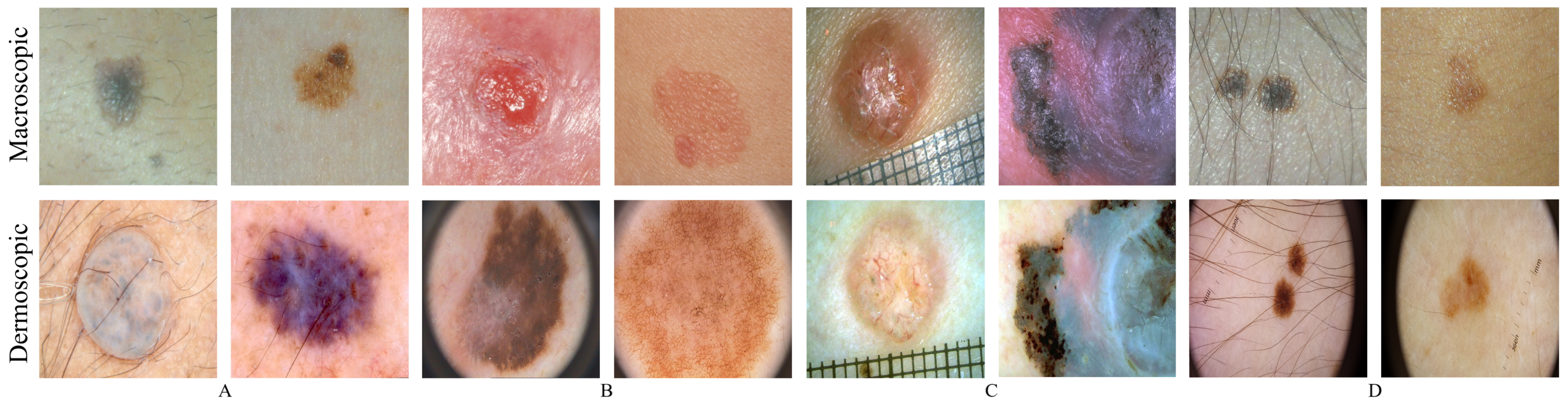
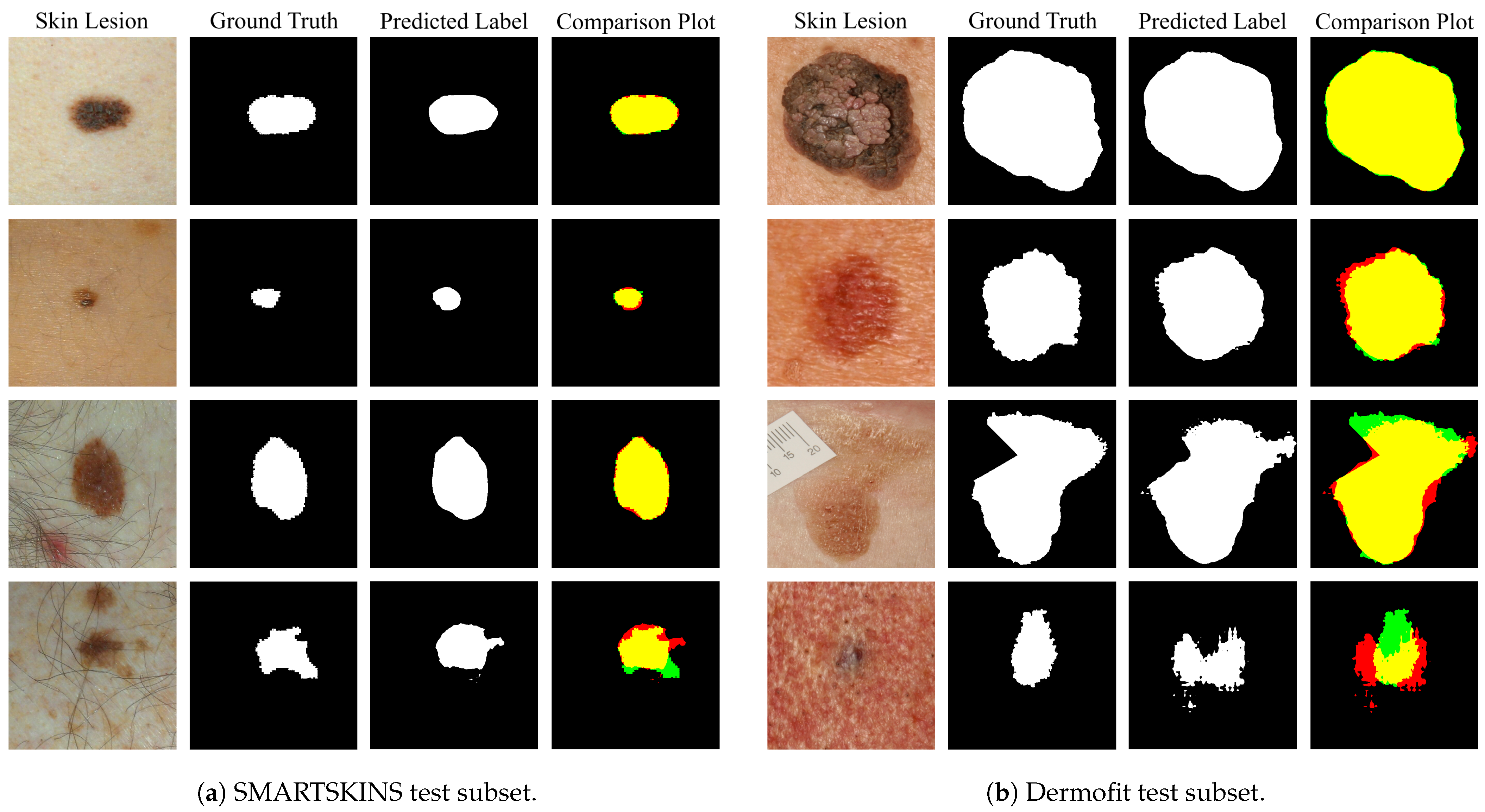
4.1.1. Visual Inspection
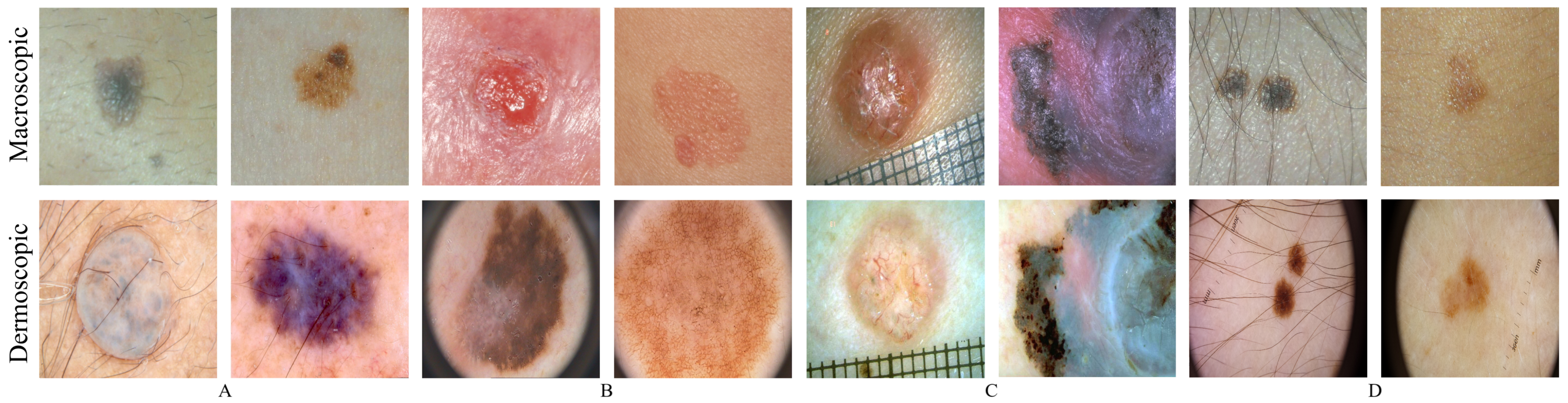
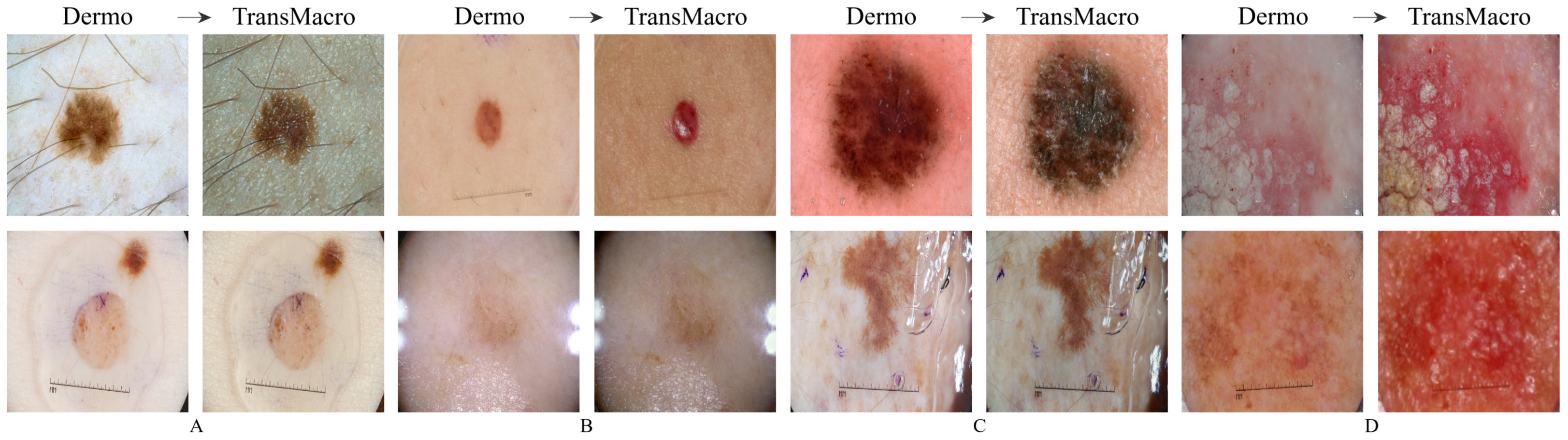
A visual assessment was performed to evaluate the outputs’ realism, by identifying the loss or preservation of some dermoscopic structures. The datasets that had both dermoscopic and macroscopic for the same skin lesion were used, namely the EDRA and SMARTSKINS 2014/2015. The same analysis was carried out with images from the ISIC and PH2 test subsets; these images were not used during the training phase of the CycleGAN.
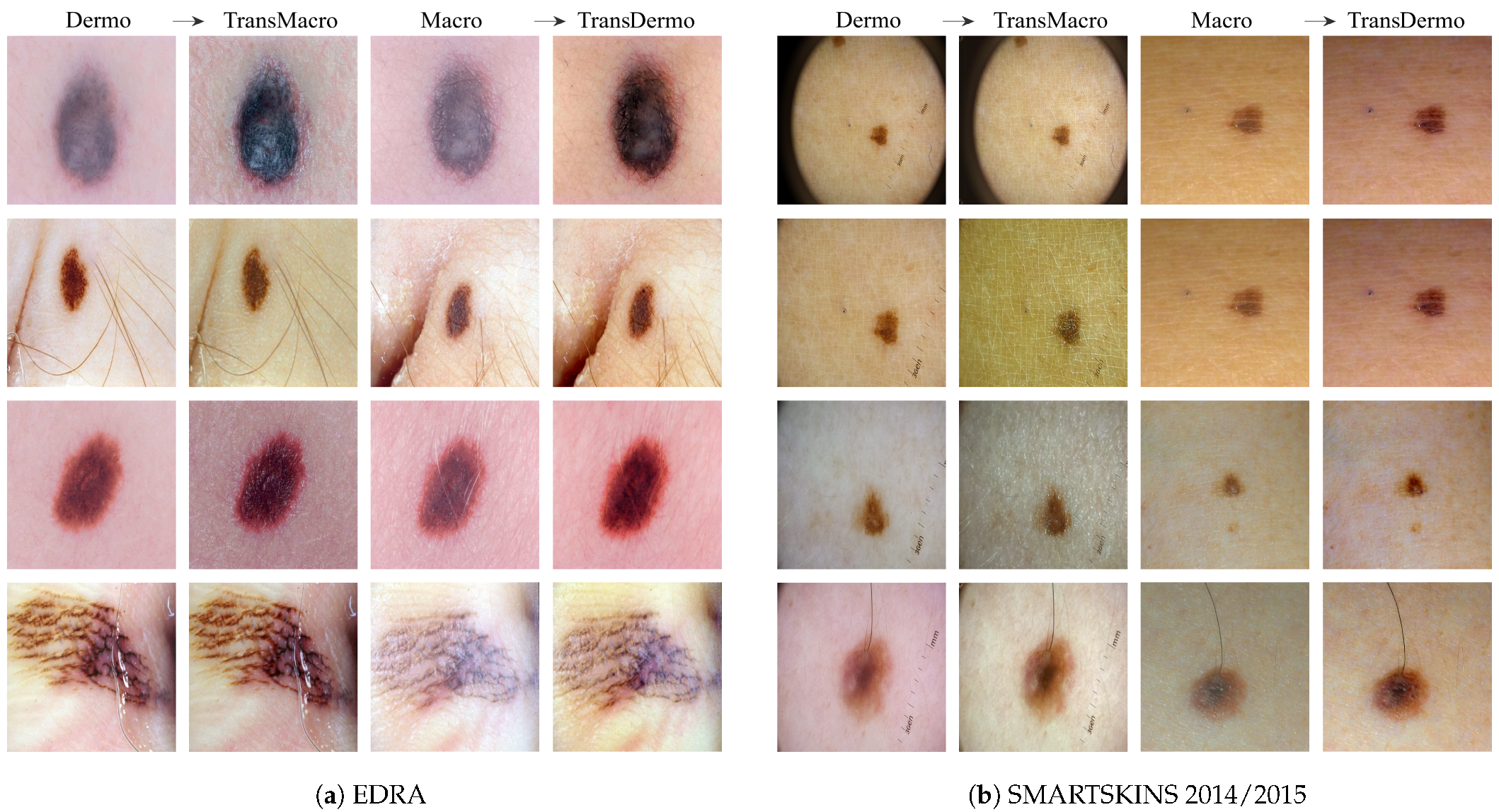
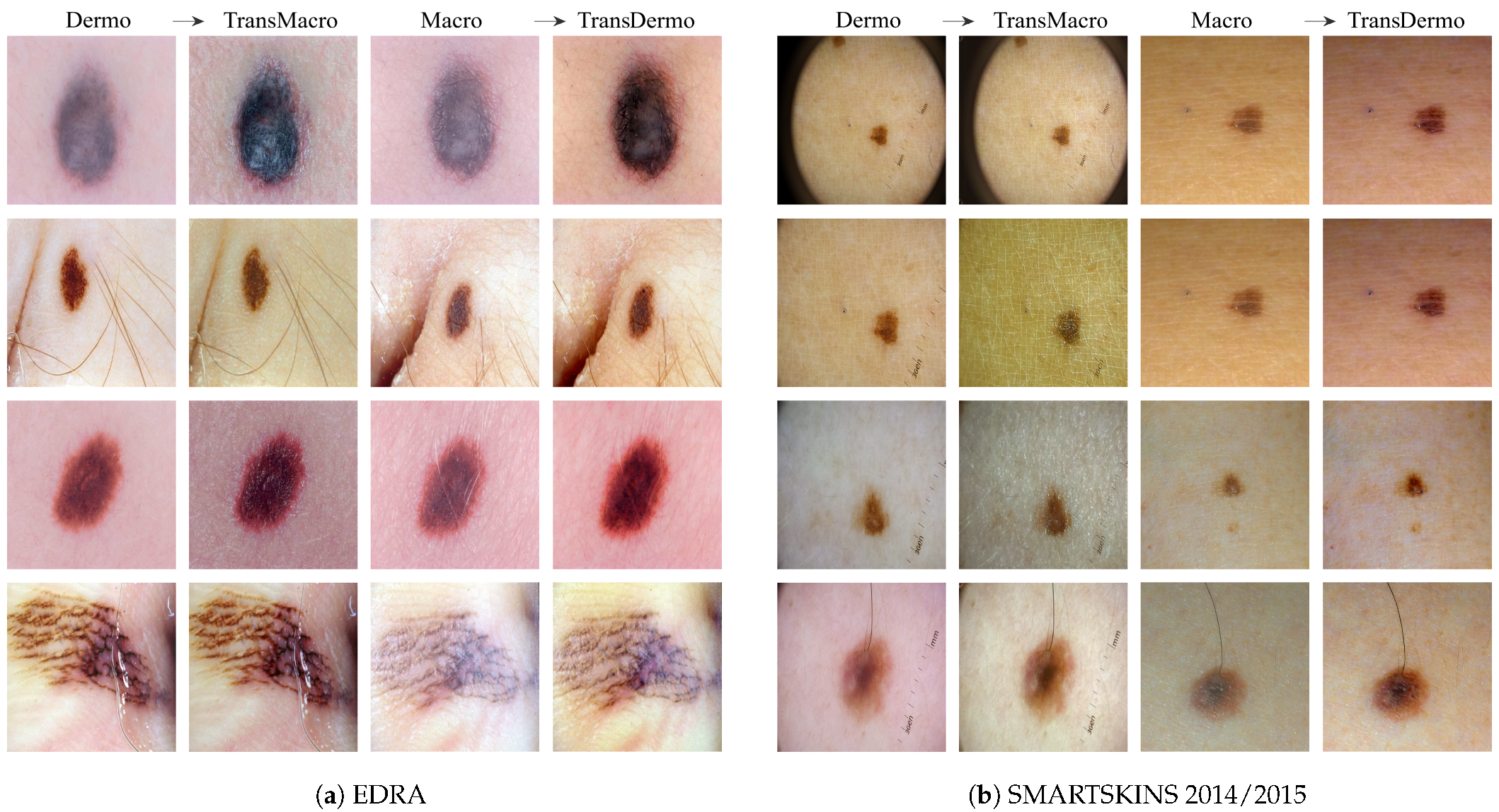
EDRAFigure 3a shows the results obtained from the trained CycleGAN in the test subset of the EDRA dataset—It is possible to compare the macroscopic image to the dermoscopic image translated into the macroscopic domain (TransMacro) and the macroscopic image translated into the dermoscopic domain (TransDermo). In the case of the dermoscopic to macroscopic translation, we can observe that the model was able to generate plausible macroscopic images from dermoscopic images. In particular, several successful transformations unique to the macroscopic domain were obtained, such as: (i) The generation of depth in the TransMacro images, that is, lesion images with nodular aspect from flat dermoscopic images, shown in
Figure 3a (row 1); (ii) The expected appearance of surface glare and change of skin tonality due to the absence of polarized light in macroscopic images, which can be seen in
Figure 3a (rows 1, 2, and 3); and (iii) The loss of dermoscopic characteristics such as specific pigmentations or diffuse borders, as illustrated in
Figure 3a (rows 1 and 2). It should be noted that failure cases occur when there is the presence of gel or ruler markings and round black borders. These three characteristics never appear in macroscopic images, so, understandably, the model could not learn how to address these artefacts. Where there is gel in the lesion, the model only performed slight modifications to the input, as shown in
Figure 3a row 4.
However, the inverse transformation seems to lead to unsatisfactory results. One possible explanation is the incapacity of the model of extrapolating the greater details of the dermoscopic images. Considering all the specific details normally obtained in the dermoscopic image, the model was not able to capture sufficient features to solve this task.
SMARTSKINS 2014/2015 This dataset proved quite challenging for the model due to the dark corners in all dermoscopic images.
Figure 3b (row 1) shows this failure case, which usually results in minimal to no changes in the TransMacro result. Since we suspected that the cause of failure was the fact that macroscopic images never have these dark borders, and consequently the generator does not learn how to deal with the characteristic, the dark corners were removed, by cropping the image. This pre-processing step led to a considerable improvement in the results.
Figure 3b (row 2), shows the translation of the same dermoscopic image, this time cropped. Here, the model was able to generate an appearance of reflection and modify the skin tonality, which can be seen in
Figure 3b (rows 2, 3, and 4). In this dataset, the generation of depth skin lesion can also be seen in
Figure 3b (row 4), however not as evidently as in the previous dataset.
In this dataset, an interesting result was obtained in the macroscopic to dermoscopic translation.
Figure 3b (row 4) shows the generation of a region with red colouration in the left inferior area of the lesion of the TransDermo image. This colouration, which was not present in the original macroscopic image, is also present in the original dermoscopic image. Another transformation detected, in this image was the accentuation in the contrast of the two brown tonalities of the lesion.
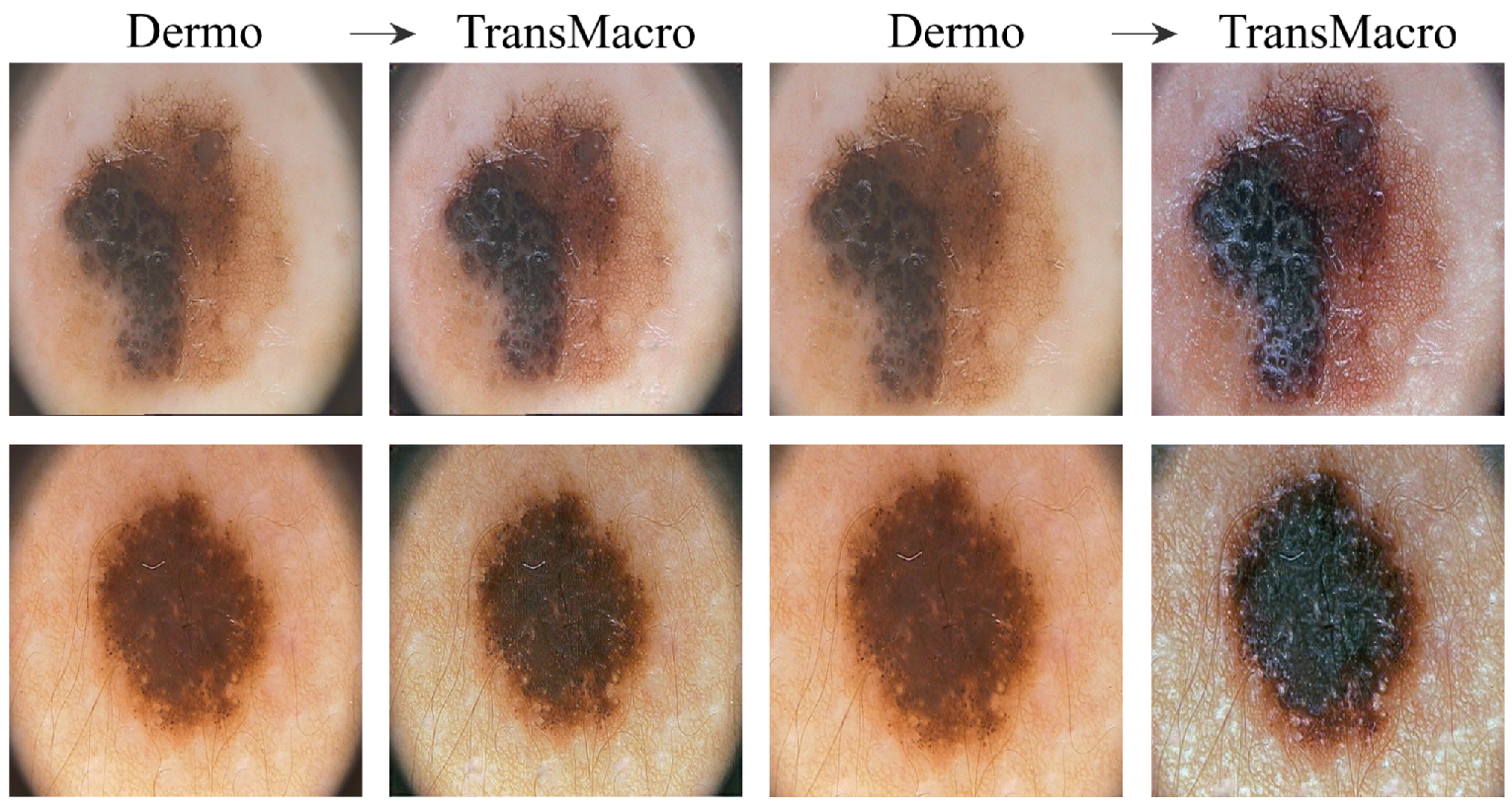
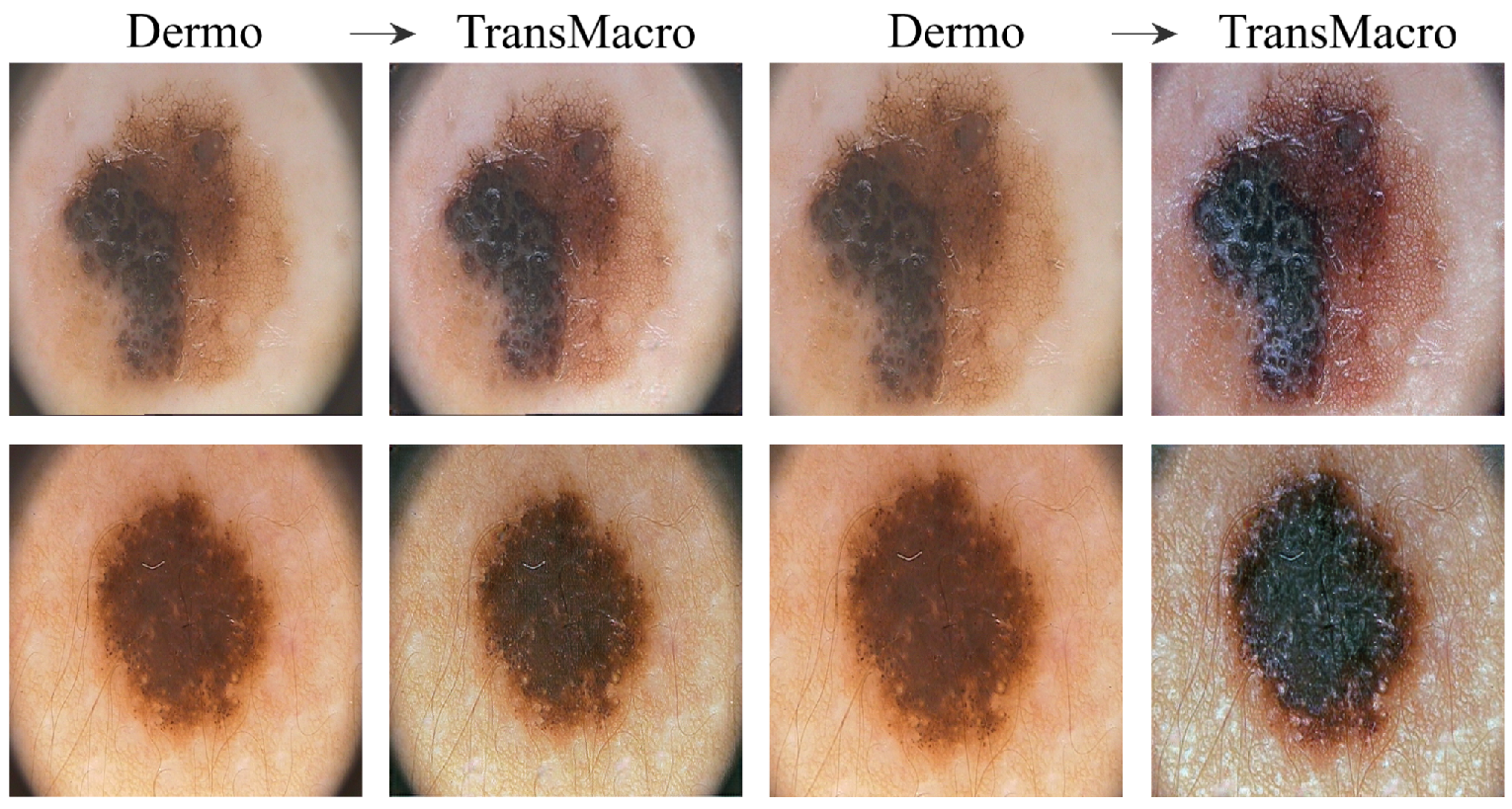
ISICFigure 4 shows the results obtained from the trained CycleGAN in the ISIC test subset. As expected, the best transformations occured in this subset, as the ISIC images represented a large portion of the training dataset. For the most part, the conversions in this dataset can be categorised into four main ones which are shown in
Figure 4 in the top row: (i) the appearance of surface glare and reflections; (ii) generation of depth; (iii) loss of dermoscopic structures; and (iv) generation of squamous appearance. Regarding the generation of surrounding skin with colourization and surface glared, typical of the macroscopic domain (
Figure 4, pair A, top row), this modification is usually accompanied by the loss on any structure typical of the dermoscopic domain. This loss can be from the diffuse borders, regression structure or pigmented networks (
Figure 4, pairs A, B and C, top row). Another frequent modification is the generation of squamous like plaque or nodular appearance (
Figure 4 pair D of the top row). The generation of an appearance of depth in the image is also very prevalent (
Figure 4, pairs A, B and C, top row).
In the translation of dermoscopic to the macroscopic domain, there are several noticeable limitations, as shown in
Figure 4 (bottom row). The appearance of artefacts such as black frames, dark corners, gel substances, intensive illuminations spots, ink marks and air bubbles can lead to translations with no noticeable modifications (
Figure 4, pairs A, B and C, bottom row). Another main concern is the transformation to an uncharacteristic lesion which does not resemble any specific domain. Normally these translated images have a reddish tone or complete loss of definition (
Figure 4, pair D, bottom row).
PH2Figure 5 shows the results obtained from the trained CycleGAN in the PH2 test subset. In order to obtain reasonable results, it was necessary to crop the image to remove the dark corners just as it was done in the SMARTSKINS 2014/2015 dataset. After this pre-processing step, the most successful transformations were the change in the tonality of the surrounding skin, the addition of reflections, the darkening of the lesion and some elevation of the lesions. However, it should be noted that the results were not as satisfactory as in the previous test subsets.
4.1.2. Fréchet Inception Distance Results
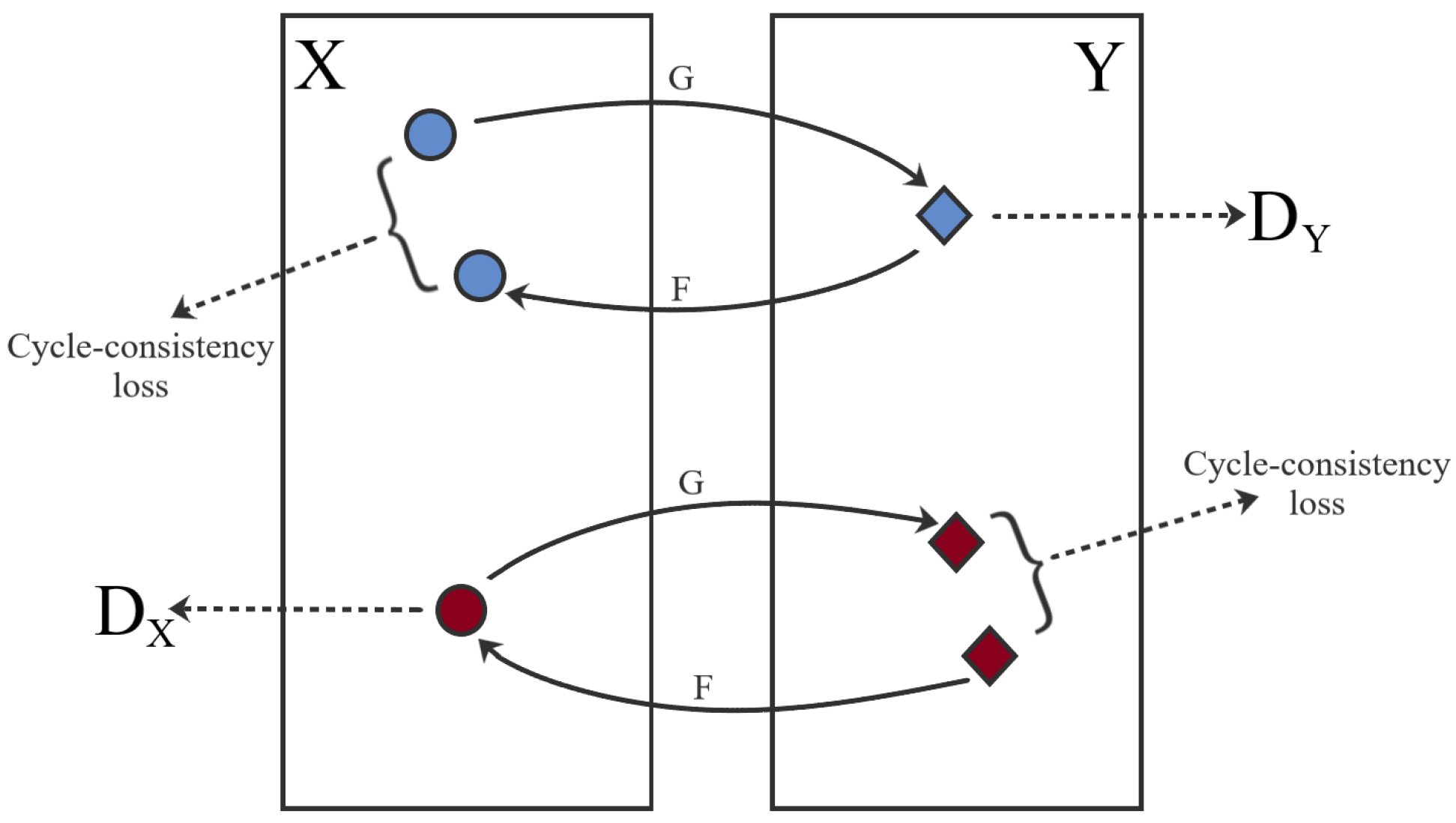
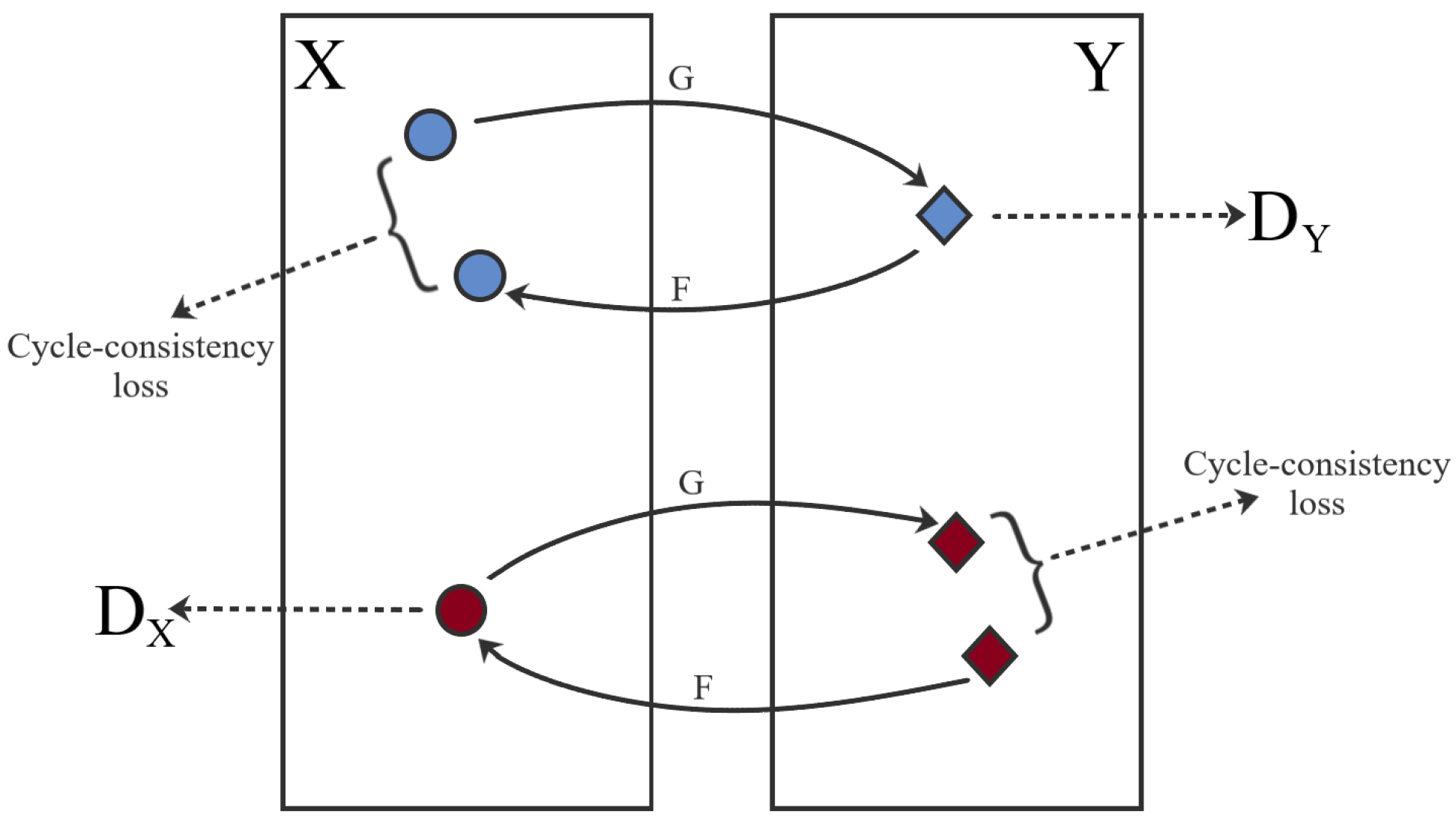
The FID metric was used to ascertain the feasibility of using the CycleGAN to translate between the macroscopic and dermoscopic domains. For this purpose, the distance between three pairs of domains was analysed: (i) Macro/Dermo, between the macroscopic and dermoscopic original images; (ii) Macro/TransMacro, between the original macroscopic image and the dermoscopic image translated into the macroscopic domain; (iii) Dermo/TransDermo, between the original dermoscopic image and the macroscopic image translated into the dermoscopic domain. Since the first pair, Macro/Dermo, compares original images, it can be considered our reference value. If the FID value of the other pairs is lower than the reference value, it means that the translation led to an approximation of the translated images to the target domain, implying a transfer of characteristics between domains.
This change can also be directly compared using the variation ratio (VR), VR =
, which will directly compare the change of similarity between the original domains (reference value) and the translated domains.
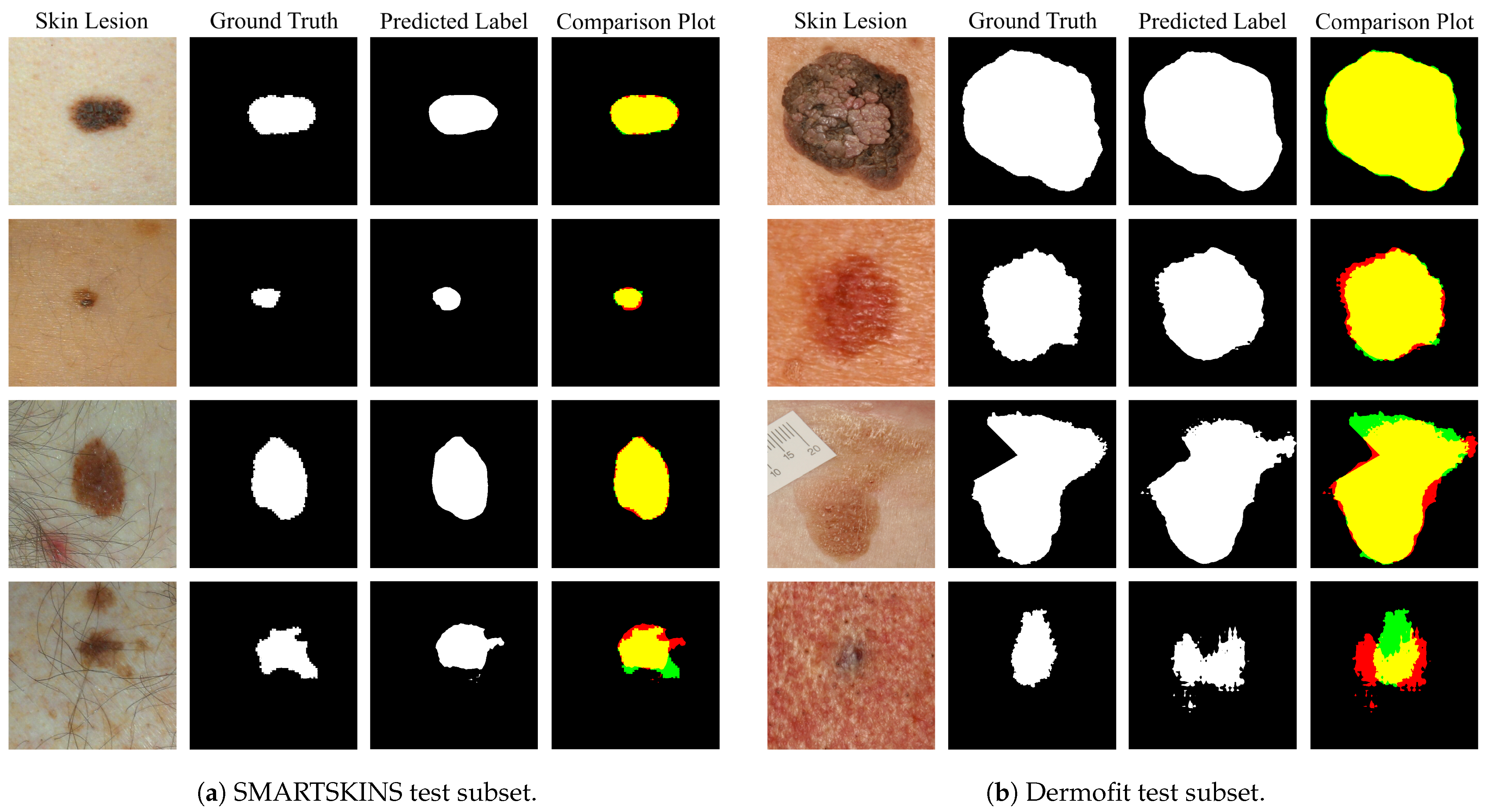
Table 3 presents the computed FID scores, using the official implementation in TensorFlow [
39], on the test subsets of EDRA, SMARSTSKINS 2014/2015, PH2 (set D) and ISIC (set D). Since PH2 (set D) and ISIC (set D) do not have a macroscopic image for each dermoscopic image, they were compared with the macroscopic images of the train subset of Dermofit (set M) and SMARTSKINS (set M).
When analysing the FID results, it is possible to confirm several findings reached in the visual inspection. In the EDRA test subset, the FID score of 160.2 between the domains Macro/TransMacro is lower than the value 167.9 between the Macro/Dermo. This shows that the translations of the dermoscopic images to macroscopic was successful and implies that the images gain specific macroscopic characteristic. In contrast, the value between Dermo/TransDermo is much higher, reaching 186.4. When comparing to the reference value, it leads to a negative VR, which indicates that translating the macroscopic images into dermoscopic made the domains more dissimilar. This further corroborates the conclusion of the visual analysis that the macroscopic to dermoscopic translation was not successful.
In the SMARTSKINS 2014/2015 test subset, the macroscopic images were compared with the uncropped and cropped dermoscopic images, as in the visual analysis. Considering that the decay between the reference FID score with the cropped dermoscopic (Macro/TransMacro) is much higher than decay between the reference value using the uncropped dermoscopic images, it can be stated that this preprocessing step improves the results. In fact, the VR of the Macro/TransMacro with cropped dermoscopic is the highest among test subsets. When analysing the other translation (Dermo/TransDermo), the absolute value of the FID score with the cropped dermoscopic (263.6) is lower than with the uncropped dermoscopic (285.6). However, the VR is also lower, which means that the preprocessing did not improve as much the results.
In the ISIC (Set D) test subset, the dermoscopic images were compared with the train images of Set M. Upon translation, the absolute FID score is the lowest of the test subsets (123.7), validating the assessment made in the visual inspection—the best results were obtained in this dataset.
The PH2 test subset was also compared with the train images of Set M. Here, the FID value obtained was the highest absolute value with the lowest percentage of variation, which is consistent with the small changes observed in the visual inspection.
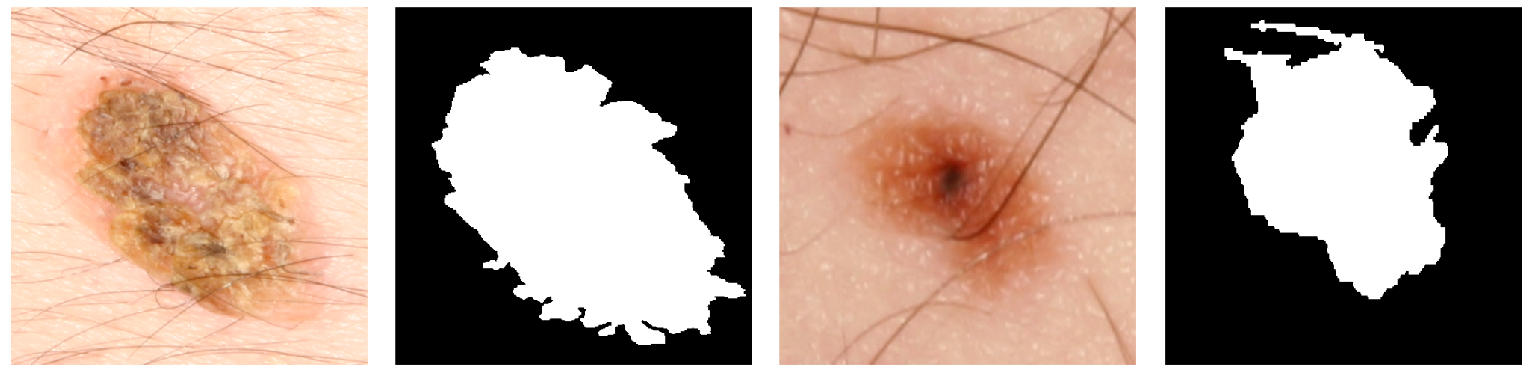
Lastly, the CycleGAN was used to translate the training/validation images from Set D to the macroscopic domain. This led to the creation of the Set M
to augment the macroscopic images.
Table 4 shows the results of the FID between the segmentation training datasets set M and Set D and the new generated Set M
. The FID score between Set M/set M
(102.4) is much lower than the reference value between Set M/Set D (181.1). This drop leads to the most significant change in the variation ratio between the reference value and the Macro/TransMacro domains. Considering also the low absolute value of the FID score (102.4), it is possible to conclude that the images of Set M
obtain several key features of the macroscopic domain.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}