
Developing a Low-Order Statistical Feature Set Based on Received Samples for Signal Classification in Wireless Sensor Networks and Edge Devices


Abstract
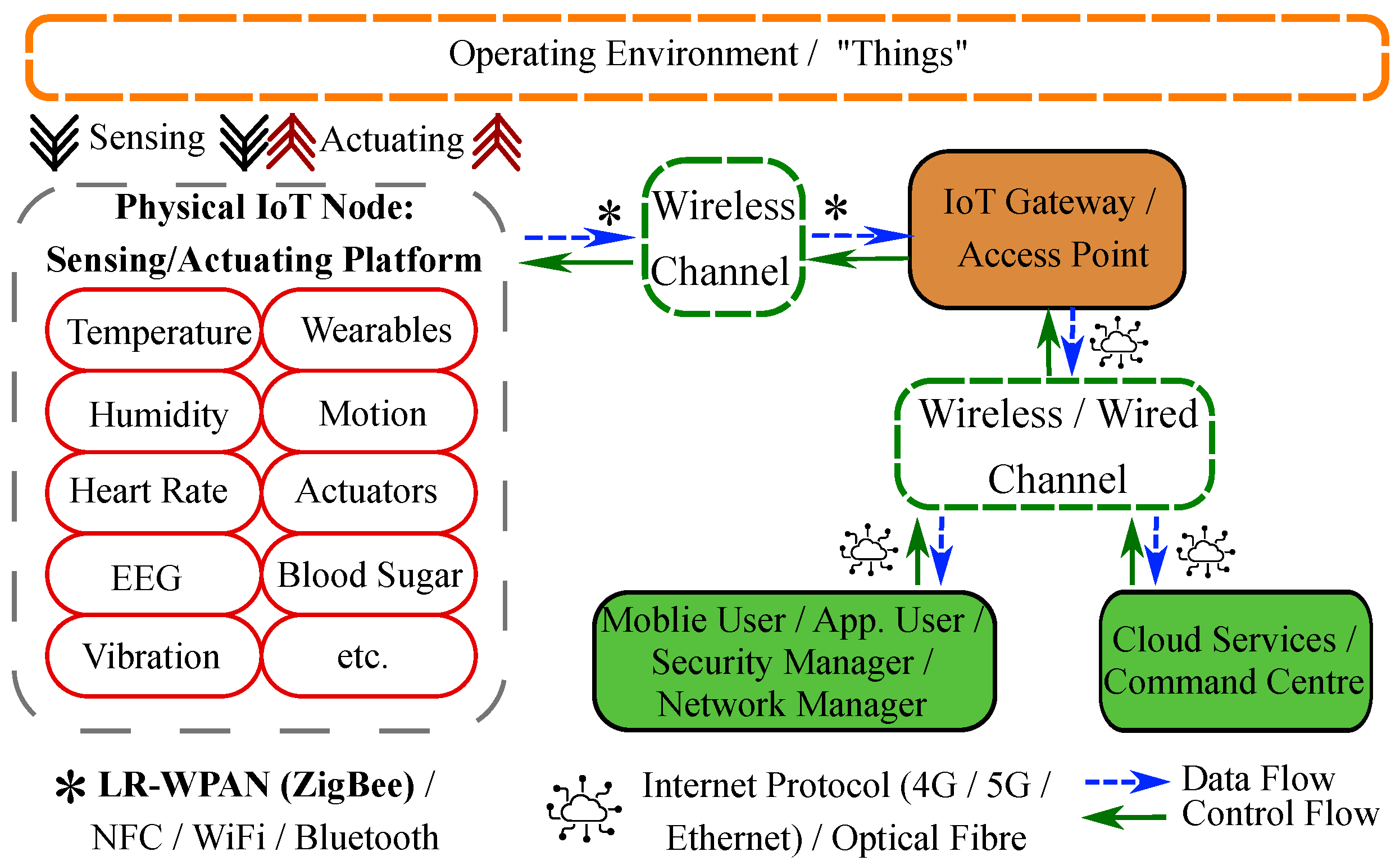
:1. Introduction
2. Related Work
3. Materials and Methods
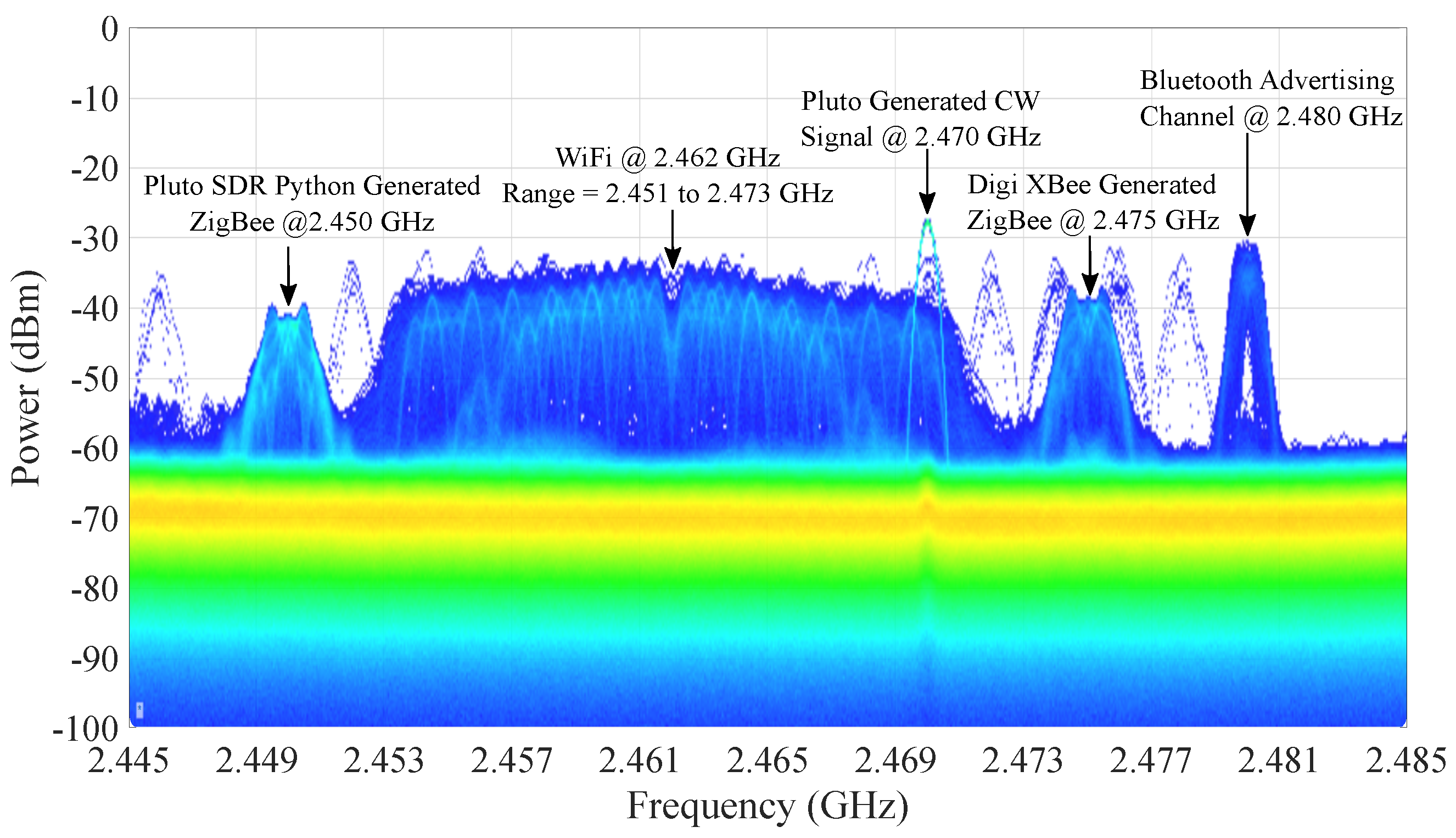
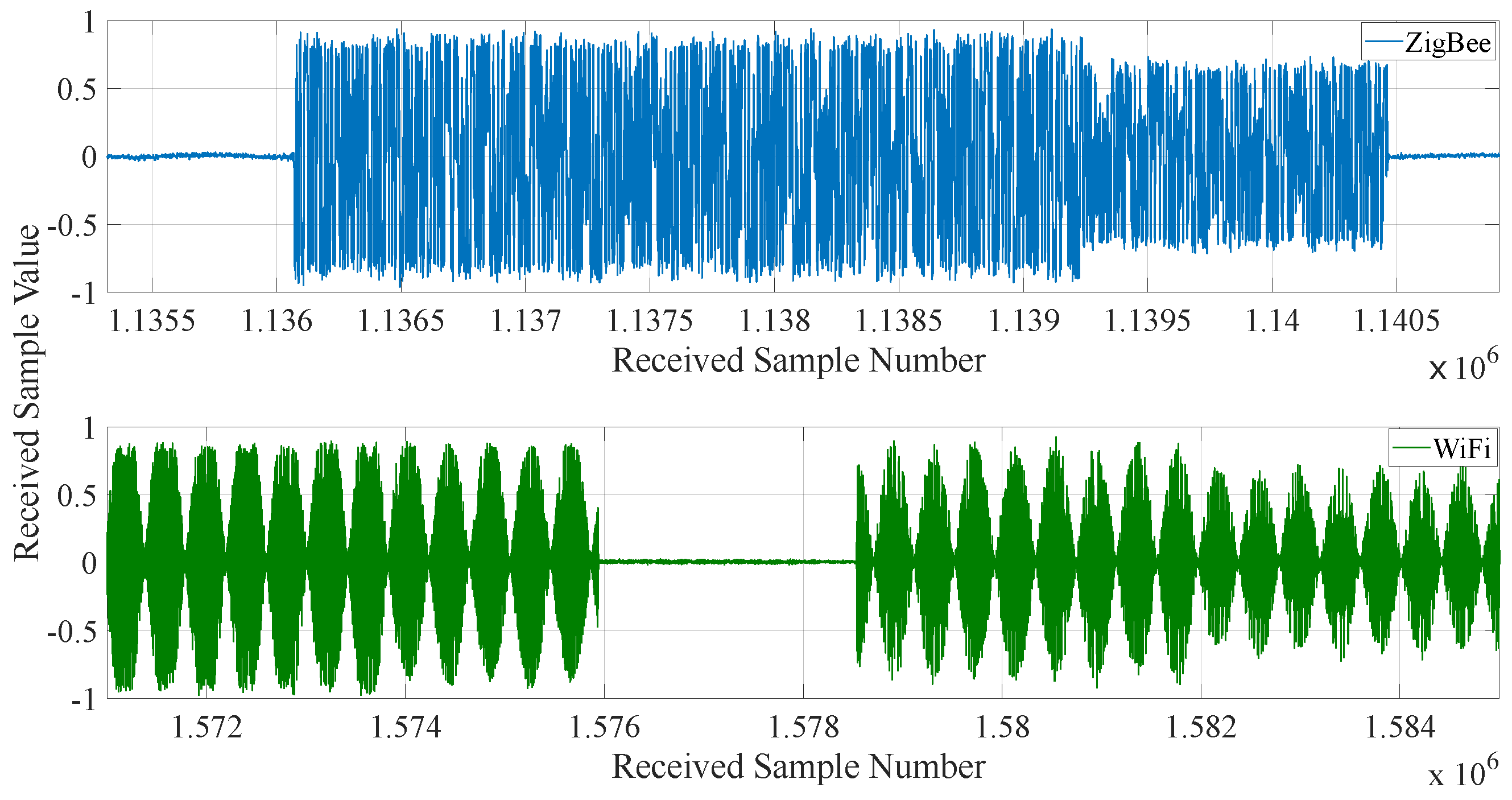
3.1. Experimental Data Collection
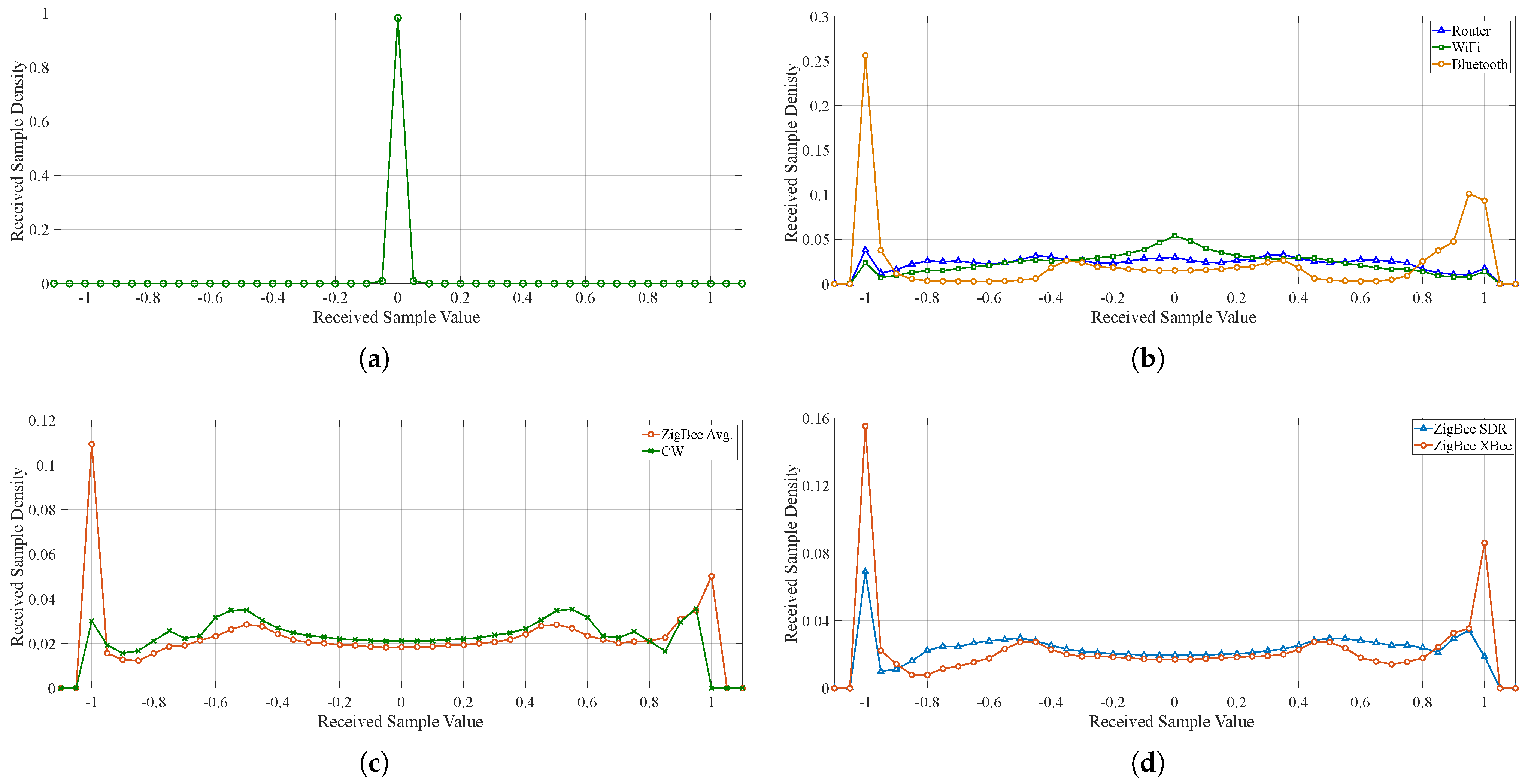
3.2. Feature Engineering
4. Results and Discussion: Signal Classification
4.1. Initial Matlab Investigation
4.2. Python Investigation
4.3. Summary and Discussion
5. Future Work and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Katopodis, P.; Katsis, G.; Walker, O.; Tummala, M.; Michael, J.B. A Hybrid, Large-scale Wireless Sensor Network for Missile Defense. In Proceedings of the 2007 IEEE International Conference on System of Systems Engineering, San Antonio, TX, USA, 16–18 April 2007; pp. 1–5. [Google Scholar]
- Förster, A. Introduction to Wireless Sensor Networks; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Tennina, S.; Santos, M.; Mesodiakaki, A.; Al, E. WSN4QoL: WSNs for remote patient monitoring in e-Health applications. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 1–6. [Google Scholar]
- Beestermöller, H.J.; Sebald, J.; Sinnreich, M.C.; Borchers, H.J.; Schneider, M.; Luttmann, H.; Schmid, V. Wireless-Sensor Networks in Space Technology Demonstration on ISS. In Proceedings of the Dresdner Sensor-Symposium 2015, Dresden, Germany, 7–9 December 2015; pp. 99–102. [Google Scholar]
- Vladimirova, T.; Bridges, C.P.; Paul, J.R.; Malik, S.A.; Sweeting, M.N. Space-based wireless sensor networks: Design issues. In Proceedings of the 2010 IEEE Aerospace Conference, Big Sky, MT, USA, 6–13 March 2010; pp. 1–14. [Google Scholar]
- O’Mahony, G.D.; Harris, P.J.; Murphy, C.C. Investigating the Prevalent Security Techniques in Wireless Sensor Network Protocols. In Proceedings of the 2019 30th Irish Signals and Systems Conference (ISSC), Maynooth, Ireland, 17–18 June 2019; pp. 1–6. [Google Scholar]
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, L.; Zorzi, M. Internet of things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Cisco. Cisco Annual Internet Report (2018–2023); Tech. Rep.; Cisco: San Jose, CA, USA, 2020. [Google Scholar]
- O’Mahony, G.D.; Curran, J.T.; Harris, P.J.; Murphy, C.C. Interference and Intrusion in Wireless Sensor Networks. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 4–16. [Google Scholar] [CrossRef]
- O’Mahony, G.D.; Harris, P.J.; Murphy, C.C. Investigating Supervised Machine Learning Techniques for Channel Identification in Wireless Sensor Networks. In Proceedings of the 2020 31st Irish Signals and Systems Conference (ISSC), Letterkenny, Ireland, 11–12 June 2020; pp. 1–6. [Google Scholar]
- Tektronix. DPX Overview. 2019. Available online: https://www.tek.com/dpx-overview (accessed on 1 July 2021).
- ZigBee Alliance. ZigBee Specification. ZigBee Document 053474r20; Tech. Rep.; The ZigBee Alliance: Davis, CA, USA, 2012. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Shanthakumar, V.A.; Banerjee, C.; Mukherjee, T.; Pasiliao, E. Uncooperative RF Direction Finding with I/Q Data. In Proceedings of the 2020 the 4th International Conference on Information System and Data Mining, Hawaii, HI, USA, 15–17 May 2020; pp. 6–13. [Google Scholar]
- Roy, D.; Mukherjee, T.; Chatterjee, M.; Pasiliao, E. Detection of Rogue RF Transmitters using Generative Adversarial Nets. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–7. [Google Scholar]
- Roy, D.; Mukherjee, T.; Chatterjee, M.; Pasiliao, E. Primary User Activity Prediction in DSA Networks using Recurrent Structures. In Proceedings of the 2019 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, NJ, USA, 11–14 November 2019; pp. 1–10. [Google Scholar]
- Roy, D.; Mukherjee, T.; Chatterjee, M.; Pasiliao, E. RF Transmitter Fingerprinting Exploiting Spatio-Temporal Properties in Raw Signal Data. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 89–96. [Google Scholar]
- Jian, T.; Rendon, B.C.; Ojuba, E.; Soltani, N.; Wang, Z.; Sankhe, K.; Gritsenko, A.; Dy, J.; Chowdhury, K.; Ioannidis, S. Deep Learning for RF Fingerprinting: A Massive Experimental Study. IEEE Internet Things Mag. 2020, 3, 50–57. [Google Scholar] [CrossRef]
- O’Mahony, G.D.; Harris, P.J.; Murphy, C.C. Identifying Distinct Features based on Received Samples for Interference Detection in Wireless Sensor Network Edge Devices. In Proceedings of the 2020 Wireless Telecommunications Symposium (WTS), Washington, DC, USA, 22–24 April 2020; pp. 1–7. [Google Scholar]
- Wu, K.; Tan, H.; Ngan, H.L.; Liu, Y.; Ni, L.M. Chip error pattern analysis in IEEE 802.15.4. IEEE Trans. Mob. Comput. 2012, 11, 543–552. [Google Scholar]
- Wahla, A.H.; Chen, L.; Wang, Y.; Chen, R.; Wu, F. Automatic Wireless Signal Classification in Multimedia Internet of Things: An Adaptive Boosting Enabled Approach. IEEE Access 2019, 7, 160334. [Google Scholar] [CrossRef]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-Ratio Approaches to Automatic Modulation Classification. IEEE Trans. Syst. Man Cybern. C Aool. Rev. 2011, 41, 455–469. [Google Scholar] [CrossRef]
- Hazza, A.; Shoaib, M.; Alshebeili, S.A.; Fahad, A. An overview of feature-based methods for digital modulation classification. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6. [Google Scholar]
- Xie, L.; Wan, Q. Cyclic Feature-Based Modulation Recognition Using Compressive Sensing. IEEE Wirel. Commun. Lett. 2017, 6, 402–405. [Google Scholar] [CrossRef]
- Park, C.; Choi, J.; Nah, S.; Jang, W.; Kim, D.Y. Automatic Modulation Recognition of Digital Signals using Wavelet Features and SVM. In Proceedings of the 2008 10th International Conference on Advanced Communication Technology, Gangwon, Korea, 17–20 February 2008; pp. 387–390. [Google Scholar]
- Lee, S.H.; Kim, K.-Y.; Shin, Y. Effective Feature Selection Method for Deep Learning-Based Automatic Modulation Classification Scheme Using Higher-Order Statistics. Appl. Sci. 2020, 10, 5882. [Google Scholar] [CrossRef] [Green Version]
- Smith, A.; Evans, M.; Downey, J. Modulation classification of satellite communication signals using cumulants and neural networks. In Proceedings of the 2017 Cognitive Communications for Aerospace Applications Workshop (CCAA), Cleveland, OH, USA, 27–28 June 2017; pp. 1–8. [Google Scholar]
- Xie, W.; Hu, S.; Yu, C.; Zhu, P.; Peng, X.; Ouyang, J. Deep Learning in Digital Modulation Recognition Using High Order Cumulants. IEEE Access 2019, 7, 63760–63766. [Google Scholar] [CrossRef]
- Pajic, M.S.; Veinovic, M.; Peric, M.; Orlic, V.D. Modulation Order Reduction Method for Improving the Performance of AMC Algorithm Based on Sixth–Order Cumulants. IEEE Access 2020, 8, 106386–106394. [Google Scholar] [CrossRef]
- Hazar, M.A.; Odabasioglu, N.; Ensari, T.; Kavurucu, Y.; Sayan, O.F. Performance analysis and improvement of machine learning algorithms for automatic modulation recognition over Rayleigh fading channels. Neural Comput. Appl. 2018, 29, 351–360. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, G.; Wang, J.; Tang, Q. Wireless signal classification based on high-order cumulants and machine learning. In Proceedings of the 2017 International Conference on Computer Technology, Electronics and Communication (ICCTEC), Chongqing, China, 25–26 March 2017; pp. 246–250. [Google Scholar]
- Hu, H.; Wang, Y.; Song, J. Signal classification based on spectral correlation analysis and SVM in cognitive radio. In Proceedings of the 22nd International Conference on Advanced Information Networking and Applications (AINA 2008), Gino-wan, Japan, 25–28 March 2008; pp. 883–887. [Google Scholar]
- Zhang, Z.; Li, Y.; Zhu, X.; Lin, Y. A Method for Modulation Recognition Based on Entropy Features and Random Forest. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security Companion (QRS-C), Prague, Czech Republic, 25–29 July 2017; pp. 243–246. [Google Scholar]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-Air Deep Learning Based Radio Signal Classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef] [Green Version]
- Gravelle, C.; Zhou, R. SDR demonstration of signal classification in real-time using deep learning. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–5. [Google Scholar]
- Zheng, S.; Chen, S.; Qi, P.; Zhou, H.; Yang, X. Spectrum sensing based on deep learning classification for cognitive radios. China Commun. 2020, 17, 138–148. [Google Scholar] [CrossRef]
- Zheng, S.; Qi, P.; Chen, S.; Yang, X. Fusion Methods for CNN-Based Automatic Modulation Classification. IEEE Access 2019, 7, 66496–66504. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Gan, C.; Sun, S.; Wang, M. Automatic Modulation Classification Using Convolutional Neural Network With Features Fusion of SPWVD and BJD. IEEE Trans. Signal Inf. Process. Netw. 2019, 5, 469–478. [Google Scholar] [CrossRef]
- He, H.; Jin, S.; Wen, C.; Gao, F.; Li, G.Y.; Xu, Z. Model-Driven Deep Learning for Physical Layer Communications. IEEE Wirel. Commun. 2019, 26, 77–83. [Google Scholar] [CrossRef] [Green Version]
- Rajendran, S.; Meert, W.; Giustiniano, D.; Lenders, V.; Pollin, S. Deep Learning Models for Wireless Signal Classification with Distributed Low-Cost Spectrum Sensors. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 433–445. [Google Scholar] [CrossRef] [Green Version]
- Fontaine, J.; Fonseca, E.; Shahid, A.; Kist, M.; DaSilva, L.A.; Moerman, I.; Poorter, E.D. Towards low-complexity wireless technology classification across multiple environments. Ad Hoc Netw. 2019, 91, 101881. [Google Scholar] [CrossRef]
- Hjorth, B. EEG analysis based on time domain properties. Electroencephalogr. Clin. Neurophysiol. 1970, 29, 306–310. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Shi, Y.; Erpek, T.; Headley, W.; Flowers, B.; Stantchev, G.; Lu, Z. When Wireless Security Meets Machine Learning: Motivation, Challenges, and Research Directions. arXiv 2020, arXiv:2001.08883. [Google Scholar]
- O’Mahony, G.D.; Harris, P.J.; Murphy, C.C. Analyzing using Software Defined Radios as Wireless Sensor Network Inspection and Testing Devices: An Internet of Things Penetration Testing Perspective. In Proceedings of the 2020 Global Internet of Things Summit (GIoTS), Dublin, Ireland, 3–5 June 2020; pp. 1–6. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Grimaldi, S.; Mahmood, A.; Gidlund, M.; Alves, M. An SVM-based method for classification of external interference in industrial wireless sensor and actuator networks. J. Sens. Actuator Netw. 2017, 6, 9. [Google Scholar] [CrossRef] [Green Version]
- O’Mahony, G.D.; McCarthy, K.G.; Harris, P.J.; Murphy, C.C. Developing novel low complexity models using received in-phase and quadrature-phase samples for interference detection and classification in Wireless Sensor Network and GPS edge devices. Ad Hoc Netw. 2021, 120, 102562. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
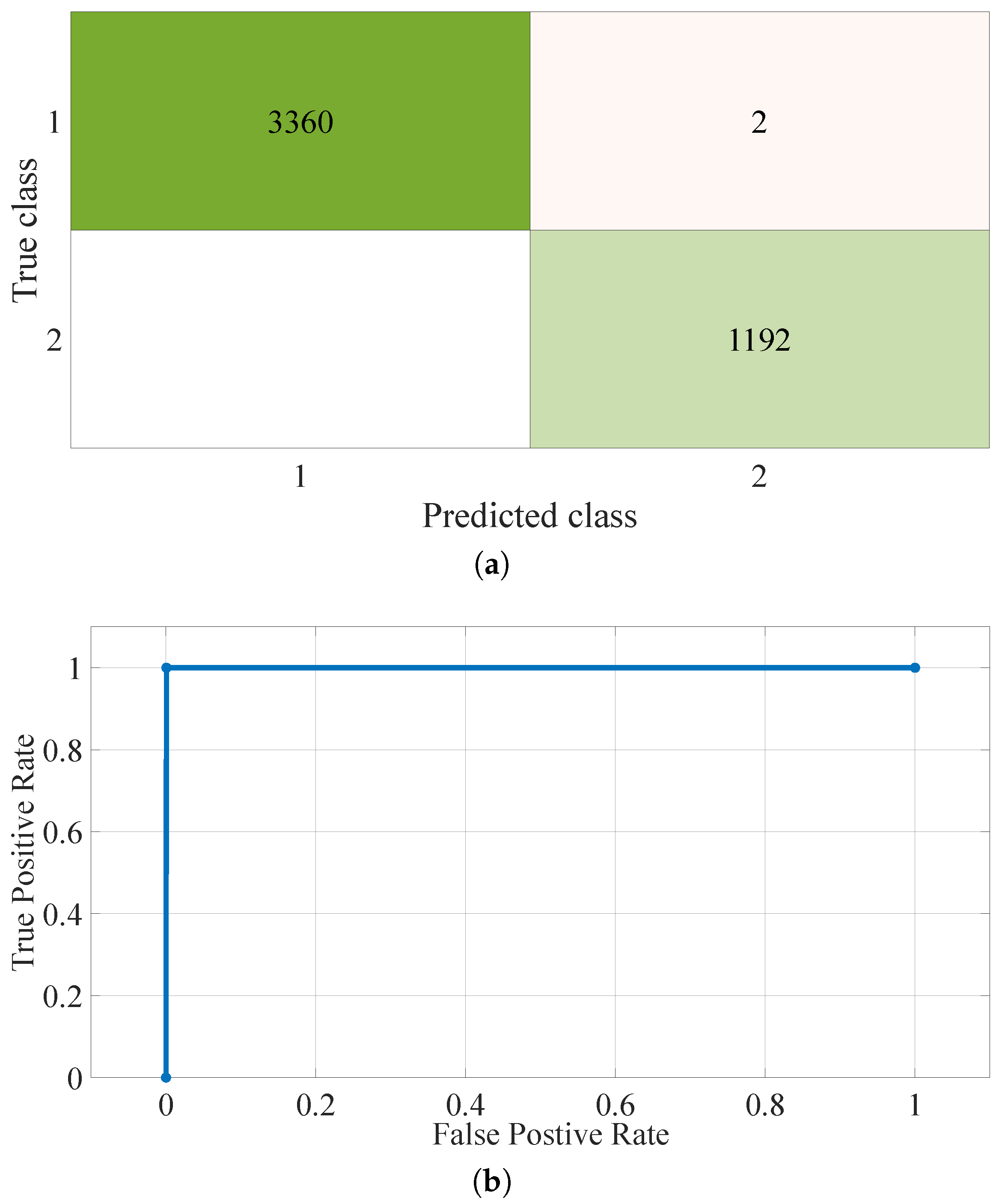{kind=link}
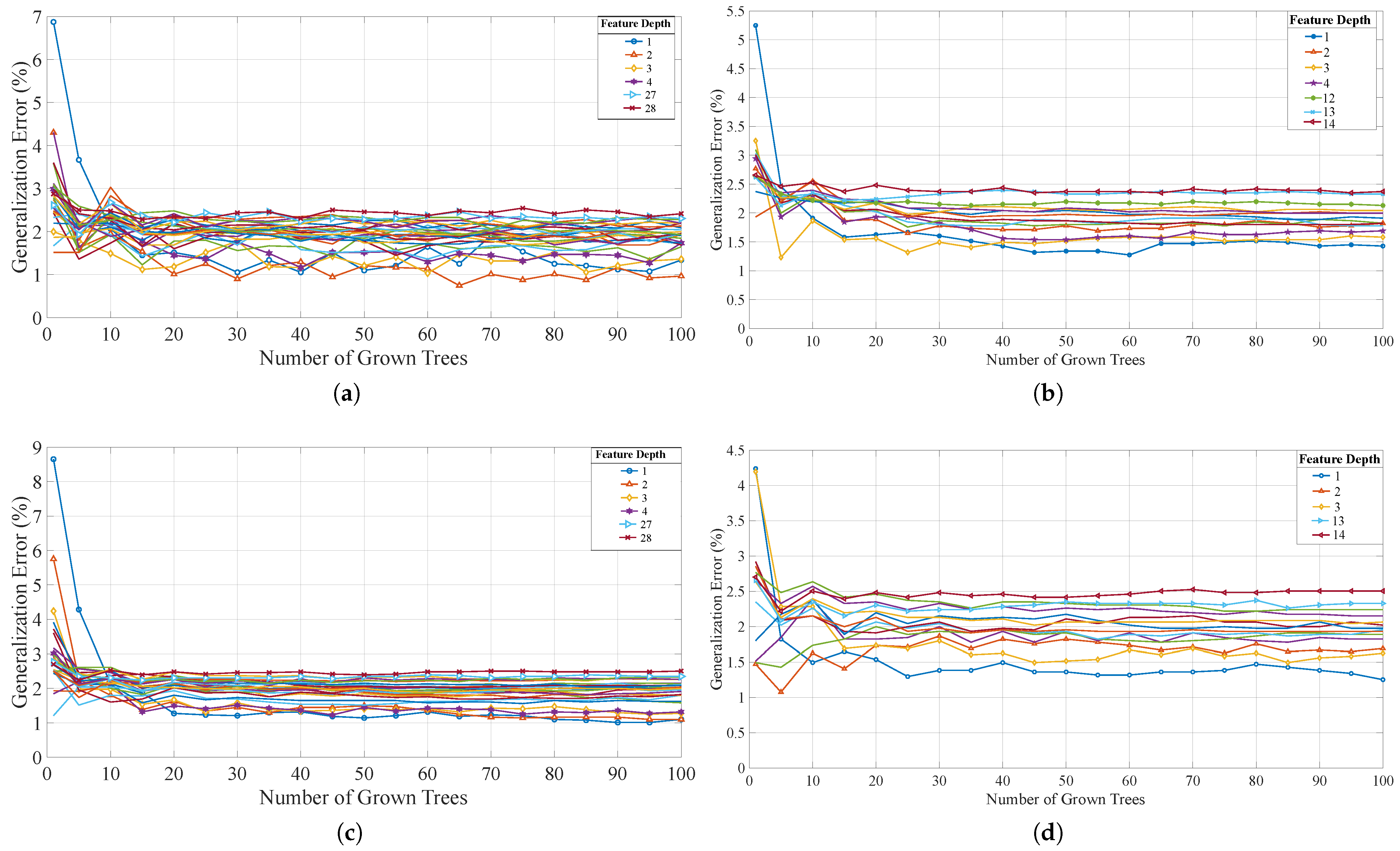{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Signal Type | Center Frequency (MHz) | Total Data Grabs | Source |
|---|---|---|---|
| WiFi | 2427 | 536 | Commercial |
| Router | 2447, 2462 | 270 | Commercial |
| Bluetooth | 2402, | 564 | Commercial |
| Advertising | 2480 | ||
| ZigBee | 16 ZigBee | 944 | Commercial |
| (XBee) | Frequencies | ||
| ZigBee (SDR) | 16 ZigBee Frequencies | 1120 | SDR |
| CW | 16 ZigBee | 1120 | SDR |
| Frequencies | |||
| Noise | 16 ZigBee | 492 | Channel |
| Frequencies |
| Signal Type | Center Frequency (MHz) | Total Data Grabs | Source |
|---|---|---|---|
| WiFi | 2427 | 144 | Commercial |
| Router | 2442 | 107 | Commercial |
| Bluetooth | 2402, | 206 | Commercial |
| Advertising | 2480 | ||
| ZigBee | Subset-ZigBee | 240 | Commercial |
| (SDR) | Frequencies | ||
| CW | Subset-ZigBee | 240 | SDR |
| Frequencies | |||
| Noise | Subset-ZigBee | 210 | Channel |
| Frequencies |
| Domain | Initial Feature Number | Final Feature Number | Feature Description |
|---|---|---|---|
| 1 | 1 | Number of non-zeros entries of PDF | |
| 2 | 2 | The area in the center bins ([−0.1:0.1]) | |
| 3 | 3 | The area in the left hand side bins (<−0.1) | |
| 28 | 14 | The center bin (0) value | |
| Time | 8 | 4 | Hjorth parameters [43]-Activity (Sample Variance) |
| 10 | 5 | Absolute mean value | |
| 12 | 6 | The root-mean square (RMS) value | |
| 13 | 7 | Hjorth parameters [43]-Mobility | |
| 14 | 8 | Hjorth parameters [43]-Complexity | |
| 16 | 9 | Shannon Entropy-using use specific approach | |
| 18 | 10 | Matlab’s “approximateEntropy” function | |
| 24 | 12 | Number of zero crossings | |
| Frequency | 21 | 11 | Number of FFT points over a predefined threshold |
| 27 | 13 | Unique function that uses the FFT points to estimate signal bandwidth |
| Signal | Model Data | Training Data | Testing Data | Testing + Unseen Data |
|---|---|---|---|---|
| Noise | 0.0938 | 0.0938 | 0.0938 | 0.1335 |
| WiFi | 0.1511 | 0.1511 | 0.1511 | 0.1601 |
| Router | 0.1077 | 0.1077 | 0.1077 | 0.1405 |
| Bluetooth Advertising | 0.1099 | 0.11 | 0.1097 | 0.1372 |
| CW | 0.1805 | 0.1805 | 0.1805 | 0.1669 |
| ZigBee | 0.3569 | 0.3569 | 0.3571 | 0.2617 |
| Kernel | Training Time (ms) | Average Prediction Time (ms) | Test Data Error (%) | 10 Fold Cross Validation Error (%) | AUC |
|---|---|---|---|---|---|
| 28 Features and All Test Data | |||||
| Linear | 520 | 1.85 | 0.219 | 0.173 | 0.9969 |
| Gaussian | 388 | 1.89 | 0.176 | 0.025 | 0.9975 |
| Radial Basis Function | 383 | 1.85 | 0.176 | 0.025 | 0.9975 |
| Polynomial (3rd Order) | 355 | 1.83 | 0.132 | 0.039 | 0.9985 |
| 14 Features and All Test Data | |||||
| Linear | 508 | 1.84 | 0.329 | 0.4863 | 0.9956 |
| Gaussian | 390 | 1.83 | 0.066 | 0.00 | 0.9993 |
| Radial Basis Function | 534 | 1.84 | 0.066 | 0.00 | 0.9993 |
| Polynomial (3rd Order) | 384 | 1.81 | 0.044 | 0.00 | 0.9997 |
| Device | Predictor Depth | No. of Trees | Training Time (ms) | Avg. Prediction Time (ms) | Test Data Error |
|---|---|---|---|---|---|
| Raspberry Pi 3-B | 1 | 85 | 1564 | 0.0679 | 1.142 |
| Specifications: | 1 GB of RAM and Quad-core Broadcom BCM2837B0, Cortex-A53 CPU @ 1.4 GHz | ||||
| PC | 1 | 85 | 139.6 | 0.005 | 1.142 |
| Specifications: | Dell XPS8930, 16 GB of RAM and an Intel i7-9700 CPU @ 3 GHz, 8 Cores | ||||
| Algorithm | Lowest Achieved Error (%) | Training Time | Iterations |
|---|---|---|---|
| XGBoost/SVM | 0.527 | 122.54 ms | n/a |
| DNN | 0.7027 | 1937.04 s | 400 |
| XGBoost | 0.7905 | 78.1 ms | 400,000 |
| Random Forest | 1.098 | 265.57 ms | 197,568 |
| AdaBoost (Matlab) | 1.2956 | 749.1 ms | n/a |
| K Nearest Neighbors (17 Neighbors) | 3.3816 | 26.93 ms | n/a |
| K Nearest Neighbors (20) (20 Neighbors) | 3.4695 | 15.6 ms | 1152 |
| K Nearest Neighbors(within Radius) | 3.6232 | 35.934 ms | 7166 |
| Gaussian Naive Bayes | 5.907 | 3 ms | 17 |
| Nearest Centroid | 9.222 | 2 ms | 8 |
| Layer Type | Layer Size | Activation Function |
|---|---|---|
| Input | 14 neurons | relu |
| Fully Connected | 50 neurons | relu |
| Fully Connected | 34 neurons | relu |
| Fully Connected | 17 neurons | relu |
| Output | 6 neurons | softmax |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
O’Mahony, G.D.; McCarthy, K.G.; Harris, P.J.; Murphy, C.C. Developing a Low-Order Statistical Feature Set Based on Received Samples for Signal Classification in Wireless Sensor Networks and Edge Devices. IoT 2021, 2, 449-475. https://0-doi-org.brum.beds.ac.uk/10.3390/iot2030023
O’Mahony GD, McCarthy KG, Harris PJ, Murphy CC. Developing a Low-Order Statistical Feature Set Based on Received Samples for Signal Classification in Wireless Sensor Networks and Edge Devices. IoT. 2021; 2(3):449-475. https://0-doi-org.brum.beds.ac.uk/10.3390/iot2030023
Chicago/Turabian StyleO’Mahony, George D., Kevin G. McCarthy, Philip J. Harris, and Colin C. Murphy. 2021. "Developing a Low-Order Statistical Feature Set Based on Received Samples for Signal Classification in Wireless Sensor Networks and Edge Devices" IoT 2, no. 3: 449-475. https://0-doi-org.brum.beds.ac.uk/10.3390/iot2030023