



Algorithms 2024, 17(5), 176; https://0-doi-org.brum.beds.ac.uk/10.3390/a17050176 (registering DOI) - 25 Apr 2024
Abstract
In the food domain, text mining techniques are extensively employed to derive valuable insights from large volumes of text data, facilitating applications such as aiding food recalls, offering personalized recipes, and reinforcing food safety regulation. To provide researchers and practitioners with a comprehensive
[...] Read more.
In the food domain, text mining techniques are extensively employed to derive valuable insights from large volumes of text data, facilitating applications such as aiding food recalls, offering personalized recipes, and reinforcing food safety regulation. To provide researchers and practitioners with a comprehensive understanding of the latest technology and application scenarios of text mining in the food domain, the pertinent literature is reviewed and analyzed. Initially, the fundamental concepts, principles, and primary tasks of text mining, encompassing text categorization, sentiment analysis, and entity recognition, are elucidated. Subsequently, an analysis of diverse types of data sources within the food domain and the characteristics of text data mining is conducted, spanning social media, reviews, recipe websites, and food safety reports. Furthermore, the applications of text mining in the food domain are scrutinized from the perspective of various scenarios, including leveraging consumer food reviews and feedback to enhance product quality, providing personalized recipe recommendations based on user preferences and dietary requirements, and employing text mining for food safety and fraud monitoring. Lastly, the opportunities and challenges associated with the adoption of text mining techniques in the food domain are summarized and evaluated. In conclusion, text mining holds considerable potential for application in the food domain, thereby propelling the advancement of the food industry and upholding food safety standards.
Full article
(This article belongs to the Special Issue Machine Learning Algorithms and Optimization in the Digital Transition)
►
Show Figures
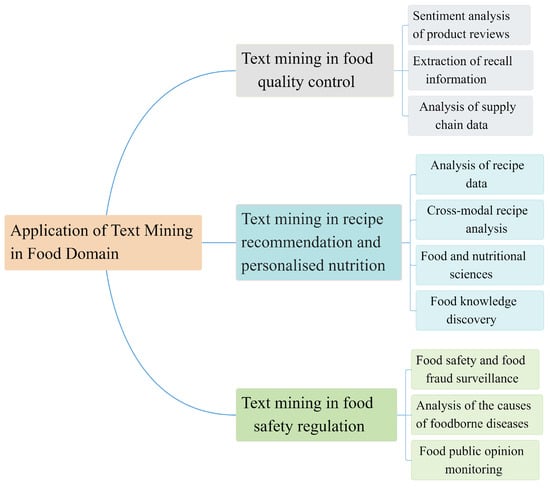
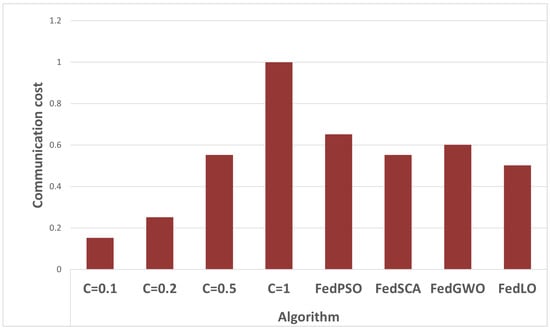
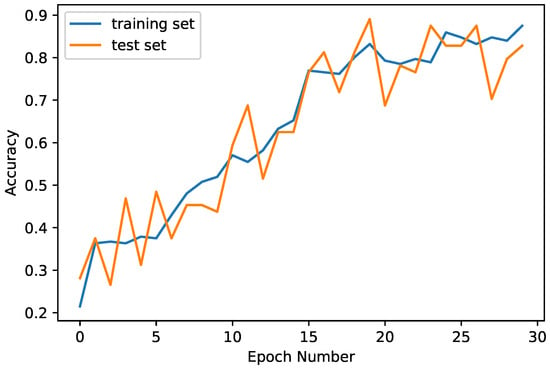
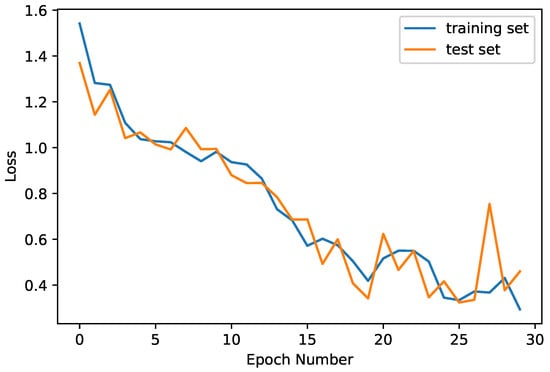
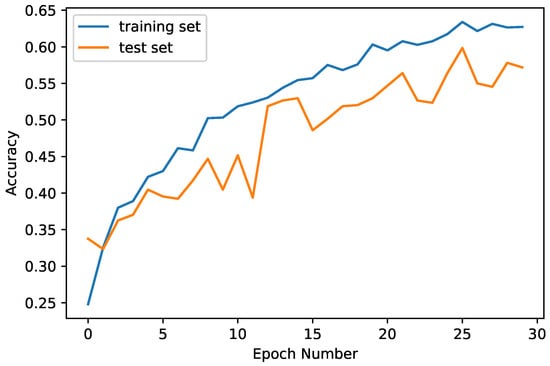
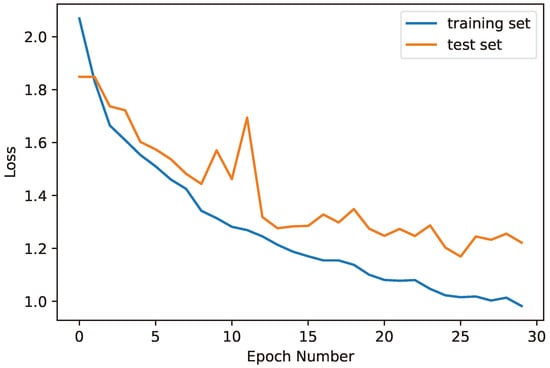
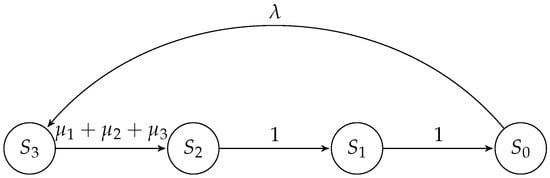
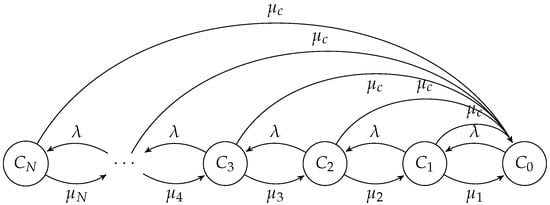
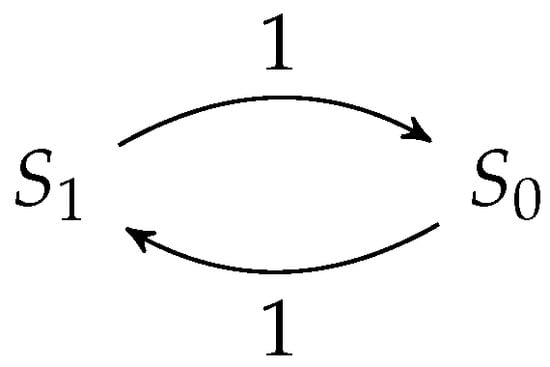
Figure 1








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}