1. Introduction
Concrete based civil infrastructure such as bridges, tunnels and dams undergo structural deterioration due to weathering, corrosion, thermal cycles and carbonation. Cracks on concrete surfaces are often identified as an early indication of possible future structural failures which could be catastrophic if unattended. Therefore, it is of utmost importance to inspect concrete structures frequently for cracks to initiate any proactive measures to avoid further damage.
Use of robotic devices and smart sensors for infrastructure monitoring has become popular in recent years in places where human access is difficult [
1,
2,
3]. Nowadays, visual inspection of larger civil structures is done using remotely controlled drones. The recorded video footages from these inspection rounds are manually watched to detect any cracks. This is a highly time-consuming process and largely depends on surveyor’s experience and knowledge, which adds an extra subjective bias to the final qualitative analysis. These inefficiencies and human errors can be avoided by developing learning models that automatically identify concrete cracks on recorded video.
Several researchers have attempted to develop deep learning models for concrete crack detection. There are many deep learning architectures that have been built specifically for concrete crack detection [
4,
5,
6]. Some of them can only classify crack images from non-crack images without localizing the cracks [
4], while others have attempted to differentiate crack pixels from the background [
5]. More recently, many have applied deep transfer learning techniques such as Mask R-CNN [
7] and YOLO [
8] for instance-level segmentation of cracks [
9,
10] where each crack location can be individually localized and labeled. None of these previous studies looked at the possibility of real-time concrete crack detection with instance-level segmentation. Real-time detection is vital as this will enable active inspection by autonomously steering autonomous robotic platforms such as drones along the cracks. In addition, the robotic platform can be navigated closer to the crack to inspect it in detail. On the other hand, instance segmentation will allow detection of localized multiple cracks on the same image which may provide extra information to predict the propagation of cracks.
In this paper, we demonstrate that deep transfer learning can be used to train an object detection model to automatically identify cracks with segmentation masks to localize cracks on images collected from video inspections in real-time. We specifically investigated YOLACT, a real-time instant segmentation algorithm [
11], which outperformed other existing algorithms in speed and accuracy in the COCO object detection dataset and used it to train deep learning model on a small dataset of concrete crack images. To train the crack detection model, we built a dataset by collecting images from a publicly available dataset and manually annotating segmentation mask for each crack. The transfer learning approach helped us to train the network on a smaller dataset with the high-level features extracted from the COCO dataset with reduced training duration.
2. Materials and Methods
Our framework for concrete crack detection is based on YOLACT: a fully-convolution deep learning model for real-time instance segmentation. Instance segmentation allows us to segment-out all the cracks present in the image into individual segmentation masks. The YOLACT architecture has recorded mean average precision (mAP) of 29.8 at 33 FPS on a single Titan XP GPU. This is significantly faster than any other available instance segmentation frameworks. For example, the popular Mask R-CNN recorded only 9 FPS with slightly higher maP of 35. YOLACT has achieved this by breaking the instance segmentation into two parallel subtasks. The first task generates a set of prototype masks and the second task predicts the per-instance mask coefficients. Then, instance masks are produced by linearly combining the prototypes with the mask coefficients. As these two tasks are run in parallel, the instance segmentation process is faster than other state-of-the-art algorithms. This makes the YOLACT model the ideal choice for real-time concrete crack detection as it provides real-time results which can be incorporated with an autonomous UAV for active inspection of concrete cracks.
To train a YOLACT model for concrete crack detection, we used the publicly available open-source implementation of the YOLACT algorithm. Even though the original YOLACT model was trained on COCO dataset with 80 real-world object categories, we intended to train a YOLACT model for concrete crack detection and instance segmentation. We achieved this by using deep transfer learning techniques and training the YOLACT model on a custom dataset of concrete crack images.
The dataset and the code base for this research work are publicly available at
https://github.com/lasithaya/YOLACT. We used freely available Google Colab for training and testing the YOLACT model for concrete crack detection. Colab notebook is available in the GitHub repository to easily replicate the results presented in this paper.
2.1. Transfer Learning
Many training images are required to train a deep network such as YOLACT as there are thousands of weight parameters that need training. In some domains, e.g. infrastructure monitoring, acquiring such a large dataset is time-consuming and costly. However, instead of training network from scratch with concrete cracks, we can pre-train a CNN model on a separate large dataset and use the pre-trained weights to initialize the weights for crack detection. This is called transfer learning and often yields better results with smaller datasets [
12]. The transfer learning technology is commonly used to initialize the backbone of the deep network, where the backbone weights are usually pre-trained on the publicly available ImageNet dataset [
13]. We used the commonly available ResNet50 and ResNet101 [
14] pre-trained backbone models for weight initialization. In addition, as our dataset is small, we used a YOLACT model pre-trained on COCO dataset [
15] to initialize the weight for concrete crack detection and trained only the last few layers of the YOLACT model on the concrete crack dataset. The results of these experiments are discussed in
Section 3.
2.2. Dataset
To test the effectiveness of YOLACT we concatenated concrete crack images from five different publicly available datasets [
16,
17,
18,
19,
20]. However, these images were not annotated with instance segmentation and were not directly usable for training the YOLACT model. Consequently, we built an instance-level segmented dataset with 300 images for training, 100 images for validation and 100 images for testing. All the images were re-scaled to 448 × 448 resolution for efficient training.
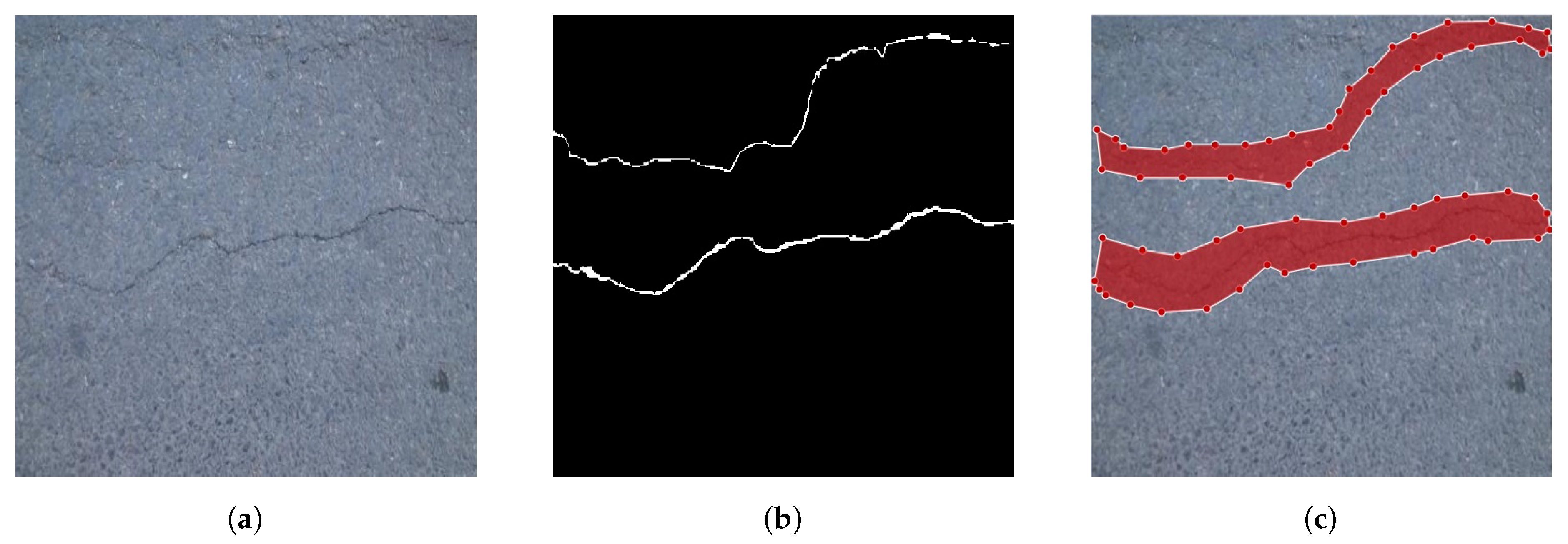
Figure 1 shows a ground-truth crack image with its instance-level segmented mask.
2.3. Training
As we used a small dataset with pre-trained weights, we did not require training for a longer time. We experimented with different training schedules with different backbone architectures. The model’s weights were saved every 1000 iteration and later used to evaluate the performance values on the validation set. We also tested different hyperparameters such as learning rate and batch sizes to find the best training parameters. We trained the network with a batch size of 8, the learning rate of and 25,000 iterations on Google Colab.
3. Results
We trained two separate networks with ResNet-50 and ResNet-101 backbone architectures and evaluated their performances on the test set. The qualitative and quantitative results are discussed in the following sections.
3.1. Qualitative Results
Figure 2 shows the qualitative results from a selected set of test images from the dataset. The first column shows the test images and the second column shows the corresponding ground-truth crack location. The last two columns show the test results with ResNet-50 and ResNet-101 backbones. Different color segments in the result columns correspond to instance segmentation of each crack. According to the test results, both backbone architectures performed well in segmenting individual crack. The trained models identified each branch of cracks as separate instances. This is preferable as we can identify the crack propagation more accurately. A close look at the test results revealed that ResNet-101 backbone performed slightly better than ResNet-50 in segmenting some cracks. This can be seen in the last image in Column C, where ResNet-50 failed to identify the small crack propagating up. This might be because ResNet-101 architecture has more deep layers than ResNet-50, which provides more fine-tuned features for the YOLACT network to improve its performances.
3.2. Quantitative Results
Table 1 shows the quantitative results of YOLACT performance on our concrete crack detection dataset with ResNet-101 and ResNet-50 backbones. The last three columns of the table show the segmentation performances for both the bounding box and the mask-based localization of cracks. According to the results shown in
Table 1, ResNet-101 backbone reported higher mAP (mean average precision) than ResNet-50 backbone in both box and mask segmentations. We used COCO definition of mAP for this evaluation, which is averaged over all object categories and 10 IoU (Intersection over Union) thresholds starting from IoU of 0.5. The last two columns are the average precision (AP) for 50% and 75% IoUs, respectively. Again, ResNet-101 backbone performed better in both
and
performance measures. This is expected as ResNet-101 twice as many deep layers as ResNet-50. However, the training on the ResNet-101 takes more time and the inference is slow compared to a network with ResNet-50 backbone.
The first two columns of
Table 1 show the frames per second (FPS) inference performances on Tesla P100 and Nvidia Titan XP GPUs. According to the test results, real-time inference is possible with Titan XP GPU, and even with the low-end P100 GPU near real-time inference is possible, which is acceptable in many robotics applications. ResNet-50 recorded a higher frame rate than ResNet-101 and is much suitable for real-time applications.
4. Discussion
In this paper, we evaluate YOLACT: a real-time instance segmentation algorithm for concrete crack detection. We created a small dataset of annotated masks with concrete crack images collected from publicly available datasets. Deep transfer learning techniques were used with different backbone architectures to speed up the training process. This also reduced the number of training images required as we only fine-tuned the last few layers of the YOLACT network for concrete crack segmentation. Both qualitative and quantitative tests were carried out with ResNet-50 and ResNet-101 backbone architectures. ResNet-101 backbone performed slightly better in average precision but ResNet-50 gave much better real-time frame rate when tested on a single GPU. As future work, YOLACT can be easily integrated with a robotic system to carry out active inspections on concrete structures.
Author Contributions
Conceptualisation, L.P. and D.M.G.P.; methodology, L.P. and U.I.; software, L.P. and G.K.; validation, D.M.G.P., L.P. and U.I.; formal analysis, L.P. and G.K.; investigation, L.P.; writing, review and editing, L.P., D.M.G.P., U.I. and G.K.; and visualization, L.P.. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| GPU | Graphic Processing Unit |
| mAP | Mean Average Precision |
| IoU | Intersection over Union |
| CNN | Convolution Neural Network |
| UAV | Unmanned Aerial Vehicle |
| FPS | Frame Per Second |
References
- Gunatilake, A.; Piyathilaka, L.; Kodagoda, S.; Barclay, S.; Vitanage, D. Real-time 3d profiling with rgb-d mapping in pipelines using stereo camera vision and structured ir laser ring. In Proceedings of the 14th IEEE Conference on Industrial Electronics and Applications (ICIEA 2019), Xi’an, China, 19–21 June 2019; pp. 916–921. [Google Scholar]
- Giovanangeli, N.; Piyathilaka, L.; Kodagoda, S.; Thiyagarajan, K.; Barclay, S.; Vitanage, D. Design and development of drill-resistance sensor technology for accurately measuring microbiologically corroded concrete depths. In 2019 Proceedings of the 36th ISARC, Banff, Canada. ISARC Proc. 2019, 36, 735–742. [Google Scholar]
- Piyathilaka, L.; Sooriyaarachchi, B.; Kodagoda, S.; Thiyagarajan, K. Capacitive Sensor Based 2D Subsurface Imaging Technology for Non-destructive Evaluation of Building Surfaces. In Proceedings of the IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Bangkok, Thailand, 18–20 November 2019; pp. 287–292. [Google Scholar]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. SDNET2018: An annotated image dataset for non-contact concrete crack detection using deep convolutional neural networks. Data Brief 2018, 21, 1664–1668. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Dung, C.V.; others. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated road crack detection using deep convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5212–5215. [Google Scholar]
- Attard, L.; Debono, C.J.; Valentino, G.; Di Castro, M.; Masi, A.; Scibile, L. Automatic Crack Detection using Mask R-CNN. In Proceedings of the 2019 11th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 23–25 September 2019; pp. 152–157. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision – ECCV 2014. ECCV 2014. Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transport. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection. IEEE Trans. Intell. Transport. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}