
Deep Learning Using Multiple Degrees of Maximum-Intensity Projection for PET/CT Image Classification in Breast Cancer

 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Patients
2.2. PET/CT Protocols
2.3. Data Set
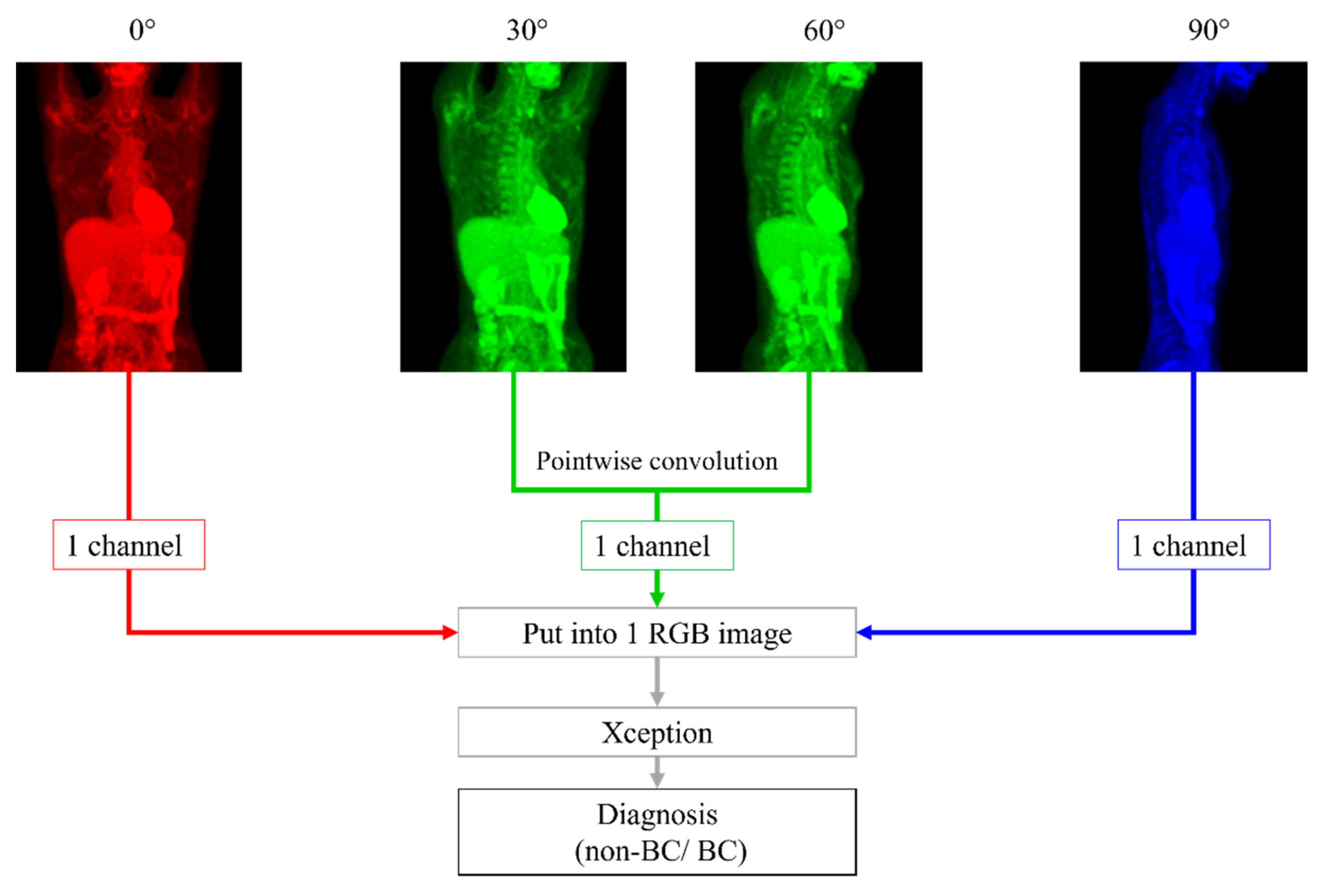
2.4. Image Processing
2.5. DL Methods
2.6. Radiologists’ Readout
2.7. Statistical Analysis
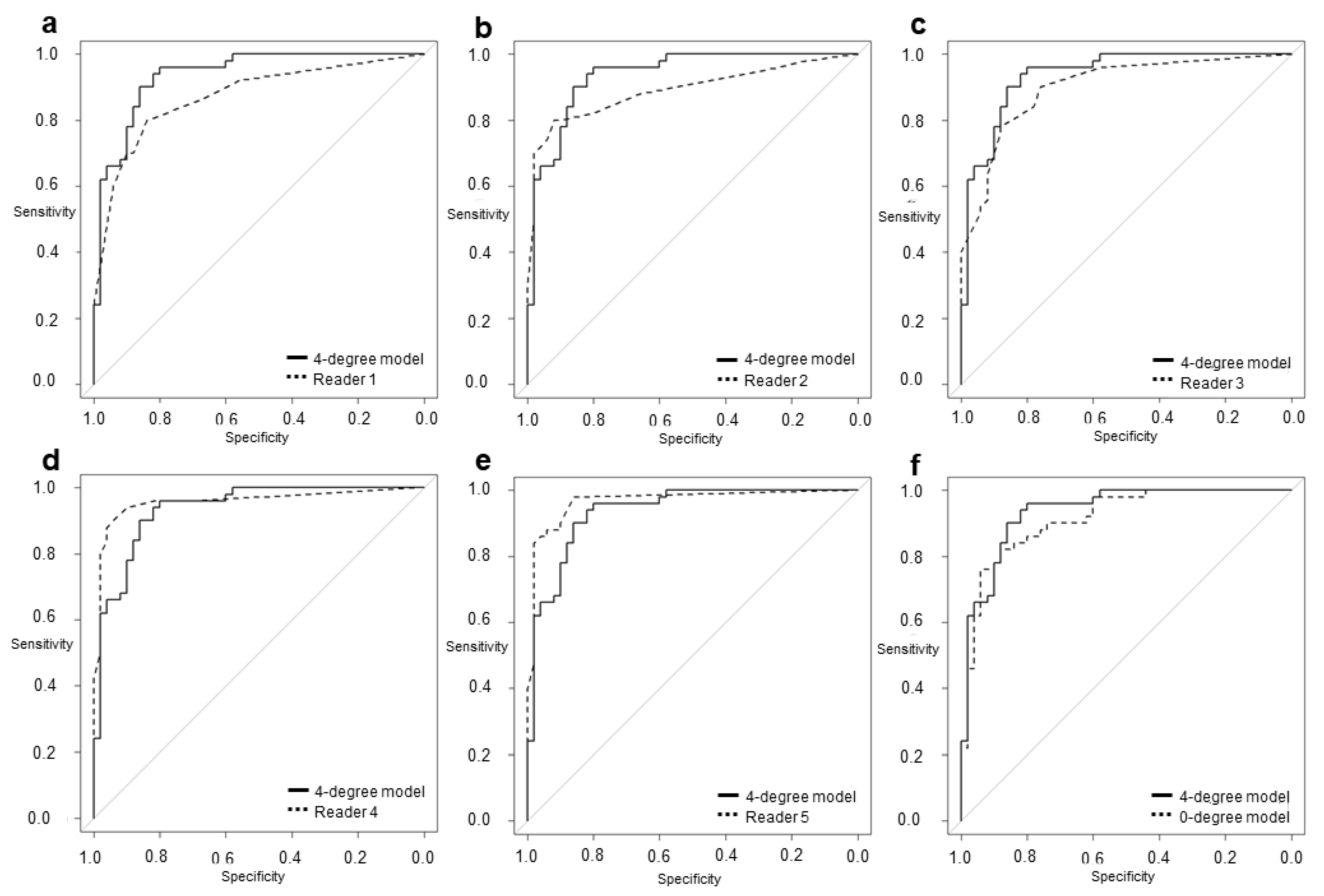
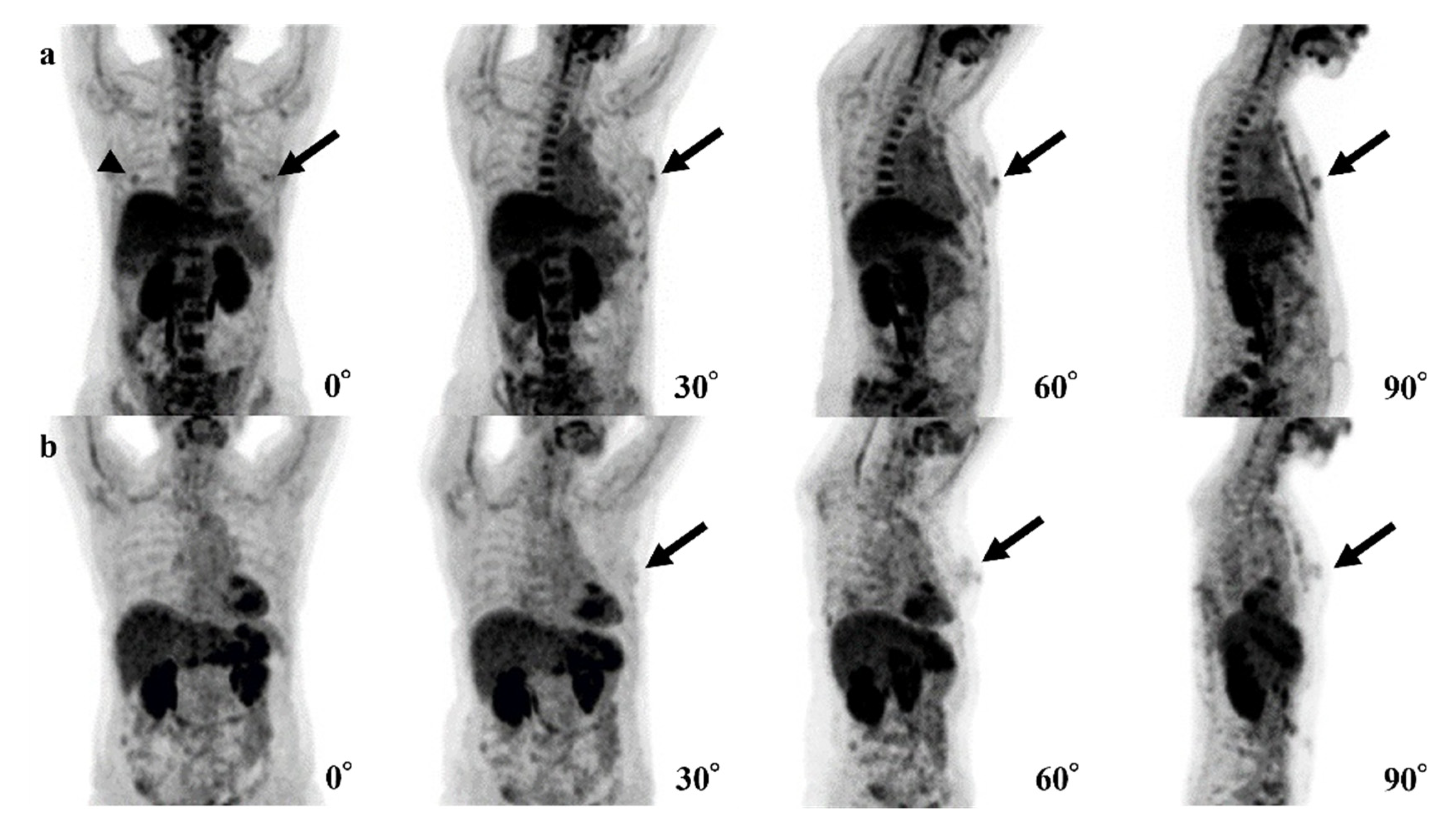
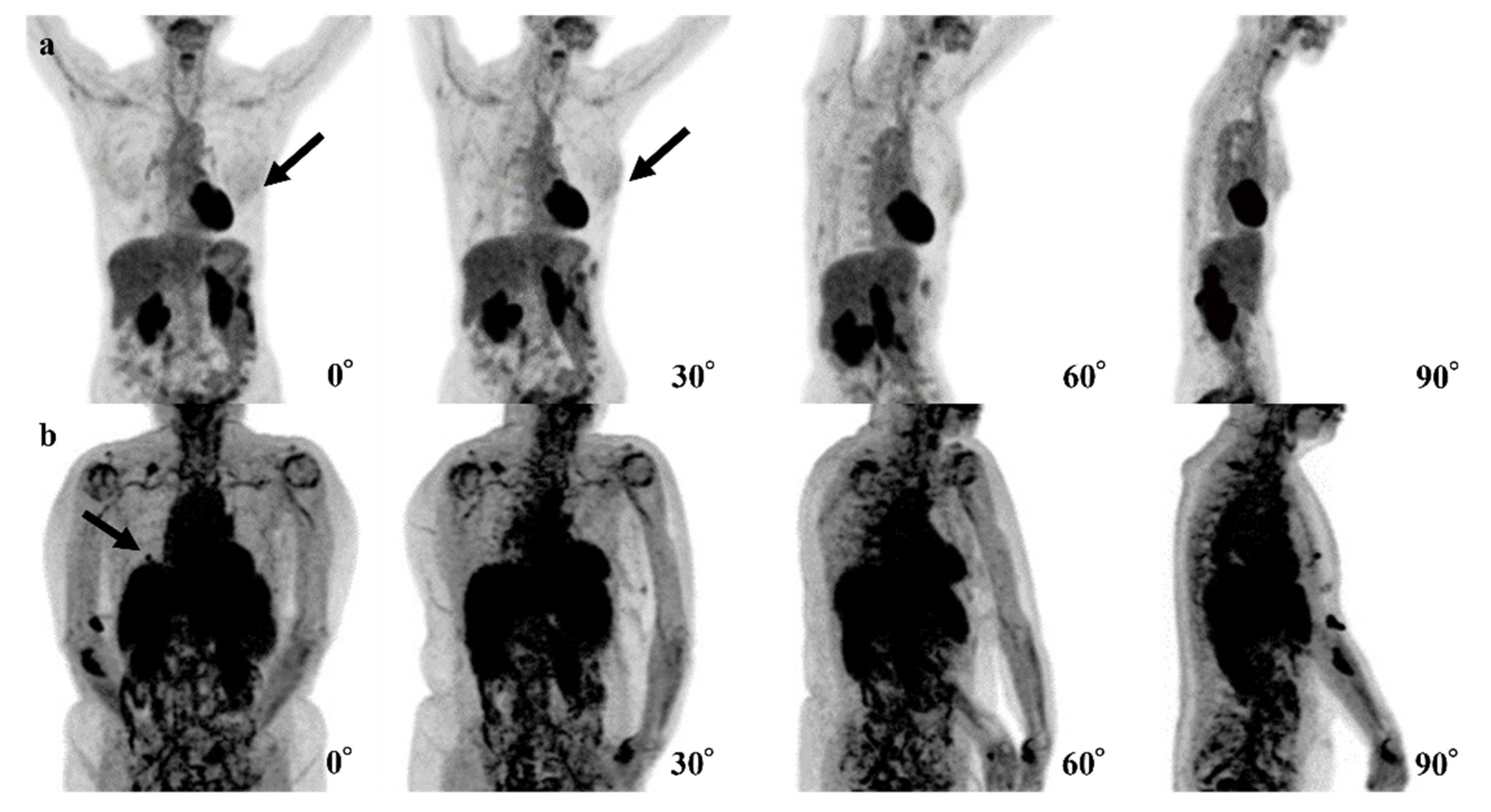
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2020. CA Cancer J. Clin. 2020, 70, 7–30. [Google Scholar] [CrossRef]
- Mori, M.; Fujioka, T.; Katsuta, L.; Tsuchiya, J.; Kubota, K.; Kasahara, M.; Oda, G.; Nakagawa, T.; Onishi, I.; Tateishi, U. Diagnostic performance of time-of-flight PET/CT for evaluating nodal metastasis of the axilla in breast cancer. Nucl. Med. Commun. 2019, 40, 958–964. [Google Scholar] [CrossRef]
- Fujioka, T.; Kubota, K.; Kikuchi, Y.; Tsuchiya, J.; Tateishi, U.; Kasaharak, M.; Oda, G.; Ishiba, T.; Nakagawa, T. The feasibility of using 18F-FDG-PET/CT in patients with mucinous breast carcinoma. Nucl. Med. Commun. 2018, 39, 1033–1038. [Google Scholar] [CrossRef]
- Paydary, K.; Seraj, S.M.; Zadeh, M.Z.; Emamzadehfard, S.; Shamchi, S.P.; Gholami, S.; Werner, T.J.; Alavi, A. The evolving role of FDG-PET/CT in the diagnosis, staging, and treatment of breast cancer. Mol. Imaging Biol. 2019, 21, 1–10. [Google Scholar] [CrossRef]
- Ishiba, T.; Nakagawa, T.; Sato, T.; Nagahara, M.; Oda, G.; Sugimoto, H.; Kasahara, M.; Hosoya, T.; Kubota, K.; Fujioka, T.; et al. Efficiency of fluorodeoxyglucose positron emission tomography/computed tomography to predict prognosis in breast cancer patients received neoadjuvant chemotherapy. Springerplus 2015, 4, 817. [Google Scholar] [CrossRef] [Green Version]
- Benveniste, A.P.; Marom, E.M.; Benveniste, M.F.; Mawlawi, O.; Fox, P.S.; Yang, W. Incidental primary breast cancer detected on PET-CT. Breast Cancer Res. Treat. 2015, 151, 261–268. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Fujioka, T.; Kubota, K.; Mori, M.; Kikuchi, Y.; Katsuta, L.; Kasahara, M.; Oda, G.; Ishiba, T.; Nakagawa, T.; Tateishi, U. Distinction between benign and malignant breast masses at breast ultrasound using deep learning method with convolutional neural network. Jpn. J. Radiol. 2019, 37, 466–472. [Google Scholar] [CrossRef] [PubMed]
- Mori, M.; Fujioka, T.; Katsuta, L.; Kikuchi, Y.; Oda, G.; Nakagawa, T.; Kitazume, Y.; Kubota, K.; Tateishi, U. Feasibility of new fat suppression for breast MRI using pix2pix. Jpn. J. Radiol. 2020, 38, 1075–1081. [Google Scholar] [CrossRef]
- Fujioka, T.; Mori, M.; Kubota, K.; Kikuchi, Y.; Katsuta, L.; Adachi, M.; Oda, G.; Nakagawa, T.; Kitazume, Y.; Tateishi, U. Breast ultrasound image synthesis using deep convolutional generative adversarial networks. Diagnostics 2019, 9, 176. [Google Scholar] [CrossRef] [Green Version]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Fujioka, T.; Yashima, Y.; Oyama, J.; Mori, M.; Kubota, K.; Katsuta, L.; Kimura, K.; Yamaga, E.; Oda, G.; Nakagawa, T.; et al. Deep-learning approach with convolutional neural network for classification of maximum intensity projections of dynamic contrast-enhanced breast magnetic resonance imaging. Magn. Reson. Imaging 2021, 75, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.-Q.; Wu, X.-L.; Huang, S.-Y.; Wu, G.-G.; Ye, H.-R.; Wei, Q.; Bao, L.Y.; Deng, Y.B.; Li, X.R.; Cui, X.W.; et al. Lymph node metastasis prediction from primary breast cancer US images using deep learning. Radiology 2020, 294, 19–28. [Google Scholar] [CrossRef] [PubMed]
- Moreau, N.; Rousseau, C.; Fourcade, C.; Santini, G.; Ferrer, L.; Lacombe, M.; Guillerminet, C.; Campone, M.; Colombie, M.; Rubeaux, M.; et al. Deep learning approaches for bone and bone lesion segmentation on 18FDG PET/CT imaging in the context of metastatic breast cancer. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 1532–1535. [Google Scholar]
- Jia, D.; Chen, C.; Chen, C.; Chen, F.; Zhang, N.; Yan, Z.; Lv, X. Breast cancer case identification based on deep learning and bioinformatics analysis. Front. Genet. 2021, 12, 628136. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ye, T.; Wang, B.; Song, P.; Li, J. Automatic railway traffic object detection system using feature fusion refine neural network under shunting mode. Sensors 2018, 18, 1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tu, X.; Xu, C.; Liu, S.; Lin, S.; Chen, L.; Xie, G.; Li, R. LiDAR point cloud recognition and visualization with deep Learning for overhead contact inspection. Sensors 2020, 20, 6387. [Google Scholar] [CrossRef]
- Kanda, Y. Investigation of the freely available easy-to-use software “EZR” for medical statistics. Bone Marrow Transplant. 2013, 48, 452–458. [Google Scholar] [CrossRef] [Green Version]
- Puth, M.T.; Neuhäuser, M.; Ruxton, G.D. Effective use of Pearson’s product–moment correlation coefficient. Anim. Behav. 2014, 93, 183–189. [Google Scholar] [CrossRef]
- DeLong, E.R.; DeLong, D.M.; Clarke-Pearson, D.L. Comparing the areas under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Lång, K.; Dustler, M.; Dahlblom, V.; Åkesson, A.; Andersson, I.; Zackrisson, S. Identifying normal mammograms in a large screening population using artificial intelligence. Eur. Radiol. 2021, 31, 1687–1692. [Google Scholar] [CrossRef]
- Hickman, S.E.; Baxter, G.C.; Gilbert, F.J. Adoption of artificial intelligence in breast imaging: Evaluation, ethical constraints and limitations. Br. J. Cancer 2021, 125, 15–22. [Google Scholar] [CrossRef]
- Fujioka, T.; Mori, M.; Kubota, K.; Oyama, J.; Yamaga, E.; Yashima, Y.; Katsuta, L.; Nomura, K.; Nara, M.; Oda, G.; et al. The utility of deep learning in breast ultrasonic imaging: A review. Diagnostics 2020, 10, 1055. [Google Scholar] [CrossRef]
- Raya-Povedano, J.L.; Romero-Martín, S.; Elías-Cabot, E.; Gubern-Mérida, A.; Rodríguez-Ruiz, A.; Álvarez-Benito, M. AI-based strategies to reduce workload in breast cancer screening with mammography and tomosynthesis: A retrospective evaluation. Radiology 2021, 300, 57–65. [Google Scholar] [CrossRef]
- Hosni, M.; Abnane, I.; Idri, A.; Carrillo de Gea, J.M.; Fernández Alemán, J.L. Reviewing ensemble classification methods in breast cancer. Comput. Methods Progr. Biomed. 2019, 177, 89–112. [Google Scholar] [CrossRef]
- Nobashi, T.; Zacharias, C.; Ellis, J.K.; Ferri, V.; Koran, M.E.; Franc, B.L.; Iagaru, A.; Davidzon, G.A. Performance comparison of individual and ensemble CNN models for the classification of brain 18F-FDG-PET scans. J. Digit. Imaging 2020, 33, 447–455. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
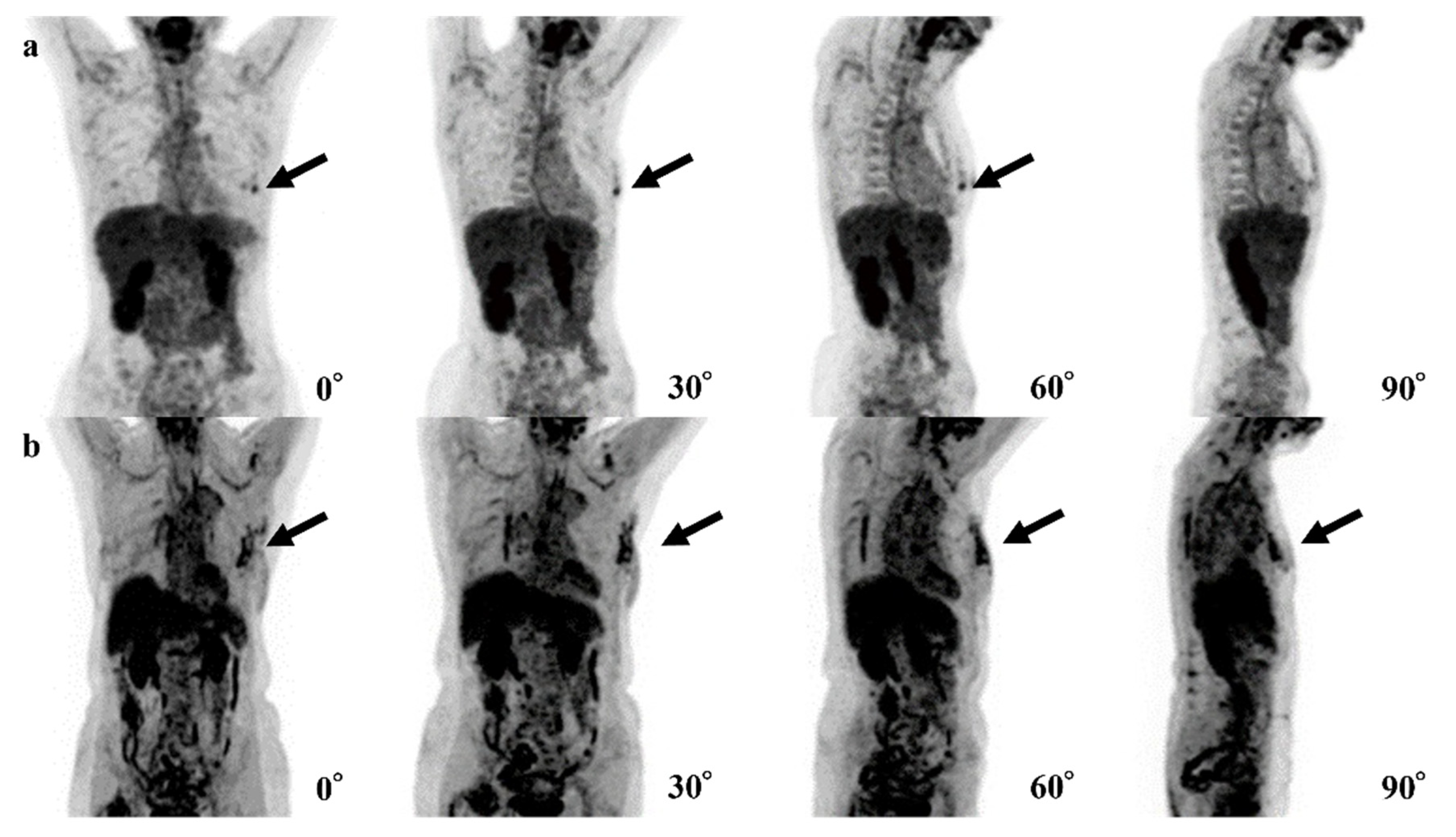{kind=link}
| Clinical T Category | Diameter of Invasion (x cm) | Training Data (n) | Test Data (n) | |
|---|---|---|---|---|
| T1 | T1a | 0.1 < x ≤ 0.5 | 2 | 0 |
| T1b | 0.5 < x ≤ 1.0 | 18 | 3 | |
| T1c | 1.0 < x ≤ 2.0 | 130 | 27 | |
| T2 | 2.0 < x ≤ 5.0 | 44 | 19 | |
| T3 | 5.0 < x | 6 | 4 | |
| Total | 200 | 50 | ||
| Reader 1 | Reader 2 | Reader 3 | Reader 4 | Reader 5 | 0-deg | 4-deg | |
|---|---|---|---|---|---|---|---|
| Reader 1 | 1 | 0.823 | 0.708 | 0.803 | 0.733 | 0.713 | 0.754 |
| Reader 2 | 0.823 | 1 | 0.786 | 0.896 | 0.823 | 0.693 | 0.6937 |
| Reader 3 | 0.708 | 0.786 | 1 | 0.754 | 0.723 | 0.581 | 0.563 |
| Reader 4 | 0.803 | 0.896 | 0.754 | 1 | 0.896 | 0.718 | 0.741 |
| Reader 5 | 0.733 | 0.823 | 0.723 | 0.896 | 1 | 0.682 | 0.709 |
| 0-deg | 0.713 | 0.693 | 0.581 | 0.718 | 0.682 | 1 | 0.910 |
| 4-deg | 0.754 | 0.697 | 0.563 | 0.742 | 0.709 | 0.910 | 1 |
| Comparison was performed with the Pearson product-moment correlation coefficient. All interobserver agreements were significant (p < 0.001). | |||||||
| Model or Radiologist | Cut-off | Sp | Sn | AUC | 95% CI | p Value |
|---|---|---|---|---|---|---|
| 4-degree model | 0.52 | 0.80 | 0.96 | 0.936 | 0.890–0.982 | — |
| 0-degree model | 0.51 | 0.88 | 0.82 | 0.918 | 0.859–0.968 | 0.078 |
| Reader 1 | 0.50 | 0.84 | 0.80 | 0.872 | 0.804–0.941 | 0.036 |
| Reader 2 | 0.40 | 0.92 | 0.80 | 0.891 | 0.824–0.957 | 0.189 |
| Reader 3 | 0.10 | 0.76 | 0.90 | 0.900 | 0.841–0.960 | 0.332 |
| Reader 4 | 0.20 | 0.90 | 0.94 | 0.957 | 0.916–0.999 | 0.405 |
| Reader 5 | 0.10 | 0.86 | 0.98 | 0.967 | 0.934–1.000 | 0.237 |
| Case | Age | SUVmax | Breast Density | Size of Invasive Components (mm) | Total Tumor Size (mm) | Pathology and Subtype | ER | PgR | HER2 | Ki67 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 44 | 2.0 | Heterogeneously | 11 | 11 | IDC | + | + | - | 9.1% |
| 2 | 70 | 0.9 | Scattered | None | 0.6 | DCIS | + | - | + | 15.4% |
| 3 | 70 | 1.2 | Heterogeneously | None | 8 | DCIS | + | + | + | 12.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takahashi, K.; Fujioka, T.; Oyama, J.; Mori, M.; Yamaga, E.; Yashima, Y.; Imokawa, T.; Hayashi, A.; Kujiraoka, Y.; Tsuchiya, J.; et al. Deep Learning Using Multiple Degrees of Maximum-Intensity Projection for PET/CT Image Classification in Breast Cancer. Tomography 2022, 8, 131-141. https://0-doi-org.brum.beds.ac.uk/10.3390/tomography8010011
Takahashi K, Fujioka T, Oyama J, Mori M, Yamaga E, Yashima Y, Imokawa T, Hayashi A, Kujiraoka Y, Tsuchiya J, et al. Deep Learning Using Multiple Degrees of Maximum-Intensity Projection for PET/CT Image Classification in Breast Cancer. Tomography. 2022; 8(1):131-141. https://0-doi-org.brum.beds.ac.uk/10.3390/tomography8010011
Chicago/Turabian StyleTakahashi, Kanae, Tomoyuki Fujioka, Jun Oyama, Mio Mori, Emi Yamaga, Yuka Yashima, Tomoki Imokawa, Atsushi Hayashi, Yu Kujiraoka, Junichi Tsuchiya, and et al. 2022. "Deep Learning Using Multiple Degrees of Maximum-Intensity Projection for PET/CT Image Classification in Breast Cancer" Tomography 8, no. 1: 131-141. https://0-doi-org.brum.beds.ac.uk/10.3390/tomography8010011