Fast Univariate Time Series Prediction of Solar Power for Real-Time Control of Energy Storage System

 ,
,
Abstract
:1. Introduction
1.1. Motivation and State of the Art
1.2. Literature Review
1.3. Objective of the Study
1.4. Innovative Contribution
1.5. Paper Organization
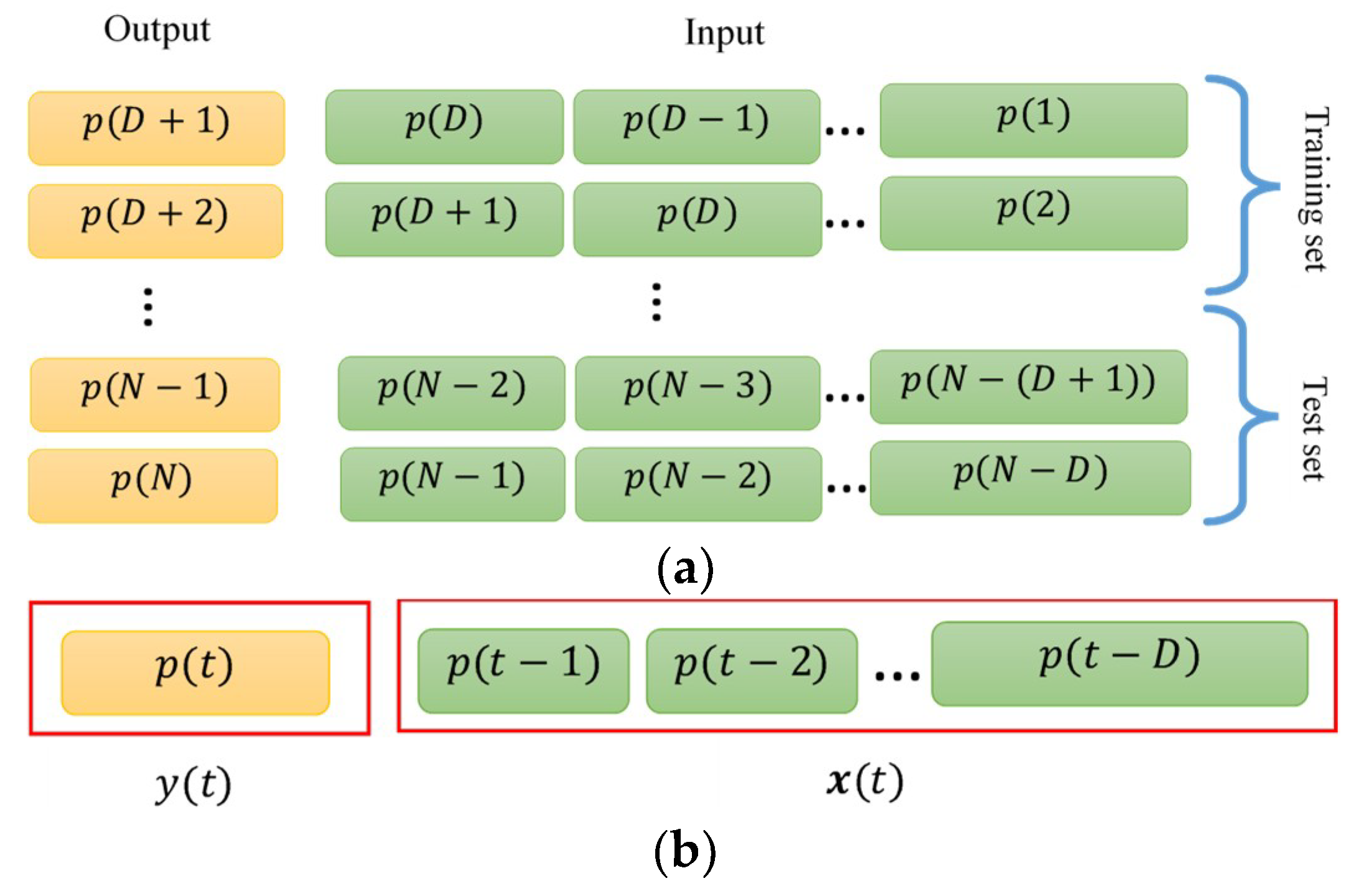
2. Problem Formulation
3. Applied Algorithms
3.1. K-Nearest Neighbor (kNN)
3.2. Support Vector Regression (SVR)
3.3. Random Forest (RF)
3.4. Auto Regressive Integrated Moving Average (ARIMA)
3.5. LinearRegression (LR)
3.6. Persistent
4. Simulation Setup
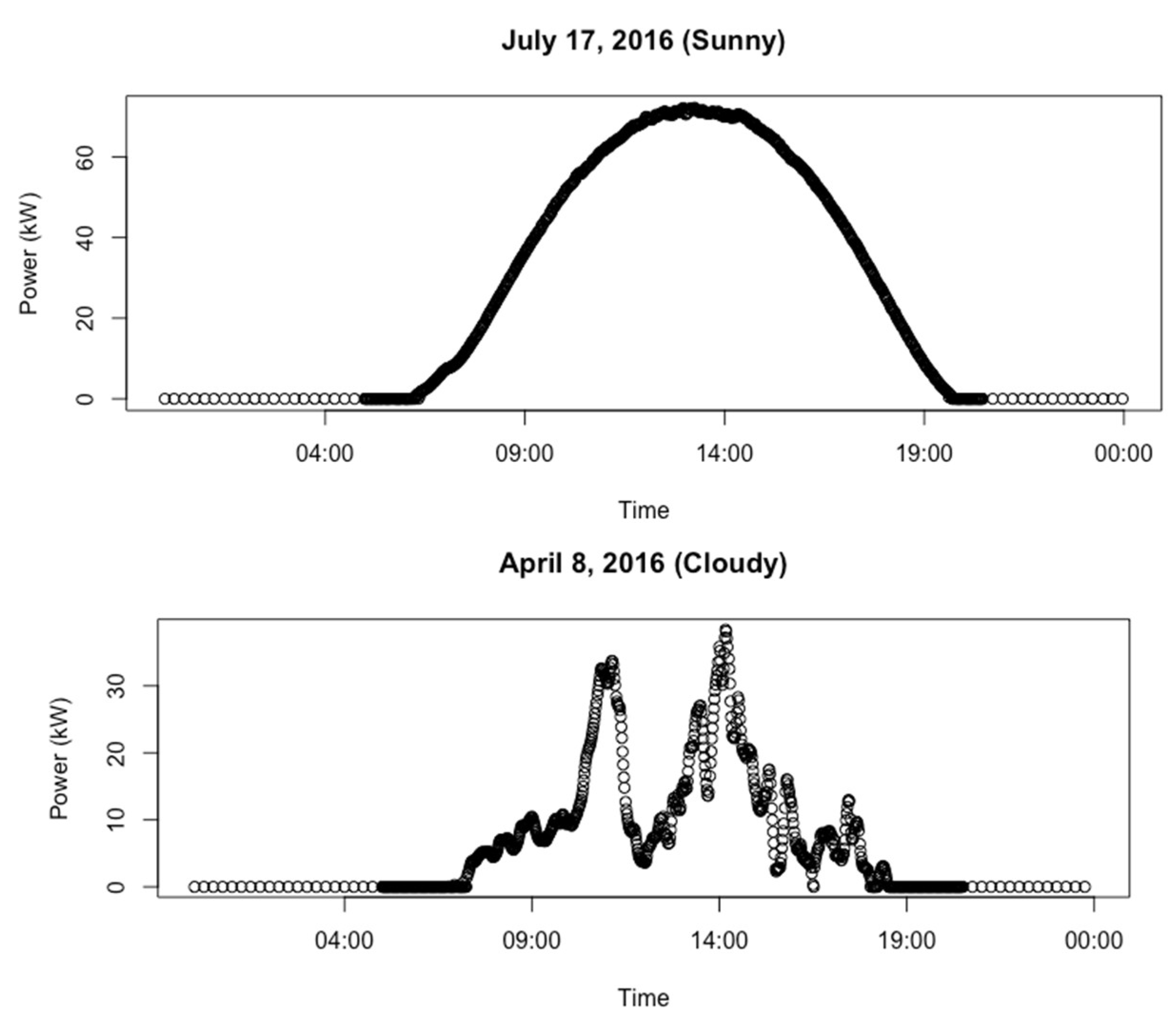
4.1. Data and Preprocessing
4.2. Parameter Selection
5. Results and Analysis
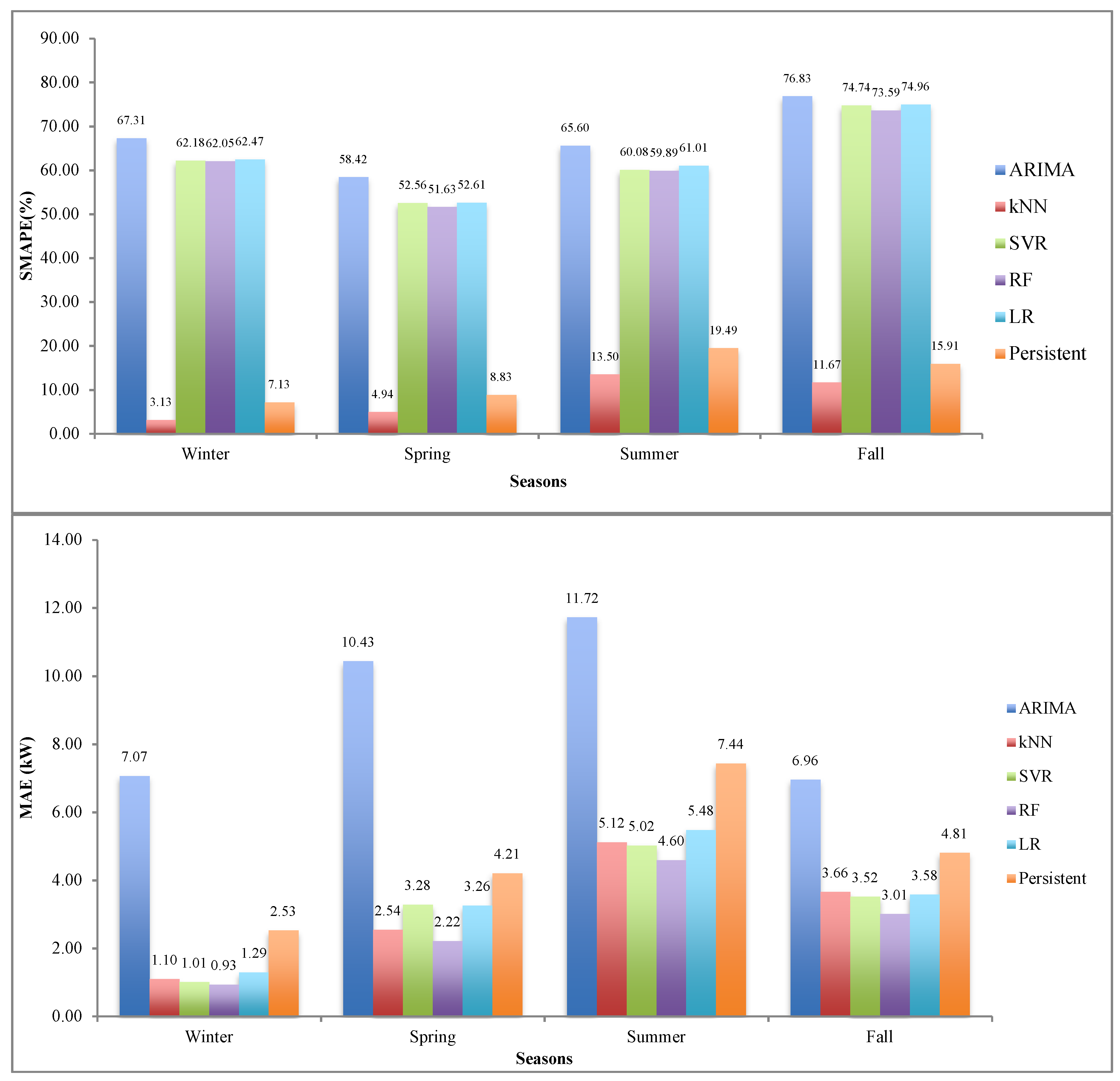
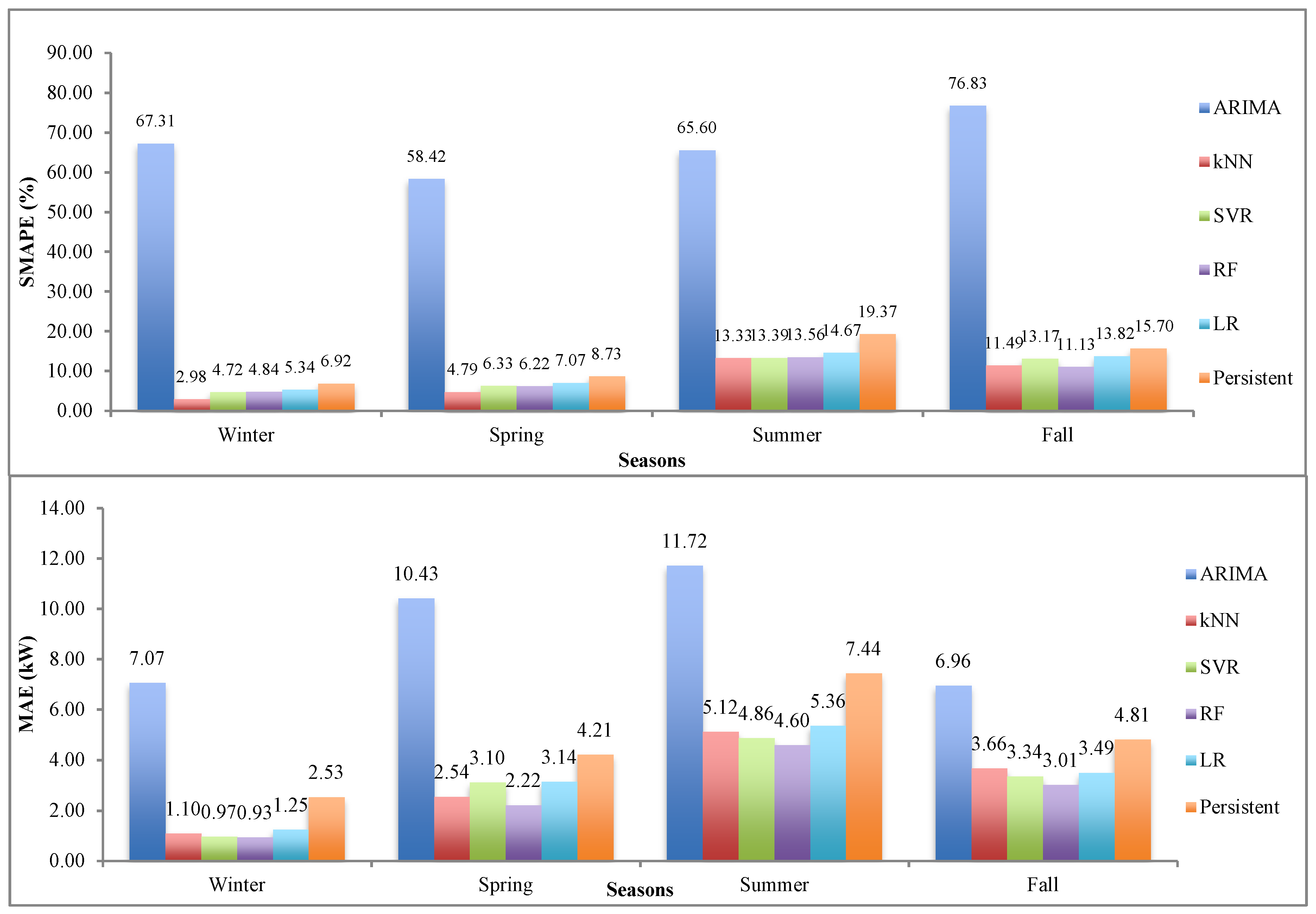
5.1. Results
5.2. Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ACF | Autocorrelation Function |
| AIC | Akaike Information Criterion |
| AR | Auto Regressive |
| ARIMA | Autoregressive Integrated Moving Average |
| BIC | Bayesian Information Criterion |
| GHI | Global Horizontal Irradiation |
| I | Integrated |
| kNN | k-Nearest Neighbors |
| KPSS | Kwiatkowski–Phillips–Schmidt–Shin |
| LOCF | Last Observation Carried Forward |
| MA | Moving Average |
| MAE | Mean Absolute Error |
| ML | Maximum Likelihood |
| PACF | Partial Autocorrelation Function |
| PV | Photovoltaic |
| RF | Random Forest |
| SMAPE | Symmetric Mean Absolute Percentage Error |
| SMERC | Smart Grid Energy Research left |
| SVM | Support Vector Machine |
| SVR | Support Vector Regression |
| UCR | University of California, Riverside |
References
- Nazaripouya, H.; Chu, C.; Pota, H.R.; Gadh, R. Battery Energy Storage System Control for Intermittency Smoothing Using an Optimized Two-Stage Filter. IEEE Trans. Sustain. Energy 2018, 9, 664–675. [Google Scholar] [CrossRef]
- Nazaripouya, H.; Wang, Y.; Chu, P.; Pota, H.R.; Gadh, R. Optimal Sizing and Placement of Battery Energy Storage in Distribution System Based on Solar Size for Voltage Regulation. In Proceedings of the 2015 IEEE PES General Meeting, Denver, CO, USA, 26–30 July 2015. [Google Scholar]
- Semero, Y.K.; Zhang, J.; Zheng, D. PV power forecasting using an integrated GA-PSO-ANFIS approach and Gaussian process regression based feature selection strategy. CSEE J. Power Energy Syst. 2018, 4, 210–218. [Google Scholar] [CrossRef]
- Tang, N.; Mao, S.; Wang, Y.; Nelms, R.M. Solar Power Generation Forecasting With a LASSO-Based Approach. IEEE Internet Things J. 2018, 5, 1090–1099. [Google Scholar] [CrossRef]
- Gigoni, L.; Betti, A.; Crisostomi, E.; Franco, A.; Tucci, M.; Bizzarri, F.; Mucci, D. Day-Ahead Hourly Forecasting of Power Generation From Photovoltaic Plants. IEEE Trans. Sustain. Energy 2018, 9, 831–842. [Google Scholar] [CrossRef]
- Verbois, H.; Huva, R.; Rusydi, A.; Walsh, W. Solar irradiance forecasting in the tropics using numerical weather prediction and statistical learning. Sol. Energy 2018, 162, 265–277. [Google Scholar] [CrossRef]
- Lauret, P.; David, M.; Pedro, H.T.C. Probabilistic solar forecasting using quantile regression models. Energies 2017, 10, 1591. [Google Scholar] [CrossRef]
- Alfadda, A.; Adhikari, R.; Kuzlu, M.; Rahman, S. Hour-ahead solar PV power forecasting using SVR based approach. In Proceedings of the 2017 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 23–26 April 2017. [Google Scholar]
- Inage, S. Development of an advection model for solar forecasting based on ground data first report: Development and verification of a fundamental model. Sol. Energy 2017, 153, 414–434. [Google Scholar] [CrossRef]
- Hong, T.; Pinson, P.; Fan, S.; Zareipour, H.; Troccoli, A.; Hyndman, R.J. Probabilistic energy forecasting: Global Energy Forecasting Competition 2014 and beyond. Int. J. Forecast. 2016, 32, 896–913. [Google Scholar] [CrossRef] [Green Version]
- Ferlito, S.; Adinolfi, G.; Graditi, G. Comparative analysis of data-driven methods online and offline trained to the forecasting of grid-connected photovoltaic plant production. Appl. Energy 2017, 205, 116–129. [Google Scholar] [CrossRef]
- Graditi, G.; Ferlito, S.; Adinolfi, G.; Tina, G.M.; Ventura, C. Energy yield estimation of thin-film photovoltaic plants by using physical approach and artificial neural networks. Sol. Energy 2016, 130, 232–243. [Google Scholar] [CrossRef]
- Huang, R.; Huang, T.; Gadh, R.; Li, N. Solar generation prediction using the ARMA model in a laboratory-level micro-grid. In Proceedings of the 2012 IEEE Third International Conference on Smart Grid Communications (SmartGridComm), Tainan, Taiwan, 5–8 November 2012. [Google Scholar]
- Asrari, A.; Wu, T.X.; Ramos, B. A Hybrid Algorithm for Short-Term Solar Power Prediction—Sunshine State Case Study. IEEE Trans. Sustain. Energy 2017, 8, 582–591. [Google Scholar] [CrossRef]
- Boualit, S.B.; Mellit, A. SARIMA-SVM hybrid model for the prediction of daily global solar radiation time series. In Proceedings of the 2016 International Renewable and Sustainable Energy Conference (IRSEC), Marrakech, Morocco, 14–17 November 2016. [Google Scholar]
- Voyant, C.; Motte, F.; Notton, G.; Fouilloy, A.; Nivet, M.L.; Duchaud, J.L. Prediction intervals for global solar irradiation forecasting using regression trees methods. Renew. Energy 2018, 126, 332–340. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.-Y.; Qiu, J.; Li, F.-F. Hybrid Decomposition-Reconfiguration Models for Long-Term Solar Radiation Prediction Only Using Historical Radiation Records. Energies 2018, 11, 1376. [Google Scholar] [CrossRef]
- Jiang, Y.; Long, H.; Zhang, Z.; Song, Z. Day-Ahead Prediction of Bihourly Solar Radiance with a Markov Switch Approach. IEEE Trans. Sustain. Energy 2017, 8, 1536–1547. [Google Scholar] [CrossRef]
- Grantham, A.; Gel, Y.R.; Boland, J. Nonparametric short-term probabilistic forecasting for solar radiation. Sol. Energy 2016, 133, 465–475. [Google Scholar] [CrossRef]
- Nazaripouya, H.; Wang, B.; Wang, Y.; Chu, P.; Pota, H.R.; Gadh, R. Univariate time series prediction of solar power using a hybrid wavelet-ARMA-NARX prediction method. In Proceedings of the 2016 IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Dallas, TX, USA, 2–5 May 2016. [Google Scholar]
- Marafiga, E.B.; Farret, F.A.; Peixoto, N.H. Effects of the seasonal sunlight variation on predictions of the solar-aeolic potential for power generation. In Proceedings of the 2015 12th International Conference on the European Energy Market (EEM), Lisbon, Portugal, 19–22 May 2015. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin, Germany, 2009. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Majidpour, M.; Qiu, C.; Chu, P.; Gadh, R.; Pota, H.R. Fast Prediction for Sparse Time Series: Demand Forecast of EV Charging Stations for Cell Phone Applications. IEEE Trans. Ind. Inform. 2015, 11, 242–250. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Majidpour, M.; Qiu, C.; Chu, P.; Pota, H.R.; Gadh, R. Forecasting the EV charging load based on customer profile or station measurement. Appl. Energy 2016, 163, 134–141. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Some properties of splitting criteria. Mach. Learn. 1996, 24, 41–47. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International conFerence on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Weisang, G.; Awazu, Y. Vagaries of the Euro: An Introduction to ARIMA Modeling. Case Stud. Bus. Ind. Gov. Stat. 2008, 2, 45–55. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]
- Opsomer, J.; Wang, Y.; Yang, Y. Nonparametric regression with correlated errors. Stat. Sci. 2001, 16, 134–153. [Google Scholar]
- Majidpour, M.; Qiu, C.; Chu, P.; Gadh, R.; Pota, H.R. Modified pattern sequence-based forecasting for electric vehicle charging stations. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014. [Google Scholar]
- Hong, W. Application of seasonal SVR with chaotic immune algorithm in traffic flow forecasting. Neural Comput. Appl. 2012, 21, 583–593. [Google Scholar] [CrossRef]
- Diebold, F.; Mariano, R. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 1995, 13, 253–263. [Google Scholar] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Season | Start | End |
|---|---|---|
| Winter | 8 February 2017 | 14 February 2017 |
| Spring | 8 May 2017 | 14 May 2017 |
| Summer | 7 August 2016 | 13 August 2016 |
| Fall | 15 November 2016 | 21 November 2016 |
| Parameter | ARIMA | kNN | SVR | RF | LR |
|---|---|---|---|---|---|
| Parameter () in Depth () | -- | 10 | 10 | 10 | 10 |
| Neighbor () | -- | 1 | -- | -- | -- |
| Order (p,d,q) | (5,0,0) | -- | -- | -- | -- |
| Kernel | -- | Polynomial | -- | -- | |
| -- | -- | 0.01 | -- | -- | |
| Cost () | -- | -- | 1 | -- | -- |
| Number of trees () | -- | -- | -- | 200 | -- |
| Splitting leaves at each node () | -- | -- | -- | = 5 | -- |
| Minimum of terminal nodes () | -- | -- | -- | 5 | -- |
| Algorithm | ARIMA | kNN | SVR | RF | LR |
|---|---|---|---|---|---|
| Prediction Time (ms) | 4 | 103 | 3.12 | 64 | 2.56 |
| Algorithm | ARIMA | kNN | SVR | RF | LR |
|---|---|---|---|---|---|
| Training time with optimal parameters (s) | 25.22 | 0.0 | 323.84 | 542.33 | 0.13 |
| Algorithm | ARIMA | kNN | SVR | RF | Persistent | LR |
|---|---|---|---|---|---|---|
| ARIMA | -- | 1 | 1 | 1 | 1 | 1 |
| kNN | 0.0000 | -- | 0.0061 | 1 | 0.0000 | 0.0000 |
| SVR | 0.0000 | 0.9938 | -- | 1 | 0.0000 | 0.0000 |
| RF | 0.0000 | 0.0000 | 0.0000 | -- | 0.0000 | 0.0000 |
| Persistent | 0.0000 | 1 | 1 | 1 | -- | 1 |
| LR | 0.0000 | 1 | 1 | 1 | 0.0000 | -- |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majidpour, M.; Nazaripouya, H.; Chu, P.; Pota, H.R.; Gadh, R. Fast Univariate Time Series Prediction of Solar Power for Real-Time Control of Energy Storage System. Forecasting 2019, 1, 107-120. https://0-doi-org.brum.beds.ac.uk/10.3390/forecast1010008
Majidpour M, Nazaripouya H, Chu P, Pota HR, Gadh R. Fast Univariate Time Series Prediction of Solar Power for Real-Time Control of Energy Storage System. Forecasting. 2019; 1(1):107-120. https://0-doi-org.brum.beds.ac.uk/10.3390/forecast1010008
Chicago/Turabian StyleMajidpour, Mostafa, Hamidreza Nazaripouya, Peter Chu, Hemanshu R. Pota, and Rajit Gadh. 2019. "Fast Univariate Time Series Prediction of Solar Power for Real-Time Control of Energy Storage System" Forecasting 1, no. 1: 107-120. https://0-doi-org.brum.beds.ac.uk/10.3390/forecast1010008