
Gaps in Live Inter-Observer Reliability Testing of Animal Behavior: A Retrospective Analysis and Path Forward


Abstract
:1. Introduction
2. Materials and Methods
2.1. Animal Subjects
2.2. Data Collection
2.3. Training and Reliability Testing Protocols
2.4. Reliability Analysis Using the ZooMonitor App
2.5. Data Analysis
2.6. Ethical Statement
3. Results
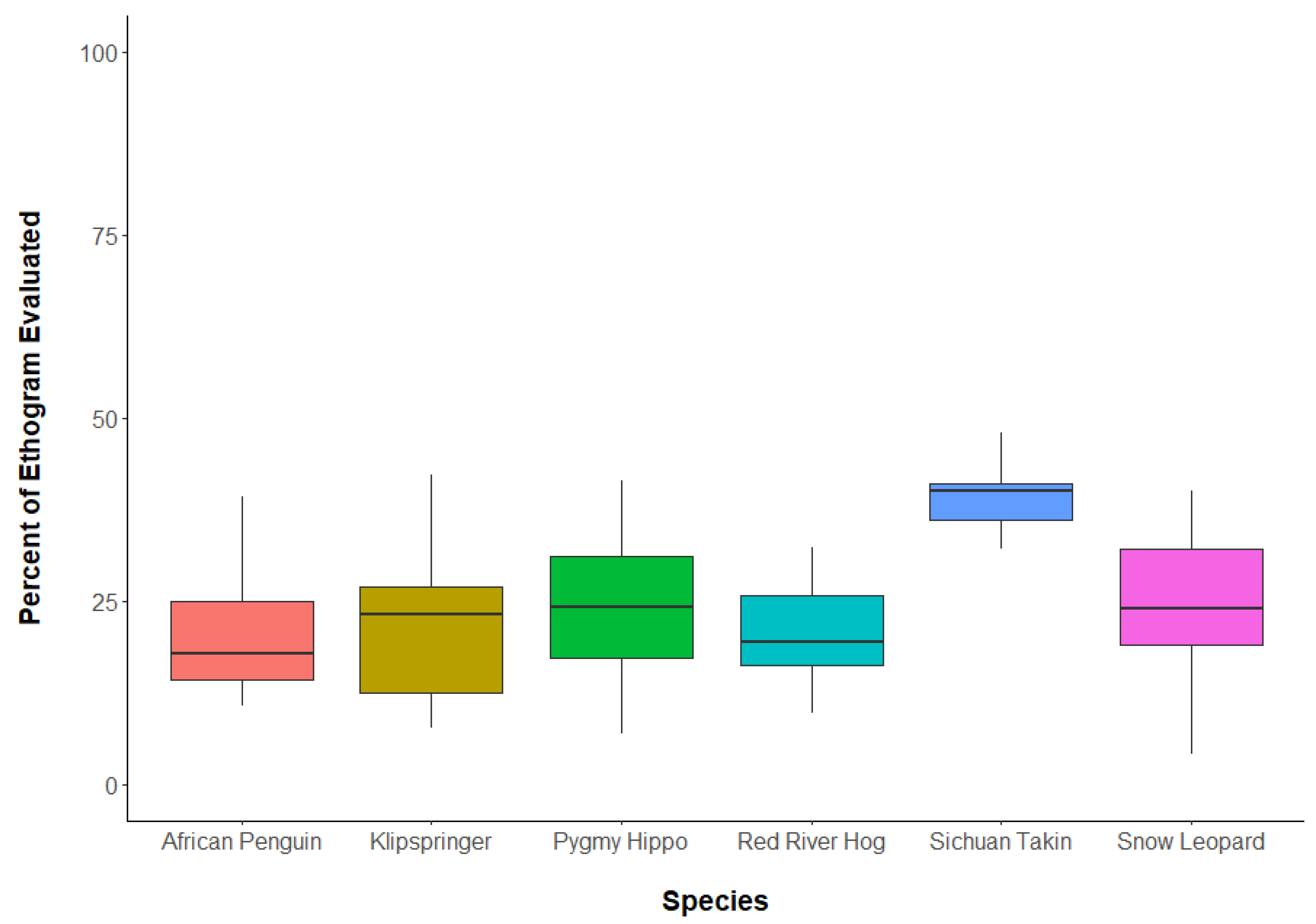
3.1. Question 1: What Percent of Ethograms Occurred during Reliability Tests?
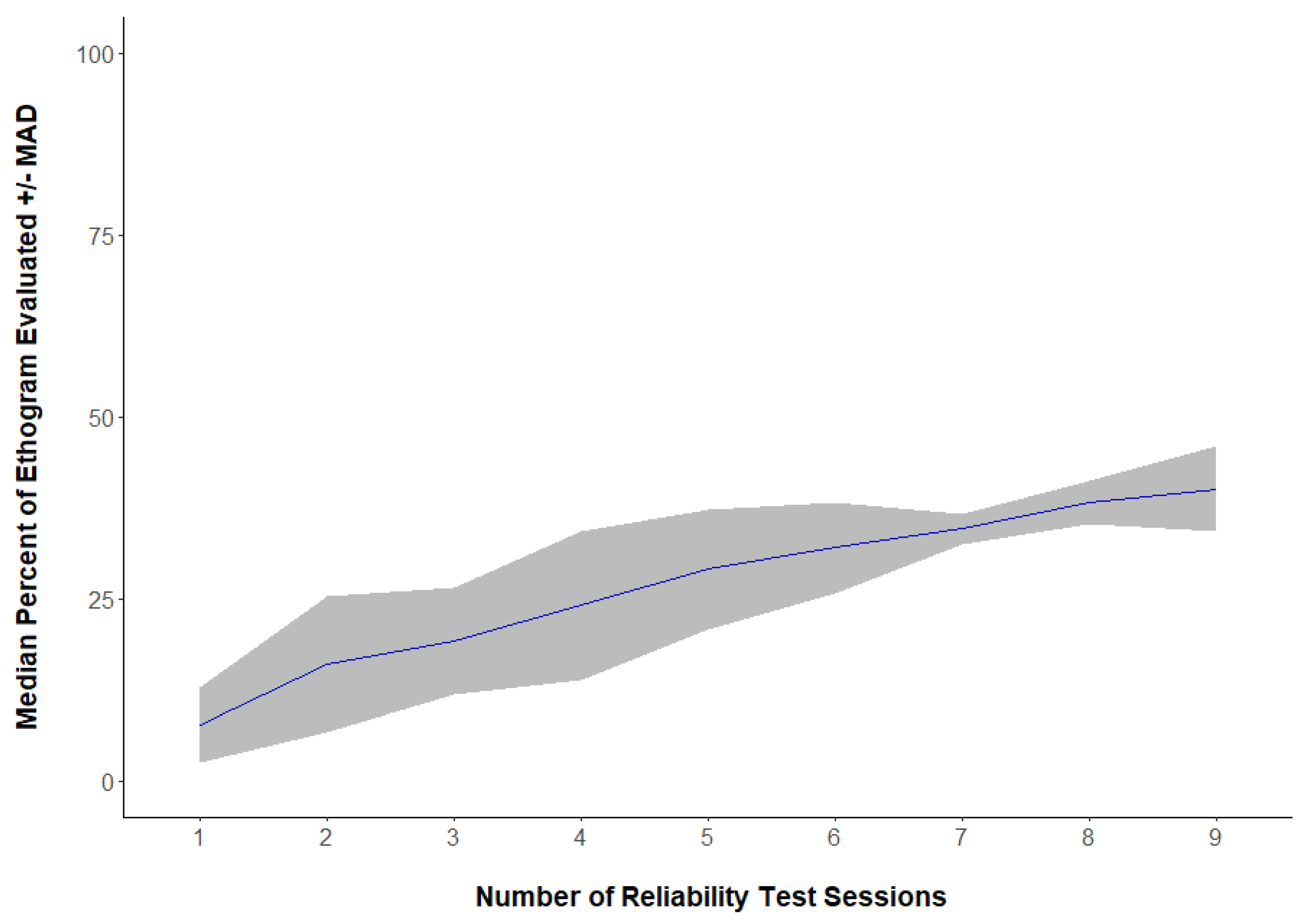
3.2. Question 2: Were a Greater Portion of Ethograms Captured with More Reliability Tests?
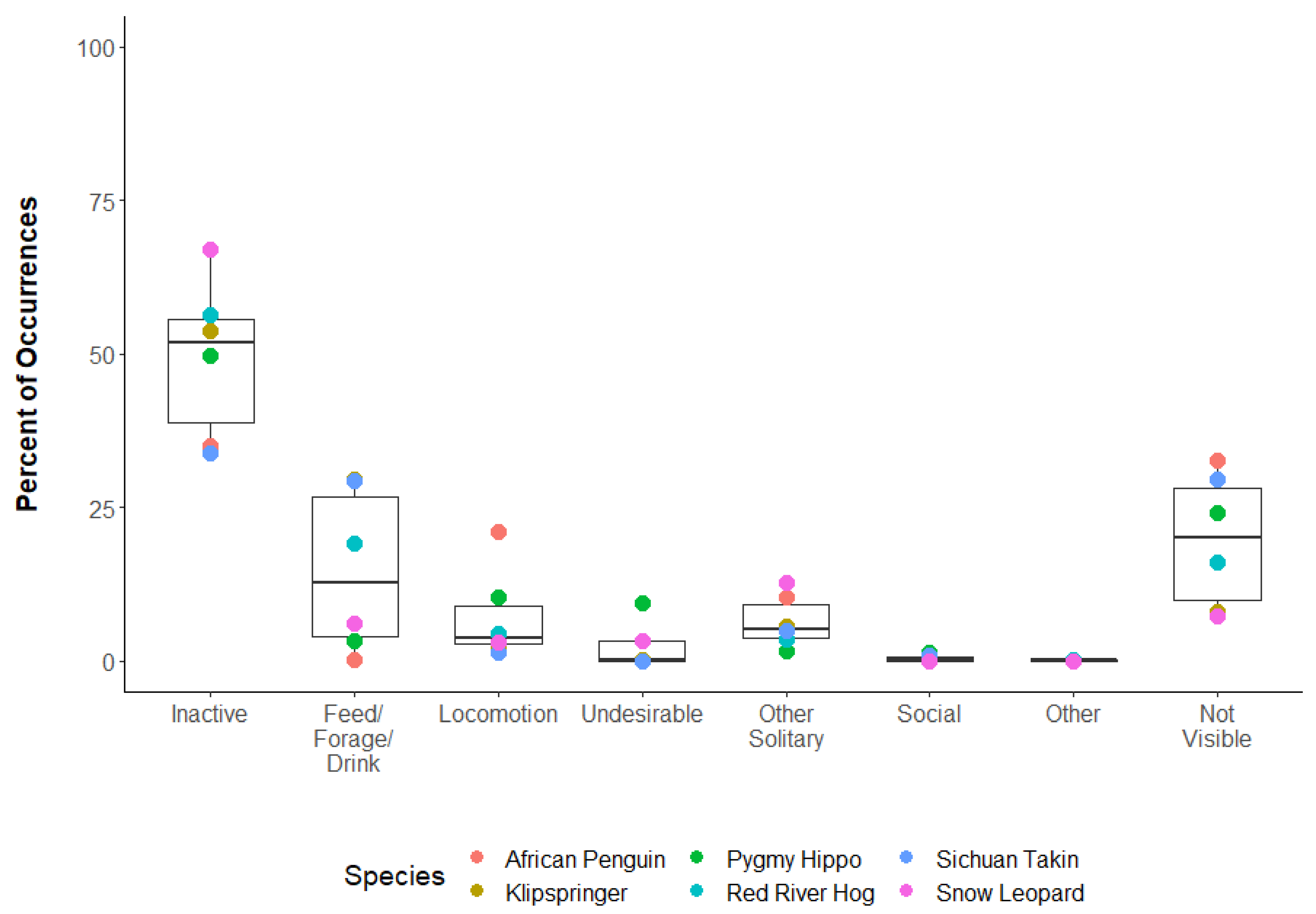
3.3. Question 3: What Behavioral Categories Typically Occurred during Reliability Tests?
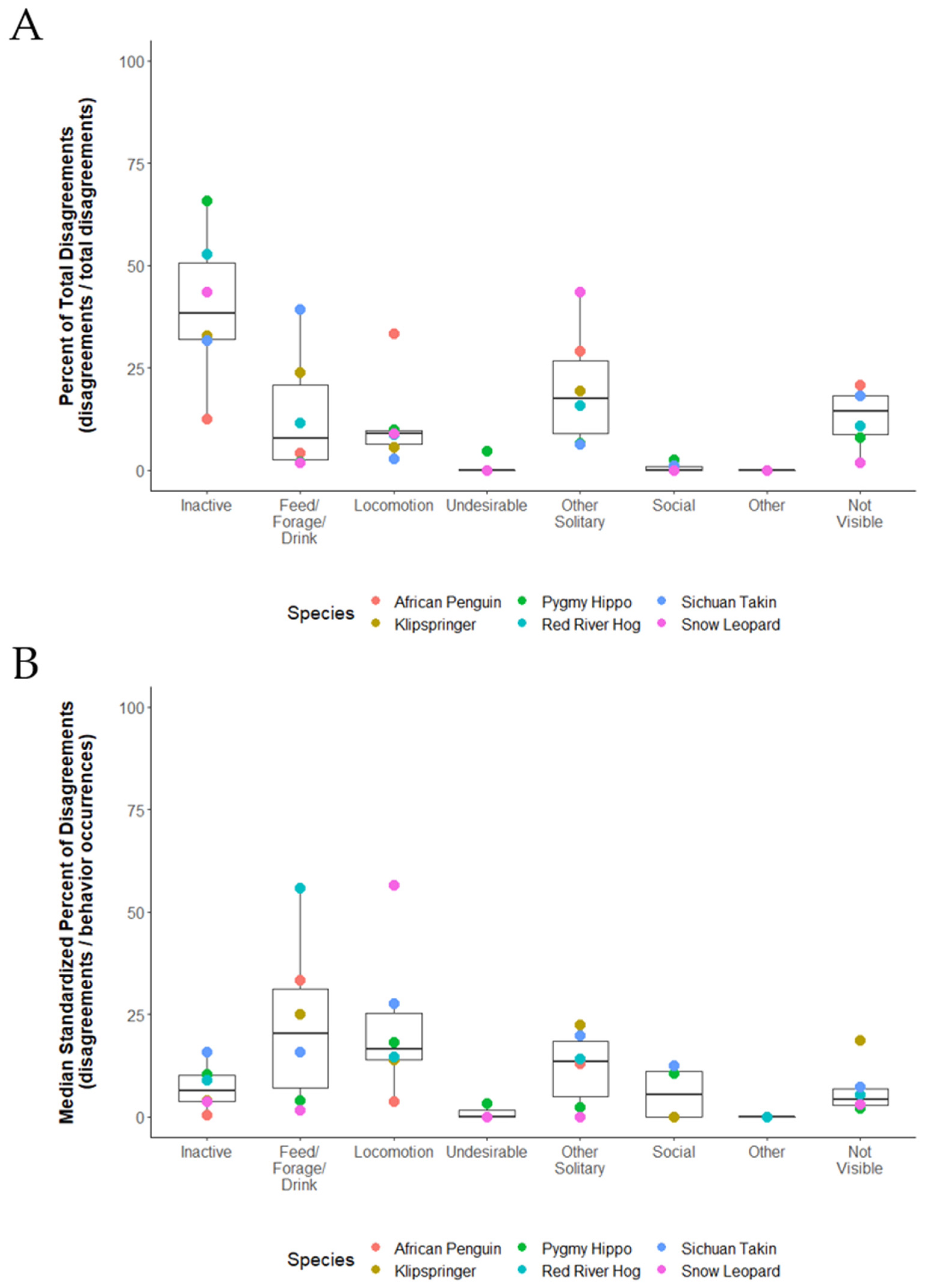
3.4. Question 4: Were Behavior Disagreements Related to How Frequenly Behaviors Occurred?
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kleiman, D.G. Behavior research in zoos: Past, present, and future. Zoo Biol. 1992, 11, 301–312. [Google Scholar] [CrossRef]
- Burkhardt, R.W., Jr. Ethology, natural history, the life sciences, and the problem of place. J. Hist. Biol. 1999, 32, 489–508. [Google Scholar] [CrossRef]
- Crockett, C.M.; Ha, R.R. Data collection in the zoo setting, emphasizing behavior. In Wild Mammals in Captivity: Principles and Techniques for Zoo Management, 2nd ed.; Kleiman, D.G., Thompson, K.V., Baer, C.K., Eds.; The University of Chicago Press: Chicago, IL, USA, 2010; pp. 386–406. [Google Scholar]
- Watters, J.V.; Margulis, S.W.; Atsalis, S. Behavioral monitoring in zoos and aquariums: A tool for guiding husbandry and directing research. Zoo Biol. 2009, 28, 35–48. [Google Scholar] [CrossRef]
- Lincoln Park Zoo. ZooMonitor (Version 3.2) [Mobile Application Software]. 2020. Available online: https://zoomonitor.org (accessed on 23 February 2021).
- Wark, J.D.; Cronin, K.A.; Niemann, T.; Shender, M.A.; Horrigan, A.; Kao, A.; Ross, M.R. Monitoring the behavior and habitat use of animals to enhance welfare using the ZooMonitor app. Anim. Behav. Cogn. 2019, 6, 158–167. [Google Scholar] [CrossRef]
- Saiyed, S.T.; Hopper, L.M.; Cronin, K.A. Evaluating the behavior and temperament of African penguins in a non-contact animal encounter program. Animals 2019, 9, 326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woods, J.M.; Ross, S.R.; Cronin, K.A. The social rank of zoo-housed Japanese macaques is a predictor of visitor-directed aggression. Animals 2019, 9, 316. [Google Scholar] [CrossRef] [Green Version]
- Jacobson, S.L.; Kwiatt, A.C.; Ross, S.R.; Cronin, K.A. The effects of cognitive testing on the welfare of zoo-housed Japanese macaques (Macaca fuscata). Appl. Anim. Behav. Sci. 2019, 212, 90–97. [Google Scholar] [CrossRef]
- Spain, M.S.; Fuller, G.; Allard, S.M. Effects of habitat modifications on behavioral indicators of welfare for Madagascar giant hognose snakes (Leioheterodon madagascariensis). Anim. Behav. Cogn. 2020, 7, 70–81. [Google Scholar] [CrossRef]
- Fazio, J.M.; Barthel, T.; Freeman, E.W.; Garlick-Ott, K.; Scholle, A.; Brown, J.L. Utilizing camera traps, closed circuit cameras and behavior observation software to monitor activity budgets, habitat use, and social interactions of zoo-housed Asian elephants (Elephus maximus). Animals 2020, 10, 2026. [Google Scholar] [CrossRef] [PubMed]
- Eyer, A.E.; Miller, L.J. Evaluating the influence of conspecifics on a male giant anteater’s (Myrmecophaga tridactyla) pacing behavior. Anim. Behav. Cogn. 2020, 7, 556–566. [Google Scholar] [CrossRef]
- Wark, J.D.; Wierzal, N.K.; Cronin, K.A. Mapping shade availability and use in zoo environments: A tool for evaluating thermal comfort. Animals 2020, 10, 1189. [Google Scholar] [CrossRef] [PubMed]
- Dietmar, C.; Romani, T.; Llorente, M.; Kalcher-Sommersguter, E. Assessing the sociability of former pet and entertainment chimpanzees by using multiplex networks. Sci. Rep. 2020, 10, 20969. [Google Scholar] [CrossRef]
- Hansen, B.K.; Hopper, L.M.; Fultz, A.; Ross, S.R. Understanding the behavior of sanctuary-housed chimpanzees during public programs. Anthrozoös 2020, 33, 481–495. [Google Scholar] [CrossRef]
- Lasky, M.; Campbell, J.; Osborne, J.A.; Ivory, E.L.; Lasky, J.; Kendall, C.J. Increasing browse and social complexity can improve zoo elephant welfare. Zoo Biol. 2021, 40, 9–19. [Google Scholar] [CrossRef] [PubMed]
- Ramont, M.; Leahy, M.; Cronin, K.A. Domestic animal welfare at the zoo: The impact of an animal visitor interaction program on chickens. Anim. Behav. Cogn. 2021, 8, 1–14. [Google Scholar] [CrossRef]
- Wolfensohn, S.; Shotton, J.; Bowley, H.; Davies, S.; Thompson, S.; Justice, W.S.M. Assessment of welfare in zoo animals: Towards optimum quality of life. Animals 2018, 8, 110. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dawkins, M.S. Using behaviour to assess animal welfare. Anim. Welf. 2004, 13 (Suppl. 1), S3–S7. [Google Scholar]
- Hill, S.P.; Broom, D.M. Measuring zoo animal welfare: Theory and practice. Zoo Biol. 2009, 28, 531–544. [Google Scholar] [CrossRef] [PubMed]
- Binding, S.; Farmer, H.; Krusin, L.; Cronin, K. Status of animal welfare research in zoos and aquariums: Where are we, where to next? J. Zoo Aquarium Res. 2020, 8, 1–9. [Google Scholar] [CrossRef]
- Association of Zoos and Aquariums. The Accreditation Standards and Related Policies. 2021. Available online: https://www.aza.org/accred-materials/ (accessed on 20 February 2021).
- European Association of Zoos and Aquaria. EAZA Standards for the Accommodation and Care of Animals in Zoos and Aquaria. 2020. Available online: https://www.eaza.net/about-us/eazadocuments/ (accessed on 20 February 2021).
- World Association of Zoos and Aquariums. WAZA 2023 Animal Welfare Goal. In Annual Report 2019. p. 13. Available online: https://www.waza.org/publications/ (accessed on 20 February 2021).
- Warsaw, D.; Sayers, J. The influence of animal welfare accreditation programmes on zoo visitor perceptions on the welfare of zoo animals. J. Zoo Aquar. Res. 2020, 8, 188–193. [Google Scholar] [CrossRef]
- Sherwen, S.L.; Hemsworth, L.M.; Beausoleil, N.J.; Embury, A.; Mellor, D.J. An animal welfare risk assessment process for zoos. Animals 2018, 8, 130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kazdin, A.E. Artifact, bias, and the complexity of assessment: The ABCs of reliability. J. Appl. Behav. Anal. 1977, 10, 141–150. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tuyttens, F.A.M.; de Graaf, S.; Heerkens, J.L.T.; Jacobs, L.; Nalon, E.; Ott, S.; Stadig, L.; Van Laer, E.; Ampe, B. Observer bias in animal behaviour research: Can we believe what we score, if we score what we believe? Anim. Behav. 2014, 90, 273–280. [Google Scholar] [CrossRef]
- Burghardt, G.M.; Bartmess-LeVasseur, J.N.; Browning, S.A.; Morrison, K.E.; Stec, C.L.; Zachau, C.E.; Freeberg, T.M. Minimizing observer bias in behavioral Studies: A review and recommendations. Ethology 2012, 118, 511–517. [Google Scholar] [CrossRef]
- Kardish, M.R.; Mueller, U.G.; Amador-Vargas, S.; Dietrich, E.I.; Ma, R.; Barrett, B.; Fang, C.C. Blind trust in unblinded observation in ecology, evolution, and behavior. Front. Ecol. Evol. 2015, 3, 51. [Google Scholar] [CrossRef] [Green Version]
- Tuyttens, F.A.M.; Stadig, L.; Heerkens, J.L.T.; Van Laer, E.; Buijs, S.; Ampe, B. Opinion of applied ethologists on expectation bias, blinding observers and other debiasing techniques. Appl. Anim. Behav. Sci. 2016, 181, 27–33. [Google Scholar] [CrossRef] [Green Version]
- Lehner, P.N. Handbook of Ethological Methods, 2nd ed.; Cambridge University Press: Cambridge, UK, 1996; pp. 210–221. [Google Scholar]
- Munch, K.L.; Wapstra, E.; Thomas, S.; Fisher, M.; Sinn, D.L. What are we measuring? Novices agree amongst themselves (but not always with experts) in their assessment of dog behaviour. Ethology 2019, 125, 203–211. [Google Scholar] [CrossRef]
- Funder, D.C. On the accuracy of personality judgment: A realistic approach. Psychol. Rev. 1995, 102, 652–670. [Google Scholar] [CrossRef] [Green Version]
- Martin, P.; Bateson, P. Measuring Behavior: An Introductory Guide, 3rd ed.; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Jansen, R.G.; Wiertz, L.F.; Meyer, E.S.; Noldus, L.P.J.J. Reliability analysis of observational data: Problems, solutions, and software implementation. Behav. Res. Methods Instrum. Comput. 2003, 35, 391–399. [Google Scholar] [CrossRef]
- Hartmann, D.P. Considerations in the choice of interobserver reliability estimates. J. Appl. Behav. Anal. 1977, 10, 103–116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.r-project.org/ (accessed on 20 February 2021).
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis. Available online: https://CRAN.R-project.org/package=ggplot2/ (accessed on 20 February 2021).
- Sherwen, S.L.; Hemsworth, P.H. The visitor effect on zoo animals: Implications and opportunities for zoo animal welfare. Animals 2019, 9, 366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Caro, T.M.; Roper, R.; Young, M.; Dang, G.R. Inter-observer reliability. Behaviour 1979, 69, 303–315. [Google Scholar] [CrossRef]
- Reid, J.B. Reliability assessment of observation data: A possible methodological problem. Child Dev. 1970, 41, 1143–1150. [Google Scholar] [CrossRef]
- Powell, D.; Speeg, B.; Li, S.; Blumer, E.; McShea, W. An ethogram and activity budget of captive Sichuan takin (Budorcas taxicolor tibetana) with comparisons to other Bovidae. Mammalia 2013, 77, 391–401. [Google Scholar] [CrossRef]
- Farmer, H.; Dayrell, E.; Pullen, K. Encouraging enclosure use for red river hogs using scatter feedings. Shape Enrich. 2006, 15, 11–13. [Google Scholar]
- Sulser, C.E.; Steck, B.L.; Baur, B. Effects of construction noise on behaviour of and exhibit use by snow leopards Uncia at Basel zoo. Int. Zoo Yearb. 2008, 42, 199–205. [Google Scholar] [CrossRef]
- Flacke, G.L.; Chambers, B.K.; Martin, G.B.; Paris, M.C.J. The pygmy hippopotamus Choeropsis liberiensis (Morton, 1849): Bringing to light research priorities for the largely forgotten, smaller hippo species. Zool. Garten 2015, 84, 234–265. [Google Scholar] [CrossRef]
- Figel, T. Activity Budget and Behavior in the African Penguin (Spheniscus demersus). Master’s Thesis, University of Saint Joseph, West Hartford, CT, USA, 20 February 2020. [Google Scholar]
- Wark, J.D.; Cronin, K.A. Expansion of a Behavioral Monitoring App for Multi-Institutional Collaboration at Zoological and Aquarium Institutions (Institute of Museum and Library Services Grant MG-245613-OMS-20). Available online: https://www.imls.gov/grants/awarded/mg-245613-oms-20 (accessed on 20 February 2021).
- Watson, C.F.I.; Buchanan-Smith, H.M. Marmoset Care Website. Available online: http://marmosetcare.com/ (accessed on 23 February 2021).
- Mouse Ethogram: An Ethogram for the Laboratory Mouse. Available online: https://mousebehavior.org/ (accessed on 23 February 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species | No. of Observers Tested | No. of Observer Pairwise Tests | No. of Focal Animal Pairwise Tests |
|---|---|---|---|
| African Penguin | 24 | 86 | 86 |
| Klipspringer | 34 | 128 | 139 |
| Pygmy Hippo | 38 | 159 | 213 |
| Red River Hog | 31 | 111 | 186 |
| Sichuan Takin | 12 | 64 | 136 |
| Snow Leopard | 24 | 100 | 100 |
| Species | Median ± MAD | Min–Max |
|---|---|---|
| African Penguin | 3 ± 0 | 3–6 |
| Klipspringer | 3 ± 0 | 3–11 |
| Pygmy Hippo | 4 ± 1.5 | 3–11 |
| Red River Hog | 3 ± 0 | 3–5 |
| Sichuan Takin 2 | 5 ± 1.5 | 4–9 |
| Snow Leopard | 4 ± 0.7 | 3–6 |
| Species | Inactive | Feed/Forage/Drink | Locomotion | Undesirable | Other Solitary | Social | Other | Not Visible |
|---|---|---|---|---|---|---|---|---|
| African Penguin | 35.1 | 0.4 | 21.1 | 10.5 | 0.1 | 0.2 | 32.6 | |
| Klipspringer | 53.8 | 29.7 | 2.6 | 0.2 | 5.6 | 0.1 | 8.0 | |
| Pygmy Hippo | 49.8 | 3.3 | 10.4 | 9.4 | 1.6 | 1.3 | 0.1 | 24.1 |
| Red River Hog | 56.4 | 19.3 | 4.5 | 0.0 | 3.5 | 0.0 | 0.2 | 16.2 |
| Sichuan Takin | 33.9 | 29.4 | 1.3 | 0.0 | 5.0 | 0.9 | 29.6 | |
| Snow Leopard | 67.1 | 6.3 | 3.1 | 3.4 | 12.9 | 0.0 | 0.0 | 7.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wark, J.D.; Wierzal, N.K.; Cronin, K.A. Gaps in Live Inter-Observer Reliability Testing of Animal Behavior: A Retrospective Analysis and Path Forward. J. Zool. Bot. Gard. 2021, 2, 207-221. https://0-doi-org.brum.beds.ac.uk/10.3390/jzbg2020014
Wark JD, Wierzal NK, Cronin KA. Gaps in Live Inter-Observer Reliability Testing of Animal Behavior: A Retrospective Analysis and Path Forward. Journal of Zoological and Botanical Gardens. 2021; 2(2):207-221. https://0-doi-org.brum.beds.ac.uk/10.3390/jzbg2020014
Chicago/Turabian StyleWark, Jason D., Natasha K. Wierzal, and Katherine A. Cronin. 2021. "Gaps in Live Inter-Observer Reliability Testing of Animal Behavior: A Retrospective Analysis and Path Forward" Journal of Zoological and Botanical Gardens 2, no. 2: 207-221. https://0-doi-org.brum.beds.ac.uk/10.3390/jzbg2020014