Mohammed, A.K.; Cheikh, F.A.; Wang, Z. A hierarchical feature model for multi-target tracking. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2612–2616. [Google Scholar]
- Ullah, M.; Cheikh, F.A. A Directed Sparse Graphical Model for Multi-Target Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1816–1823. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Zhao, X.; Kim, T. Multiple Object Tracking: A Literature Review. arXiv: Computer Vision and Pattern Recognition. arXiv 2014, arXiv:1409.7618. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PCE/CA Full (0% Missing) | |||||
|---|---|---|---|---|---|
| CLE | DP@10 | EinGT | mAP | % Detection | |
| 500 m | 3.03 | 1.00 | 0.98 | 0.38 | 95.01 |
| 1000 m | 1.45 | 1.00 | 1.00 | 0.69 | 97.95 |
| 1500 m | 1.78 | 1.00 | 0.94 | 0.49 | 95.81 |
| PCE/CA 50% (50% Missing) | |||||
| CLE | DP@10 | EinGT | mAP | % Detection | |
| 500 m | 4.94 | 0.98 | 0.76 | 0.45 | 94.39 |
| 1000 m | 11.02 | 0.83 | 0.55 | 0.38 | 96.52 |
| 1500 m | 10.57 | 0.64 | 0.22 | 0.14 | 66.31 |
| PCE/CA 25% (75% Missing) | |||||
| CLE | DP@10 | EinGT | mAP | % Detection | |
| 500 m | 18.47 | 0.89 | 0.51 | 0.36 | 96.88 |
| 1000 m | 18.13 | 0.63 | 0.14 | 0.15 | 99.38 |
| 1500 m | 20.14 | 0.42 | 0.12 | 0.07 | 69.43 |
| PCE/CA Full (0 % Missing) | PCE/CA 50% (50% Missing) | |||
|---|---|---|---|---|
| Range: 500 | GT: Human | GT: Background | GT: Human | GT: Background |
| Classified: Human | 0% | 100% | 87% | 91% |
| Classified: Background | 100% | 0% | 13% | 9% |
| Range: 1000 | GT: Human | GT: Background | GT: Human | GT: Background |
| Classified: Human | 50% | 50% | 95.02% | 94.66% |
| Classified: Background | 50% | 50% | 4.98% | 5.34% |
| Range: 1500 | GT: Human | GT: Background | GT: Human | GT: Background |
| Classified: Human | 87% | 98% | 99.88% | 99.56% |
| Classified: Background | 13% | 2% | 0.12% | 0.44% |
| PCE/CA Full (0% Missing) | |||||
|---|---|---|---|---|---|
| CLE | DP@10 | EinGT | mAP | % Detection | |
| 500 m | 2.48 | 1.00 | 0.96 | 0.52 | 85.98 |
| 1000 m | 2.25 | 1.00 | 0.80 | 0.52 | 96.84 |
| 1500 m | 2.79 | 1.00 | 0.39 | 0.22 | 99.72 |
| PCE/CA 50% (50% Missing) | |||||
| CLE | DP@10 | EinGT | mAP | % Detection | |
| 500 m | 3.70 | 0.98 | 0.92 | 0.44 | 69.92 |
| 1000 m | 7.42 | 0.85 | 0.64 | 0.38 | 94.99 |
| 1500 m | 11.48 | 0.71 | 0.18 | 0.13 | 77.44 |
| PCE/CA 25% (75% Missing) | |||||
| CLE | DP@10 | EinGT | mAP | % Detection | |
| 500 m | 10.41 | 0.95 | 0.91 | 0.38 | 58.77 |
| 1000 m | 13.43 | 0.66 | 0.43 | 0.25 | 79.11 |
| 1500 m | 10.79 | 0.49 | 0.03 | 0.05 | 46.61 |
| PCE/CA Full (0% Missing) | PCE/CA 50% (50% Missing) | |||
|---|---|---|---|---|
| Range: 500 | GT: Human | GT: Background | GT: Human | GT: Background |
| Classified: Human | 94.32% | 93.43% | 99.11% | 98.17% |
| Classified: Background | 5.68% | 6.57% | 0.89% | 1.83% |
| Range: 1000 | GT: Human | GT: Background | GT: Human | GT: Background |
| Classified: Human | 95.54% | 93.54% | 99.85% | 100% |
| Classified: Background | 4.46% | 6.46% | 0.15% | 0% |
| Range: 1500 | GT: Human | GT: Background | GT: Human | GT: Background |
| Classified: Human | 92.26% | 92.06% | 100% | 100% |
| Classified: Background | 7.74% | 7.94% | 0 | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwan, C.; Gribben, D.; Rangamani, A.; Tran, T.; Zhang, J.; Etienne-Cummings, R. Detection and Confirmation of Multiple Human Targets Using Pixel-Wise Code Aperture Measurements. J. Imaging 2020, 6, 40. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6060040
Kwan C, Gribben D, Rangamani A, Tran T, Zhang J, Etienne-Cummings R. Detection and Confirmation of Multiple Human Targets Using Pixel-Wise Code Aperture Measurements. Journal of Imaging. 2020; 6(6):40. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6060040
Chicago/Turabian StyleKwan, Chiman, David Gribben, Akshay Rangamani, Trac Tran, Jack Zhang, and Ralph Etienne-Cummings. 2020. "Detection and Confirmation of Multiple Human Targets Using Pixel-Wise Code Aperture Measurements" Journal of Imaging 6, no. 6: 40. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6060040