1. Introduction
A social network is a social structure that consists of nodes (e.g., unique users, businesses, artistic profiles, etc.), which are connected to each other by various types of interdependence (e.g., kinship, friendship, sympathy, admiration, curiosity, financial relations). In recent years, however, the usefulness of these networks, as well as the extensions they have taken on in our lives, make any definition rather incomplete.
Twitter is a tool for microblogging [
1] and a social networking platform that appeared in March 2006 and still remains among the most visited websites in the world. The power of Twitter is essentially the production of news in real-time, and it remains today one of the best indicators of what is happening in the world at any given time. This is really amazing, considering that the original idea behind its creation was a platform that allows a registered user to compile and publish a status of up to 280 characters.
Influencer marketing and consequently influencers, as well as the ability provided by the data of millions of Twitter users to create or predict trends, thus determining even the global fluctuations of stock prices, are the main aspects discussed in this study. Influencers in the world outside of social networks are persons who have the ability to influence the choices of others because of their knowledge, their professional reputation, or their personal relationship that they have managed to develop with a certain portion of the audience. This audience can be influenced by each influencer to a small and sometimes to a greater extent. The natural question that arises is whether a social network can be the appropriate digital platform in which this power of influence of an individual can be measured, calculated, and in some way be a product of study.
When trying to empirically measure the impact of a Twitter account or any other social network, the following question will be triggered: what is the content that primarily increases the loyalty or commitment of an existing audience? Engagement is essentially considered as the way of discriminating whether the content of an account manages to keep the interest of its audience, which would result in a potential increase in the number of followers.
The ubiquity of Internet access has triggered the emergence of currencies distinct from those used in the prevailing monetary system. The advent of cryptocurrencies based on a unique method called “mining” has brought about significant changes in the online financial activities of users. Various cryptocurrencies have appeared since 2008, when Bitcoin was first introduced [
2,
3]. Nowadays, cryptocurrencies are often used in online transactions, and their usage has increased every year since their introduction [
4,
5].
Cryptocurrencies are mainly characterized by fluctuations in their price and number of transactions [
3,
4]. For instance, the most famous cryptocurrency, Bitcoin, did not fluctuate significantly in price and number of transactions until the end of 2013, when it began to attract global attention, and marked a significant increase and fluctuation in price and number of transactions [
4]. Bitcoin quickly gained interest as a possible replacement for standard monetary forms. Other cryptocurrencies, such as Ripple and Litecoin, have shown significantly unstable fluctuations since the end of December 2013 [
6]. Such volatile fluctuations have served as an opportunity for some users to speculate while preventing most others from using cryptocurrencies [
3,
7,
8]. In this way, the plethora of objects, opinions, and information about Bitcoin are predominant through the majority of social media sphere [
9]. In addition, the Bitcoin currency is considered the modern principal cryptocurrency that could even replace other currencies [
10].
Twitter constitutes a platform on which peoples’ thoughts can be almost automatically translated into digital information. Nonetheless, one of the most important issues for the supporters of Bitcoin is not only the sharp fluctuation of its exchange rate but also the factors that influence these fluctuations. Sentiment analysis in Twitter has been extensively studied in numerous works that demonstrate the potential of this topic [
11,
12,
13,
14]. Based on these thoughts, in this article, we made a statistical causality test for investigating whether sentiment, followers, retweets, favorites, and lists time series are effective in forecasting the popularity of two cryptocurrencies. Finally, we conclude on the popularity of cryptocurrencies in users’ list timelines.
This study presents a comparison of the popularity of four popular cryptocurrencies, i.e., Bitcoin, Ethereum, Litecoin, and Stellar, based on different features that can be identified in the posts of Twitter users. These characteristics are the number of followers, the ratio of retweets per tweet, the ratio of favorites per tweet, and the number of lists to which the user belongs. Furthermore, the dataset used in the paper consists of 12,000 posts collected for a time period of 12 days, from 6 April to 18 April 2020. More to the point, the timelines of the 500 most influential users were taken into consideration. As a next step, we applied the Spearman, Pearson, and Kendall Correlation Coefficients as post-hoc procedures to support hypotheses about the correlation between these four features. Finally, the Granger causality test was employed to evaluate the statistical significance of various features time series in popularity prediction as it identified the most influential variable to predict future values of cryptocurrency popularity.
The rest of this paper is structured as follows:
Section 2 presents related works in the field of Blockchain and Cryptocurrency, as well as sentiment analysis in Cryptocurrencies.
Section 3 analyzes the proposed architecture and the tools required for its implementation. Next,
Section 4 describes and analyzes the features of the used dataset and provides the experimental results, including correlation analysis and statistical tests. Finally, we summarize the paper and conclude with future work in
Section 5.
3. Tools and Environment
This section presents the preliminaries from the Twitter perspective, which will be utilized for the implementation of the proposed approach using Twitter API and Libraries [
46]. Next, the framework for the two-dimensional evaluation of cryptocurrency popularity is presented. Finally, some background information on Spearman Correlation Coefficient is given as it will be used in the data analysis section.
3.1. Preliminaries
Twitter’s Streaming API provides access to the global Twitter feed. The creation of a connection to the Twitter Streaming API is implemented with a long-lasting HTTP request without having to stop the data flow like in Rest API.
Regarding the implementation, a set of Python libraries were utilized, which proved to be particularly useful both in collecting, processing, and displaying data. Several pre-processing steps must be applied in order for the mining methodology of the collected data to be facilitated. The major modules of the proposed methodology are:
Tweepy: It is a Python library that implements the fetching of the posts; it also permits, with the use of the Twitter interface, the management of the profile of a user, the data collection by considering specific search words, and finally the creation of a batch of posts over a particular time interval. Tweepy is therefore the communication bridge between Python and the Twitter API.
Textblob: It is a Python library capable of processing data in text format as it provides a simple API for performing natural language processing (NLP) tasks, including sentiment analysis, and, specifically, in our paper, it will be used to calculate the popularity of cryptocurrencies.
Pandas: It constitutes a Python library that effectively handles high-performance data and provides tools for the analysis of powerful structures. It also utilizes the fast and efficient structure of Dataframes with automatic initialization indexes and offers data alignment along with many options for managing potentially missing data.
3.2. Proposed Approach
In this subsection, two different and related points of interest are presented. On one hand, the users’ influence on Twitter can be practically evaluated using Python and Twitter API, whereas, in the second step, we elaborate on methods using the Twitter API search, which simulates a specific metric. This metric is entitled status.reply_count and is considered an additional metric of user popularity.
We aim to create a list of users that can be considered the most influential regarding specific criteria related to financial interest on the Twitter social networking platform. The topic of discussion on which we focus our attention is a cryptocurrency, while the relevant words that users search for are Economy, Bitcoin, Finance, Forex, Ethereum, and others related to cryptocurrencies.
The implementation details are presented below:
Search for tweets based on popular hashtags of financial interest (e.g., #Bitcoin, #Finance and #Markets).
Collection of users who address the specific tweets in dataframes, named List_of_Users _#X, where X corresponds to the hashtag of our search.
Create a common dataframe named List_of_Users_Final, which consists of the union of all the concrete dataframes and contains all the users sorted by the number of their followers; this is the first influence rank.
Three more columns to the dataframe are added, where each user receives a ranking number according to three different popularity features. The first criterion is the ratio of retweets per tweet, which expresses both the user’s ability to produce quality content and their ability to communicate their tweets to a larger audience. The second criterion constitutes the favorites per tweet ratio, which expresses the percentage of tweets that have a positive response from the user’s followers. The third and last is the number of lists to which the user belongs and thus taking into consideration the fact that this metric strengthens the user links through the creation of new networks.
These four criteria (followers, retweets, favorites, lists) are simultaneously applied by combining data from all rankings and extracting a list of 30 users who are considered as the Twitter users with the greatest influence on the economy and cryptocurrencies.
Having received the id of each user, the next step is to search their timeline with api.user_timeline in order to extract a variable-sized list of users that meets all four of the above popularity criteria.
3.3. Sentiment Score Calculation
The sentiment score of each tweet is calculated using the VADER algorithm, which is a combined approach of lexicon and rule-based sentiment analytic software [
47]. VADER is feasible to identify the polarity of text into three categories, which are positive, negative, and neutral. It uses factors like emojis, intensifiers, contraction, punctuation, and acronyms to calculate the scores.
Pre-processing is not essential for VADER as, unlike with some supervised methods of NLP, pre-processing necessities such as tokenisation, stemming, and lemmatisation are not required. The sentiment is determined by the use of plain text. Python provides a library entitled “vaderSentiment” and specifically the “polarityscores” function.
Furthermore, there is no need for pre-processing as VADER implements five major heuristics in terms of sentiment intensity. These include capitalisation, degree modifiers, punctuation, tri-grams analysis as well as the use of “but”.
3.4. Correlation Coefficients
The correlation analysis of the sentiment score determined from the tweets with the cryptocurrency popularity plays an important role in prediction. This correlation can quantify the relationship strength associated with the derived sentiment score and popularity. Specifically, the change in opinion of users can later have an impact on the popularity. This marks the importance of the cross-correlation analysis.
The distinction is that cross-correlation introduces a lag, allowing one of the time-series to be shifted left or right to obtain a better correlation. Three statistical correlation methods, namely Spearman, Pearson, and Kendall, were used and compared in the analysis.
To support hypotheses about correlation or not between columns, the Spearman Correlation Coefficient was applied. This factor constitutes a numerical measure, or better indicator, of the size of the correlation between two sets of values. It ranges from to passing through . A positive sign indicates a positive correlation; this practically means that, when the values of one variable increase, the same happens with those of the second variable. On the contrary, the negative symbol indicates a negative correlation between the two variables; that is, when the values of one variable seem to increase, the values of the second variable decrease. The value indicates complete randomness concerning the fluctuations of the two variables we are considering.
Spearman’s
is the Pearson Correlation Coefficient applied to a set of values after separately sorting the values of both variables, from the smallest to the largest. Calculating the constant correlation of Spearman is a non-parametric process, while the constant evaluates the relationship between two numerical variables without speculating on the real relationship between these two variables. The Spearman constant is calculated from the following equation and expresses the correlation between two tables:
where
and
are the ranks of the variables in a number of observations.
The Pearson Correlation constitutes one of the most widely used correlation approaches as it is for variables with a linear relationship and normal distribution of data. According to [
48], Pearson’s correlation coefficient (
r) is defined as:
where
and
are the values of features
x and
y and
denote the mean of
x and
y for the
i-th record in
N-ranking tables.
The Kendall Correlation constitutes a non-parametric statistical technique that measures the strength of dependency between two or more variables, similar to Spearman Rank Correlation. Following [
49], this coefficient is defined as:
where
N is the sample size,
are the unique unordered pairs, and
are the number of concordant and discordant, respectively.
4. Results
In this section, we show the outcomes from the evaluation of the proposed approach. For this purpose, three experiments have been conducted. The first one concerns the analysis of the features from a Twitter perspective, the second investigates the association between the involved features, and the last one concerns the sentiment score and the statistical significance of the time-lag per feature for the cryptocurrency popularity prediction.
The first set of experiments produced top-k ranked user lists for four different features, namely followers, retweets, favorites, and lists. In order to estimate whether a correlation between these columns exists, the second set of experiments was applied regarding the aforementioned correlation coefficients. In the following, we present the values of the three above correlation statistical methods. The third experiment employs the Granger causality test to assess the importance of sentiment and each feature, separately, in the cryptocurrency popularity.
4.1. Features Analysis
Twitter’s Streaming API, along with the Tweepy library, was used in order to fetch Twitter posts and information for the sentiment analysis. Tweepy constitutes, as previously mentioned, an effective way of retrieving concrete information through permitting information retrieval from Twitter and allowing filtering based on keywords, topics, or hashtags.
The hashtags were derived from the most representative words in the context of each corresponding cryptocurrency. However, this search may incorporate posts that are relevant to other cryptocurrencies as well, and so the selection must be focused in order to comprise particular words that are considered as synonyms to each cryptocurrency. For example, regarding #Bitcoin, the synonyms are #BTC and #Bitcoinprice. The posts we collected were published for a time period of 12 days (from 6 April to 18 April 2020), and in the following
Table 1, the relevant hashtags are displayed.
In
Table 2, the number of posts of the four most well-known cryptocurrencies, i.e., Bitcoin, Ethereum, Litecoin, and Stellar, are compared as the timelines of the 500 most influential users were taken into consideration. The results of this table are not associated with the actual prices of these cryptocurrencies but only with the profile of the users. The number of posts regarding Ethereum and Bitcoin is much larger than the others, followed by those of Litecoin and Stellar, respectively.
Specifically, in
Table 3, we notice that, especially when considering a small number of users, overlap can be identified. More to the point, user #Forbes is observed among the top users in two features, namely followers as well as lists. The same stands for other users that exist in the lists of two different features.
4.2. Correlation Analysis
In the second set of experiments, we observe in
Table 4 that the feature of lists has a strong degree of correlation with the feature of followers, that is, the highest value is equal to 0.795. Similarly, the feature of favorites is also strongly associated with the feature of retweets, with the value of
being the second highest degree of correlation. Finally, the feature of followers appears to have a weak correlation with the feature of retweets and the same stands for Lists with Favorites.
The relationship of the user influence is found to be positive using a Pearson statistical method. Respectively,
Table 5 and
Table 6 assess the relatedness among the same features by employing Pearson’s and Kendall’s coefficients. Similar behavior is verified by both of these correlation methods, although the values of the latter are slightly different (with either lower or higher reduction).
4.3. Sentiment Analysis Results
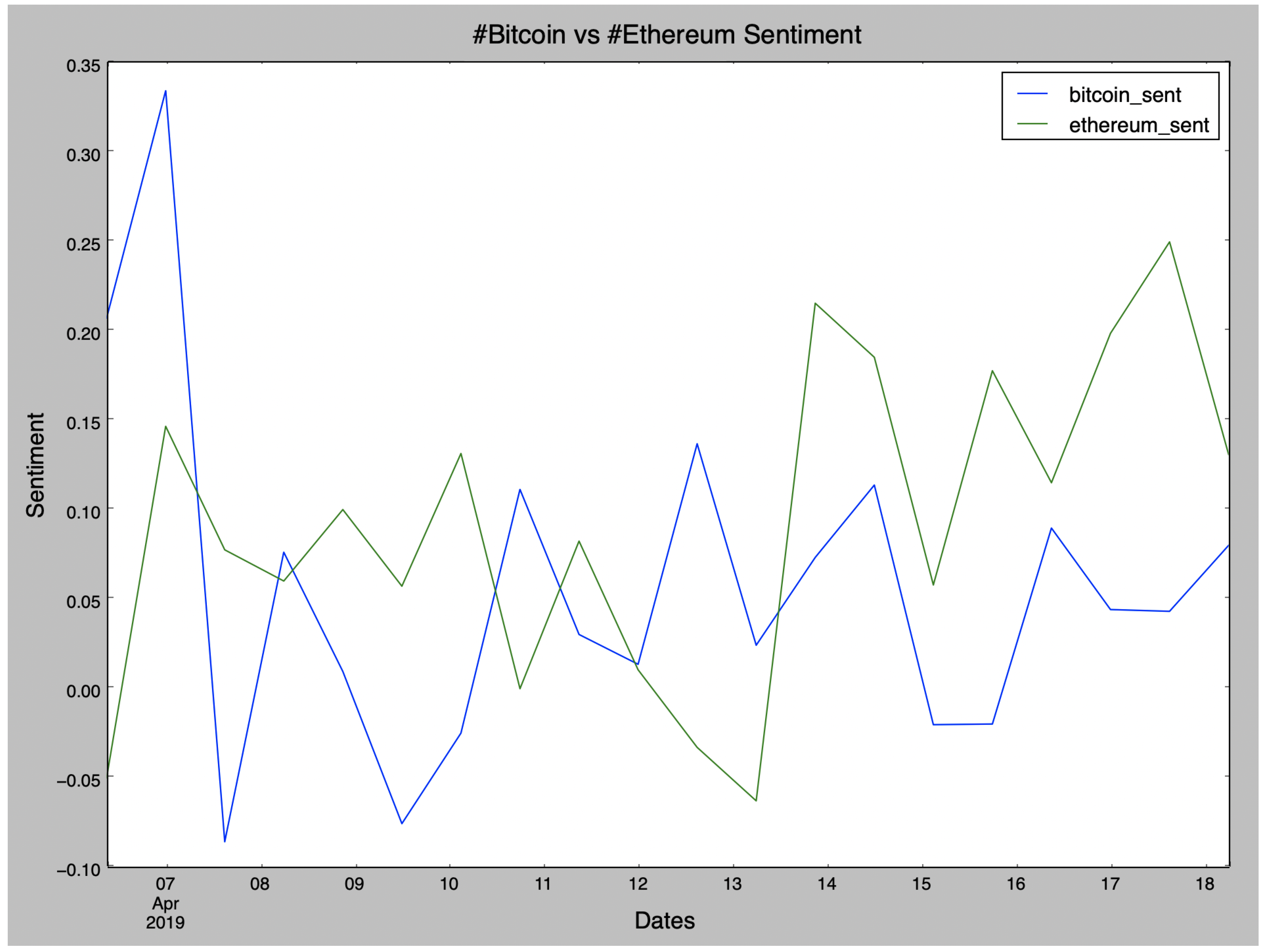
Furthermore, another experiment concerns the sentiment scores of posts per cryptocurrency, where we will focus only on Bitcoin and Ethereum in
Figure 1. Sentiment analysis relies on a dictionary which has lexical features corresponding with emotion values, which constitute the sentiment scores. The sentiment score of a tweet can be acquired by summing up the sentiment score of each word in it.
We tried to draw conclusions about their popularity not by counting the overall number of tweets but by measuring the sentiment of the tweets regarding these two cryptocurrencies. We can not identify any important notions regarding the price of each cryptocurrency; nevertheless, fluctuations of tweets sentiment by observing the timelines of the most influential user groups can be illustrated.
4.4. Features Statistical Significance on Cryptocurrency Popularity Prediction
To assess cryptocurrency popularity, we based our proposed methodology on (a) user influence and (b) sentiment scores. Sentiment analysis is often combined with a (Granger-) causality test and/or regression model(s) [
28]. Initially, we evaluate the statistical significance (
p-value) of time lag in both components of popularity using the Granger causality test. The null hypothesis (
) mentions that sentiment/followers/retweets/favorites/lists time series do not (Granger) cause cryptocurrency popularity time series.To reject the null hypothesis, it can be shown that sentiment/followers/retweets/favorites/lists values provide statistically significant information about future values of popularity.
Cryptocurrency popularity is treated as a multivariate autoregressive model of order
p. Let us consider the variables
,
,
,
,
, and
that represent the popularity, sentiment, followers, retweets, favorites, and lists time series data, respectively. In the last experiment, we evaluate five cases where each column of
Table 7,
Table 8,
Table 9 and
Table 10 corresponds to one of the following cases for all four cryptocurrencies, respectively:
Case 1: Forecast based on past values , .
Case 2: Forecast based on past values , .
Case 3: Forecast based on past values , .
Case 4: Forecast based on past values , .
Case 5: Forecast based on past values , .
We avoid combining the following pair of variables , , and due to their dependency, as Spearman’s correlation coefficient shows. The popularity model considers the lagged values of both and the time series of the rest features separately for various time lags. Specifically, this test aims to determine the significance of the association between time lag and each tweet sentiment (positive or negative). The same process is repeated independently for the time series that captures user influence, namely, followers, retweets, favorites, and lists in relation to the time series. This test was performed on a short time period of 12 days (from 6 April to 18 April 2020) to identify relations that are statistically significant (p < 0.05).
Observing
Table 7,
Table 8,
Table 9 and
Table 10, for Bitcoin, Ethereum, Litecoin, and Stellar cryptocurrencies, we conclude the predictive power of all variables on the popularity variable, as the
p-values are all well below the
level. Hence, we reject the null hypothesis, and, as a result, the current data are stationary. The lower the
p-value (
) of the variables, the higher their predictive power on cryptocurrencies’ popularity is. Finally, the daily changes in Twitter metrics-variables could forecast a similar rise or fall in cryptocurrency popularity and its fluctuations in advance.
5. Conclusions and Future Work
In this paper, we focused on comparing the popularity of four popular cryptocurrencies based on two different results. Initially, the number of tweets for a concrete time period was measured, and, in the following, the classification of these tweets as positive or negative was implemented. Furthermore, the Granger causality analysis is applied to identify the proper time lag and the most influential variable to predict future values of the cryptocurrency popularity considering the past. In addition, given that previous correlation analysis only indicates the relationship between features (either positive or negative), it could be used in conjunction with convergent cross-mapping (CCM) [
50] to determine the direction and magnitude of the causality (as illustrated in Figure 4 of Sugihara et al. [
51]), also studying the problem under noisy conditions.
For future work, the analysis could be improved by employing a domain-specific lexicon, as the latter can improve the classifier performance and the prediction accuracy by identifying corresponding cryptocurrency, economy and financial terms; thus, a more representative sentiment can be yielded [
28]. Moreover, Bitcoin price can be treated as a time-series problem where the price index can be forecasted with the use of machine learning techniques, like Recurrent Neural Network (RNN), Long Short Term Memory (LSTM), or ARIMA model [
52,
53,
54]. The proposed method of predicting fluctuations in the price and trading volume of cryptocurrencies based on user comments and replies in online communities is likely to increase the understanding and availability of cryptocurrencies if a range of improvements and applications are implemented. Finally, different approaches to user comments and replies in online communities are expected to bring more significant results in diverse fields.


 ,
, 


{kind=link}