
Green Multi-Platform Solution for the Quantification of Levodopa Enantiomeric Excess in Solid-State Mixtures for Pharmacological Formulations



Abstract
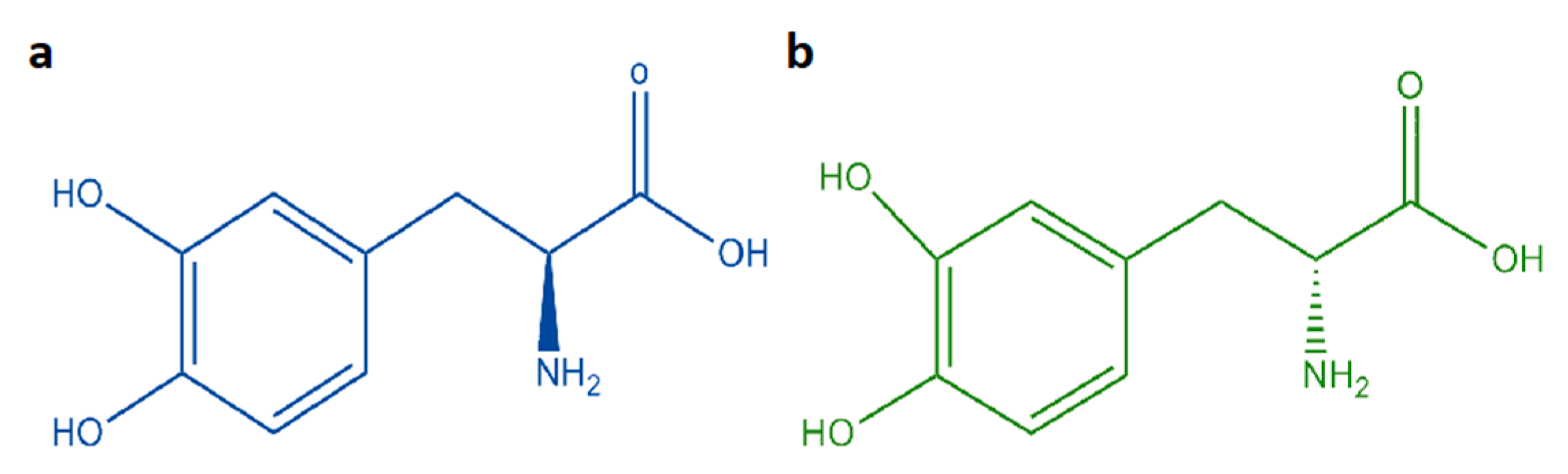
:1. Introduction
2. Results and Discussion
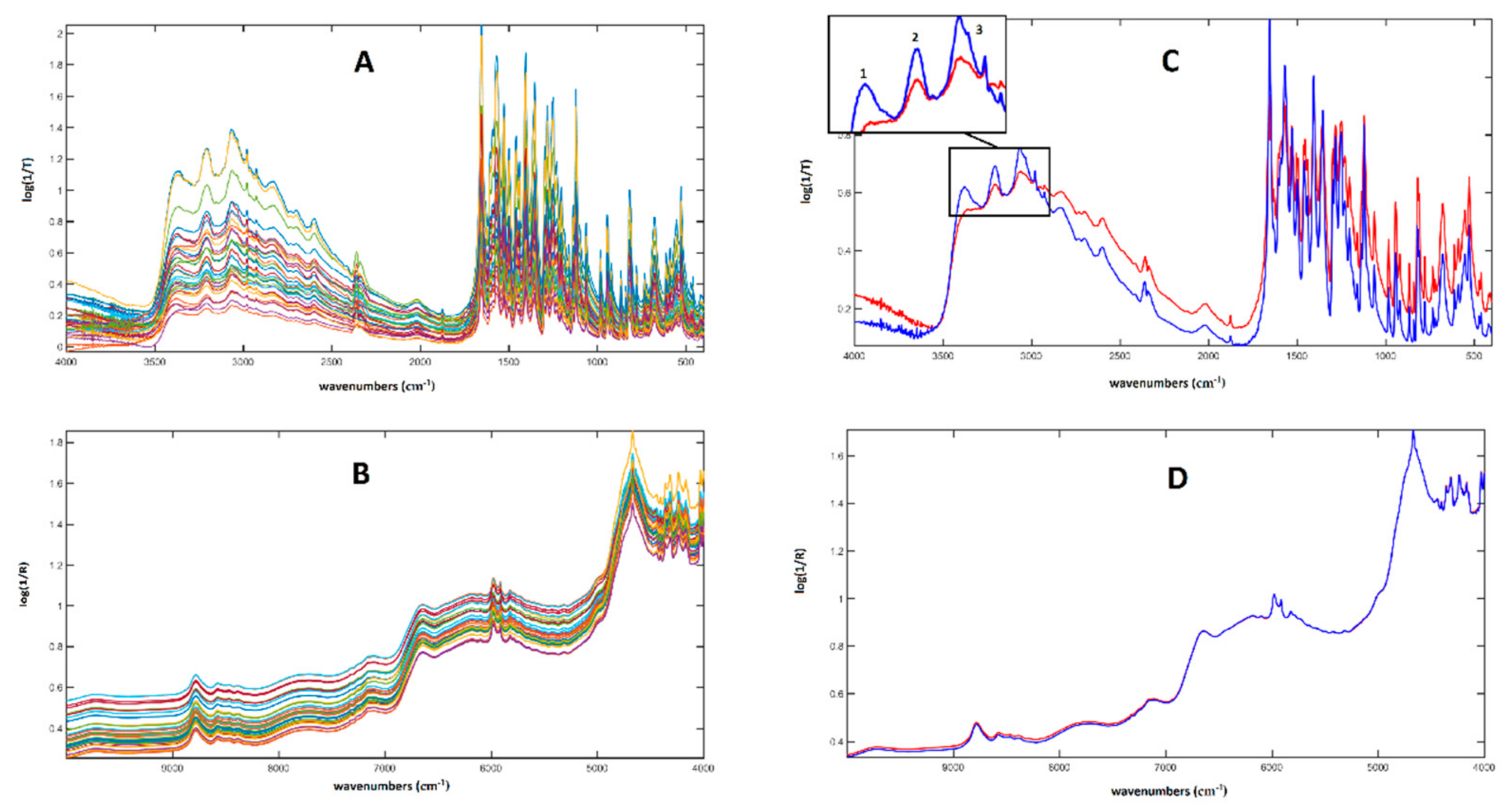
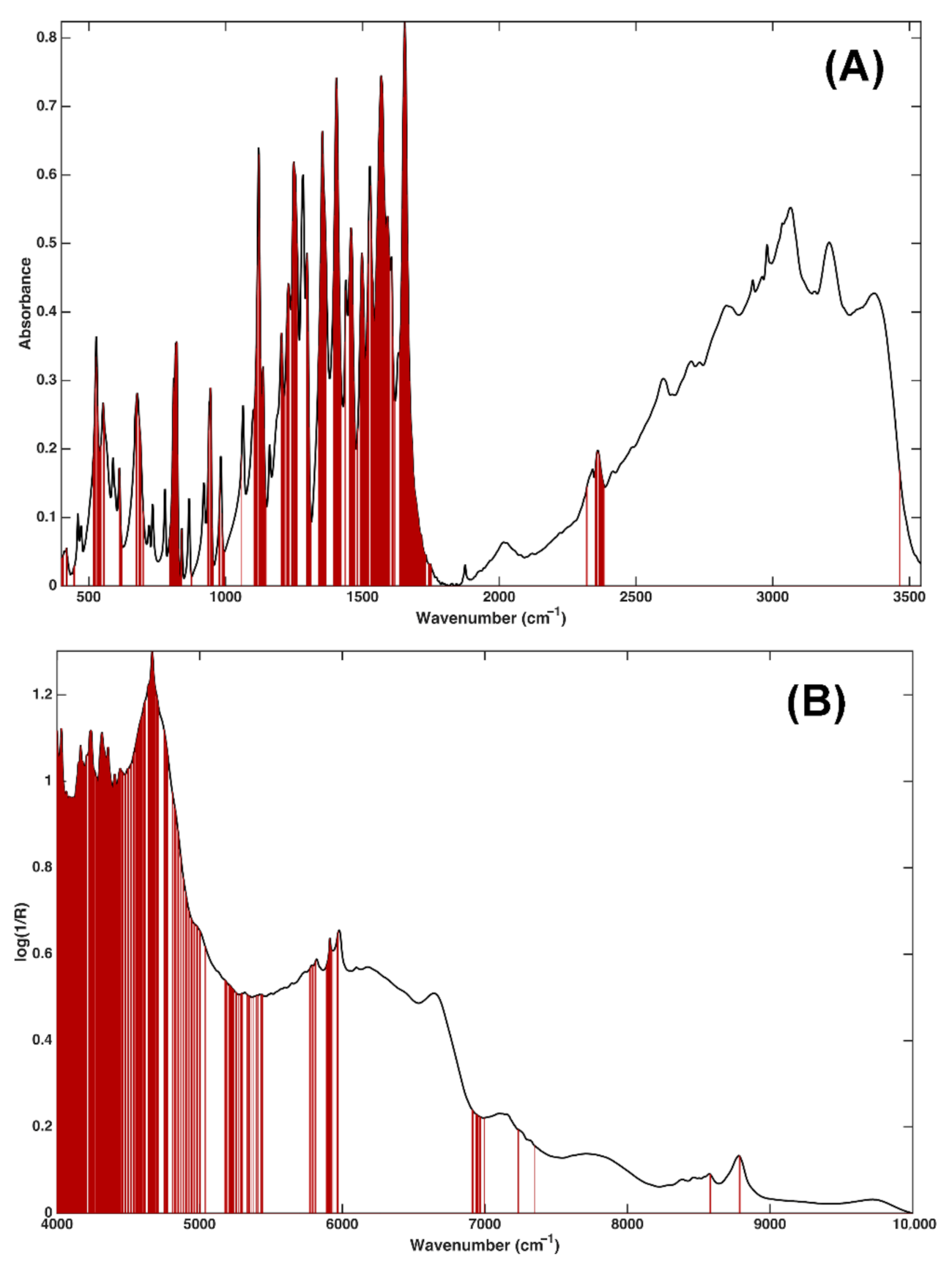
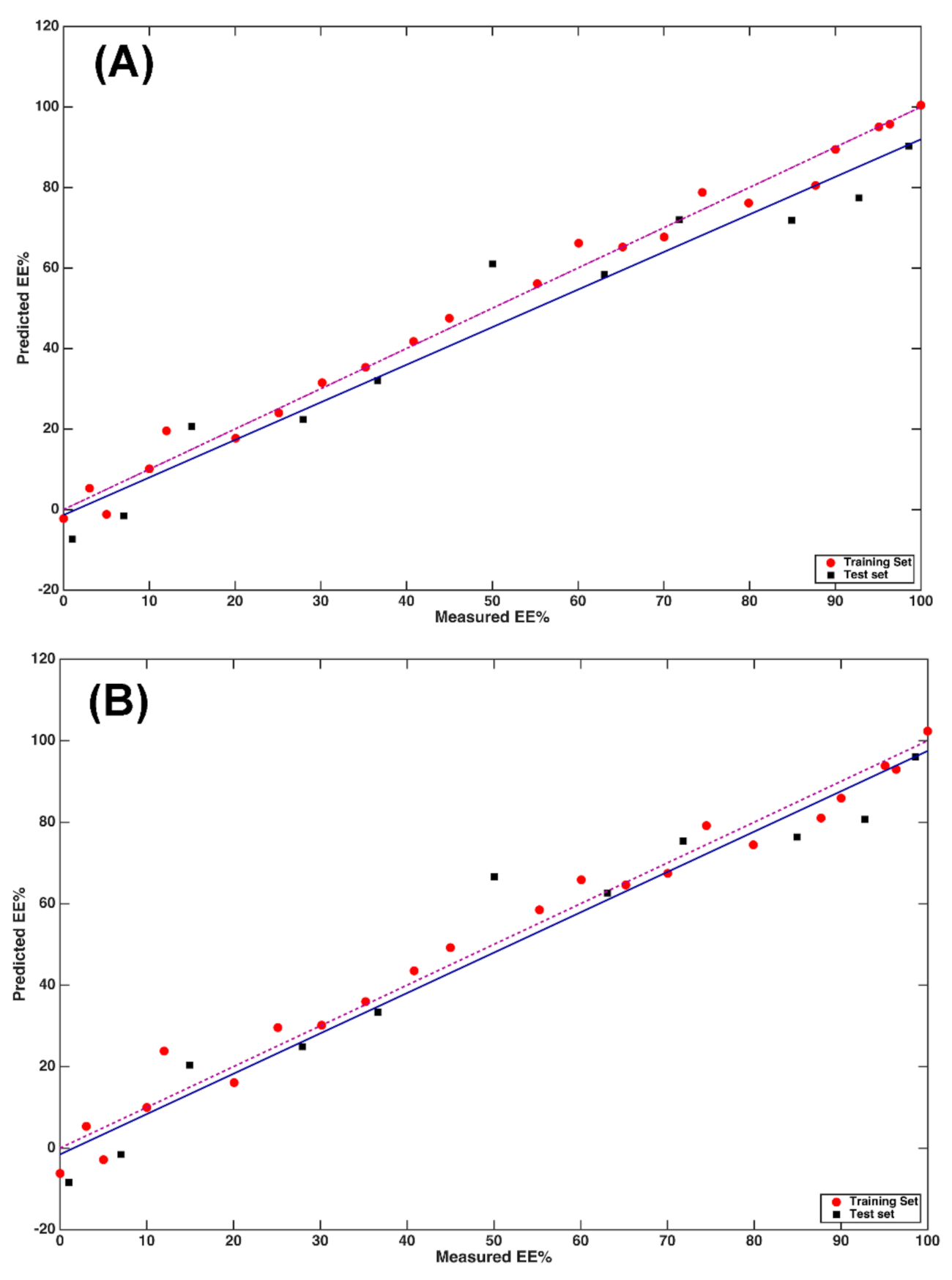
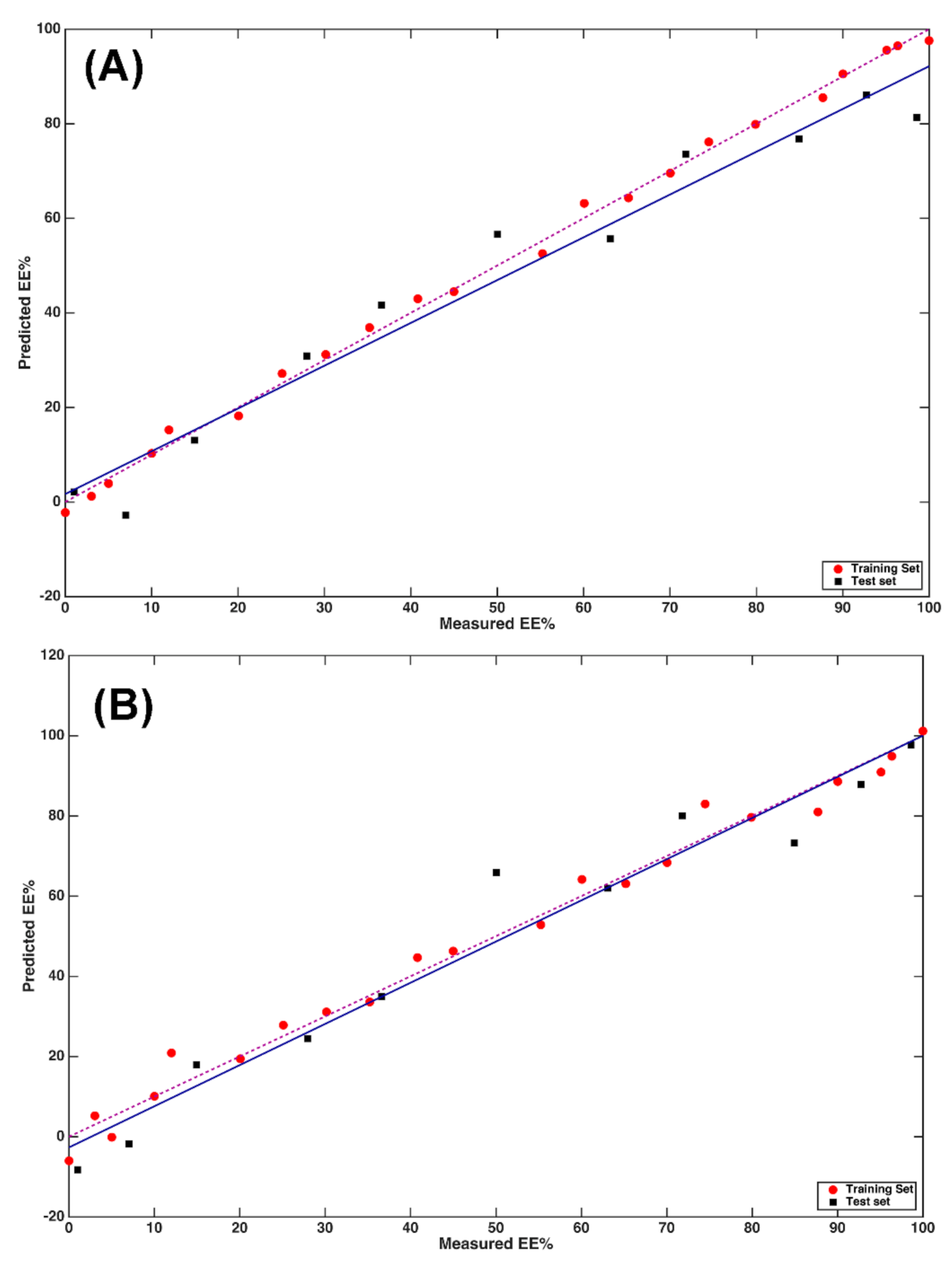
2.1. MIR and NIR Single Block Analysis
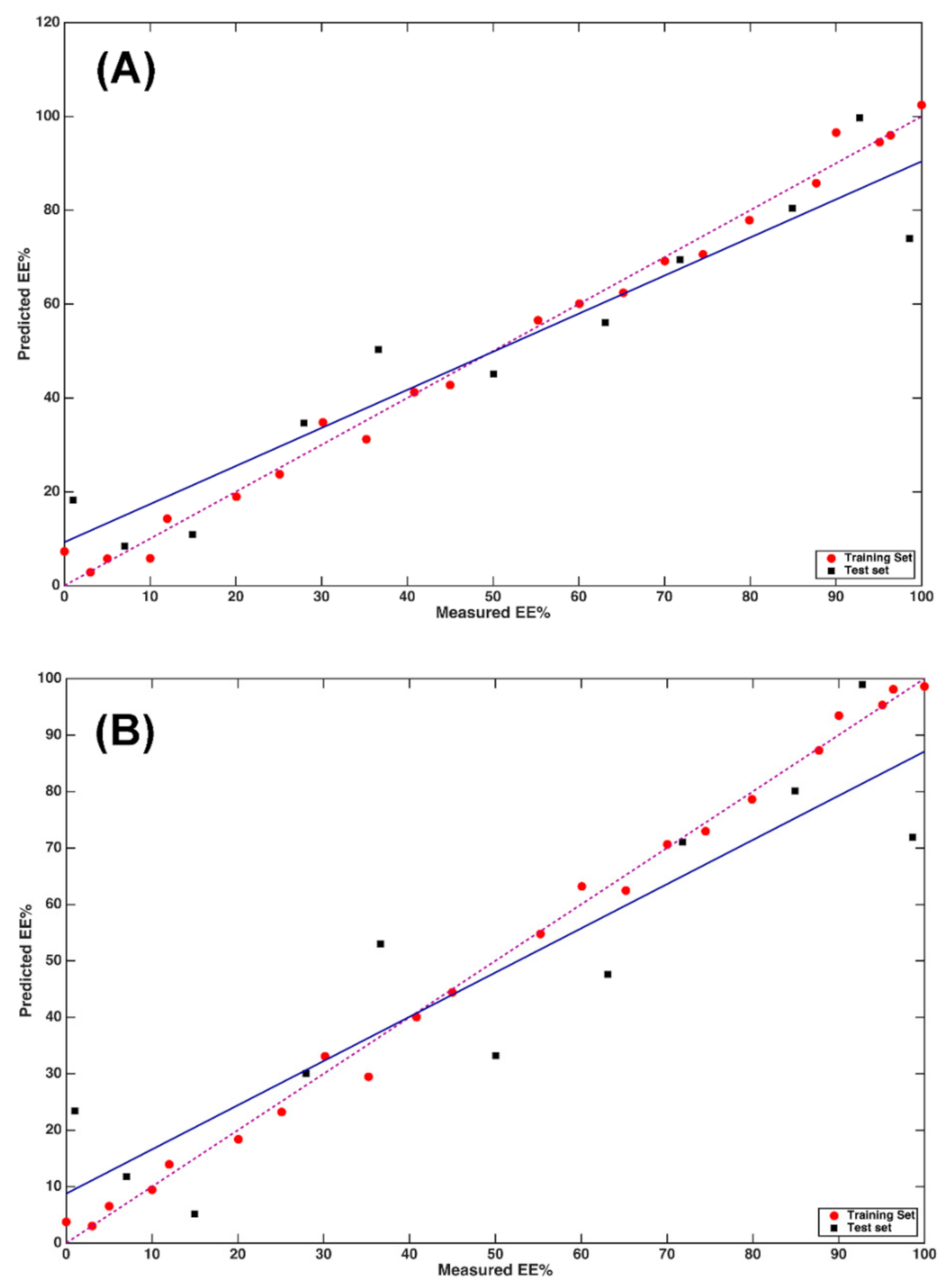
2.2. Multi-Block Analysis
3. Materials and Methods
3.1. Sample Preparation
3.2. Spectroscopic Analysis
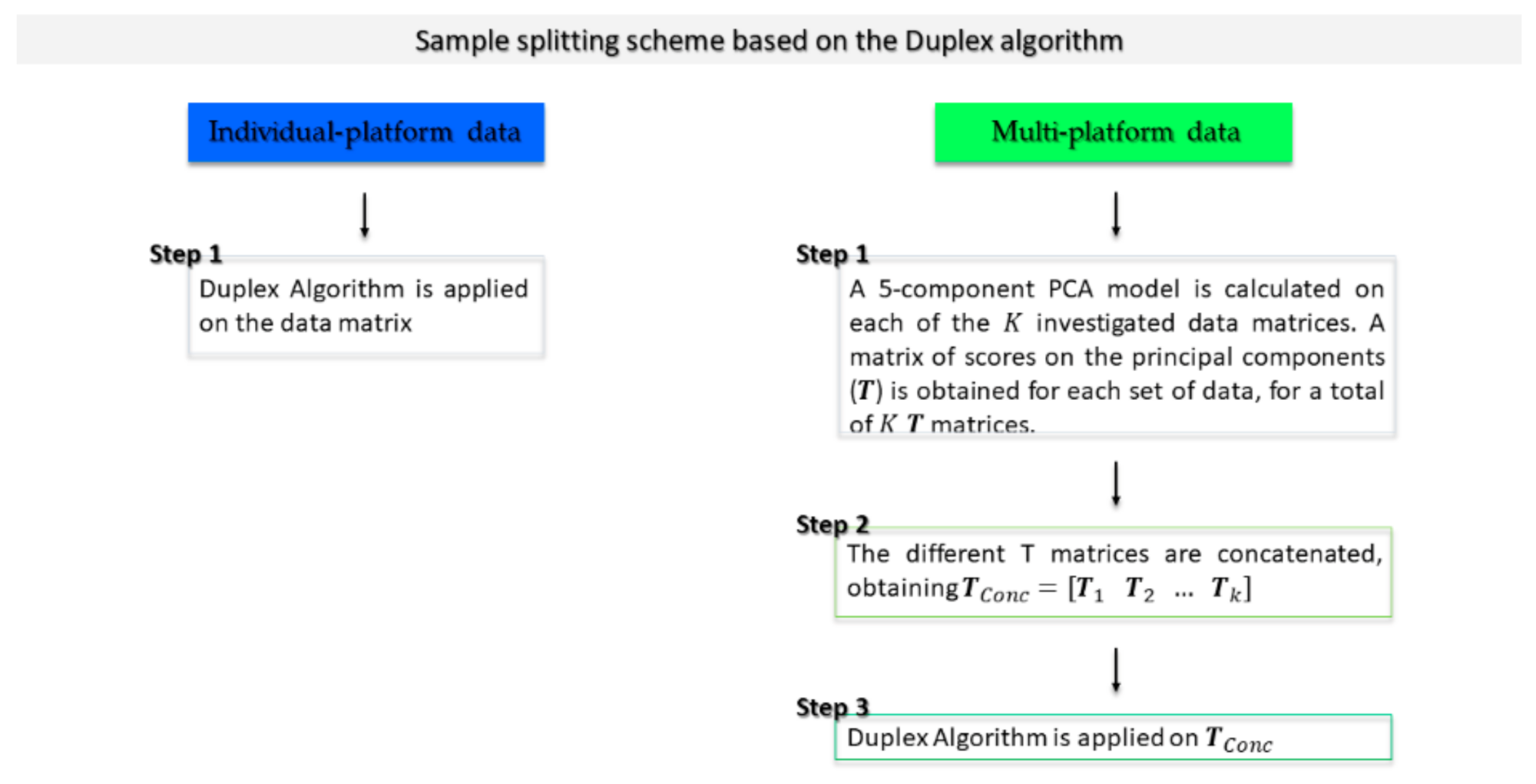
3.3. Multivariate Regression Methods
3.3.1. Partial Least Squares (PLS)
3.3.2. Sequential and Orthogonalized Partial Least Squares (SO-PLS)
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Sample Availability
References
- Editorial: Dopa decarboxylase inhibitors. Br. Med. J. 1974, 4, 250–251. [CrossRef] [Green Version]
- Caner, H.; Groner, E.; Levy, L.; Agranat, I. Trends in the development of chiral drugs. Drug Discov. Today 2004, 9, 105–110. [Google Scholar] [CrossRef]
- Council of Europe. European Pharmacopoeia, 3rd ed.; Council of Europe: Strasbourg, France, 1996. [Google Scholar]
- Armstrong, D.W.; Han, S.M.; Hinze, W.L. Enantiomeric Separations in Chromatography. CRC Crit. Rev. Anal. Chem. 1988, 19, 175–224. [Google Scholar] [CrossRef]
- Dolezalová, M.; Tkaczyková, M. Direct high-performance liquid chromatographic determination of the enantiomeric purity of levodopa and methyldopa: Comparison with pharmacopoeial polarimetric methods. J. Pharm. Biomed. Anal. 1999, 19, 555–567. [Google Scholar] [CrossRef]
- Blanco, M.; Valverde, I. Chiral and non chiral determination of Dopa by capillary electrophoresis. J. Pharm. Biomed. Anal. 2003, 31, 431–438. [Google Scholar] [CrossRef]
- Jacques, J.; Collet, A.; Wilen, S.H. Enantiomers, Racemates and Resolutions; John Wiley & Sons: New York, NY, USA, 1981. [Google Scholar]
- Schlegel, L.B.; Schubert-Zsilavecz, M.; Abdel-Tawab, M. Quantification of active ingredients in semi-solid pharmaceutical formulations by near infrared spectroscopy. J. Pharm. Biomed. Anal. 2017, 142, 178–189. [Google Scholar] [CrossRef]
- De Leersnyder, F.; Peeters, E.; Djalabi, H.; Vanhoorne, V.; Van Snick, B.; Hong, K.; Hammond, S.; Liu, A.Y.; Ziemons, E.; Vervaet, C.; et al. Development and validation of an in-line NIR spectroscopic method for continuous blend potency determination in the feed frame of a tablet press. J. Pharm. Biomed. Anal. 2018, 151, 274–283. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wieser, H.; Antes, S.; Seilmeier, W. Quantitative Determination of Gluten Protein Types in Wheat Flour by Reversed-Phase High-Performance Liquid Chromatography. Cereal Chem. 1998, 75, 644–650. [Google Scholar] [CrossRef]
- Tonolini, M.; Sørensen, K.M.; Skou, P.B.; Ray, C.; Engelsen, S.B. Prediction of α-Lactalbumin and β-Lactoglobulin Composition of Aqueous Whey Solutions Using Fourier Transform Mid-Infrared Spectroscopy and Near-Infrared Spectroscopy. Appl. Spectrosc. 2021, 75, 718–727. [Google Scholar] [CrossRef]
- Haraszi, R.; Chassaigne, H.; Maquet, A.; Ulberth, F. Analytical methods for detection of gluten in food—Method developments in support of food labeling legislation. J. AOAC Int. 2011, 94, 1006–1025. [Google Scholar] [CrossRef]
- Dong, Y.; Sørensen, K.M.; He, S.; Engelsen, S.B. Gum Arabic authentication and mixture quantification by near infrared spectroscopy. Food Control 2017, 78, 144–149. [Google Scholar] [CrossRef]
- Marini, F.; Bucci, R.; Ginevro, I.; Magrì, A.L. Coupling of IR measurements and multivariate calibration techniques for the determination of enantiomeric excess in pharmaceutical preparations. Chemom. Intell. Lab. Syst. 2009, 97, 52–63. [Google Scholar] [CrossRef]
- Rigoni, L.; Venti, S.; Bevilacqua, M.; Bucci, R.; Magrì, A.D.; Magrì, A.L.; Marini, F. Quantification of the enantiomeric excess of two APIs by means of near infrared spectroscopy and chemometrics. Chemom. Intell. Lab. Syst. 2014, 133, 149–156. [Google Scholar] [CrossRef]
- Luner, P.E.; Patel, A.D. Quantifying crystal form content in physical mixtures of (±)-tartaric acid and (+)-tartaric acid using near infrared reflectance spectroscopy. AAPS PharmSciTech 2005, 6, E245–E252. [Google Scholar] [CrossRef] [Green Version]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression: A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Wold, S.; Martens, H.; Wold, H. The Multivariate Calibration Problem in Chemistry Solved by the PLS Method. In Matrix Pencils. Lecture Notes in Mathematics, 1st ed.; Kågström, B., Ruhe, A., Eds.; Springer: Berlin/Heidelberg, Germany, 1983; Volume 973, pp. 286–293. [Google Scholar]
- Biancolillo, A.; Boqué, R.; Cocchi, M.; Marini, F. Data Fusion Strategies in Food Analysis. In Data Handling in Science and Technology, 1st ed.; Cocchi, M., Ed.; Elsevier B.V.: Amsterdam, The Netherlands, 2019; Volume 31, pp. 271–310. [Google Scholar]
- Næs, T.; Tomic, O.; Mevik, B.-H.; Martens, H. Path modelling by sequential PLS regression. J. Chemom. 2011, 25, 28–40. [Google Scholar] [CrossRef]
- Biancolillo, A.; Næs, T. The Sequential and Orthogonalized PLS Regression for Multiblock Regression: Theory, Examples, and Extensions. In Data Handling in Science and Technology, 1st ed.; Cocchi, M., Ed.; Elsevier B.V.: Amsterdam, The Netherlands, 2019; Volume 31, pp. 157–177. [Google Scholar]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Pinto, L.; Stechi, F.; Breitkreitz, M.C. A simplified and versatile multivariate calibration procedure for multiproduct quantification of pharmaceutical drugs in the presence of interferences using first order data and chemometrics. Microchem. J. 2019, 146, 202–209. [Google Scholar] [CrossRef]
- De Luca, M.; Ioele, G.; Ragno, G. Spectral Data Analysis for a Complex Drug Mixture Containing Altizide, Potassium Canrenoate, and Rescinnamine. J. Appl. Spectrosc. 2021, 87, 1079–1086. [Google Scholar] [CrossRef]
- Li, B.; Casamayou-Boucau, Y.; Calvet, A.; Ryder, A.G. Chemometric approaches to low-content quantification (LCQ) in solid-state mixtures using Raman mapping spectroscopy. Anal. Methods 2017, 9, 6293–6301. [Google Scholar] [CrossRef] [Green Version]
- Biancolillo, A.; Bucci, R.; Magrì, A.L.; Magrì, A.D.; Marini, F. Data-fusion for multiplatform characterization of an italian craft beer aimed at its authentication. Anal. Chim. Acta 2014, 820, 23–31. [Google Scholar] [CrossRef] [PubMed]
- Bajoub, A.; Medina-Rodríguez, S.; Gómez-Romero, M.; Ajal, E.A.; Bagur-González, M.G.; Fernández-Gutiérrez, A.; Carrasco-Pancorbo, A. Assessing the varietal origin of extra-virgin olive oil using liquid chromatography fingerprints of phenolic compound, data fusion and chemometrics. Food Chem. 2017, 215, 245–255. [Google Scholar] [CrossRef] [PubMed]
- Nescatelli, R.; Bonanni, R.C.; Bucci, R.; Magrì, A.L.; Magrì, A.D.; Marini, F. Geographical traceability of extra virgin olive oils from Sabina PDO by chromatographic fingerprinting of the phenolic fraction coupled to chemometrics. Chemom. Intell. Lab. Syst. 2014, 139, 175–180. [Google Scholar] [CrossRef]
- Calvini, R.; Foca, G.; Ulrici, A. Data dimensionality reduction and data fusion for fast characterization of green coffee samples using hyperspectral sensors. Anal. Bioanal. Chem. 2016, 408, 7351–7366. [Google Scholar] [CrossRef]
- Hertrampf, A.; Sousa, R.M.; Menezes, J.C.; Herdling, T. Semi-quantitative prediction of a multiple API solid dosage form with a combination of vibrational spectroscopy methods. J. Pharm. Biomed. Anal. 2016, 124, 246–253. [Google Scholar] [CrossRef] [PubMed]
- Roger, J.-M.; Garcia, S.M.; Cambert, M.; Rondeau-Mouro, C. Multiblock analysis applied to TD-NMR of butters and related products. Appl. Sci. 2020, 10, 5317. [Google Scholar] [CrossRef]
- Mishra, P.; Marini, F.; Brouwer, B.; Roger, J.M.; Biancolillo, A.; Woltering, E.; Echtelt, E.H.-V. Sequential fusion of information from two portable spectrometers for improved prediction of moisture and soluble solids content in pear fruit. Talanta 2021, 223, 121733. [Google Scholar] [CrossRef]
- Picca, A.; Ponziani, F.R.; Calvani, R.; Marini, F.; Biancolillo, A.; Coelho-Junior, H.J.; Gervasoni, J.; Primiano, A.; Putignani, L.; Del Chierico, F.; et al. Gut microbial, inflammatory and metabolic signatures in older people with physical frailty and sarcopenia: Results from the BIOSPHERE study. Nutrients 2020, 12, 65. [Google Scholar] [CrossRef] [Green Version]
- Giannetti, V.; Mariani, M.B.; Marini, F.; Torrelli, P.; Biancolillo, A. Grappa and Italian spirits: Multi-platform investigation based on GC–MS, MIR and NIR spectroscopies for the authentication of the Geographical Indication. Microchem. J. 2020, 157, 104896. [Google Scholar] [CrossRef]
- Calvani, R.; Picca, A.; Landi, G.; Marini, F.; Biancolillo, A.; Coelho-Junior, H.J.; Gervasoni, J.; Persichilli, S.; Primiano, A.; Arcidiacono, A.; et al. A novel multi-marker discovery approach identifies new serum biomarkers for Parkinson’s disease in older people: An EXosomes in PArkiNson Disease (EXPAND) ancillary study. GeroScience 2020, 42, 1323–1334. [Google Scholar] [CrossRef]
- Awhangbo, L.; Bendoula, R.; Roger, J.M.; Béline, F. Multi-block data analysis for online monitoring of anaerobic co-digestion process. Chemom. Intell. Lab. Syst. 2020, 205, 104120. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, S.; Wang, Y.; Zhang, J. Multi-platform integration based on NIR and UV–Vis spectroscopies for the geographical traceability of the fruits of Amomum tsao-ko. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 258, 119872. [Google Scholar] [CrossRef]
- Snee, R.D. Validation of Regression Models: Methods and Examples. Technometrics 1977, 19, 415–428. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Firmani, P.; Nardecchia, A.; Nocente, F.; Gazza, L.; Marini, F.; Biancolillo, A. Multi-block classification of Italian semolina based on Near Infrared Spectroscopy (NIR) analysis and alveographic indices. Food Chem. 2020, 309, 125677. [Google Scholar] [CrossRef]
- López, T.; Bata-García, J.L.; Esquivel, D.; Ortiz-Islas, E.; Gonzalez, R.; Ascencio, J.; Quintana, P.; Oskam, G.; Alvarez-Cervera, F.J.; Heredia-López, F.J.; et al. Treatment of Parkinson’s disease: Nanostructured sol-gel silica-dopamine reservoirs for controlled drug release in the central nervous system. Int. J. Nanomed. 2010, 6, 19–31. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Johansson, E.; Cocchi, M. PLS—Partial least-squares projections to latent structures. In 3D QSAR in Drug Design, Theory, Methods, and Applications, 1st ed.; Kubinyi, H., Ed.; ESCOM Science Publishers B.V.: Leiden, The Netherlands, 1993; pp. 523–550. [Google Scholar]
- Cocchi, M.; Biancolillo, A.; Marini, F. Chemometric Methods for Classification and Feature Selection. In Comprehensive Analytical Chemistry; Jaumot, J., Bedia, C., Tauler, R., Eds.; Elsevier B.V.: Amsterdam, The Netherlands, 2018; Volume 82, pp. 265–299. [Google Scholar]
- Biancolillo, A.; Liland, K.H.; Måge, I.; Næs, T.; Bro, R. Variable selection in multi-block regression. Chemom. Intell. Lab. Syst. 2016, 156, 89–101. [Google Scholar] [CrossRef]
- Biancolillo, A.; Marini, F.; Roger, J.-M. SO-CovSel: A novel method for variable selection in a multiblock framework. J. Chemom. 2020, 34, e3120. [Google Scholar] [CrossRef]
- Biancolillo, A.; Marini, F. Chemometric methods for spectroscopy-based pharmaceutical analysis. Front. Chem. 2018, 6, 576. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MIR Data—Calibration Models | |||
| Model | Preprocessing | LVs | RMSECV |
| Model Ia | Raw data (+MC) | 13 | 18.8 |
| Model IIa | First derivative (+MC) | 8 | 18.3 |
| Model IIIa | Second derivative (+MC) | 9 | 24.3 |
| Model IVa | SNV (+MC) | 9 | 23.4 |
| Model Va | SNV + First derivative (+MC) | 9 | 18.1 |
| Model VIa | SNV + Second derivative (+MC) | 8 | 18.3 |
| NIR Data—Calibration Models | |||
| Model | Preprocessing | LVs | RMSECV |
| Model Ib | Raw data (+MC) | 4 | 32.2 |
| Model IIb | First derivative (+MC) | 3 | 25.5 |
| Model IIIb | Second derivative (+MC) | 6 | 11.5 |
| Model IVb | SNV (+MC) | 3 | 27.7 |
| Model Vb | SNV+ First derivative (+MC) | 3 | 23.6 |
| Model VIb | SNV+ Second derivative (+MC) | 6 | 10.8 |
| N. of Sample | Sample Name | Mass of Racemic DOPA (g) | Mass of l-DOPA (g) | Total Sample Mass (g) | Enantiomeric Excess (%) |
|---|---|---|---|---|---|
| 1 | Dopa 000 | 0.60567 | 0.00000 | 0.60567 | 0.00 |
| 2 | Dopa 001 | 0.61403 | 0.00627 | 0.62030 | 1.01 |
| 3 | Dopa 003 | 0.58243 | 0.01818 | 0.60061 | 3.03 |
| 4 | Dopa 005 | 0.57182 | 0.03014 | 0.60196 | 5.01 |
| 5 | Dopa 007 | 0.55921 | 0.04213 | 0.60134 | 7.01 |
| 6 | Dopa 010 | 0.54491 | 0.06062 | 0.60553 | 10.01 |
| 7 | Dopa 012 | 0.52834 | 0.07202 | 0.60036 | 12.00 |
| 8 | Dopa 015 | 0.51493 | 0.09050 | 0.60543 | 14.95 |
| 9 | Dopa 020 | 0.48431 | 0.12165 | 0.60596 | 20.07 |
| 10 | Dopa 025 | 0.45100 | 0.15118 | 0.60218 | 25.10 |
| 11 | Dopa 028 | 0.43340 | 0.16803 | 0.60143 | 27.94 |
| 12 | Dopa 030 | 0.42269 | 0.18258 | 0.60527 | 30.16 |
| 13 | Dopa 035 | 0.39116 | 0.21281 | 0.60397 | 35.23 |
| 14 | Dopa 037 | 0.38150 | 0.22040 | 0.60190 | 36.62 |
| 15 | Dopa 040 | 0.35759 | 0.24661 | 0.60420 | 40.81 |
| 16 | Dopa 045 | 0.33336 | 0.27181 | 0.60517 | 44.99 |
| 17 | Dopa 050 | 0.30024 | 0.30083 | 0.60107 | 50.05 |
| 18 | Dopa 055 | 0.26983 | 0.33322 | 0.60305 | 55.25 |
| 19 | Dopa 060 | 0.24147 | 0.36331 | 0.60478 | 60.07 |
| 20 | Dopa 063 | 0.22171 | 0.37875 | 0.60046 | 63.08 |
| 21 | Dopa 065 | 0.21067 | 0.39487 | 0.60554 | 65.21 |
| 22 | Dopa 070 | 0.18019 | 0.42144 | 0.60163 | 70.05 |
| 23 | Dopa 072 | 0.16962 | 0.43234 | 0.60196 | 71.82 |
| 24 | Dopa 075 | 0.15354 | 0.44841 | 0.60195 | 74.49 |
| 25 | Dopa 080 | 0.12132 | 0.48260 | 0.60392 | 79.91 |
| 26 | Dopa 085 | 0.09083 | 0.51198 | 0.60281 | 84.93 |
| 27 | Dopa 088 | 0.07411 | 0.52830 | 0.60241 | 87.70 |
| 28 | Dopa 090 | 0.06008 | 0.54253 | 0.60261 | 90.03 |
| 29 | Dopa 093 | 0.04357 | 0.55858 | 0.60215 | 92.76 |
| 30 | Dopa 095 | 0.02961 | 0.57519 | 0.60480 | 95.10 |
| 31 | Dopa 097 | 0.02194 | 0.58238 | 0.60432 | 96.37 |
| 32 | Dopa 099 | 0.00848 | 0.59434 | 0.60282 | 98.59 |
| 33 | Dopa 100 | 0.00000 | 0.60565 | 0.60565 | 100.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Biancolillo, A.; Battistoni, S.; Presutto, R.; Marini, F. Green Multi-Platform Solution for the Quantification of Levodopa Enantiomeric Excess in Solid-State Mixtures for Pharmacological Formulations. Molecules 2021, 26, 4944. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules26164944
Biancolillo A, Battistoni S, Presutto R, Marini F. Green Multi-Platform Solution for the Quantification of Levodopa Enantiomeric Excess in Solid-State Mixtures for Pharmacological Formulations. Molecules. 2021; 26(16):4944. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules26164944
Chicago/Turabian StyleBiancolillo, Alessandra, Stefano Battistoni, Regina Presutto, and Federico Marini. 2021. "Green Multi-Platform Solution for the Quantification of Levodopa Enantiomeric Excess in Solid-State Mixtures for Pharmacological Formulations" Molecules 26, no. 16: 4944. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules26164944