Revocable Identity-Based Encryption and Server-Aided Revocable IBE from the Computational Diffie-Hellman Assumption †


Abstract
:1. Introduction
1.1. Our Contributions
- Weaker security assumption. The securities of our RIBE and SR-IBE schemes can be reduced to the CDH assumption. Hence our schemes serve as the first RIBE/SR-IBE schemes from the CDH assumption over non-pairing groups. More precisely, our first RIBE scheme can achieve adaptive-IND-ID-CPA security but without the property of decryption key exposure resistance(DKER). Our second RIBE scheme obtains decryption key exposure resistance but with selective-IND-ID-CPA security. Our SR-IBE scheme is selective-SR-ID-CPA secure. The securities of the three schemes can be reduced to the CDH assumption.
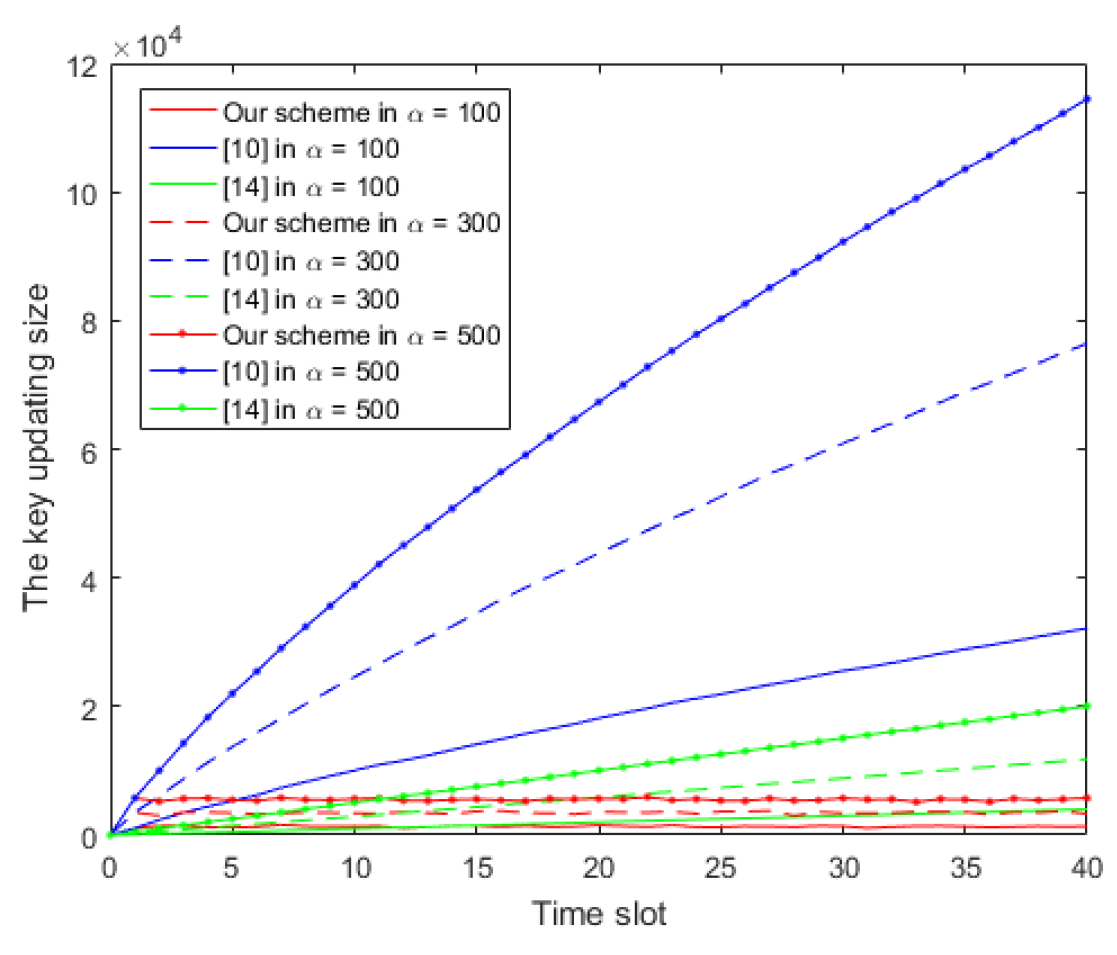
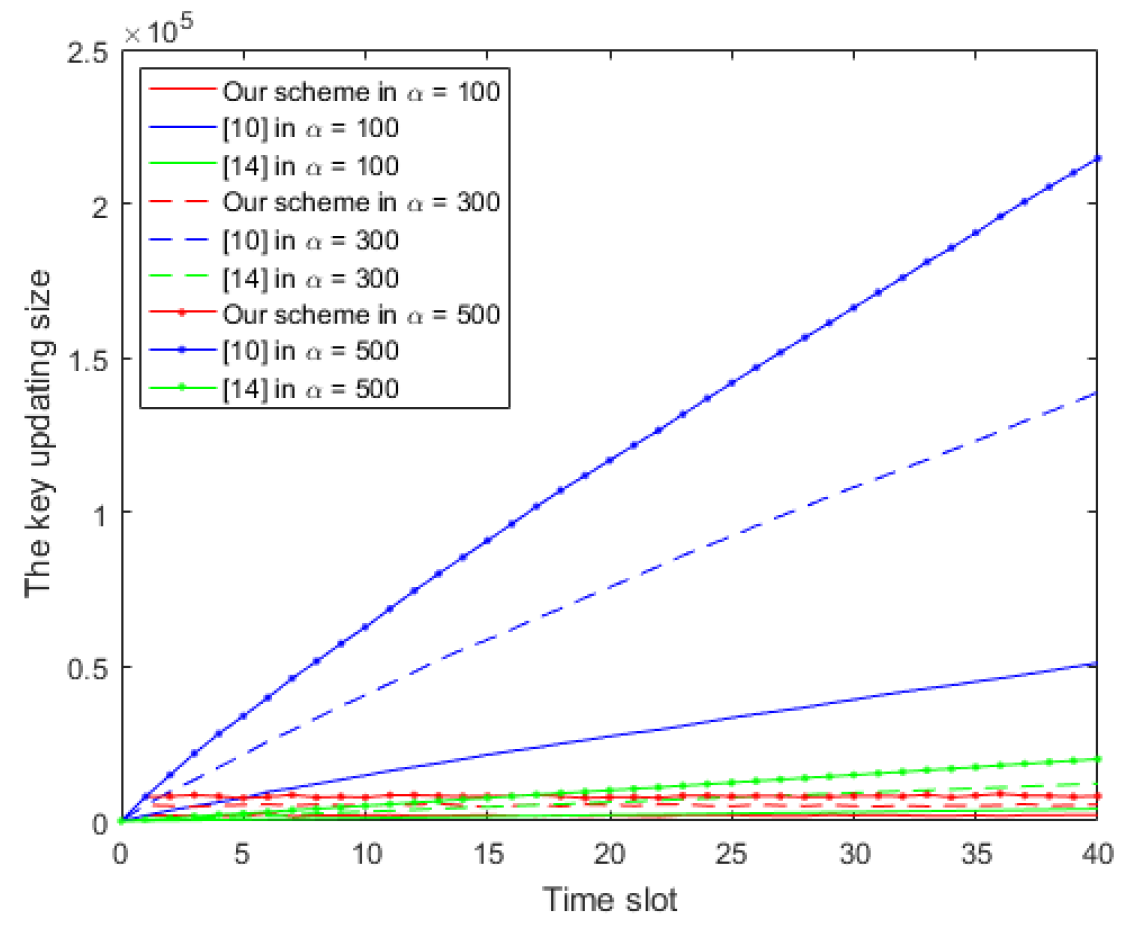
- Smaller size of key updating. When a time slot begins, the key updating algorithm of our RIBE/SR-IBE will issue updating keys whose size is only linear to the number of newly revoked users in the past time slot. In comparison, most of the existing RIBE/SR-IBE schemes have to update keys whose number is related to the number of all revoked users across all the previous time slots.
1.2. Paper Organization
2. Preliminaries
2.1. Notations
2.2. Pseudorandom Functions
2.3. Revocable Identity-Based Encryption
- Setup: The setup algorithm is run by the key authority. The input of the algorithm is a security parameter and n, where the maximal number of users is . The output of this algorithm consists of a pair of key , an initial state st = (KL, PL, RL, KU), where KL is the key list, PL is the list of public information, RL is the list of revoked users and KU is the update key list. In formula,
- Private Key Generation: This algorithm is run by the key authority which takes as input the key pair , an identity and the state st. The output of this algorithm is a private key and an updated state . In formula, .
- Key Update Generation: This algorithm is run by the authority. Given the key pair , an update time , and a state st, this algorithm updates the update key list and the the list of public information . In formula, .
- Decryption key generation: This algorithm is run by the receiver. Given the master public key , a private key , the update key list and the time slot , this algorithm outputs a decryption key for time slot . In formula,
- Encryption: This algorithm is run by the sender. Given the public key , a public list PL, an identity id, a time slot and a message m, this algorithm outputs a ciphertext . In formula, .
- Decryption: This algorithm is run by the receiver. The algorithm takes as input the master public key , the decryption key and the ciphertext , and outputs a message m or a failure symbol ⊥. In formula, .
- Revocation: This algorithm is run by the key authority. Given a revoked identity and the time slot during which is revoked and a state , this algorithm updates the revocation list with . It outputs a new state .
- The two plaintexts submitted by have the same length, i.e., .
- The time slot submitted to and by is in ascending order.
- If the challenger has published at time , then it is not allowed to query oracle with .
- If has queried to oracle , then there must be query to oracle satisfies , i.e., must has been revoked before time .
- If is not revoked at time , cannot be queried on .
| . |
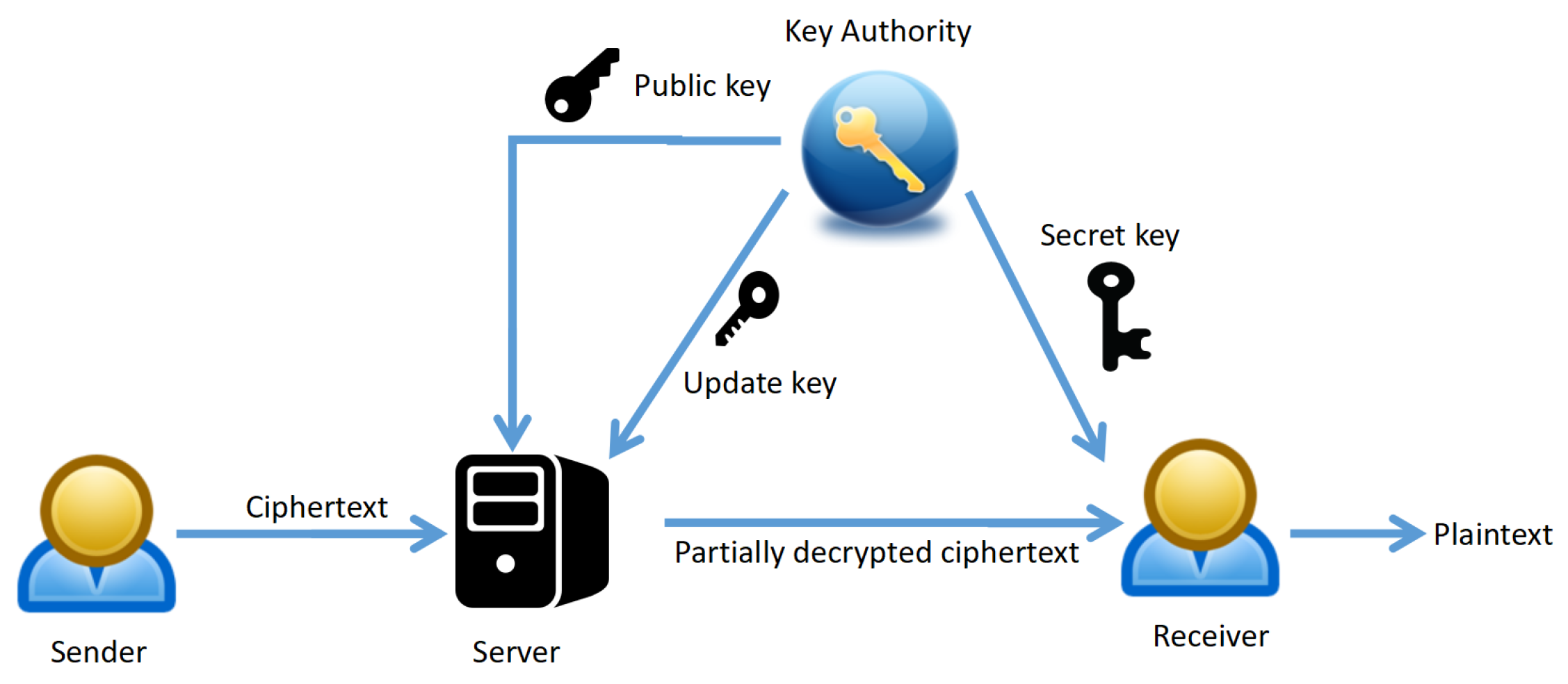
2.4. Server-Aided Revocable Identity-Based Encryption
- Key Authority generates a public key and a secret key for every registered user and issues the secret key to the user and the public key to the server. In each time slot, the key authority delivers a update key list (to revoke users) to the server.
- Sender encrypts a message for an identity and a time slot and sends the ciphertext to the server.
- Sever combines the update key list and the stored users’ public keys to generate the transformation keys in every time slot for all users. When receiving a ciphertext, the server transforms it to a partially decrypted ciphertext using the transformation key corresponding to the receiver’s identity and the corresponding time slot. Then it sends the partially decrypted ciphertext to the receiver.
- Receiver recovers the sender’s message from the partially decrypted ciphertext using a decryption key which can be generated by his/her own secret key and the corresponding time slot.
- Setup: The setup algorithm is run by the key authority. The input of the algorithm is a security parameter and a parameter n, which indicates that the maximal number of users is . The output of this algorithm consists of a pair of key and an initial state , where is the key list, is the list of public information, is the list of revoked users and is the update key list. In formula,
- Public Key Generation: The public key generation algorithm is run by the key authority. It takes as input a master secret key , an identity and a state . The output of this algorithm is the public key on identity . In formula, .
- Key Update Generation: The key update generation algorithm is run by the key authority. It takes as input a master secret key , an update time and a state . The output of this algorithm is an update key list and an updated state . In formula, .
- Transformation Key Generation: The transformation key generation algorithm is run by the server. It takes as input the master public key , the public key and an update key list . The output of this algorithm is the transformation key . In formula, .
- Private Key Generation: The private key generation algorithm is run by the key authority. It takes the master secret key and an identity as input. The output of this algorithm is the private key on identity . In formula, .
- Decryption Key Generation: The decryption key generation algorithm is run by the receiver. It takes the secret key and a slot as input. The output of this algorithm is the decryption key . In formula, .
- Encryption: The encryption algorithm is run by the sender. It takes the master public key , an identity , a time plot , a plaintext message and a public list as the input. The output of this algorithm is the ciphertext . In formula, .
- Transformation: The transformation algorithm is run by the server. It takes the master public key , the transformation key and the ciphertext as the input. The output of this algorithm is the partially decrypted ciphertext . In formula, .
- Decryption: The decryption algorithm is run by the receiver. The input of this algorithm consists of the master public key , the decryption key and the partially decrypted ciphertext . The output of this algorithm is the plaintext . In formula, .
- Revocation: The revocation algorithm is run by the key authority. The input of this algorithm consists of an identity , a time plot and a state . The output of this algorithm is the updated state . In formula, .
| . |
- The two plaintexts submitted by have the same length, i.e., .
- The time slot submitted to and by is in ascending order.
- If the challenger has published at time , then it is not allowed to query oracle with .
- If has queried to oracle , then there must exist a query to oracle satisfying , i.e., must has been revoked before time .
- If is not revoked at time , cannot be queried on .
2.5. Garbled Circuits
- : The algorithm takes a security parameter and a circuit as input. This algorithm outputs a garbled circuit and labels where each . Here represents the set [ℓ] where ℓ is the bit-length of the input of the circuit .
- : The algorithm takes as input a garbled circuit and a set of label , and it outputs y.
2.6. Computational Diffie-Hellman Assumption
2.7. Chameleon Encryption
- HGen: The algorithm takes the security parameter and a message-length n as input. This algorithm outputs a key k and a trapdoor t.
- H: The algorithm takes the key k, a message and a randomness r as input. This algorithm outputs a hash value h and the length of h is .
- : The algorithm takes a trapdoor t, a previously used message , random coins r and a message as input. It outputs .
- HEnc: The algorithm takes a key k, a hash value h, an index , a bit , and a message as input. It outputs a ciphertext .
- HDec: The algorithm takes a key k, a message , a randomness r and a ciphertext as input. It outputs a value m or ⊥.
- Uniformity. For all ,if both r and are chosen uniformly at random, the two distribution and are statistically indistinguishable.
- Trapdoor Collisions. For any and r, if and , then it holds that Moreover, if r is chosen uniformly and randomly, is statistically close to uniform.
- Correctness. For all , randomness r, index and message m, if , and , then
- Security. For a PPT adversary against a chameleon encryption, consider the following experiment:The security of a chameleon encryption defines as follows: For any PPT adversary , the advantage of in experiment satisfies
3. Idea of Our Revocable IBE Scheme
3.1. Idea of the DG Scheme
- (1)
- is a circuit with m hardwired and its input is . It computes and outputs the ciphertext of message m under the public-key .
- (2)
- is a circuit which hardwires bit , key k and a serial of labels . It computes and outputs , where is the short for .
3.2. Idea of Our Revoked IBE Scheme
- If a leaf is revoked during time period , then a new public/secret key pair will generated with for this leaf. As a result, is replaced with a fresh value . This fresh value will not consistent to what the father node of has. Therefore, we have to change the attachments of all nodes along the path from the revoked leaf to root bottom upward.
- For i from down to 0Let . Choose random coins ; ;Here if is not defined, where .
4. Revocable IBE Scheme
- Setup: given a security parameter , an integer n where is the maximal number of users that the scheme supports. Define identity space as and time space as , and do the following.
- Sample .
- For each , invoke .
- Initialize key list , public list , key update list and revocation list .
- ; ; .
- Output .
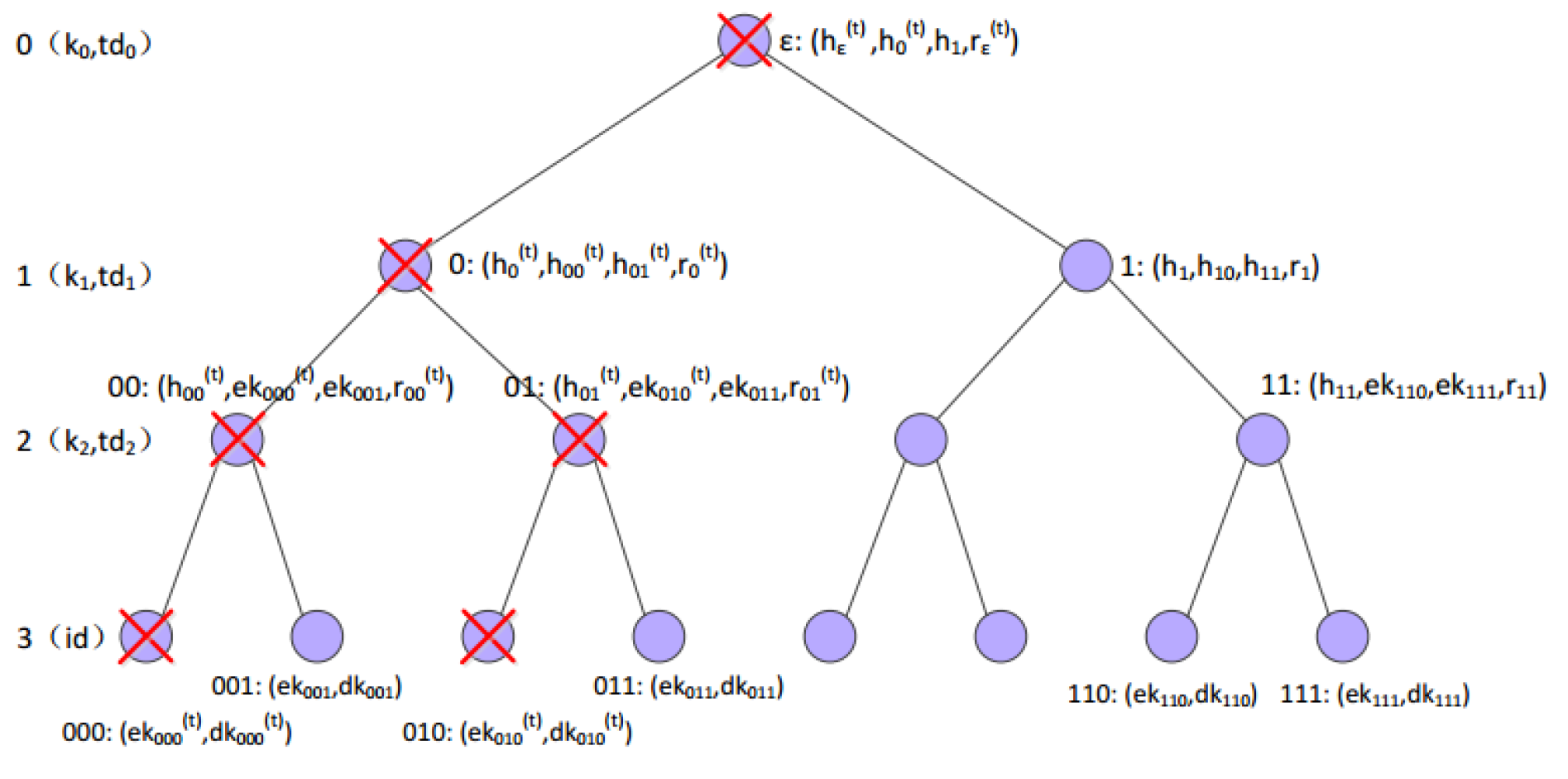
- Private Key Generation See Figure 4 for illustrations.
- Parse and .
- , where is the empty string.
- For all :,,.
- For :,,.
- and .
- Output .
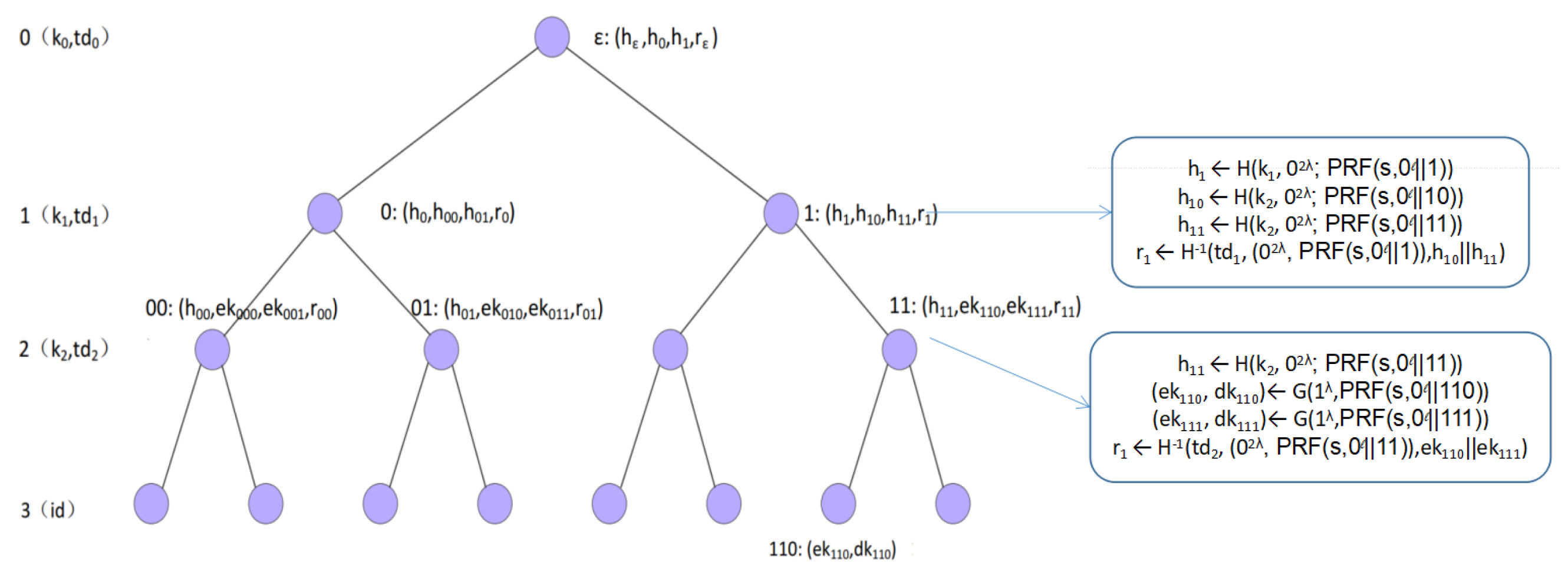
- Key Update Generation: See Figure 5 for illustrations.
- Parse , and .
- . // stores all revoked leaves and their ancestors
- If , Output() //stay unchanged.
- Set key update list .
- For all node such that : // deal with all leaves in Y,. // new attachments for all leaves in Y.
- For to 0: // generate new attachments for all non-leaf nodes in Yall node and :, .()s.t.,;..
- and .
- Output .
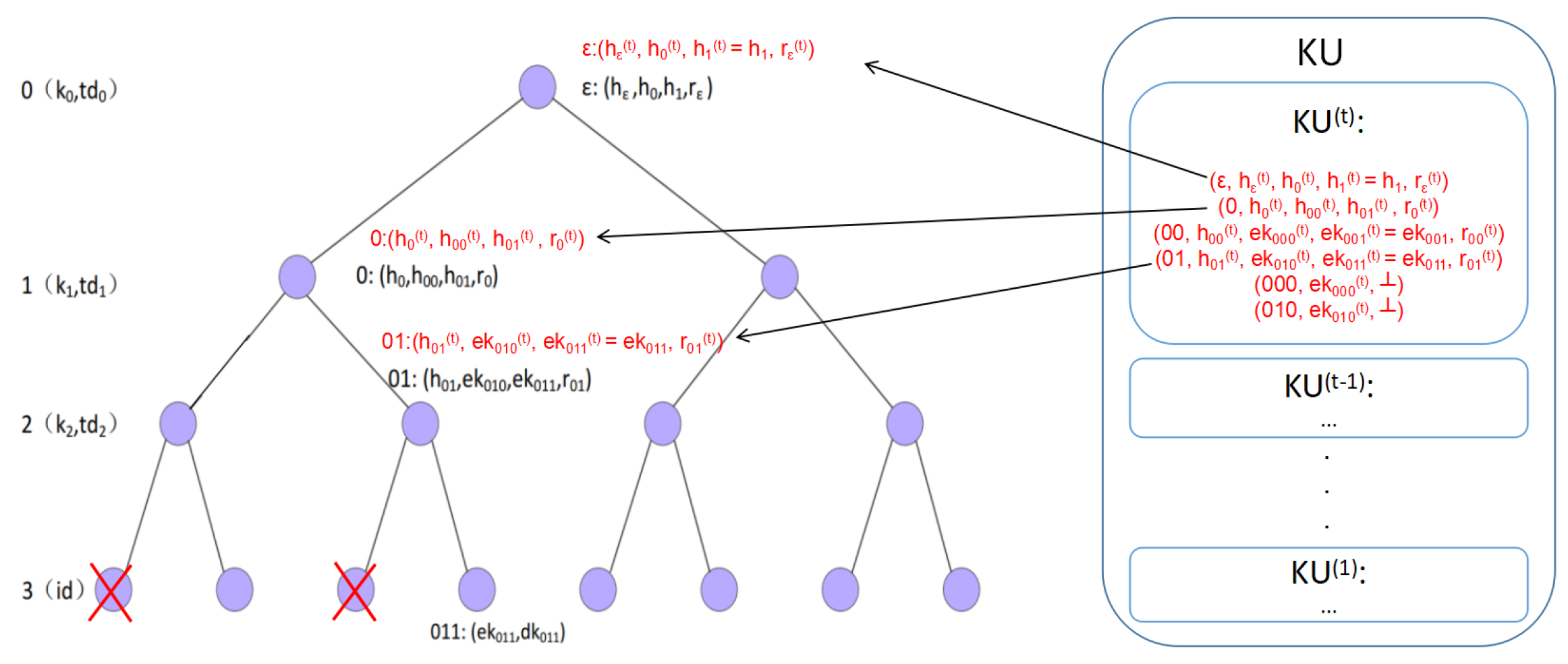
- Decryption Key Generation: See Figure 6 for illustrations.
- , where is the empty string.
- Parse mpk and .
- From retrieve a set .
- For each with in ascending order, does the following:to :(Recall ).:.
- If s.t. : is revoked at.
- Output
- Encryption:We describe two circuits that will be garbled during the encryption procedure.
- -
- Compute and output .
- -
- : Compute and output , where is the short for .
Encryption proceeds as follows:- Retrieve the last item from . If , output ⊥; otherwise .
- Parse mpk.
- .
- For to 0,and set .
- Output , where is the bit of .
- Decryption
- , where is the empty string.
- Parse mpk and , where .
- Parse
- Set .
- For to :(Recall ;, set and , and for each ,, set and for each , compute
- Compute .
- Output .
- Revocation:
- Parse .
- Update the revocation list by .
- .
- Output .
- , where is the empty string.
- Parse mpk and .
- If , Output ⊥.
- If , Output .
- From retrieve a set .
- For each with in ascending order, does the following:to :(Recall ).:.
- If s.t. : is revoked at.
- Output .
4.1. Correctness
- Recall that and are the output of .
- Due to the correctness of the chameleon encryption, we know that given one can recover by decrypting. And is the label for the next garbled circuit .
- When , we obtain the set of labels . Recall that and are the output of . And is the result of selected by . Thus,Due to the correctness of , given decryption key , one can always recover the original message m correctly with .
4.2. Security
5. Revocable IBE Scheme with DKER
- : given a security parameter , an integer n where is the maximal number of users that the scheme supports, i.e., . Define the time space as .
- Run .
- Parse .
- Run .
- Output .
- :
- Parse and .
- Run .
- Run .
- Output .
- :
- Parse and .
- Run .
- Output ().
- :
- Parse and .
- Run .
- Run .
- Output .
- :
- Parse .
- Sample a pair uniformly at random, subject to .
- Run .
- Run .
- Output .
- :
- Parse and .
- Run .
- Run .
- Output .
- :
- Run .
- Output .
6. Server-Aided Revocable IBE Scheme
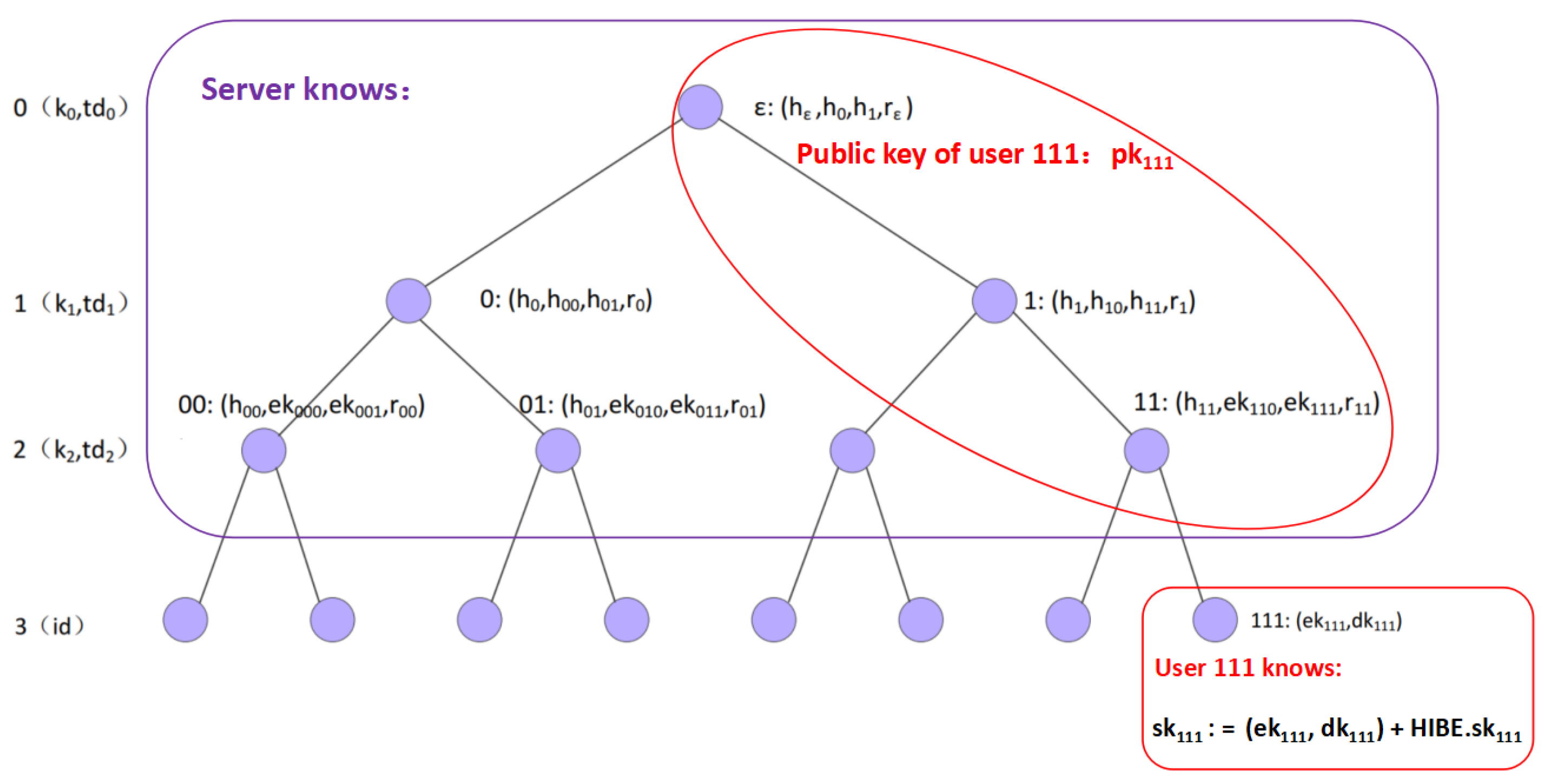
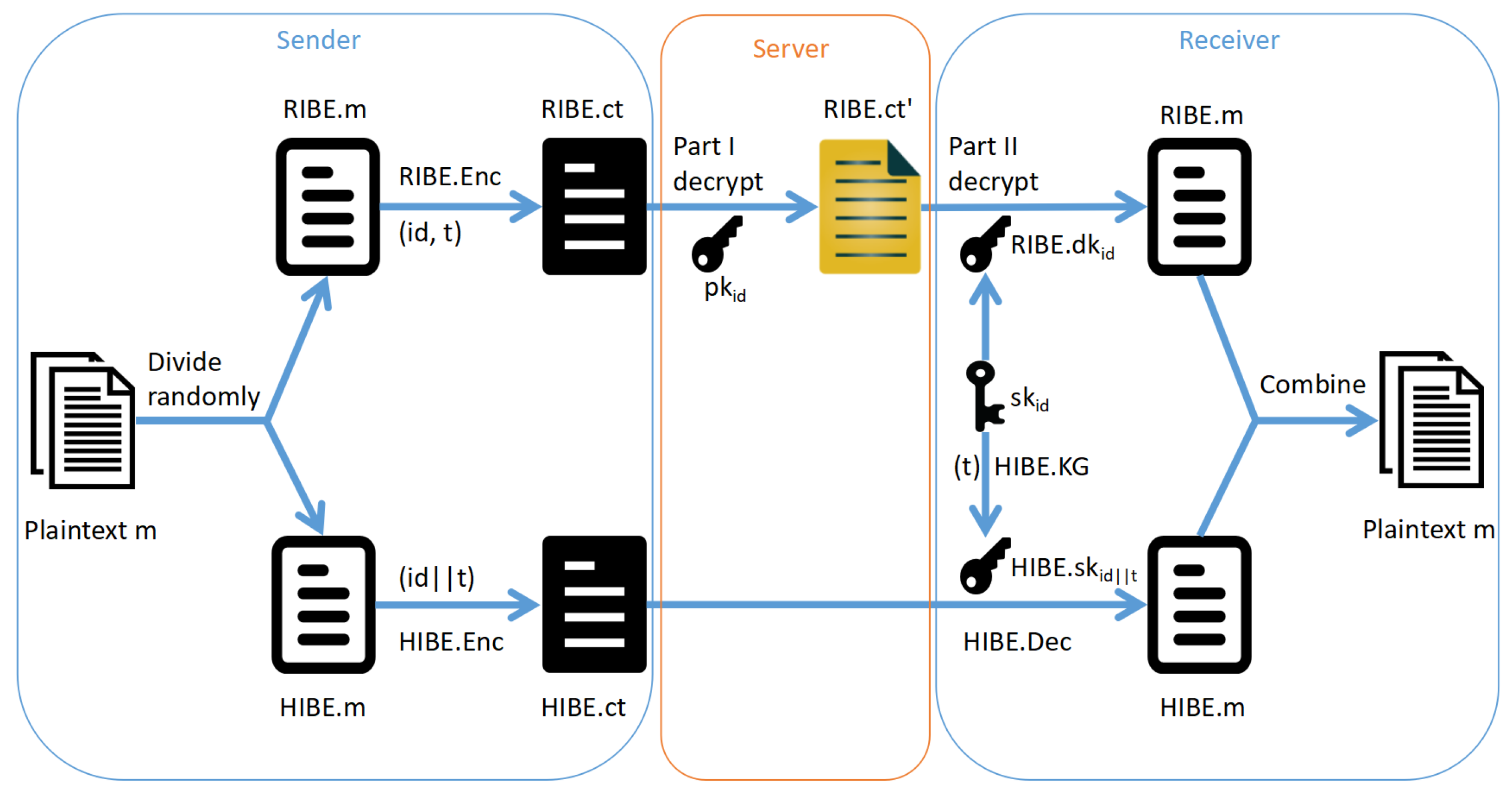
- Key Generation: Recall that in RIBE the secret key of a user is . Moreover, as shown in Figure 2, the RIBE private key can be treated as a path from the root to the leaf corresponding to in a tree. Now for SR-IBE , we divide the RIBE private key into two parts, the non-leaf part and the leaf part. The non-leaf part (we name it ) is assigned to the server and the leaf part () (in fact is enough) to user . Besides, user is also assigned with the HIBE private key . This is shown in Figure 7.
- Key Update: If a user has been revoked in RIBE , the updating information in the leaf node corresponding to the user will not be issued. In other words, all the key updating information only occurs in the upper part of the tree excluding the leaves. Therefore, in SR-IBE the key authority can issue the key updating list to the server and the server is in charge of updating keys for users.
- Decryption: Recall that in the RIBE scheme with DKER in Section 5, the ciphertext consists of two parts: the ciphertext of the RIBE scheme and the ciphertext of the HIBE scheme . To decrypt in SR-IBE , the decryption is implemented from the top to the bottom along the path in the tree. The server will decrypt the upper non-leaf part while the user will decrypt the leaf part. Meanwhile, the user is alway able to use and time slot to compute and decrypt with it. The process is shown in Figure 8.
- : given a security parameter , an integer n where is the maximal number of users that the scheme supports. Define identity space as and time space as , and do the following.
- Sample .
- For each , invoke .
- Initialize key list , public list , key update list and revocation list .
- Run .
- ; ; .
- Output .
- Parse , and .
- , where is the empty string.
- For all :,,.
- For :,,.
- and .
- Output .// This algorithm is almost the same as the Private Key Generation algorithm in Section 4 except that there is no in .
- :
- Parse , and .
- . // stores all revoked leaves and their ancestors
- If , Output()
- Set key update list .
- For all node such that : ,. .
- For to 0: all node and :, .()s.t.,;..
- and .
- Output .// This algorithm is identical to the Key Update Generation algorithm in Section 4.
- :
- , where is the empty string.
- Parse and .
- From retrieve a set .
- For each with in ascending order, does the following:to :(Recall ).:.
- Output// This algorithm is almost the same as the Decryption Key Generation algorithm in Section 4 except that all update operations do not involve leaf nodes, i.e., .
- Parse and .
- Run .
- .
- Output .
- Parse .
- Run .
- .
- Output .
- :Same to the encryption algorithm in Section 4, we use these two circuits that will be garbled during the encryption procedure.
- -
- Compute and output .
- -
- : Compute and output , where is the short for .
Encryption proceeds as follows:- Retrieve the last item from . If , output ⊥; otherwise .
- Parse .
- Sample a pair uniformly at random, subject to .
- Run .
- .
- For to 0,and set .
- Output , where is the bit of .
- Output .
- , where is the empty string.
- Parse , and , where .
- Parse
- Set .
- For to :(Recall ;, set and , and for each ,, set and for each , compute
- Compute .
- Output// This algorithm is almost the same as the Decryption algorithm in Section 4 except that this algorithm omits the last step, i.e., it does not recover from f.
- Parse , and .
- Run .
- Run .
- Output
- :
- Parse .
- Update the revocation list by .
- .
- Output .
7. Analysis of Key Updating Size
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Hierarchical Identity Based Encryption
- Setup: The setup algorithm is run by the key authority. The input of the algorithm is a security parameter . The output of this algorithm consists of a pair of key . In formula,
- Key Generation: The key generation algorithm is run by the key authority. It takes a secret key ( for ) and an identity as the input. The output of this algorithm is . In formula, .
- Encryption: The encryption algorithm is run by the sender. It takes the master public key , an identity and a plaintext message as the input. The output of this algorithm is the ciphertext . In formula, .
- Decryption: The decryption algorithm is run by the receiver. The input of this algorithm consists of the master public key , the secret key and the ciphertext . The output of this algorithm is the plaintext . In formula, .
| . |
- The two plaintexts submitted by have the same length, i.e., .
- If has queried to oracle , then cannot be the a prefix of .
Appendix B. Proofs of Theorems
Appendix B.1. Proof of Theorem 1
- : This hybrid is just the original experiment (without oracle ) as shown in Definition 1. ThusSpecifically, in this hybrid, the challenger will first invoke to obtain where . sends to the adversary and answers oracle queries as follows.
- Private key generation oracle . Upon receiving ’s query , the challenger invokes and returns to .
- Key update oracle . Upon receiving ’s query , does as follows:For from 1 to :.ParseReturns to .
- Revocation oracle . Upon receiving ’s query an and a , invokes and parses . It returns to .
- : In this hybrid, we change how the challenger answers oracle and oracle . Recall that in , the subroutines NodeGen and LeafGen are involved in RIBE.KG when answering queries to the oracle , and the subroutines NodeChange and LeafChange are involved in RIBE.KU when answering queries to the oracle A pseudo-random subroutine is invoked in all the four subroutines. Now in , this will be replaces by a truly subroutine . Note that can efficiently implement the truly subroutine : Given a fresh input x, chooses a random element R in as the output of . records locally. If x is not fresh, retrieves R from its records.Any difference between and will lead to a distinguisher , who can distinguish from . Hence
- for : In this hybrid, challenger changes the generation of the challenge ciphertext. Recall that the challenge ciphertext . In hybrid , invokes the simulator provided by the garbled circuit scheme to generate the first garbled circuits . Meanwhile, for , the input of the is the chameleon encryption ciphertexts. We stress that the labels satisfy . Please note that needs the hash value with . Therefore the challenger has to determine first with . Then invokes to generate , and invokes to generate the rest circuits. Below is the detailed description of the generation of the challenge ciphertext by .Assume ’s challenge query as . first chooses a random bit , and encrypts under in as follows:
- Define , where is the empty string. Determine the values which are the values attached to all nodes on the path from the root to .
- -
- .
- -
- .Retrieve from .
- -
- .Parse , where. Please note that if has been revoked before .
- , where .
- For to ,Set .
- For to 0, set , where if .and set .
- Output , where is the bit of .
Please note that the randomnesses in and are generated by random subroutines instead of the . - for : This hybrid is the same as except that the challenger changes the way of generating and when answering private key queries and the way of generating and when answering key update queries for . For , set . In addition, setwhere and . Specifically, changes the generation process of fromtouses the same way to generate , i.e., is chosen randomly, and .Due to uniformity properties of the chameleon hash, hybrids and are statistical indistinguishable. So
- for : This hybrid is the same as except step 3 (as shown in in detail). Specifically, set . changes the generation process of garbled circuits fromand setting toand setting .Since is exactly the output of , the indistinguishability of and directly follows from the security of the garbled circuit scheme. If there is a PPT adversary who can distinguish and with advantage , then we can construct a PPT algorithm who can break the security of the garbled circuit scheme with same advantage . Please note that can generate itself and simulate all the oracles for perfectly. embeds its own challenge to . If is generated by , perfectly simulates . If is generated by , perfectly simulates . Hence
- for : This hybrid is the same as except step 4 (as shown in ). Challenger changestoPlease note that is not used any more, the indistinguishability between and can be reduced to the security of the chameleon encryption scheme defined in Section 2.7. We need hybrids, , to prove this, where is the same as except the generation of . SetIn ,Obviously, is the same as and is the same as . Please note that the only difference between and is , whereIf there is a PPT adversary who can distinguish and with a advantage for , we can construct a PPT distinguisher can use this adversary to break the security of the chameleon encryption scheme with the same advantage . simulates () for as follows:
- receives a hash key from it own challenger of the chameleon encryption scheme.
- generates . resets . Now does not know the corresponding chameleon hash trapdoor . Then sends to .
- can perfectly simulates all oracles for since these oracles do not need the trapdoor anymore.
- When receiving the challenge query , sets, (Please note that is chosen randomly).
- -
- generates according to (A3), just like ().
- -
- To generate , does the following. It computes but leaves undefined. Set and , where . sets its own challenge query as . Then the challenger of generates a challenge ciphertext and sends it to . sets . In addition, it computes as (A7).
- -
- generates according to (A4), just like ().
- -
- sends the challenge ciphertext.
- If returns a guessing bit to , returns to its own challenger.
If is the chameleon encryption of , simulates perfectly for . If is the chameleon encryption of , simulates perfectly for . If can distinguish these two hybrids with advantage , can break the security of the multi-bit chameleon encryption with the same advantage . Therefore,Recall that is the same as and is the same as . We have - for : In this hybrid, challenger undoes the changes made from and . It is obvious that the computational indistinguishability between and also follows from uniformity properties of the chameleon hash. Please note that is the same as . We have
- : This hybrid is the same as except that the challenger changes the way of generating . More Formally, changes the generation process of garbled circuits fromtoThis indistinguishability between and follows by the security of the garble circuit scheme. The proof is similar to the indistinguishability between and .Hence,
- : This hybrid is the same as except that the challenger replaces the ciphertext hard-coded in the circuit with .If there is a PPT adversary who can distinguish between and with advantage , there is a PPT distinguisher who can break the IND-CPA security of with advantage . First of all, We consider two kinds of adversaries:
- Type-I
- : never queries to key generation oracle for .
- Type-II
- : queries to and obtains . In this case should be revoked before .
- generates . sends to .
- receives encryption key from its own challenger.
- chooses .
- If , since has , can perfectly simulate all oracles for as in (). embeds in the private key generation of identity (the output of ()). More specifically, invokes with a little change (framed parts are added) in the fourth step of the algorithm as follows:
- -
- For :, where .,
. . ,.Recall that is generated byin LeafGen algorithm, hence has identical distribution with . As a result, perfectly simulates the oracle on for just like ().
- receives the challenge query from .If and , aborts the game.If and there exists such that , aborts the game.Otherwise:chooses .sets its own challenge query as and .receiving the challenge ciphertext from its own challenger, computes , and continues to generate according to (A4), just like .sends the challenge ciphertext to .
- Finally, outputs what outputs.
- generates . sends to .
- receives encryption key from its own challenger.
- chooses .
- Since has , can perfectly simulate all oracles for as in (). embeds in the key update generation (the output of ) of time . More specifically, invokes with a little change (a framed part is added) in the fifth step of the algorithm as follows:
- -
- For all node such that : ,
If , . ..Recall that is generated by in LeafChange algorithm, hence has an identical distribution with . As a result, perfectly simulates the oracle for just like ().
- receives the challenge query parsed as from .If , aborts the game.Else:chooses .sets its own challenge query as and .receiving the challenge ciphertext from its own challenger, computes , and continues to generate according to (A4), just like .sends the challenge ciphertext to .
- Finally, outputs what outputs.
- Please note that in , the challenge ciphertext is information theoretically independent of the plaintexts submitted by . So we have
Appendix B.2. Proof of Theorem 3
- generates the challenge identity and time slot to . Then sends the same challenge pair to its own challenger.
- receives from its own challenger and sets . Then sends to .
- When queries for the oracle PubKG with an identity , queries for his oracle KG with the same identity to its own challenger. Set , where is the empty string. Upon receiving the , parses , where and . sends to .
- When queries for the oracle PrivKG with an identity , queries for his oracle KG with the same identity to its own challenger. Set , where is the empty string. Upon receiving the , parses , where and . sends to .
- When queries for the oracle KU, queries for the oracle KU to its own challenger. Upon receiving the , sends to .
- When queries for the oracle DK with an identity and a time slot , queries for his oracle DK with the same pair () to its own challenger. Set , where is the empty string. Upon receiving the , parses . sends to .
- When queries for the oracle Rvk with an identity and a time slot , queries for his oracle Rvk with the same pair () to its own challenger.
- When submits the challenge query , sends the same challenge query to its own challenger. Upon receiving the challenge ciphertext , sends to .
- Finally, outputs what outputs.
References
- Shamir, A. Identity-Based Cryptosystems and Signature Schemes. In Proceedings of the CRYPTO 1984, Advances in Cryptology, Santa Barbara, CA, USA, 19–22 August 1984; pp. 47–53. [Google Scholar] [CrossRef]
- Waters, B. Efficient Identity-Based Encryption Without Random Oracles. In Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Advances in Cryptology (EUROCRYPT 2005), Aarhus, Denmark, 22–26 May 2005; pp. 114–127. [Google Scholar] [CrossRef]
- Gentry, C. Practical Identity-Based Encryption Without Random Oracles. In Proceedings of the 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Advances in Cryptology (EUROCRYPT 2006), St. Petersburg, Russia, 28 May–1 June 2006; pp. 445–464. [Google Scholar] [CrossRef]
- Okamoto, T.; Takashima, K. Fully Secure Functional Encryption with General Relations from the Decisional Linear Assumption. In Proceedings of the 30th Annual Cryptology Conference, Advances in Cryptology (CRYPTO 2010), Santa Barbara, CA, USA, 15–19 August 2010; pp. 191–208. [Google Scholar] [CrossRef]
- Gentry, C.; Peikert, C.; Vaikuntanathan, V. Trapdoors for hard lattices and new cryptographic constructions. In Proceedings of the 40th Annual ACM Symposium on Theory of Computing, Victoria, BC, Canada, 17–20 May 2008; pp. 197–206. [Google Scholar] [CrossRef]
- Agrawal, S.; Boneh, D.; Boyen, X. Efficient Lattice (H)IBE in the Standard Model. In Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques: Advances in Cryptology: (EUROCRYPT 2010), Monaco/Nice, France, 30 May–3 June 2010; pp. 553–572. [Google Scholar] [CrossRef] [Green Version]
- Cash, D.; Hofheinz, D.; Kiltz, E.; Peikert, C. Bonsai Trees, or How to Delegate a Lattice Basis. In Proceedings of the 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Advances in Cryptology (EUROCRYPT 2010), Monaco/Nice, France, 30 May–3 June 2010; pp. 523–552. [Google Scholar] [CrossRef]
- Döttling, N.; Garg, S. Identity-Based Encryption from the Diffie-Hellman Assumption. In Proceedings of the 37th Annual International Cryptology Conference, Advances in Cryptology (CRYPTO 2017), Santa Barbara, CA, USA, 20–24 August 2017; pp. 537–569. [Google Scholar] [CrossRef]
- Boneh, D.; Franklin, M.K. Identity-Based Encryption from the Weil Pairing. SIAM J. Comput. 2003, 32, 586–615. [Google Scholar] [CrossRef] [Green Version]
- Boldyreva, A.; Goyal, V.; Kumar, V. Identity-based encryption with efficient revocation. In Proceedings of the 2008 ACM Conference on Computer and Communications Security (CCS 2008), Alexandria, VA, USA, 27–31 October 2008; pp. 417–426. [Google Scholar] [CrossRef]
- Sahai, A.; Waters, B. Fuzzy Identity-Based Encryption. In Proceedings of the 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Advances in Cryptology (EUROCRYPT 2005), Aarhus, Denmark, 22–26 May 2005; pp. 457–473. [Google Scholar] [CrossRef]
- Libert, B.; Vergnaud, D. Adaptive-ID Secure Revocable Identity-Based Encryption. In Proceedings of the Cryptographers’ Track at the RSA Conference on Topics in Cryptology (CT-RSA 2009), San Francisco, CA, USA, 20–24 April 2009; pp. 1–15. [Google Scholar] [CrossRef]
- Seo, J.H.; Emura, K. Revocable Identity-Based Encryption Revisited: Security Model and Construction. In Proceedings of the 16th International Conference on Practice and Theory in Public-Key Cryptography: Public-Key Cryptography (PKC 2013), Nara, Japan, 26 February–1 March 2013; pp. 216–234. [Google Scholar] [CrossRef]
- Lee, K.; Lee, D.H.; Park, J.H. Efficient revocable identity-based encryption via subset difference methods. Des. Codes Cryptogr. 2017, 85, 39–76. [Google Scholar] [CrossRef]
- Watanabe, Y.; Emura, K.; Seo, J.H. New Revocable IBE in Prime-Order Groups: Adaptively Secure, Decryption Key Exposure Resistant, and with Short Public Parameters. In Proceedings of the Cryptographers’ Track at the RSA Conference on Topics in Cryptology (CT-RSA 2017), San Francisco, CA, USA, 14–17 February 2017; pp. 432–449. [Google Scholar] [CrossRef]
- Park, S.; Lee, K.; Lee, D.H. New Constructions of Revocable Identity-Based Encryption from Multilinear Maps. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1564–1577. [Google Scholar] [CrossRef]
- Chen, J.; Lim, H.W.; Ling, S.; Wang, H.; Nguyen, K. Revocable Identity-Based Encryption from Lattices. In Proceedings of the 17th Australasian Conference on Information Security and Privacy (ACISP 2012), Wollongong, NSW, Australia, 9–11 July 2012; pp. 390–403. [Google Scholar] [CrossRef]
- Takayasu, A.; Watanabe, Y. Lattice-Based Revocable Identity-Based Encryption with Bounded Decryption Key Exposure Resistance. In Proceedings of the 22nd Australasian Conference on Information Security and Privacy (ACISP 2017), Auckland, New Zealand, 3–5 July 2017; pp. 184–204. [Google Scholar] [CrossRef]
- Qin, B.; Deng, R.H.; Li, Y.; Liu, S. Server-Aided Revocable Identity-Based Encryption. In Proceedings of the 20th European Symposium on Research in Computer Security (ESORICS 2015), Vienna, Austria, 21–25 September 2015; pp. 286–304. [Google Scholar] [CrossRef]
- Liang, K.; Liu, J.K.; Wong, D.S.; Susilo, W. An Efficient Cloud-Based Revocable Identity-Based Proxy Re-encryption Scheme for Public Clouds Data Sharing. In Proceedings of the 19th European Symposium on Research in Computer Security (ESORICS 2014), Wroclaw, Poland, 7–11 September 2014; pp. 257–272. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, J.K.; Liang, K.; Choo, K.R.; Zhou, J. Extended Proxy-Assisted Approach: Achieving Revocable Fine-Grained Encryption of Cloud Data. In Proceedings of the 20th European Symposium on Research in Computer Security (ESORICS 2015), Vienna, Austria, 21–25 September 2015; pp. 146–166. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, J.K.; Wei, Z.; Huang, X. Towards Revocable Fine-Grained Encryption of Cloud Data: Reducing Trust upon Cloud. In Proceedings of the 22nd Australasian Conference on Information Security and Privacy (ACISP 2017), Auckland, New Zealand, 3–5 July 2017; pp. 127–144. [Google Scholar] [CrossRef]
- Liu, J.K.; Yuen, T.H.; Zhang, P.; Liang, K. Time-Based Direct Revocable Ciphertext-Policy Attribute-Based Encryption with Short Revocation List. In Proceedings of the 16th International Conference on Applied Cryptography and Network Security (ACNS 2018), Leuven, Belgium, 2–4 July 2018; pp. 516–534. [Google Scholar] [CrossRef]
- Katsumata, S.; Matsuda, T.; Takayasu, A. Lattice-based Revocable (Hierarchical) IBE with Decryption Key Exposure Resistance. IACR Cryptol. ePrint Arch. 2018, 2018, 420. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IBE | Security Assumption | Pairing Free | Security Model | Key Updating Size | DKER |
|---|---|---|---|---|---|
| [17] | LWE | ✓ | Selective-IND-ID-CPA | × | |
| [18] | LWE | ✓ | Selective-IND-ID-CPA | Bounded | |
| [10] | DBDH | × | Selective-IND-ID-CPA | × | |
| [12] | DBDH | × | Adaptive-IND-ID-CPA | × | |
| [13] | DBDH | × | Adaptive-IND-ID-CPA | ✓ | |
| [14] | DBDH | × | Adaptive-IND-ID-CPA | ✓ | |
| [15] | DDH and ADDH | × | Adaptive-IND-ID-CPA | ✓ | |
| [16] | Multilinear | × | Selective-IND-ID-CPA | ✓ | |
| Our RIBE 1 | CDH | ✓ | Adaptive-IND-ID-CPA | × | |
| Our RIBE 2 | CDH | ✓ | Selective-IND-ID-CPA | ✓ | |
| Our SR-IBE | CDH | ✓ | Selective-IND-ID-CPA | ✓ |
| . | |
| Parse | |
| Output . | Output , . |
| Output . | Output . |
| Output . | . |
| Parse | |
| Output , . | |
| Output . | |
| Output . | Output . |
| NodeGen: | FindNodes: |
| Let | |
| , | |
| , | , then add to . |
| . | For to 0: find the ancestors of . |
| . | with : |
| Output . | , add v to . |
| Output . | |
| LeafGen: | NodeChange: |
| , | |
| , | . |
| , | Output . |
| , | LeafChange: |
| . | . |
| Output . | Output . |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Liu, S.; Chen, K.; Liu, J.K. Revocable Identity-Based Encryption and Server-Aided Revocable IBE from the Computational Diffie-Hellman Assumption. Cryptography 2018, 2, 33. https://0-doi-org.brum.beds.ac.uk/10.3390/cryptography2040033
Hu Z, Liu S, Chen K, Liu JK. Revocable Identity-Based Encryption and Server-Aided Revocable IBE from the Computational Diffie-Hellman Assumption. Cryptography. 2018; 2(4):33. https://0-doi-org.brum.beds.ac.uk/10.3390/cryptography2040033
Chicago/Turabian StyleHu, Ziyuan, Shengli Liu, Kefei Chen, and Joseph K. Liu. 2018. "Revocable Identity-Based Encryption and Server-Aided Revocable IBE from the Computational Diffie-Hellman Assumption" Cryptography 2, no. 4: 33. https://0-doi-org.brum.beds.ac.uk/10.3390/cryptography2040033