1. Introduction
Recommender systems (RSs), or recommenders for short, help users to navigate large collections of items in a personalized way [
1]. Broadly speaking, RSs function by correlating user preference data with item attribute data to generate a ranked list of recommended items for each user. Systems of this kind play a crucial role in our modern information overloaded society. RSs are linked to the area of affective computing and sentiment analysis [
2], as they combine user opinions and feelings to produce predictions in affective dimensions, including (but not limited to) such dimensions as ‘like’ and ‘dislike’.
RSs have received special attention in the television domain over the last two decades (see [
3] for an extensive survey), due in part to a rapid increase in the production of scripted TV series in conjunction with an online streaming service boom [
4]. One issue concerning scripted TV series is that, in most RSs, items are considered at “channel” or “program” level [
3]. As a consequence, scripted TV series consisting of dozens or even hundreds of episodes get treated as single items [
5]. In addition, RSs applied to the television domain face the general item cold-start problem [
6], as well as the particular issue of scripted TV series consisting of sets of mostly similar items (i.e., episodes) that are difficult to differentiate among for the purpose of recommendation. We address these issues in the present work by enriching the representation of scripted TV episodes through the use of an ontology of literary themes.
The cold-start problem refers to the temporal situation where there is not enough information for an RS to produce new item or user recommendations. The user-cold-start scenario is commonly addressed by constructing a user profile by appealing to explicitly or implicitly provided user information (e.g., user preferences, demographic information, browsing history) [
7,
8,
9]. In this paper, we address the item-cold-start scenario, where it is necessary to item metadata to associate it with other items that have already been seen by users. In contrast, the warm-system scenario is the ideal situation when both items and users are already known by the system, providing the conditions to perform a static evaluation. In our evaluations, we use item-cold-start (hereinafter cold-start) and warm-system settings to compare the performance of different recommendation algorithms.
Star Trek stands out among television series for its cultural significance, number of episodes, and longevity [
10] (STARFLEET, The International Star Trek Fan Association, Inc. (2019) [
11]). For these reasons, we elected to use Star Trek as a testbed to develop and evaluate the RSs presented in this paper. Another reason motivating our choice of Star Trek is the availability of multiple sources of information, including transcripts, user ratings, sets of tags associated with episodes, and an ontology hierarchy of tags. In particular, we used a detailed ontology of literary themes [
12,
13] that was initially developed for Star Trek but has since evolved to be used for general works of fiction. This particular situation allowed us to carry out a thorough evaluation that produced insights about the usefulness of different information resources for the construction of RSs, as well as a means to evaluate a new approach for RSs based on ontology.
Most state-of-the-art RSs are built using collaborative filtering (CF) [
1,
3,
6], which is based solely on the analysis of user assigned item preferences. Common CF methods include the classical
k-nearest neighbors algorithm [
14], non-negative matrix factorization [
15], and recent approaches based on efficient representations obtained using deep learning [
16]. The CF approach is popular because of its high performance and independence from the nature of the items. However, it is particularly weak against the issues mentioned for the TV series domain. As an alternative, content-based filtering (CBF), knowledge-based filtering (KBF), and ontology-based filtering (OBF) approaches aim to leverage available domain knowledge in an effort to speed up the discovery of relationships between items and users, which CF approaches require large amounts of data to infer [
17].
The most common role of ontology in RS design consists of providing a taxonomic classification of items [
18,
19,
20]. According to this approach, user profiles are indexed by the entities from the ontology and each dimension is weighted according to the preferences of the explicit (e.g., ratings, likes) [
18,
19] and/or implicit users (e.g., reads, views) [
20]. Non-domain ontologies have also been used in combination with domain ontologies to aid the recommendation process, but their integration is achieved by means of rules or inference engines [
21,
22,
23]. Other approaches aim to model both users and items with ontologies looking for relationships in a single semantic space [
22,
24,
25]. Most of these approaches either use lightweight ontologies or use ontologies as a source for a controlled vocabulary, resulting in a shallow or null use of the ontological hierarchical structure. The exceptions are the approaches that use inference engines [
18,
23]. Recent approaches [
26,
27] manage to handle large ontologies while exploiting relationships along the entire hierarchy.
When practitioners plan to develop a new RS, they face the problem of selecting those information resources needed to bootstrap the new system. During these initial stages, CBF/KBF/OBF approaches are to be preferred over CF alternatives, given the obvious lack of user feedback. Although there is an extensive body of literature on each of these approaches, traversal studies comparing the performances of alternative methods on a single dataset are scarce. In this paper, we aim to fill this gap and to provide practitioners with useful insights for decision-making regarding information resources.
We focus on the OBF approach because this is the one where the results depend mainly on developers and because ontologies are the most informative resource to start a new RS. For instance, CBF approaches depend heavily on the nature of the items (e.g., books, hotels, clothing, movies), whose native data representations are not always RS friendly. Similarly, CF approaches depend on the number of users, which in turn depends on external factors such as popularity, advertising, trends, etc. However, there are many factors in the construction of an ontology for an RS that influences recommendation quality. One important issue pertains to the amount of domain knowledge that can be encoded in the ontology. Many domains provide only shallow ontologies that are unable to leverage an RS. This is the case for the episodes of television series such as Star Trek, which with some effort can be organized into a taxonomy with a few dozen classes. In this paper, we present a method to exploit a subordinate ontology of literary themes that models features of the episodes instead of the episodes themselves. Our hypothesis is that, if a much more detailed and non-domain specific ontology is available, then a recommendation engine can exploit it to produce higher quality recommendations.
Another issue arising when developers engage in the construction of an ontology is that most existing studies do not provide information about the insights on ontology development and the item annotation process. In what follows, we provide non-technical descriptions of the motivations behind the presented ontology and a detailed example of the process of annotating a Star Trek episode with literary themes drawn from the ontology (see
Appendix A). In addition, aside from the mandatory quantitative evaluation of the presented methods, we provide a proof of concept by means of a qualitative assessment of the neighbor episodes of a particular Star Trek episode in a web application implemented with the resources proposed in this paper (see
Appendix B).
The rest of the paper is organized as follows. In
Section 2, we describe the materials used and our proposed methodology. In
Section 3, we evaluate our method by predicting the preferences (i.e., ratings) given by a set of users to a set of items (i.e., Star Trek episodes) in the classical rating prediction task (Warm System) and in the item cold-start scenario (Cold Start). In
Section 4, we discuss the results and share some concluding remarks. Finally, in the appendices, we look at an example episode to illustrate the system of thematic annotation we employed and show how our R Shiny web application can be used to recommend Star Trek television series episodes. Data and computer code availability is described in
Supplementary Materials.
3. Experimental Validation
The goal of this experimental validation is to compare the performance of RSs built with different types of resources using as a testbed a single set of items to be recommended (i.e., Star Trek episodes). In short, we used four information sources to leverage the RS engines: (1) CBF using item content (i.e., transcripts), (2) KBF using items tagged with a set of labels from a controlled vocabulary (i.e., LTO themes), (3) OBF using knowledge in the form of an ontology (i.e., LTO themes with ontology structure), and (4) CF using user preferences (i.e., ratings). Aside from the classical rating prediction task (Warm System), we evaluated the methods in the item cold-start scenario (Cold Start) and analyzed their parameters.
3.1. Experimental Setup
We carried out the experiments using the MyMediaLite RS library [
65], which includes an implementation of the IKNN model [
14] along with a host of other classical RS algorithms [
15,
66,
67,
68,
69,
70]. To test the item-similarity functions presented in
Section 2.2, we predicted user ratings for the Star Trek television series episode data presented in
Section 2.5. For evaluation, the ratings in the data were randomly divided into two parts: 70% for training the model and 30% for testing it. For the item cold-start scenario, the training-test partitions were drawn by splitting the items (not the ratings) and selecting those partitions covering roughly 30% of the total ratings in the test partition. The selected performance measure is the root-mean-square error (RMSE) as measured between the actual ratings and the predictions produced by the RS method in the test partition. Next, we produced 30 shuffles of such partitions and evaluated the RMSE of each method for each partition. The final reported result for each model is the average RMSE across the 30 training-test partitions. We used the Wilcoxon rank-sum test statistic to assess the statistical significance of the observed differences in performance between methods.
The RS methods to be tested are classified into four groups according to the resources they use. The first three categories are variations of the IKNN method presented in
Section 2.1, in which we substitute the
of Equation (
1) by the different item similarity functions presented in
Section 2.2. In practice, each variation produces a text file containing on each line the identifiers of two items and their corresponding similarity score. Then, the MyMediaLite application is instructed to use this file as source for computing the similarities between items. For the sake of a fair comparison, the system (
), item (
), and user (
) biases (see Equation (
2)) are used in all the IKNN algorithm variations tested. The fourth category comprises an assortment of CF methods and baselines that are used to ensure for a comprehensive comparison.
Below, we present a summary of the methods used in the experiments:
- CBF recommenders using transcripts:
These methods use the data and preprocessing procedure described in
Section 2.3.
TFIDF is implemented using Equations (
3) and (
4), and
LSI is implemented by performing SVD, as described in
Section 2.2.1, on the document-term matrix obtained from the data. The number of latent factors was varied from 10 to 100 in increments of 10. Both approaches are implemented using the Gensim (Gensim: Topic modelling for humans (2019). URL:
https://radimrehurek.com/gensim/. (Online; accessed 30 June 2019)) text processing library [
71].
- KBF recommenders using themes:
The three methods described in
Section 2.2.2 applied to the thematically annotated representation of the episodes described in
Section 2.3.3.
JACCARD and
DICE were implemented using the Equation (
5) formulae as item similarity functions, while
COSINE_IDF was implemented using Equation (
6).
- OBF recommenders using themes and the ontology:
This category comprises the methods introduced in this work, which are described in detail in
Section 2.2.3. These methods make use of the thematically annotated Star Trek episodes described in
Section 2.3.3, and of the LTO themes as presented in
Section 2.3.2. Each of the six variants is named after the abbreviation for their assocaited item similarity function:
,
,
,
,
, and
.
- CF recommenders and baselines:
In this group, we tested a set of classical RSs based purely on user ratings. These methods can be grouped into KNN [
14] and matrix factorization approaches [
15,
66,
67,
68,
69,
70]. In addition, we included five popular baseline methods: (1) User Item Baseline, which produces rating predictions using the baselines described in
Section 2.1; (2) Item Average Baseline, which uses as predictions the mean rating of each item; (3) User Average Baseline same as before, but averaging by user; (4) Global Average Baseline which always predicts the average rating of the dataset; and (5) Random Baseline, which produces random ratings distributed uniformly.
3.2. Results
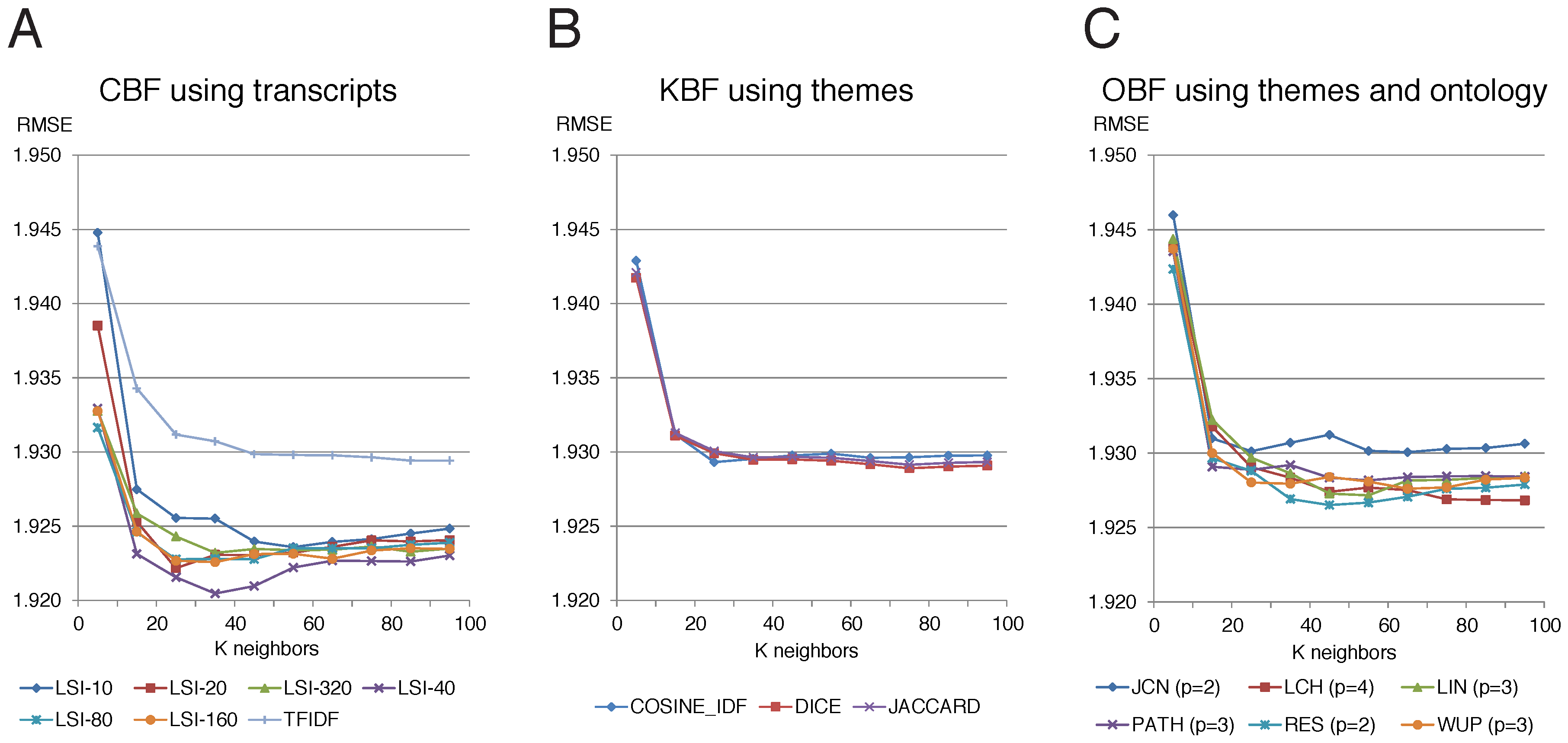
Figure 3 shows the results obtained by the methods presented in this work based on
IKNN. For each method, the parameter
k (the number of nearest neighbors) was ranged from 10 to 100 in increments of 10. As the performance measure RMSE is an error measure, the lower the score, the better the performance of the tested method. In addition, as usual with star-scaled rating prediction experiments, the differences between methods are only noticeable in the second and third decimal places.
Figure 3A shows the results for the CBF recommenders, which obtained the best results. In particular, the best configuration is
LSI-40 (40 latent factors) with
. The other
LSI methods performed similarly.
TFIDF produced the worst result out of the CBF recommenders.
Figure 3B shows the KBF recommender results. The three methods performed practically identically with
DICE showing a slight advantage over the others. Finally,
Figure 3C shows the results obtained using the novel OBF recommenders, which performed in between the first two groups. Since these methods depend on the softness control parameter
p, the figure shows the results using the best value of
p for each method.
Figure 4 shows how this parameter behaves for each one of the methods. The
LIN,
WUP, and
LCH methods clearly exhibit robust behavior regarding that parameter.
In
Table 4, we compare the best performing CBF, KBF, and OBF configurations (the first four rows) shown in
Figure 3 with a variety of CF recommenders and baselines. We report the resources used for building each model and their average RMSE values with standard deviation. In the first column, we labeled the top six methods numerically from 1 to 6 in order to report pairwise hypothesis test results in the last six columns. If the null hypothesis of equal performance is rejected for two methods being compared, then we record an “*” mark (for clarity we record an “=” when the table entry corresponds to the same method). Since the numerical differences in the observed RMSE values are narrow, we increased the typical statistical significance level from
to
. Note that the number of paired samples for each test corresponds to the 30 random partitions of the data. The first set of columns corresponds to the results and hypothesis testing for the
Warm System scenario, while the second set of columns corresponds to those for the
Cold Start scenario.
3.3. Results Discussion
Let us first discuss the results for the Warm System scenario. The best results were achieved by the
LSI method. In contrast, among CBF recommenders,
TFIDF performed considerably poorer, meaning that the sparsity of this representation hinders its ability to model the items (see
Figure 3A). The optimal number of latent factors is 40, which must be assessed against the original vocabulary size (∼14 K words) and the average transcript length (∼3 K words). Other domains having larger vocabularies and textual representations can be expected to require more latent factors and vice versa.
The KBF recommenders based on themes (COSIDE_IDF, DICE, and JACCARD) performed practically identically to TFIDF, meaning that the effort involved in representing the items using a controlled vocabulary of size ∼2 K did not provide much benefit. In spite of this finding, all the methods that used thematic representation in combination with the ontology managed to improve the results (with the exception of the JCN method). Therefore, the knowledge encoded in the ontology and the novel method for exploiting the ontology are useful in spite of the sparsity of the representation that was used. In addition, this result suggests that even a representation of relatively moderate dimensionality (∼2 K entities) could benefit from a combination with a method such as LSI.
Among the OBF recommenders,
RES and
LCH tied for the best performance. However,
Figure 4 shows that
RES is rather sensitive to the parameter
p, while
LCH exhibited the best robustness on that matter. In addition,
RES requires IC, which also requires the existence of a relatively large corpus to compute those statistics.
The graphs in
Figure 3 also show performance variation due to parameter
k, which is the number of nearest neighbors used in IKKN. The clear tendency is to get lower error rates as
k increases. There is a general inflection point around
where more neighbors provide only a small benefit, and even an increased RMSE beyond this point for two of the best performing methods: LSI-40 and RES.
Regarding the comparison of CBF/KBF/OBF recommenders against their CF counterparts, we observed that only the KBF recommenders fail to significantly outperform the CF ones in the Warm System scenario. It is important to note that, in that scenario, our modifications of the IKNN algorithm using LSI-40 and LCH do outperform the classical purely collaborative IKNN and remaining CF tested approaches. The most notable difference in the results of the Cold Start scenario is that all methods exhibit comparatively large variances across the 30 random partitions. Although all the IKKN variants manage to surpass all other CF recommenders, the latter do not produce significant statistical differences among them. Out of the IKNN approaches, the only statistically significant difference was observed between the CBF recommender (LSI-40) and the OBF recommenders (RES and LCH).
The results also show that the CBF and OBF recommenders behave similarly in comparison to the other approaches, but the CBF recommender consistently outperforms the OBF one by a small margin. This difference is attributable to the particularly good quality of the content-based representation in the cause of our dataset. The fan curated Star Trek episode transcripts provide high-quality and detailed descriptions that even include fragments without dialog. This particular situation leads us to conclude that the effort invested in the construction of a detailed ontology is not worth it for recommendation purposes. However, that kind of representation is only possible for certain types of items (e.g., books, movies, TV shows) and, even if that is possible, its availability is not guaranteed. In our opinion, it is possible that the cost and effort involved in providing high-quality textual descriptions of the items surpass those of building a detailed domain ontology.
In conclusion, LCH using and is a reasonable choice when a relatively large ontology is available, and LSI-40 is a good choice when an appropriate textual representation of the items is available. In the event that none of these resources are available, then DICE can be expected to have a performance equivalent to the classic IKKN algorithm.
4. Discussion
In this paper, we presented a novel set of OBF recommenders aimed at mitigating the item cold-start problem in the domain of fiction content recommendation. Unlike most conventional approaches [
3,
22,
24,
25], which exploit lightweight ontological representations of users and items, we propose a scheme for factoring large taxonomic hierarchies of item features directly into the recommendation process. In a case study, we compared the performance of our proposed OBF recommenders against a variety of alternatives in a Star Trek television series episode user rating prediction exercise. For comparison’s sake, we implemented: (1) conventional CF recommenders based solely on user ratings, (2) CBF recommenders based on episode transcripts using traditional text mining practices, and (3) novel KBF recommenders based on LTO thematically annotated Star Trek episodes without the ontology hierarchy. Meanwhile, the OBF recommenders exploited LTO thematically annotated Star Trek episodes together with LTO ontology hierarchy. We found the CBF, KBF and OBF approaches to be suitable alternatives to CF for the Cold Start stage of an RS’s lifetime. The CBF approach obtained the best results, suggesting that it is to be preferred over the KBF/OBF alternatives when an informative textual representation of the items under consideration is available. However, interestingly, we found that the OBF approach outperformed the KBF one, indicating that the ontology hierarchy is informative above and beyond the terms that populate it. This result provides definitive evidence in support for our original research hypothesis. However, the CF approach is the clear choice in the case of the Warm System stage of an RS when there is already a continuous supply of explicit or implicit user preferences.
We conclude based on our experimental evaluation that the best approaches tested in each of the groups of algorithms (CBF, KBF, OBF, and CF) performed similarly with some statistically significant differences but with overall small effect sizes. This result should be evaluated taking into consideration that the dataset used was exceptionally balanced in the quality of the information resources that each approach exploited. For instance, the used content-based representation in the form of episode transcripts contained particularly compact and informative semantic descriptions of the items, which is not commonly available for other domains. Since the CBF recommenders tested obtained the best results, practitioners should transfer this finding to other domains with caution, if the content representations are not as informative or detailed as the ones used in this study. Similarly, regarding the thematic annotation of the episodes (KBF approach), our methodology was rather thorough involving a significant manual effort. Again, we suggest that practitioners should compare their methodologies of item annotation with the example provided in
Appendix A to put our results in context. Finally, the same remark applies to the results of the OBF recommenders, since the ontology used was of considerable size and depth. Therefore, we recommend that, in order to transfer the results to other domains, the characteristics of the ontologies used ought to be compared with the description of
Section 2.3.2 (also see [
12,
13]).
The perspectives of future work that are opened from this study are diverse. In our opinion, the main path is to take advantage of the proposed Star Trek television series testbed for the development of multiple-modality hybrid recommendation algorithms. The inclusion of users reviews constitutes an interesting extension of our testbed. Doing so would effectively extend the analysis to other affective dimensions that can be extracted from the reviews, given recent developments in natural language processing using deep learning applied to sentiment analysis [
72]. Additionally, we consider that the set of aligned data resources offers the opportunity to explore new tasks in the area of artificial intelligence. For example, the alignment between transcripts and thematic annotations is an interesting input for an automatic annotation approach based on machine learning. Likewise, the modality of user preferences introduces an interesting factor that opens up the possibility of developing algorithms for the automatic creation of personalized literary content.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















