
A Performance Comparison of Different Cloud-Based Natural Language Understanding Services for an Italian e-Learning Platform †

 ,
,
Abstract
:1. Introduction
- The User Interface, which allows the user to dialogue with the service, by talking or typing their questions.
- The Application Core, which contains the logic that allows the dialogue with the user, analyzing the text or the speech, defining the conversation flow and the exchange of information. In this module, the chatbot must keep track of the context and the previous interaction with the user: for example, in the question “How can I activate it?” the chatbot has to reference the pronoun it to a previous entity the user has mentioned. This task is often referred as Dialogue State Tracking [9].
- The interface with the External Services, which allows the application core to connect with databases, human operators and other services in order to satisfy the users’ requests.
2. Related Work
3. Natural Language Understanding Cloud Platforms
- Intent—the services have the goal to understand what the user means in their sentence, which can be any type of utterance (greetings, requests, complaints, etc.), and provide a classification value for it.
- Entity—the services should identify the important parameters of the users’ requests, extracting names, addresses, numbers, quantities, etc.
4. Case Study
- “Corso scaduto è possibile riattivarlo?”Course expired; is it possible to reactivate it?
- “Buongiorno ho inviato stamattina un messaggio perchè non riesco ad accedere al corso “Lavoratori - Formazione specifica Basso rischio Uffici” probabilmente perchè è scaduto e purtroppo non me ne sono reso conto. Cosa posso fare? Grazie”Good morning, I sent a message this morning because I cannot join “Workers - Specific training course about Low risk in Offices”, probably because it is expired and unfortunately I did not realise it. What should I do? Thank you
4.1. Data Collection
4.2. Data Classification
5. Evaluation Experiments
5.1. Training and Test Sets
5.2. Experimental Design
- The Training module: for each intention considered, all examples related to it are sent to the NLU platform and then the module waits until the service ends the training phase.
- The Testing module for each element in the test set, the module sends a message containing the user’s utterance and the application waits for the response of the NLU platform. All the platforms analyzed report the results of the intent identification process and the confidence related to the prediction, therefore this module can compare the prediction made by the system and the correct intention. We want to underline that our application sends and analyzes every element of the test set (i.e., every user request) independently. In this module, there is an option that allows testing the response time using a timer which is activated before sending the message, and it is ended when the service reply arrives.
- The Reporting module, which is responsible for reading the file produced by the previous module and for calculating the performance metrics. The metrics calculated are Recall, Accuracy, F-score, and Error rate. This module also allows saving a report containing the response time in order to compute the average, the standard deviation, and the maximum and minimum response times.
6. Results and Discussion
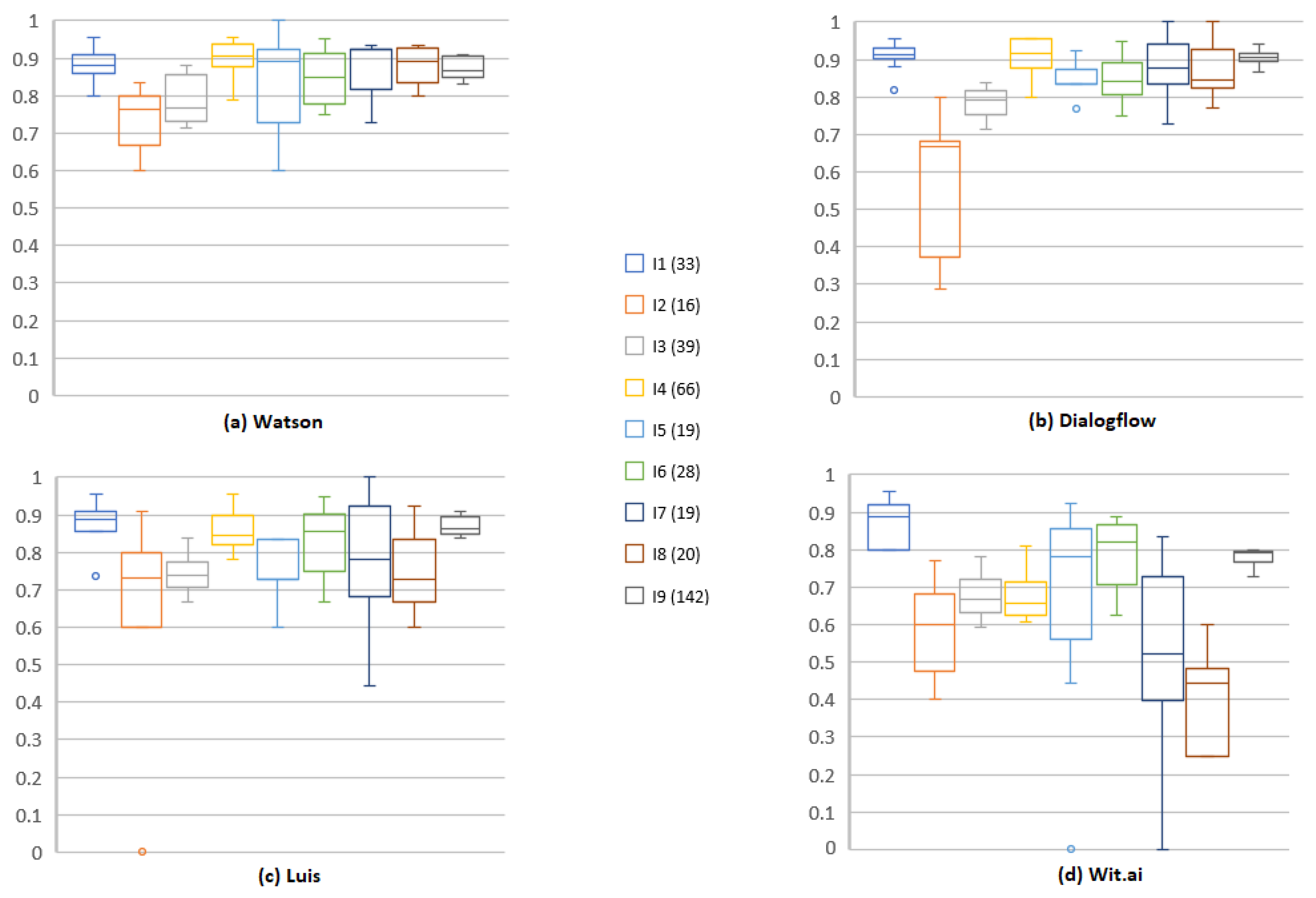
6.1. Experiment (A)
6.2. Experiment (B)
6.3. Experiment (C)
6.4. Experiment (D)
6.5. Overall Evaluation
7. System Implemented and Real-World Evaluation
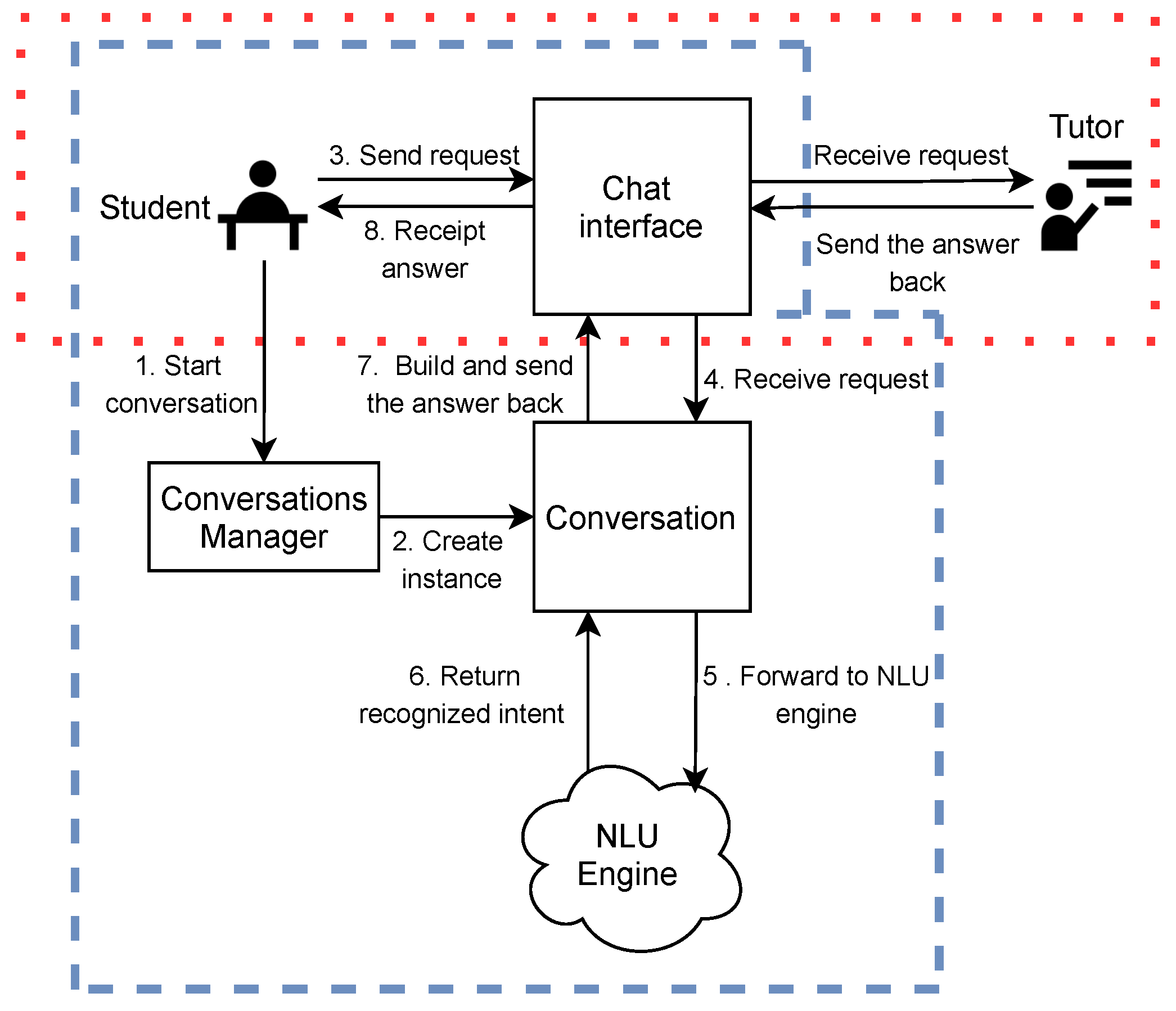
7.1. System Implemented
- The chat is opened and the system sends a signal to the conversation manager.
- The conversation manager creates a thread representing an instance of a conversation between a student and the NLU engine. Therefore, for each student who opens the chat, the conversation manager creates a dedicated conversation instance; this allows the system to manage multiple conversations simultaneously. Each instance is independent from the others.
- The student enters the text into the chat interface. The request is sent to the conversation instance.
- The conversation instance receives the student’s request and checks the integrity of the sentence.
- The conversation instance sends the student’s request to the NLU engine using a specific API.
- The NLU engine returns a message containing one or more intentions recognized with their confidence scores to the conversation instance. The NLU engine often predicts more than one intent, but the confidence allows distinguishing which intention is more likely than another.
- The conversation instance scans all the intentions recognized and selects the one which has the highest confidence and builds the corresponding answer. If the student’s request was unclear for the NLU engine, it is possible to have more intentions with similar confidence values, in this case, a disambiguation message is generated. A disambiguation message is a special request that the conversation instance sends to the student asking to specify, from a list of possible intentions previously selected, the correct one. Whether the intention of the student’s request was evident, or the student responds to a disambiguation message, the conversation instance selects the correct answer and sends it back to the student.
- The student receives the answer and (s)he can enter a new request into the chat interface and send it to the conversation instance.
7.2. Real-World Evaluation
- Success: the NLU engine recognizes the underlying intention and the chatbot provides the correct answer to the student. In Table 4, we do not classify the Human Operator intent recognition as Success. In fact, this intention can only be triggered after the chatbot fails to recognize a user request.
- Disambiguation necessary: the NLU engine does not provide a unique intention or the request is unclear, so the chatbot builds a disambiguation message as described previously. The student selects the correct intention among a subgroup of probable intentions. Therefore, the chatbot determines the correct answer and sends it to the student.
- Fail and redirect to human tutor: the NLU engine recognizes the wrong intention and the chatbot consequently sends an incorrect answer, therefore users ask to talk to a human operator; in this case, the chatbot does not attempt to satisfy any request and the user is immediately redirected to a human tutor.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mauldin, M.L. CHATTERBOTS, TINYMUDS, and the Turing Test: Entering the Loebner Prize Competition. Available online: https://www.aaai.org/Papers/AAAI/1994/AAAI94-003.pdf (accessed on 15 January 2022).
- Kumar, R.; Ali, M.M. A Review on Chatbot Design and Implementation Techniques. Int. J. Eng. Technol. 2020, 7, 2791. [Google Scholar]
- Caldarini, G.; Jaf, S.; McGarry, K. A Literature Survey of Recent Advances in Chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Turing, A.M. Computing machinery and intelligence. In Parsing the Turing Test; Springer: Berlin/Heidelberg, Germany, 2009; pp. 23–65. [Google Scholar]
- Brandtzaeg, P.B.; Følstad, A. Why People Use Chatbots. In Internet Science; Springer International Publishing: Cham, Switzerland, 2017; pp. 377–392. [Google Scholar]
- Luo, B.; Lau, R.Y.; Li, C.; Si, Y.W. A critical review of state-of-the-art chatbot designs and applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1434. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Di Prospero, A.; Norouzi, N.; Fokaefs, M.; Litoiu, M. Chatbots as assistants: An architectural framework. In Proceedings of the 27th Annual International Conference on Computer Science and Software Engineering, Markham, ON, Canada, 6–8 November 2017; pp. 76–86. [Google Scholar]
- Henderson, M. Machine Learning for Dialog State Tracking: A Review. In Proceedings of the First International Workshop on Machine Learning in Spoken Language Processing, Fukushima, Japan, 19–20 September 2015. [Google Scholar]
- Nazir, A.; Khan, M.Y.; Ahmed, T.; Jami, S.I.; Wasi, S. A novel approach for ontology-driven information retrieving chatbot for fashion brands. Int. J. Adv. Comput. Sci. Appl. IJACSA 2019, 10, 546–552. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26; Curran Associates, Inc.: San Jose, CA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Prasomphan, S. Improvement of Chatbot in Trading System for SMEs by Using Deep Neural Network. In Proceedings of the 2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 12–15 April 2019; pp. 517–522. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Adiwardana, D.; Luong, M.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a Human-like Open-Domain Chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Thorat, S.A.; Jadhav, V. A review on implementation issues of rule-based chatbot systems. In Proceedings of the International Conference on Innovative Computing & Communications (ICICC), Delhi, India, 21–23 February 2020. [Google Scholar]
- Lokman, A.S.; Ameedeen, M.A. Modern Chatbot Systems: A Technical Review. In Proceedings of the Future Technologies Conference (FTC) 2018, Vancouver, BC, Canada, 13–14 November 2018. [Google Scholar]
- Canonico, M.; Russis, L.D. A Comparison and Critique of Natural Language Understanding Tools. In Proceedings of the CLOUD COMPUTING 2018: The Ninth International Conference on Cloud Computing, GRIDs, and Virtualization, Barcelona, Spain, 18–22 February 2018; pp. 110–115. [Google Scholar]
- Leoni, C.; Torre, I.; Vercelli, G. Conversiamo: Improving Italian question answering exploiting IBM watson services. In Proceedings of the International Conference on Text, Speech, and Dialogue, Brno, Czech Republic, 8–11 September 2020; pp. 504–512. [Google Scholar]
- Tavanapour, N.; Bittner, E.A. Automated facilitation for idea platforms: Design and evaluation of a Chatbot prototype. In Proceedings of the 39th International Conference on Information Systems, San Francisco, CA, USA, 13–16 December 2018. [Google Scholar]
- Rosruen, N.; Samanchuen, T. Chatbot Utilization for Medical Consultant System. In Proceedings of the 3rd Technology Innovation Management and Engineering Science International Conference (TIMES-iCON), Bangkok, Thailand, 12–14 December 2018; pp. 1–5. [Google Scholar]
- Kadlec, R.; Schmid, M.; Bajgar, O.; Kleindienst, J. Text Understanding with the Attention Sum Reader Network. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Koehn, P. Neural Machine Translation; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Xiang, Y.; Zhou, X.; Chen, Q.; Zheng, Z.; Tang, B.; Wang, X.; Qin, Y. Incorporating label dependency for answer quality tagging in Community Question Answering Via CNN-LSTM-CRF. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 1231–1241. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Mullenbach, J.; Wiegreffe, S.; Duke, J.; Sun, J.; Eisenstein, J. Explainable Prediction of Medical Codes from Clinical Text. In Proceedings of the 16th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 1101–1111. [Google Scholar]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Maroldi, R.; Serina, I. Attention-Based Explanation in a Deep Learning Model For Classifying Radiology Reports. In Proceedings of the Artificial Intelligence in Medicine-19th International Conference on Artificial Intelligence in Medicine, AIME 2021, Lecture Notes in Computer Science, Virtual Event, 15–18 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12721, pp. 367–372. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Qu, C.; Yang, L.; Qiu, M.; Croft, W.B.; Zhang, Y.; Iyyer, M. BERT with history answer embedding for conversational question answering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1133–1136. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; Volume EMNLP 2020, pp. 4163–4174. [Google Scholar]
- Wu, C.; Wu, F.; Qi, T.; Huang, Y.; Xie, X. Fastformer: Additive Attention Can Be All You Need. arXiv 2021, arXiv:2108.09084. [Google Scholar]
- Mehmood, T.; Gerevini, A.E.; Lavelli, A.; Serina, I. Combining Multi-task Learning with Transfer Learning for Biomedical Named Entity Recognition. In Knowledge-Based and Intelligent Information & Engineering Systems, Proceedings of the 24th International Conference KES-2020, Virtual Event, 16–18 September 2020; Cristani, M., Toro, C., Zanni-Merk, C., Howlett, R.J., Jain, L.C., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Volume 176, pp. 848–857. [Google Scholar]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Olivato, M.; Serina, I. Deep Learning for Classification of Radiology Reports with a Hierarchical Schema. In Knowledge-Based and Intelligent Information & Engineering Systems, Proceedings of the 24th International Conference KES-2020, Virtual Event, 16–18 September 2020; Cristani, M., Toro, C., Zanni-Merk, C., Howlett, R.J., Jain, L.C., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Volume 176, pp. 349–359. [Google Scholar]
- Mehmood, T.; Serina, I.; Lavelli, A.; Gerevini, A. Knowledge Distillation Techniques for Biomedical Named Entity Recognition. In Proceedings of the 4th Workshop on Natural Language for Artificial Intelligence (NL4AI 2020) Co-Located with the 19th International Conference of the Italian Association for Artificial Intelligence (AI*IA 2020), Virture, 25–27 November 2020; pp. 141–156. [Google Scholar]
- Putelli, L.; Gerevini, A.; Lavelli, A.; Serina, I. Applying Self-interaction Attention for Extracting Drug-Drug Interactions. In Proceedings of the AI*IA 2019-Advances in Artificial Intelligence-XVIIIth International Conference of the Italian Association for Artificial Intelligence, Roma, Italy, 19–22 November 2019; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11946, pp. 445–460. [Google Scholar]
- Gerevini, A.E.; Lavelli, A.; Maffi, A.; Maroldi, R.; Minard, A.; Serina, I.; Squassina, G. Automatic classification of radiological reports for clinical care. Artif. Intell. Med. 2018, 91, 72–81. [Google Scholar] [CrossRef] [PubMed]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Serina, I. The Impact of Self-Interaction Attention on the Extraction of Drug-Drug Interactions. Available online: http://ceur-ws.org/Vol-2481/paper61.pdf (accessed on 15 January 2022).
- Mishev, K.; Gjorgjevikj, A.; Vodenska, I.; Chitkushev, L.T.; Trajanov, D. Evaluation of sentiment analysis in finance: From lexicons to transformers. IEEE Access 2020, 8, 131662–131682. [Google Scholar] [CrossRef]
- Mohamed, B.A.; Abdelhakim, B.A.; Youness, S. A Deep Learning Model for an Intelligent Chat Bot System: An Application to E-Learning Domain. In Proceedings of the Third International Conference on Smart City Applications, Tetouan, Morocco, 10–11 October 2018; Springer: Berlin/Heidelberg, Germany, 2020; pp. 165–179. [Google Scholar]
- Xie, Q.; Zhang, Q.; Zhang, X.; Tian, D.; Wen, R.; Zhu, T.; Yi, P.; Li, X. A Context-Centric Chatbot for Cryptocurrency Using the Bidirectional Encoder Representations from Transformers Neural Networks. Int. J. Econ. Manag. Eng. 2021, 15, 150–156. [Google Scholar]
- Patti, V.; Basile, V.; Bosco, C.; Varvara, R.; Fell, M.; Bolioli, A.; Bosca, A. EVALITA4ELG: Italian Benchmark Linguistic Resources, NLP Services and Tools for the ELG Platform. IJCoL Ital. J. Comput. Linguist. 2020, 6, 105–129. [Google Scholar] [CrossRef]
- Bellini, V.; Biancofiore, G.M.; Di Noia, T.; Di Sciascio, E.; Narducci, F.; Pomo, C. GUapp: A Conversational Agent for Job Recommendation for the Italian Public Administration. In Proceedings of the 2020 IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS), Bari, Italy, 27–29 May 2020; pp. 1–7. [Google Scholar]
- Polignano, M.; Basile, P.; De Gemmis, M.; Semeraro, G.; Basile, V. Alberto: Italian BERT language understanding model for NLP challenging tasks based on tweets. In Proceedings of the 6th Italian Conference on Computational Linguistics, CLiC-it 2019. CEUR, Bari, Italy, 13–15 November 2019; Volume 2481. [Google Scholar]
- Polignano, M.; Basile, P.; De Gemmis, M.; Semeraro, G. Hate Speech Detection through AlBERTo Italian Language Understanding Model. Available online: http://ceur-ws.org/Vol-2521/paper-06.pdf (accessed on 15 January 2022).
- Goel, A.K.; Polepeddi, L. Jill Watson: A Virtual Teaching Assistant for Online Education. Available online: https://smartech.gatech.edu/bitstream/handle/1853/59104/goelpolepeddi-harvardvolume-v7.1.pdf?sequence=1&isAllowed=y (accessed on 15 January 2022).
- Kar, R.; Haldar, R. Applying Chatbots to the Internet of Things: Opportunities and Architectural Elements. Int. J. Adv. Comput. Sci. Appl. 2016, 7. [Google Scholar] [CrossRef] [Green Version]
- Braun, D.; Hernandez Mendez, A.; Matthes, F.; Langen, M. Evaluating Natural Language Understanding Services for Conversational Question Answering Systems. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Saarbrücken, Germany, 15–17 August 2017; Association for Computational Linguistics: Saarbrücken, Germany, 2017; pp. 174–185. [Google Scholar]
- Liu, X.; Eshghi, A.; Swietojanski, P.; Rieser, V. Benchmarking Natural Language Understanding Services for building Conversational Agents. arXiv 2019, arXiv:1903.05566. [Google Scholar]
- Zubani, M.; Sigalini, L.; Serina, I.; Gerevini, A.E. Evaluating different Natural Language Understanding services in a real business case for the Italian language. In Proceedings of the Knowledge-Based and Intelligent Information & Engineering Systems: Proceedings of the 24th International Conference KES2020, Virtual Event, 16–18 September 2020. [Google Scholar]
- Mehmood, T.; Gerevini, A.; Lavelli, A.; Serina, I. Leveraging Multi-task Learning for Biomedical Named Entity Recognition. In Proceedings of the AI*IA 2019-Advances in Artificial Intelligence-XVIIIth International Conference of the Italian Association for Artificial Intelligence, Rende, Italy, 19–22 November 2019; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11946, pp. 431–444. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
|---|---|---|---|---|---|---|---|---|---|---|
| Training | 39 | 76 | 116 | 153 | 192 | 228 | 265 | 305 | 342 | 382 |
| Test | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 | 132 |
| D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 | AVG | StD | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Watson | Err | 0.136 | 0.144 | 0.091 | 0.121 | 0.114 | 0.174 | 0.151 | 0.1364 | 0.167 | 0.144 | 0.138 | 0.023 |
| FS | 0.857 | 0.851 | 0.907 | 0.878 | 0.887 | 0.822 | 0.845 | 0.863 | 0.832 | 0.857 | 0.860 | 0.02 | |
| Dailoflow | Err | 0.129 | 0.144 | 0.144 | 0.106 | 0.121 | 0.151 | 0.159 | 0.106 | 0.136 | 0.144 | 0.134 | 0.017 |
| FS | 0.877 | 0.851 | 0.856 | 0.894 | 0.875 | 0.857 | 0.844 | 0.893 | 0.871 | 0.863 | 0.868 | 0.016 | |
| Luis | Err | 0.174 | 0.197 | 0.144 | 0.167 | 0.159 | 0.174 | 0.182 | 0.167 | 0.144 | 0.182 | 0.169 | 0.016 |
| FS | 0.825 | 0.785 | 0.853 | 0.823 | 0.840 | 0.828 | 0.815 | 0.831 | 0.851 | 0.819 | 0.827 | 0.018 | |
| Wit | Err | 0.227 | 0.273 | 0.280 | 0.273 | 0.265 | 0.235 | 0.311 | 0.258 | 0.273 | 0.318 | 0.271 | 0.027 |
| FS | 0.778 | 0.716 | 0.692 | 0.708 | 0.706 | 0.757 | 0.671 | 0.743 | 0.718 | 0.656 | 0.714 | 0.035 |
| Experiment | Requirement | Watson | Dialogflow | Luis | Wit |
|---|---|---|---|---|---|
| (A) | F-Score greater than 0.8 | ✓ | ✓ | ✓ | ✗ |
| (B) | Good performance with few training instances | ✓ | ✓ | ✗ | ✗ |
| (C) | Response times always under 0.5 s | ✓ | ✓ | ✓ | ✓ |
| (D) | Spelling errors robustness | ✓ | ✗ | ✗ | ✗ |
| Occurrence | Percentage |
|---|---|
| Success (Without Human Operator intention) | 78.9 |
| Disambiguation | 15.1 |
| Fail and Redirect to Human Tutor | 6.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zubani, M.; Sigalini, L.; Serina, I.; Putelli, L.; Gerevini, A.E.; Chiari, M. A Performance Comparison of Different Cloud-Based Natural Language Understanding Services for an Italian e-Learning Platform. Future Internet 2022, 14, 62. https://0-doi-org.brum.beds.ac.uk/10.3390/fi14020062
Zubani M, Sigalini L, Serina I, Putelli L, Gerevini AE, Chiari M. A Performance Comparison of Different Cloud-Based Natural Language Understanding Services for an Italian e-Learning Platform. Future Internet. 2022; 14(2):62. https://0-doi-org.brum.beds.ac.uk/10.3390/fi14020062
Chicago/Turabian StyleZubani, Matteo, Luca Sigalini, Ivan Serina, Luca Putelli, Alfonso E. Gerevini, and Mattia Chiari. 2022. "A Performance Comparison of Different Cloud-Based Natural Language Understanding Services for an Italian e-Learning Platform" Future Internet 14, no. 2: 62. https://0-doi-org.brum.beds.ac.uk/10.3390/fi14020062