
VIPPrint: Validating Synthetic Image Detection and Source Linking Methods on a Large Scale Dataset of Printed Documents


Abstract
:1. Introduction
- We present a large scale dataset of color-printed face images for digital image forensics purposes, such as source attribution and synthetic images detection (deep fake images).
- We increased the diversity of the images in our dataset to make it suitable for approaches working on images of different sizes. Full scanned images and regions of interest with different sizes are available.
- We present the results of an in-depth comparative study conducted on the new dataset regarding several baseline approaches, including both data-driven methods and methods based on handcrafted features. The comparison regards both source attribution and synthetic image detection.
2. Related Work
- There is a need for a publicly available dataset that grows through time to include modern printers with different technologies and manufacturing procedures. We expect that different printers manufactured at different times generate different artifacts in printed documents that cannot be detected by previous works.
- There is a need for multimedia forensic techniques able to detect deepfake printed images. This is a very challenging problem, since several artifacts, such as the correlation between RGB channels, discrete cosine transform irregularities, and even illumination inconsistencies in the digital image versions are usually removed by the print and scan process. In this way, although several adversarial attacks have been discussed in the literature [55], the print and scan procedure is the easiest yet most powerful attack an adversary could perform against deepfake digital image detectors.
3. The VIPPrint Dataset
3.1. VIPPrint Dataset for Source Attribution
3.2. VIPPrint Dataset for Synthetic GAN Images Detection
4. Experimental Setup
4.1. Metrics
4.1.1. Recall
4.1.2. Precision
4.1.3. F-Measure
4.1.4. Accuracy
4.2. Experimental Methodology
4.3. Statistical Tests
4.4. Baseline Methods
Source Attribution
- The gray histogram [66] (hereafter referred to as GH) divides the grayscale version of the analyzed image into a fixed number of blocks. Then, a histogram of gray intensities is calculated for each block and all the histograms together are used to generate a description vector.
- The histogram of oriented gradients [67] (hereafter referred to as HOG) extracts the edges in the image by means of the Sobel kernel gradients; then it computes the gradients for all the orientations. Finally, a histogram of such orientations is fed into the input of a machine learning classifier.
- The edge histogram [66] (hereafter referred to as EH) is similar to HOG. However, it calculates, for each block, the dominant edge orientation instead of all of them, and the descriptor is a histogram of these orientations.
- The local binary patterns [68] divide the image into blocks and compare each pixel in a block to all its neighbors. If the pixel in the center of the block is greater than a neighbor’s value, then a 0 digit is written (1 otherwise). Considering eight neighbors in each block, 8-digit binary numbers are generated for each pixel in a block. Such digits are converted to decimals and histograms for each block are calculated, normalized, and concatenated to describe the image.
- The multidirectional version of the gray level co-occurrence matrix (GLCM-MD) from Ferreira et al. [34].
- The multidirectional and multiscale version of the same approach proposed in [34] (GLCM-MD-MS).
- The convolutional texture gradient filter in a window [34] (CTGF-3X3).
- The 39 statistical features from the diagonal discrete wavelet transform sub-band from Choi et al. [26] (DWT-STATS).
Printed and Scanned GAN Image Detection
4.5. Implementation Details
- We fine-tuned the neural networks pre-trained on ImageNet with the input training data (e.g., high energized patches), by initializing the weights with Imagenet pre-trained weights. We tried other procedures, such as fine-tuning, only the tops of the networks (i.e., the fully connected layers) and freezing the other layers, but the results were not worthwhile.
- In the fine-tuning procedure, we cut off the tops of these networks, replacing them with a layer of 512 fully connected neurons, followed by a 50% dropout layer and a final layer with eight or two neurons, depending on the task.
- The networks were trained with the steepest gradient descent optimizer [75], with an initial learning rate of 0.01. The learning rate was reduced by a factor of once the validation loss stagnated after five epochs. We fixed the learning rate lower bound to 0.5 . We trained the networks on minibatches of size 32 for source attribution and 16 for GAN detection.
- We set the maximum number of epochs for source attribution to 300 epochs. However, after 20 epochs we implemented an early stopping procedure if the validation loss did not improve. For deepfake detection, we chose 10 epochs and the early stopping condition was implemented after five epochs, as we were using much more data.
- We used data augmentation for the source attribution task by using the following image processing operations: rotation, zoom, width shifts, height shifts, shears, and horizontal flips. For GAN detection, since much more training data are available (more than 300,000 images), we did not use any data augmentation.
5. Experimental Results
5.1. Source Attribution
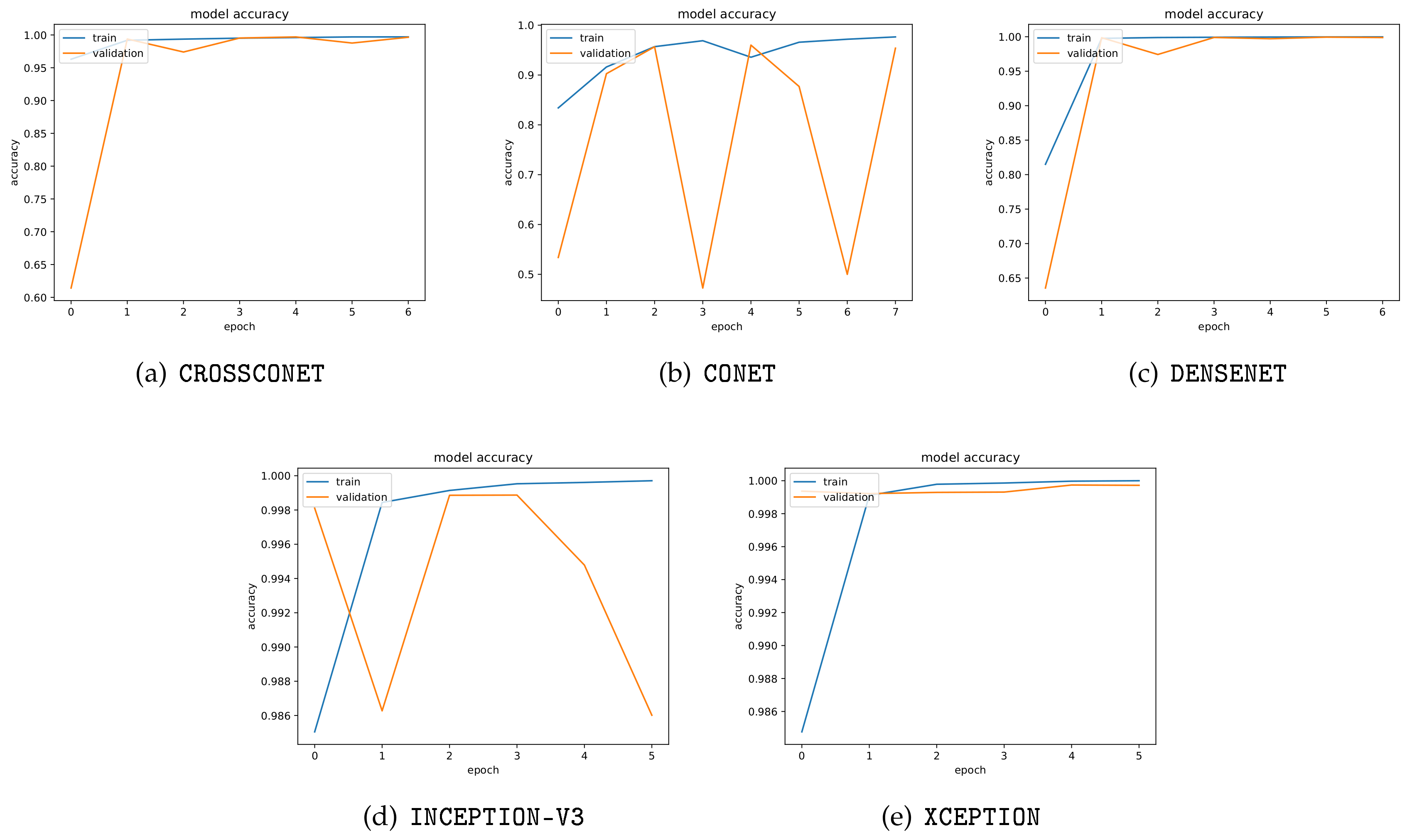
5.2. Detection of GAN Images
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Electronic Frontier Foundation. List of Printers Which Do or Do Not Display Tracking Dots. Available online: https://www.eff.org/pages/list-printers-which-do-or-do-not-display-tracking-dots (accessed on 5 October 2020).
- Richter, T.; Escher, S.; Schönfeld, D.; Strufe, T. Forensic Analysis and Anonymisation of Printed Documents. In ACM Workshop on Information Hiding and Multimedia Security; Association for Computing Machinery: New York, NY, USA, 2018; pp. 127–138. [Google Scholar]
- Ali, G.; Mikkilineni, A.; Delp, E.; Allebach, J.; Chiang, P.J.; Chiu, G. Application of principal components analysis and gaussian mixture models to printer identification. In NIP & Digital Fabrication Conference; Society for Imaging Science and Technology: Springfield, VA, USA, 2004; pp. 301–305. [Google Scholar]
- Mikkilineni, A.; Chiang, P.; Ali, G.; Chiu, G.; Allebach, J.; Delp, E. Printer identification based on texture features. In NIP & Digital Fabrication Conference; Society for Imaging Science and Technology: Springfield, VA, USA, 2004; pp. 306–311. [Google Scholar]
- Mikkilineni, A.K.; Chiang, P.J.; Ali, G.N.; Chiu, G.T.C.; Allebach, J.P.; Delp, E.J. Printer identification based on graylevel co-occurrence features for security and forensic applications. In Security, Steganography, and Watermarking of Multimedia Contents VII; Delp, E.J., III, Wong, P.W., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2005; Volume 5681, pp. 430–440. [Google Scholar] [CrossRef] [Green Version]
- Mikkilineni, A.; Arslan, O.; Chiang, P.J.; Kumontoy, R.; Allebach, J.; Chiu, G.; Delp, E. Printer Forensics using SVM Techniques. In NIP & Digital Fabrication Conference; Society for Imaging Science and Technology: Springfield, VA, USA, 2005; pp. 223–226. [Google Scholar]
- Kee, E.; Farid, H. Printer Profiling for Forensics and Ballistics. In Proceedings of the ACM Workshop on Multimedia and Security, Oxford, UK, 22–23 September 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 3–10. [Google Scholar] [CrossRef]
- Deng, W.; Chen, Q.; Yuan, F.; Yan, Y. Printer Identification Based on Distance Transform. In Proceedings of the International Conference on Intelligent Networks and Intelligent Systems, Wuhan, China, 1–3 November 2008; pp. 565–568. [Google Scholar]
- Wu, Y.; Kong, X.; Guo, Y. Printer forensics based on page document’s geometric distortion. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 2909–2912. [Google Scholar]
- Jiang, W.; Ho, A.T.S.; Treharne, H.; Shi, Y.Q. A Novel Multi-size Block Benford’s Law Scheme for Printer Identification. In Pacific-Rim Conference on Multimedia; Qiu, G., Lam, K.M., Kiya, H., Xue, X.Y., Kuo, C.C.J., Lew, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 643–652. [Google Scholar]
- Mikkilineni, A.K.; Khanna, N.; Delp, E.J. Forensic printer detection using intrinsic signatures. In Media Watermarking, Security, and Forensics III; Memon, N.D., Dittmann, J., Alattar, A.M., Delp, E.J., III, Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2011; Volume 7880, pp. 278–288. [Google Scholar] [CrossRef]
- Tsai, M.; Liu, J. Digital forensics for printed source identification. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Beijing, China, 19–23 May 2013; pp. 2347–2350. [Google Scholar]
- Elkasrawi, S.; Shafait, F. Printer Identification Using Supervised Learning for Document Forgery Detection. In Proceedings of the International Workshop on Document Analysis Systems, Tours, France, 7–10 April 2014; pp. 146–150. [Google Scholar]
- Tsai, M.J.; Yin, J.S.; Yuadi, I.; Liu, J. Digital Forensics of Printed Source Identification for Chinese Characters. Multimed. Tools Appl. 2014, 73, 2129–2155. [Google Scholar] [CrossRef]
- Hao, J.; Kong, X.; Shang, S. Printer Identification Using Page Geometric Distortion on Text Lines. In Proceedings of the IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Chengdu, China, 12–15 July 2015; pp. 856–860. [Google Scholar]
- Shang, S.; Kong, X.; You, X. Document forgery detection using distortion mutation of geometric parameters in characters. J. Electron. Imaging 2015, 24, 1–10. [Google Scholar] [CrossRef]
- Tsai, M.; Hsu, C.; Yin, J.; Yuadi, I. Japanese Character Based Printed Source Identification. In Proceedings of the Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 2800–2803. [Google Scholar]
- Ferreira, A.; Bondi, L.; Baroffio, L.; Bestagini, P.; Huang, J.; dos Santos, J.A.; Tubaro, S.; Rocha, A. Data-Driven Feature Characterization Techniques for Laser Printer Attribution. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1860–1873. [Google Scholar] [CrossRef]
- Joshi, S.; Khanna, N. Single Classifier-Based Passive System for Source Printer Classification Using Local Texture Features. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1603–1614. [Google Scholar] [CrossRef] [Green Version]
- Joshi, S.; Lomba, M.; Goyal, V.; Khanna, N. Augmented Data and Improved Noise Residual-Based CNN for Printer Source Identification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2002–2006. [Google Scholar]
- Jain, H.; Gupta, G.; Joshi, S.; Khanna, N. Passive classification of source printer using text-line-level geometric distortion signatures from scanned images of printed documents. Multimed. Tools Appl. 2019, 79, 7377–7400. [Google Scholar] [CrossRef] [Green Version]
- Joshi, S.; Khanna, N. Source Printer Classification Using Printer Specific Local Texture Descriptor. IEEE Trans. Inf. Forensics Secur. 2020, 15, 160–171. [Google Scholar] [CrossRef] [Green Version]
- Ali, G.; Mikkilineni, A.; Chiang, P.J.; Allebach, J.; Chiu, G.; Delp, E. Intrinsic and Extrinsic Signatures for Information Hiding and Secure Printing with Electrophotographic Devices. In Proceedings of the International Conference on Digital Printing Technologies, New Orleans, MS, USA, 28 September–3 October 2003. [Google Scholar]
- Eid, A.H.; Ahmed, M.N.; Rippetoe, E.E. EP Printer Jitter Characterization Using 2D Gabor Filter and Spectral Analysis. In Proceedings of the IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1860–1863. [Google Scholar]
- Bulan, O.; Mao, J.; Sharma, G. Geometric Distortion Signatures for Printer Identification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICAASP), Taipei, Taiwan, 19–24 April 2009; pp. 1401–1404. [Google Scholar]
- Choi, J.H.; Im, D.H.; Lee, H.Y.; Oh, J.T.; Ryu, J.H.; Lee, H.K. Color Laser Printer Identification by Analyzing Statistical Features on Discrete Wavelet Transform. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1505–1508. [Google Scholar]
- Choi, J.H.; Lee, H.K.; Lee, H.Y.; Suh, Y.H. Color Laser Printer Forensics with Noise Texture Analysis. In Proceedings of the ACM Workshop on Multimedia and Security, Cairo, Egypt, 7–10 November 2009; Association for Computing Machinery: New York, NY, USA, 2010; pp. 19–24. [Google Scholar]
- Ryu, S.; Lee, H.; Im, D.; Choi, J.; Lee, H. Electrophotographic Printer Identification by Halftone Texture Analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICAASP), Dallas, TX, USA, 14–19 March 2010; pp. 1846–1849. [Google Scholar]
- Tsai, M.; Liu, J.; Wang, C.; Chuang, C. Source Color Laser Printer Identification Using Discrete Wavelet Transform and Feature Selection Algorithms. In Proceedings of the IEEE International Symposium of Circuits and Systems (ISCAS), Rio de Janeiro, Brazil, 15–18 May 2011; pp. 2633–2636. [Google Scholar]
- Choi, J.H.; Lee, H.Y.; Lee, H.K. Color laser printer forensic based on noisy feature and support vector machine classifier. Multimed. Tools Appl. 2013, 67, 363–382. [Google Scholar] [CrossRef]
- Kim, D.; Lee, H. Color Laser Printer Identification Using Photographed Halftone Images. In Proceedings of the European Signal Processing Conference (EUSIPCO), Lisbon, Portugal, 1–5 September 2014; pp. 795–799. [Google Scholar]
- Wu, H.; Kong, X.; Shang, S. A Printer Forensics Method Using Halftone Dot Arrangement Model. In Proceedings of the IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Chengdu, China, 12–15 July 2015; pp. 861–865. [Google Scholar]
- Kim, D.; Lee, H. Colour laser printer identification using halftone texture fingerprint. Electron. Lett. 2015, 51, 981–983. [Google Scholar] [CrossRef]
- Ferreira, A.; Navarro, L.C.; Pinheiro, G.; dos Santos, J.A.; Rocha, A. Laser printer attribution: Exploring new features and beyond. Forensics Sci. Int. 2015, 247, 105–125. [Google Scholar] [CrossRef] [PubMed]
- Tsai, M.; Yuadi, M.; Tao, Y.; Yin, J. Source Identification for Printed Documents. In Proceedings of the International Conference on Collaboration and Internet Computing (CIC), San Jose, CA, USA, 15–17 October 2017; pp. 54–58. [Google Scholar]
- Bibi, M.; Hamid, A.; Moetesum, M.; Siddiqi, I. Document Forgery Detection using Printer Source Identification—A Text-Independent Approach. In Proceedings of the International Conference on Document Analysis and Recognition Workshops, Sydney, Australia, 22–25 September 2019; Volume 8, pp. 7–12. [Google Scholar]
- James, H.; Gupta, O.; Raviv, D. Printing and Scanning Attack for Image Counter Forensics. arXiv 2020, arXiv:2005.02160. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-Generated Fake Images over Social Networks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.; Chandrasekaran, S.; Flenner, A.; Bappy, M.J.; Roy-Chowdhury, A. Detecting GAN generated Fake Images using Co-occurrence Matrices. Electron. Imaging 2019, 2019, 532-1. [Google Scholar] [CrossRef] [Green Version]
- Barni, M.; Kallas, K.; Nowroozi, E.; Tondi, B. CNN Detection of GAN-Generated Face Images based on Cross-Band Co-occurrences Analysis. In Proceedings of the IEEE Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2020; pp. 1–6. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4396–4405. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. arXiv 2017, arXiv:1711.09020. [Google Scholar]
- Khanna, N.; Mikkilineni, A.K.; Martone, A.F.; Ali, G.N.; Chiu, G.T.C.; Allebach, J.P.; Delp, E.J. A survey of forensic characterization methods for physical devices. Digit. Investig. 2006, 3, 17–28. [Google Scholar] [CrossRef]
- Khanna, N.; Mikkilineni, A.K.; Chiu, G.T.C.; Allebach, J.P.; Delp, E.J. Survey of Scanner and Printer Forensics at Purdue University. In International Workshop on Computational Forensics; Srihari, S.N., Franke, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 22–34. [Google Scholar]
- Chiang, P.J.; Khanna, N.; Mikkilineni, A.; Segovia, M.; Suh, S.; Allebach, J.; Chiu, G.; Delp, E. Printer and Scanner Forensics. IEEE Signal Process. Mag. 2009, 26, 72–83. [Google Scholar] [CrossRef]
- Devi, M.U.; Rao, C.R.; Agarwal, A. A Survey of Image Processing Techniques for Identification of Printing Technology in Document Forensic Perspective. Int. J. Comput. Appl. 2010, 1, 9–15. [Google Scholar]
- Oliver, J.; Chen, J. Use of signature analysis to discriminate digital printing technologies. In NIP & Digital Fabrication Conference; Society for Imaging Science and Technology: Springfield, VA, USA, 2002; pp. 218–222. [Google Scholar]
- Lampert, C.H.; Mei, L.; Breuel, T.M. Printing Technique Classification for Document Counterfeit Detection. In Proceedings of the International Conference on Computational Intelligence and Security, Guangzhou, China, 3–6 November 2006; Volume 1, pp. 639–644. [Google Scholar]
- Schulze, C.; Schreyer, M.; Stahl, A.; Breuel, T. Using DCT Features for Printing Technique and Copy Detection. In Advances in Digital Forensics V; Peterson, G., Shenoi, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 95–106. [Google Scholar]
- Schreyer, M.; Schulze, C.; Stahl, A.; Effelsberg, W. Intelligent Printing Technique Recognition and Photocopy Detection for Forensic Document Examination. In Informatiktage: Fachwissenschaftlicher Informatik-Kongress; Informatiktage: Bonn, Germany, 2009; pp. 39–42. [Google Scholar]
- Roy, A.; Halder, B.; Garain, U. Authentication of Currency Notes through Printing Technique Verification. Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Chennai, India, 12–15 December 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 383–390. [Google Scholar]
- Chiang, P.; Allebach, J.P.; Chiu, G.T. Extrinsic Signature Embedding and Detection in Electrophotographic Halftoned Images Through Exposure Modulation. IEEE Trans. Inf. Forensics Secur. 2011, 6, 946–959. [Google Scholar] [CrossRef]
- Beusekom, J.V.; Shafait, F.; Breuel, T. Automatic authentication of color laser print-outs using machine identification codes. Pattern Anal. Appl. 2012, 16, 663–678. [Google Scholar] [CrossRef]
- Nowroozi, E.; Dehghantanha, A.; Parizi, R.M.; Choo, K.K.R. A survey of machine learning techniques in adversarial image forensics. Comput. Secur. 2021, 100, 102092. [Google Scholar] [CrossRef]
- Bondi, L.; Baroffio, L.; Güera, D.; Bestagini, P.; Delp, E.J.; Tubaro, S. First Steps Toward Camera Model Identification With Convolutional Neural Networks. IEEE Signal Process. Lett. 2017, 24, 259–263. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, A.; Chen, H.; Li, B.; Huang, J. An Inception-Based Data-Driven Ensemble Approach to Camera Model Identification. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Agarwal, S.; Fan, W.; Farid, H. A Diverse Large-Scale Dataset for Evaluating Rebroadcast Attacks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1997–2001. [Google Scholar]
- Li, H.; Li, B.; Tan, S.; Huang, J. Identification of deep network generated images using disparities in color components. Signal Process. 2020, 174, 107616. [Google Scholar] [CrossRef]
- Hsu, C.; Lee, C.; Zhuang, Y. Learning to Detect Fake Face Images in the Wild. In Proceedings of the International Symposium on Computer, Consumer and Control (IS3C), Taichung, Taiwan, 6–8 December 2018; pp. 388–391. [Google Scholar]
- Bonettini, N.; Cannas, E.D.; Mandelli, S.; Bondi, L.; Bestagini, P.; Tubaro, S. Video Face Manipulation Detection Through Ensemble of CNNs. arXiv 2020, arXiv:2004.07676. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dietterich, T.G. Approximate Statistical Test For Comparing Supervised Classification Learning Algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedman, M. The Use of Ranks to Avoid the Assumption of Normality Implicit in the Analysis of Variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Gosset, W.S. The Probable Error of a Mean. Biometrika 1908, 6, 1–25. [Google Scholar]
- Jain, A.K.; Vailaya, A. Image retrieval using color and shape. Pattern Recognit. 1996, 29, 1233–1244. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Ferreira, A. Printer Forensics Source Code. 2014. Available online: https://github.com/anselmoferreira/printer_forensics_source_code (accessed on 5 October 2020).
- Wardi, Y. A stochastic steepest-descent algorithm. J. Optim. Theory Appl. 1988, 59, 307–323. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VIPPrint Dataset- Printer Source Linking | |||||
|---|---|---|---|---|---|
| ID | Brand | Model | Resolution | Type | #Images |
| #1 | Epson | WorkForce WF-7715 | 4800 × 2400 dpi | Laser | 200 |
| #2 | Kyocera | Color Laser | 600 × 600 dpi | Laser | 200 |
| #3 | Kyocera | TaskAlfa 3551 | 600 × 600 dpi | Laser | 200 |
| #4 | Kyocera | TaskAlfa 3551 | 600 × 600 dpi | Laser | 200 |
| #5 | Samsung | Multiexpress X3280NR | 600 × 600 dpi | Laser | 200 |
| #6 | HP | Color LaserJet Pro rfp-r479fdw | 600 × 600 dpi | Laser | 200 |
| #7 | HP | Color LaserJet rfp-r377dw | 600 × 600 dpi | Laser | 200 |
| #8 | OKI | C612 LaserColor | 1200 × 600 dpi | Laser | 200 |
| Type | Method | 5 × 2 Cross Validation Results–Close Set Printer Attribution | |||
|---|---|---|---|---|---|
| Input Size | F | Precision | Recall | ||
| TEXTURE DESCRIPTORS | GH [66] | Image | 0.52 ± 0.01 | 0.53 ± 0.01 | 0.52 ± 0.01 |
| HOG [67] | Image | 0.68 ± 0.01 | 0.69 ± 0.01 | 0.68 ± 0.01 | |
| EH [66] | Image | 0.69 ± 0.01 | 0.69 ± 0.01 | 0.69 ± 0.01 | |
| LBP [68] | Image | 0.75 ± 0.01 | 0.75 ± 0.01 | 0.75 ± 0.01 | |
| FEATURE-BASED BASELINES | DWT-STATS [26] | Image | 0.76 ± 0.01 | 0.76 ± 0.01 | 0.76 ± 0.01 |
| GLCM-MD [34] | Image | 0.78 ± 0.01 | 0.79 ± 0.01 | 0.78 ± 0.01 | |
| GLCM-MD-MS [34] | Image | 0.84 ± 0.01 | 0.84 ± 0.01 | 0.84 ± 0.01 | |
| CTGF-3x3 [34] | Image | 0.79 ± 0.01 | 0.79 ± 0.01 | 0.79 ± 0.01 | |
| DATA-DRIVEN BASELINES | RESNET-50 [36,70] | 224 × 224 patches | 0.91 ± 0.01 | 0.92 ± 0.00 | 0.91 ± 0.00 |
| RESNET-101 [36,70] | 224 × 224 patches | 0.90 ± 0.01 | 0.92 ± 0.00 | 0.91 ± 0.00 | |
| VGG−16 [36,69] | 224 × 224 patches | 0.46 ± 0.45 | 0.45 ± 0.46 | 0.51 ± 0.40 | |
| VGG−19 [36,69] | 224×224 patches | 0.37 ± 0.44 | 0.37 ± 0.44 | 0.42 ± 0.39 | |
| Confusion Matrix – RESNET50 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Printer | Epson-WorkForce WF-7715 | Kyocera ColorLaser | Kyocera TaskAlfa3551ci | Kyocera TaskAlfa3551ci-2 | Samsung Multiexpress X3280NR | HP Color-LaserJet Pro rfp-r479fdw | HP Color-LaserJet rfp-r377dw | OKI-C612 LaserColor |
| Epson-WorkForce WF-7715 | 100.00% | |||||||
| Kyocera ColorLaser | 56.00% | 41.00% | 3.00% | |||||
| Kyocera TaskAlfa3551ci | 5.00% | 92.00% | 3.00% | |||||
| KyoceraTaskAlfa 3551ci-2 | 1.00% | 99.00% | ||||||
| Samsung Multiexpress-X3280NR | 100.00% | |||||||
| HP Color-LaserJet Pro rfp-r479fdw | 98.00% | 2.00% | ||||||
| HP-Color-LaserJet rfp-r377dw | 100.00% | |||||||
| OKI-C612 LaserColor | 100.00% | |||||||
| Confusion Matrix – RESNET101 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Printer | Epson-WorkForce WF-7715 | Kyocera ColorLaser | Kyocera TaskAlfa3551ci | Kyocera TaskAlfa3551ci-2 | Samsung Multiexpress X3280NR | HP Color-LaserJet Pro rfp-r479fdw | HP Color-LaserJet rfp-r377dw | OKI-C612 LaserColor |
| Epson-WorkForce WF-7715 | 100,00% | |||||||
| Kyocera ColorLaser | 35.00% | 60.00% | 5.00% | |||||
| Kyocera TaskAlfa3551ci | 5.00% | 93.00% | 2.00% | |||||
| KyoceraTaskAlfa 3551ci-2 | 1.00% | 99.00% | ||||||
| Samsung Multiexpress-X3280NR | 100.00% | |||||||
| HP Color-LaserJet Pro rfp-r479fdw | 98.00% | 2.00% | ||||||
| HP-Color-LaserJet rfp-r377dw | 1.00% | 99.00% | ||||||
| OKI-C612 LaserColor | 100.00% | |||||||
| Method | GH [66] | HOG [67] | EH [66] | LBP [68] | DWT-STATS [26] | GLCM-MD [34] | GLCM-MD -MS [34] | CTGF-3x3 [34] | RESNET-50 [36,70] | RESNET−101 [36,70] | VGG−16 [36,69] | VGG−19 [36,69] | TOTAL |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GH [66] | 0 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | 0 | 0 | −9 |
| HOG [67] | 1 | 0 | 0 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | 0 | 1 | −5 |
| EH [66] | 1 | 0 | 0 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | 0 | 1 | −5 |
| LBP [68] | 1 | 1 | 1 | 0 | 0 | −1 | −1 | −1 | −1 | −1 | 0 | 1 | −1 |
| DWT-STATS [26] | 1 | 1 | 1 | 0 | 0 | −1 | −1 | −1 | −1 | −1 | 1 | 1 | 0 |
| GLCM-MD [34] | 1 | 1 | 1 | 1 | 1 | 0 | −1 | 0 | −1 | −1 | 1 | 1 | 4 |
| GLCM-MD-MS [34] | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | −1 | −1 | 1 | 1 | 7 |
| CTGF-3x3 [34] | 1 | 1 | 1 | 1 | 1 | 0 | −1 | 0 | −1 | −1 | 1 | 1 | 4 |
| RESNET-50 [36,70] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 10 |
| RESNET−101 [36,70] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 10 |
| VGG−16 [36,69] | 0 | 0 | 0 | 0 | −1 | −1 | −1 | −1 | −1 | −1 | 0 | 0 | −6 |
| VGG−19 [36,69] | 0 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | −1 | 0 | 0 | −9 |
| 1 = Line method is better than column method | |||||||||||||
| 0 = Line method is equivalent to column method | |||||||||||||
| −1 = Line method is worse than column method | |||||||||||||
| Digital Images Testing Results | Printed and Scanned Testing Images Results | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Training/Validation Data | Input Size | Acc | F | Precision | Recall | Acc | F | Precision | Recall |
| DENSENET [38,71] | Images Patches | 224 × 224 × 3 | 1.00 | 1.00 | 1.00 | 1.00 | 0.50 | 0.00 | 0.00 | 0.00 |
| INCEPTION-V3 [38,72] | Images Patches | 224 × 224 × 3 | 1.00 | 1.00 | 1.00 | 1.00 | 0.50 | 0.00 | 0.00 | 0.00 |
| XCEPTION [38,73] | Images Patches | 299 × 299 × 3 | 1.00 | 1.00 | 1.00 | 1.00 | 0.50 | 0.00 | 0.00 | 0.00 |
| CONET [39] | Co-occurency Matrices | 256 × 256 × 3 | 0.96 | 0.96 | 0.95 | 0.98 | 0.50 | 0.00 | 0.00 | 0.00 |
| CROSSCONET [40] | Co-occurency Matrices | 256 × 256 × 6 | 0.99 | 0.99 | 0.98 | 1.00 | 0.50 | 0.29 | 0.50 | 0.21 |
| Confusion Matrix Xception Digital Test Patches | ||
|---|---|---|
| Class | Real | Fake |
| Real | 8914 | 5 |
| Fake | 2 | 8983 |
| Confusion Matrix CROSSCONET PrintScan Test Images | ||
|---|---|---|
| Class | Real | Fake |
| Real | 796 | 204 |
| Fake | 788 | 212 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferreira, A.; Nowroozi, E.; Barni, M. VIPPrint: Validating Synthetic Image Detection and Source Linking Methods on a Large Scale Dataset of Printed Documents. J. Imaging 2021, 7, 50. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7030050
Ferreira A, Nowroozi E, Barni M. VIPPrint: Validating Synthetic Image Detection and Source Linking Methods on a Large Scale Dataset of Printed Documents. Journal of Imaging. 2021; 7(3):50. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7030050
Chicago/Turabian StyleFerreira, Anselmo, Ehsan Nowroozi, and Mauro Barni. 2021. "VIPPrint: Validating Synthetic Image Detection and Source Linking Methods on a Large Scale Dataset of Printed Documents" Journal of Imaging 7, no. 3: 50. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7030050