Stochastic Volatility and GARCH: Do Squared End-of-Day Returns Provide Similar Information?


1
School of Mathematics and Statistics, University of Sydney, Sydney, NSW 2006, Australia
2
Department of Finance, Asia University, Wufeng, Taichung 41354, Taiwan
3
School of Business and Law, Edith Cowan University, Joondalup 6027, Australia
J. Risk Financial Manag. 2020, 13(9), 202; https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm13090202
Submission received: 19 June 2020
/
Revised: 1 September 2020
/
Accepted: 2 September 2020
/
Published: 7 September 2020
(This article belongs to the Special Issue Volatility Modelling and Forecasting)
Abstract
:The paper examines the relative performance of Stochastic Volatility (SV) and GARCH(1,1) models fitted to twenty plus years of daily data for three indices. As a benchmark, I use the realized volatility (RV) for the S&P 500, DOW JONES and STOXX50 indices, sampled at 5-minute intervals, taken from the Oxford Man Realised Library. Both models demonstrate comparable performance and are correlated to a similar extent with the RV estimates, when measured by OLS. However, a crude variant of Corsi’s (2009) Heterogenous Auto-Regressive (HAR) model, applied to squared demeaned daily returns on the indices, appears to predict the daily RV of the series, better than either of the two base models. The base SV model was then enhanced by adding a regression matrix including the first and second moments of the demeaned return series. Similarly, the GARCH(1,1) model was augmented by adding a vector of demeaned squared returns to the mean equation. The augmented SV model showed a marginal improvement in explanatory power. This leads to the question of whether we need either of the two standard volatility models, if the simple expedient of using lagged squared demeaned daily returns provides a better RV predictor, at least in the context of the indices in the sample. The paper thus explores whether simple rules of thumb match the volatility forecasting capabilities of more sophisticated models.
Keywords:
stochastic volatility; GARCH(1,1); S&P500; DOWJONES 50; RV 5 min; HAR model; demeaned daily squared returnsJEL Classification:
C22; G121. Introduction
The paper explores the performance of Stochastic Volatility and GARCH(1,1) models as estimators of the volatility of the S&P 500, the DOW JONES and the STOXX50 indices. The volatilities estimated by these models are compared with realized volatility estimates for the three indices, obtained from the Oxford Man Realised Library, sampled at 5-minute intervals, as described in Heber et al. (2009). Their volatility forecasts are further compared with those derived from a simple historical volatility model. The data series features a 20 year sample window of daily prices taken from 3 January 2000 to 30 April 2020, initially comprising 5100 observations, also taken from the Oxford Man Realised Library. The study is a companion study to Allen and McAleer (2020).
The paper is motivated by Poon and Granger (2003, p. 507) who observed that: “as a rule of thumb, historical volatility methods work equally well compared with more sophisticated ARCH class and SV models.” The paper features a continued exploration of this observation in the context of basic GARCH and Stochastic Volatility models as compared with a simple historical volatility model based on lags of squared demeaned daily returns.
The R packages, stochvol and factorstochvol, are used, which employ Markov chain Monte Carlo (MCMC) samplers to conduct inference by obtaining draws from the posterior distribution of parameters and latent variables, which can then be used for predicting future volatilities. This is done within the context of a fully Bayesian implementation of heteroskedasticity modelling within the framework of stochastic volatility. For more information, see the discussion of the methods by Kastner and Frühwirth-Schnatter (2014), Kastner et al. (2017), and of the stochvol and factorstochvol packages by Kastner (2016, 2019).
Taylor (1982) developed modelling volatility probabilistically, through a state-space model where the logarithm of the squared volatilities—the latent states—follow an autoregressive process of order one, which became known as the stochastic volatility (SV) model. Jacquier et al. (1994), Ghysels et al. (1996), and Kim et al. (1998) provided evidence in support of the application of stochastic volatility models, but their practical use has been infrequent. The shortage of empirical applications of the SV models has been limited by two major factors: the variety (and potential incompatibility) of estimation methods for SV models, plus the lack of standard software packages (see Bos (2012)). The situation for multivariate SV was even more problematic until Hosszejni and Kastner (2019) developed the R package ’factorstochvol’.
Taylor (1994) reviews the stochastic volatility and the ARCH/GARCH literature. Other reviews are by McAleer (2005) and Asai et al. (2006). Poon and Granger (2003, p. 485), noted the difficulties in the application of the SV model: “the SV model has no closed form, and hence cannot be estimated directly by maximum likelihood”. The advantage of the stochvol and factorstochvol R packages is that they incorporate an efficient MCMC estimation scheme for SV models, as discussed by Kastner and Frühwirth-Schnatter (2014) and Kastner et al. (2017). These two R library packages facilitate the analysis in the paper, which features a direct comparison of the volatility predictions of a SV model, a GARCH (1,1) model, and a simple application of a historical volatility based estimation method, as applied to the the three indices.
2. Previous Work and Econometric Models
2.1. Stochastic Volatility
There have been numerous empirical studies of changes in volatility in various stock, currency, and commodities markets. The findings in volatility research have implications for option pricing, volatility estimation, and the degree to which volatility shocks persist. These research questions have been approached by means of different models and methodologies.
Taylor (1982) suggested a novel SV approach, and Taylor (1994) developed the SV model as follows: if denotes the prices of an asset at time and assuming no dividend payments, the returns on the asset can be defined, in the context of discrete time periods, as:
Volatility is customarily indicated by , and prices are described by a stochastic differential equation:
with W a standard Weiner process. If and are constants, has a normal distribution, and:
with independent and identically distributed
Equation (3) can be generalised by replacing with a positive random variable , to give:
where
In circumstances where the returns process can be presented by Equation (4), Taylor (1994) calls the stochastic volatility for period t. His definition assumes that follows a normal distribution.
The stochastic process generates realised volatilities which, in general, are not observable. For any realisation, :
The mixture of these conditional normal distributions defines the unconditional distribution of , which will have excess kurtosis whenever has positive variance and is independent of .
In the empirical section which follows, I use the RV of the S&P500, DOW JONES and STOXX50 indices, sampled at 5-minute intervals provided by Oxford Man, as a proxy for the true realised volatility. I then compare the estimates of volatility obtained from SV and GARCH(1,1) models, using the RV estimates as a benchmark.
Taylor (1994, p. 3) suggests using “capital letters to represent random variables and lower case letters to represent outcomes”. I shall follow that convention. Given observed returns of the conditional variance for period t is:
Taylor (1994) notes that, in general, the random variable , which generates the observed conditional variance is not, in general, equal to . A convenient way to use economic theory to motivate changes in volatility is to assume that returns are generated by a number of intra-period price revisions, as in the manner of Clark (1973) and Tauchen and Pitts (1983).
It is assumed that there are price revisions during trading day t, each caused by unpredictable information. Let event i on day t change the logarithmic price by , with:
If we assume that and is independent of the random variable , with , then:
The above model suggests that squared volatility is proportional to the amount of price information.
The lack of standard software to estimate such a model is addressed by Kastner and Frühwirth-Schnatter (2014) who propose an efficient MCMC estimation scheme which is implemented in the R stochvol package, Kastner (2016). Kastner (2016, p. 2) proceeds by “letting be a vector of returns, with mean zero. An intrinsic feature of the SV model is that each observation is assumed to have its ’own’ contemporaneous variance, , which relaxes the usual assumption of homoscedasticity”. It is assumed that the logarithm of this variance follows an autoregressive process of order one. This assumption is fundamentally different to GARCH models, where the time-varying conditional volatility is assumed to follow a deterministic instead of a stochastic evolution.
The centered parameterization of the SV model can be given as:
where denotes the normal distribution with mean and variance . is the vector of parameters which consists of the level of the log variance , the persistence of log variance, , and the volatility of log variance, The process which features in equations (10) and (11) is the unobserved or latent time-varying volatility process.
Kastner (2016, p. 4) remarks that: “A novel and crucial feature of the algorithm implemented in stochvol is the usage of a variant of the “ancillarity-sufficiency interweaving strategy” (ASIS) which was suggested in the general context of state-space models by Yu and Meng (2011). ASIS exploits the fact that, for certain parameter constellations, sampling efficiency improves substantially when considering a non-centered version of a state-space model”.
Another key feature of the algorithm used in stochvol is the joint sampling of all instantaneous volatilities “all without a loop” (AWOL), a technique with links to Rue (2001) and as discussed in McCausland et al. (2011). The combination of these features enables the R package stochvol to estimate SV models efficiently even when large datasets are involved.
Kastner et al. (2017) suggest that the multivariate factor stochastic volatility (SV) model (Chib et al. 2006) provides a means of uniting simplicity with flexibility and robustness. It is simple in the sense that the potentially high-dimensional observation space is reduced to a lower-dimensional orthogonal latent factor space. It is flexible in the sense that these factors are allowed to exhibit volatility clustering, and it is robust in the sense that idiosyncratic deviations are themselves stochastic volatility processes, thereby allowing for the degree of volatility co-movement to be time-varying. Hosszejni and Kastner (2019) set up a factor SV model employed in the factorstochvol package in R, and the analysis also uses code from this package.
2.2. ARCH and GARCH
Engle (1982) developed the Autoregressive Conditional Heteroskedasticity (ARCH) model that incorporates all past error terms. It was generalised to GARCH by Bollerslev (1986) to include lagged term conditional volatility. GARCH predicts that the best indicator of future variance is a weighted average of long-run variance, the predicted variance for the current period, and any new information in this period, as captured by the squared residuals.
Consider a time series where is the conditional expectation of at time and is the error term. The basic GARCH model has the following specification:
in which and (usually a positive fraction), to ensure a positive conditional variance, (see Tsay (1987)). The ARCH effect is captured by the parameter which represents the short-run persistence of shocks to returns, captures the GARCH effect that contributes to long-run persistence, and measures the persistence of the impact of shocks to returns to long-run persistence. A GARCH(1,1) process is weakly stationary if . (See the discussion in Allen et al. (2013).
We contrast the estimates of volatility from the SV model with those from a GARCH(1,1) model, and assess which better explains the behaviour of the RV of FTSE sampled at 5-minute intervals.
2.3. Realised Volatility
Use was made of the RV 5-min estimates from Oxford Man for the three indices as the RV benchmark (see: https://realized.oxford-man.ox.ac.uk/data). This database contains “daily (close to close) financial returns, and a corresponding sequence of daily realised measures . Realised measures are theoretically sound high frequency, nonparametric-based estimators of the variation of the price path of an asset during the times at which the asset trades frequently on an exchange. Realised measures ignore the variation of prices overnight and sometimes the variation in the first few minutes of the trading day when recorded prices may contain large errors”. The metrics were developed by Andersen et al. (2001), Andersen et al. (2003), and Barndorff-Nielsen and Shephard (2002). Shephard and Sheppard (2010) provide an account of the RV measures used in the Oxford Man Realised Library.
The simplest realised metric is realised variance (RV):
where . The are the times of trades or quotes on the t-th day. The theoretical justification of this measure is that, if prices are observed without noise then, as , it consistently estimates the quadratic variation of the price process on the t-th day. If the sampling is reduced to very small intervals of time, market microstructure noise may become a contaminant. In order to avoid this issue, we use RV estimates from Oxford Man, sampled at 5-minute intervals, hereafter
2.4. Historical Volatility Model
Poon and Granger (2005) discuss various practical issues involved in forecasting volatility. They suggest that the HISVOL model has the following form:
where is the expected standard deviation at time t, is the weight parameter, and is the historical standard deviation for periods indicated by the subscripts. Poon and Granger (2005) suggest that this group of models include the random walk, historical averages, autoregressive (fractionally integrated) moving average, and various forms of exponential smoothing that depend on the weight parameter .
We use a simple form of this model in which the estimate of is the previous day’s demeaned squared return. Poon and Granger (2005) review 66 previous studies, and suggest that implied standard deviations appear to perform best, followed by historical volatility and GARCH which have roughly equal performance. They also note that, at the time of writing, there were insufficient studies of SV models to come to any conclusions about this class of models. This observation provides the motivation for the current study which assesses the performance of all three classes of models. It also provides the motivation to use a crude rule of thumb in the form of 20 lags of daily squared demeaned returns. The choice of 20 lags is conditioned by Corsi’s (2009) “Heterogeneous Autoregressive model of Realized Volatility” (HAR) model, as discussed in the next section. A feature of this model is that it includes estimates of daily, weekly, and monthly ex-post realised volatility. The crude HISVOL model adopted in the paper takes 20 lags as an approximation for this, as it roughly represents a month of trading days.
Barndorff-Nielsen and Shephard (2003) point out that taking the sums of squares of increments of log-prices has a long tradition in the financial economics literature. See, for example, Poterba and Summers (1986), Schwert (1989), Taylor and Xu (1997), Christensen and Prabhala (1998), Dacorogna et al. (1998), and Andersen et al. (2001). (Shephard and Sheppard (2010), p 200, footnote 4) note that: “Of course, the most basic realised measure is the squared daily return”. We utilise this approach as the basis of our historical volatility model.
2.5. Heterogenous Autoregressive Model (HAR)
Corsi (2009, p. 174) suggests “an additive cascade model of volatility components defined over different time periods. The volatility cascade leads to a simple AR-type model in the realized volatility with the feature of considering different volatility components realized over different time horizons and which he termed as a “Heterogeneous Autoregressive model of Realized Volatility”. Corsi (2009) suggests that the model successfully achieves the purpose of reproducing the main empirical features of financial returns (long memory, fat tails, and self-similarity) in a parsimonious way. He writes his model as:
where is the daily integrated volatility, and and are respectively the daily, weekly, and monthly (ex post) observed realized volatilities, and .
Corsi (2009) inspires the HISVOL model adopted in the paper, which uses lags of historical RV estimates, but, in the current case, lags of squared demeaned daily close-to-close returns are employed.
A further justification for the approach adopted in the current study is provided by a recent publication by Perron and Shi (2020), who show that squared low-frequency daily returns can be expressed in terms of the temporal aggregation of a high-frequency series. They explore the links between the spectral density function of squared low-frequency and high-frequency returns. They analyze the properties of the spectral density function of realized volatility, constructed from squared returns with different frequencies under temporal aggregation. However, for the low frequency data on S&P 500 returns, they cannot infer whether the noise is stationary long memory but a long-memory process appears needed to explain the features related to high frequency S&P 500 futures. However, they caution that they cannot explain this difference and that it may also be related to the fact that they have used both spot and futures series for the S&P500 in the case of the high frequency data.
Perron and Shi (2020, p. 14), suggest that: “that both the realized volatility and the squared daily returns contain the same information about long memory. However, the squared daily returns contain a larger noise component than does the realized volatility”. The current paper uses the long-memory component of low frequency squared daily demeaned returns to capture this long memory feature and to provide an approximation to a HAR model. The paper does not apply a full HAR model as the intention is to explore whether a simple HISVOL rule of thumb model, based on lagged squared demeaned returns, performs as well as standard GARCH or SV models. It is clear that a full HAR specification is likely to perform better, though Perron and Shi (2020) suggest that many of the HAR’s long memory features will be captured by the approach adopted in the paper.
3. Results of the Analysis
3.1. Preliminary Analysis
The sample data set consists of 20 years and four months of daily data of adjusted continuously compounded close to close returns for S&P 500, DOW JONES and STOXX50 indices, taken from 3 January 2000 through to 30 April 2020. There are a matching set of daily RV5 estimates for the three indices obtained from the Oxford Man Realised library. These three indices are chosen because they constitute major components of global capital markets in the US and in Europe.
The S&P500 reflects the performance of the top 500 stocks of leading companies in the USA, and is listed on the NYSE (New York Stock Exchange) and (Nasdaq Exchange). The companies included comprise roughly 80% coverage of the available US market capitalisation. The DOW JONES index is a much narrower index that measures the daily price movements of 30 large American companies on the Nasdaq and the New York Stock Exchange and is comprised of blue-chip stocks. The EURO STOXX 50 is a stock index of Eurozone stocks designed by STOXX, an index provider owned by Deutsche Börse Group. STOXX suggests that the aim is “to provide a blue-chip representation of Supersector leaders in the Eurozone”. It is made up of fifty of the largest and most liquid stocks. These indices are representative of blue chip stocks in the USA and Eurozone, plus the broader US market. Thus, these indices are likely to be of great importance and appeal to investors given the nature of the markets that they cover.
Summary statistics for the six series are provided in Table 1. The sample size varies for the three indices varies given a different incidence of holidays in the USA and in Europe. For example, in 2019, there were nine days of holiday related closures on the NYSE but only five in Europe. The total number of sample observations for the USA indices initially comprised 5100 data points whilst the total for the STOXX50 was 5180.
Close to close returns were used because it was thought that these are likely to capture all the information released over a 24 h period and would provide more accurate measures of volatility for the demeaned squared return series used in the regression tests.
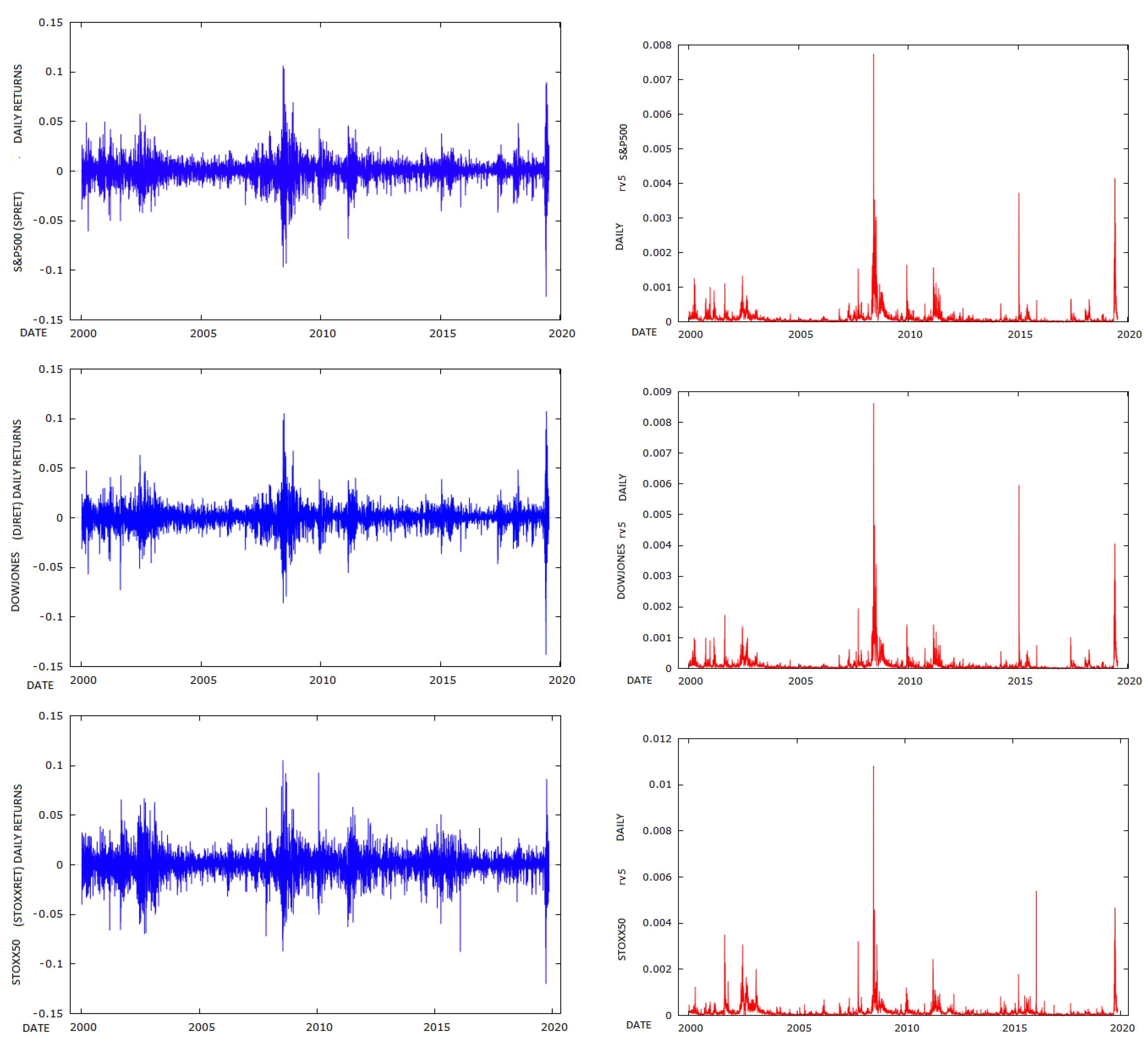
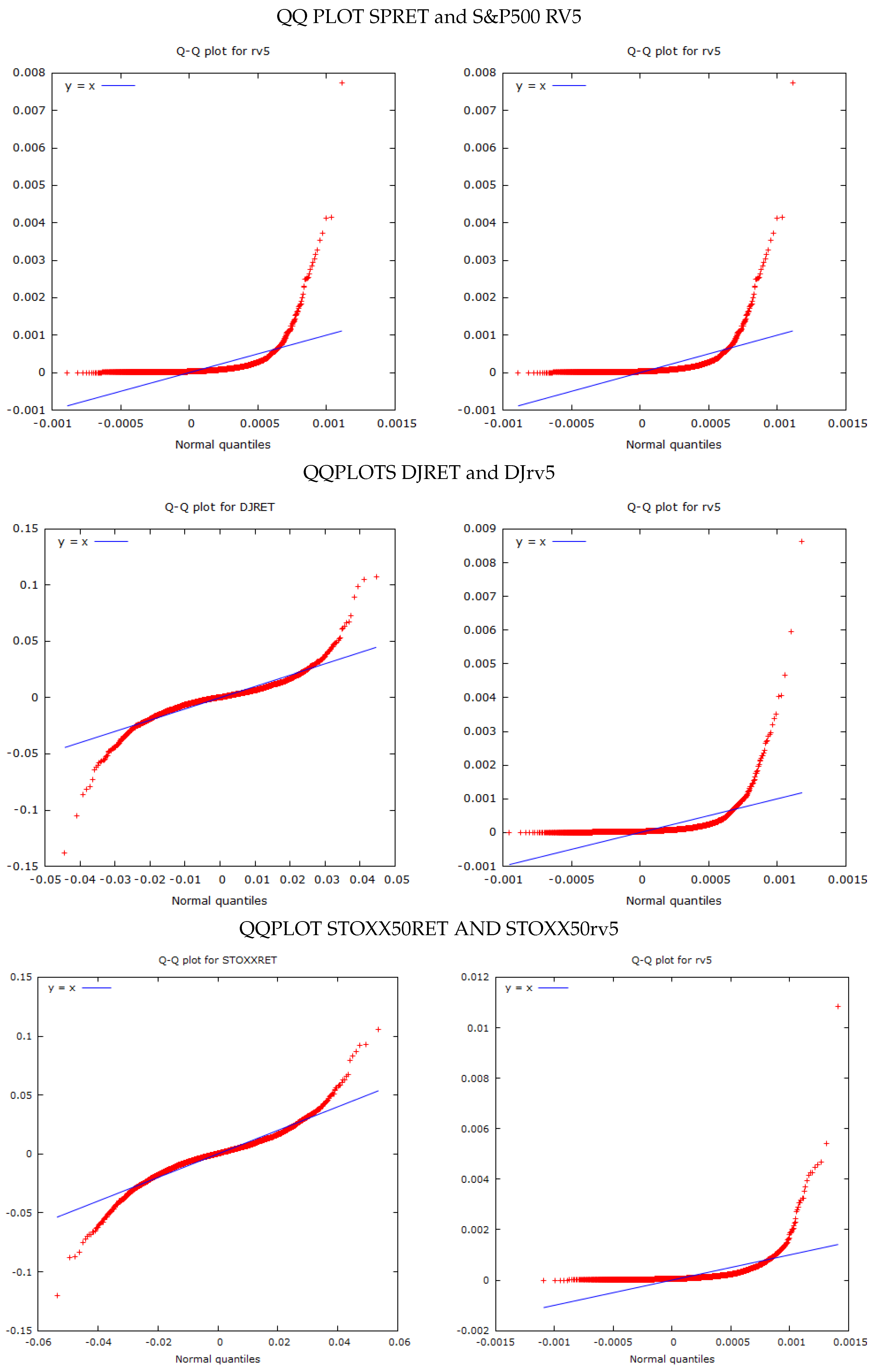
The S&P500 has a mean daily return of 0.01361 per cent and a standard deviation of 1.248 per cent. Plots of the daily returns and RV5 estimates are provided in Figure 1. It had positive excess kurtosis and does not conform to a Gaussian distribution, as can be seen from the QQ plot in Figure 2. The S&P500 RV5 has a mean of 0.00011202 and a standard deviation of 0.00026873. However, Rv5 is measured as a variance, and, if we take the square root of its value and multiply it by 100, it will be on a common scale with the S&P500 returns. We undertake this transformation in some of the comparison plots in subsequent figures. It has very high skewness and kurtosis which is also evident in the QQ plots in Figure 2.
The DOWJONES has a mean return of 0.01496 per cent and a standard deviation of 1.1946 per cent, while STOXX50 has a mean return of −0.0098108 per cent and a standard deviation of 1.4439. DOWJONES RV5 has a mean of 0.00011386 and a standard deviation of 0.00028661, while RV5 of DOWJONES has a mean of 0.00011386 and a standard deviation of 0.00028661. STOXX50 RV5 has a mean of 0.00016066 and a standard deviation of 0.00033556. All three RV5 series are skewed and have high excess kurtosis.
3.2. SV and GARCH Estimates
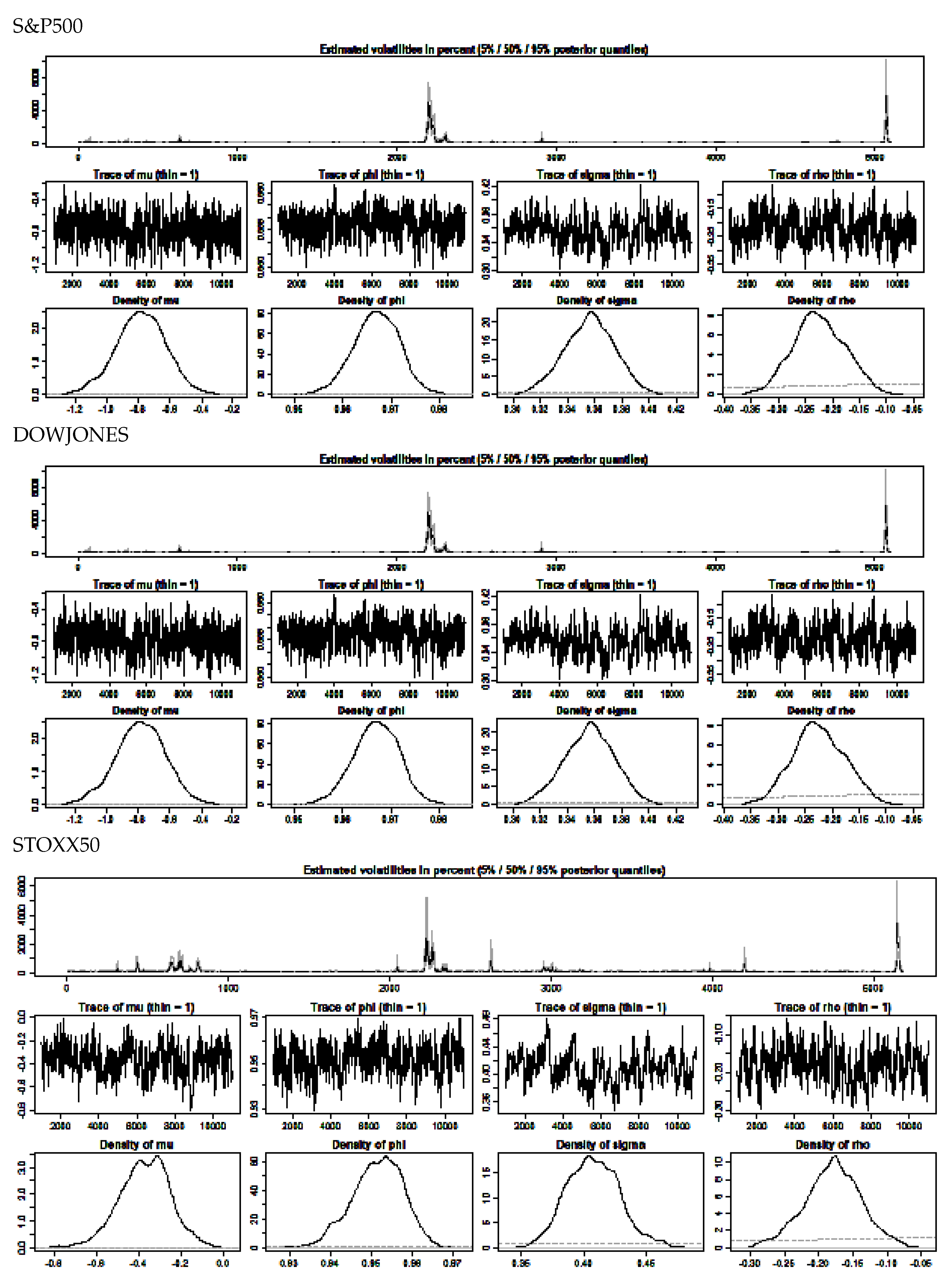
The R library stochvol was used to fit a stochastic volatility model to the S&P500, DOWJONES and STOXX50 de-meaned return series, and Gaussian distributions applied to fit the SV model. Some of the initial parameters for the SV model estimation, as applied to the three series, are shown in Table 2. The SV model applied to the three series produces the volatility estimates shown in Figure 3, while Figure 4 displays a comparison of the volatility estimates for both a GARCH (1,1) model and the SV model, as applied to the three return series. The estimates of volatility are quite similar. The estimates for the GARCH(1,1) model used to obtain conditional volatilities are shown in Table 3. The diagnostic tests (not reported), suggested that the models are a satisfactory fit and that the volatility model parameter estimates are within stable limits.
The benchmark used in this paper is the same as in Allen and McAleer (2020), namely estimates of realised volatility sampled at five-minute intervals, as obtained from Oxford Man. These are employed as the baseline in ordinary least squares regressions adopted to explore the linear correlations between the estimates of the two volatility models and the base RV5 estimates of volatility. The results are shown in panels A, B and C of Table 4.
All the regressions reported in Table 4 use RV5 values as the benchmark dependent variable, for the three index series. The first set of regressions in each panel reports the results of the regression of RV5 on the predictions of volatility obtained from the SV model, lagged by one day. Each of the three estimated coefficients on SV, for the three indices S&P500, DOW JONES and STOXX50, with respective values of 0.000305766, 0.000328020 and 0.000249773 are significant at the 1 per cent level. The respective adjusted R-Squares of these regressions are 0.528418, 0.483024 and 0.398682. The results suggest that the base SV model captures between 40 and 50 per cent of the volatilities of the three index series when the benchmark is RV5.
As a further cross-check of the effectiveness of the two models, we used a further crude estimate of volatility with the demeaned squared daily returns on the three series, in the context of a HISVOL model, which is motivated by Corsi’s (2009) Heterogeneous Autoregressive model of Realized Volatility (HAR-RV).
This crude model produces better results than those using SV and GARCH(1,1) conditional volatilities as explanatory variables. The adjusted R-squared values are 0.540166 for the S&P500 Index in Panel A, 0.445781 in Panel B for DOWJONES, and 0.443043 in Panel C for STOXX50. The adjusted R-square values obtained by this crude approximation to a HAR-RV model all exceed the explanatory values produced by the SV and GARCH(1,1) models in two of the three cases with the exception of the DOWJONES. These results are largely consistent with Allen and McAleer (2020).
3.3. Mincer–Zarnowitz Tests
As an additional test of the accuracy of the forecasts, I used some Mincer and Zarnowitz (1969) regression tests. (I am grateful to a reviewer for this suggestion). The test involves regressing realised values on the forecasts:
The joint hypothesis tested is that and The results of the test on the full sample are shown in Table 5.
The results in Table 5 uniformly and significantly reject the accuracy of the forecasts. However, the forecasts involve long time series with in excess of 5000 observations. As a further check, I ran some rolling Mincer–Zarnowitz regressions using a 100 observation window to explore how frequently the slope coefficient had a value of 1 bounded within two standard deviation intervals. This was done to check the relative frequency of periods in which the forecasts could not reject the null hypothesis. The results for the S&P500 index are shown in Figure 5 (I have omitted the results of the other series in the interests of brevity, but they are available from the author on request).
It can be seen in Figure 5 that there are extended periods of time in which the null hypothesis that the slope coefficient of the results of regressing the actual on the forecast is not significantly different from 1. This highlights the issues related to type one and type two errors. It also is consistent with the Mincer–Zarnowitz tests consistently rejecting the null hypothesis yet the adjusted Rsquares of the regressions of actuals on forecasts being consistently in the range of 40–50%.
3.4. Further Analysis
Kastner (2019) in the factorstochvol R package, together with the Hosszejni and Kastner (2019) vignette, on factorstochvol, demonstrated how to expand the capabilities of the original stochvol package. In particular, they explained how it is possible to construct a multiple regression model with an intercept, two regressors, and SVl residuals using the following construction:
This approach was adopted to include the second and third moments of the index series in the form of de-meaned squared returns and de-meaned cubed returns as the two regressors in the regression model. The intention was to check whether these simple enhancements would improve the performance of the basic stochastic volatility model, in regression tests which used the estimated volatility, as reported in the previous section, as the explanatory variable regressed on the benchmark values of RV5 for the three index series. Table 6 presents the the stochastic volatility estimates for the augmented model and posterior density plots of parameters in are shown in Figure 6.
The values appear to be reasonably well-behaved and the density plots in Figure 6 are acceptable, although the density estimates for the STOXX50 are the weakest of the three with some evidence of bimodality in the mu estimation plot.
A similar simple enhancement was applied to the GARCH(1,1) conditional volatility model in which the mean equation featured the addition of a vector of squared de-meaned returns to assess whether this improved its explanatory performance. The results of the GARCH(1,1) models with enhanced mean equations are not reported in the paper in the interests of brevity, but are available on request. Suffice to say all the estimates appeared to be satisfactory.
Table 7 reports the results of the regression analyses featuring the volatility estimates from both the augmented stochastic volatility and GARCH models. The results are mixed. The benchmark in Table 4 is provided by the ’rule of thumb’ historical volatility model in which 20 lags of de-meaned close-to-close returns were regressed on the Oxford Man RV5 estimates for the three indices. The adjusted R-squares in the cases of the S&P500, DOWJONES and STOXX50 were, respectively, 0.54, 0.54, and 0.44. The augmented SV model for the S&P500, as shown in the first regression in Table 6, has an adjusted R-square of 0.56, a marginal improvement. The original GARCH model for this index had an adjusted R-square of 0.36, which also improves marginally to 0.37.
The DOWJONES historical volatility model’s adjusted R-square of 0.54 is not matched by that for the augmented SV model, which is 0.43 in Table 7. However, the adjusted R-square of the enhanced GARCH model has a value of 0.47, which is a considerable improvement over its previous value in Table 4 of 0.37. Finally, in the case of the STOXX50, the original historical volatility model had an adjusted R-square of 0.44. This is surpassed by that of the augmented SV model which has a value of 0.47. However, the augmented GARCH model shows a marked deterioration with an adjusted R-square of 0.17.
Thus, in two cases out of three, the augmented SV model does have higher explanatory power, when regressed on the RV5 estimates for these three indices. However, the improvement is by a couple of percent, and so it remains a moot point about whether it is of practical worth considering the difference in estimation complexity required to estimate an augmented SV model, as opposed to merely applying 20 lags of squared demeaned returns.
4. Conclusions
The paper featured a further examination of the effectiveness of SV and GARCH(1,1) models, as explanators of model-free estimates of the volatility of S&P500, DOWJONES and STOXX50, using RV samples at 5-minute intervals, as provided by Oxford Man Institute’s Realised Library, as a benchmark. In order to provide further contrast, 1 also used lags of squared demeaned daily returns on FTSE to provide a simple alternative estimate of daily volatility. The effectiveness of these three methods was explored via the application of ordinary least squares (OLS) regression analysis. Poon and Granger (2005) provided motivation in their analysis of 66 studies of this topic in which they noted that, at that time, there were an insufficient number of SV studies to provide a comparison between GARCH and HISVOL models. My intention in the paper was to further address this sparsity in the literature.
The enhanced estimates of SV were obtained by means of the R package factorstockvol and the addition of a regression matrix which included vectors of the second and third moments of the demeaned return series for the three indices. The enhanced GARCH(1,1) model was obtained by adding the squared demeaned return series to the mean equation.
The results were consistent with those of an earlier companion study by Allen and McAleer (2020) which featured the FTSE. In all the three base cases, the simple expedient of adopting 20 lags of squared demeaned returns in the regression model, out-performing the volatility estimates from those of the base SV model and the GARCH(1,1) models.
The enhanced SV model did show higher explanatory power than the base models in the cases of both the S&P500 and the STOXX50. The results from the enhanced GARCH model were also variable, but in no case matched those of the simple HISVOL model.
However, both performed relatively poorly as compared with the simple expedient of using squared demeaned daily returns on the three indices, in order to predict RV5 volatility. The results support Poon and Granger (2005), in that neither GARCH or SV models outperform a simple form of a HISVOL model in this sample when RV sampled at 5-minute intervals are used as a benchmark. In the case of the enhanced SV model, there was evidence of a marginal increase in adjusted R-squares in two cases out of three. It is a moot point as to whether the difficulty of the estimation of an enhanced SV model justifies the marginal gain in explanatory power.
The results are also consistent with Perron and Shi (2020) who demonstrate that squared low-frequency returns can be expressed in terms of the temporal aggregation of a high-frequency series.
Funding
This research received no external funding.
Acknowledgments
The author is grateful to three anonymous reviewers and the editors for their helpful comments.
Conflicts of Interest
The author declares no conflict of interest.
References
- Allen, David Edmund, and Michael McAleer. 2020. Do we need Stochastic Volatility and Generalised Autoregressive Conditional Heteroscedasticity? Comparing squared End-Of-Day returns on FTSE. Risks 8: 12. [Google Scholar] [CrossRef] [Green Version]
- Allen, David Edmund, Ron Amram, and Michael McAleer. 2013. Volatility spillovers from the Chinese stock market to economic neighbours. Mathematics and Computers in Simulation 94: 238–57. [Google Scholar] [CrossRef] [Green Version]
- Andersen, Torben. G., Tim Bollerslev, Frances X. Diebold, and Heiko Ebens. 2001. The distribution of realized stock return volatility. Journal of Financial Economics 61: 43–76. [Google Scholar] [CrossRef]
- Andersen, Thorben. G., Tim Bollerslev, Frances. X. Diebold, and Paul Labys. 2003. Modeling and forecasting realized volatility. Econometrica 71: 529–626. [Google Scholar] [CrossRef] [Green Version]
- Asai, Manabu, Michael McAleer, and Jun Yu. 2006. Multivariate stochastic volatility: A review. Econometric Reviews 25: 145–75. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole E., and Neil Shephard. 2002. Econometric analysis of realised volatility and its use in estimating stochastic volatility models. Journal of the Royal Statistical Society Series B 63: 253–80. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole E., and Neil Shephard. 2003. Realized power variation and stochastic volatility models. Bernoulli 9: 243–65. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef] [Green Version]
- Bos, Charles. S. 2012. Relating stochastic volatility estimation methods. In Handbook of Volatility Models and Their Applications. Edited by Luc Bauwens, Christian Hafner and Sebastien Laurent. Hoboken: John Wiley & Sons, pp. 147–74. [Google Scholar]
- Chib, Sidhartha, Federico Nardari, and Neil Shephard. 2006. Analysis of High Dimensional Multivariate Stochastic Volatility Models. Journal of Econometrics 134: 341–71. [Google Scholar] [CrossRef]
- Christensen, Bent. J., and Nagpurnanan. R. Prabhala. 1998. The relation between implied and realized volatility. Journal of Financial Economics 37: 125–50. [Google Scholar] [CrossRef]
- Clark, Peter K. 1973. A subordinated stochastic process model with finite variance for speculative prices. Econometrica 41: 135–55. [Google Scholar] [CrossRef]
- Corsi, Fulvio. 2009. A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics 7: 174–96. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive conditional heteroskedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Dacorogna, Michel M., Ulrich A. Muller, Richard B. Olsen, and Olivier V. Pictet. 1998. Modelling short term volatility with GARCH and HARCH. In Nonlinear Modelling of High Frequency Financial Time Series. Edited by Christian Dunis and Bin Zhou. Chichester: Wiley. [Google Scholar]
- Ghysels, Eric, Andrew C. Harvey, and Eric Renault. 1996. Stochastic volatility. In Statistical Methods in Finance, Volume 14, Handbook of Statistics. Edited by Gangadharrao S. Maddala and Chandra. R. Rao. Amsterdam: Elsevier, pp. 119–91. [Google Scholar]
- Heber, Gerd, Ascar Lunde, Neil Shephard, and Kevin Sheppard. 2009. Oxford-Man Institute’s Realized Library, Oxford-Man Institute, University of Oxford. Available online: https://realized.oxford-man.ox.ac.uk/data (accessed on 3 May 2020).
- Jacquier, Eric, Nicholas G. Polson, and Peter E. Rossi. 1994. Bayesian analysis of stochastic volatility models. Journal of Business & Economic Statistics 12: 371–89. [Google Scholar]
- Kastner, Gregor, and Sylvia Frühwirth-Schnatter. 2014. Ancillarity-sufficiency interweaving strategy (ASIS) for boosting MCMC estimation of stochastic volatility models. Computational Statistics and Data Analysis 76: 408–23. [Google Scholar] [CrossRef] [Green Version]
- Kastner, Gregor. 2016. Dealing with stochastic volatility in time series using the R package stochvol. Journal of Statistical Software 69: 1–30. [Google Scholar] [CrossRef] [Green Version]
- Kastner, Gregor. 2019. Factorstochvol: Bayesian Estimation of (Sparse) Latent Factor Stochastic Volatility Models. R package version 0.9.3. Available online: https://cran.r-project.org/package=factorstochvol (accessed on 3 May 2020).
- Kastner, Gregor, Sylvia Frühwirth-Schnatter, and Hedibert. F. Lopes. 2017. Efficient Bayesian Inference for Multivariate Factor Stochastic Volatility Models. Journal of Computational and Graphical Statistics 26: 905–17. [Google Scholar] [CrossRef] [Green Version]
- Hosszejni, Darjus, and Gregor Kastner. 2019. Modeling Univariate and Multivariate Stochastic Volatility in R with Stochvol and Factorstochvol, R package vignette. Available online: https://CRAN.R-project.org/package=factorstochvol/vignettes/paper.pdf (accessed on 3 May 2020).
- Kim, Sangjoon, Neil Shephard, and Siddhartha Chib. 1998. Stochastic volatility: Likelihood inference and comparison with ARCH models. Review of Economic Studies 65: 361–93. [Google Scholar] [CrossRef]
- McAleer, Michael. 2005. Automated inference and learning in modeling financial volatility. Econometric Theory 21: 232–61. [Google Scholar] [CrossRef] [Green Version]
- McCausland, William J., Shirley Miller, and Denis Pelletier. 2011. Simulation smoothing for state-space models: A computational efficiency analysis. Computational Statistics and Data Analysis 55: 199–212. [Google Scholar] [CrossRef]
- Mincer, Jacob, and Victor Zarnowitz. 1969. The evaluation of economic forecasts, a chapter. In Economic Forecasts and Expectations: Analysis of Forecasting Behavior and Performance. Cambridge: National Bureau of Economic Research, pp. 3–46. [Google Scholar]
- Perron, Pierre, and Wendong Shi. 2020. Temporal aggregation and Long Memory for asset price volatility. Journal of Risk and Financial Management 13: 182. [Google Scholar] [CrossRef]
- Poon, Ser-Huang, and Clive W. T. Granger. 2003. Forecasting volatility in financial markets: A review. Journal of Economic Literature 41: 478–539. [Google Scholar] [CrossRef]
- Poon, Ser-Huang, and Clive. W. T. Granger. 2005. Practical issues in forecasting volatility. Financial Analysts Journal 61: 45–56. [Google Scholar] [CrossRef] [Green Version]
- Poterba, James, and Larry Summers. 1986. The persistence of volatility and stock market fluctuations. American Economic Review 76: 1124–41. [Google Scholar]
- Rue, Havard. 2001. Fast sampling of Gaussian Markov random fields. Journal of the Royal Statistical Society, Series B 63: 325–38. [Google Scholar] [CrossRef]
- Schwert, G. William. 1989. Why does stock market volatility change over time? Journal of Finance 44: 1115–53. [Google Scholar] [CrossRef]
- Shephard, Neil, and Kevin Sheppard. 2010. Realising the future: Forecasting with high-frequency-based volatility (HEAVY) models. Journal of Applied Econometrics 25: 197–231. [Google Scholar] [CrossRef] [Green Version]
- Taylor, Stephen J. 1982. Financial returns modelled by the product of two stochastic processes: A study of daily sugar prices 1691–79. In Time Series Analysis: Theory and Practice 1. Edited by Torben Anderson. Amsterdam: North-Holland, pp. 203–26. [Google Scholar]
- Taylor, Stephen J. 1994. Modeling stochastic volatility: A review and comparative study. Mathematical Finance 4: 183–204. [Google Scholar] [CrossRef]
- Taylor, Stephen J., and Xinzhong Xu. 1997. The incremental volatility information in one million foreign exchange quotations. Journal of Empirical Finance 4: 317–40. [Google Scholar] [CrossRef]
- Tauchen, George E., and Mark Pitts. 1983. The price variability-volume relationship on speculative markets. Econometrica 5: 485–505. [Google Scholar] [CrossRef] [Green Version]
- Tsay, Ruey S. 1987. Conditional heteroscedastic time series models. Journal of the American Statistical Association 82: 590–604. [Google Scholar] [CrossRef]
- Yu, Yaming, and Xia-Li Meng. 2011. To center or not to center: That is not the question—An ancillarity-suffiency interweaving strategy (ASIS) for boosting MCMC efficiency. Journal of Computational and Graphical Statistics 20: 531–70. [Google Scholar] [CrossRef]
Figure 1.
Series plots.

Figure 2.
QQ plots.

Figure 3.
Posterior density plots of parameters in .

Figure 4.
Comparison SV and GARCH(1,1) Volatility Estimates.

Figure 5.
Mincer–Zarnowitz rolling regression slope coefficients bounded by two standard deviations.
Figure 5.
Mincer–Zarnowitz rolling regression slope coefficients bounded by two standard deviations.

Figure 6.
Posterior density plots of parameters in .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary statistics.
| Mean | Median | Minimum | Maximum | Standard Deviation | Skewness | Excess Kurtosis | |
|---|---|---|---|---|---|---|---|
| SPRET | 0.000136 | 0.000540 | −0.126700 | 0.106420 | 0.012485 | −0.360540 | 10.874 |
| SPRV5 | 0.000112 | 0.000047 | 0.000001 | 0.007748 | 0.000269 | 10.6520 | 188.60 |
| DJRET | 0.000150 | 0.000488 | −0.138070 | 0.107540 | 0.011946 | −0.376640 | 13.380 |
| DJRV5 | 0.000114 | 0.000049 | 0.000001 | 0.008624 | 0.000287 | 12.0870 | 238.02 |
| STOXX50RET | −0.000098 | 0.000236 | −0.120050 | 0.105540 | 0.014399 | −0.225470 | 5.8411 |
| STOXX50RV5 | 0.000161 | 0.000081 | 0.000000 | 0.010827 | 0.000336 | 12.0260 | 256.24 |
| KEY: | |||||||
| SPRET | Continuously compounded close to close return on the S&P500 Index | ||||||
| SPRV5 | Daily realised volatility on the S&P500 Index sampled at 5 min intervals provided by Oxford Man | ||||||
| DJRET | Continuously compounded close to close return on the DOWJONES Index | ||||||
| DJRV5 | Daily realised volatility on the S&P500 Index sampled at 5 min intervals provided by Oxford Man | ||||||
| STOXX50RET | Continuously compounded close to close return on the S&P500 Index | ||||||
| STOXX50RV5 | Daily realised volatility on the S&P500 Index sampled at 5 min intervals provided by Oxford Man | ||||||
Table 2.
Stochastic volatility estimates.
| Summary of 1000 MCMC Draws after Burn in of 1000 | |||||
|---|---|---|---|---|---|
| Prior Distributions | |||||
| mean = 0 | S.D. = 100 | ||||
| S&P500 | |||||
| Posterior draws thinning = 1 | |||||
| Mean | S.D. | 5% | 50% | 95% | |
| −9.4565 | 0.15973 | −9.7172 | −9.4562 | −9.193 | |
| 0.9803 | 0.00377 | 0.9739 | 0.9804 | 0.986 | |
| 0.2154 | 0.01526 | 0.1902 | 0.2152 | 0.241 | |
| 0.0089 | 0.00071 | 0.0078 | 0.0088 | 0.010 | |
| 0.0466 | 0.00659 | 0.0362 | 0.0463 | 0.058 | |
| DOWJONES | |||||
| Posterior draws thinning = 1 | |||||
| Mean | S.D. | 5% | 50% | 95% | |
| −9.5491 | 0.14899 | −9.7890 | −9.7890 | −9.3053 | |
| 0.9784 | 0.00393 | 0.9718 | 0.9785 | 0.9846 | |
| 0.2222 | 0.01509 | 0.1982 | 0.2214 | 0.2470 | |
| 0.0085 | 0.00063 | 0.0075 | 0.0084 | 0.0095 | |
| 0.0496 | 0.00676 | 0.0393 | 0.0490 | 0.0610 | |
| STOXX50 | |||||
| Posterior draws thinning = 1 | |||||
| Mean | S.D. | 5% | 50% | 95% | |
| −8.969 | 0.15544 | −9.2223 | −8.969 | −8.719 | |
| 0.983 | 0.00346 | 0.9774 | 0.983 | −8.719 | |
| 0.177 | 0.01362 | 0.1556 | 0.176 | 0.200 | |
| 0.011 | 0.00088 | 0.0099 | 0.011 | 0.200 | |
| 0.031 | 0.00484 | 0.0242 | 0.031 | 0.040 | |
Table 3.
GARCH(1,1) fitted to INDICES RETURNS.
| Coefficients | Standard Error | T Statistic | |
|---|---|---|---|
| S&P500 | |||
| 0.00071466 | 0.0001000 | 7.144 *** | |
| 0.0000013037 | 0.0000002911 | 4.479 *** | |
| 0.12429 | 0.0118 | 10.530 *** | |
| 0.87470 | 0.01081 | 80.918 *** | |
| DOWJONES | |||
| 0.00028945 | 0.0001063 | 2.723 *** | |
| 0.000001861 | 0.000000258 | 7.212 *** | |
| 0.12121 | 0.009328 | 12.995 *** | |
| 0.86583 | 000.9399 | 92.123 *** | |
| STOXX50 | |||
| 0.000093821 | 0.0001411 | 0.665 | |
| 0.0000024108 | 0.000000407 | 5.911 *** | |
| 0.099385 | 0.008582 | 11.580 *** | |
| 0.89020 | 0.009059 | 98.266 *** | |
Note: *** Indicates significance at the 1 per cent level.
Table 4.
Regression analysis of the three volatility models as Explanators of RV5.
| S&P500 | ||||
|---|---|---|---|---|
| OLS, using observations 2000-01-06–2020-04-30 (T = 5098) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | −0.000193903 | 4.80241 × 10 | −40.38 | 0.0000 |
| STVOL_1 | 0.000305766 | 4.04560 × 10 | 75.58 | 0.0000 |
| Mean dependent var | 0.000112 | S.D. dependent var | 0.000269 | |
| Sum squared resid | 0.000174 | S.E. of regression | 0.000185 | |
| 0.528511 | Adjusted | 0.528418 | ||
| 5712.306 | P-value(F) | 0.000000 | ||
| 0.355673 | Durbin–Watson | 1.288578 | ||
| OLS, using observations 2000-01-06–2020-04-30 (T = 5098) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | −0.000186320 | 5.58228 × 10 | −33.38 | 0.0000 |
| garchh_t_1 | 0.000282384 | 4.54881 × 10 | 62.08 | 0.0000 |
| Mean dependent var | 0.000112 | S.D. dependent var | 0.000269 | |
| Sum squared resid | 0.000210 | S.E. of regression | 0.000203 | |
| 0.430599 | Adjusted | 0.430488 | ||
| 3853.762 | P-value(F) | 0.000000 | ||
| 0.432641 | Durbin–Watson | 1.134608 | ||
| OLS, using observations 2000-02-02–2020-04-30 (T = 5079) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 3.02687 × 10 | 2.84918 × 10 | 10.62 | 0.0000 |
| sq_DMSPRET_1 | 0.174138 | 0.00556030 | 31.32 | 0.0000 |
| sq_DMSPRET_2 | 0.0933966 | 0.00559548 | 16.69 | 0.0000 |
| sq_DMSPRET_3 | 0.0527851 | 0.00588575 | 8.968 | 0.0000 |
| sq_DMSPRET_4 | 0.0280498 | 0.00588689 | 4.765 | 0.0000 |
| sq_DMSPRET_5 | 0.0591621 | 0.00588274 | 10.06 | 0.0000 |
| sq_DMSPRET_6 | 0.0387770 | 0.00590617 | 6.565 | 0.0000 |
| sq_DMSPRET_7 | 0.0127639 | 0.00593373 | 2.151 | 0.0315 |
| sq_DMSPRET_8 | 0.0128494 | 0.00591714 | 2.172 | 0.0299 |
| sq_DMSPRET_9 | 0.0460289 | 0.00591518 | 7.781 | 0.0000 |
| sq_DMSPRET_10 | 0.0108100 | 0.00588990 | 1.835 | 0.0665 |
| sq_DMSPRET_11 | −0.0125045 | 0.00589057 | −2.123 | 0.0338 |
| sq_DMSPRET_12 | 0.00683578 | 0.00591643 | 1.155 | 0.2480 |
| sq_DMSPRET_13 | 0.000837936 | 0.00591795 | 0.1416 | 0.8874 |
| sq_DMSPRET_14 | −0.00804767 | 0.00593584 | −1.356 | 0.1752 |
| sq_DMSPRET_15 | −0.00239430 | 0.00590724 | −0.4053 | 0.6853 |
| sq_DMSPRET_16 | −0.0108916 | 0.00588602 | −1.850 | 0.0643 |
| sq_DMSPRET_17 | 0.00482912 | 0.00588926 | 0.8200 | 0.4123 |
| sq_DMSPRET_18 | 0.0125097 | 0.00593287 | 2.109 | 0.0350 |
| sq_DMSPRET_19 | 0.0123520 | 0.00564065 | 2.190 | 0.0286 |
| sq_DMSPRET_20 | −0.00717624 | 0.00560040 | −1.281 | 0.2001 |
| Mean dependent var | 0.000112 | S.D. dependent var | 0.000269 | |
| Sum squared resid | 0.000169 | S.E. of regression | 0.000183 | |
| 0.541977 | Adjusted | 0.540166 | ||
| 299.2563 | P-value(F) | 0.000000 | ||
| 0.283092 | Durbin–Watson | 1.433782 | ||
| OLS, using observations 2000-01-06–2020-04-30 (T = 5094) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | −0.000198625 | 5.37151 × 10 | −36.98 | 0.0000 |
| SVDJ_1 | 0.000328020 | 4.75466 × 10 | 68.99 | 0.0000 |
| Mean dependent var | 0.000114 | S.D. dependent var | 0.000287 | |
| Sum squared resid | 0.000216 | S.E. of regression | 0.000206 | |
| 0.483125 | Adjusted | 0.483024 | ||
| 4759.515 | P-value(F) | 0.000000 | ||
| 0.331936 | Durbin–Watson | 1.336075 | ||
| OLS, using observations 2000-01-06–2020-04-30 (T = 5094) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | −0.000170947 | 6.16017 × 10 | −27.75 | 0.0000 |
| Djht_1 | 0.000280420 | 5.18265 × 10 | 54.11 | 0.0000 |
| Mean dependent var | 0.000114 | S.D. dependent var | 0.000287 | |
| Sum squared resid | 0.000266 | S.E. of regression | 0.000228 | |
| 0.365056 | Adjusted | 0.364932 | ||
| 2927.610 | p-value(F) | 0.000000 | ||
| 0.434841 | Durbin–Watson | 1.130290 | ||
| OLS, using observations 2000-01-04–2020-04-30 (T = 5075) | ||||
| Dependent variable: lrv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 0.0405870 | 0.00329492 | 12.32 | 0.0000 |
| SQDMDJRET_1 | 0.000165523 | 6.55973 × 10 | 25.23 | 0.0000 |
| SQDMDJRET_2 | 0.000101750 | 6.61717 × 10 | 15.38 | 0.0000 |
| SQDMDJRET_3 | 5.22487 × 10 | 6.99793 × 10 | 7.466 | 0.0000 |
| SQDMDJRET_4 | 2.10587 × 10 | 6.99864 × 10 | 3.009 | 0.0026 |
| SQDMDJRET_5 | 6.58804 × 10 | 7.00022 × 10 | 9.411 | 0.0000 |
| SQDMDJRET_6 | 4.64120 × 10 | 7.00145 × 10 | 6.629 | 0.0000 |
| SQDMDJRET_7 | 1.56715 × 10 | 7.13269 × 10 | 0.2197 | 0.8261 |
| SQDMDJRET_8 | 1.54284 × 10 | 7.11737 × 10 | 0.2168 | 0.8284 |
| SQDMDJRET_9 | 4.60489 × 10 | 7.11644 × 10 | 6.471 | 0.0000 |
| SQDMDJRET_10 | −2.98185 × 10 | 7.06670 × 10 | −0.4220 | 0.6731 |
| SQDMDJRET_11 | −1.35137 × 10 | 7.06710 × 10 | −1.912 | 0.0559 |
| SQDMDJRET_12 | −2.77575 × 10 | 7.11818 × 10 | −0.3900 | 0.6966 |
| SQDMDJRET_13 | 5.94860 × 10 | 7.11930 × 10 | 0.8356 | 0.4034 |
| SQDMDJRET_14 | −8.20421 × 10 | 7.13518 × 10 | −1.150 | 0.2503 |
| SQDMDJRET_15 | −8.26171 × 10 | 7.00344 × 10 | −1.180 | 0.2382 |
| SQDMDJRET_16 | −4.30980 × 10 | 7.00422 × 10 | −0.6153 | 0.5384 |
| SQDMDJRET_17 | 6.42163 × 10 | 7.00281 × 10 | 0.9170 | 0.3592 |
| SQDMDJRET_18 | 2.34879 × 10 | 7.08619 × 10 | 3.315 | 0.0009 |
| SQDMDJRET_19 | 2.02923 × 10 | 6.69703 × 10 | 3.030 | 0.0025 |
| SQDMDJRET_20 | −4.02896 × 10 | 6.63951 × 10 | −0.6068 | 0.5440 |
| Mean dependent var | 0.113763 | S.D. dependent var | 0.287164 | |
| Sum squared resid | 230.9808 | S.E. of regression | 0.213782 | |
| 0.447966 | Adjusted | 0.445781 | ||
| 205.0615 | p-value(F) | 0.000000 | ||
| 0.324610 | Durbin–Watson | 1.350773 | ||
| OLS, using observations 2000-01-06–2020-04-30 (T = 5179) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | −0.000255606 | 7.97034 × 10 | −32.07 | 0.0000 |
| STOXXSV_1 | 0.000249773 | 4.26226 × 10 | 58.60 | 0.0000 |
| Mean dependent var | 0.000161 | S.D. dependent var | 0.000336 | |
| Sum squared resid | 0.000351 | S.E. of regression | 0.000260 | |
| 0.398798 | Adjusted | 0.398682 | ||
| 3434.088 | p-value(F) | 0.000000 | ||
| 0.334086 | Durbin–Watson | 1.331768 | ||
| OLS, using observations 2000-01-05–2020-04-30 (T = 5179) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | −3.19171 × 10 | 4.70679 × 10 | −0.6781 | 0.4977 |
| h2STOXX50_1 | 0.783757 | 0.0140212 | 55.90 | 0.0000 |
| Mean dependent var | 0.000161 | S.D. dependent var | 0.000336 | |
| Sum squared resid | 0.000364 | S.E. of regression | 0.000265 | |
| 0.376384 | Adjusted | 0.376264 | ||
| 3124.586 | p-value(F) | 0.000000 | ||
| 0.342843 | Durbin–Watson | 1.314043 | ||
| OLS, using observations 2000-02-02–2020-04-30 (T = 5160) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | ct-ratio | p-value | |
| const | 2.05927 × 10 | 4.29557 × 10 | 4.794 | 0.0000 |
| sq_DMSTOXXRET_1 | 0.118968 | 0.00666728 | 17.84 | 0.0000 |
| sq_DMSTOXXRET_2 | 0.120534 | 0.00666684 | 18.08 | 0.0000 |
| sq_DMSTOXXRET_3 | 0.0933684 | 0.00669582 | 13.94 | 0.0000 |
| sq_DMSTOXXRET_4 | 0.0896290 | 0.00678649 | 13.21 | 0.0000 |
| sq_DMSTOXXRET_5 | 0.0342222 | 0.00682410 | 5.015 | 0.0000 |
| sq_DMSTOXXRET_6 | 0.0105941 | 0.00684945 | 1.547 | 0.1220 |
| sq_DMSTOXXRET_7 | 0.0193777 | 0.00684880 | 2.829 | 0.0047 |
| sq_DMSTOXXRET_8 | 0.0415985 | 0.00685618 | 6.067 | 0.0000 |
| sq_DMSTOXXRET_9 | 0.0676568 | 0.00686950 | 9.849 | 0.0000 |
| sq_DMSTOXXRET_10 | 0.0648663 | 0.00687561 | 9.434 | 0.0000 |
| sq_DMSTOXXRET_11 | 0.00745897 | 0.00687600 | 1.085 | 0.2781 |
| sq_DMSTOXXRET_12 | 0.00363238 | 0.00687086 | 0.5287 | 0.5971 |
| sq_DMSTOXXRET_13 | 0.00415015 | 0.00685846 | 0.6051 | 0.5451 |
| sq_DMSTOXXRET_14 | 0.00309319 | 0.00685311 | 0.4514 | 0.6518 |
| sq_DMSTOXXRET_15 | 0.0459385 | 0.00685415 | 6.702 | 0.0000 |
| sq_DMSTOXXRET_16 | −0.0110292 | 0.00682975 | −1.615 | 0.1064 |
| sq_DMSTOXXRET_17 | 3.58184 × 10 | 0.00680192 | 0.005266 | 0.9958 |
| sq_DMSTOXXRET_18 | −0.0226702 | 0.00671209 | −3.378 | 0.0007 |
| sq_DMSTOXXRET_19 | 0.00604883 | 0.00668237 | 0.9052 | 0.3654 |
| sq_DMSTOXXRET_20 | −0.0196779 | 0.00668193 | −2.945 | 0.0032 |
| Mean dependent var | 0.000161 | S.D. dependent var | 0.000336 | |
| Sum squared resid | 0.000324 | S.E. of regression | 0.000251 | |
| 0.445202 | Adjusted | 0.443043 | ||
| 206.1915 | p-value(F) | 0.000000 | ||
| 0.216381 | Durbin–Watson | 1.567234 | ||
Note: squared de-meaned return series used for the three index series.
Table 5.
Mincer–Zarnowitz regressions.
| Method | Test Statistic | Probability |
|---|---|---|
| S&P500 | ||
| STOCHVOL | 1.06838 × 10 | 0.0 |
| GARCH | 1.01522 × 10 | 0.0 |
| sq_DMSPRET-1 | 2205.89 | 0.0 |
| DOWJONES | ||
| STOCHVOL | 7.72384 × 10 | 0.0 |
| GARCH | 7.33155 × 10 | 0.0 |
| sq_DMDJRET-1 | 1.84768 × 10 | 0.0 |
| STOXX50 | ||
| STOCHVOL | 626.635 | 0.0 |
| GARCH | 2.7139 × 10 | 0.0 |
| sq_DMSTOXRET-1 | 5449.58 | 0.0 |
Table 6.
Stochastic volatility estimates augmented SV model.
| Summary of 1000 MCMC draws after burn in of 1000 | |||||
|---|---|---|---|---|---|
| Prior Distributions | |||||
| mean = 0 | S.D. = 100 | ||||
| S&P500 | |||||
| Posterior draws thinning = 1 | |||||
| Mean | S.D. | 5% | 50% | 95% | |
| −0.78 | 0.1562 | −1.05 | −0.78 | −0.53 | |
| 0.97 | 0.0048 | 0.96 | 0.97 | 0.97 | |
| 0.36 | 0.0182 | 0.32 | 0.36 | 0.39 | |
| 0.68 | 0.0529 | 0.59 | 0.68 | 0.77 | |
| 0.13 | 0.0130 | 0.11 | 0.13 | 0.15 | |
| DOWJONES | |||||
| Posterior draws thinning = 1 | |||||
| Mean | S.D. | 5% | 50% | 95% | |
| −0.907 | 0.1447 | −1.14 | −0.913 | −0.656 | |
| 0.957 | 0.0058 | 0.95 | 0.957 | 0.966 | |
| 0.437 | 0.0232 | 0.40 | 0.435 | 0.478 | |
| 0.637 | 0.0462 | 0.56 | 0.634 | 0.720 | |
| 0.191 | 0.0204 | 0.16 | 0.189 | 0.229 | |
| STOXX50 | |||||
| Posterior draws thinning = 1 | |||||
| Mean | S.D. | 5% | 50% | 95% | |
| −0.37 | 0.1197 | −0.57 | −0.37 | −0.18 | |
| 0.95 | 0.0062 | 0.94 | 0.95 | 0.96 | |
| 0.41 | 0.0211 | 0.37 | 0.41 | 0.44 | |
| 0.83 | 0.0494 | 0.75 | 0.83 | 0.92 | |
| 0.17 | 0.0173 | 0.14 | 0.17 | 0.20 | |
Table 7.
Regression analysis of the three augmented stochastic volatility and GARCH models as explanators of RV5.
Table 7.
Regression analysis of the three augmented stochastic volatility and GARCH models as explanators of RV5.
| S&P500 | ||||
|---|---|---|---|---|
| OLS, using observations 2000-01-05–2020-04-30 (T = 5098) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 4.80570 × 10 | 2.59906 × 10 | 18.49 | 0.0000 |
| SVREGSPRET_1 | 5.61407 × 10 | 6.87701 × 10 | 81.64 | 0.0000 |
| Mean dependent var | 0.000112 | S.D. dependent var | 0.000269 | |
| Sum squared resid | 0.000160 | S.E. of regression | 0.000177 | |
| 0.566679 | Adjusted | 0.566594 | ||
| 6664.347 | p-value(F) | 0.000000 | ||
| 0.288688 | Durbin–Watson | 1.422414 | ||
| OLS, using observations 2000-01-05–2020-04-30 (T = 5098) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 0.000136717 | 3.02817 × 10 | 45.15 | 0.0000 |
| yhat3_1 | −0.0810177 | 0.00148855 | −54.43 | 0.0000 |
| Mean dependent var | 0.000112 | S.D. dependent var | 0.000269 | |
| Sum squared resid | 0.000233 | S.E. of regression | 0.000214 | |
| 0.367610 | Adjusted | 0.367486 | ||
| 2962.324 | p-value(F) | 0.000000 | ||
| 0.248686 | Durbin–Watson | 1.502451 | ||
| DOWJONES | ||||
| OLS, using observations 2000-01-05–2020-04-30 (T = 5094) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 7.08759 × 10 | 3.11272 × 10 | 22.77 | 0.0000 |
| DJSVREG_1 | 3.42022 × 10 | 5.52569 × 10 | 61.90 | 0.0000 |
| Mean dependent var | 0.000114 | S.D. dependent var | 0.000287 | |
| Sum squared resid | 0.000239 | S.E. of regression | 0.000217 | |
| 0.429352 | Adjusted | 0.429240 | ||
| 3831.187 | p-value(F) | 0.000000 | ||
| 0.382376 | Durbin–Watson | 1.235179 | ||
| OLS, using observations 2000-01-06–2020-04-30 (T = 5093) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 0.000144841 | 2.96368 × 10 | 48.87 | 0.0000 |
| yhat7_1 | −0.00213366 | 3.18142 × 10 | −67.07 | 0.0000 |
| Mean dependent var | 0.000114 | S.D. dependent var | 0.000287 | |
| Sum squared resid | 0.000222 | S.E. of regression | 0.000209 | |
| 0.469072 | Adjusted | 0.468968 | ||
| 4497.872 | p-value(F) | 0.000000 | ||
| 0.347045 | Durbin–Watson | 1.305745 | ||
| OLS, using observations 2000-01-05–2020-04-30 (T = 5179) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 3.92593 × 10 | 3.84434 × 10 | 10.21 | 0.0000 |
| STOXXREGFAC_1 | 1.04919 × 10 | 1.55219 × 10 | 67.59 | 0.0000 |
| Mean dependent var | 0.000161 | S.D. dependent var | 0.000336 | |
| Sum squared resid | 0.000310 | S.E. of regression | 0.000245 | |
| 0.468805 | Adjusted | 0.468702 | ||
| 4568.947 | p-value(F) | 0.000000 | ||
| 0.212647 | Durbin–Watson | 1.574424 | ||
| OLS, using observations 2000-01-05–2020-04-30 (T = 5179) | ||||
| Dependent variable: rv5 | ||||
| Coefficient | Std. Error | t-ratio | p-value | |
| const | 0.000191985 | 4.32834 × 10 | 44.36 | 0.0000 |
| yhat2_1 | −0.111512 | 0.00332039 | −33.58 | 0.0000 |
| Mean dependent var | 0.000161 | S.D. dependent var | 0.000336 | |
| Sum squared resid | 0.000479 | S.E. of regression | 0.000304 | |
| 0.178889 | Adjusted | 0.178731 | ||
| 1127.876 | p-value(F) | 7.0 × 10 | ||
| 0.258795 | Durbin–Watson | 1.482403 | ||
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Allen, D.E. Stochastic Volatility and GARCH: Do Squared End-of-Day Returns Provide Similar Information? J. Risk Financial Manag. 2020, 13, 202. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm13090202
AMA Style
Allen DE. Stochastic Volatility and GARCH: Do Squared End-of-Day Returns Provide Similar Information? Journal of Risk and Financial Management. 2020; 13(9):202. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm13090202
Chicago/Turabian StyleAllen, David Edmund. 2020. "Stochastic Volatility and GARCH: Do Squared End-of-Day Returns Provide Similar Information?" Journal of Risk and Financial Management 13, no. 9: 202. https://0-doi-org.brum.beds.ac.uk/10.3390/jrfm13090202