
Flexible Implementation of the Trilinearity Constraint in Multivariate Curve Resolution Alternating Least Squares (MCR-ALS) of Chromatographic and Other Type of Data



Abstract
:1. Introduction
2. Methods
2.1. MCR-ALS Bilinear Method
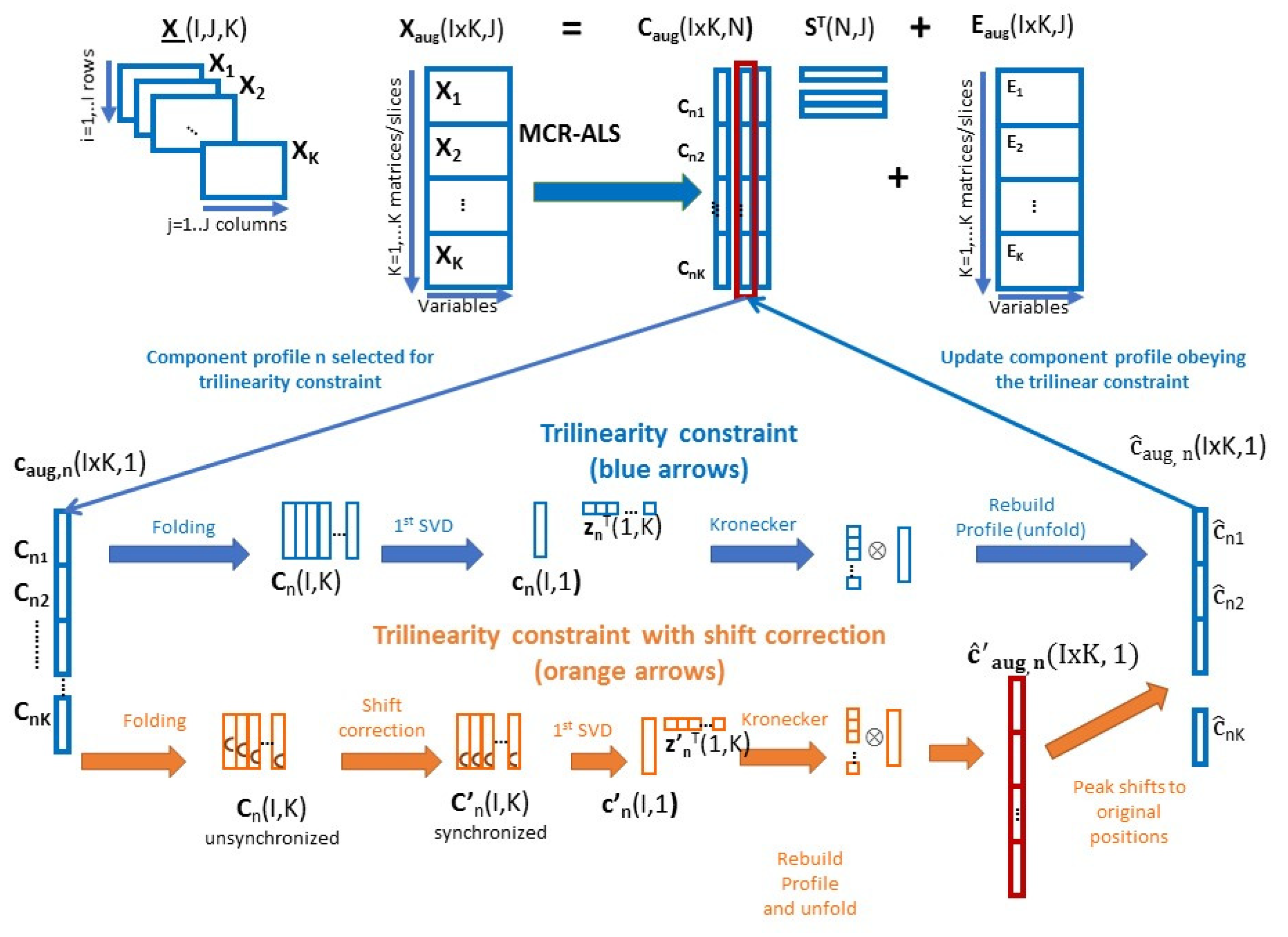
2.2. MCR Trilinear and Mixed Bilinear-Trilinear Methods
2.3. Other Trilinear Methods (ATLD, PARAFAC, PARAFAC2 and DNTD)
2.4. Quality Parameters
2.5. Testing the Adequacy of the Trilinear Model by the Singular Value Decomposition of the Data Matrices Augmented in Their Different Modes
2.6. Software and Calculations
3. Data
3.1. Synthetic LC-DAD Data
3.2. Wine GC-MS Experimental Data
3.3. Flow Injection Analysis (FIA) Experimental Data
4. Results
4.1. Synthetic LC-DAD Dataset
4.2. Wine GC-MS Experimental Dataset
4.3. Flow Injection Analysis (FIA) Experimental Data
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- (1)
- Folding the input augmented profile from current ALS iteration caug,n (IxK,1) ➔ Cn(I, K)
- (2)
- 1st SVD of Cn(I,K) ➔ cn(I,1)znT(1,K)
- (3)
- Kronecker product zn(K,1) cn(I,1) ➔ aug,n(IxK,1)
- (4)
- Updating augmented profile for the considered component n after the application of the trilinearity constraint aug,n(IxK,1)
- (1)
- Folding the augmented profile from current ALS iteration caug,n (IxK1) ➔ Cn(I,K)
- (2)
- Synchronization of Cn (I, K) profiles to have their peak maximum at the same position Cn (I,K) ➔ C’n(I,K)
- (3)
- 1st SVD of C’n (I,K) ➔ c’n (I 1)znT(1,K)
- (4)
- Kronecker product zn(K,1) c’n(I, 1) ➔ aug,n(IxK,1)
- (5)
- Recovering unsynchronized profiles to their original time shifted values. aug,n(IxK,1)➔ aug,n(IxK,1)
- (6)
- Updating augmented profile for the considered component n after the application of the trilinearity constraint and incorporating their time shifted values aug,n(IxK,1)
References
- De Juan, A.; Tauler, R. Multivariate Curve Resolution: 50 years addressing the mixture analysis problem—A review. Anal. Chim. Acta 2021, 1145, 59–78. [Google Scholar] [CrossRef] [PubMed]
- Garrido, M.; Rius, F.X.; Larrechi, M.S. Multivariate curve resolution–alternating least squares (MCR-ALS) applied to spectroscopic data from monitoring chemical reactions processes. Anal. Bioanal. Chem. 2008, 390, 2059–2066. [Google Scholar] [CrossRef] [PubMed]
- Debus, B.; Kirsanov, D.; Ruckebusch, C.; Agafonova-Moroz, M.; Babain, V.; Lumpov, A.; Legin, A. Restoring important process information from complex optical spectra with MCR-ALS: Case study of actinide reduction in spent nuclear fuel reprocessing. Chemom. Intell. Lab. Syst. 2015, 146, 241–249. [Google Scholar] [CrossRef]
- Monago-Maraña, O.; Pérez, R.L.; Escandar, G.M.; Muñoz de la Peña, A.; Galeano-Díaz, T. Combination of Liquid Chromatography with Multivariate Curve Resolution-Alternating Least-Squares (MCR-ALS) in the Quantitation of Polycyclic Aromatic Hydrocarbons Present in Paprika Samples. J. Agric. Food Chem. 2016, 64, 8254–8262. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, X.; Tauler, R. Application of Multivariate Curve Resolution Alternating Least Squares (MCR-ALS) to remote sensing hyperspectral imaging. Anal. Chim. Acta 2013, 762, 25–38. [Google Scholar] [CrossRef] [PubMed]
- Grassi, S.; Alamprese, C.; Bono, V.; Casiraghi, E.; Amigo, J.M. Modelling Milk Lactic Acid Fermentation Using Multivariate Curve Resolution-Alternating Least Squares (MCR-ALS). Food Bioprocess Technol. 2014, 7, 1819–1829. [Google Scholar] [CrossRef]
- Jaumot, J.; Tauler, R.; Gargallo, R. Exploratory data analysis of DNA microarrays by multivariate curve resolution. Anal. Biochem. 2006, 358, 76–89. [Google Scholar] [CrossRef]
- Azzouz, T.; Tauler, R. Application of multivariate curve resolution alternating least squares (MCR-ALS) to the quantitative analysis of pharmaceutical and agricultural samples. Talanta 2008, 74, 1201–1210. [Google Scholar] [CrossRef]
- Marro, M.; Nieva, C.; Sanz-Pamplona, R.; Sierra, A. Molecular monitoring of epithelial-to-mesenchymal transition in breast cancer cells by means of Raman spectroscopy. Biochim. Et Biophys. Acta (BBA)-Mol. Cell Res. 2014, 1843, 1785–1795. [Google Scholar] [CrossRef] [Green Version]
- Alier, M.; Felipe, M.; Hernández, I.; Tauler, R. Trilinearity and component interaction constraints in the multivariate curve resolution investigation of NO and O3 pollution in Barcelona. Anal. Bioanal. Chem. 2011, 399, 2015–2029. [Google Scholar] [CrossRef]
- de Juan, A.; Tauler, R. Chemometrics applied to unravel multicomponent processes and mixtures: Revisiting latest trends in multivariate resolution. Anal. Chim. Acta 2003, 500, 195–210. [Google Scholar] [CrossRef]
- De Juan, A.; Tauler, R. Chapter 8—Data Fusion by Multivariate Curve Resolution. In Data Handling in Science and Technology; Cocchi, M., Ed.; Elsevier: Amsterdam, The Netherlands, 2019; Volume 31, pp. 205–233. [Google Scholar]
- Tauler, R.; Smilde, A.; Kowalski, B. Selectivity, local rank, three-way data analysis and ambiguity in multivariate curve resolution. J. Chemom. 1995, 9, 31–58. [Google Scholar] [CrossRef]
- Tauler, R. Multivariate curve resolution of multiway data using the multilinearity constraint. J. Chemom. 2021, 35, e3279. [Google Scholar] [CrossRef]
- Olivieri, A.C. Recent advances in analytical calibration with multi-way data. Anal. Methods 2012, 4, 1876–1886. [Google Scholar] [CrossRef]
- Olivieri, A.C.; Tauler, R. N-BANDS: A new algorithm for estimating the extension of feasible bands in multivariate curve resolution of multicomponent systems in the presence of noise and rotational ambiguity. J. Chemom. 2021, 35, e3317. [Google Scholar] [CrossRef]
- Olivieri, A.C.; Neymeyr, K.; Sawall, M.; Tauler, R. How noise affects the band boundaries in multivariate curve resolution. Chemom. Intell. Lab. Syst. 2022, 220, 104472. [Google Scholar] [CrossRef]
- Wu, H.-L.; Shibukawa, M.; Oguma, K. An alternating trilinear decomposition algorithm with application to calibration of HPLC–DAD for simultaneous determination of overlapped chlorinated aromatic hydrocarbons. J. Chemom. 1998, 12, 1–26. [Google Scholar] [CrossRef]
- Bro, R. PARAFAC. Tutorial and applications. Chemom. Intell. Lab. Syst. 1997, 38, 149–171. [Google Scholar] [CrossRef]
- Kompany-Zareh, M.; Akhlaghi, Y.; Bro, R. Tucker core consistency for validation of restricted Tucker3 models. Anal. Chim. Acta 2012, 723, 18–26. [Google Scholar] [CrossRef]
- Chen, Z.-P.; Wu, H.-L.; Li, Y.; Yu, R.-Q. Novel constrained PARAFAC algorithm for second-order linear calibration. Anal. Chim. Acta 2000, 423, 187–196. [Google Scholar] [CrossRef]
- Shomali, Z.; Omidikia, N.; Kompany-Zareh, M. Application of non-linear optimization for estimating Tucker3 solutions. Chemom. Intell. Lab. Syst. 2018, 174, 62–75. [Google Scholar] [CrossRef]
- Skov, T.; Hoggard, J.C.; Bro, R.; Synovec, R.E. Handling within run retention time shifts in two-dimensional chromatography data using shift correction and modeling. J. Chromatogr. A 2009, 1216, 4020–4029. [Google Scholar] [CrossRef] [PubMed]
- Vial, J.; Noçairi, H.; Sassiat, P.; Mallipatu, S.; Cognon, G.; Thiébaut, D.; Teillet, B.; Rutledge, D.N. Combination of dynamic time warping and multivariate analysis for the comparison of comprehensive two-dimensional gas chromatograms: Application to plant extracts. J. Chromatogr. A 2009, 1216, 2866–2872. [Google Scholar] [CrossRef] [PubMed]
- De Juan, A.; Tauler, R. Comparison of three-way resolution methods for non-trilinear chemical data sets. J. Chemom. 2001, 15, 749–771. [Google Scholar] [CrossRef]
- Anzardi, M.B.; Arancibia, J.A.; Olivieri, A.C. Interpretation of matrix chromatographic-spectral data modeling with parallel factor analysis 2 and multivariate curve resolution. J. Chromatogr. A 2019, 1604, 460502. [Google Scholar] [CrossRef]
- Zachariassen, C.B.; Larsen, J.; van den Berg, F.; Bro, R.; de Juan, A.; Tauler, R. Comparison of PARAFAC2 and MCR-ALS for resolution of an analytical liquid dilution system. Chemom. Intell. Lab. Syst. 2006, 83, 13–25. [Google Scholar] [CrossRef]
- Bortolato, S.A.; Arancibia, J.A.; Escandar, G.M. Non-Trilinear Chromatographic Time Retention−Fluorescence Emission Data Coupled to Chemometric Algorithms for the Simultaneous Determination of 10 Polycyclic Aromatic Hydrocarbons in the Presence of Interferences. Anal. Chem. 2009, 81, 8074–8084. [Google Scholar] [CrossRef]
- Carabajal, M.D.; Arancibia, J.A.; Escandar, G.M. Multivariate curve resolution strategy for non-quadrilinear type 4 third-order/four way liquid chromatography–excitation-emission fluorescence matrix data. Talanta 2018, 189, 509–516. [Google Scholar] [CrossRef]
- Bro, R.; Andersson, C.A.; Kiers, H.A.L. PARAFAC2—Part II. Modeling chromatographic data with retention time shifts. J. Chemom. 1999, 13, 295–309. [Google Scholar] [CrossRef]
- Amigo, J.M.; Skov, T.; Bro, R.; Coello, J.; Maspoch, S. Solving GC-MS problems with PARAFAC2. TrAC Trends Anal. Chem. 2008, 27, 714–725. [Google Scholar] [CrossRef]
- Zhang, J.; Guo, C.; Cai, W.; Shao, X. Direct non-trilinear decomposition for analyzing high-dimensional data with imperfect trilinearity. Chemom. Intell. Lab. Syst. 2021, 210, 104244. [Google Scholar] [CrossRef]
- Wang, T.; Wu, H.-L.; Yu, Y.-J.; Long, W.-J.; Cheng, L.; Chen, A.-Q.; Yu, R.-Q. A simple method for direct modeling of second-order liquid chromatographic data with retention time shifts and holding the second-order advantage. J. Chromatogr. A 2019, 1605, 360360. [Google Scholar] [CrossRef] [PubMed]
- Tavakkoli, E.; Abdollahi, H.; Gemperline, P.J. Soft-trilinear constraints for improved quantitation in multivariate curve resolution. Analyst 2020, 145, 223–232. [Google Scholar] [CrossRef] [PubMed]
- Escandar, G.M.; Olivieri, A.C. A road map for multi-way calibration models. Analyst 2017, 142, 2862–2873. [Google Scholar] [CrossRef]
- Skov, T.; Ballabio, D.; Bro, R. Multiblock variance partitioning: A new approach for comparing variation in multiple data blocks. Anal. Chim. Acta 2008, 615, 18–29. [Google Scholar] [CrossRef]
- de Juan, A.; Jaumot, J.; Tauler, R. Multivariate Curve Resolution (MCR). Solving the mixture analysis problem. Anal. Methods 2014, 6, 4964–4976. [Google Scholar] [CrossRef]
- de Leeuw, J.; Young, F.W.; Takane, Y. Additive structure in qualitative data: An alternating least squares method with optimal scaling features. Psychometrika 1976, 41, 471–503. [Google Scholar] [CrossRef]
- Tauler, R.; Izquierdo-Ridorsa, A.; Casassas, E. Simultaneous analysis of several spectroscopic titrations with self-modelling curve resolution. Chemom. Intell. Lab. Syst. 1993, 18, 293–300. [Google Scholar] [CrossRef]
- Jaumot, J.; de Juan, A.; Tauler, R. MCR-ALS GUI 2.0: New features and applications. Chemom. Intell. Lab. Syst. 2015, 140, 1–12. [Google Scholar] [CrossRef]
- Golub, G.H.; Reinsch, C. Singular value decomposition and least squares solutions. Numer. Math. 1970, 14, 403–420. [Google Scholar] [CrossRef]
- Golub, G.H.; Loan, C.F.V. Matrix Computations, 2nd ed; Johns Hopkins University Press: Baltimore, MD, USA, 1989. [Google Scholar]
- Klema, V.; Laub, A. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control 1980, 25, 164–176. [Google Scholar] [CrossRef] [Green Version]
- Windig, W.; Guilment, J. Interactive self-modeling mixture analysis. Anal. Chem. 1991, 63, 1425–1432. [Google Scholar] [CrossRef]
- Windig, W.; Markel, S. Simple-to-use interactive self-modeling mixture analysis of FTIR microscopy data. J. Mol. Struct. 1993, 292, 161–170. [Google Scholar] [CrossRef]
- Bro, R.; De Jong, S. A fast non-negativity-constrained least squares algorithm. J. Chemom. 1997, 11, 393–401. [Google Scholar] [CrossRef]
- Tauler, R.; Kowalski, B.; Fleming, S. Multivariate curve resolution applied to spectral data from multiple runs of an industrial process. Anal. Chem. 1993, 65, 2040–2047. [Google Scholar] [CrossRef]
- Alinaghi, M.; Rajkó, R.; Abdollahi, H. A systematic study on the effects of multi-set data analysis on the range of feasible solutions. Chemom. Intell. Lab. Syst. 2016, 153, 22–32. [Google Scholar] [CrossRef]
- Luca, M.D.; Ragno, G.; Ioele, G.; Tauler, R. Multivariate curve resolution of incomplete fused multiset data from chromatographic and spectrophotometric analyses for drug photostability studies. Anal. Chim. Acta 2014, 837, 31–37. [Google Scholar] [CrossRef] [PubMed]
- Parastar, H.; Tauler, R. Multivariate Curve Resolution of Hyphenated and Multidimensional Chromatographic Measurements: A New Insight to Address Current Chromatographic Challenges. Anal. Chem. 2014, 86, 286–297. [Google Scholar] [CrossRef]
- Loan, C.F.V. The ubiquitous Kronecker product. J. Comput. Appl. Math. 2000, 123, 85–100. [Google Scholar] [CrossRef] [Green Version]
- Malik, A.; Tauler, R. Performance and validation of MCR-ALS with quadrilinear constraint in the analysis of noisy datasets. Chemom. Intell. Lab. Syst. 2014, 135, 223–234. [Google Scholar] [CrossRef]
- Tauler, R.; Marqués, I.; Casassas, E. Multivariate curve resolution applied to three-way trilinear data: Study of a spectrofluorimetric acid–base titration of salicylic acid at three excitation wavelengths. J. Chemom. 1998, 12, 55–75. [Google Scholar] [CrossRef]
- Tomasi, G.; Savorani, F.; Engelsen, S.B. icoshift: An effective tool for the alignment of chromatographic data. J. Chromatogr. A 2011, 1218, 7832–7840. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, N.-P.V.; Carstensen, J.M.; Smedsgaard, J. Aligning of single and multiple wavelength chromatographic profiles for chemometric data analysis using correlation optimised warping. J. Chromatogr. A 1998, 805, 17–35. [Google Scholar] [CrossRef]
- Bro, R. Multi-way Analysis in the Food Industry. Models, Algorithms Applications. Acad. Proefschr. Dinam. 1998. Available online: http://www.models.kvl.dk/sites/default/files/brothesis_0.pdf (accessed on 1 October 2021).
- Leardi, R. Multi-Way Analysis with Applications in the Chemical Sciences, Age Smilde, Rasmus Bro and Paul Geladi; John Wiley & Sons: Chichester, UK, 2004; p. 381. ISBN 0-471-98691-7. [Google Scholar] [CrossRef]
- Andersson, C.A.; Bro, R. The N-way Toolbox for MATLAB. Chemom. Intell. Lab. Syst. 2000, 52, 1–4. [Google Scholar] [CrossRef]
- Olivieri, A.C.; Wu, H.-L.; Yu, R.-Q. MVC2: A MATLAB graphical interface toolbox for second-order multivariate calibration. Chemom. Intell. Lab. Syst. 2009, 96, 246–251. [Google Scholar] [CrossRef]
- Horai, H.; Arita, M.; Kanaya, S.; Nihei, Y.; Ikeda, T.; Suwa, K.; Ojima, Y.; Tanaka, K.; Tanaka, S.; Aoshima, K.; et al. MassBank: A public repository for sharing mass spectral data for life sciences. J. Mass Spectrom. 2010, 45, 703–714. [Google Scholar] [CrossRef]
- Nørgaard, L.; Ridder, C. Rank annihilation factor analysis applied to flow injection analysis with photodiode-array detection. Chemom. Intell. Lab. Syst. 1994, 23, 107–114. [Google Scholar] [CrossRef]
- Bro, R.; Harshman, R.A.; Sidiropoulos, N.D.; Lundy, M.E. Modeling multi-way data with linearly dependent loadings. J. Chemom. 2009, 23, 324–340. [Google Scholar] [CrossRef]
- Bahram, M.; Bro, R. A novel strategy for solving matrix effect in three-way data using parallel profiles with linear dependencies. Anal. Chim. Acta 2007, 584, 397–402. [Google Scholar] [CrossRef]
- Mazivila, S.J.; Lombardi, J.M.; Páscoa, R.N.M.J.; Bortolato, S.A.; Leitão, J.M.M.; Esteves da Silva, J.C.G. Three-way calibration using PARAFAC and MCR-ALS with previous synchronization of second-order chromatographic data through a new functional alignment of pure vectors for the quantification in the presence of retention time shifts in peak position and shape. Anal. Chim. Acta 2021, 1146, 98–108. [Google Scholar] [CrossRef]
- Yu, H.; Augustijn, D.; Bro, R. Accelerating PARAFAC2 algorithms for non-negative complex tensor decomposition. Chemom. Intell. Lab. Syst. 2021, 214, 104312. [Google Scholar] [CrossRef]
- Abdollahi, H.; Tauler, R. Uniqueness and rotation ambiguities in Multivariate Curve Resolution methods. Chemom. Intell. Lab. Syst. 2011, 108, 100–111. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | R2 | Lof | Profiles | Recovery of Profiles | |||||
|---|---|---|---|---|---|---|---|---|---|
| Component 1 | Component 2 | Component 3 | |||||||
| r2 | Angle | r2 | Angle | r2 | Angle | ||||
| ATLD | 87.4 | 35.5 | Elution | 0.6369 | 50.4 | 0.07 | 85.4 | 0.959 | 16.4 |
| Sample | 1.0000 | 0.17 | 1.0000 | 0.23 | 1.0000 | 0.4 | |||
| Spectra | 0.9961 | 5.0 | 0.9984 | 3.2 | 0.9999 | 0.6 | |||
| PARAFAC | 94.1 | 24.2 | Elution | 0.7673 | 39.8 | 0.5486 | 56.7 | 0.9128 | 24.1 |
| Sample | 0.9834 | 10.4 | 0.9908 | 7.8 | 0.9035 | 25.4 | |||
| Spectra | 0.9991 | 2.4 | 0.9885 | 8.7 | 0.9053 | 25.1 | |||
| PARAFAC2 | 99.4 | 7. 7 | Elution | 0.9997 | 1.3 | 0.9991 | 2.4 | 0.9970 | 4.5 |
| Sample | 1.0000 | 0.3 | 1.0000 | 0.18 | 1.0000 | 0.03 | |||
| Spectra | 0.9999 | 0.8 | 1.0000 | 0.26 | 1.0000 | 0.2 | |||
| DNTD | 99.4 | 7.5 | Elution | 0.1174 | 83.3 | 0.9908 | 7.8 | 0.9781 | 12.02 |
| Sample | 0.9992 | 2.3 | 0.9869 | 9.3 | 0.9710 | 13.8 | |||
| Spectra | 0.9186 | 23.3 | 0.9450 | 19.1 | 0.9950 | 5.7 | |||
| MCR-ALS bilinear (0,0,0) | 99.4 | 7.7 | Elution | 0.9992 | 2.3 | 0.9988 | 15.0 | 0.9216 | 22.8 |
| Sample | 0.9999 | 0.7 | 0.9998 | 1.2 | 1.0000 | 0.4 | |||
| Spectra | 0.9998 | 1.3 | 0.9995 | 1.8 | 0.9998 | 1.1 | |||
| MCR-ALS trilinear (1,1,1) | 96.4 | 18.8 | Elution | 0.9769 | 12.3 | 0.9845 | 10.1 | 0.9889 | 8.5 |
| Sample | 0.9999 | 0.8 | 0.9998 | 1.2 | 1.0000 | 0.5 | |||
| Spectra | 1.0000 | 0.2 | 1.0000 | 0.4 | 0.9999 | 0.7 | |||
| MCR-ALS trilinear (2,2,2) | 99.4 | 7.7 | Elution | 0.9990 | 2.5 | 0.9970 | 4.4 | 0.9876 | 9.0 |
| Sample | 0.9999 | 0.7 | 0.9998 | 1.1 | 0.9999 | 1.0 | |||
| Spectra | 0.9994 | 1.9 | 0.9995 | 1.8 | 0.9993 | 2.1 | |||
| R2 | Lof | Recovery of Spectra Profiles | ||||
|---|---|---|---|---|---|---|
| 3-Hydroxy-2-Butanone | Hexyl Acetate | |||||
| r2 | Angle | r2 | Angle | |||
| ATLD | 94.0 | 24.6 | 0.9855 | 9.8 | 0.9673 | 14.7 |
| PARAFAC | 94.9 | 22.6 | 0.9869 | 9.3 | 0.9793 | 11.7 |
| PARAFAC2 | 99.7 | 5.4 | 0.9868 | 9.3 | 0.9790 | 11.8 |
| DNTD | 99.7 | 5.4 | 0.9857 | 9.7 | 0.9536 | 17.5 |
| MCR bilinear (0,0,0) | 99.7 | 5.3 | 0.9860 | 9.6 | 0.9487 | 18.4 |
| MCR trilinear (1,1,1) | 94.8 | 22.2 | 0.9866 | 9.4 | 0.9544 | 17.4 |
| MCR mixed (1 1 0) | 94.8 | 22.8 | 0.9867 | 9.4 | 0.9492 | 18.3 |
| MCR mixed (2 2 0) | 99.2 | 9.4 | 0.9864 | 9.5 | 0.9489 | 18.4 |
| MCR mixed (2 2 1) | 99.2 | 9.2 | 0.9865 | 9.4 | 0.9790 | 11.8 |
| R2 | Lof | Recovery of Sample Profiles | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FIA Profiles | Spectra Profiles | Sample Profiles | ||||||||
| r2 | Angle | r2 | Angle | r2 | Angle | |||||
| ATLD | 67.6 | 56.9 | 2HBA | acid | 0.7607 | 40.5 | 0.8081 | 36.1 | 0.8081 | 36.1 |
| alkali | 0.9188 | 23.2 | 0.6934 | 46.1 | 0.6934 | 46.1 | ||||
| 3HBA | acid | 0.8738 | 29.1 | 0.8254 | 34.4 | 0.8254 | 34.3 | |||
| alkali | 0.2152 | 77.6 | −0.8030 | 143.4 | −0.8030 | 143.4 | ||||
| 4HBA | acid | 0.8874 | 27.4 | 0.6834 | 46.9 | 0.6834 | 46.9 | |||
| alkali | 0.7951 | 37.3 | −0.3078 | 107.9 | −0.3078 | 107.9 | ||||
| DNTD | 38.1 | 65.5 | 2HBA | acid | 0.6910 | 46.3 | 0.0912 | 84.8 | 0.9676 | 14.6 |
| alkali | 0.9206 | 23.0 | 0.4533 | 63.0 | 0.9623 | 15.8 | ||||
| 3HBA | acid | 0.9208 | 23.0 | 0.8561 | 31.1 | 0.8125 | 35.7 | |||
| alkali | 0.8293 | 34.0 | 0.4030 | 66.2 | 0.7944 | 37.4 | ||||
| 4HBA | acid | 0.7811 | 38.6 | 0.1393 | 82.0 | 0.6932 | 46.1 | |||
| alkali | 0.9366 | 20.5 | 0.8108 | 35.8 | 0.9840 | 10.3 | ||||
| PARAFAC | 99.1 | 9.4 | 2HBA | acid | 0.9772 | 12.3 | 0.9940 | 6.3 | 0.9770 | 12.3 |
| alkali | 0.9990 | 2.5 | 0.9852 | 9.9 | 0.9473 | 18.7 | ||||
| 3HBA | acid | 0.9727 | 13.4 | 0.9708 | 13.9 | 0.9354 | 20.7 | |||
| alkali | 0.9807 | 11.3 | 0.4535 | 63.0 | 0.6755 | 47.5 | ||||
| 4HBA | acid | 0.9980 | 3.7 | 0.9798 | 11.5 | 0.9855 | 9.8 | |||
| alkali | 0.9942 | 6.2 | 0.9776 | 12.1 | 0.9647 | 15.3 | ||||
| PARAFAC2 | 99.9 | 0.8 | 2HBA | acid | 0.9417 | 19.7 | 0.4128 | 65.6 | 0.8836 | 27.9 |
| alkali | 0.8311 | 33.8 | 0.9548 | 17.3 | 0.9705 | 14.0 | ||||
| 3HBA | acid | 0.9661 | 15.0 | 0.9857 | 9.7 | 0.9063 | 25.0 | |||
| alkali | −0.4305 | 115.5 | 0.9115 | 24.3 | 0.9482 | 18.5 | ||||
| 4HBA | acid | 0.8031 | 36.6 | 0.8508 | 31.7 | 0.9537 | 17.5 | |||
| alkali | −0.0725 | 94.2 | 0.9163 | 23.6 | 0.9914 | 7.5 | ||||
| MCR-ALS bilinear (0,0,0) | 99.9 | 1.2 | 2HBA | acid | 0.9956 | 5.4 | 0.9747 | 12.9 | 0.9895 | 8.3 |
| alkali | 0.9703 | 14.0 | 0.9994 | 2.0 | 0.9572 | 16.8 | ||||
| 3HBA | acid | 0.9980 | 3.6 | 0.9807 | 11.3 | 0.9976 | 4.0 | |||
| alkali | 0.9339 | 21.0 | 0.9974 | 4.1 | 0.9988 | 2.8 | ||||
| 4HBA | acid | 0.9997 | 1.3 | 0.9949 | 5.8 | 0.9997 | 1.3 | |||
| alkali | 0.9970 | 4.4 | 0.9992 | 2.4 | 0.9997 | 1.3 | ||||
| MCR-ALS trilinear (1,1,1) | 99.4 | 7.4 | 2HBA | acid | 0.9681 | 14.5 | 0.9967 | 4.7 | 0.9806 | 11.3 |
| alkali | 0.9997 | 1.3 | 0.9696 | 14.1 | 0.9918 | 7.3 | ||||
| 3HBA | acid | 0.9694 | 14.2 | 0.9973 | 4.2 | 0.9519 | 17.0 | |||
| alkali | 0.9928 | 6.9 | 0.9244 | 22.4 | 0.9962 | 4.9 | ||||
| 4HBA | acid | 0.9897 | 8.2 | 0.9981 | 3.6 | 0.9996 | 1.5 | |||
| alkali | 0.9992 | 2.3 | 0.9976 | 3.9 | 0.9998 | 1.1 | ||||
| MCR-ALS trilinear (2,2,2) | 99.9 | 3.1 | 2HBA | acid | 0.9784 | 11.9 | 0.9995 | 1.7 | 0.8881 | 27.3 |
| alkali | 0.9991 | 2.4 | 0.9688 | 14.3 | 0.9981 | 3.5 | ||||
| 3HBA | acid | 0.9751 | 12.8 | 0.9892 | 8.4 | 0.9761 | 12.5 | |||
| alkali | 0.9957 | 5.3 | 0.9815 | 11.1 | 0.9947 | 5.9 | ||||
| 4HBA | acid | 0.9909 | 7.7 | 0.9002 | 25.8 | 0.9932 | 6.7 | |||
| alkali | 0.9932 | 6.7 | 0.9972 | 4.3 | 0.9998 | 1.2 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Tauler, R. Flexible Implementation of the Trilinearity Constraint in Multivariate Curve Resolution Alternating Least Squares (MCR-ALS) of Chromatographic and Other Type of Data. Molecules 2022, 27, 2338. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules27072338
Zhang X, Tauler R. Flexible Implementation of the Trilinearity Constraint in Multivariate Curve Resolution Alternating Least Squares (MCR-ALS) of Chromatographic and Other Type of Data. Molecules. 2022; 27(7):2338. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules27072338
Chicago/Turabian StyleZhang, Xin, and Romà Tauler. 2022. "Flexible Implementation of the Trilinearity Constraint in Multivariate Curve Resolution Alternating Least Squares (MCR-ALS) of Chromatographic and Other Type of Data" Molecules 27, no. 7: 2338. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules27072338