MH-MetroNet—A Multi-Head CNN for Passenger-Crowd Attendance Estimation

 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
- the proposed MH-MetroNet innovative architecture that introduction of multi-head layers for density crowd estimation
- MH-MetroNet outperforms the leading state of the art techniques on established publicly available datasets
- the introduction of crowd density estimation in subway cars where the best performing architecture is MH-MetroNet which outperforms the latest state-of-the-art architectures where publicly code is available.
2. Problem Formulation
Training Strategy
3. Network Architecture
3.1. Backbone
3.1.1. DenseNet
3.1.2. ResNet
3.1.3. SeNet
3.1.4. EfficientNet
3.2. Head Layers
4. Experimental Results
4.1. Datasets
4.2. UCF_CC_50 Dataset
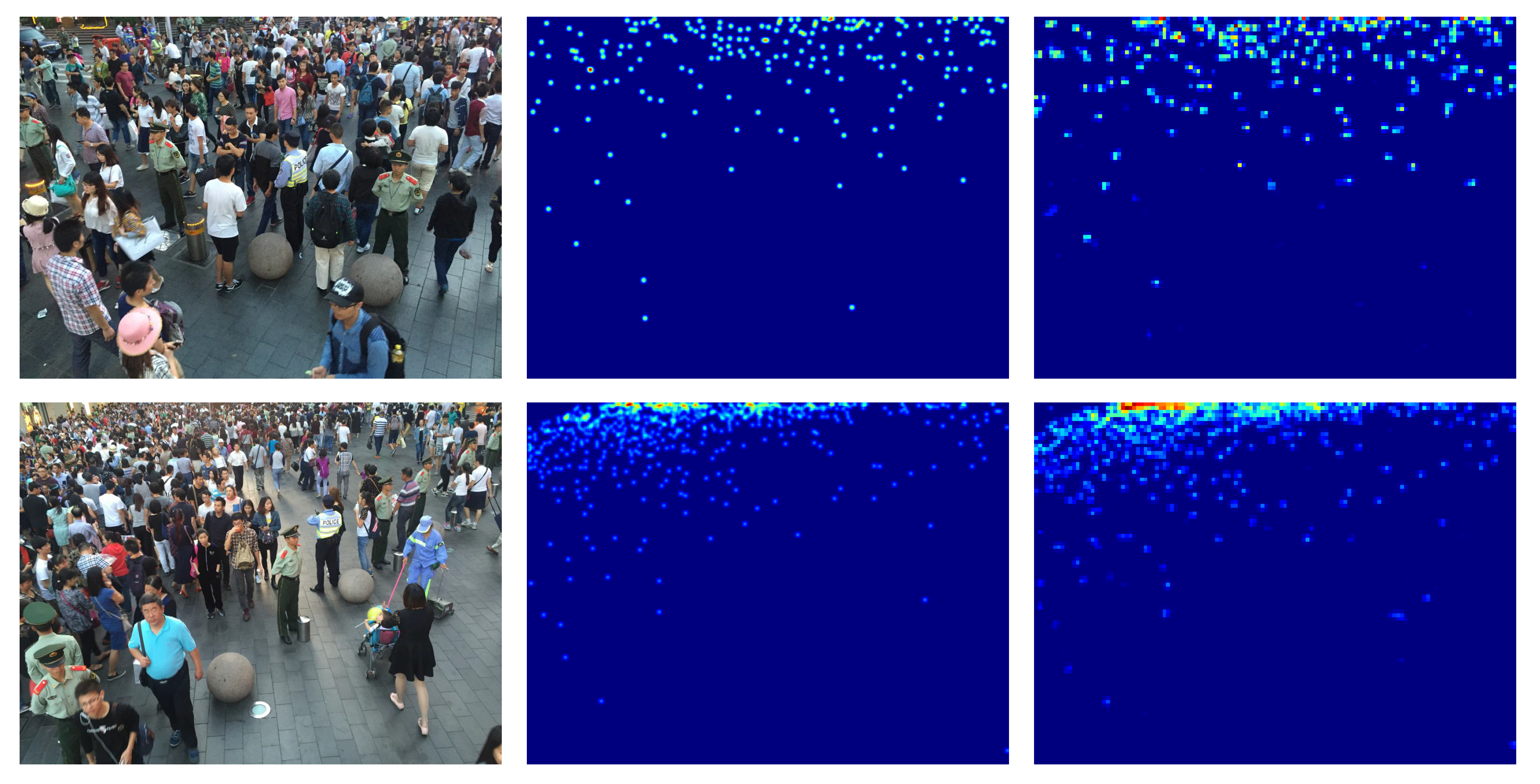
4.3. ShanghaiTech Dataset
4.3.1. ShanghaiTech Part A Dataset
4.3.2. ShanghaiTech Part B Dataset
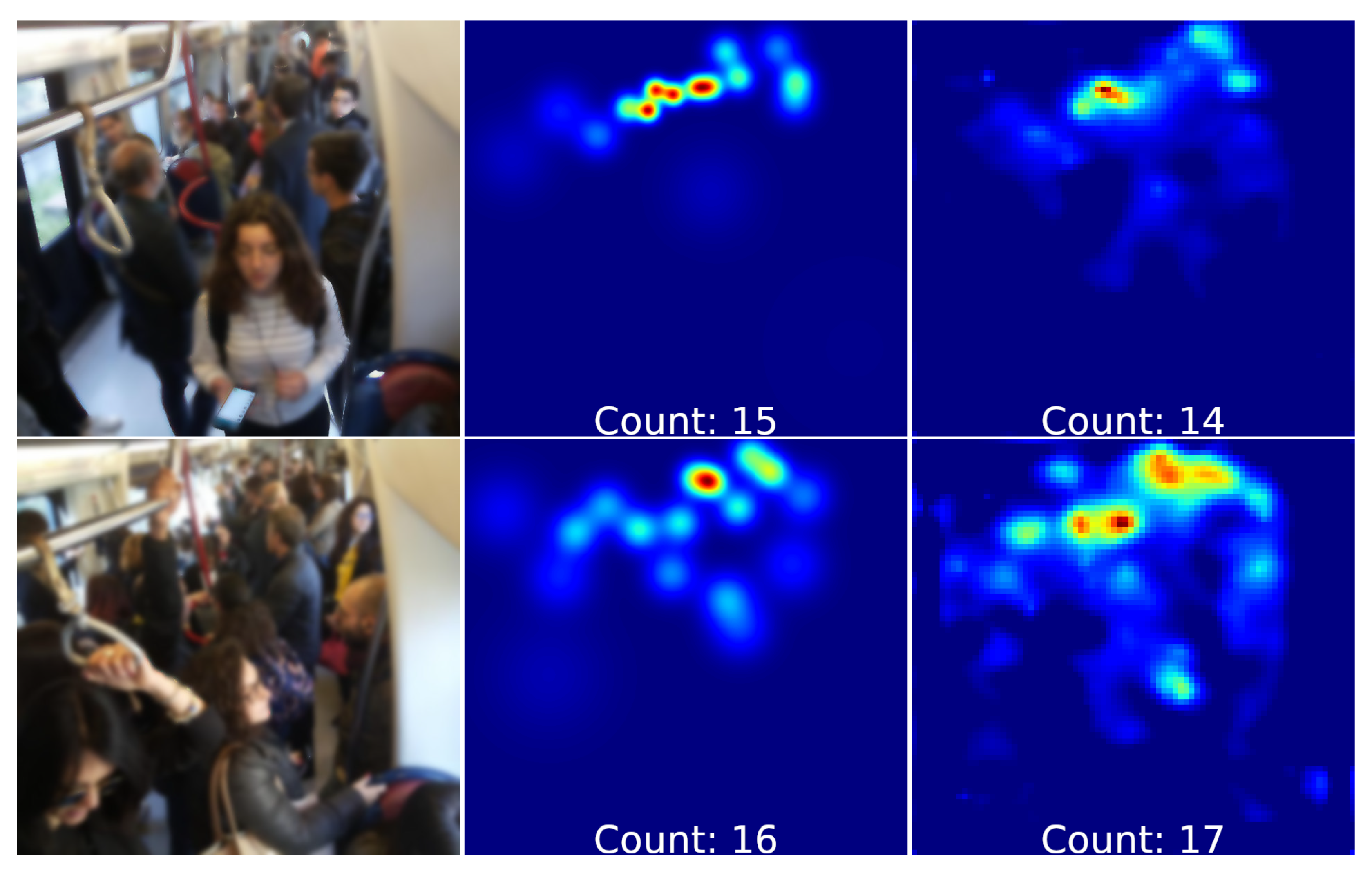
4.4. Subway Cars Dataset
4.5. Metrics
4.5.1. Mean Absolute Error
4.5.2. Mean Squared Error
4.6. Results on UCF_CC_50 Dataset
4.7. Results on ShanghaiTech Part A and B Datasets
4.8. Results Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ullah, H.; Altamimi, A.B.; Uzair, M.; Ullah, M. Anomalous entities detection and localization in pedestrian flows. Neurocomputing 2018, 290, 74–86. [Google Scholar] [CrossRef]
- Qi, W.; Su, H.; Aliverti, A. A Smartphone-based Adaptive Recognition and Real-time Monitoring System for Human Activities. IEEE Trans. Hum. Mach. Syst. 2020. [Google Scholar] [CrossRef]
- Su, H.; Qi, W.; Yang, C.; Sandoval, J.; Ferrigno, G.; Momi, E.D. Deep Neural Network Approach in Robot Tool Dynamics Identification for Bilateral Teleoperation. IEEE Robot. Autom. Lett. 2020, 5, 2943–2949. [Google Scholar] [CrossRef]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE PAMI 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE CVPR 2005, San Diego, CA, USA, 20–25 June 2005; Volume 2. [Google Scholar]
- Wu, B.; Nevatia, R. Detection of multiple, partially occluded humans in a single image by Bayesian combination of edgelet part detectors. In Proceedings of the IEEE ICCV 2005, Beijing, China, 17–21 October 2005; Volume 1, pp. 90–97. [Google Scholar] [CrossRef]
- Sabzmeydani, P.; Mori, G. Detecting Pedestrians by Learning Shapelet Features. In Proceedings of the 2007 IEEE CVPR, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE TPAMI 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Chan, A.B.; Vasconcelos, N. Bayesian Poisson regression for crowd counting. In Proceedings of the 2009 IEEE ICCV, Kyoto, Japan, 29 September–2 October 2009; pp. 545–551. [Google Scholar] [CrossRef]
- Chan, A.B.; Liang, Z.S.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE CVPR, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature Mining for Localised Crowd Counting. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; BMVA Press: Durham, UK, 2012; pp. 21.1–21.11. [Google Scholar] [CrossRef] [Green Version]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source Multi-scale Counting in Extremely Dense Crowd Images. In Proceedings of the 2013 IEEE CVPR, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar]
- Lempitsky, V.; Zisserman, A. Learning to count objects in images. In Proceedings of the NIPS 2010, Vancouver, BC, Canada, 6–9 December 2010. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Boominathan, L.; Kruthiventi, S.S.S.; Babu, R.V. CrowdNet: A Deep Convolutional Network for Dense Crowd Counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Oñoro-Rubio, D.; López-Sastre, R.J. Towards Perspective-Free Object Counting with Deep Learning. In Proceedings of the ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 615–629. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the 2017 IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. CNN-Based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the 14th IEEE AVSS, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, L.; Shi, M.; Chen, Q. Crowd Counting via Scale-Adaptive Convolutional Neural Network. In Proceedings of the 2018 IEEE WACV, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1113–1121. [Google Scholar] [CrossRef] [Green Version]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd Counting via Adversarial Cross-Scale Consistency Pursuit. In Proceedings of the 2018 IEEE/CVF CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5245–5254. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the 2018 IEEE/CVF CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar] [CrossRef] [Green Version]
- Khan, S.D.; Ullah, H.; Uzair, M.; Ullah, M.; Ullah, R.; Cheikh, F.A. Disam: Density Independent and Scale Aware Model for Crowd Counting and Localization. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4474–4478. [Google Scholar]
- Tian, Y.; Lei, Y.; Zhang, J.; Wang, J.Z. PaDNet: Pan-Density Crowd Counting. IEEE Trans. Image Process. 2020, 29, 2714–2727. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sindagi, V.A.; Yasarla, R.; Patel, V.M. Pushing the Frontiers of Unconstrained Crowd Counting: New Dataset and Benchmark Method. In Proceedings of the IEEE ICCV 2019, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wan, J.; Chan, A. Adaptive Density Map Generation for Crowd Counting. In Proceedings of the IEEE ICCV 2019, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, L.; Qiu, Z.; Li, G.; Liu, S.; Ouyang, W.; Lin, L. Crowd Counting with Deep Structured Scale Integration Network. In Proceedings of the IEEE ICCV 2019, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Yan, Z.; Yuan, Y.; Zuo, W.; Tan, X.; Wang, Y.; Wen, S.; Ding, E. Perspective-Guided Convolution Networks for Crowd Counting. In Proceedings of the 2019 IEEE ICCV, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, X.; Bin, Y.; Sang, N.; Gao, C. Scale Pyramid Network for Crowd Counting. In Proceedings of the 2019 IEEE WACV, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1941–1950. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 10691–10700. [Google Scholar]








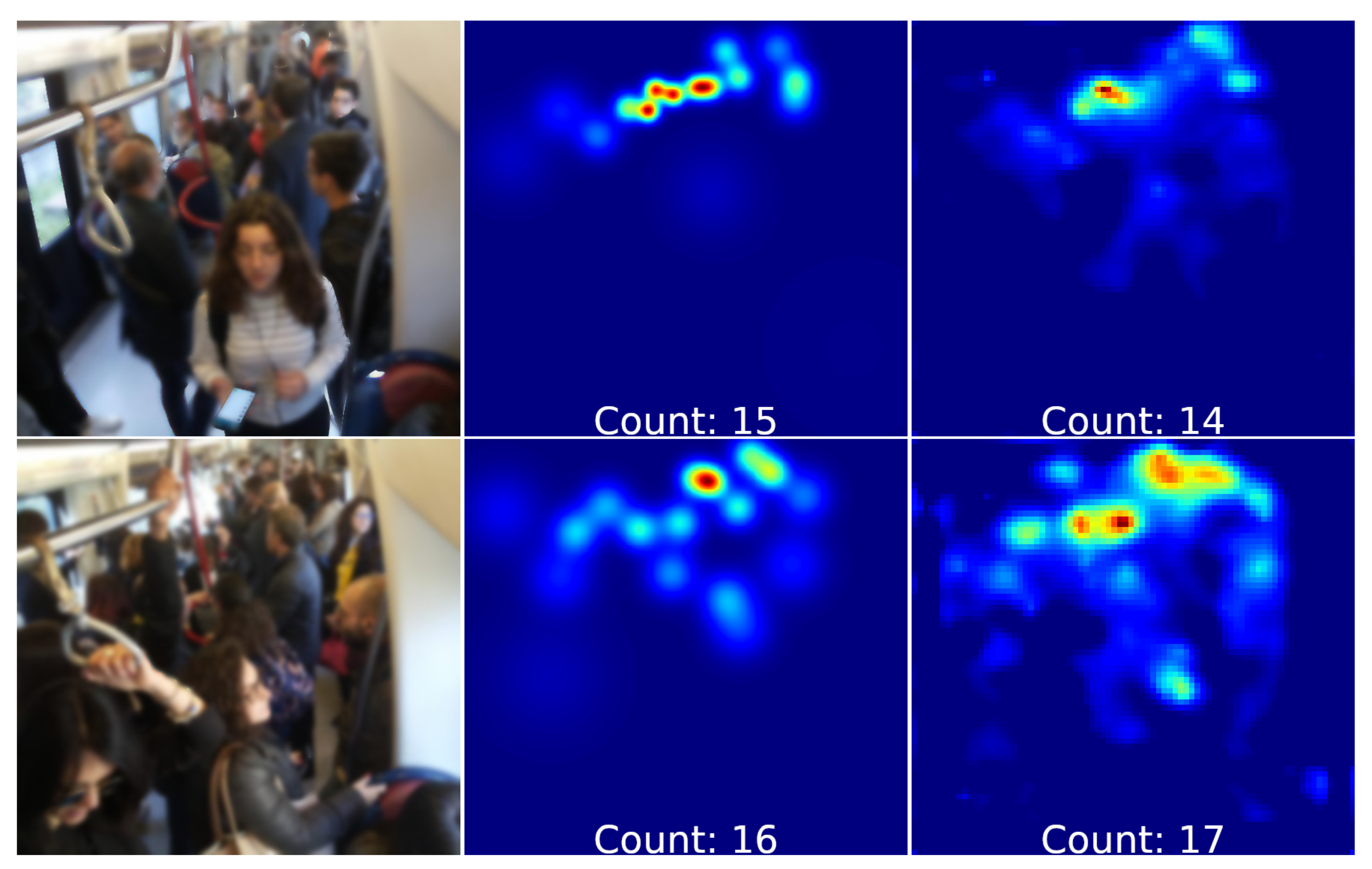

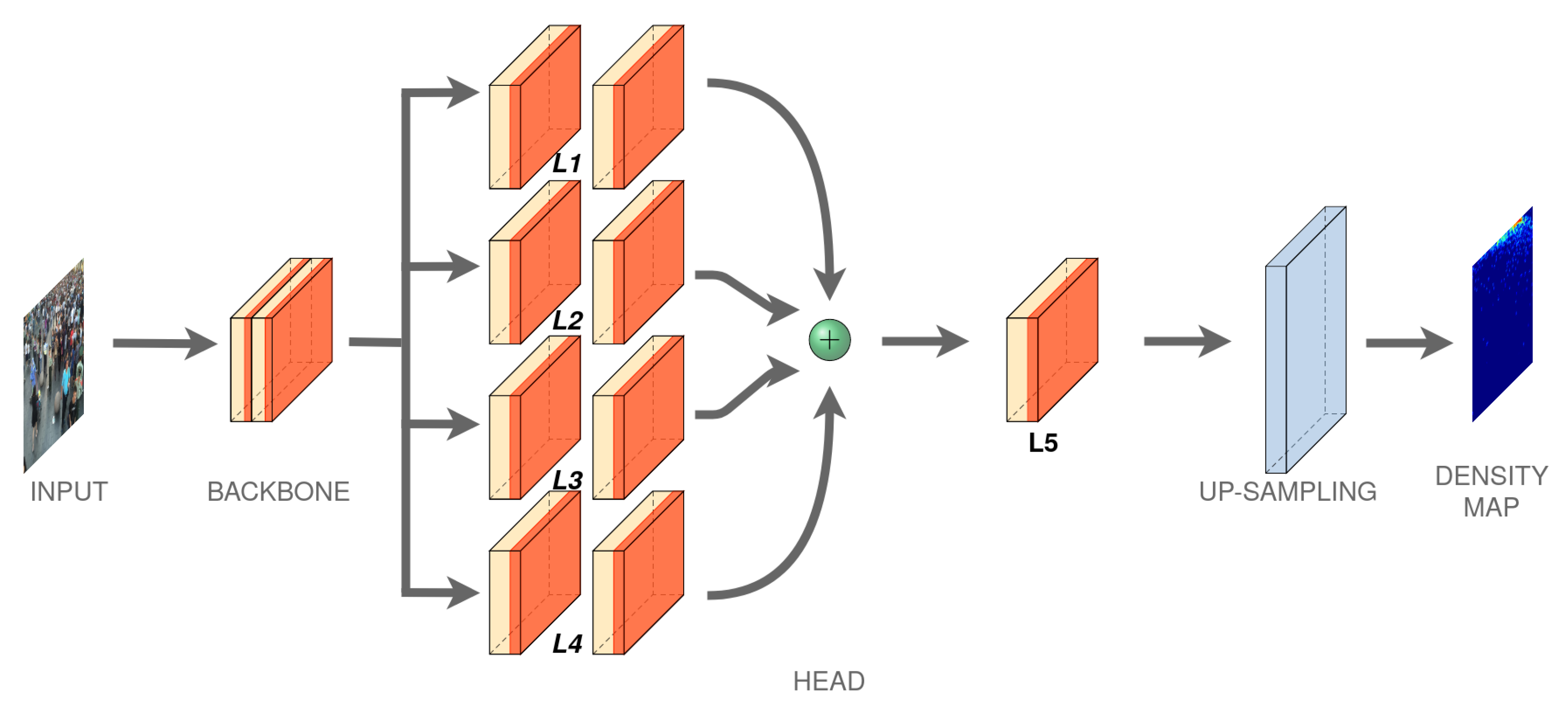{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Multi-Head Blocks Config | ||
|---|---|---|
| conv3-256 | conv3-32 | |
| conv3-64 | conv3-32 | |
| conv5-256 | conv5-32 | |
| conv5-64 | conv5-32 | |
| conv1-1 | ||
| Backbone | MAE | MSE |
|---|---|---|
| DenseNet-121 [31] | 187.74 | 270.31 |
| ResNet-152 [32] | 170.0 | 221.95 |
| SeNet-154 [33] | 181.24 | 257.21 |
| EfficientNet-b5 [34] | 277.48 | 314.73 |
| Part A | Part B | |||
|---|---|---|---|---|
| Backbone | MAE | MSE | MAE | MSE |
| DenseNet-121 [31] | 82.62 | 133.75 | 8.66 | 13.85 |
| ResNet-152 [32] | 67.52 | 113.47 | 7.93 | 13.0 |
| SeNet-154 [33] | 181.24 | 257.21 | 9.46 | 14.57 |
| EfficientNet-b5 [34] | 115.62 | 179.53 | 14.39 | 23.96 |
| Method | MAE | MSE |
|---|---|---|
| MCNN [14] | 377.6 | 509.1 |
| CrowdNet [15] | 452.5 | - |
| Hydra CNN [17] | 333.73 | 425.26 |
| Switching CNN [18] | 318.1 | 439.2 |
| CMTL [19] | 322.8 | 397.9 |
| SANet [20] | 258.4 | 334.9 |
| SaCNN [21] | 314.9 | 424.8 |
| ACSCP [22] | 291.0 | 404.6 |
| CSRNet [23] | 266.1 | 397.5 |
| PADNet [25] | 185.8 | 278.3 |
| DSSINet [28] | 216.9 | 302.4 |
| SPN [30] | 259.2 | 335.9 |
| Our | 170.0 | 221.95 |
| Method | Part A | Part B | ||
|---|---|---|---|---|
| MAE | MSE | MAE | MSE | |
| MCNN [14] | 110.2 | 173.2 | 26.4 | 41.3 |
| Switching CNN [18] | 90.4 | 135.0 | 21.6 | 33.4 |
| CMTL [19] | 101.3 | 152.4 | 20.0 | 31.1 |
| SANet [20] | 67.0 | 104.5 | 8.4 | 13.6 |
| SaCNN [21] | 86.8 | 139.2 | 16.2 | 25.8 |
| ACSCP [22] | 75.7 | 102.7 | 17.2 | 27.4 |
| CSRNet [23] | 68.2 | 115.0 | 10.6 | 16.0 |
| PADNet [25] | 59.2 | 98.1 | 8.1 | 12.2 |
| DSSINet [28] | 60.63 | 96.04 | 6.85 | 10.34 |
| PGCNet [29] | 57.0 | 86.0 | - | - |
| SPN [30] | 61.7 | 99.5 | 9.4 | 14.4 |
| Our | 67.52 | 113.47 | 7.93 | 13.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazzeo, P.L.; Contino, R.; Spagnolo, P.; Distante, C.; Stella, E.; Nitti, M.; Renò, V. MH-MetroNet—A Multi-Head CNN for Passenger-Crowd Attendance Estimation. J. Imaging 2020, 6, 62. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6070062
Mazzeo PL, Contino R, Spagnolo P, Distante C, Stella E, Nitti M, Renò V. MH-MetroNet—A Multi-Head CNN for Passenger-Crowd Attendance Estimation. Journal of Imaging. 2020; 6(7):62. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6070062
Chicago/Turabian StyleMazzeo, Pier Luigi, Riccardo Contino, Paolo Spagnolo, Cosimo Distante, Ettore Stella, Massimiliano Nitti, and Vito Renò. 2020. "MH-MetroNet—A Multi-Head CNN for Passenger-Crowd Attendance Estimation" Journal of Imaging 6, no. 7: 62. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging6070062