Adult Users of the Oticon Medical Neuro Cochlear Implant System Benefit from Beamforming in the High Frequencies

 , , , ,
, , , ,
Abstract
:1. Introduction
1.1. Signal Processing to Improve Cochlear Implant Listening
1.2. Neuro CI System by Oticon Medical
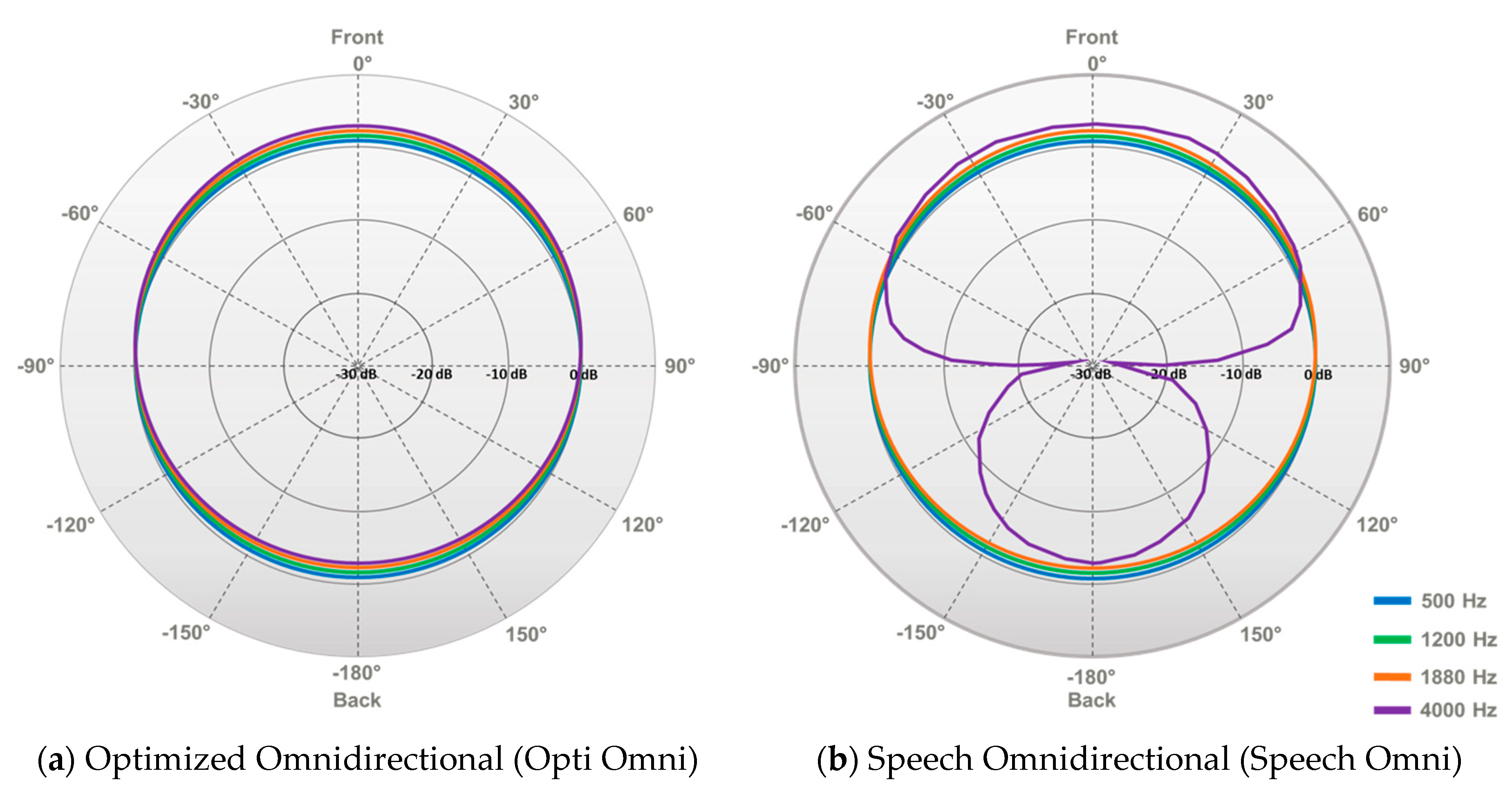
1.3. Previous Studies Comparing Opti Omni and Speech Omni in Hearing Aid and Cochlear Implant Users
1.4. Measuring Directional Microphone Benefit in Cochlear Implant Users
1.5. Research Aim
2. Materials and Methods
2.1. Study 1: Speech Identification with Opti Omni and Speech Omni after Habituation
2.1.1. Summary of Methods
2.1.2. Participants
2.1.3. Procedure
2.2. Study 2: Speech Identification with Opti Omni and Speech Omni at Various Signal-to-Noise Ratios
2.2.1. Summary of Methods
2.2.2. Participants
2.2.3. Procedure
2.3. Statistical Analyses
3. Results
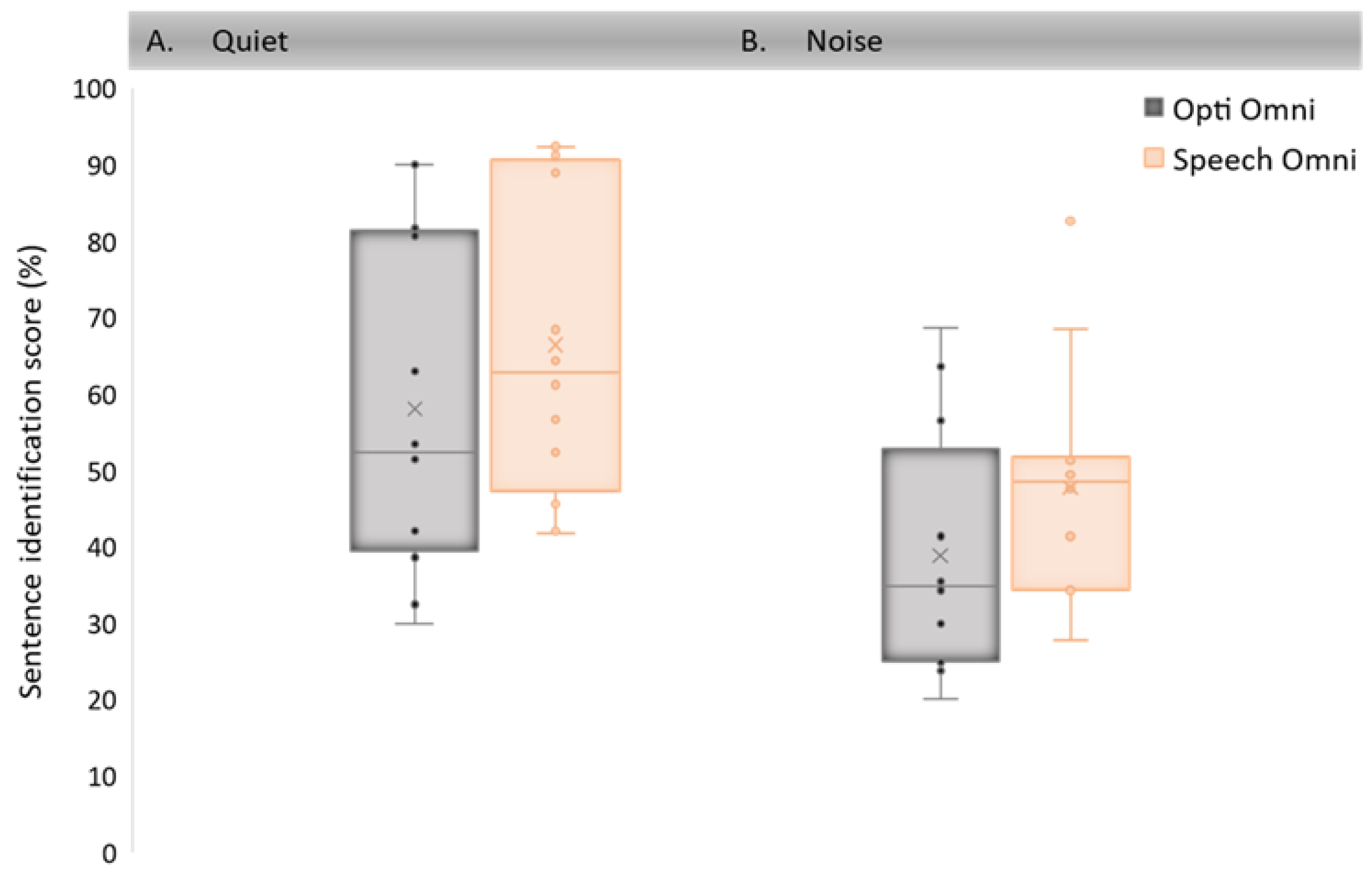
3.1. Study 1: Speech Identification with Opti Omni and Speech Omni after Habituation
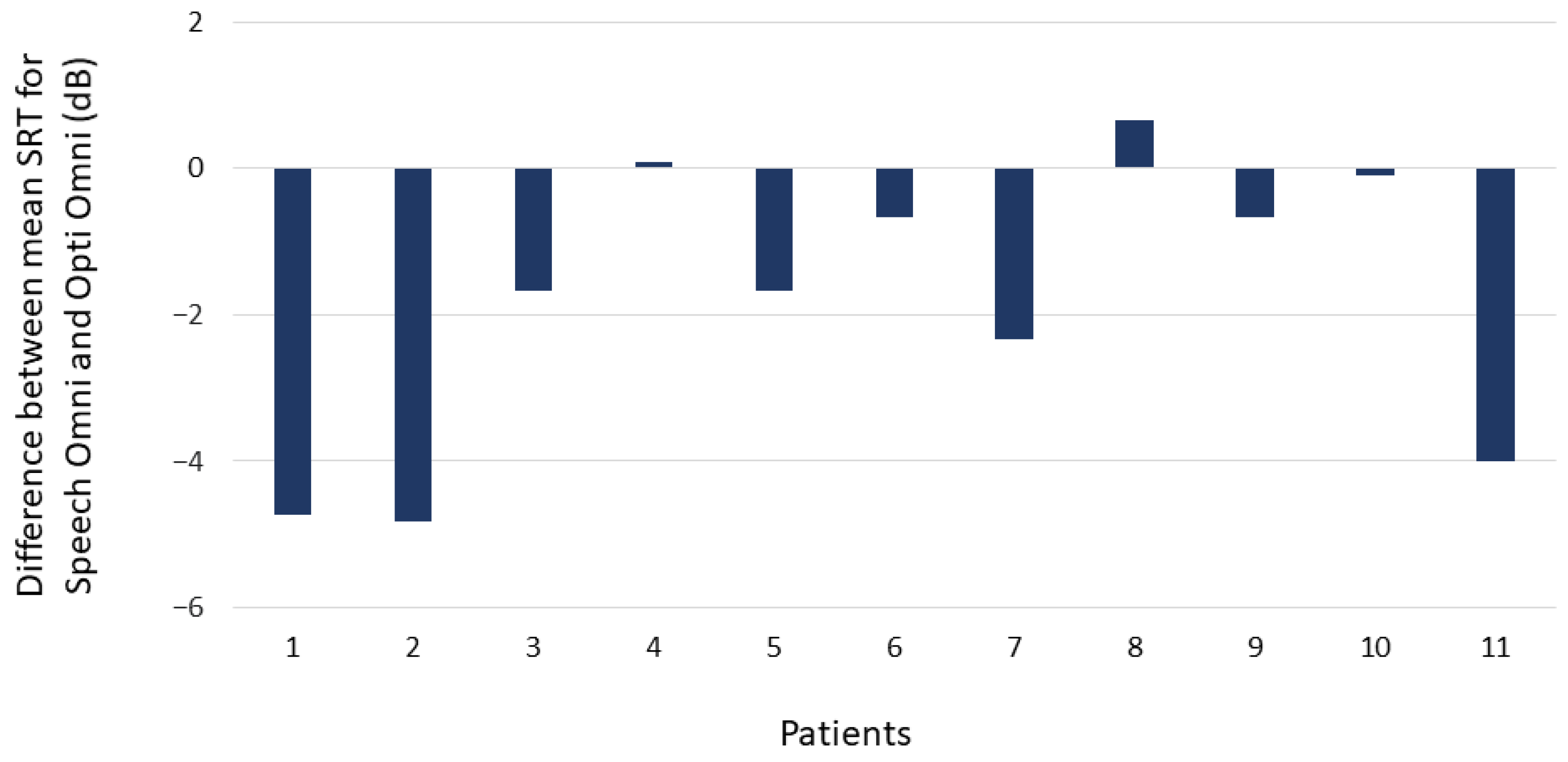
3.2. Study 2: Speech Identification with Opti Omni and Speech Omni at Various Signal-to-Noise Ratios
4. Discussion
4.1. Strengths and Limitations
4.2. Clinical Implications
4.3. Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hazrati, O.; Loizou, P.C. The combined effects of reverberation and noise on speech intelligibility by cochlear implant listeners. Int. J. Audiol. 2012, 51, 437–443. [Google Scholar] [CrossRef]
- Busch, T.; Vanpoucke, F.; van Wieringen, A. Auditory environment across the life span of cochlear implant users: Insights from data logging. J. Speech Lang. Hear. Res. 2017, 60, 1362–1377. [Google Scholar] [CrossRef]
- Dimitrijevic, A.; Smith, M.L.; Kadis, D.S.; Moore, D.R. Neural indices of listening effort in noisy environments. Sci. Rep. 2019, 9, 11278. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wagner, A.E.; Nagels, L.; Toffanin, P.; Opie, J.M.; Başkent, D. Individual variations in effort: Assessing pupillometry for the hearing impaired. Trends Hear. 2019, 23, 2331216519845596. [Google Scholar] [CrossRef] [PubMed]
- Russo, F.Y.; Hoen, M.; Karoui, C.; Demarcy, T.; Ardoint, M.; Tuset, M.P.; De Seta, D.; Sterkers, O.; Lahlou, G.; Mosnier, I. Pupillometry assessment of speech recognition and listening experience in adult cochlear implant patients. Front. Neurosci. 2020, 14, 1115. [Google Scholar] [CrossRef] [PubMed]
- Pichora-Fuller, M.K.; Kramer, S.E.; Eckert, M.A.; Edwards, B.; Hornsby, B.W.; Humes, L.E.; Lemke, U.; Lunner, T.; Matthen, M.; Mackersie, C.L.; et al. Hearing impairment and cognitive energy: The Framework for Understanding Effortful Listening (FUEL). Ear Hear. 2016, 37, 5S–27S. [Google Scholar] [CrossRef] [PubMed]
- Doclo, S.; Gannot, S.; Moonen, M.; Spriet, A. Acoustic beamforming for hearing aid applications. In Handbook on Array Processing and Sensor Networks; Liu, K.J.R., Haykin, S., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2010; Chapter 10; pp. 269–302. [Google Scholar]
- Wouters, J.; Berghe, J.V. Speech recognition in noise for cochlear implantees with a two-microphone monaural adaptive noise reduction system. Ear Hear. 2001, 22, 420–430. [Google Scholar] [CrossRef] [PubMed]
- Kokkinakis, K.; Azimi, B.; Hu, Y.; Friedland, D.R. Single and multiple microphone noise reduction strategies in cochlear implants. Trends Amplif. 2012, 16, 102–116. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chung, K.; Zeng, F.G. Using hearing aid adaptive directional microphones to enhance cochlear implant performance. Hear. Res. 2009, 250, 27–37. [Google Scholar] [CrossRef] [PubMed]
- Franco-Vidal, V.; Parietti-Winkler, C.; Guevara, N.; Truy, E.; Loundon, N.; Bailleux, S.; Ardoint, M.; Saaï, S.; Hoen, M.; Laplante-Lévesque, A.; et al. The Oticon Medical Neuro Zti cochlear implant and the Neuro 2 sound processor: Multicentric evaluation of outcomes in adults and children. Int. J. Audiol. 2020, 59, 153–160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schramm, D.; Chen, J.; Morris, D.P.; Shoman, N.; Philippon, D.; Cayé-Thomasen, P.; Hoen, M.; Karoui, C.; Laplante-Lévesque, A.; Gnansia, D. Clinical efficiency and safety of the Oticon Medical Neuro cochlear implant system: A multicenter prospective longitudinal study. Expert Rev. Med. Devices 2020, 17, 959–967. [Google Scholar] [CrossRef] [PubMed]
- Segovia-Martínez, M.; Gnansia, D.; Hoen, M. Coordinated Adaptive Processing in the Neuro Cochlear Implant System; Oticon Medical White Paper; Oticon Medical: Vallauris, France, 2016. [Google Scholar]
- Weile, J.; Santiago, L.; Newman, C.; Sandridge, S. A broader look at performance and personalization in hearing aid fittings. Hear. Rev. 2016, 18, 16–23. [Google Scholar]
- Caruso, A.; Negri, M.; Zanetti, D.; Guida, M.; Dallaturca, E.; Sanna, M. Neuro Users Say It: The Everyday Sounds Better with Speech-Omni—A Subjective Preference Evaluation of Omni Options in the Neuro System; Oticon Medical White Paper; Oticon Medical: Vallauris, France, 2018. [Google Scholar]
- Spriet, A.; Van Deun, L.; Eftaxiadis, K.; Laneau, J.; Moonen, M.; Van Dijk, B.; Van Wieringen, A.; Wouters, J. Speech understanding in background noise with the two-microphone adaptive beamformer BEAM™ in the Nucleus Freedom™ cochlear implant system. Ear Hear. 2007, 28, 62–72. [Google Scholar] [CrossRef]
- Mosnier, I.; Mathias, N.; Flament, J.; Amar, D.; Liagre-Callies, A.; Borel, S.; Ambert-Dahan, E.; Sterkers, O.; Bernardeschi, D. Benefit of the UltraZoom beamforming technology in noise in cochlear implant users. Eur. Arch. Otorhinolaryngol. 2017, 274, 3335–3342. [Google Scholar] [CrossRef]
- Mauger, S.J.; Warren, C.D.; Knight, M.R.; Goorevich, M.; Nel, E. Clinical evaluation of the Nucleus® 6 cochlear implant system: Performance improvements with SmartSound iQ. Int. J. Audiol. 2014, 53, 564–576. [Google Scholar] [CrossRef] [Green Version]
- Chung, K.; Zeng, F.G.; Acker, K.N. Effects of directional microphone and adaptive multichannel noise reduction algorithm on cochlear implant performance. J. Acoust. Soc. Am. 2006, 120, 2216–2227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hersbach, A.A.; Arora, K.; Mauger, S.J.; Dawson, P.W. Combining directional microphone and single-channel noise reduction algorithms: A clinical evaluation in difficult listening conditions with cochlear implant users. Ear. Hear. 2012, 33, e13–e23. [Google Scholar] [CrossRef]
- Geißler, G.; Arweiler, I.; Hehrmann, P.; Lenarz, T.; Hamacher, V.; Büchner, A. Speech reception threshold benefits in cochlear implant users with an adaptive beamformer in real life situations. Cochlear Implants Int. 2015, 16, 69–76. [Google Scholar] [CrossRef]
- Dorman, M.F.; Natale, S.; Spahr, A.; Castioni, E. Speech understanding in noise by patients with cochlear implants using a monaural adaptive beamformer. J. Speech Lang. Hear. Res. 2017, 60, 2360–2363. [Google Scholar] [CrossRef]
- Honeder, C.; Liepins, R.; Arnoldner, C.; Šinkovec, H.; Kaider, A.; Vyskocil, E.; Riss, D. Fixed and adaptive beamforming improves speech perception in noise in cochlear implant recipients equipped with the MED-EL SONNET audio processor. PLoS ONE 2018, 13, e0190718. [Google Scholar] [CrossRef] [Green Version]
- Ernst, A.; Anton, K.; Brendel, M.; Battmer, R.D. Benefit of directional microphones for unilateral, bilateral and bimodal cochlear implant users. Cochlear Implants Int. 2019, 20, 147–157. [Google Scholar] [CrossRef]
- Sivonen, V.; Willberg, T.; Aarnisalo, A.A.; Dietz, A. The efficacy of microphone directionality in improving speech recognition in noise for three commercial cochlear-implant systems. Cochlear Implants Int. 2020, 21, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Cordeiro, B.B.; Banhara, M.R.; Mendes, C.M. Hearing improvement and influence of hearing deprivation time on speech perception in cochlear implant users. Audiol. Commun. Res. 2020, 25. [Google Scholar] [CrossRef]
- Costa, M.J. Listas De Sentenças Em Português: Apresentação E Estratégias De Aplicação Na Audiologia (Lists of Sentences in Portuguese: Presentation and Application Strategies in Audiology); Pallotti: Santa Maria, CA, USA, 1998. [Google Scholar]
- Costa, M.J.; Iorio, M.C.M.; Mangabeira-Albernaz, P.L. Desenvolvimento de um teste para avaliar a habilidade de reconhecer a fala no silêncio e no ruído (Development of a test to evaluate speech recognition with and without noise). Pró-Fono 2000, 12, 9–16. [Google Scholar]
- Santos, S.N.; Daniel, R.C.; Costa, M.J. Estudo da equivalência entre as listas de sentenças em Português (Study of equivalence among the lists of sentences in Portuguese). Revista CEFAC 2009, 11, 673–680. [Google Scholar] [CrossRef] [Green Version]
- Costa, M.J.; Santos, S.N.; Lessa, A.H.; Mezzomo, C.L. Proposal for implementing the Sentence Recognition Index in individuals with hearing disorders. CoDAS 2015, 27, 148–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leclercq, F.; Renard, C.; Vincent, C. Speech audiometry in noise: Development of the French-language VRB (vocale rapide dans le bruit) test. Eur. Ann. Otorhinolaryngol. Head Neck Dis. 2018, 135, 315–319. [Google Scholar] [CrossRef]
- Killion, M.C.; Niquette, P.A.; Gudmundsen, G.I.; Revit, L.J.; Banerjee, S. Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 2004, 116, 2395–2405. [Google Scholar] [CrossRef] [PubMed]
- Kuznetsova, A.; Brockhoff, P.; Christensen, R. lmerTest Package: Tests in Linear Mixed Effects Models. J. Stat. Soft. 2017, 82. [Google Scholar] [CrossRef] [Green Version]
- Theunissen, M.; Swanepoel, D.W.; Hanekom, J. Sentence recognition in noise: Variables in compilation and interpretation of tests. Int. J. Audiol. 2009, 48, 743–757. [Google Scholar] [CrossRef]
- Hey, M.; Hocke, T.; Böhnke, B.; Mauger, S.J. Forward Focus with cochlear implant recipients in spatially separated and fluctuating competing signals-introduction of a reference metric. Int. J. Audiol. 2019, 58, 869–878. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Study 1 | Study 2 | |
|---|---|---|
| Center and Country | Santo Antônio Hospital, Charitable Works Foundation of Sister Dulce in Salvador, Brazil | Lille University Hospital in Lille, France |
| Participants | 12 Neuro One sound processor users | 11 Neuro 2 sound processor users |
| Sex | 7 women, 5 men | 5 women, 6 men |
| Age | Mean = 39.8 years | Mean = 55.2 years |
| SD = 10.9 years | SD = 18.4 years | |
| Min = 21 years | Min = 19 years | |
| Max = 54 years | Max = 81 years | |
| CI experience 1 | Mean = 0.2 year | Mean = 3.7 years |
| SD = 0.0 year | SD = 2.5 years | |
| Min = 0.2 years | Min = 1 year | |
| Max =0.2 years | Max = 18 years | |
| Deafness duration | Mean = 11.9 years | Mean = 5.1 years |
| SD = 9.8 years | SD = 5.2 years | |
| Min = 1 year | Min = 1 year | |
| Max = 30 years | Max = 19 years | |
| Testing configuration | One Neuro cochlear implant system | |
| Stimuli type | Open-set sentences | |
| Stimuli language | Brazilian Portuguese LLP [30] | French VRB [31] |
| Speech stimuli presentation level | 65 dB SPL | |
| Stimuli position | One loudspeaker: Azimuth 0 degrees | |
| Noise type | Speech-shaped noise i.e., stationary noise | Four-talker babble i.e., fluctuating masker |
| Noise presentation level(s) | 55 dB SPL | 47 to 68 dB SPL, increasing in 3 dB steps |
| Noise position | One loudspeaker: Azimuth 180 degrees | Five loudspeakers: Azimuth 0, +60, +120, −120, and −60 degrees |
| Signal-to-noise ratio | +10 dB | +18 to –3 dB, reducing in 3 dB steps |
| −3 | 0 | 3 | 6 | 9 | 12 | 15 | 18 | Quiet | |
|---|---|---|---|---|---|---|---|---|---|
| −3 | |||||||||
| 0 | 1.000 | ||||||||
| 3 | 0.996 | 0.099 | |||||||
| 6 | 0.001 | 0.002 | 0.099 | ||||||
| 9 | <0.001 | <0.001 | <0.001 | 0.014 | |||||
| 12 | <0.001 | <0.001 | <0.001 | <0.001 | 0.005 | ||||
| 15 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | 1.000 | |||
| 18 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | 0.478 | 0.973 | ||
| Quiet | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | 0.008 | 0.161 | 0.990 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bastos Cordeiro, B.; Banhara, M.R.; Cardeal Mendes, C.M.; Danieli, F.; Laplante-Lévesque, A.; Karoui, C.; Hoen, M.; Ardoint, M.; Gauvrit, F.; Demullier, R.; et al. Adult Users of the Oticon Medical Neuro Cochlear Implant System Benefit from Beamforming in the High Frequencies. Audiol. Res. 2021, 11, 179-191. https://0-doi-org.brum.beds.ac.uk/10.3390/audiolres11020016
Bastos Cordeiro B, Banhara MR, Cardeal Mendes CM, Danieli F, Laplante-Lévesque A, Karoui C, Hoen M, Ardoint M, Gauvrit F, Demullier R, et al. Adult Users of the Oticon Medical Neuro Cochlear Implant System Benefit from Beamforming in the High Frequencies. Audiology Research. 2021; 11(2):179-191. https://0-doi-org.brum.beds.ac.uk/10.3390/audiolres11020016
Chicago/Turabian StyleBastos Cordeiro, Bianca, Marcos Roberto Banhara, Carlos Maurício Cardeal Mendes, Fabiana Danieli, Ariane Laplante-Lévesque, Chadlia Karoui, Michel Hoen, Marine Ardoint, Fanny Gauvrit, Romane Demullier, and et al. 2021. "Adult Users of the Oticon Medical Neuro Cochlear Implant System Benefit from Beamforming in the High Frequencies" Audiology Research 11, no. 2: 179-191. https://0-doi-org.brum.beds.ac.uk/10.3390/audiolres11020016