Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake e-Commerce Sites


Abstract
:1. Introduction
- A generic system design for effective and efficient analysis of tree data with the subpath kernel;
- A detailed application of the subpath kernel to document object model (DOM) trees, an important example of tree data; and
- The remarkably high performance observed in analysis of DOM trees for detecting fake e-commerce sites with the subpath kernel system.
- Web-page contents can provide information at the finest granularity, and the range of features that can be extracted is the widest. The features of hyperlinked URLs [11], linked images [11,12], and embedded executable codes [13] are all extracted from page contents. Distributions of various information such as terms used [14], tag contents [11], contents types [14] and terms’ TF-IDF values [15,16] are also useful features. In exchange, the detailed investigation of web-page contents may cause damages to users’ computers by executing malware included, and features extracted from texts are prone to be language-specific. More importantly, content-based features can be shallow in many cases, that is, it is not difficult for adversaries to alter them so as to circumvent detection.
- The URL of a website can also provide useful information for phishing detection. The features include not only tokens from the URL [15,16,17] but also metadata obtained from external sources such as DNS [15], Google PageRank [15] and Amazon Alexa [14]. Because of the limit of the length of URL strings, the information obtained is also limited. Link redirection and change of web-contents can be an effective circumvention method, as well.
- A blacklist is created in a concentrative manner and specifies URLs of known phishing sites. Since its trustworthiness is high, it is widely used in real services like Google Safe Browsing [18] and eBay Toolbar [7]. Nevertheless, automated crawlers can be easily detected, and also, changing web-contents can easily outdate it. The most significant disadvantage of blacklists is the time difference between discovery of phishing sites and their registration to blacklists. The most significant disadvantage of blacklists is the time difference between discovery of phishing sites and their registration on blacklists.
2. The Data Used in Our Research
2.1. Positive Examples—Fake Sites
2.2. Negative Examples—Authentic Sites
2.3. Partition into a Training and Validation Datasets
3. Similarity Measures for DOM Trees
3.1. Measures Based on Shallow Features
3.2. Measures Based on Deep Features
- Kullback-Leibler divergence is the best known example, but it does not satisfy the axiom of symmetry. The symmetric divergences include Jensen-Shannon divergence, Bhattacharrya distance, Hellinger distance, -norm and Brownian distance. Divergences can be used with distance-based classifiers such as the nearest centroid and k-nearest neighborhood algorithms for classification, and k-means and k-memoid algorithms for clustering.
- A positive definite kernel can be viewed as an inner product operator of some inner product space [28] (reproducing kernel Hilbert space, RKHS). That is, by some mapping , an element can be identified with a vector , and holds. In particular, normalization of yields the well-known cosine similarity.More importantly, by identifying as a subspace of , we can extensively apply many useful multivariate analysis techniques to including PCA for feature extraction, SVM classifier for classification, the kernel k-means algorithm for clustering, and Gaussian process analysis for regression. A positive definite mapping kernel [27], in addition, evaluates spectrum distributions.
3.3. Prior Work on Tree Mapping Kernels
3.3.1. Positive Definite Mapping Kernels
- is positive definite, if k is positive definite.
- is transitive, that is, if and , then the composition is in .
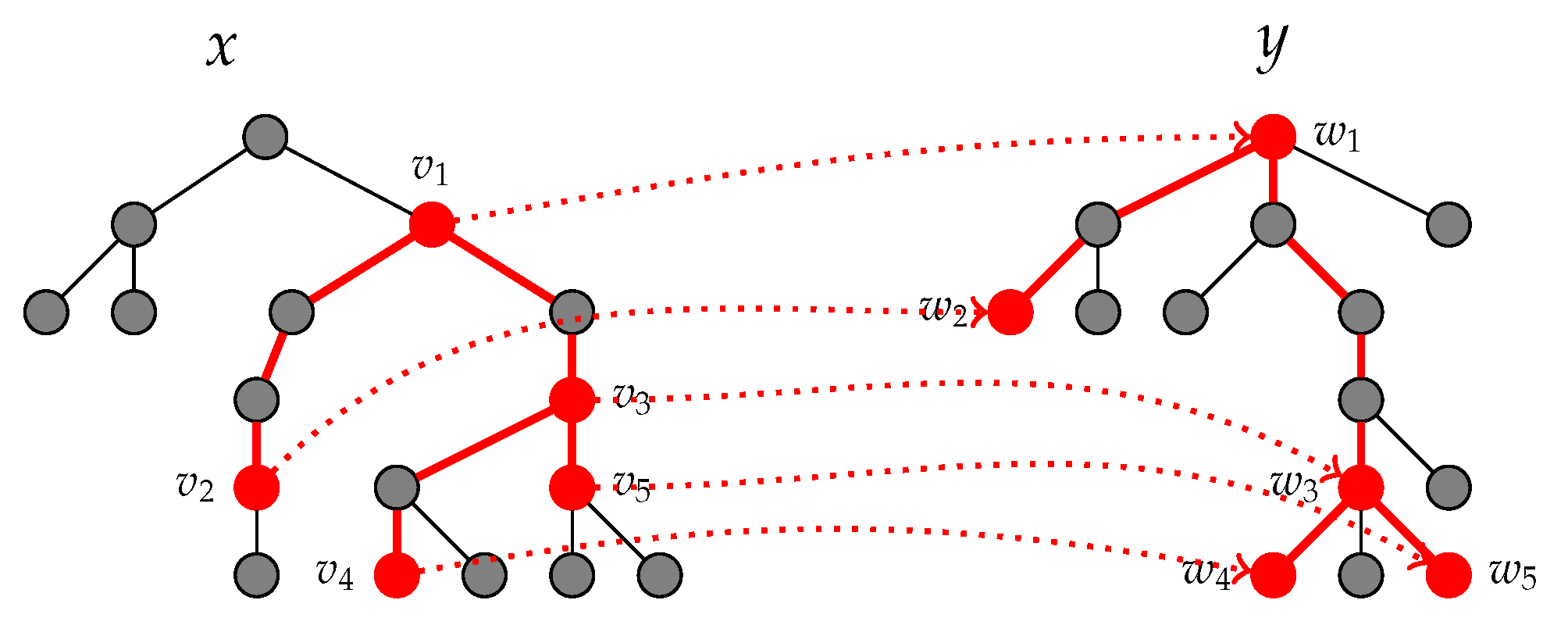
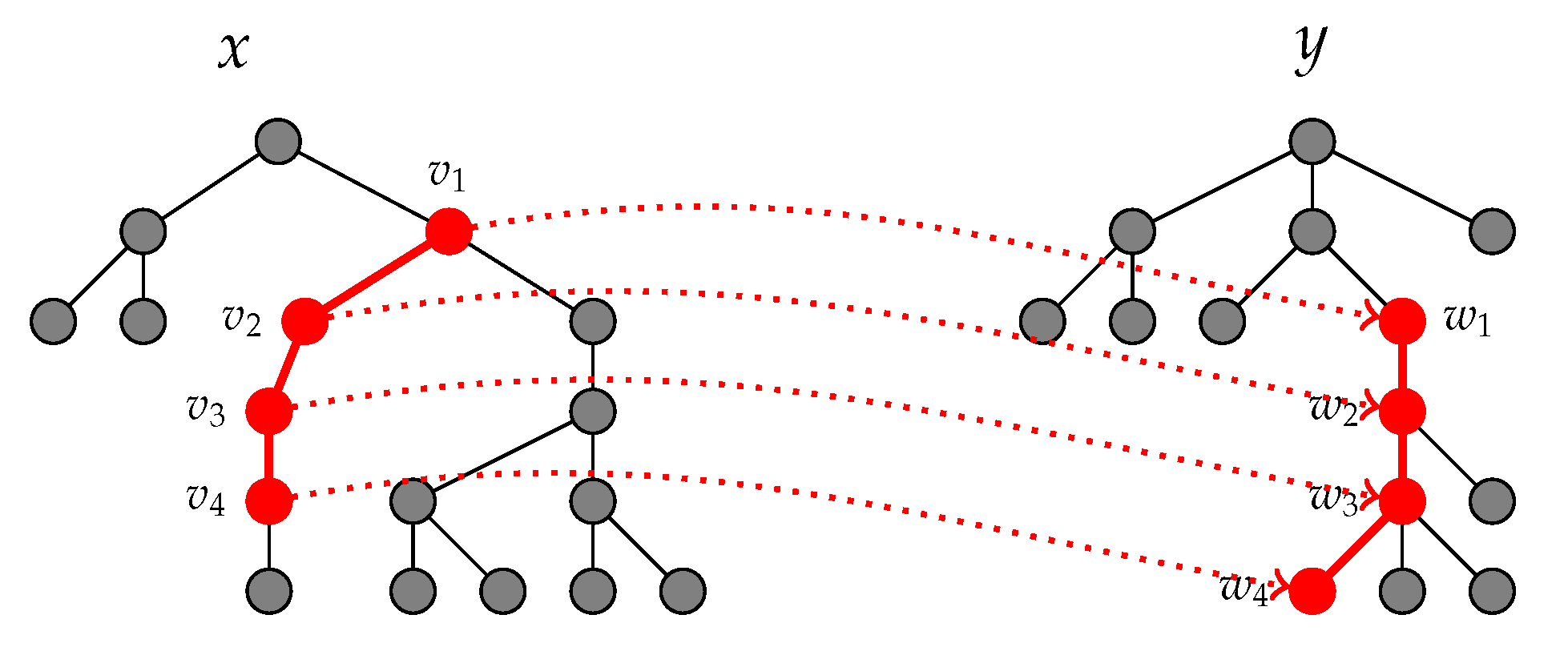
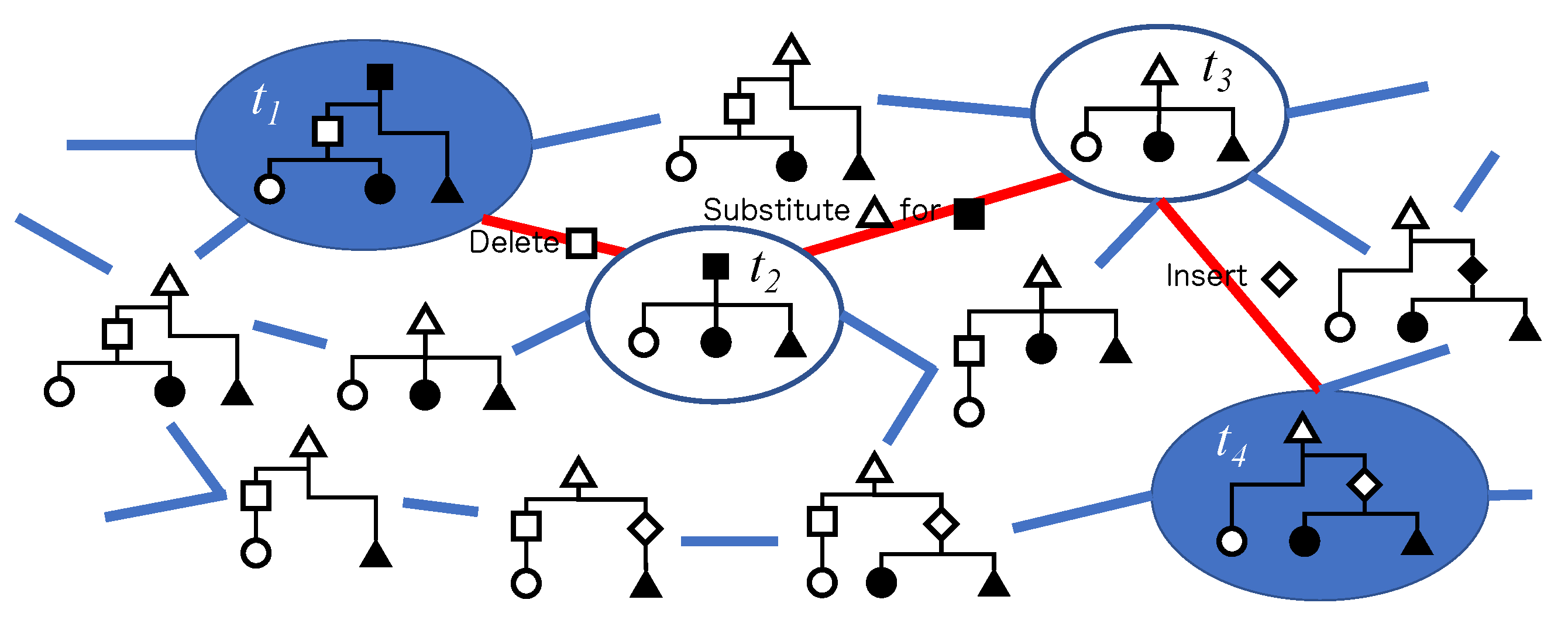
3.3.2. Tree Mapping Kernels
- is a one-to-one partial mapping;
- preserves the generation orders of x and y, that is, , if, and only if, ;
- preserves the generation orders of x and y, that is, , if, and only if, ;
3.3.3. A Comparison of Tree Mapping Kernels
3.4. Conclusion on Kernel Selection
- Linear time algorithms to compute the subpath kernel are known [4,5]. Since the time complexity of computing other tree kernels is mostly of the quadratic order of the size of input trees, this advantage is significant. In particular, this enables real-time detection of fake large-scale DOM trees with thousands of vertices.
- The definition of the subpath kernel is invariant no matter whether trees are ordered or unordered. Although DOM trees are derived as ordered trees, adversaries may change the traversal order of vertices without impacting their logical meaning or layout. Thus, we see that the results by the subpath kernel is secure against the attack of changing the traversal order.
4. The Subpath Kernel
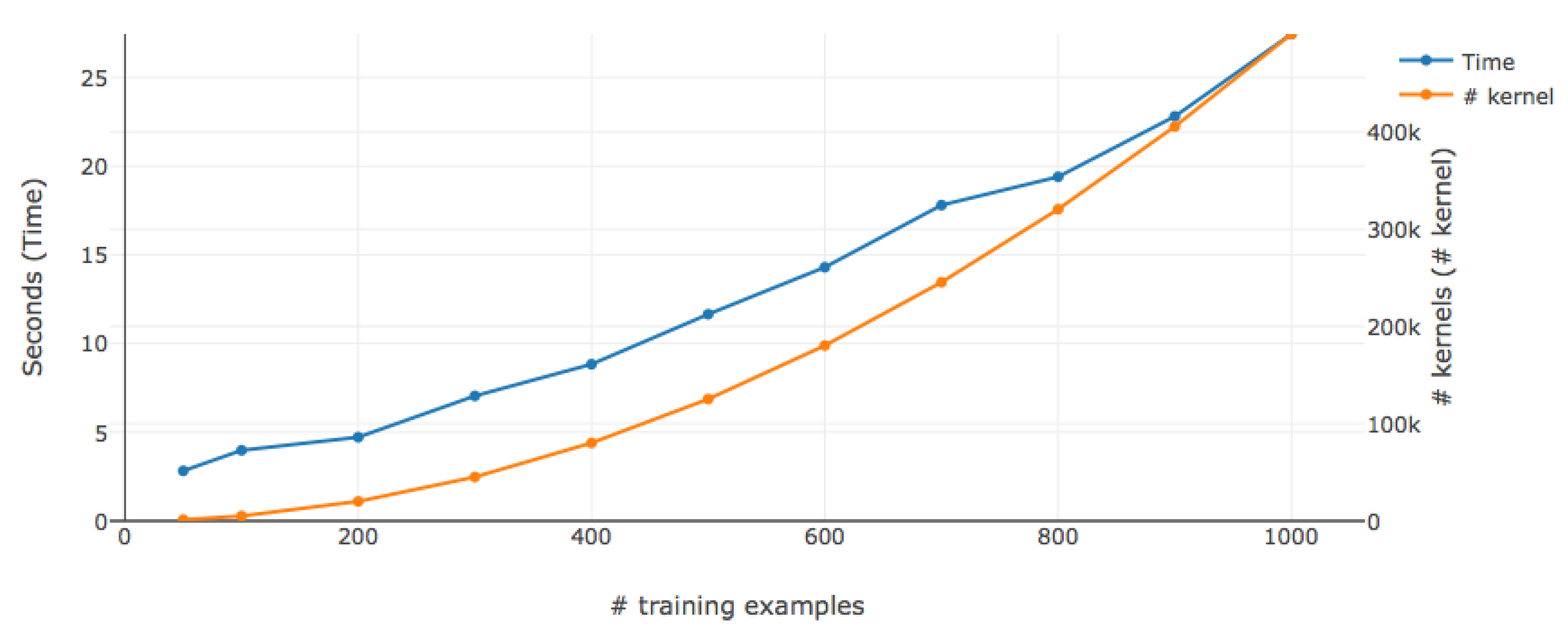
4.1. Efficient Computing of the Subpath Kernel
4.1.1. Extraction of Suffixes
4.1.2. Generation of Least Common Prefix Arrays
4.2. Understanding the Decay Factor
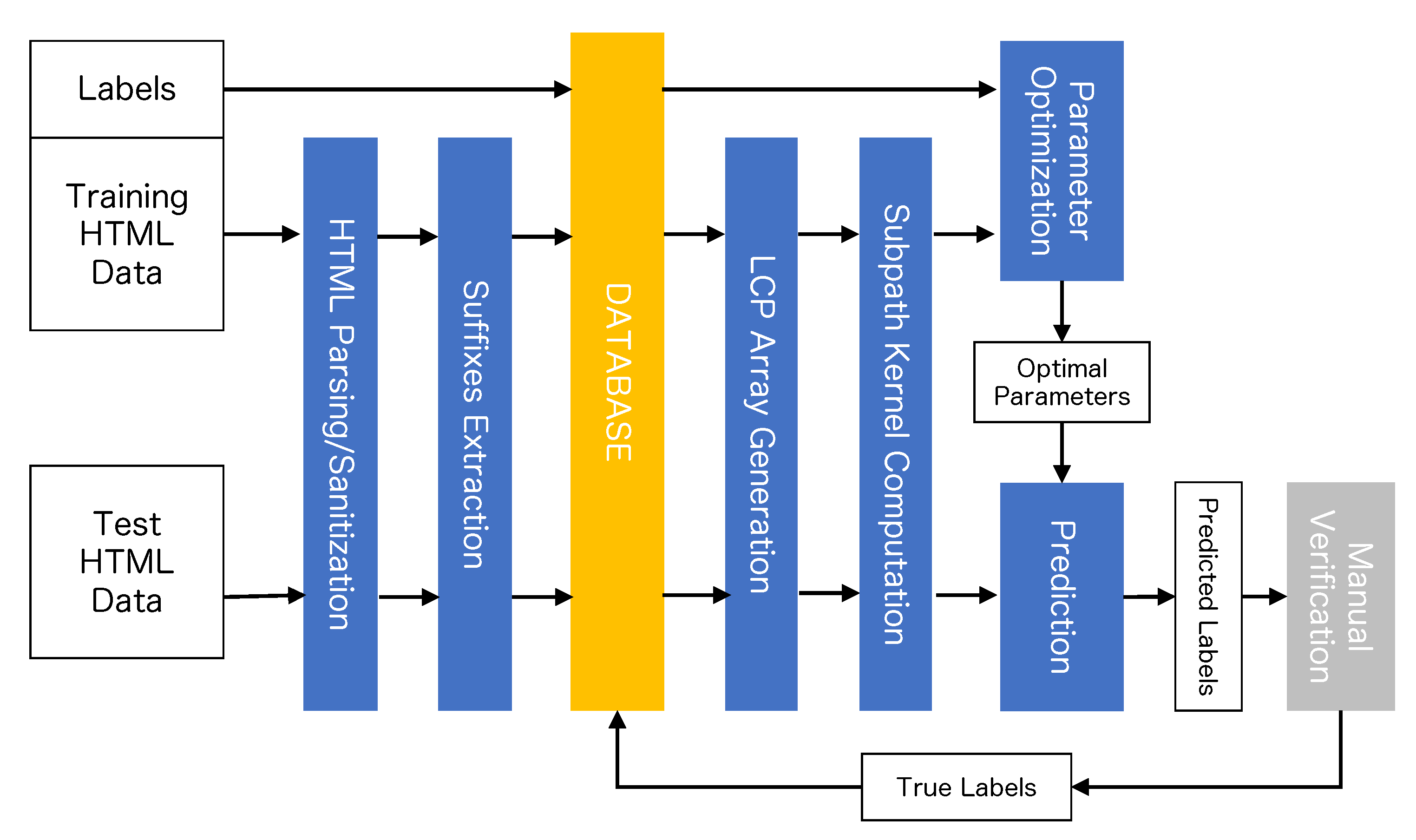
5. The Proposed Method
5.1. The Entire Picture
5.2. Suffixes Extraction
5.3. Gram Matrix Generation
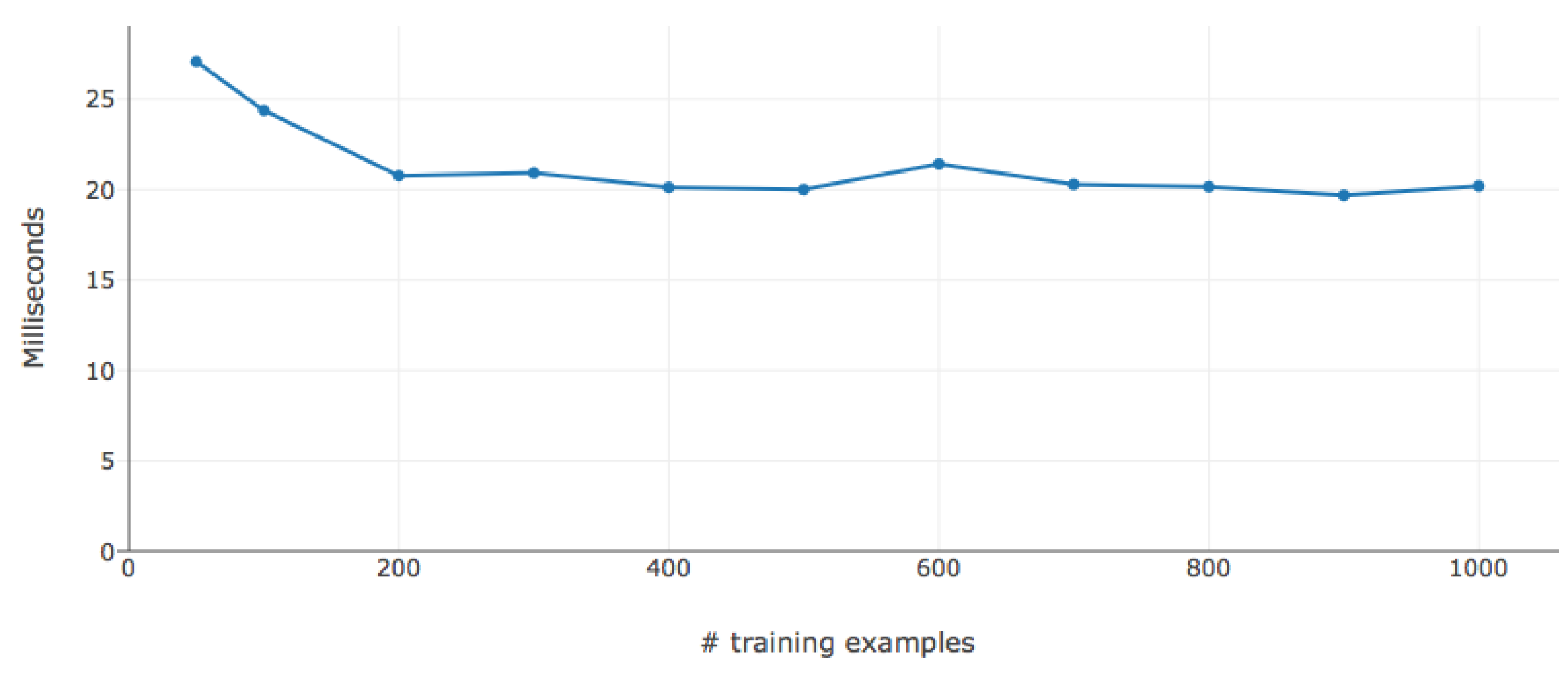
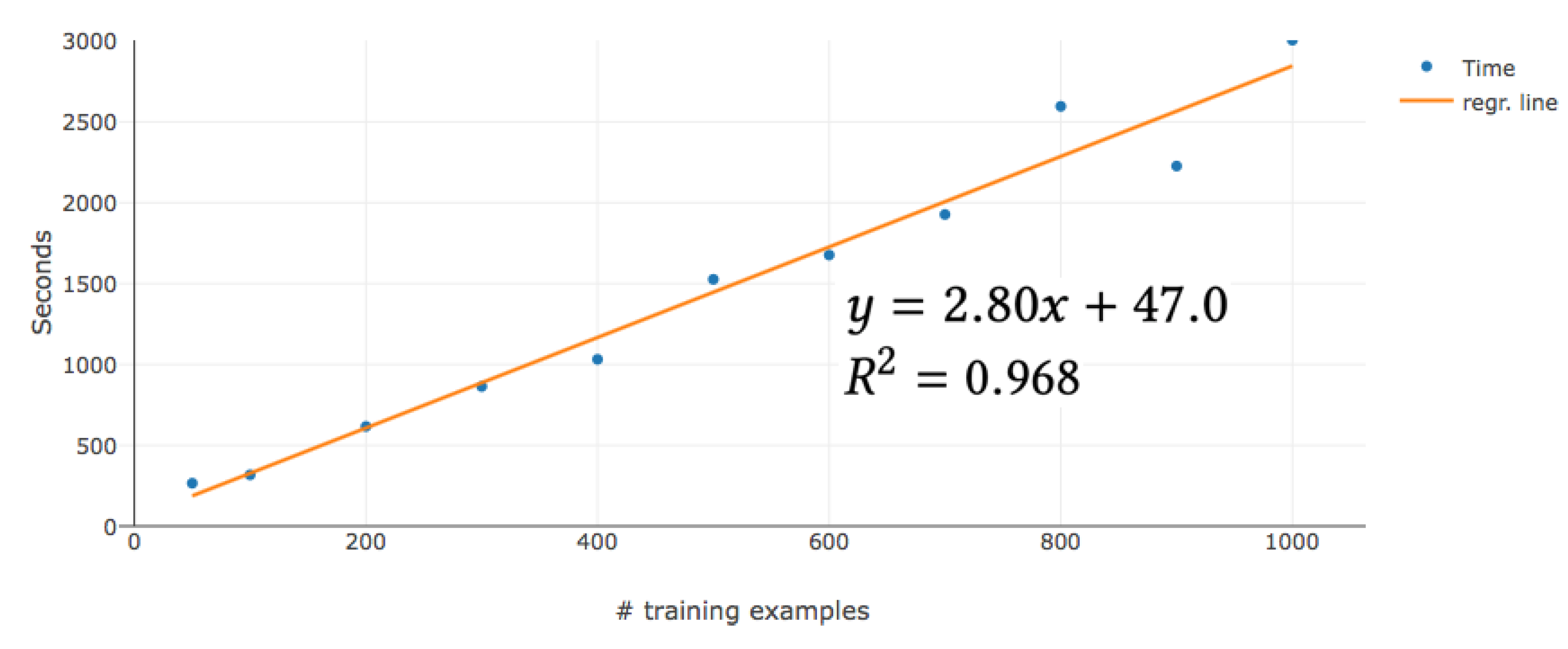
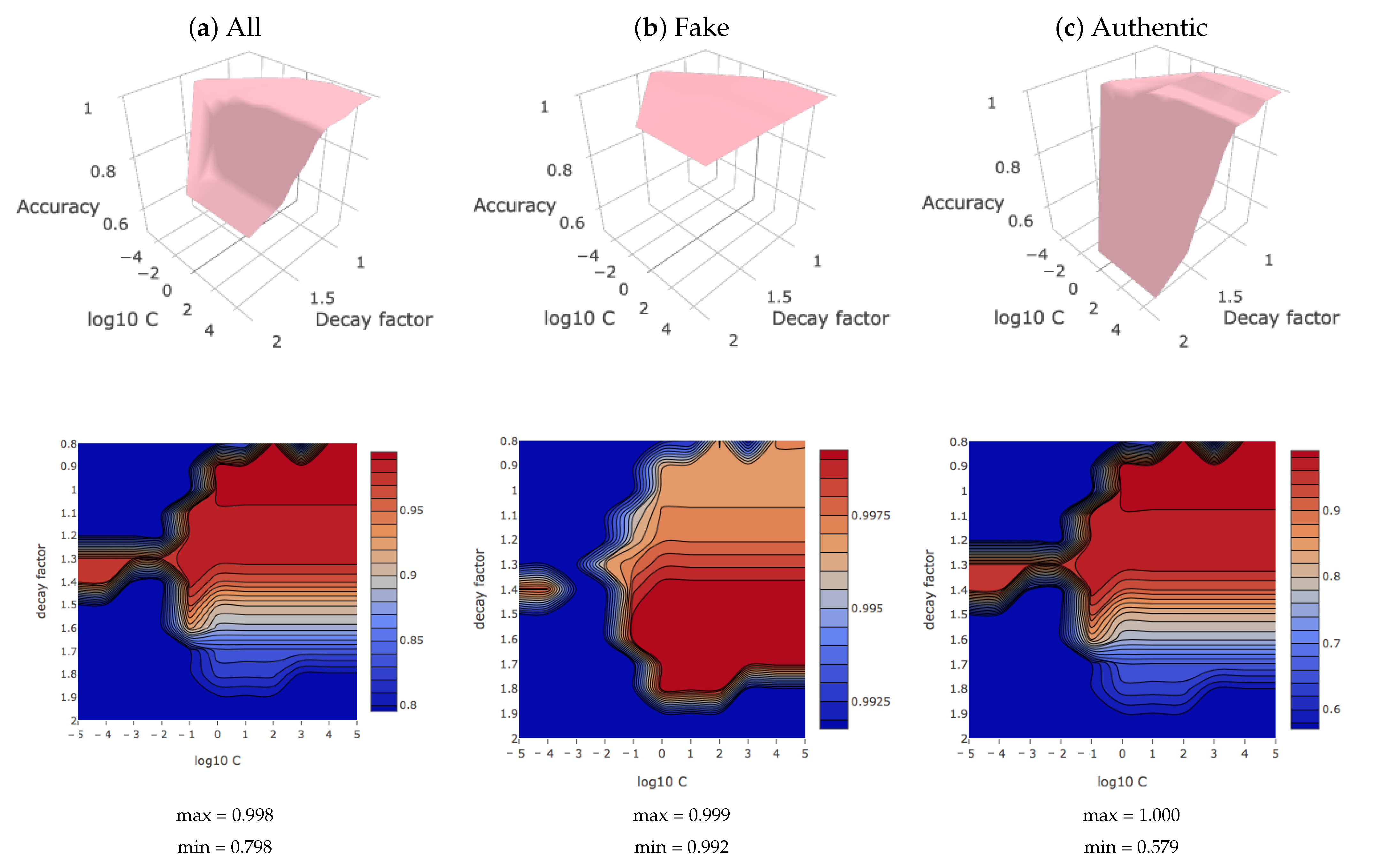
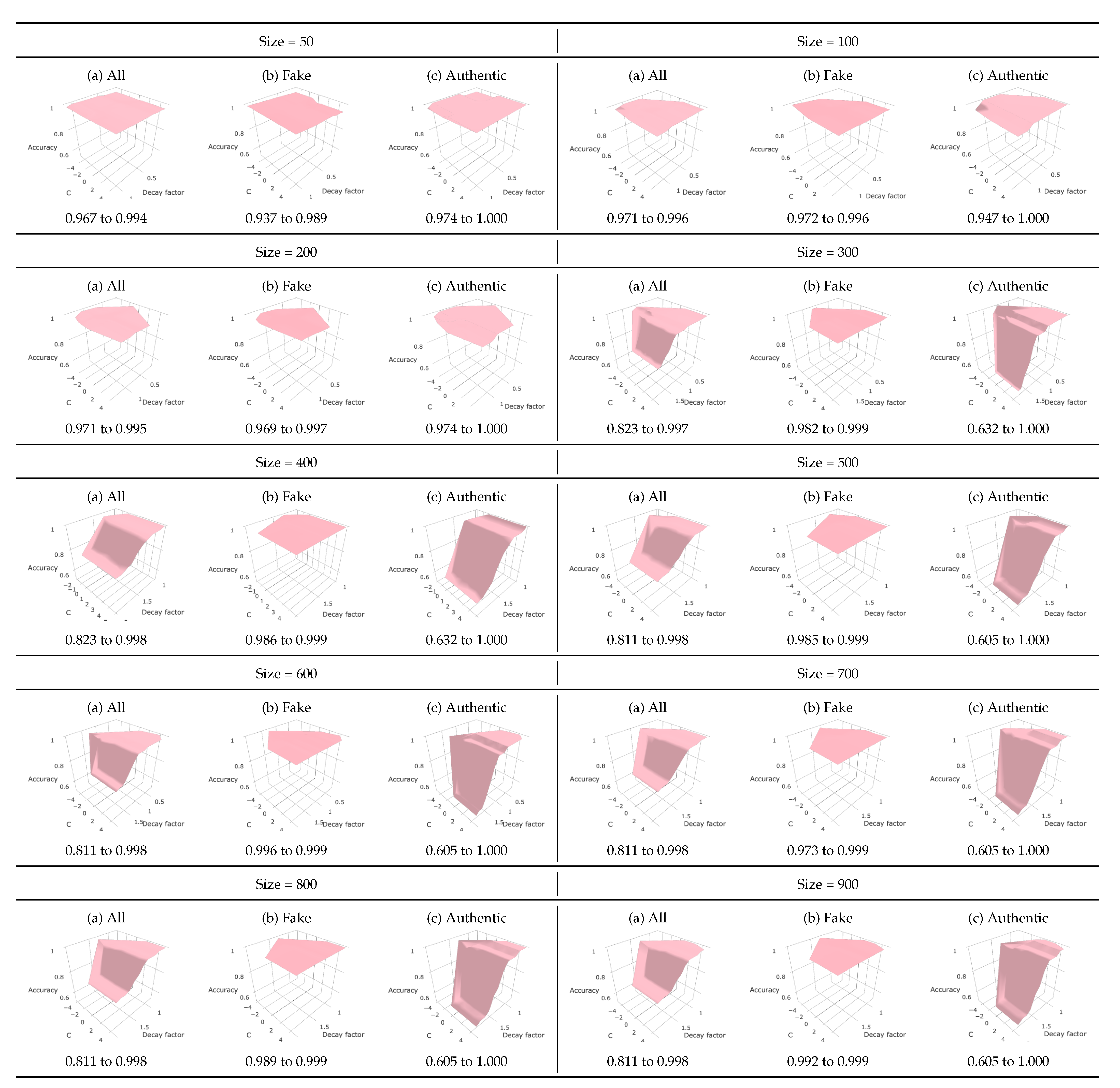
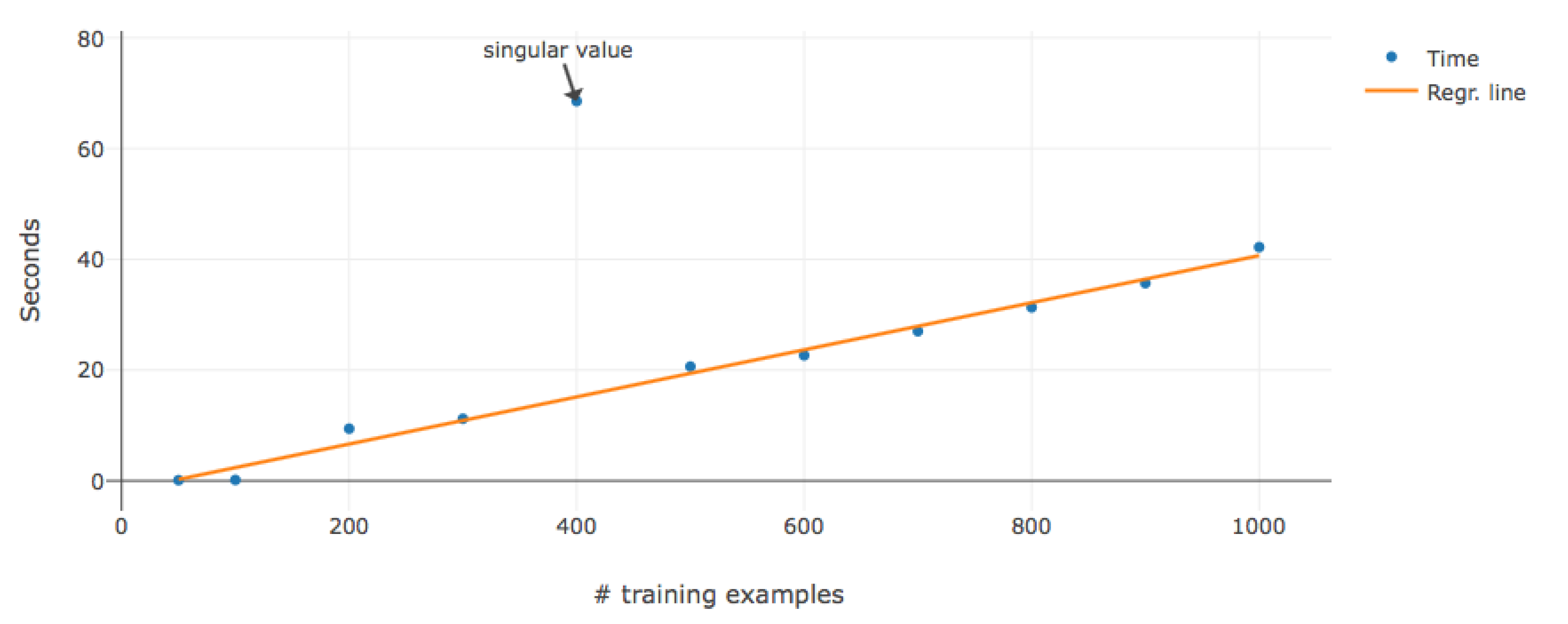
5.4. Hyper-Parameter Optimization
5.5. Prediction
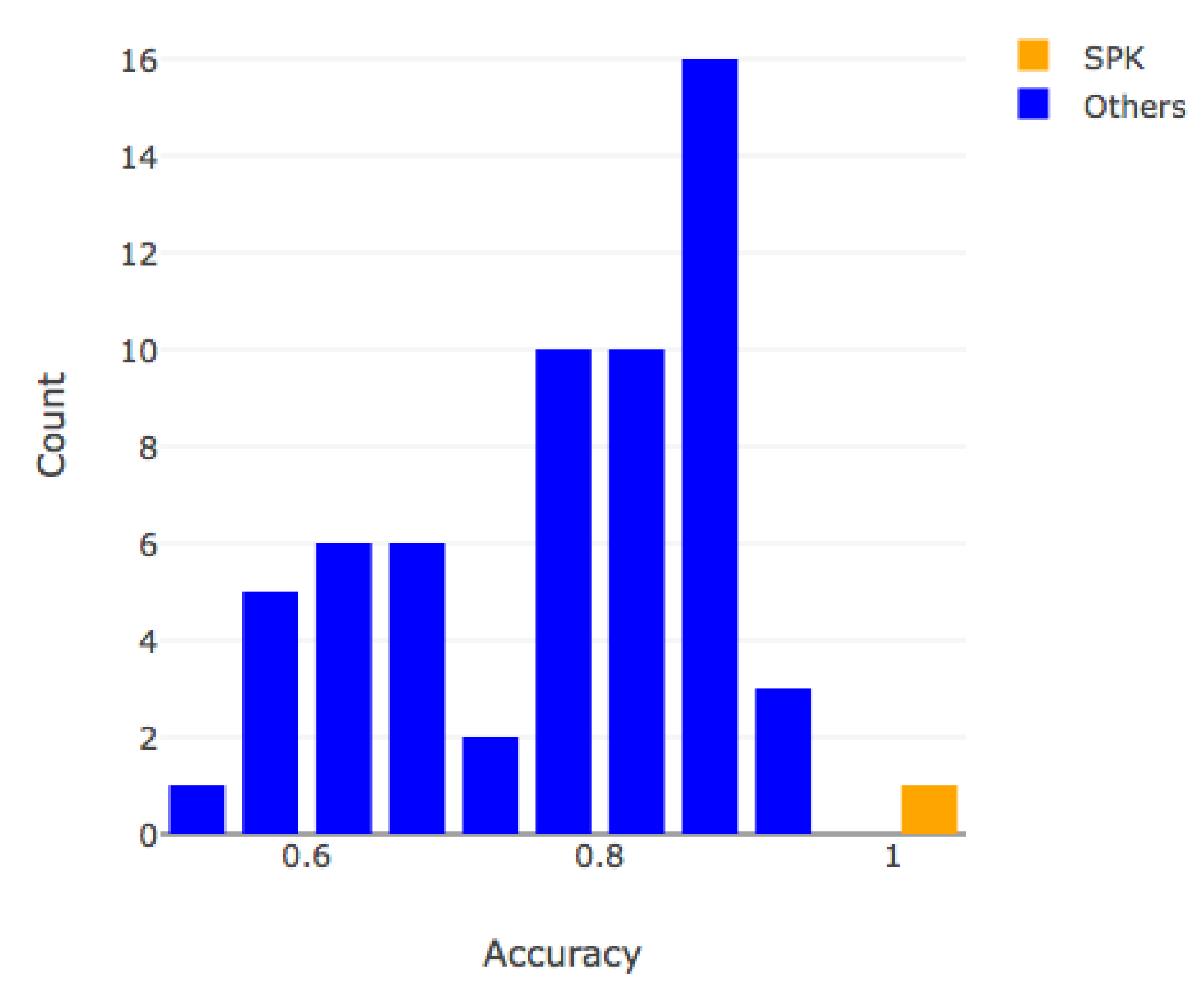
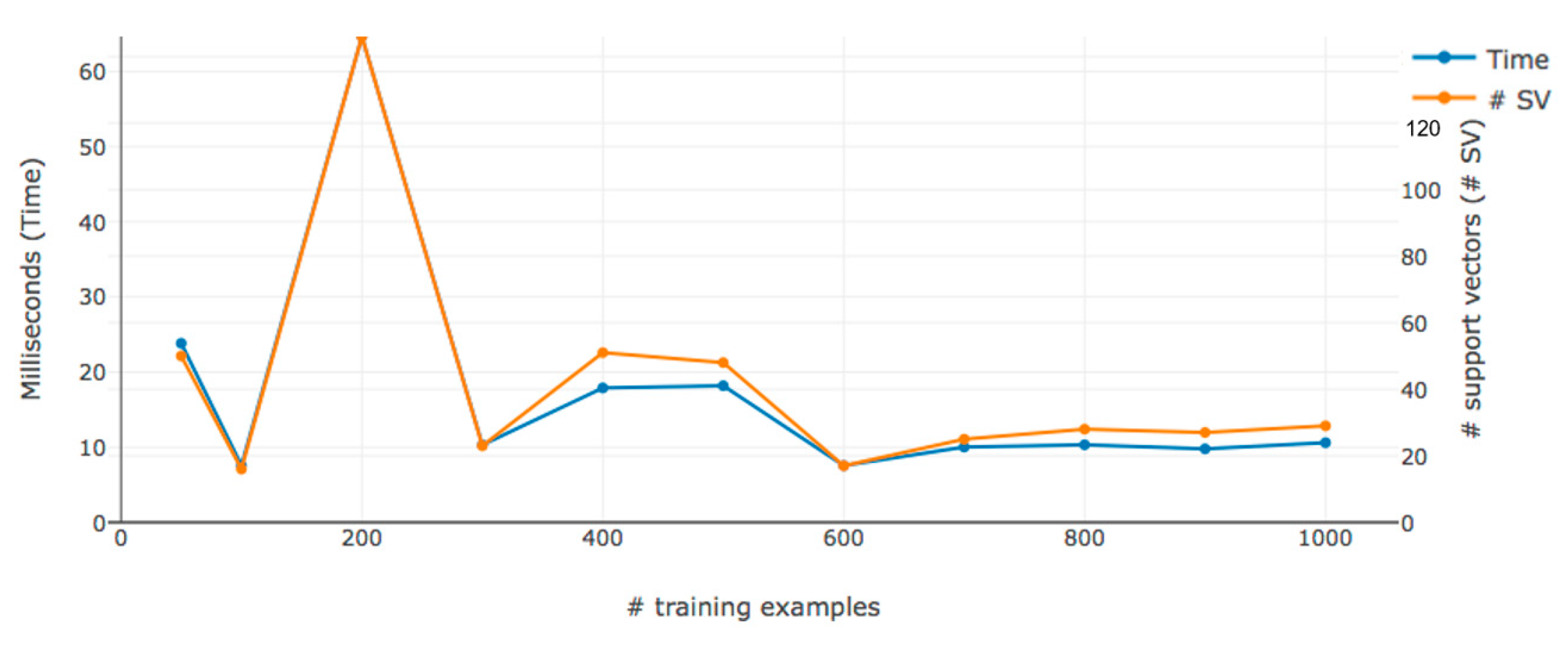
5.6. Comparison in Accuracy Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. A Theory of Positive Definite Kernels
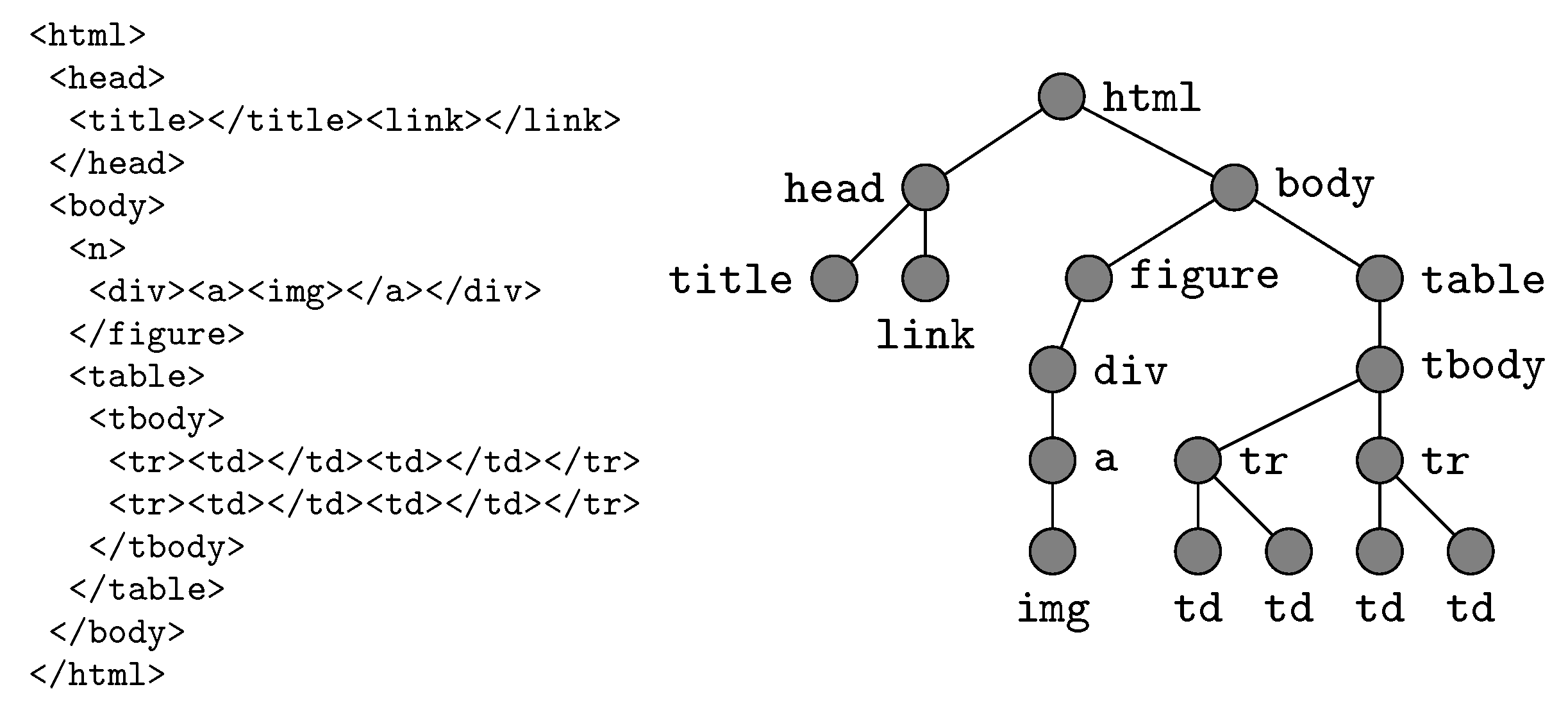
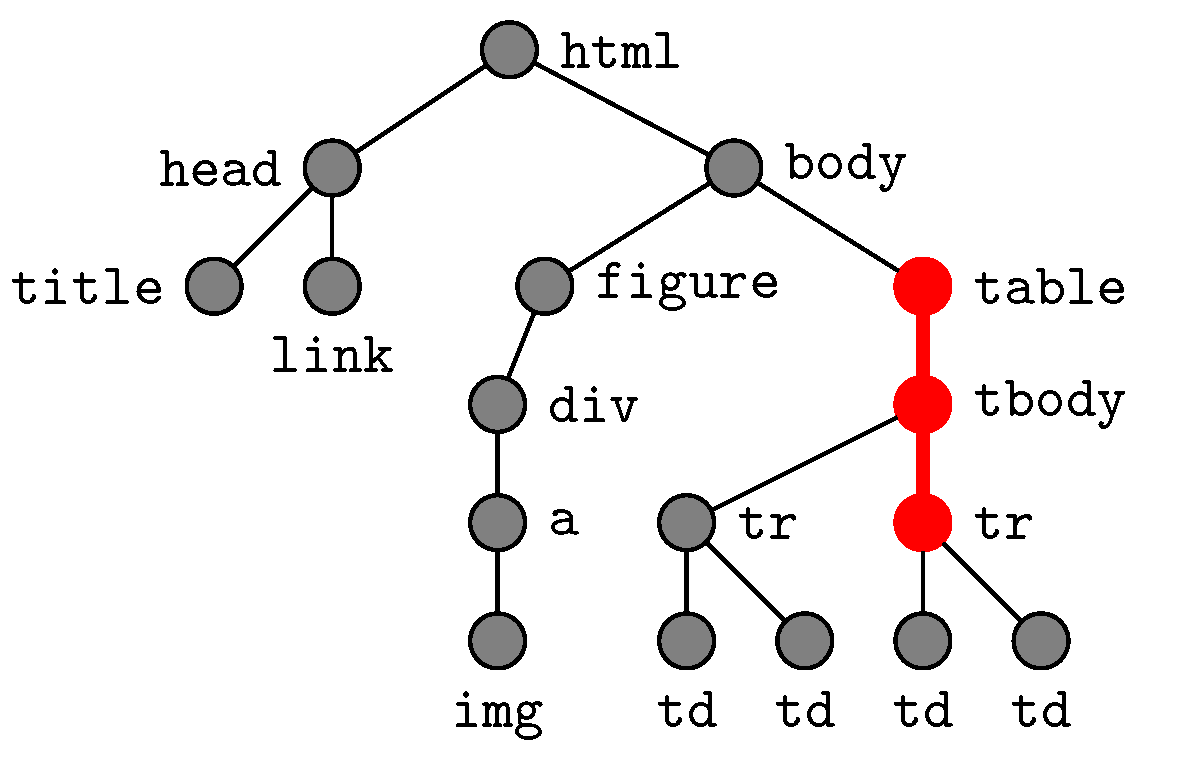
Appendix B. Rooted Ordered Trees
- The root exists such that for any .
- For any , is totally ordered.

Appendix C. Edit Distances for Trees
Appendix C.1. Taï Distance and Its Variations

- Zhang and Shasha [40] proposed an algorithm of-time: X and Y denote rooted ordered trees; , and denote the size (the number of vertices), the width (the number of leaves) and the height (the length of the longest path from the root to a leaf) of X. According to shapes of trees, this varies between and .
- Demaine et al. [50] further optimized this technique and presented an algorithm of -time. Demaine’s algorithm is the fastest in terms of the asymptotic evaluations, but it easily lapses into the worst case. Therefore, the algorithm of Zhang and Shasha in fact outperforms Demaine’s algorithm in many practical cases.
- RTED, an algorithm that Pawlik and Augsten [51] have developed, not only has the same asymptotic complexity as Demaine’s algorithm but also almost always outperforms the competitors in practice.
Appendix C.2. Mappings Associated with Edit Paths
Appendix C.3. The Constrained Distance

Appendix C.4. The Degree-Two Distance

Appendix A. Divergences
Appendix E. Positive Definite Kernels and RKHS
Appendix E.1. Properties of of Positive Definite Kernels
- .
- If , then for any y
- . This inequality is known as the Cauchy-Schwartz inequality.
- determines a distance over . This property is follows from the cosine formula.
- For and , the linear combination is positive definite.
- The product is positive definite.
- For any non-negative integer , the power is positive definite.
- For any polynomial with only positive coefficients, is positive definite.
Appendix B.2. RKHS for Finite Sets
References
- Taï, K.C. The tree-to-tree correction problem. J. ACM 1979, 26, 422–433. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Collins, M.; Duffy, N. Convolution Kernels for Natural Language. In Advances in Neural Information Processing Systems 14 [Neural Information Processing Systems: Natural and Synthetic, NIPS 2001]; MIT Press: Cambridge, MA, USA, 2001; pp. 625–632. [Google Scholar]
- Kimura, D.; Kashima, H. Fast Computation of Subpath Kernel for Trees. arXiv 2012, arXiv:1206.4642. [Google Scholar]
- Shin, K.; Ishikawa, T. Linear-time algorithms for the subpath kernel. In Proceedings of the 29th Annual Symposium on Combinatorial Pattern Matching (CPM 2018), Qingdao, China, 2–4 July 2018; pp. 22:1–22:13. [Google Scholar]
- Corona, I.; Biggio, B.; Contini, M.; Piras, L.; Corda, R.; Mereu, M.; Mureddu, G.; Ariu, D.; Roli, F. DeltaPhish: Detecting Phishing Webpages in Compromised Websites. arXiv 2017, arXiv:1707.00317. Available online: https://arxiv.org/abs/1707.00317 (accessed on 13 January 2021).
- Zhang, Y.; Egelman, S.; Cranor, L.; Hong, J. Phinding Phish: Evaluating anti-phishing tools. In Proceedings of the 14th Anual Network and Distributed System Security Symposium, San Diego, CA, USA, 28 February–2 March 2007. [Google Scholar]
- Li, L.; Helenius, M. Usability Evaluation of Anti-Phishing Toolbars. J. Comput. Virol. 2007, 3, 163–184. [Google Scholar] [CrossRef]
- Abbasi, A.; Chen, H. A comparison of tools for detecting fake websites. Computer 2009, 42, 78–86. [Google Scholar] [CrossRef]
- Marchal, S.; Asokan, N. On Designing and Evaluating Phishing Webpage Detection Techniques for the Real World. In Proceedings of the 11th USENIX Workshop on Cyber Security Experimentation and Test (CSET 18), Baltimore, MD, USA, 11–13 August 2018; USENIX Association: Baltimore, MD, USA, 2018. [Google Scholar]
- Corona, I.; Biggio, B.; Contini, M.; Piras, L.; Corda, R.; Mereu, M.; Mureddu, G.; Ariu, D.; Roli, F. DeltaPhish: Detecting Phishing Webpages in Compromised Websites. Lect. Notes Comput. Sci. 2017, 10492, 370–388. [Google Scholar]
- Liu, W. An antiphishing strategy based on visual similarity assessment. IEEE Internet Comput. 2006, 10, 58–65. [Google Scholar]
- Satish, S.; Babu, K.S. Phishing Websites Detection Based on Web Source Code and URL in the Webpage. Int. J. Comput. Sci. Eng. Commun. 2013, 1, 1–5. [Google Scholar]
- Marchal, S.; Saari, K.; Singh, N.; Asokan, N. Know Your Phish: Novel Techniques for Detecting Phishing Sites and Their Targets. In Proceedings of the 2016 IEEE 36th International Conference on Distributed Computing Systems (ICDCS), Nara, Japan, 27–30 June 2016; pp. 323–333. [Google Scholar]
- Whittaker, C.; Ryner, B.; Nazif, M. Large-Scale Automatic Classification of Phishing Pages. In Proceedings of the NDSS ’10, San Diego, CA, USA, 28 February–3 March 2010. [Google Scholar]
- Zhang, Y.; Hong, J.I.; Cranor, L.F. Cantina: A Content-based Approach to Detecting Phishing Web Sites. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; ACM: New York, NY, USA, 2007; pp. 639–648. [Google Scholar] [CrossRef]
- Marchal, S.; François, J.; State, R.; Engel, T. PhishStorm: Detecting Phishing With Streaming Analytics. IEEE Trans. Netw. Serv. Manag. 2014, 11, 458–471. [Google Scholar] [CrossRef] [Green Version]
- Gerbet, T.; Kumar, A.; Lauradoux, C. (Un)Safe Browsing; Technical Report RR-8594; INRIA: Talence, France, 2014. [Google Scholar]
- Raut, P.; Vengurlekar, H.; Shete, R. A Survey of Phishing Website Detection Systems. Int. Res. J. Eng. Technol. 2020, 7, 1145–1148. [Google Scholar]
- Vazhayil, A.; Vinayakumar, R.; Soman, K.P. Comparative Study of the Detection of Malicious URLs Using Shallow and Deep Networks. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, P.; Zhao, G.; Zeng, P. Phishing Website Detection Based on Multidimensional Features Driven by Deep Learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Shima, K.; Miyamoto, D.; Abe, H.; Ishihara, T.; Okada, K.; Sekiya, Y.; Asai, H.; Doi§, Y. Classification of URL bitstreams using bag of bytes. In Proceedings of the 21st Conference on Innovation in Clouds, Internet and Networks and Workshops (ICIN), Paris, France, 19–22 February 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Sönmez, Y.; Tuncer, T.; Gökal, H.; Avcı, E. Phishing web sites features classification based on extreme learning machine. In Proceedings of the 2018 6th International Symposium on Digital Forensic and Security (ISDFS), Antalya, Turkey, 22–25 March 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Machado, L.; Gadge, J. Phishing Sites Detection Based on C4.5 Decision Tree Algorithm. In Proceedings of the 2017 International Conference on Computing, Communication, Control and Automation (ICCUBEA), Maharashtra, India, 17–18 August 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Abbasi, A.; Zhang, Z.; Zimbra, D.; Chen, H.; Nunamaker, J.F. Detecting Fake Websites: The Contribution of Statistical Learning Theory. MIS Q. 2010, 34, 435–461. [Google Scholar] [CrossRef] [Green Version]
- Zahedi, F.M.; Abbasi, A.; Chen, Y. Fake-Website Detection Tools: Identifying Elements that Promote Individuals’ Use and Enhance Their Performance. J. Assoc. Inf. Syst. 2015, 16, 2. [Google Scholar] [CrossRef]
- Shin, K.; Niiyama, T. The mapping distance—A generalization of the edit distance—And its application to trees. In Proceedings of the 10th International Conference on Agent and Artificial Intelligence, ICAART 2018, Madeira, Portugal, 16–18 January 2018; Volume 2, pp. 266–275. [Google Scholar]
- Berg, C.; Christensen, J.P.R.; Ressel, R. Harmonic Analysis on Semigroups. Theory of Positive Definite and Related Functions; Springer: Berlin/Heidelberg, Germany, 1984. [Google Scholar]
- Haussler, D. Convolution Kernels on Discrete Structures; UCSC-CRL 99-10; Dept. of Computer Science, University of California at Santa Cruz: Santa Cruz, CA, USA, 1999. [Google Scholar]
- Shin, K.; Kuboyama, T. A generalization of Haussler’s convolution kernel—Mapping kernel. In Proceedings of the ICML 2008, Helsinki, Finland, 5–9 June 2008. [Google Scholar]
- Shin, K.; Kuboyama, T. A Comprehensive Study of Tree Kernels. In JSAI-isAI Post-Workshop Proceedings; Lecture Notes in Articial Intelligence 8417; Springer: Berlin/Heidelberg, Germany, 2014; pp. 329–343. [Google Scholar]
- Kashima, H.; Koyanagi, T. Kernels for Semi-Structured Data. In Proceedings of the 9th International Conference on Machine Learning (ICML 2002), Sydney, Australia, 8–12 July 2002; pp. 291–298. [Google Scholar]
- Shin, K. A Theory of Subtree Matching and Tree Kernels based on the Edit Distance Concept. Ann. Math. Artif. Intell. 2015. [Google Scholar] [CrossRef]
- Hommel, G. A stagewise rejective multiple test procedure based on a modified Bonferroni tests. Biometrika 1988, 75, 383–386. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Theory 2006, 7, 1–30. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. 2001. Available online: https://www.csie.ntu.edu.tw/~cjlin/libsvm/ (accessed on 12 January 2021).
- Rao, R.S.; Ali, S.T. PhishShield: A Desktop Application to Detect Phishing Webpages through Heuristic Approach. Procedia Comput. Sci. 2015, 54, 147–156. [Google Scholar] [CrossRef] [Green Version]
- Tyagi, I.; Shad, J.; Sharma, S.; Gaur, S.; Kaur, G. A Novel Machine Learning Approach to Detect Phishing Websites. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 425–430. [Google Scholar] [CrossRef]
- Jiang, T.; Wang, L.; Zhang, K. Alignment of trees—An alternative to tree edit. Theor. Comput. Sci. 1995, 143, 137–148. [Google Scholar] [CrossRef]
- Zhang, K.; Shasha, D. Simple Fast Algorithms for the Editing Distance Between Trees and Related Problems. SICOMP 1989, 18, 1245–1262. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, J.T.L.; Shasha, D. On the editing distance between undirected acyclic graphs. Int. J. Found. Comput. Sci. 1996, 7, 43–58. [Google Scholar] [CrossRef]
- Zhang, K.; Statman, R.; Shasha, D. On the editing distance between unordered labeled trees. Inf. Process. Lett. 1996, 42, 133–139. [Google Scholar] [CrossRef]
- Zhang, K. A Constrained Edit Distance Between Unordered Labeled Trees. Algorithmica 1996, 15, 205–222. [Google Scholar] [CrossRef]
- Lu, C.L.; Su, Z.Y.; Tang, G.Y. A New Measure of Edit Distance between Labeled Trees. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2108, pp. 338–348. [Google Scholar]
- Wang, J.T.L.; Zhang, K. Finding similar consensus between trees: An algorithm and a distance hierarchy. Pattern Recognit. 2001, 34, 127–137. [Google Scholar] [CrossRef]
- Kuboyama, T.; Shin, K.; Miyahara, T.; Yasuda, H. A theoretical analysis of alignment and edit problems for trees. In Proceedings of the Theoretical Computer Science, The 9th Italian Conference, Siena, Italy, 12–14 October 2005; pp. 323–337. [Google Scholar]
- Neuhaus, M.; Bunke, H. Bridging the Gap between Graph Edit Distance and Kernel Machines; World Scientific: Singapore, 2007. [Google Scholar]
- Klein, P.N. Computing the edit-distance between unrooted ordered trees. LNCS 1998, 1461, 91–102. [Google Scholar]
- Dulucq, S.; Touzet, H. Analysis of tree edit distance algorithms. In Proceedings of the 14th Annual Symposium on Combinatorial Pattern Matching (CPM), Michoacan, Mexico, 25–27 June 2003; pp. 83–95. [Google Scholar]
- Demaine, E.D.; Mozes, S.; Rossman, B.; Weimann, O. An Optimal Decomposition Algorithm for Tree Edit Distance. ACM Trans. Algo. 2006, 6, 2. [Google Scholar]
- Pawlik, M.; Augsten, N. RTED: A Robust Algorithm for the Tree Edit Distance. VLDB Endow. 2011, 5, 334–345. [Google Scholar] [CrossRef]
- Zhang, K. Algorithms for the constrained editing distance between ordered labeled trees and related problems. Pattern Recognit. 1995, 28, 463–474. [Google Scholar] [CrossRef]
- Richter, T. A New Measure of the Distance between Ordered Trees and Its Applications; Technical Report 85166-CS; Dept. of Computer Science, Univ. of Bonn: Bonn, Germany, 1997. [Google Scholar]
- Bille, P. A survey on tree edit distance and related problems. Theor. Comput. Sci. 2005, 337, 217–239. [Google Scholar] [CrossRef] [Green Version]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Suffixes | LCP | |
|---|---|---|
| 3 | 1 | 0 |
| 3 | 0 | 1 |
| 4,3 | 0 | 0 |
| 6,4,3 | 0 | 0 |
| 7,4,3 | 0 | 0 |
| 8,3 | 2 | 0 |
| 8,3 | 0 | 1 |
| 10,24,23,8,3 | 1 | 1 |
| 10,65,8,3 | 0 | 0 |
| 13,17,10,65,8,3 | 0 | 0 |
| 17,10,65,8,3 | 0 | 0 |
| 23,8,3 | 3 | 0 |
| 23,8,3 | 0 | 1 |
| 24,23,8,3 | 4 | 0 |
| 24,23,8,3 | 0 | 1 |
| 25,10,24,23,8,3 | 1 | 1 |
| 25,24,23,8,3 | 5 | 0 |
| 25,24,23,8,3 | 0 | 0 |
| 26,25,10,24,23,8,3 | 7 | 1 |
| 26,25,10,24,23,8,3 | 2 | 1 |
| 26,25,24,23,8,3 | 6 | 0 |
| 26,25,24,23,8,3 | 6 | 0 |
| 26,25,24,23,8,3 | 6 | 0 |
| 26,25,24,23,8,3 | 0 | 0 |
| 65,8,3 | −1 | 0 |
| Method | Test Dataset | Train | Evaluation | ||||
|---|---|---|---|---|---|---|---|
| Authentic | Fake | /Test | Prec. | Recall | F-Score | Acc. | |
| Subpath Kernel (100) | 2849 | 3097 | 1/60 | 0.988 | 1.000 | 0.994 | 0.994 |
| Subpath Kernel (1000) | 2849 | 3097 | 1/6 | 0.999 | 1.000 | 0.999 | 0.999 |
| Whittaker et al. [15] | 1,499,109 | 16,967 | 6/1 | 0.989 | 0.915 | 0.951 | 0.999 |
| Cantina [16] | 2100 | 19 | – | 0.212 | 0.89 | 0.342 | 0.969 |
| PhishStorm [17] | 48,009 | 48,009 | 9/1 | 0.984 | 0.913 | 0.947 | 0.949 |
| PhishShield [37] | 250 | 1600 | – | 0.999 | 0.971 | 0.985 | 0.966 |
| Yang et al. [21] | 22,390 | 22,445 | 44/1 | 0.994 | 0.986 | 0.996 | 0.989 |
| Sonmez et al. [23] | – | – | – | – | – | – | 0.953 |
| Tyagi et al. [38] | – | – | – | – | – | – | 0.984 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, K.; Ishikawa, T.; Liu, Y.-L.; Shepard, D.L. Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake e-Commerce Sites. Mach. Learn. Knowl. Extr. 2021, 3, 95-122. https://0-doi-org.brum.beds.ac.uk/10.3390/make3010006
Shin K, Ishikawa T, Liu Y-L, Shepard DL. Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake e-Commerce Sites. Machine Learning and Knowledge Extraction. 2021; 3(1):95-122. https://0-doi-org.brum.beds.ac.uk/10.3390/make3010006
Chicago/Turabian StyleShin, Kilho, Taichi Ishikawa, Yu-Lu Liu, and David Lawrence Shepard. 2021. "Learning DOM Trees of Web Pages by Subpath Kernel and Detecting Fake e-Commerce Sites" Machine Learning and Knowledge Extraction 3, no. 1: 95-122. https://0-doi-org.brum.beds.ac.uk/10.3390/make3010006