
Environmental Influences on Density and Height Growth of Natural Ponderosa Pine Regeneration following Wildfires

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Sites and Field Methods
2.2. Derived Variable Sources
2.3. Statistical Methods
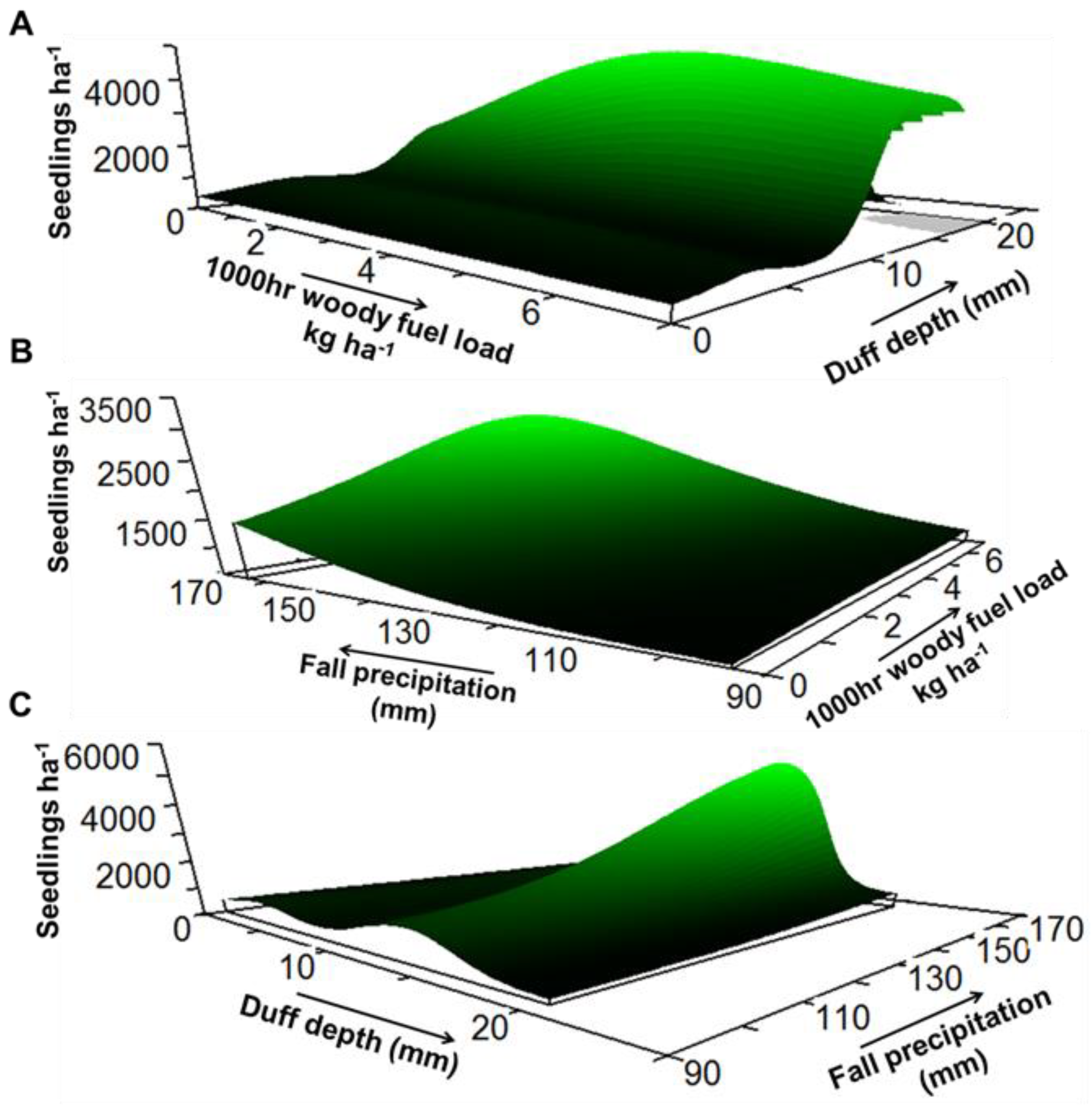
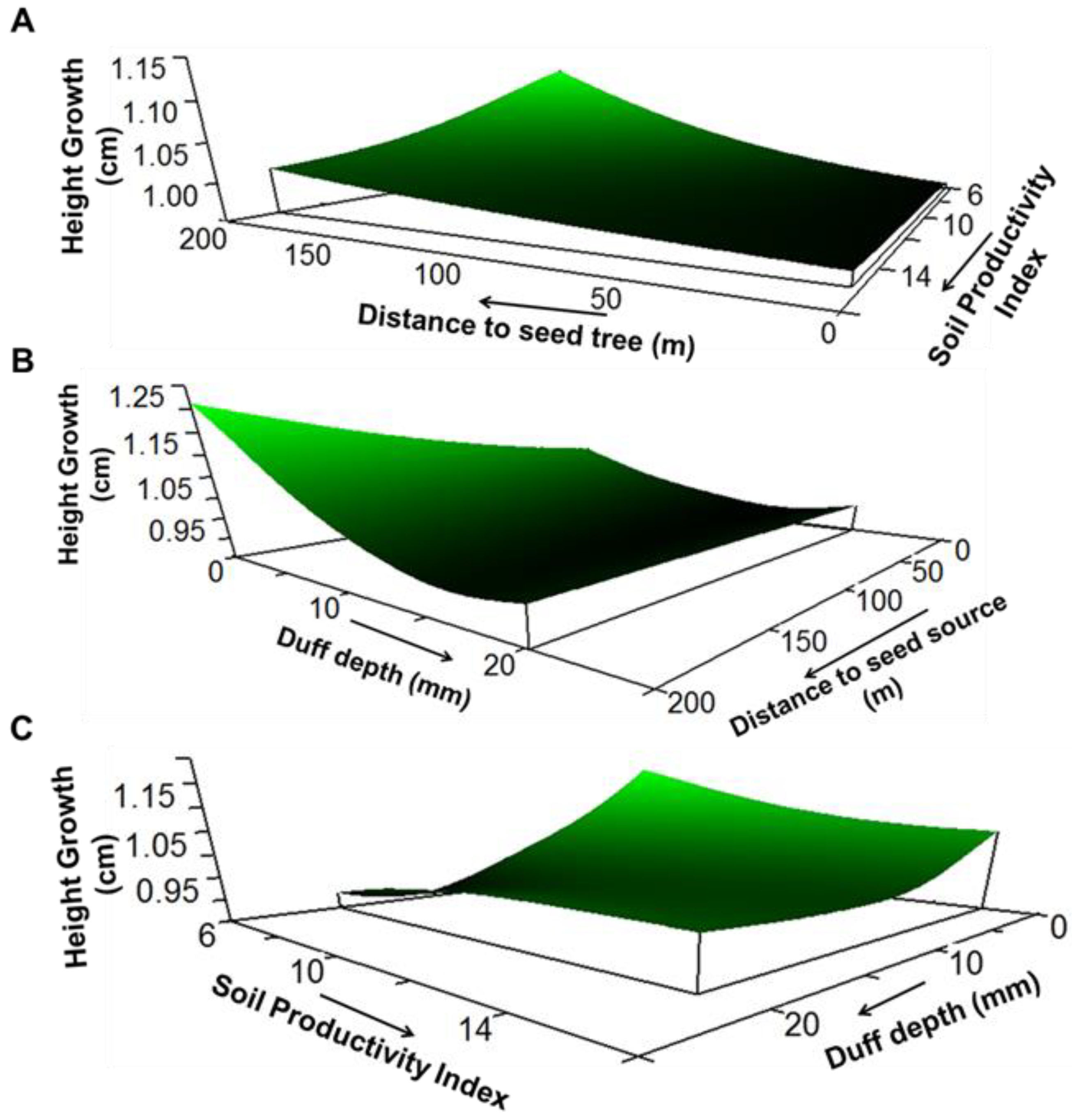
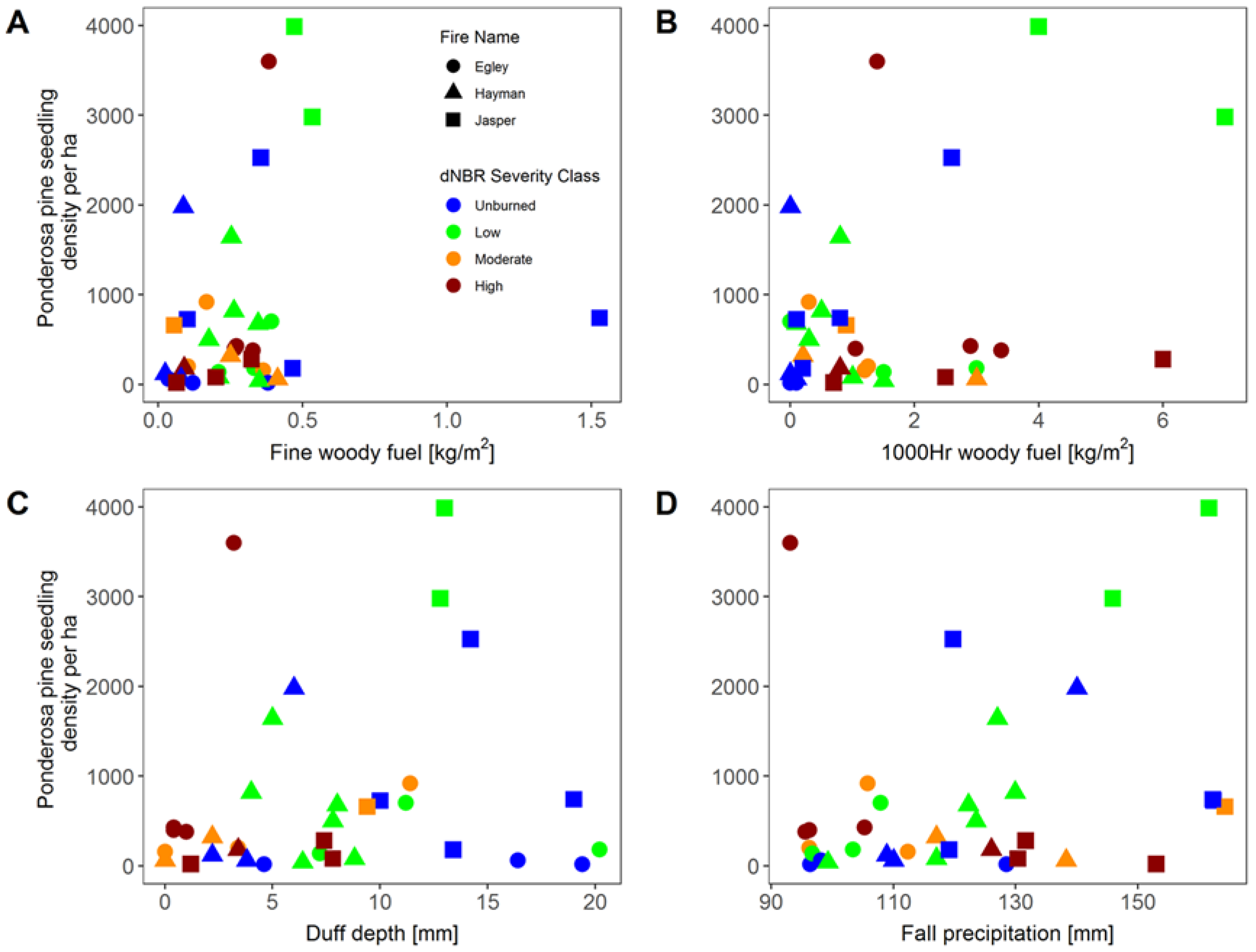
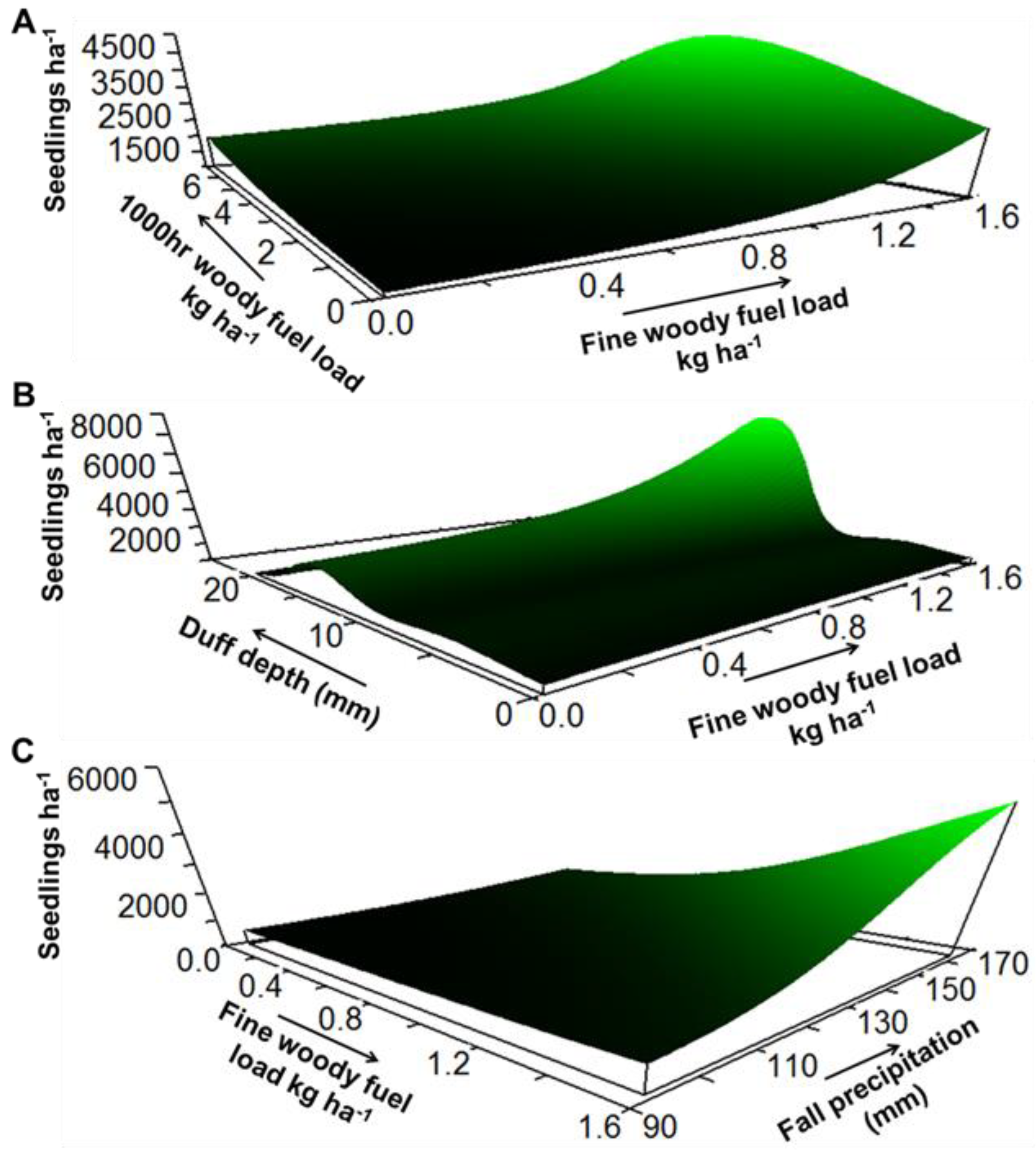
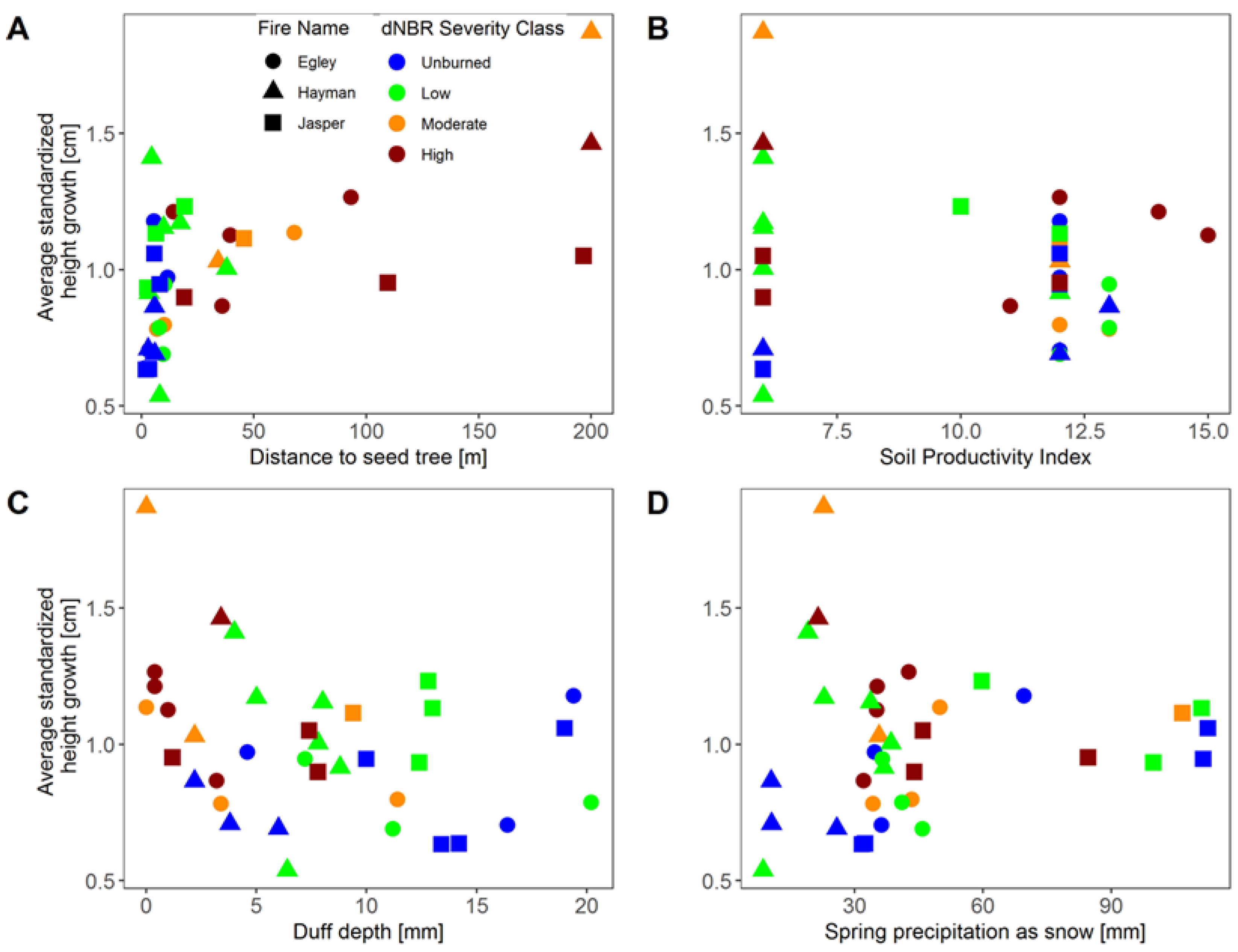
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fahey, T.J.; Woodbury, P.B.; Battles, J.J.; Goodale, C.L.; Hamburg, S.P.; Ollinger, S.V.; Woodall, C.W. Forest carbon storage: Ecology, management, and policy. Front. Ecol. Environ. 2010, 8, 245–252. [Google Scholar] [CrossRef] [Green Version]
- Martens, S.N.; Breshears, D.D.; Meyer, C.W. Spatial distributions of understory light along the grassland/forest continuum: Effects of cover, height, and spatial pattern of tree canopies. Ecol. Model. 2000, 126, 79–93. [Google Scholar] [CrossRef]
- Chang, M. Forest Hydrology: An Introduction to Water and Forests; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Shenoy, A.; Johnstone, J.; Kasischke, E.S.; Kielland, K. Persistent effects of fire severity on early successional forests in interior Alaska. For. Ecol. Manag. 2011, 261, 381–390. [Google Scholar] [CrossRef]
- Savage, M.; Mast, J.N.; Feddema, J.J. Double whammy: High-severity fire and drought in ponderosa pine forests of the Southwest. Can. J. For. Res. 2013, 43, 570–583. [Google Scholar] [CrossRef]
- Johnstone, J.F.; Allen, C.D.; Franklin, J.F.; Frelich, L.E.; Harvey, B.J.; Higuera, P.; Mack, M.C.; Meentemeyer, R.K.; Metz, M.R.; Perry, G.L.; et al. Changing disturbance regimes, ecological memory, and forest resilience. Front. Ecol. Environ. 2016, 14, 369–378. [Google Scholar] [CrossRef]
- Larson, A.J.; Franklin, J.F. Patterns of conifer tree regeneration following an autumn wildfire event in the western Oregon Cascade Range, USA. For. Ecol. Manag. 2005, 218, 25–36. [Google Scholar] [CrossRef]
- Crotteau, J.; Varner, J.M.; Ritchie, M.W. Post-fire regeneration across a fire severity gradient in the southern Cascades. For. Ecol. Manag. 2013, 287, 103–112. [Google Scholar] [CrossRef]
- Kemp, K.B.; Higuera, P.; Morgan, P. Fire legacies impact conifer regeneration across environmental gradients in the U.S. northern Rockies. Landsc. Ecol. 2016, 31, 619–636. [Google Scholar] [CrossRef]
- DeBano, L.F.; Neary, D.G.; Folliott, P.F. Fire: Its Effect on Soil and Other Ecosystem Resources; John Wiley & Sons, Inc.: New York, NY, USA, 1998; pp. 71–159. ISBN 978-0-471-16356-5. [Google Scholar]
- Stevens-Rumann, C.S.; Kemp, K.B.; Higuera, P.E.; Harvey, B.J.; Rother, M.T.; Donato, D.C.; Morgan, P.; Veblen, T.T. Evidence for declining forest resilience to wildfires under climate change. Ecol. Lett. 2018, 21, 243–252. [Google Scholar] [CrossRef]
- Kemball, K.J.; Wang, G.G.; Westwood, A.R. Are mineral soils exposed by severe wildfire better seedbeds for conifer regeneration? Can. J. For. Res. 2006, 36, 1943–1950. [Google Scholar] [CrossRef]
- Hesketh, M.; Greene, D.F.; Pounden, E. Early establishment of conifer recruits in the northern Rocky Mountains as a function of postfire duff depth. Can. J. For. Res. 2009, 39, 2059–2064. [Google Scholar] [CrossRef]
- Bonnet, V.H.; Schoettle, A.W.; Shepperd, W.D. Postfire environmental conditions influence the spatial pattern of regeneration for Pinus ponderosa. Can. J. For. Res. 2005, 35, 37–47. [Google Scholar] [CrossRef] [Green Version]
- Keeton, W.S.; Franklin, J.F. Do remnant old-growth trees accelerate rates of succession in mature Douglas-fir forests? Ecol. Monogr. 2005, 75, 103–118. [Google Scholar] [CrossRef]
- Donato, D.C.; Fontaine, J.; Campbell, J.L.; Robinson, W.D.; Kauffman, J.B.; Law, B. Conifer regeneration in stand-replacement portions of a large mixed-severity wildfire in the Klamath–Siskiyou Mountains. Can. J. For. Res. 2009, 39, 823–838. [Google Scholar] [CrossRef] [Green Version]
- Dodson, E.K.; Root, H.T. Conifer regeneration following stand-replacing wildfire varies along an elevation gradient in a ponderosa pine forest, Oregon, USA. For. Ecol. Manag. 2013, 302, 163–170. [Google Scholar] [CrossRef]
- Feddema, J.J.; Mast, J.N.; Savage, M. Modeling high-severity fire, drought and climate change impacts on ponderosa pine regeneration. Ecol. Model. 2013, 253, 56–69. [Google Scholar] [CrossRef]
- Pounden, E.; Greene, D.F.; Michaletz, S.T. Non-serotinous woody plants behave as aerial seed bank species when a late-summer wildfire coincides with a mast year. Ecol. Evol. 2014, 4, 3830–3840. [Google Scholar] [CrossRef] [PubMed]
- Oliver, W.W.; Dolph, K.L. Mixed-conifer seedling growth varies in response to overstory release. For. Ecol. Manag. 1992, 48, 179–183. [Google Scholar] [CrossRef]
- Shepperd, W.D.; Edminster, C.B.; Mata, S.A. Long-term seedfall, establishment, survival, and growth of natural and planted ponderosa pine in the Colorado Front Range. West. J. Appl. For. 2006, 21, 19–26. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.G.; Kemball, K.J. Effects of fire severity on early survival and growth of planted jack pine, black spruce and white spruce. For. Chron. 2010, 86, 193–199. [Google Scholar] [CrossRef] [Green Version]
- Rother, M.T.; Veblen, T.T.; Furman, L.G. A field experiment informs expected patterns of conifer regeneration after disturbance under changing climate conditions. Can. J. For. Res. 2015, 45, 1607–1616. [Google Scholar] [CrossRef]
- Hankin, L.E.; Higuera, P.E.; Davis, K.T.; Dobrowski, S. Impacts of growing-season climate on tree growth and post-fire regeneration in ponderosa pine and Douglas-fir forests. Ecosphere 2019, 10, 02679. [Google Scholar] [CrossRef] [Green Version]
- Littlefield, C.E. Topography and post-fire climatic conditions shape spatio-temporal patterns of conifer establishment and growth. Fire Ecol. 2019, 15, 1–20. [Google Scholar] [CrossRef]
- Bansal, S.; Jochum, T.; Wardle, D.; Nilsson, M.-C. The interactive effects of surface-burn severity and canopy cover on conifer and broadleaf tree seedling ecophysiology. Can. J. For. Res. 2014, 44, 1032–1041. [Google Scholar] [CrossRef]
- Donato, D.C.; Harvey, B.J.; Turner, M.G. Regeneration of montane forests 24 years after the 1988 Yellowstone fires: A fire-catalyzed shift in lower treelines? Ecosphere 2016, 7, 01410. [Google Scholar] [CrossRef]
- Roberts, D.W.; Cooper, S.V. Concepts and Techniques of Vegetation Mapping; U.S. Department of Agriculture, Forest Service, Intermountain Research Station: Ogden, UT, USA, 1989. [Google Scholar]
- Eidenshink, J.; Schwind, B.; Brewer, K.; Zhu, Z.; Quayle, B.; Howard, S. A project for Monitoring Trends in Burn Severity. Fire Ecol. 2007, 3, 3–21. [Google Scholar] [CrossRef]
- Karmaker, A.C.; Hoffmann, A.; Hinrichsen, G. Influence of water uptake on the mechanical properties of jute fiber-reinforced polypropylene. J. Appl. Polym. Sci. 1994, 54, 1803–1807. [Google Scholar] [CrossRef]
- Hudak, A.T.; Morgan, P.; Bobbitt, M.J.; Smith, A.M.S.; Lewis, S.A.; Lentile, L.B.; Robichaud, P.R.; Clark, J.T.; McKinley, R.A. The relationship of multispectral satellite imagery to immediate fire effects. Fire Ecol. 2007, 3, 64–90. [Google Scholar] [CrossRef]
- Urza, A.K.; Sibold, J.S. Nondestructive aging of postfire seedlings for four conifer species in northwestern Montana. West. J. Appl. For. 2013, 28, 22–29. [Google Scholar] [CrossRef]
- Wang, T.; Hamann, A.; Spittlehouse, D.; Carroll, C. Locally downscaled and spatially customizable climate data for historical and future periods for North America. PLoS ONE 2016, 11, e0156720. [Google Scholar] [CrossRef]
- Keane, R.E.; Dickinson, L.J. The Photoload Sampling Technique: Estimating Surface Fuel Loadings from Downward-Looking Photographs of Synthetic Fuelbeds; U.S. Department of Agriculture, Forest Service, North Central Forest Experiment Station: Saint Paul, MI, USA, 2007; Volume 190. [Google Scholar]
- Schaetzl, R.J.; Krist, F.J.; Miller, B.A. A Taxonomically based ordinal estimate of soil productivity for landscape-scale analyses. Soil Sci. 2012, 177, 288–299. [Google Scholar] [CrossRef] [Green Version]
- Chambers, M.E.; Fornwalt, P.; Malone, S.; Battaglia, M.A. Patterns of conifer regeneration following high severity wildfire in ponderosa pine—dominated forests of the Colorado Front Range. For. Ecol. Manag. 2016, 378, 57–67. [Google Scholar] [CrossRef]
- McCune, B.; Mefford, J. HyperNiche: Multiplicative Habitat Modeling; Version 2.22; MjM Software: Gleneden Beach, OR, USA, 2009. [Google Scholar]
- McCune, B. Non-parametric habitat models with automatic interactions. J. Veg. Sci. 2006, 17, 819–830. [Google Scholar] [CrossRef]
- Stevens- Rumann, C.; Morgan, P.; Davis, K.; Kemp, K. Post-fire tree regeneration (or lack thereof) can change ecosystems. NRFSN Sci. Rev. 2019, 5, 1–12. [Google Scholar]
- Davis, K.T.; Dobrowski, S.Z.; Higuera, P.E.; Holden, Z.A.; Veblen, T.T.; Rother, M.T.; Parks, S.A.; Sala, A.; Maneta, M.P.; Davis, K.T.; et al. Wildfires and climate change push low-elevation forests across a critical climate threshold for tree regeneration. Proc. Natl. Acad. Sci. USA 2019, 116, 6193–6198. [Google Scholar] [CrossRef] [Green Version]
- Foster, A.C.; Martin, P.H.; Redmond, M.D. Soil moisture strongly limits Douglas-fir seedling establishment near its upper elevational limit in the southern Rocky Mountains. Can. J. For. Res. 2020, 50, 1–6. [Google Scholar] [CrossRef]
- Owen, S.M.; Sieg, C.H.; Fulé, P.Z.; Gehring, C.A.; Baggett, L.S.; Iniguez, J.M.; Fornwalt, P.J.; Battaglia, M.A. Persistent effects of fire severity on ponderosa pine regeneration niches and seedling growth. For. Ecol. Manag. 2020, 477, 118502. [Google Scholar] [CrossRef]
- Oliver, W.W.; Ryker, R.A. Pinus ponderosa Dougl. ex Laws. In Silvics of North America: 1. Conifers. Agriculture Handbook 654; Burns, R.M., Honkala, B.H., Eds.; USDA Forest Service: Madison, WI, USA, 1990; pp. 413–424. [Google Scholar]
- League, K.; Veblen, T. Climatic variability and episodic Pinus ponderosa establishment along the forest-grassland ecotones of Colorado. For. Ecol. Manag. 2006, 228, 98–107. [Google Scholar] [CrossRef]
- Burns, R.M.; Honkala, B.H. Silvics of North America; Miscellaneous Publication: Washington, DC, USA, 1990; Agriculture Handbook 654; Volume 1. [Google Scholar]
- York, R.A.; Battles, J.J.; Heald, R.C. Gap-Based Silviculture in a Sierran Mixed-Conifer Forest: Effects of Gap Size on Early Survival and 7-year Seedling Growth. USDA Forest Serv. Gen. Tech. Rep. 2007, 203, 181–191. [Google Scholar]
- Goodrich, B.A.; Waring, K.M. Pinus strobiformis seedling growth in southwestern US mixed conifer forests in managed and non-managed stands. For. An. Int. J. For. Res. 2017, 90, 393–403. [Google Scholar] [CrossRef] [Green Version]
- York, R.A.; Battles, J.J.; Heald, R.C. Edge effects in mixed conifer group selection openings: Tree height response to resource gradients. For. Ecol. Manag. 2003, 179, 107–121. [Google Scholar] [CrossRef] [Green Version]
- Boag, A.E.; Ducey, M.J.; Palace, M.W.; Hartter, J. Topography and fire legacies drive variable post-fire juvenile conifer regeneration in eastern Oregon, USA. For. Ecol. Manag. 2020, 474, 118312. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Minimum–Maximum Value |
|---|---|
| Post-fire climate variables | |
| Summer mean maximum temperature | 22.1–28.2 °C |
| Fall mean maximum temperature | 11.4–18.6 °C |
| Winter precipitation | 54.9–210.6 mm |
| Summer precipitation | 47.5–292.1 mm |
| Fall precipitation | 92.4–164.3 mm |
| Fall degree-days above 5 °C | 258.1–520.0 degree-days |
| Fall number of frost-free days | 33.0–51.4 days |
| Winter precipitation as snow | 23.3–113.3 mm |
| Spring precipitation as snow | 8.6–112.6 mm |
| Fall precipitation as snow | 2.9–40.3 mm |
| Winter Hargreaves Reference Evapotranspiration | 0.0–25.5 mm |
| Fall Hargreaves Reference Evapotranspiration | 129.0–222.9 mm |
| Spring Hargreaves Climatic Moisture Deficit | 19.4–148.0 mm |
| Winter relative humidity | 43.3–60.8% |
| Spring relative humidity | 48.3–58.5% |
| Summer relative humidity | 44.0–59.3% |
| Derived variables | |
| Elevation | 1507.1–2858.7 m |
| Transformed aspect (Roberts and Cooper 1989) | 0.0097–0.9960 |
| Slope | 0.79–32.15% |
| Differenced Normalized Burn Ratio | −24.0–717.6 |
| Soil productivity index | 6.0–15.0 |
| Field variables | |
| Distance to nearest cone-bearing tree | 2.1–200.0 m |
| Understory species richness | 4.2–17.6 |
| Understory live vegetation cover | 5.2–81.0% |
| Understory non-photosynthetic vegetation cover | 14.0–94.4% |
| Rock cover | 0.0–21.4% |
| Soil cover | 0.0–60.0% |
| Total cover of charred surface components | 0.0–141.0% |
| Tall shrub cover | 0.0–2.0% |
| 1000 h woody fuel load | 0.0–8.8 kg ha−1 |
| Fine (1, 10, and 100 h) woody fuel load | 0.024–1.582 kg ha−1 |
| Litter depth | 5.4–39.0 mm |
| Duff depth | 0.0–24.4 mm |
| Total basal area of live trees | 0.0–30.6 m2 ha−1 |
| Total basal area of dead trees | 0.0–23.0 m2 ha−1 |
| Live sapling density * | 0.0–1913.3 stems ha−1 |
| Dead seedling density * | 0.0–240.0 stems ha−1 |
| Live seedling density * | 20.0–13,360.0 stems ha−1 |
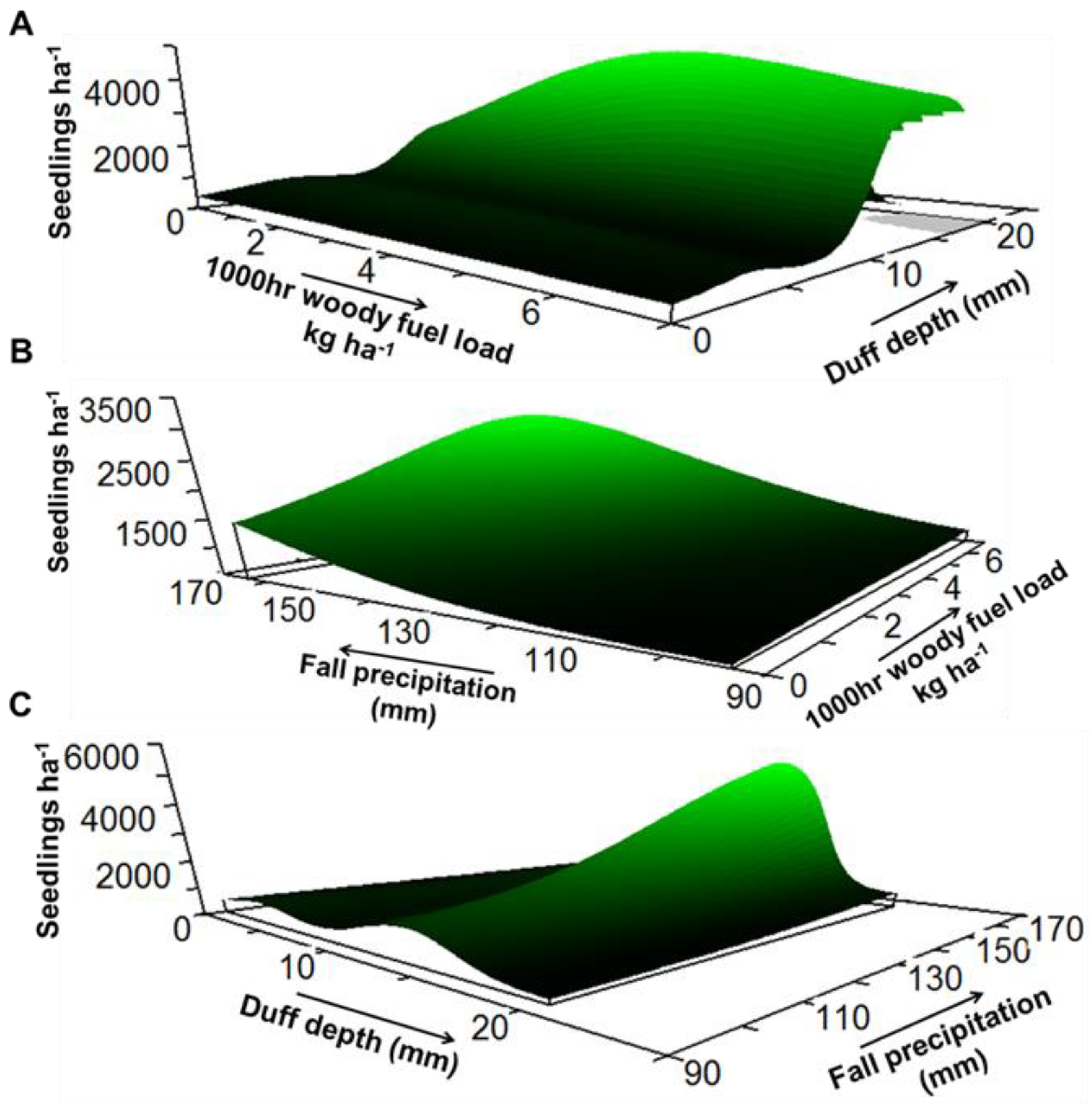
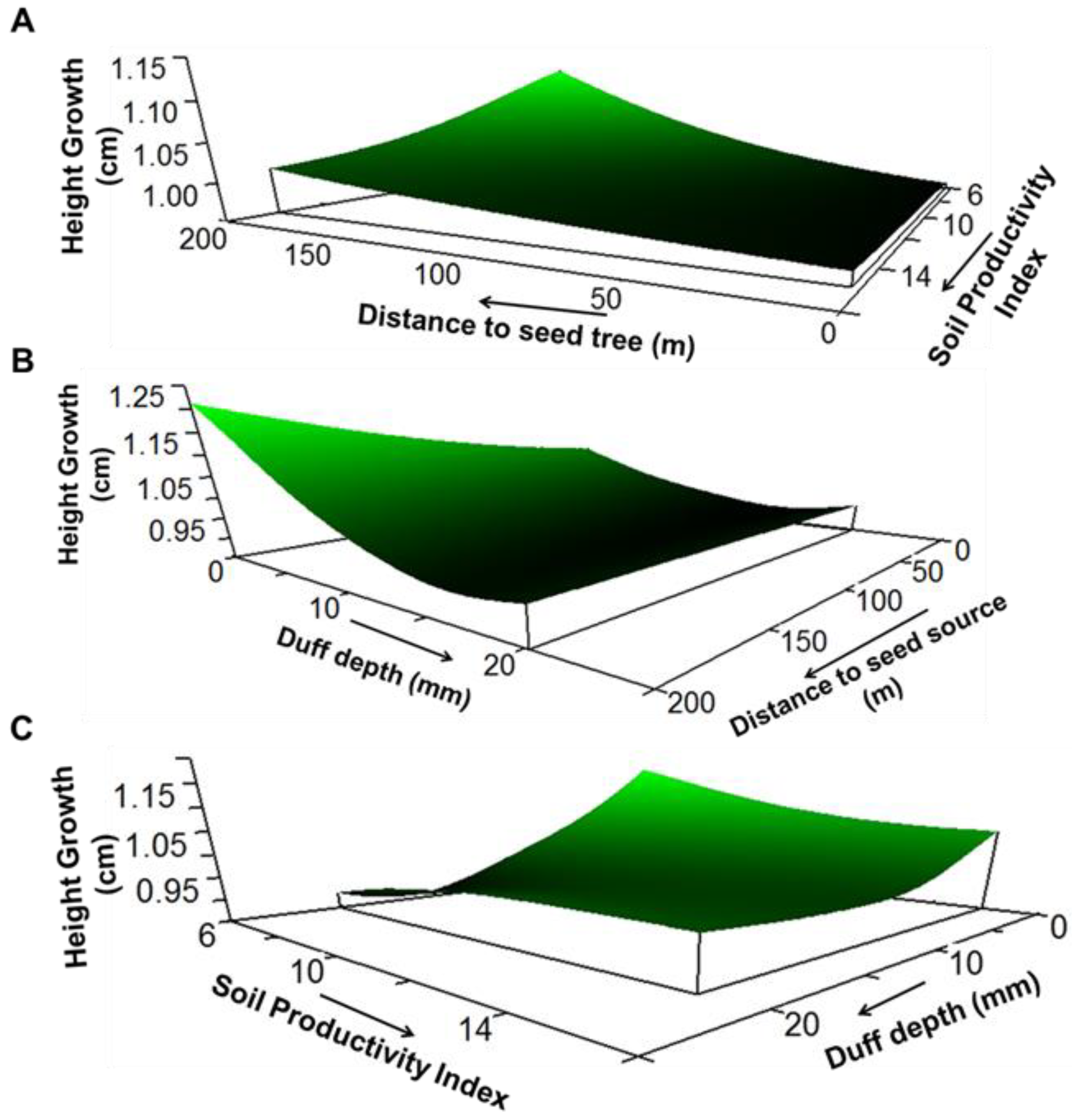
| Response Variable | Model xR2 | Average Size | Predictor Variable | Sensitivity | Tolerance |
|---|---|---|---|---|---|
| Density | 0.39 | 3.49 | Fine woody fuel load | 0.037 | 0.62 (40%) |
| 1000 h woody fuel load | 0.030 | 2.10 (30%) | |||
| Duff depth | 0.114 | 2.02 (10%) | |||
| Fall precipitation | 0.035 | 24.90 (35%) | |||
| Height growth | 0.57 | 2.12 | Distance to seed tree | 0.028 | 118.76 (60%) |
| Soil productivity index | 0.033 | 4.05 (45%) | |||
| Duff depth | 0.189 | 4.04 (20%) | |||
| Spring precipitation as snow | 0.652 | 5.2 (5%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hammond, D.H.; Strand, E.K.; Morgan, P.; Hudak, A.T.; Newingham, B.A. Environmental Influences on Density and Height Growth of Natural Ponderosa Pine Regeneration following Wildfires. Fire 2021, 4, 80. https://0-doi-org.brum.beds.ac.uk/10.3390/fire4040080
Hammond DH, Strand EK, Morgan P, Hudak AT, Newingham BA. Environmental Influences on Density and Height Growth of Natural Ponderosa Pine Regeneration following Wildfires. Fire. 2021; 4(4):80. https://0-doi-org.brum.beds.ac.uk/10.3390/fire4040080
Chicago/Turabian StyleHammond, Darcy H., Eva K. Strand, Penelope Morgan, Andrew T. Hudak, and Beth A. Newingham. 2021. "Environmental Influences on Density and Height Growth of Natural Ponderosa Pine Regeneration following Wildfires" Fire 4, no. 4: 80. https://0-doi-org.brum.beds.ac.uk/10.3390/fire4040080