
Fuzzy Prediction Intervals Using Credibility Distributions †


Dept Statistics and Operations Research, University of Valencia, C/Dr. Moliner 50, 46100 Burjassot, Spain
*
Author to whom correspondence should be addressed.
†
Presented at the 7th International conference on Time Series and Forecasting, Gran Canaria, Spain,
19–21 July 2021.
‡
These authors contributed equally to this work.
Eng. Proc. 2021, 5(1), 51; https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005051
Published: 9 July 2021
(This article belongs to the Proceedings of The 7th International Conference on Time Series and Forecasting)
Abstract
:We present a new forecasting scheme based on the credibility distribution of fuzzy events. This approach allows us to build prediction intervals using the first differences of the time series data. Additionally, the credibility expected value enables us to estimate the k-step-ahead pointwise forecasts. We analyze the coverage of the prediction intervals and the accuracy of pointwise forecasts using different credibility approaches based on the upper differences. The comparative results were obtained working with yearly time series from the M4 Competition. The performance and computational cost of our proposal, compared with automatic forecasting procedures, are presented.
1. Introduction
This paper presents a new prediction scheme for time series using fuzzy logic and credibility distributions. Uncertainty about the future behavior of each time series is analyzed through the first and upper differences of the observed data, while the last raw observation is maintained as the level of the time series. That is, we assume that the uncertainty is not in the observed data, but in the underlying processes of the relationship between the data of the time series.
The uncertainty about the future of the time series is approximated using fuzzy variables [1]. Thus, working with fuzzy variables enables us to build prediction intervals with a given credibilistic coverage and provide pointwise forecasts through the credibility expected value, using various fuzzy prediction models. This credibility approach has not been previously proposed in the context of time series, although approximation of the uncertainty of fuzzy events using fuzzy variables is well established in other knowledge areas.
In previous works, we dealt with fuzzy variables to approximate the uncertainty of the future returns on assets or the return of a given portfolio [2,3]. In this paper, we propose to predict the future performance of the times series using LR-type fuzzy variables, whose parameters are estimated by using the sets of differences of several orders of the observed data. Finally, the optimistic values of the fuzzy variable provide us with the prediction intervals for each nominal coverage.
It must be noted that this new approach does not follow the classical fuzzy time series methodology, suggested by Song and Chissom [4], which has subsequently been improved by other authors (for more details about fuzzy time series, see, e.g., [5] and references therein). Recently, we introduced a new weighted fuzzy-trend method to forecast a stock index, which outperforms Chen’s methodology [6] for pointwise one-step forecasting [7]. However, the aforementioned approach does not provide suitable tools for building accurate fuzzy prediction intervals and k-step-ahead forecasts.
The main goal of this research is to design new fuzzy prediction models for nonseasonal time series that provide fuzzy variables as forecasts of the future performance of the time series, using the historical datasets. The properties of the fuzzy variables and their credibility distributions are useful to obtain prediction intervals and accurate ex-post forecasts.
To further investigate the predictive behavior of our proposals and the accuracy of the outputs compared to other forecasting approaches, we applied them to a set of yearly time series from the M4 Competition [8]. For the comparison with automatic forecasting procedures, we selected the exponential smoothing (ES) and ARIMA procedures included in the forecast package for R [9], which is available in CRAN (https://cran.r-project.org/, accessed on 15 June 2021), by using the R commands ‘es’ and ‘auto.arima’, respectively.
The rest of the paper is structured as follows. Section 2 summarizes concepts and definitions of fuzzy theory. The proposed methodology for building prediction intervals and pointwise forecasts is formulated in Section 3. In Section 4, we analyze the numerical results obtained by the fuzzy prediction models for a dataset from the M4 Competition. Finally, we set out our conclusions in Section 5.
2. Uncertainty Estimation with Fuzzy Logic
Let us recall some useful definitions based on fuzzy logic. The possibility and necessity of every fuzzy event (for instance, , for any ), where T is a fuzzy number, can be evaluated according to the possibility distribution associated with its membership function () as follows [10]:
Thus, an alternative to quantify the uncertainty is the credibility measure introduced in [11]:
A fuzzy variable is described by means of the following membership function,
whose credibility distribution is defined as
In particular, is said to be an L-R power fuzzy variable if its credibility distribution has the following form [2]:
Throughout the paper, we denote LR-power fuzzy variables of this type by . The estimation of the parameters of is made by means of sample percentiles of the dataset of differences between chronologically consecutive historical data.
Credibility Expected Values and Prediction Intervals
The pointwise estimation of a fuzzy variable is approximated by its credibility expected value, denoted by [11]. For an LR-power fuzzy variable , its expected mean is calculated as follows [2]:
Finally, it must be said that the prediction intervals can be built using the credibility distribution (5), calculating suitable -optimistic values of the fuzzy variable , defined as follows [1]:
Alternatively, the endpoints of one specific prediction interval, for instance, with a of nominal coverage for , can be directly calculated through the inverse function of the credibility distribution, , as follows:
3. New Fuzzy Prediction Methods
Let us consider a time series , whose observed data are , being the last observation. Then, we can build the k-order differences between consecutive observations, .
At time i, , let us define the k-difference, , as the difference between the forward observation of k order from time i and the observation at time i, that is
Thus, for every k-order, , we calculate the time series of the k-differences:
We assume that the uncertainty about the future behavior of the time series can be estimated through the credibility approximation of the time series of the k-differences. To do so, we consider the LR-power fuzzy variable , whose credibility distribution is given in Equation (5), which is built using the sample percentiles of the set . The bounded support of is approximated by and , where . The shape parameters are obtained as and , assuming that the sample percentiles and have a possibility of being realistic (see, e.g., [12] for more information about LR fuzzy numbers). The forecaster can choose other sample percentiles, if that decision could improve the approximation of , avoiding outliers.
3.1. One-Step Ahead Fuzzy Forecast Model: FFM
For the time series , let us consider the fuzzy variable , which is built considering the set of the first differences, . Since is the last observation, the one-step ahead fuzzy forecast is defined as follows:
That is, a translation of magnitude is applied to the fuzzy variable to build the one-step-ahead fuzzy forecast. Consequently, by applying the well-known property of the credibility expected mean (, for ), the pointwise forecast is the credibility expected value .
In order to provide further fuzzy predictions, we define the fuzzy variables for h steps ahead, , using those previously forecasted pointwise as
and obtain that . Analogously, we obtain the pointwise forecasts as their credibility expected values: , for .
The prediction intervals for the h-step-ahead pointwise prediction, , are built following Equation (8) for the corresponding fuzzy variables .
3.2. K-Step-Ahead Fuzzy Forecast Model: FFKM
Let us consider the time series , for which k-step-ahead forecasts are requested. For , we build the fuzzy variables , using the corresponding set of the h-order differences, , . Note that in this modeling approach we need to build k fuzzy variables, for , depending on the ex-post predictions requested.
Let be the last observation; then, for every , the h-step-ahead fuzzy forecast is defined as follows:
The pointwise h-step-ahead forecast is then , and the corresponding prediction intervals are built using the credibility distribution of every fuzzy variable , .
In the context of fuzzy time series, other authors have also considered the differences of consecutive observations to introduce new forecasting methods [13,14], following the basic scheme introduced in [6]. However, their approaches do not have any element in common with the ones we propose in this paper.
3.3. A Numerical Example
Let us present the performance of our methods FFM and FFkM, using the first yearly time series from the M4 Competition [8]. This time series contains 31 observations, . We make a partition of this observed data, in such a way that 28 first observations belong to the training set ( = 7651.4), while the last 3 are reserved for the comparison with the pointwise h-step-ahead forecasts provided, h = 1, 2, 3.
3.3.1. Performance of the FFM Method
Using the aforementioned methodology for applying the FFM method, we build the fuzzy variable , which is defined as , the credibility expected value being =98.93. Thus, = 7750.33.
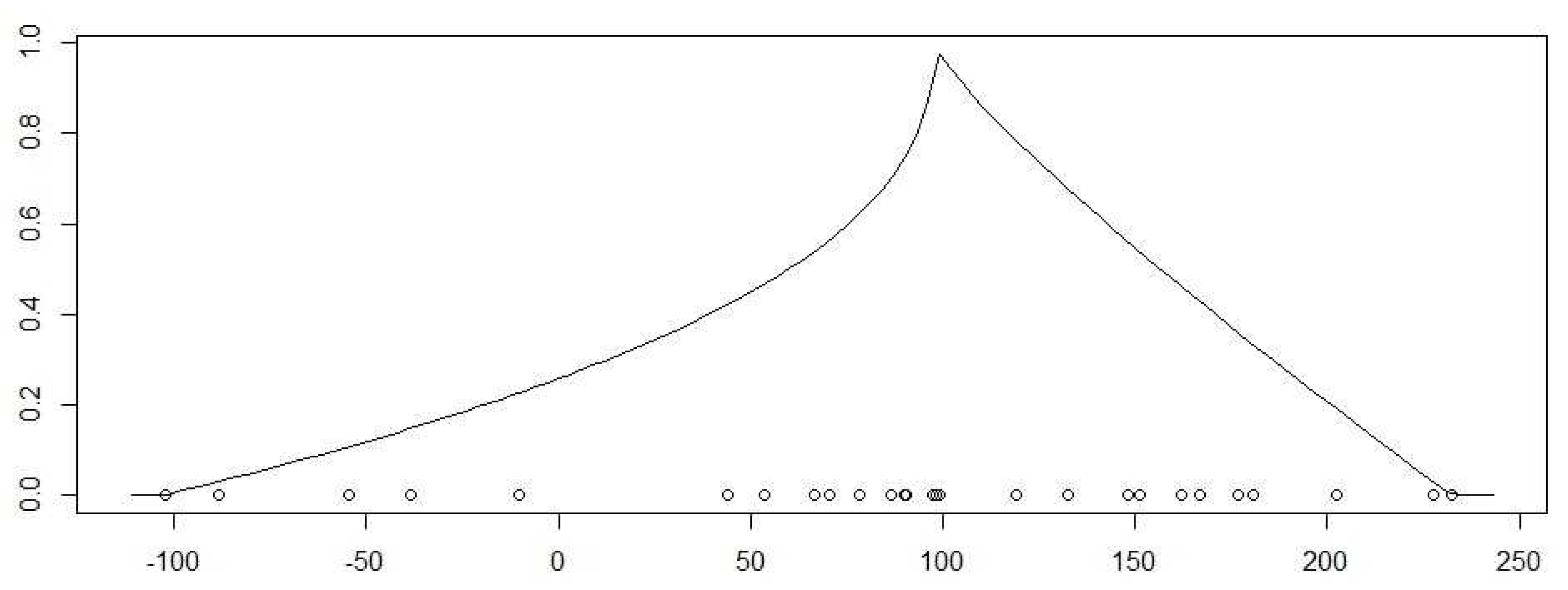
Figure 1 shows the plot of the membership function of the fuzzy variable . The observed first differences are plotted as small circles. Using the suitable sample percentiles of the first differences in , we calculate the 90% prediction interval of . Note that the credibility expected value of the fuzzy variable is not the middle point of this prediction interval.
The calculations of the corresponding h-step-ahead forecasts and the prediction intervals, for h = 2, 3, are easily obtained by taking into account both the properties of the expected value and the sample percentiles, , for . In particular, = 7849.26 and = 7948.20.
3.3.2. Performance of the FFKM Method
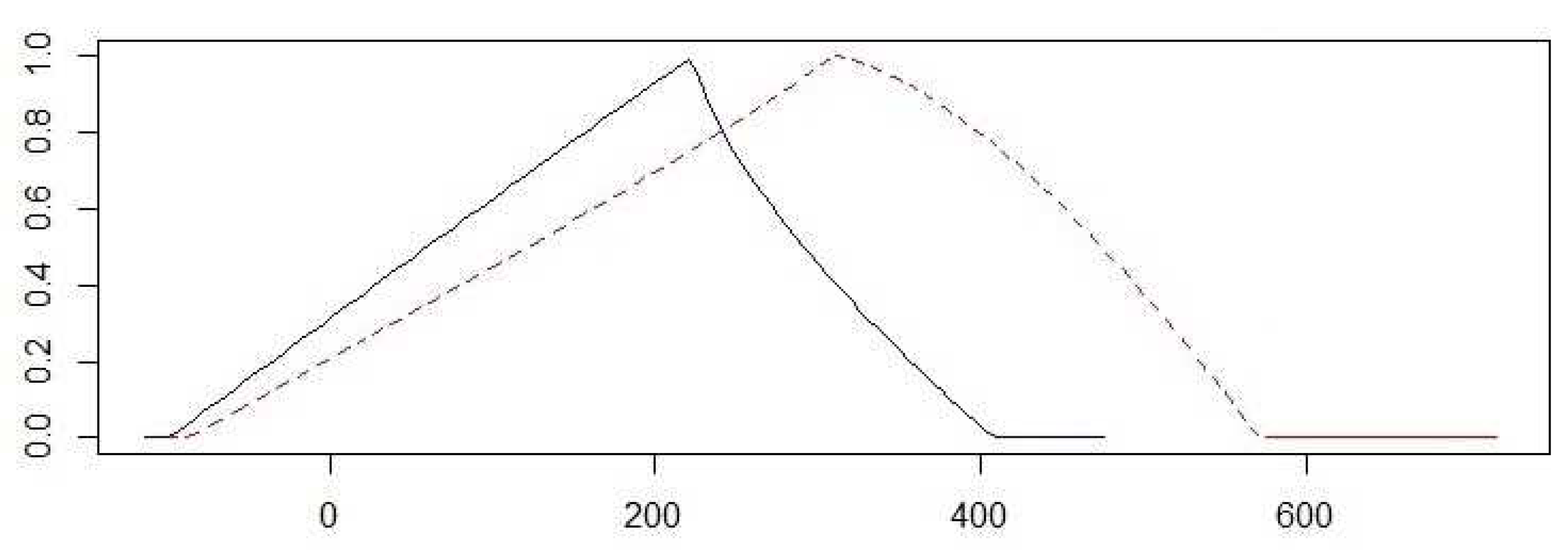
In order to determine the out-of-sample forecasts and their prediction intervals, we apply the FFkM method, for k = 3. It is easily seen that the first iteration is identical for both methods, FFM and FFkM. However, we need to build the sets of the second- and third-order differences to obtain the fuzzy variables and , respectively. Figure 2 shows the membership function of the aforementioned fuzzy variables.
Table 1 shows the raw observation, the pointwise forecasts obtained by applying the FF3M method, the 90% prediction interval and the prediction error, , for h = 1, 2, 3.
Note that the trend changes in the observed data have not been suitably estimated by the proposed methods, so that the prediction error has increased when h increases. In fact, only the 90% prediction interval of the first step contains the actual observation. In the next section, we report the results obtained using our proposals for a large set of yearly time series.
4. Results
To investigate the predictive behavior of our fuzzy methods, also in comparison to standard automatic approaches, we applied them to a set of data from the M4 Competition [8]. This competition contains 100,000 seasonal and nonseasonal time series. The results of the M4 Competition have been globally published for each type of subset of time series, depending on their forecasting horizon.
We worked with the nonseasonal yearly time series. Since our proposals need a number of observations to build the fuzzy variables, a filter was applied to this set of 23,000 yearly series, that is, . We thus obtained a selection of 9060 yearly time series, with a range of observed sizes: [31, 700]. To carry out our study, we used the R language [15], applying various R functions in conjunction with some functions written by the authors.
For the comparison, we followed the specifications established for the M4 Competition and computed forecasts up to six steps ahead. Initially, until 31 May 2018, only the training set was available, but, once it was finished, the values to be forecasted were published in the R package M4comp2018. We also selected two automatic forecasting procedures available in the R package forecast, exponential smoothing (es) and auto.arima [9], for the comparison of both ex-post predictions and coverage of the prediction intervals. We also compared the average computational cost of obtaining these forecasts.
For every model and each time series, for , the prediction errors were measured as follows:
being the forecast at h steps-ahead applying the method and being the observation at time . The mean absolute percentage error (MAPE) and the symmetric mean absolute percentage error (sMAPE) were employed to measure forecasting accuracy, respectively:
For the comparison of the prediction intervals, wed use their empirical coverage, that is, the percentage of times that the observation in included in those intervals.
4.1. Prediction Intervals
Table 2 shows the results of the empirical coverage obtained by applying the different methods at each h-step ahead, denoted as , for , on the scale [0,1], for the 9060 yearly time series. Note that the nominal coverage is established in 80% and 95%, respectively. The last column shows the mean of the empirical coverage, as a percentage.
The results in Table 2 show that the prediction intervals provided by the FFM method are wider than those provided by FFkM method, while the coverage of the prediction intervals provided by FFkM is closer to that provided by exponential smoothing. The ARIMA procedure provided prediction intervals with lower empirical coverage.
The computational time was calculated in milliseconds for every run, that is, the elapsed time from when time series data were read until the six ex-post forecasts were given. Table 3 shows the descriptive statistics of the computing time for each method.
Concerning the computational cost, the new fuzzy proposals are much more competitive than the automatic forecasting procedures. The average time consumed for each run favors the FFM method, although the FFkM method reported better empirical coverage for the prediction intervals.
4.2. Pointwise Forecasts
For the predictive analysis of the performance of a forecasting method, it is also important to verify the accuracy of the out-of-sample forecasts. Table 4 shows the averaged post-sample accuracy of the forecasts obtained for the aforementioned methods, both using MAPE and sMAPE prediction errors. These results are consistent with the best performance of our proposed fuzzy forecast methods, at least with respect to forecasting accuracy. The forecasting errors were calculated for each forecasting horizon (1–6 steps ahead) and for the aggregated periods.
The results concerning the accuracy of the ex-post forecasts are consistent with the best performance of our proposed fuzzy forecast methods. It must also be noted that the FFkM method obtained the best results at every step for the averaged MAPE and sMAPE, and it provided these accurate ex-post forecasts in a very competitive computation time.
In addition, a statistical pairwise comparison of the MAPE errors was performed, using the Wilcoxon nonparametric test and adjusting the p-values by Holm’s method. All comparisons were statistically significant (adjusted p-values not greater than 0.012) except the SE and ARIMA comparison for the second-step-ahead forecast (p value = 0.32).
The statistical differences and homogeneities using sMAPE follow similar patterns to those of averaged MAPE. We also found analogous results when averaged ex-post forecast errors were compared using parametric methods.
5. Conclusions
In this paper, we introduce a new forecasting scheme based on fuzzy variables and credibility distributions of the first and upper differences of the data series. Our fuzzy forecasting methods enable us to obtain accurate pointwise forecasts and reliable prediction intervals for nonseasonal time series. Our methods also provide LR-power fuzzy variables as ex-post fuzzy forecasts.
Our approach was tested using yearly time series from the M4 Competition. Concerning the out-of-sample performance of the point forecast in comparison with automatic forecasting packages, we obtained a competitive accuracy with the lowest computation time, for a set of 9060 time series.
Statistical pairwise comparison was used to compare the averaged forecasting errors, showing significant differences between the averaged MAPE and sMAPE forecast errors of our fuzzy methods and the other automatic forecasting methods included in the experiment.
In further studies, we will analyze the performance of our proposed techniques on other type of time series. Those studies could also focus on the analysis of other fuzzy strategies to improve the detection of trend changes, using the upper differences between observed data.
Author Contributions
Conceptualization, J.D.B. and E.V.; methodology, J.D.B., A.R. and E.V.; software, A.R.; validation, J.D.B., A.R. and E.V.; formal analysis, E.V.; investigation, A.R.; resources, A.R.; data curation, A.R.; writing—original draft preparation, E.V.; writing—review and editing, E.V.; supervision, J.D.B.; project administration, J.D.B.; and funding acquisition, J.D.B. and E.V. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Spanish Ministry of Economy and Competitiveness (Project MTM2017-83850-P), co-financed by FEDER funds.
Data Availability Statement
Datasets available in: Montero-Manso, P., Netto, C. & Talagala, C. (2018). M4comp2018: Data from the M4-Competition. R package version 0.1.0.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, B. A survey of credibility theory. Fuzzy Optim. Decis. Mak. 2006, 5, 387–408. [Google Scholar] [CrossRef]
- Vercher, E.; Bermúdez, J.D. Portfolio optimization using a credibility mean-absolute semi-deviation model. Expert Syst. Appl. 2015, 42, 7121–7131. [Google Scholar] [CrossRef]
- Ruiz, A.B.; Saborido, R.; Bermúdez, J.D.; Luque, M.; Vercher, E. Preference-based evolutionary multi-objective optimization for portfolio selection: A new credibilistic model under investor preferences. J. Glob. Optim. 2020, 76, 295–315. [Google Scholar] [CrossRef]
- Song, Q.; Chissom, B.S. Fuzzy time series and its models. Fuzzy Sets Syst. 1993, 54, 269–277. [Google Scholar] [CrossRef]
- Wang, L.; Liu, X.; Pedrycz, W.; Shao, Y. Determination of temporal information granules to improve forecasting in fuzzy time series. Expert Syst. Appl. 2014, 41, 3134–3142. [Google Scholar] [CrossRef]
- Chen, S.-M. Forecasting enrollments based on fuzzy time series. Fuzzy Sets Syst. 1996, 81, 311–319. [Google Scholar] [CrossRef]
- Rubio, A.; Bermúdez, J.D.; Vercher, E. Improving stock index forecasts by using a new weighted fuzzy-trend time series method. Expert Syst. Appl. 2017, 76, 12–20. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 competition: Results, findings, conclusion and way forward. Int. J. Forecast. 2018, 34, 802–808. [Google Scholar] [CrossRef]
- Hyndman, R.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar]
- Zadeh, L. Probability measures of fuzzy events. J. Math. Anal. Appl. 1968, 23, 421–427. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Liu, Y.-K. Expected value of fuzzy variable and fuzzy expected value models. IEEE Trans. Fuzzy Syst. 2002, 10, 445–450. [Google Scholar]
- León, T.; Vercher, E. Solving a class of fuzzy linear programs by using semi-infinite programming techniques. Fuzzy Sets Syst. 2004, 146, 235–252. [Google Scholar] [CrossRef]
- Singh, S. A computational method of forecasting based on fuzzy time series. Math. Comput. Simul. 2008, 79, 539–554. [Google Scholar] [CrossRef]
- Stevenson, M.; Porter, J. Fuzzy time series forecasting using percentage change as the universe of discourse. World Acad. Sci. Eng. Technol. 2009, 55, 154–157. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
Figure 1.
Function of the LR-power fuzzy variable . The small circles represent the elements of the set .
Figure 1.
Function of the LR-power fuzzy variable . The small circles represent the elements of the set .

Figure 2.
Membership functions of the LR-power fuzzy variables and . The solid line shows , while the dashed line is for .
Figure 2.
Membership functions of the LR-power fuzzy variables and . The solid line shows , while the dashed line is for .


{kind=link}
{kind=link}
Table 1.
Pointwise h-step-ahead forecasts obtained by applying the FF3M method, 90% prediction intervals and prediction errors, for h = 1, 2, 3.
Table 1.
Pointwise h-step-ahead forecasts obtained by applying the FF3M method, 90% prediction intervals and prediction errors, for h = 1, 2, 3.
| y(28 + h) | (28 + h) | IP(90%) | Prediction Error | |
|---|---|---|---|---|
| h = 1 | 7587.3 | 7750.3 | [7572.4, 7878.0] | 163.0 |
| h = 2 | 7530.5 | 7831.3 | [7568.4, 8053.0] | 300.8 |
| h = 3 | 7261.1 | 7944.0 | [7585.4, 8202.7] | 682.9 |
Table 2.
Comparison of the empirical coverage at each step ahead attained for every method. The last column shows the mean of the coverage as a percentage.
Table 2.
Comparison of the empirical coverage at each step ahead attained for every method. The last column shows the mean of the coverage as a percentage.
| IP(80%) | E.1 | E.2 | E.3 | E.4 | E.5 | E.6 | Mean |
|---|---|---|---|---|---|---|---|
| SE | 0.65 | 0.72 | 0.76 | 0.76 | 0.77 | 0.78 | 74% |
| ARIMA | 0.51 | 0.53 | 0.56 | 0.56 | 0.56 | 0.57 | 55% |
| FFM | 0.66 | 0.79 | 0.89 | 0.92 | 0.93 | 0.94 | 86% |
| FF6M | 0.66 | 0.80 | 0.86 | 0.83 | 0.78 | 0.73 | 78% |
| IP(95%) | |||||||
| SE | 0.81 | 0.87 | 0.89 | 0.89 | 0.88 | 0.89 | 87% |
| ARIMA | 0.49 | 0.56 | 0.65 | 0.68 | 0.69 | 0.72 | 63% |
| FFM | 0.74 | 0.86 | 0.93 | 0.95 | 0.96 | 0.96 | 90% |
| FF6M | 0.74 | 0.87 | 0.93 | 0.91 | 0.86 | 0.83 | 86% |
Table 3.
Statistics of computing times for forecasting the 9060 yearly time series.
| Milliseconds | SE | ARIMA | FFM | FF6M |
|---|---|---|---|---|
| Mean | 10.80 | 80.91 | 0.75 | 2.61 |
| Standard deviation | 27.81 | 53.60 | 17.51 | 2.07 |
| TOTAL TIME | 97,876.75 | 73,3054.9 | 6,788.27 | 23,605.61 |
Table 4.
MAPE and sMAPE for the 9060 time series of yearly data.
| MAPE | E.1 | E.2 | E.3 | E.4 | E.5 | E.6 | Average 1 to 6 |
|---|---|---|---|---|---|---|---|
| SE | 7.70 | 10.80 | 13.44 | 16.48 | 18.80 | 22.05 | 14.88 |
| ARIMA | 8.14 | 11.38 | 13.77 | 16.70 | 18,60 | 22.02 | 15.10 |
| FFM | 7.55 | 10.26 | 12.64 | 15.67 | 17.63 | 20.93 | 14.11 |
| FF6M | 7.55 | 10.08 | 12.14 | 14.86 | 16.53 | 19.67 | 13.47 |
| sMAPE | |||||||
| SE | 7.36 | 9.89 | 12.10 | 14.3 | 16.38 | 18.08 | 13.02 |
| ARIMA | 7.70 | 10.25 | 12.10 | 14.12 | 16.02 | 17.52 | 12.95 |
| FFM | 7.31 | 9.63 | 11.69 | 13.95 | 15.82 | 17.62 | 12.67 |
| FF6M | 7.31 | 9.37 | 11.17 | 13.16 | 14.89 | 16.63 | 12.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Vercher, E.; Rubio, A.; Bermúdez, J.D. Fuzzy Prediction Intervals Using Credibility Distributions . Eng. Proc. 2021, 5, 51. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005051
AMA Style
Vercher E, Rubio A, Bermúdez JD. Fuzzy Prediction Intervals Using Credibility Distributions . Engineering Proceedings. 2021; 5(1):51. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005051
Chicago/Turabian StyleVercher, Enriqueta, Abel Rubio, and José D. Bermúdez. 2021. "Fuzzy Prediction Intervals Using Credibility Distributions " Engineering Proceedings 5, no. 1: 51. https://0-doi-org.brum.beds.ac.uk/10.3390/engproc2021005051