
Proposal and Investigation of a Convolutional and LSTM Neural Network for the Cost-Aware Resource Prediction in Softwarized Networks †




Abstract
:1. Introduction
- its resource-based prediction allows for a more implementable and European Telecommunications Standards Institute (ETSI)-compliant solution; in particular we highlight which are the ETSI functional blocks that may be involved in the allocation and prediction procedure;
- APRPA is based on a convolutional and Long Short Term Memory (LSTM) neural network able to handle both spatial correlations of the processing capacities of the VNFIs located in each NFVI-PoP and the temporal correlation in a single VNFI; conversely ATPA performs a simple traffic prediction with a LSTM neural network able to handle temporal correlation only;
- APRPA allows for a more accurate prediction, consequence of multiple SFCs sharing a single VNFI that leads to the prediction of an aggregated requested processing capacity; conversely ATPA predicts the traffic of a single SFC.
2. Related Work and Research Contribution
3. NFV Network Architecture with AI-Based Resource Allocation
- the VNF Manager (VNFM) manages the lifecycle of VNFIs; it is provided with a Monitoring Agent (MA) whose task is to measure the processing capacity used by the VNFI;
- the Virtual Infrastructure Manager (VIM) controls and manages the NFVI-PoP resources; it is provided with an Allocation Agent (AA) whose task is to collect the data measured by the VNFIs and execute the algorithm for evaluating the processing capacities to be allocated to the VNFIs;
- the NFV Orchestrator (NFVO) manages the lifecycle of Network Services; it is provided with a Reconfiguration and Placement Agent (RPA) whose task is to execute an algorithm for the resource reconfiguration and the VNFI placement on the basis of the processing capacities to be allocated to the VNFIs.
- Step-1: The MAs continuously monitor on a periodic basis with duration and using the Ve-Vnfm-vnf ETSI interface [12] the processing capacity required by the VNFI; let us consider the reference NFVI-PoP of Figure 1 and let be the number of instantiated VNFIs. Next we denote with () the processing capacity measured for the -th VNFI in the -th Monitoring Interval (MI) that is in ;
- Step-2: The measured processing capacities are retrieved on the Vi-Vnfm ETSI interface [12] from the AA that trains a neural network in order to determine the processing capacity to be allocated to the VNFIs; we assume the allocation procedure is performed on a periodic basis with duration ; we denote with S the ratio of to and with () the processing capacity to be allocated to the -th VNFI in ; is evaluated by a neural network based on knowledge of the required processing capacities required and measured in L previous MIs that is the values .
- Step-3: The NFVO receives on the Or-Vi interface [12] from all of the VIMs the processing capacities () to be allocated and decides if new VNFI placement, VNFI migration and updating of processing capacity allocated to the VNFI have to be performed.
- Step-4: The placement and reconfiguration operations are conducted through the VIM and using the Or-Vi and Nf-Vi interfaces.
4. Convolutional/LSTM-Based Resource Allocation Framework
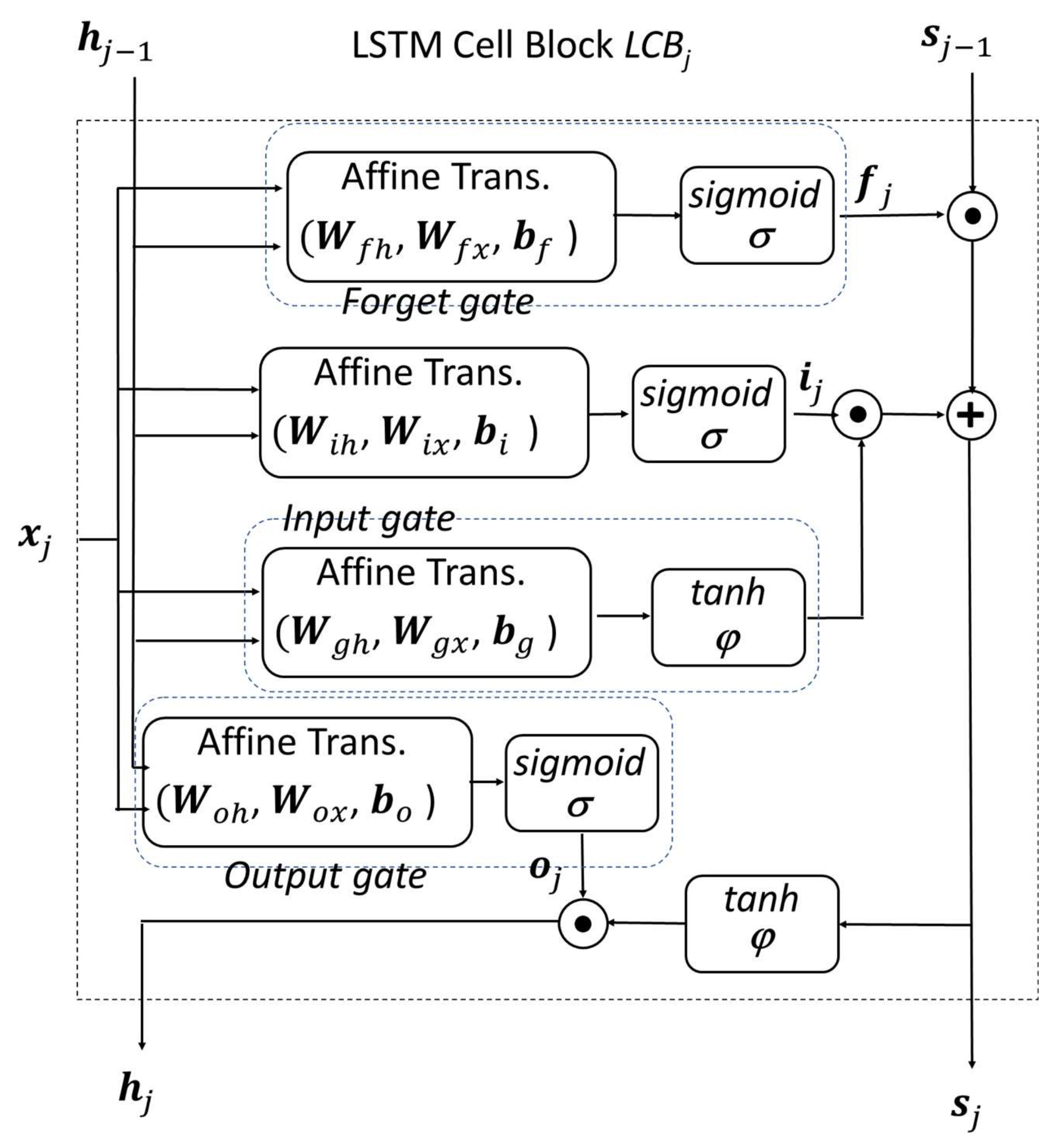
4.1. Convolutional/LSTM Neural Network
4.2. Training Algorithm
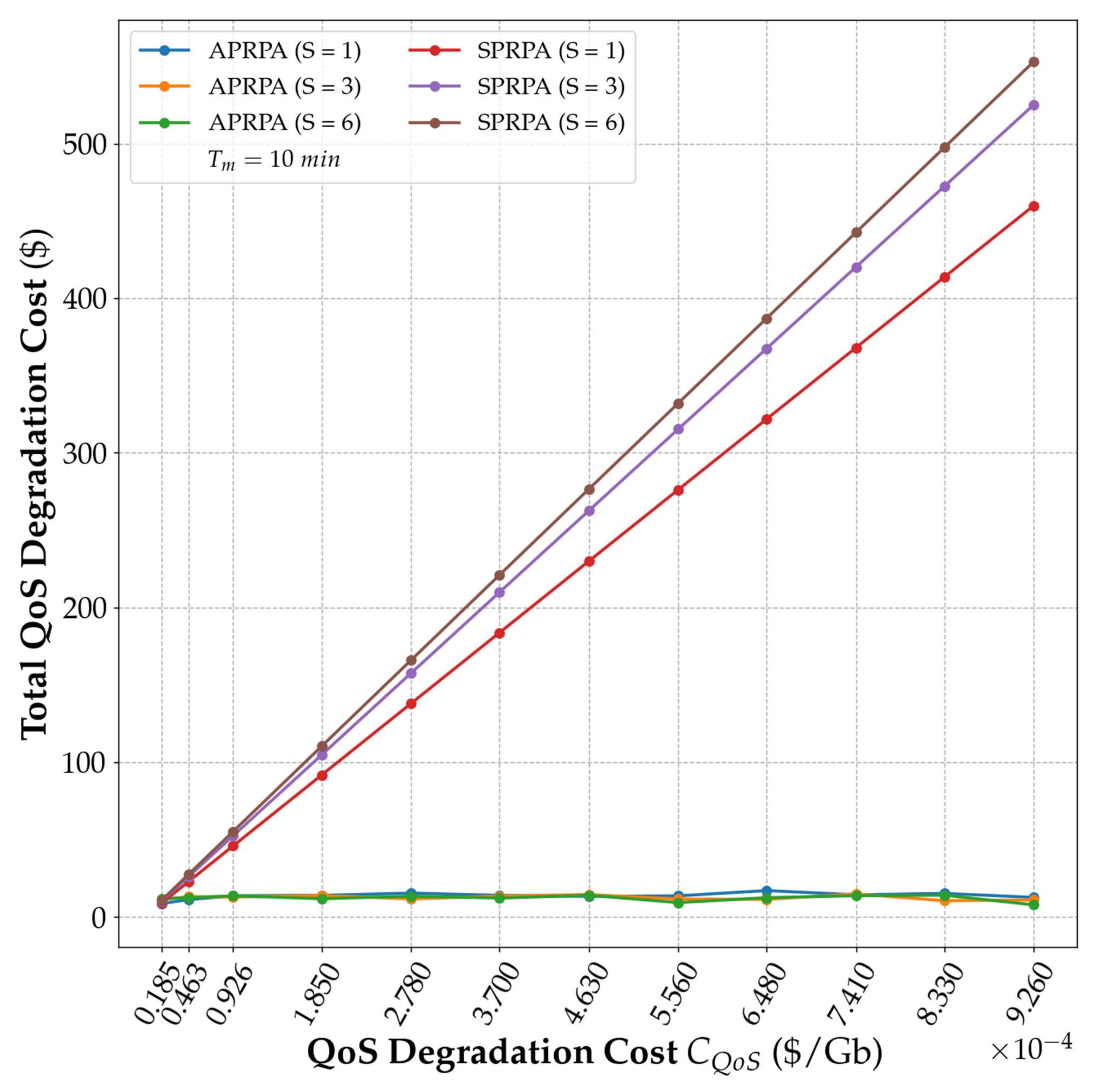
5. Numerical Results
- the look-back parameter L has been choice by studying the partial autocorrelation function (PACF) [36] of the processing capacities of the training set; it has been chosen the first value in which the PACF has a negligible value ();
- the Kernel filter size has been chosen equal to the number of VNFIs executing in each NFVI-PoP;
- the remaining hyperparametrs (the number of neurons of the LSTM layer, the number of Kernel filters and the batch size ) have been chosen by performing a sensitivity analysis with the KerasTuner software [37]. KerasTuner is an easy-to-use, scalable hyperparameter optimization framework that solves the pain points of hyperparameter search. Easily configure the search space with a define-by-run syntax, then leverage one of the available search algorithms to find the best hyperparameter values for the models. We have chosen the KerasTuner option that performs the hyperparameter optimization with the Hyperband algorithm.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mijumbi, R.; Serrat, J.; Gorricho, J.; Bouten, N.; De Turck, F.; Boutaba, R. Network Function Virtualization: State-of-the-art and Research Challenges. IEEE Commun. Surv. Tutor. 2016, 18, 236–262. [Google Scholar] [CrossRef] [Green Version]
- Eramo, V.; Miucci, E.; Ammar, M. Study of Migration Policies in Energy-Aware Virtual Router Networks. IEEE Commun. Lett. 2014, 18, 1919–1922. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G. Proposal and Investigation of a Reconfiguration Cost Aware Policy for Resource Allocation in Multi-Provider NFV Infrastructures Interconnected by Elastic Optical Networks. J. Light. Technol. 2019, 37, 4098–4114. [Google Scholar] [CrossRef]
- Yi, B.; Wang, X.; Huang, M.; Li, K. Design and Implementation of Network-Aware VNF Migration Mechanism. IEEE Access 2020, 8, 44346–44358. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G.; Catena, T.; Di Giorgio, F. Reconfiguration of Optical-NFV Network Architectures Based on Cloud Resource Allocation and QoS Degradation Cost-Aware Prediction Techniques. IEEE Access 2020, 8, 200834–200850. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G.; Catena, T.; Perez Salazar, P.J. Application of a Long Short Term Memory neural predictor with asymmetric loss function for the resource allocation in NFV network architectures. Comput. Netw. 2021, 193, 108104–108116. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G.; Catena, T.; Perez Salazar, P.J. Proposal and Investigation of an Artificial Intelligence (AI)-Based Cloud Resource Allocation Algorithm in Network Function Virtualization Architectures. Future Internet 2020, 12, 196. [Google Scholar] [CrossRef]
- Eramo, V.; Valente, F.; Lavacca, F.G.; Catena, T. Cost-Aware and AI-based Resource Prediction in Softwarized Networks. In Proceedings of the 2021 AEIT International Annual Conference, Virtual, 4–8 October 2021. [Google Scholar]
- Trakadas, P.; Sarakis, L.; Giannopoulos, A.; Spantideas, S.; Capsalis, N.; Gkonis, P.; Karkazis, P.; Rigazzi, G.; Antonopoulos, A.; Cambeiro, M.A.; et al. A Cost-Efficient 5G Non-Public Network Architectural Approach: Key Concepts and Enablers, Building Blocks and Potential Use Cases. Sensors 2021, 21, 5578. [Google Scholar] [CrossRef]
- Eramo, V.; Listanti, M.; Lavacca, F.G.; Iovanna, P.; Bottari, G.; Ponzini, F. Trade-Off Between Power and Bandwidth Consumption in a Reconfigurable Xhaul Network Architecture. IEEE Access 2016, 4, 9053–9065. [Google Scholar] [CrossRef]
- Chiosi, M.; Clarke, D.; Feder, J.; Cui, C.; Benitez, J.; Michel, U.; Fumui, M.; Delisle, D.; Guardini, I.; Lopez, D.; et al. Network Functions Virtualization: An Introduction, Benefits, Enablers, Challenges and Call for Action; Technical Report; ETSI—European Telecommunications Standards Institute: Darmstadt, Germany, 2012. [Google Scholar]
- ETSI Industry Specification Group (ISG) NFV. ETSI Group Specifications on Network Function Virtualization. January 2015. Available online: https://docbox.etsi.org/ISG/NFV/Open/Published/ (accessed on 15 November 2021).
- Mostafavi, S.; Hakami, V.; Sanaei, M. Quality of service provisioning in network function virtualization: A survey. Computing 2021, 103, 917–991. [Google Scholar] [CrossRef]
- Umrao, B.K.; Yadav, D.K. Algorithms for functionalities of virtual network: A survey. J. Supercomput. 2021, 77, 7368–7439. [Google Scholar] [CrossRef]
- Yang, S.; Li, F.; Trajanovski, S.; Chen, X.; Wang, Y.; Fu, X. Delay-Aware Virtual Network Function Placement and Routing in Edge Clouds. IEEE Trans. Mob. Comput. 2021, 20, 445–459. [Google Scholar] [CrossRef] [Green Version]
- Zu, J.; Hu, G.; Yan, J.; Tang, S. A community detection based approach for Service Function Chain online placement in data center network. Comput. Commun. 2021, 169, 168–178. [Google Scholar] [CrossRef]
- Qiao, W.; Liu, Y.; Lu, Y.; Li, X.; Yan, J.; Yao, Z. A Novel Approach for Service Function Chain Embedding in Cloud Datacenter Networks. IEEE Commun. Lett. 2021, 25, 1134–1138. [Google Scholar] [CrossRef]
- Varasteh, A.; Madiwalar, B.; Van Bemten, A.; Kellerer, W.; Mas-Machuca, C. Holu: Power-Aware and Delay-Constrained VNF Placement and Chaining. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1524–1539. [Google Scholar] [CrossRef]
- Schneider, S.; Puthenpurayil Satheeschandrany, N.; Peuster, M.; Karl, H. Machine Learning-Based Method for Prediction of Virtual Network Function Resource Demands. In Proceedings of the 2020 IEEE Conference on Network Softwarization (NetSoft), Ghent, Belgium, 29 June–3 July 2020. [Google Scholar]
- Li, B.; Lu, W.; Liu, S.; Zhu, Z. Deep-Learning-Assisted Network Orchestration for On-Demand and Cost-Effective vNF Service Chaining in Inter-DC Elastic Optical Networks. IEEE J. Opt. Commun. Netw. 2018, 10, D29–D41. [Google Scholar] [CrossRef]
- Tang, H.; Zhou, D.; Chen, D. Dynamic Network Function Instance Scaling Based on Traffic Forecasting and VNF Placement in Operator Data Centers. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 530–543. [Google Scholar] [CrossRef]
- Oliveira, D.H.L.; de Araujo, T.P.; Gomes, R.L. An Adaptive Forecasting Model for Slice Allocation in Softwarized Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 94–103. [Google Scholar] [CrossRef]
- Farahnakian, F.; Pahikkala, T.; Liljeberg, P.; Plosila, J.; Hieu, N.T.; Tenhunen, H. Energy-Aware VM Consolidation in Cloud Data Centers Using Utilization Prediction Model. IEEE Trans. Cloud Comput. 2019, 7, 524–536. [Google Scholar] [CrossRef]
- Yang, Q.; Zhou, Y.; Yu, Y.; Yuan, J.; Xing, X.; Du, S. Multi-step-ahead Host Load Prediction using Autoencoder and Echo State Networks in Cloud Computing. J. Supercomput. 2015, 71, 3037–3053. [Google Scholar] [CrossRef]
- Nguyen, H.M.; Kalra, G.; Kim, D. Host Load Prediction in Cloud Computing using Long Short-Term Memory Encoder-Decoder. J. Supercomput. 2019, 75, 7592–7605. [Google Scholar] [CrossRef]
- Subramanya, T.; Riggio, R. Centralized and Federated Learning for Predictive VNF Autoscaling in Multi-Domain 5G Networks and Beyond. IEEE Trans. Netw. Serv. Manag. 2021, 18, 63–78. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G. Computing and Bandwidth Resource Allocation in Multi-Provider NFV Environment. IEEE Commun. Lett. 2018, 22, 2060–2063. [Google Scholar] [CrossRef]
- Matera, F.; Schiffini, A.; Guglielmucci, M.; Settembre, M.; Eramo, V. Numerical Investigation on Design of Wide Geographical Optical Transport Networks Based on n× 40 Gbit/s Transmission. J. Light. Technol. 2003, 21, 456–465. [Google Scholar] [CrossRef]
- Eramo, V.; Listanti, M. Input Wavelength Conversion in Optical Packet Switches. IEEE Commun. Lett. 2003, 7, 281–283. [Google Scholar] [CrossRef]
- Yi, B.; Wang, X.; Li, K.; Das, S.K.; Huang, M. A comprehensive survey of Network Function Virtualization. Comput. Netw. 2018, 133, 212–262. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- EC2—Amazon Web Services. Available online: https://aws.amazon.com/ec2/ (accessed on 15 November 2021).
- SND-lib. Available online: http://sndlib.zib.de/home.action (accessed on 15 November 2021).
- De Giorgi, M.G.; Quarta, M. Hybrid MultiGene Genetic Programming-Artificial neural networks approach for dynamic performance prediction of an aeroengine. Aerosp. Sci. Technol. 2020, 103, 105902. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- KerasTuner. Available online: https://github.com/keras-team/keras-tuner (accessed on 15 November 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Allocated Cores | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 1-st type VNFI (Firewall) | 225 | 450 | 675 | 900 | — | — | — | — |
| 2-nd type VNFI (IDS) | 75 | 150 | 225 | 300 | 375 | 450 | 525 | 600 |
| 3-rd type VNFI (NAT) | 450 | 900 | — | — | — | — | — | — |
| 4-th type VNFI (PROXY) | 150 | 300 | 450 | 600 | — | — | — | — |
| NFVI-PoP | NFVI-PoP | NFVI-PoP | NFVI-PoP | NFVI-PoP | |
|---|---|---|---|---|---|
| 1-st type VNFI (Firewall) | |||||
| 2-nd type VNFI (IDS) | |||||
| 3-rd type VNFI (NAT) | |||||
| 4-th type VNFI (PROXY) |
| L | |||||
|---|---|---|---|---|---|
| NFVI-PoP | 33 | 40 | 8 | 10 | 24 |
| NFVI-PoP | 19 | 40 | 16 | 10 | 24 |
| NFVI-PoP | 38 | 40 | 32 | 10 | 24 |
| NFVI-PoP | 34 | 40 | 32 | 10 | 24 |
| NFVI-PoP | 39 | 40 | 16 | 8 | 24 |
| SPRPA (S = 1) | APRPA (S = 1) | SPRPA (S = 3) | APRPA (S = 3) | SPRPA (S = 6) | APRPA (S = 6) | |
|---|---|---|---|---|---|---|
| = | ||||||
| = | ||||||
| = | ||||||
| = |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eramo, V.; Valente, F.; Catena, T.; Lavacca, F.G. Proposal and Investigation of a Convolutional and LSTM Neural Network for the Cost-Aware Resource Prediction in Softwarized Networks. Future Internet 2021, 13, 316. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13120316
Eramo V, Valente F, Catena T, Lavacca FG. Proposal and Investigation of a Convolutional and LSTM Neural Network for the Cost-Aware Resource Prediction in Softwarized Networks. Future Internet. 2021; 13(12):316. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13120316
Chicago/Turabian StyleEramo, Vincenzo, Francesco Valente, Tiziana Catena, and Francesco Giacinto Lavacca. 2021. "Proposal and Investigation of a Convolutional and LSTM Neural Network for the Cost-Aware Resource Prediction in Softwarized Networks" Future Internet 13, no. 12: 316. https://0-doi-org.brum.beds.ac.uk/10.3390/fi13120316