
Classification of the Residues after High and Low Order Explosions Using Machine Learning Techniques on Fourier Transform Infrared (FTIR) Spectra

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
3. Results
3.1. The Lollipop Chart
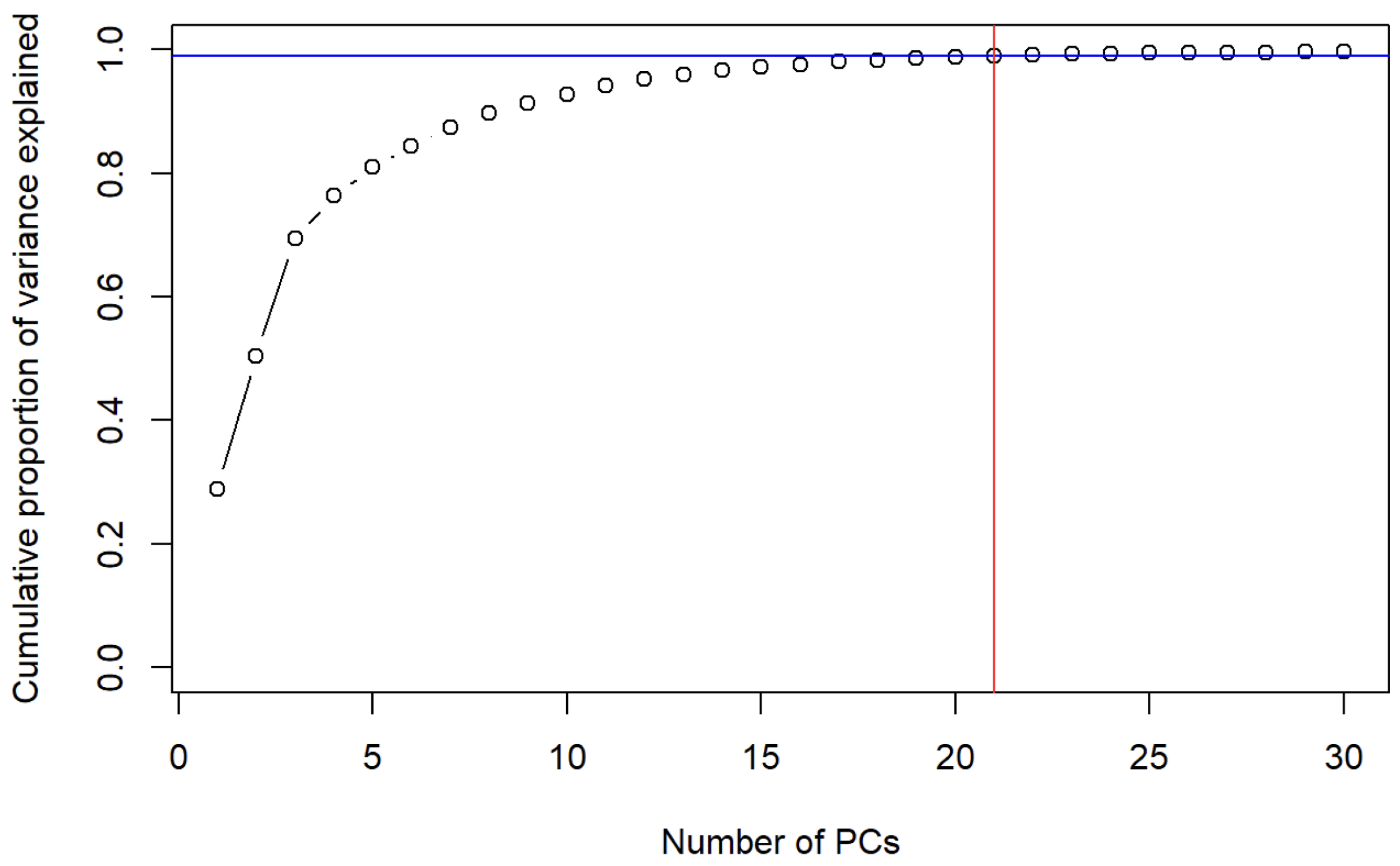
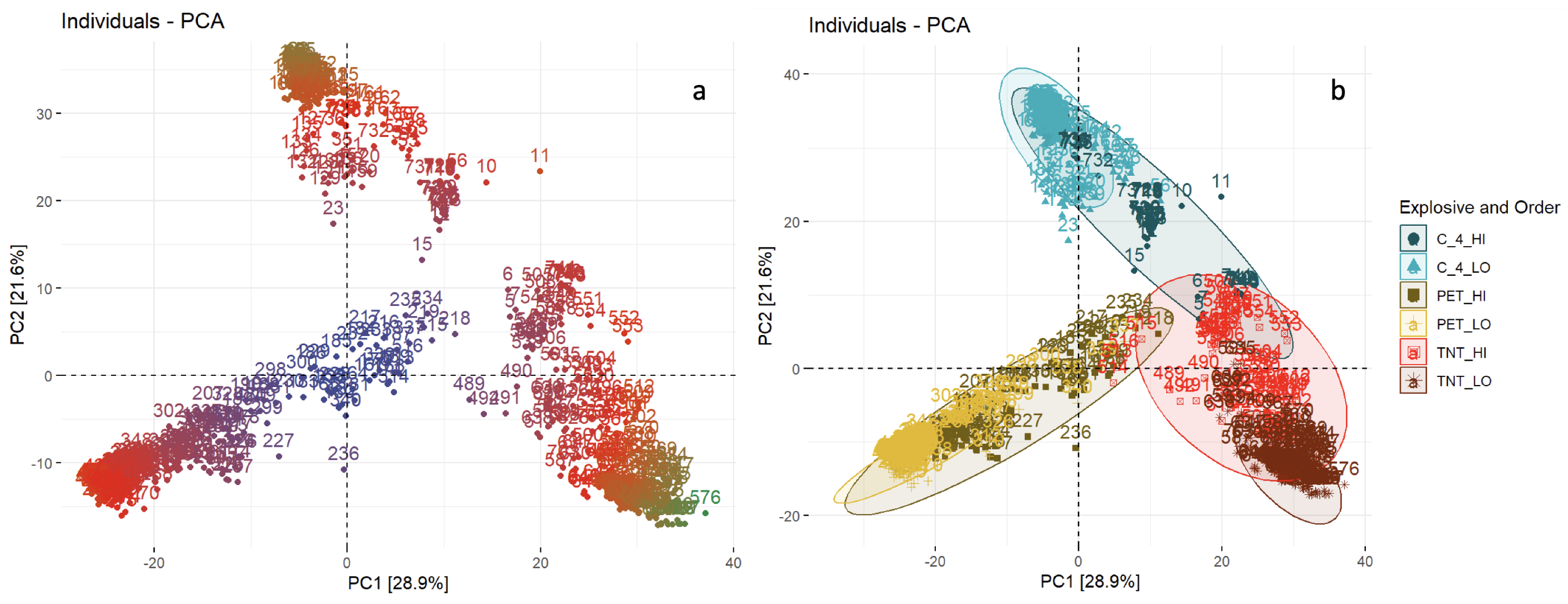
3.2. LDA-PCA
3.2.1.
3.2.2. Partition Plot LDA
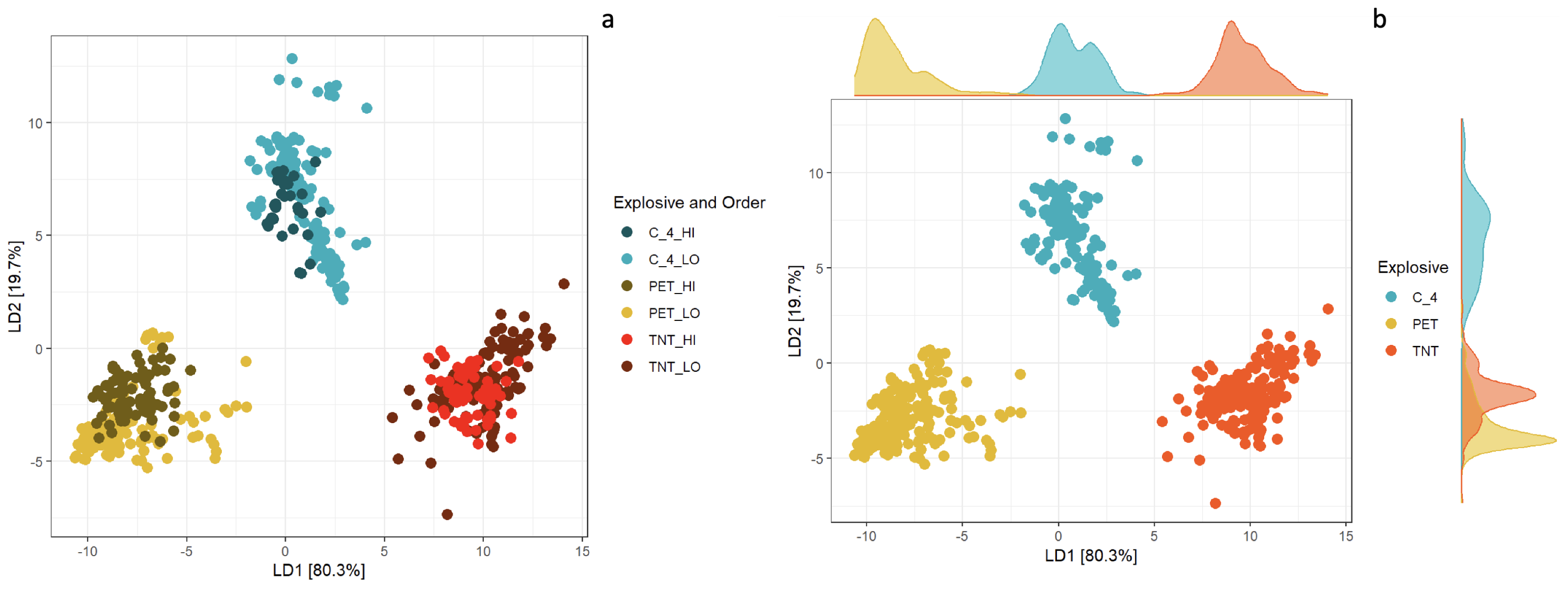
3.2.3. Final LDA-PCA Model
4. Conclusions
- Integration of additional analytical techniques: combining FTIR spectroscopy with other analytical techniques such as Raman spectroscopy or mass spectrometry could provide a more comprehensive understanding of the chemical composition of the residues and lead to improved classification results.
- Data augmentation and expansion: increasing the size and diversity of the FTIR spectral data used for training machine learning algorithms could lead to improved classification results, especially in cases where the number of samples is limited.
- Residue characterization: further research into the chemical and physical properties of residues produced by different types of explosions could provide additional information to improve the accuracy of classification results.
- Real-world applications: research could focus on the practical applications of FTIR spectroscopy and machine learning techniques for residue classification in real-world scenarios. This could include evaluating the effectiveness of the methods in different environments and under different conditions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FTIR | Fourier Transform Infrared Spectroscopy |
| HE | High Explosive |
| PCA | Principal Component Analysis |
| LDA | Linear Disciminant Analysis |
References
- Zonderman, J. Beyond the Crime Lab: The New Science of Investigation; John Wiley: Hoboken, NJ, USA, 1999. [Google Scholar]
- Kuula, J.; Rinta, H.J.; Pölönen, I.; Puupponen, H.H.; Haukkamäki, M.; Teräväinen, T. Detecting Explosive Substances by the IR Spectrography. In Chemical, Biological, Radiological, Nuclear, and Explosives (CBRNE) Sensing XV; SPIE: Orlando, FL, USA, 2014; Volume 90730Q. [Google Scholar] [CrossRef]
- Abdul-Karim, N.; Blackman, C.S.; Gill, P.P.; Wingstedt, E.M.M.; Reif, B.A.P. Post-Blast Explosive Residue—A Review of Formation and Dispersion Theories and Experimental Research. RSC Adv. 2014, 4, 54354–54371. [Google Scholar] [CrossRef] [Green Version]
- Trélat, S.; Sochet, I.; Autrusson, B.; Cheval, K.; Loiseau, O. Impact of a Shock Wave on a Structure on Explosion at Altitude. J. Loss Prev. Process. Ind. 2007, 20, 509–516. [Google Scholar] [CrossRef] [Green Version]
- Pennington, J.C.; Silverblatt, B.; Poe, K.; Hayes, C.A.; Yost, S. Explosive Residues from Low-Order Detonations of Heavy Artillery and Mortar Rounds. Soil Sediment Contam. 2008, 17, 533–546. [Google Scholar] [CrossRef]
- Oxley, J.C.; Marshall, M.; Lancaster, S.L. Principles and Issues in Forensic Analysis of Explosives. In Forensic Chemistry Handbook; Kobilinsky, L., Ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2012; pp. 23–39. [Google Scholar] [CrossRef]
- Kelleher, J.D. Explosives Residue: Origin and Distribution. Forensic Sci. Commun. 2002, 4. Available online: https://archives.fbi.gov/archives/about-us/lab/forensic-science-communications/fsc/april2002/kelleher.htm (accessed on 28 December 2022).
- Thurman, J.T. Practical Bomb Scene Investigation; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Houck, M.M.; Siegel, J.A. Fundamentals of Forensic Science, 2nd ed.; Academic Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Samuels, J.E.; Boyd, D.G.; Rau, R.M. A Guide for Explosion and Bombing Scene Investigation; US Department of Justice, Office of Justice Programs, National Institute of Justice: Washington, DC, USA, 2020.
- Gaskell, D.R. Forensic Investigation of Explosions; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Álvarez, Á.; Yáñez, J.; Contreras, D.; Saavedra, R.; Sáez, P.; Amarasiriwardena, D. Propellant’s differentiation using FTIR-photoacoustic detection for forensic studies of improvised explosive devices. Forensic Sci. Int. 2017, 280, 169–175. [Google Scholar] [CrossRef]
- Ostrander, J.S.; Knepper, R.; Tappan, A.S.; Kay, J.J.; Zanni, M.T.; Farrow, D.A. Energy Transfer Between Coherently Delocalized States in Thin Films of the Explosive Pentaerythritol Tetranitrate (PETN) Revealed by Two-Dimensional Infrared Spectroscopy. J. Phys. Chem. B 2017, 121, 1352–1361. [Google Scholar] [CrossRef] [PubMed]
- Bauer, C.; Sharma, A.; Willer, U.; Burgmeier, J.; Braunschweig, B.; Schade, W.; Blaser, S.; Hvozdara, L.; Müller, A.; Holl, G. Potentials and Limits of Mid-Infrared Laser Spectroscopy for the Detection of Explosives. Appl. Phys. B 2008, 92, 327–333. [Google Scholar] [CrossRef]
- Guven, B.; Eryilmaz, M.; Üzer, A.; Boyaci, I.H.; Tamer, U.; Apak, R. Surface-enhanced Raman spectroscopy combined with gold nanorods for the simultaneous quantification of nitramine energetic materials. RSC Adv. 2017, 7, 37039–37047. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Perkins, R.; Liu, Y.; Tzeng, N. Normal mode and experimental analysis of TNT Raman spectrum. J. Mol. Struct. 2017, 1133, 217–225. [Google Scholar] [CrossRef]
- Sharma, S.P.; Lahiri, S.C. Characterization and Identification of Explosives and Explosive Residues Using GC-MS, an FTIR Microscope, and HPTLC. J. Energetic Mater. 2005, 23, 239–264. [Google Scholar] [CrossRef]
- TWGFEX. TWGFEX Recommended Guidelines for the Forensic Identification of Post-blast Explosive Residues; NIST: Gaithersburg, MD, USA, 2007. [Google Scholar]
- Yinon, J. (Ed.) Counterterrorist Detection Techniques of Explosives; Elsevier Science: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Banas, A.; Banas, K.; Bahou, M.; Moser, H.; Wen, L.; Yang, P.; Li, Z.; Cholewa, M.; Lim, S.; Lim, C. Post-Blast Detection of Traces of Explosives by Means of Fourier Transform Infrared Spectroscopy. Vib. Spectrosc. 2009, 51, 168–176. [Google Scholar] [CrossRef]
- Banas, K.; Banas, A.; Moser, H.O.; Bahou, M.; Li, W.; Yang, P.; Cholewa, M.; Lim, S.K. Multivariate Analysis Techniques in the Forensics Investigation of the Postblast Residues by Means of Fourier Transform-Infrared Spectroscopy. Anal. Chem. 2010, 82, 3038–3044. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2022. [Google Scholar]
- RStudio Team. RStudio: Integrated Development Environment for R; POSIT: Boston, MA, USA, 2020. [Google Scholar]
- Beleites, C.; Sergo, V. hyperSpec: A Package to Handle Hyperspectral Data Sets in R; Chemometrix GmbH: Wolfersheim, Germany, 2021. [Google Scholar]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016. [Google Scholar]
- Kuhn, M. Caret: Classification and Regression Training; 2022. Available online: https://github.com/topepo/caret/ (accessed on 28 December 2022).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Weihs, C.; Ligges, U.; Luebke, K.; Raabe, N. klaR Analyzing German Business Cycles. In Proceedings of the Data Analysis and Decision Support; Baier, D., Decker, R., Schmidt-Thieme, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 335–343. [Google Scholar]
- Lê, S.; Josse, J.; Husson, F. FactoMineR: A Package for Multivariate Analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Kassambara, A.; Mundt, F. Factoextra: Extract and Visualize the Results of Multivariate Data Analyses; 2020; Available online: https://CRAN.R-project.org/package=factoextra (accessed on 28 December 2022).
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the Tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef] [Green Version]
- Zancla, A.; Santis, S.D.; Scorza, A.; Sciuto, S.A.; Sotgiu, G.; Orsini, M. A Preliminary Study on the Importance of Normalization Methods in Infrared Micro- Spectroscopy for Biomedical Applications. In Proceedings of the 22nd International Workshop on ADC and DAC Modelling and Testing, Palermo, Italy, 14–16 September 2020. [Google Scholar]
- Taylor, J.R. An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements, 2nd ed.; University Science Books: Sausalito CA, USA, 1997. [Google Scholar]
- Mittal, S.; Bhargava, R. A Comparison of Mid-Infrared Spectral Regions on Accuracy of Tissue Classification. Analyst 2019, 144, 2635–2642. [Google Scholar] [CrossRef]
- Rudis, B.; Bolker, B.; Schulz, J.; Kothari, A.; Sidi, J. Lollipop Charts. 2022. Available online: https://yonicd.github.io/ggalt/articles/lollipop.html (accessed on 25 December 2022).
- Deborah, H.; Richard, N.; Hardeberg, J.Y. A Comprehensive Evaluation of Spectral Distance Functions and Metrics for Hyperspectral Image Processing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3224–3234. [Google Scholar] [CrossRef]
- Abdul-Karim, N. The Spatial Distribution of Post-blast Condensed Phase Explosive Residues; University College London: London, UK, 2015. [Google Scholar]
- Zapata, F.; García-Ruiz, C. Analysis of Different Materials Subjected to Open-Air Explosions in Search of Explosive Traces by Raman Microscopy. Forensic Sci. Int. 2017, 275, 57–64. [Google Scholar] [CrossRef]
- Fearn, T. Discriminant Analysis. In Handbook of Vibrational Spectroscopy, 1st ed.; Chalmers, J.M., Griffiths, P.R., Eds.; Wiley: Hoboken, NJ, USA, 2001. [Google Scholar] [CrossRef]
- Pramoditha, R. How to Select the Best Number of Principal Components for the Dataset. 28 December 2022. Available online: https://towardsdatascience.com/how-to-select-the-best-number-of-principal-components-for-the-dataset-287e64b14c6d (accessed on 28 December 2022).
- Kaiser, H.F. The Application of Electronic Computers to Factor Analysis. Educ. Psychol. Meas. 1960, 20, 141–151. [Google Scholar] [CrossRef]
- Cangelosi, R.; Goriely, A. Component Retention in Principal Component Analysis with Application to cDNA Microarray Data. Biol. Direct 2007, 2, 2. [Google Scholar] [CrossRef] [Green Version]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banas, A.M.; Banas, K.; Breese, M.B.H. Classification of the Residues after High and Low Order Explosions Using Machine Learning Techniques on Fourier Transform Infrared (FTIR) Spectra. Molecules 2023, 28, 2233. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules28052233
Banas AM, Banas K, Breese MBH. Classification of the Residues after High and Low Order Explosions Using Machine Learning Techniques on Fourier Transform Infrared (FTIR) Spectra. Molecules. 2023; 28(5):2233. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules28052233
Chicago/Turabian StyleBanas, Agnieszka M., Krzysztof Banas, and Mark B. H. Breese. 2023. "Classification of the Residues after High and Low Order Explosions Using Machine Learning Techniques on Fourier Transform Infrared (FTIR) Spectra" Molecules 28, no. 5: 2233. https://0-doi-org.brum.beds.ac.uk/10.3390/molecules28052233