
ChainLineNet: Deep-Learning-Based Segmentation and Parameterization of Chain Lines in Historical Prints


Abstract
:1. Introduction
2. Related Work
2.1. Segmentation and Detection of Chain Lines
2.2. Segmentation and Detection of Lines
2.3. Contour Detection Using Generative Adversarial Networks
3. Method
3.1. Chain Line Segmentation Network Architecture
3.2. End-to-End Training of Line Segmentation and Parameterization
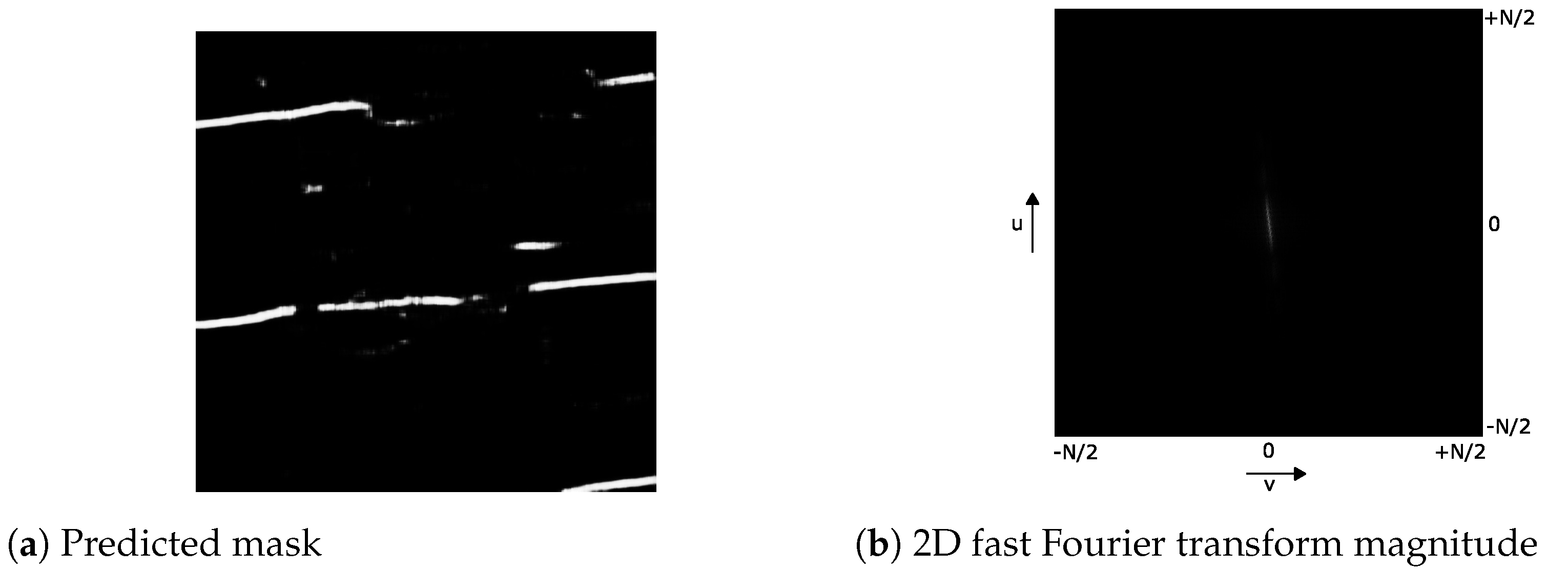
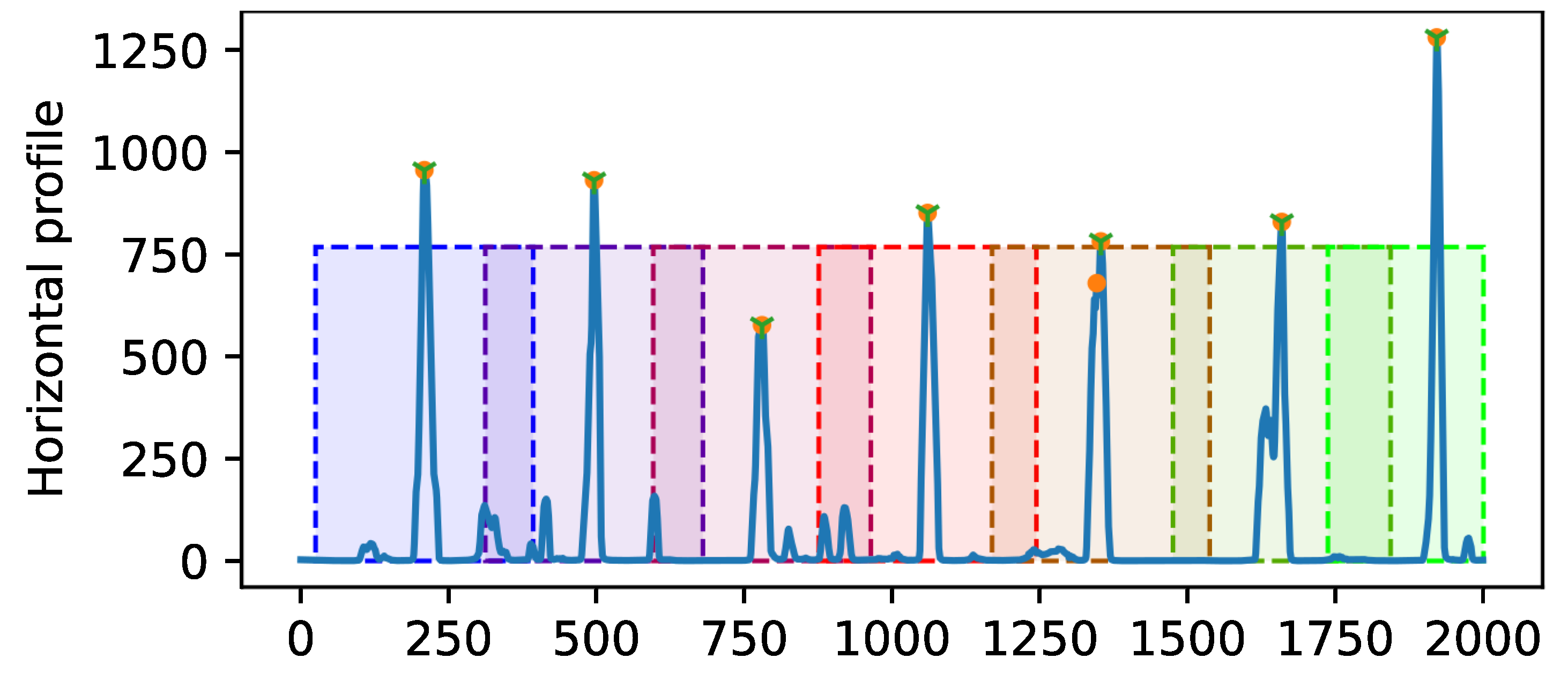
3.3. Line Parameterization Pipeline and Line Loss Functions
- Line hypothesis sampling: Based on the predicted point coordinates z, m line hypotheses are randomly sampled by choosing for each hypothesis two points of the point set. Each hypothesis predicts an estimate for the line parameters, the slope a and intercept b of the line equation ;
- Hypothesis selection: A scoring function computes a score for each hypothesis based on the soft inlier count. The hypothesis is selected according to the softmax probabilistic distribution ;
- Hypothesis refinement: The hypothesis is refined by using the weighted Deming regression for line fitting [25], which is a special case of the total least-squares that accounts for errors in the observations in both the x- and y-direction, for which we used the soft inlier scores as the weights.
3.4. Inference of Chain Line Segmentation and Parameterization Network
4. Experiments and Results
4.1. Chain Line Dataset
4.2. Implementation Details
4.3. Evaluation of Line Segmentation
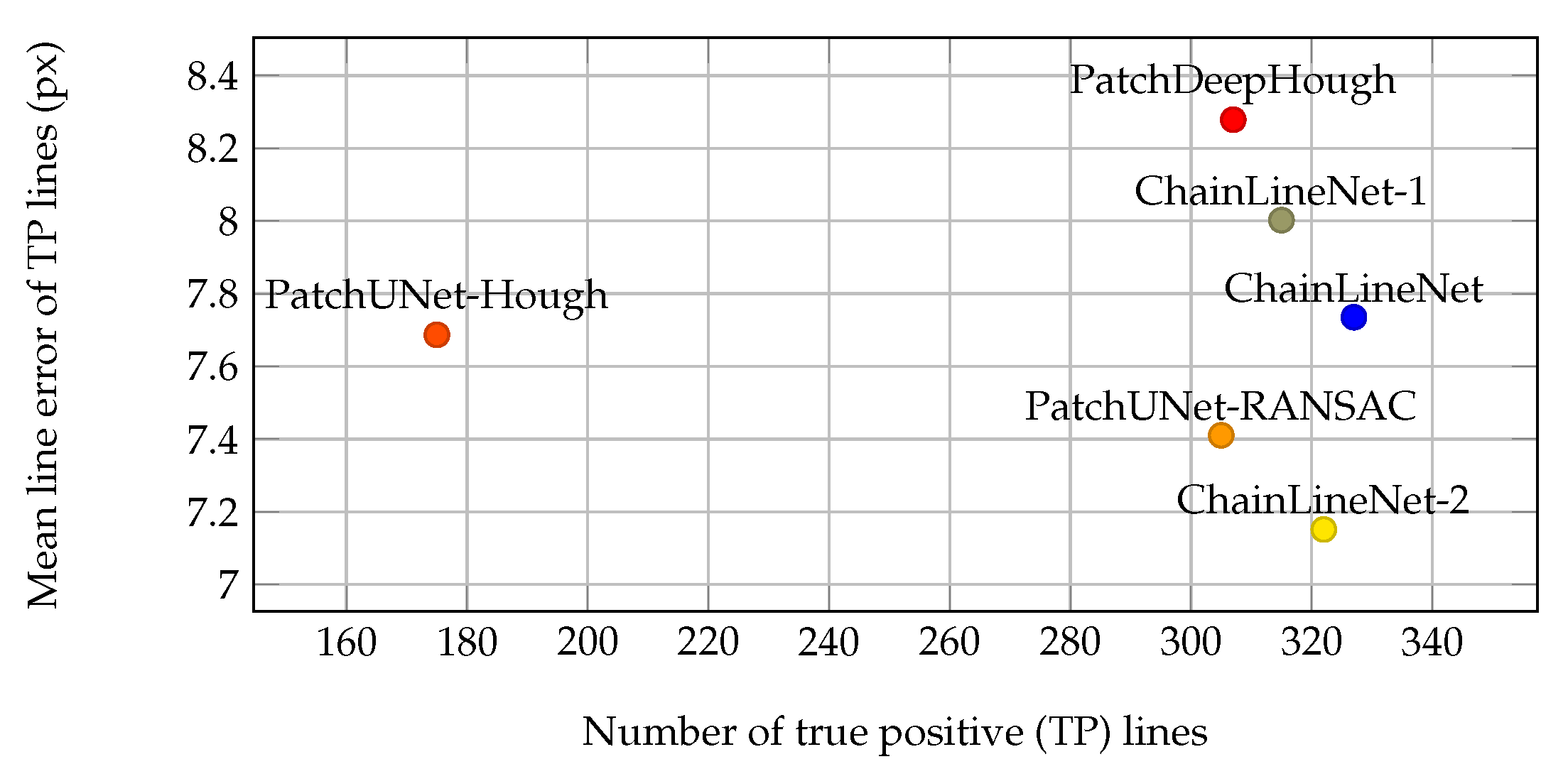
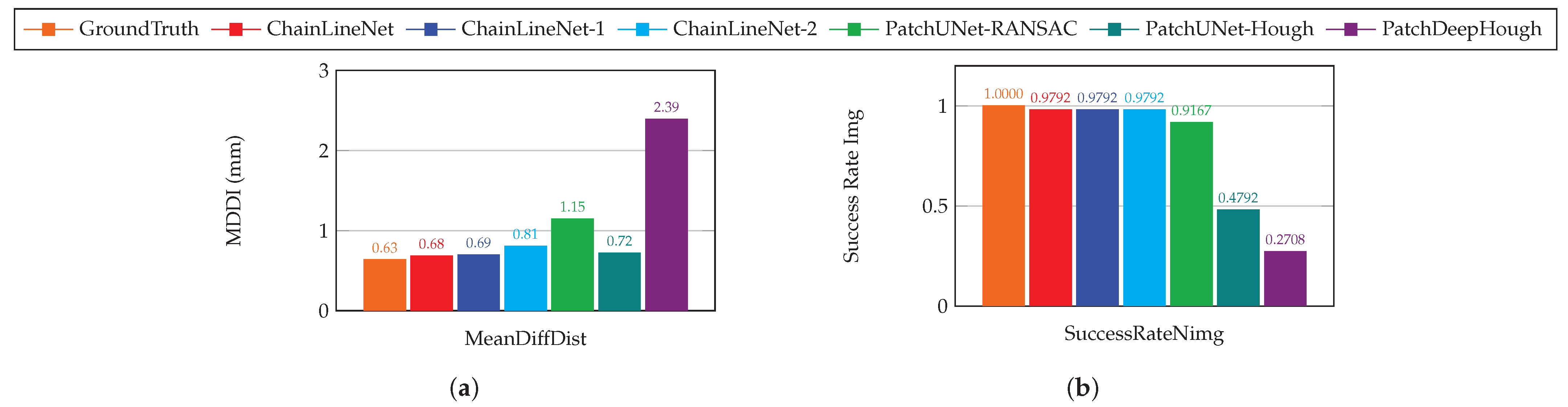
4.4. Evaluation of Line Detection and Parameterization
4.4.1. Ablation Study
4.4.2. Comparison to the State-of-the-Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Johnson, C.R.; Sethares, W.A.; Ellis, M.H.; Haqqi, S. Hunting for Paper Moldmates Among Rembrandt’s Prints: Chain-line pattern matching. IEEE Signal Process. Mag. 2015, 32, 28–37. [Google Scholar] [CrossRef]
- Hiary, H.; Ng, K. A system for segmenting and extracting paper-based watermark designs. Int. J. Digit. Libr. 2007, 351–361. [Google Scholar] [CrossRef]
- van der Lubbe, J.; Someren, E.; Reinders, M.J. Dating and Authentication of Rembrandt’s Etchings with the Help of Computational Intelligence. In Proceedings of the International Cultural Heritage Informatics Meeting (ICHIM), Milan, Italy, 3–7 September 2001; pp. 485–492. [Google Scholar]
- Atanasiu, V. Assessing paper origin and quality through large-scale laid lines density measurements. In Proceedings of the 26th Congress of the International Paper Historians Association, Rome/Verona, Italy, 30 August–6 September 2002; pp. 172–184. [Google Scholar]
- van Staalduinen, M.; van der Lubbe, J.; Backer, E.; Paclík, P. Paper Retrieval Based on Specific Paper Features: Chain and Laid Lines. In Proceedings of the Multimedia Content Representation, Classification and Security (MRCS) 2006, Istanbul, Turkey, 11–13 September 2006; pp. 346–353. [Google Scholar] [CrossRef]
- Biendl, M.; Sindel, A.; Klinke, T.; Maier, A.; Christlein, V. Automatic Chain Line Segmentation in Historical Prints. In Proceedings of the Pattern Recognition, ICPR International Workshops and Challenges, Milan, Italy, 10–15 January 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 657–665. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2015, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Huang, K.; Wang, Y.; Zhou, Z.; Ding, T.; Gao, S.; Ma, Y. Learning to Parse Wireframes in Images of Man-Made Environments. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 626–635. [Google Scholar] [CrossRef]
- Zhou, Y.; Qi, H.; Ma, Y. End-to-End Wireframe Parsing. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Xue, N.; Wu, T.; Bai, S.; Wang, F.; Xia, G.S.; Zhang, L.; Torr, P.H. Holistically-Attracted Wireframe Parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Lin, Y.; Pintea, S.L.; van Gemert, J.C. Deep Hough-Transform Line Priors. In Proceedings of the European Conference on Computer Vision (ECCV) 2020, Glasgow, UK, 23–28 August 2020; Volume 12367, pp. 323–340. [Google Scholar] [CrossRef]
- Lee, J.T.; Kim, H.U.; Lee, C.; Kim, C.S. Semantic Line Detection and Its Applications. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3249–3257. [Google Scholar] [CrossRef]
- Zhao, K.; Han, Q.; Zhang, C.B.; Xu, J.; Cheng, M.M. Deep Hough Transform for Semantic Line Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. LS-Net: Fast single-shot line-segment detector. Mach. Vis. Appl. 2020, 1432–1769. [Google Scholar] [CrossRef]
- Brachmann, E.; Rother, C. Neural-Guided RANSAC: Learning Where to Sample Model Hypotheses. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4321–4330. [Google Scholar] [CrossRef] [Green Version]
- Brachmann, E.; Krull, A.; Nowozin, S.; Shotton, J.; Michel, F.; Gumhold, S.; Rother, C. DSAC—Differentiable RANSAC for Camera Localization. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Li, Y.; Yan, X.; Cao, F. ContourGAN: Image contour detection with generative adversarial network. Knowl.-Based Syst. 2019, 164, 21–28. [Google Scholar] [CrossRef]
- Sindel, A.; Maier, A.; Christlein, V. Art2Contour: Salient Contour Detection in Artworks Using Generative Adversarial Networks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 788–792. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; Volume 9906, pp. 694–711. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Lin, Z.; Mech, R.; Yumer, E.; Ramanan, D. Photo-Sketching: Inferring Contour Drawings from Images. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1403–1412. [Google Scholar] [CrossRef] [Green Version]
- Maier, A.; Syben, C.; Stimpel, B.; Würfl, T.; Hoffmann, M.; Schebesch, F.; Fu, W.; Mill, L.; Kling, L.; Christiansen, S. Learning with known operators reduces maximum error bounds. Nat. Mach. Intell. 2019, 1, 2522–5839. [Google Scholar] [CrossRef] [PubMed]
- Linnet, K. Performance of Deming regression analysis in case of misspecified analytical error ratio in method comparison studies. Clin. Chem. 1998, 44, 1024–1031. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | Dice Coefficient |
|---|---|---|---|
| UNet (F ) | 0.4046 | 0.5070 | 0.4464 |
| UNet (F ) | 0.3958 | 0.5034 | 0.4392 |
| UNet-GAN (F ) | 0.4283 | 0.4787 | 0.4437 |
| UNet-GAN (F ) | 0.3829 | 0.4591 | 0.4108 |
| ResNet-E-D (F ) | 0.3855 | 0.5935 | 0.4628 |
| ResNet-GAN (F ) | 0.3920 | 0.6001 | 0.4696 |
| Number of Lines | TP | FP | FN | Precision (%) | Recall (%) | Score (%) | |
|---|---|---|---|---|---|---|---|
| Ground truth (manually annotated) | 342 | 342 | 0 | 0 | 100.00 | 100.00 | 100.00 |
| Reference (manually measured) | 339 | 339 | 0 | 3 | 100.00 | 99.12 | 99.56 |
| PatchDeepHough | 528 | 307 | 221 | 35 | 58.14 | 89.77 | 70.57 |
| PatchUNet-Hough | 228 | 175 | 53 | 162 | 76.75 | 51.93 | 61.95 |
| PatchUNet-RANSAC | 325 | 305 | 20 | 32 | 93.85 | 90.50 | 92.15 |
| ChainLineNet-1 (BCE+DICE+DSAC) | 323 | 315 | 8 | 27 | 97.52 | 92.11 | 94.74 |
| ChainLineNet-2 (BCE+DICE) | 330 | 322 | 8 | 20 | 97.58 | 94.15 | 95.83 |
| ChainLineNet (BCE+DICE+DSAC+MLE) | 333 | 327 | 6 | 15 | 98.20 | 95.61 | 96.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sindel, A.; Klinke, T.; Maier, A.; Christlein, V. ChainLineNet: Deep-Learning-Based Segmentation and Parameterization of Chain Lines in Historical Prints. J. Imaging 2021, 7, 120. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070120
Sindel A, Klinke T, Maier A, Christlein V. ChainLineNet: Deep-Learning-Based Segmentation and Parameterization of Chain Lines in Historical Prints. Journal of Imaging. 2021; 7(7):120. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070120
Chicago/Turabian StyleSindel, Aline, Thomas Klinke, Andreas Maier, and Vincent Christlein. 2021. "ChainLineNet: Deep-Learning-Based Segmentation and Parameterization of Chain Lines in Historical Prints" Journal of Imaging 7, no. 7: 120. https://0-doi-org.brum.beds.ac.uk/10.3390/jimaging7070120