Design a Semantic Scale for Passenger Perceived Quality Surveys of Urban Rail Transit: Within Attribute’s Service Condition and Rider’s Experience


Abstract
:1. Introduction
2. Literature Review
3. Methodology
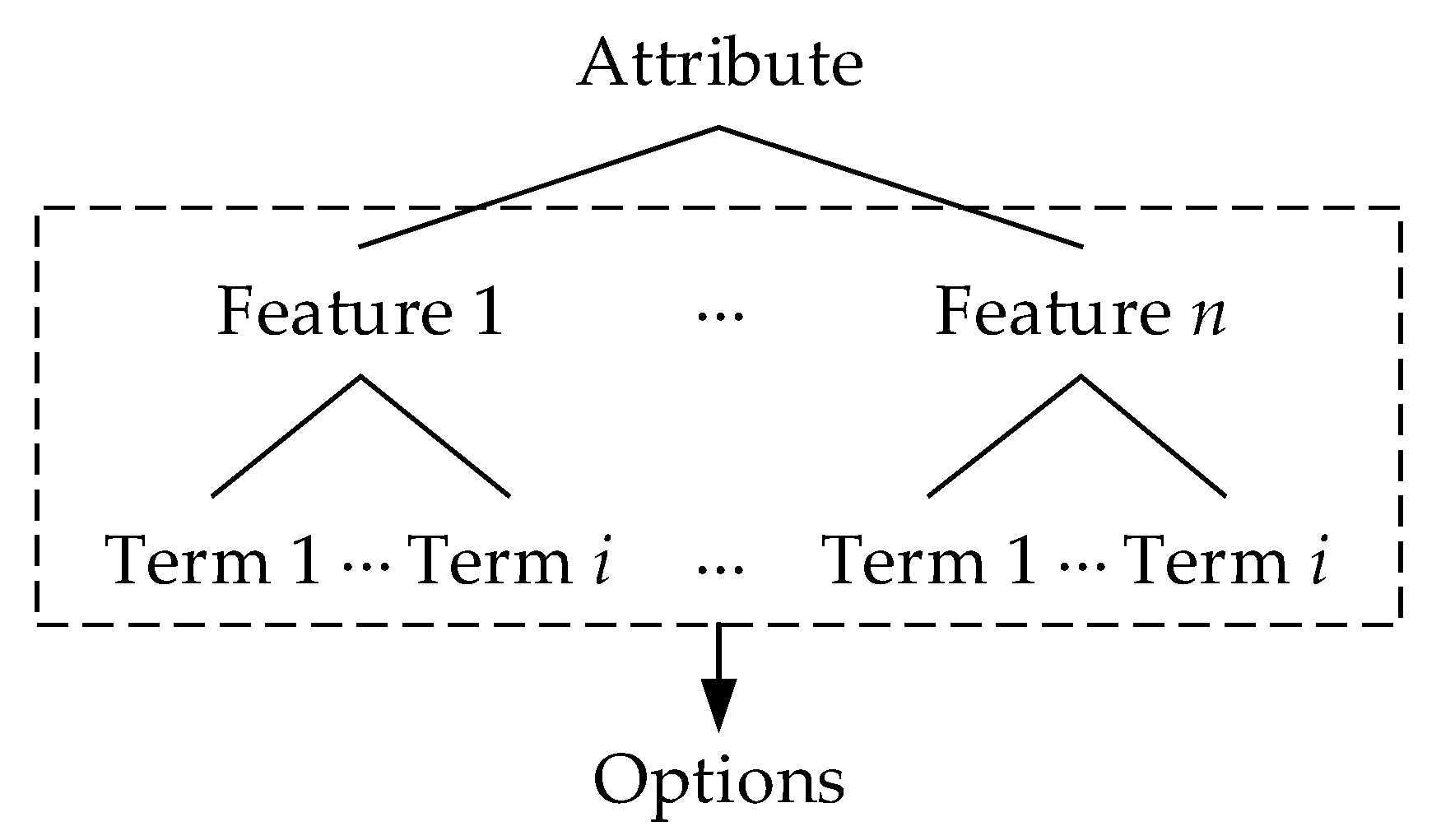
3.1. Design Concept and Framework
3.2. Key Steps
3.2.1. First Step: Identifying Features of Attribute
3.2.2. Second Step: Identifying Terms of Features
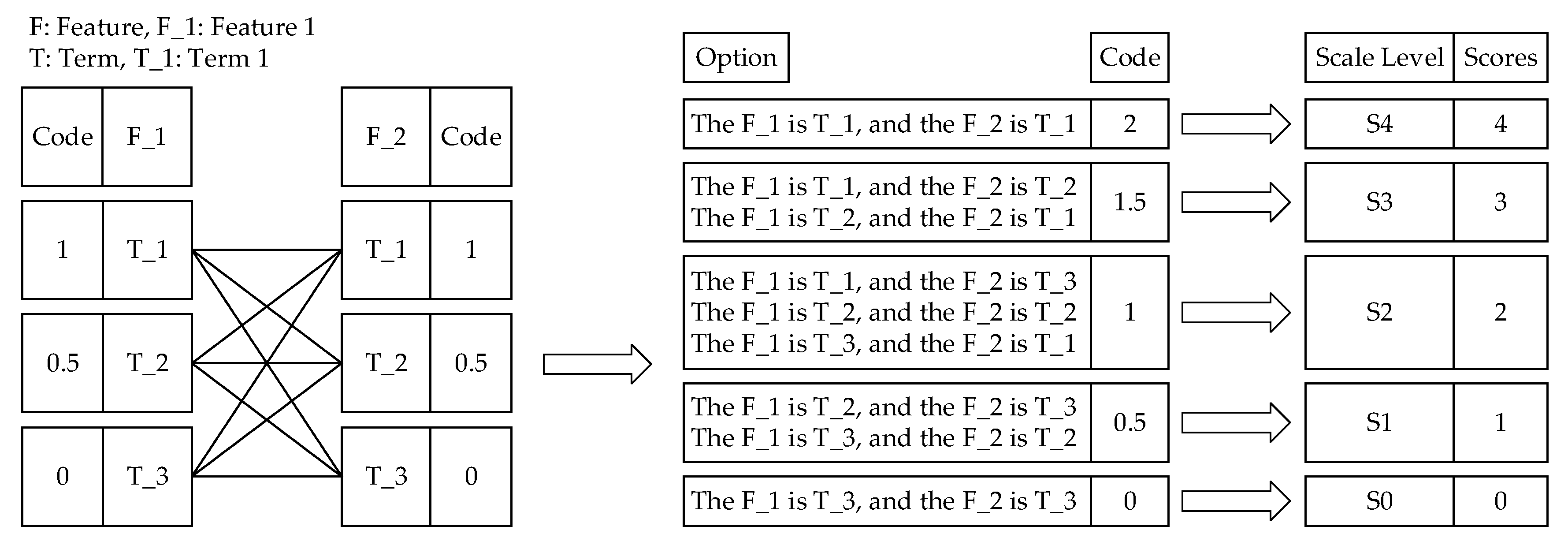
3.2.3. Third Step: Combing Features and Their Terms to Form Options
3.2.4. Fourth Step: Assigning Scale Levels and Scores to Options
4. Application of Semantic Scale Design in Urban Rail Transit Service
4.1. First Step: Identifying Features of Attributes
4.2. Second Step: Identifying Terms of Features
4.3. Third Step: Combing Features and Their Terms to Form Options
4.4. Fourth Step: Assigning Scale Levels and Scores to Options
4.5. The Validity and Reliability
5. Empirical Study
5.1. Data Collection
5.2. Data Processing
- In the first step, we excluded the invalid questionnaires.
- In the second step, we converted the evaluation result of the semantic scale into scores.
- In the third step, we compared the score’s relative frequency distributions in the three scales of each attribute and then conducted hypothesis tests.
- In the fourth step, we compared the means in the three scales of each attribute and then conducted hypothesis tests.
- In the fifth step, we compared the variances in the three scales of each attribute and then conducted hypothesis tests.
5.3. Results and Discussion
5.3.1. Comparisons of the Score’s Relative Frequency Distributions
- On the semantic scale, the four-point frequency of some attributes is around the sum of the three- and four-point frequencies on the other two scales.
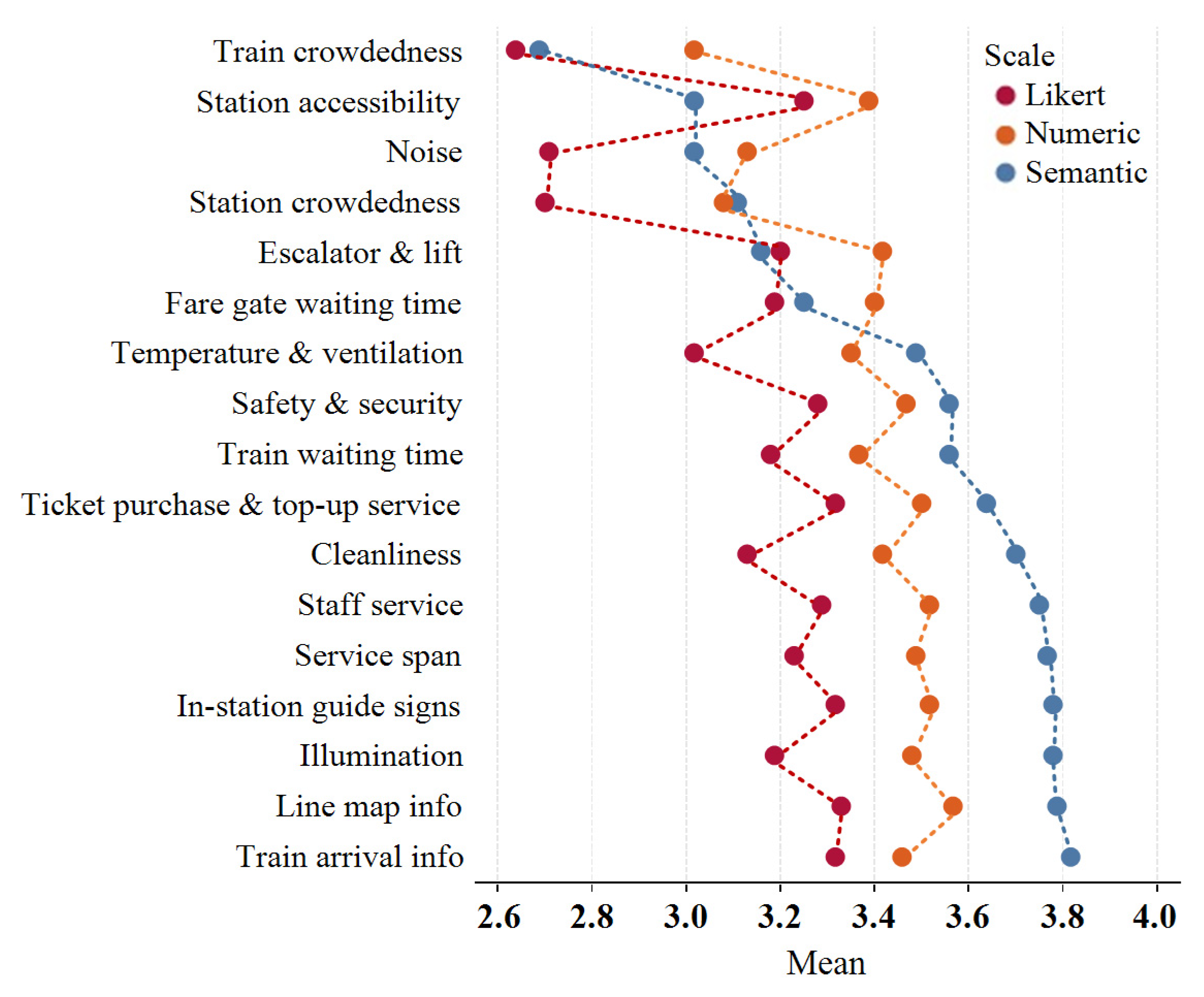
5.3.2. Mean Comparison
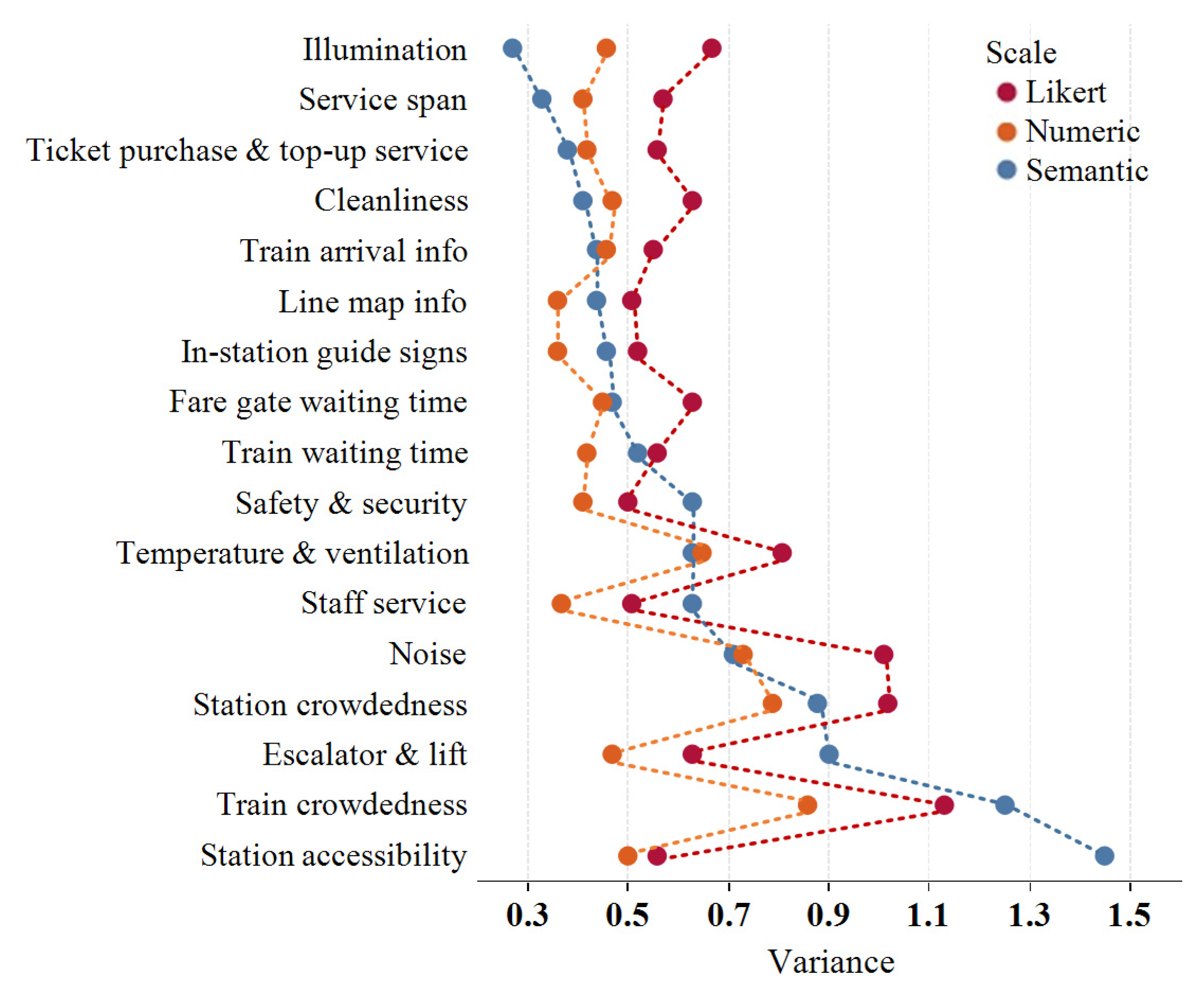
5.3.3. Variance Comparison
6. Conclusions
- First, for attributes with homogeneous service conditions over operation periods, the semantic scale offers fairer evaluation results from the transit agency perspective than Likert and numeric scales. It can be because of lessened hesitation among riders when answering.
- Second, the semantic scale can usually reduce central tendency bias. It may be because the semantic scale options depict visualized service conditions of attributes or rider’s experience.
- Third, compared to Likert and numeric scales, the evaluation result of the semantic scale is more homogeneous for attributes with homogeneous service conditions and is more heterogeneous for attributes with heterogeneous service conditions. It can be due to fewer riders’ cognitive steps are required while applying the semantic scale to answer.
- First, as the scale form can affect the evaluation results, we recommend transport authorities to unify a questionnaire of passenger perceived quality surveys of urban rail transit in a region or even the whole country. Hence, when the evaluation results of different times (e.g., different years) or spaces (e.g., different cities) are compared, the results are more reliable.
- Second, the collected data should cover operation periods as fully as possible; otherwise, it may increase the measured deviation of riders’ perceived quality.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Percentage (%) | |||
|---|---|---|---|
| Empirical Study (n = 408) | Focus Group (n = 10) | ||
| Gender | Male | 39.71 | 40 |
| Female | 60.29 | 60 | |
| Age (years old) | <20 | 21.08 | 30 |
| 20–40 | 55.88 | 50 | |
| >40 | 23.04 | 20 | |
| Education background | Under college | 27.45 | 30 |
| Bachelor | 49.02 | 50 | |
| Master or Ph.D. | 23.53 | 20 | |
| Driver license | Yes | 44.12 | 50 |
| No | 55.88 | 50 | |
| Private car ownership | Yes | 48.53 | 40 |
| No | 51.47 | 60 | |
| Metro use frequency | Daily | 31.37 | 40 |
| Weekly | 43.38 | 40 | |
| Monthly or fewer | 25.25 | 20 | |
| Travel purpose of metro | Commute | 54.90 | 40 |
| Entertainment (e.g., shopping, parks) | 41.18 | 50 | |
| Others (e.g., see a doctor) | 3.92 | 10 | |
| Ticket types | Cash | 2.45 | 10 |
| Pass | 76.96 | 50 | |
| Mobile phone | 19.36 | 40 | |
| Free of charge | 1.23 | 0 | |
| Evaluated operation periods | |||
| Weekdays | Before 07:00 | 5.66 | |
| 07:00–10:00 | 49.06 | ||
| 10:00–17:00 | 26.89 | ||
| 17:00–20:30 | 14.15 | ||
| 20:30–21:30 | 2.83 | ||
| After 21:30 | 1.42 | ||
| Total | 51.96 | ||
| Weekends | Before 09:00 | 4.59 | |
| 09:00–15:00 | 67.35 | ||
| 15:00–22:00 | 25.00 | ||
| After 22:00 | 3.06 | ||
| Total | 48.04 | ||
References
- Transportation Research Board; The National Academies of Sciences, Engineering, and Medicine. Transit Capacity and Quality of Service Manual, 3rd ed.; Kittelson, &, Associates, Inc., Parsons Brinckerhoff, KFH Group, Texas A, &, M Transportation, Institute, Eds.; The National Academies Press: Washington, DC, USA, 2013; Chapter 4, p. 6, Chapter 5, pp. 4, 24, Chapter 10, p. 14, Chapter 4, pp. 17–36, Chapter 10, pp. 10–29. [Google Scholar]
- De Oña, J.; De Oña, R.; Eboli, L.; Mazzulla, G. Perceived service quality in bus transit service: A structural equation approach. Transp. Policy 2013, 29, 219–226. [Google Scholar] [CrossRef]
- Guirao, B.; García-Pastor, A.; López-Lambas, M.E. The importance of service quality attributes in public transportation: Narrowing the gap between scientific research and practitioners’ needs. Transp. Policy 2016, 49, 68–77. [Google Scholar] [CrossRef]
- De Oña, J.; De Oña, R.; Eboli, L.; Mazzulla, G. Index numbers for monitoring transit service quality. Transp. Res. Part A Policy Pract. 2016, 84, 18–30. [Google Scholar] [CrossRef]
- Rahman, F.; Das, T.; Hadiuzzaman, M.; Hossain, S. Perceived service quality of paratransit in developing countries: A structural equation approach. Transp. Res. Part A Policy Pract. 2015, 93, 23–38. [Google Scholar] [CrossRef]
- De Oña, J.; De Oña, R. Quality of service in public transport based on customer satisfaction surveys: A review and assessment of methodological approaches. Transp. Sci. 2015, 49, 605–622. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Y.; Lu, W.; Xiao, G. Evaluating passenger satisfaction index based on PLS-SEM model: Evidence from Chinese public transport service. Transp. Res. Part A Policy Pract. 2019, 120, 149–164. [Google Scholar] [CrossRef]
- Hernandez, S.; Monzon, A.; de Oña, R. Urban transport interchanges: A methodology for evaluating perceived quality. Transp. Res. Part A Policy Pract. 2016, 84, 31–43. [Google Scholar] [CrossRef]
- Tourangeau, R.; Rips, L.J.; Rasinski, K. The Psychology of Survey Response; Cambridge University Press: Cambridge, UK, 2000; pp. 1–22. ISBN 0521576296. [Google Scholar]
- Krosnick, J.A.; Presser, S. Question and Questionnaire Design; Standford University: Standford, CA, USA, 2010; pp. 10–11. [Google Scholar]
- Brace, I. Questionnaire Design: How to Plan, Structure and Write Survey Material for Effective Market Research; Kogan Page Publishers: London, UK, 2018; pp. 51, 53, 78, 135; ISBN 0749481986. [Google Scholar]
- Barabino, B.; Deiana, E.; Tilocca, P. Measuring service quality in urban bus transport: A modified SERVQUAL approach. Int. J. Qual. Serv. Sci. 2012, 4, 238–252. [Google Scholar] [CrossRef]
- Marcucci, E.; Gatta, V. Quality and public transport service contracts. Eur. Transp. 2007, 36, 92–106. [Google Scholar]
- Eboli, L.; Mazzulla, G. A stated preference experiment for measuring service quality in public transport. Transp. Plan. Technol. 2008, 31, 509–523. [Google Scholar] [CrossRef] [Green Version]
- Beck, M.J.; Rose, J.M. The best of times and the worst of times: A new best-worst measure of attitudes toward public transport experiences. Transp. Res. Part A Policy Pract. 2016, 86, 108–123. [Google Scholar] [CrossRef]
- Echaniz, E.; Ho, C.Q.; Rodriguez, A.; dell’Olio, L. Comparing best-worst and ordered logit approaches for user satisfaction in transit services. Transp. Res. Part A Policy Pract. 2019, 130, 752–769. [Google Scholar] [CrossRef]
- Presser, S.; Schuman, H. The Measurement of a Middle Position in Attitude Surveys. Public Opin. Q. 1980, 44, 70–85. [Google Scholar] [CrossRef]
- Ofir, C.; Reddy, S.K.; Bechtel, G.G. Are Semantic Response Scales Equivalent? Multivar. Behav. Res. 1987, 22, 21–38. [Google Scholar] [CrossRef]
- Friborg, O.; Martinussen, M.; Rosenvinge, J.H. Likert-based vs. semantic differential-based scorings of positive psychological constructs: A psychometric comparison of two versions of a scale measuring resilience. Pers. Individ. Diff. 2006, 40, 873–884. [Google Scholar] [CrossRef]
- Bonera, M.; Maternini, G.; Parkhurst, G.; Paddeu, D.; Clayton, W.; Vetturi, D. Travel experience on board urban buses: A comparison between Bristol and Brescia. Eur. Transp. Trasp. Eur. 2020, 1–12. [Google Scholar]
- Barabino, B.; Cabras, N.A.; Conversano, C.; Olivo, A. An Integrated Approach to Select Key Quality Indicators in Transit Services; Springer Netherlands: Berlin/Heidelberg, Germany, 2020; Volume 149, ISBN 0123456789. [Google Scholar]
- Dell’Olio, L.; Ibeas, A.; De Ona, J.; De Ona, R. Public Transportation Quality of Service: Factors, Models, and Applications; Elsevier: Amsterdam, The Netherlands, 2017; pp. 41, 105, 111, 115; ISBN 0081022794. [Google Scholar]
- De Oña, J.; De Oña, R.; Eboli, L.; Mazzulla, G. Heterogeneity in Perceptions of Service Quality among Groups of Railway Passengers. Int. J. Sustain. Transp. 2015, 9, 612–626. [Google Scholar] [CrossRef]
- De Oña, R.; Eboli, L.; Mazzulla, G. Key factors affecting rail service quality in the Northern Italy: A decision tree approach. Transport 2014, 29, 75–83. [Google Scholar] [CrossRef] [Green Version]
- Aydin, N. A fuzzy-based multi-dimensional and multi-period service quality evaluation outline for rail transit systems. Transp. Policy 2017, 55, 87–98. [Google Scholar] [CrossRef]
- Awasthi, A.; Chauhan, S.S.; Omrani, H.; Panahi, A. A hybrid approach based on SERVQUAL and fuzzy TOPSIS for evaluating transportation service quality. Comput. Ind. Eng. 2011, 61, 637–646. [Google Scholar] [CrossRef]
- Nathanail, E. Measuring the quality of service for passengers on the Hellenic railways. Transp. Res. Part A Policy Pract. 2008, 42, 48–66. [Google Scholar] [CrossRef]
- Eboli, L.; Mazzulla, G. Relationships between rail passengers’ satisfaction and service quality: A framework for identifying key service factors. Public Transp. 2015, 7, 185–201. [Google Scholar] [CrossRef]
- Shen, W.; Xiao, W.; Wang, X. Passenger satisfaction evaluation model for Urban rail transit: A structural equation modeling based on partial least squares. Transp. Policy 2016, 46, 20–31. [Google Scholar] [CrossRef]
- Wilson, F.R.; Pan, W.; Schumsky, D.A. Recalculation of the critical values for Lawshe’s content validity ratio. Meas. Eval. Couns. Dev. 2012, 45, 197–210. [Google Scholar] [CrossRef] [Green Version]
- Devon, H.A.; Block, M.E.; Moyle-Wright, P.; Ernst, D.M.; Hayden, S.J.; Lazzara, D.J.; Savoy, S.M.; Kostas-Polston, E. A psychometric toolbox for testing validity and reliability. J. Nurs. Scholarsh. 2007, 39, 155–164. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, G.E.; Prion, S. Making Sense of Methods and Measurement: Lawshe’s Content Validity Index. Clin. Simul. Nurs. 2016, 12, 530–531. [Google Scholar] [CrossRef]
- Lawshe, C.H. A quantitative approach to content validity”.Personnel Psychology. Pers. Psychol. 1975, 28, 563–575. [Google Scholar] [CrossRef]
- Ayre, C.; Scally, A.J. Critical values for Lawshe’s content validity ratio: Revisiting the original methods of calculation. Meas. Eval. Couns. Dev. 2014, 47, 79–86. [Google Scholar] [CrossRef] [Green Version]
- Wenjuanxing Homepage. Available online: https://www.wjx.cn/ (accessed on 15 April 2020).
- Cochran, W.G. Sampling Techniques; John Wiley & Sons: Hoboken, NJ, USA, 2007; ISBN 8126515244. [Google Scholar]
- Yannis, T.; Georgia, A. A complete methodology for the quality control of passenger services in the public transport business. Eur. Transp. Eur. 2008, 38, 1–16. [Google Scholar]
- Hassan, M.N.; Hawas, Y.E.; Ahmed, K. A multi-dimensional framework for evaluating the transit service performance. Transp. Res. Part A Policy Pract. 2013, 50, 47–61. [Google Scholar] [CrossRef]
- Echaniz, E.; dell’Olio, L.; Ibeas, Á. Modelling perceived quality for urban public transport systems using weighted variables and random parameters. Transp. Policy 2018, 67, 31–39. [Google Scholar] [CrossRef]
- Dell’Olio, L.; Ibeas, A.; Cecin, P. The quality of service desired by public transport users. Transp. Policy 2011, 18, 217–227. [Google Scholar] [CrossRef]
- Li, L.; Cao, M.; Bai, Y.; Song, Z. Analysis of Public Transportation Competitiveness Based on Potential Passenger Travel Intentions: Case Study in Shanghai, China. Transp. Res. Rec. 2019, 2673, 823–832. [Google Scholar] [CrossRef]
- Yap, B.W.; Sim, C.H. Comparisons of various types of normality tests. J. Stat. Comput. Simul. 2011, 81, 2141–2155. [Google Scholar] [CrossRef]
- Stephens, M.A. EDF Statistics for Goodness of Fit and Some Comparisons. J. Am. Stat. Assoc. 1974, 69, 730–737. [Google Scholar] [CrossRef]
- Krosnick, J.A. Response strategies for coping with the cognitive demands of attitude measures in surveys. Appl. Cogn. Psychol. 1991, 5, 213–236. [Google Scholar] [CrossRef]
- Kalton, G.; Roberts, J.; Holt, D. The Effects of Offering a Middle Response Option with Opinion Questions. J. R. Stat. Soc. Ser. D Stat. 1980, 29, 65–78. [Google Scholar] [CrossRef]
- Barabino, B. Automatic Recognition of “Low-Quality” Vehicles and Bus Stops in Bus Services; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10, ISBN 0123456789. [Google Scholar]
- Eboli, L.; Mazzulla, G. A methodology for evaluating transit service quality based on subjective and objective measures from the passenger’s point of view. Transp. Policy 2011, 18, 172–181. [Google Scholar] [CrossRef]






| Scales | Cognitive Step | Real Experience Reflection | Data Quality | Data Process | Usage Frequency |
|---|---|---|---|---|---|
| Likert | four | vague | central tendency bias (respondents tend to choose the option near the middle level instead of the extreme levels) | easy | popular |
| Numeric | four | vague | - | easy | popular |
| Stated preference | two | detailed | less central tendency bias | complex | moderate |
| Best–worst | four | vague | better derived importance of attributes | complex | low |
| Semantic-differential | four | less vague | high reliability, internal validity, and model fit | easy | low |
| Attribute | Feature | The Term Used to Describe the Feature (Code) |
|---|---|---|
| Station accessibility | Distance | Walking (1) cycling (0.5) vehicle transfer (0) |
| Walking environment | good (1) bad (0) | |
| In-station guide signs/Line map info/Train arrival info | Clarity | clear (1) a bit unclear (0.5) hard to understand (0) |
| Conspicuousness | conspicuous (1) concealed (0) | |
| Ticket purchase and top-up service | Operational simplicity | simple (1) a bit inconvenient (0.5) inconvenient (0) |
| Number of machines | sufficient (1) a bit insufficient (0.5) insufficient (0) | |
| Fare gate waiting time | Length | wait a moment (1) a long line (0) |
| Machine sensitivity | smooth (1) stuck (0) | |
| Escalator and lift | Crowdedness | no need to wait or wait a moment (1) a long line (0) |
| Frequency of out of service | never met (1) occasionally encountered on (0.5) often encountered on (0) | |
| Station crowdedness | Walking speed | freely selected (1) slightly restricted (0.75) slow move (0.5) hard to move (0.25) wait outside the station (0) |
| Frequency of physical contact with others | without(1) avoidable (0.75) occasional (0.5) frequent (0.25) wait outside the station (0) | |
| Train waiting time | Frequency of checking train timetable | no need (1) want to (0.75) occasional (0.5) frequent (0.25) must (0) |
| Train crowdedness | Number of available handrails | Plenty or have empty seats (1) some (0.75) few (0.5) zero (0.25) fail to get on and off one or more times (0) |
| Frequency of physical contact with others | retain space (1) without (0.75) occasional (0.5) frequent (0.25) fail to get on and off one or more times (0) | |
| Noise | Level | small (1) big (0) |
| Continuity | intermittent (1) continuous (0) | |
| Illumination | Brightness | bright (1) slightly dark (0.5) Dark (0) |
| Broken lights | not found (1) found (0.5) there are many (0) | |
| Temperature and ventilation | Temperature comfort | comfortable (1) slightly sweating or trembling (0.5) significantly sweating or trembling (0) |
| Air circulation | well-ventilated (1) a bit unventilated (0.5) unventilated (0) | |
| Cleanliness | Stains, dust | not found (1) found (0.5) there are much (0) |
| Trash | not found (1) found (0.5) there are much (0) | |
| Staff service | Attitude | friendly (1) indifferent (0) |
| Work ability | solve problems quickly (1) solve problems slowly (0.5) cannot solve problems (0) | |
| Safety and security | Personal safety | no worries (1) occasional worries (0.5) frequent worries (0) |
| Property security | no worries (1) occasional worries (0.5) frequent worries (0) | |
| Service span | Start of operation | meet my demand (1) a bit late (0.5) too late (0) |
| End of operation | meet my demand (1) a bit early (0.5) too early (0) |
| Attribute | Feature | Content Validity | Reliability |
|---|---|---|---|
| Lawshe’s CVR | Cronbach’s α | ||
| Station accessibility | Distance | 0.99 | 0.84 |
| Walking environment | 0.99 | ||
| In-station guide signs | Clarity | 0.99 | |
| Conspicuousness | 0.99 | ||
| Ticket purchase and top-up service | Operational simplicity | 0.99 | |
| Number of machines | 0.99 | ||
| Fare gate waiting time | Length | 0.75 | |
| Machine sensitivity | 0.75 | ||
| Line map info | Clarity | 0.99 | |
| Conspicuousness | 0.99 | ||
| Escalator and lift | Crowdedness | 0.75 | |
| Frequency of out of service | 0.75 | ||
| Station crowdedness | Walking speed | 0.99 | |
| Frequency of physical contact with others | 0.99 | ||
| Train arrival info | Clarity | 0.99 | |
| Conspicuousness | 0.99 | ||
| Train waiting time | Frequency of checking train timetable | 0.99 | |
| Train crowdedness | Number of available handrails | 0.99 | |
| Frequency of physical contact with others | 0.99 | ||
| Noise | Level | 0.75 | |
| Continuity | 0.75 | ||
| Illumination | Brightness | 0.75 | |
| Broken lights | 0.75 | ||
| Temperature and ventilation | Temperature comfort | 0.99 | |
| Air circulation | 0.99 | ||
| Cleanliness | Stains, dust | 0.99 | |
| Trash | 0.99 | ||
| Staff service | Attitude | 0.99 | |
| Work ability | 0.99 | ||
| Safety and security | Personal safety | 0.99 | |
| Property security | 0.99 | ||
| Service span | Start of operation | 0.99 | |
| End of operation | 0.99 |
| Attribute | Scale Form | Score’s Relative Frequency Distributions | p-Value of Bowker Test | |||||
|---|---|---|---|---|---|---|---|---|
| 4 | 3 | 2 | 1 | 0 | ||||
| Station accessibility | Likert | 40.20 | 47.79 | 10.54 | 0.25 | 1.23 | *** | *** |
| Semantic | 55.39 | 4.66 | 30.88 | 4.66 | 4.41 | |||
| Numeric | 50.25 | 40.69 | 7.11 | 1.96 | 0.00 | |||
| In-station guide signs | Likert | 42.65 | 49.51 | 6.13 | 0.49 | 1.23 | *** | *** |
| Semantic | 87.25 | 8.09 | 1.23 | 2.45 | 0.98 | |||
| Numeric | 57.60 | 37.01 | 5.39 | 0.00 | 0.00 | |||
| Ticket purchase and top-up service | Likert | 43.87 | 47.06 | 7.35 | 0.25 | 1.47 | *** | 0.013 * |
| Semantic | 69.85 | 25.00 | 4.41 | 0.49 | 0.25 | |||
| Numeric | 57.11 | 36.76 | 5.39 | 0.49 | 0.25 | |||
| Fare gate waiting time | Likert | 37.25 | 49.26 | 10.54 | 1.47 | 1.47 | 0.005 ** | *** |
| Semantic | 35.54 | 56.86 | 4.66 | 2.70 | 0.25 | |||
| Numeric | 49.26 | 43.14 | 6.62 | 0.74 | 0.25 | |||
| Line map info | Likert | 43.63 | 48.53 | 6.37 | 0.25 | 1.23 | *** | *** |
| Semantic | 88.97 | 4.41 | 4.17 | 1.72 | 0.74 | |||
| Numeric | 61.76 | 33.58 | 4.17 | 0.49 | 0.00 | |||
| Escalator and lift | Likert | 36.76 | 50.74 | 9.56 | 1.23 | 1.72 | *** | *** |
| Semantic | 43.38 | 38.97 | 8.33 | 8.58 | 0.74 | |||
| Numeric | 51.96 | 39.46 | 7.60 | 0.74 | 0.25 | |||
| Station crowdedness | Likert | 24.51 | 34.80 | 28.68 | 10.05 | 1.96 | *** | 0.30 |
| Semantic | 39.95 | 39.71 | 13.24 | 5.64 | 1.47 | |||
| Numeric | 37.01 | 40.20 | 17.40 | 4.66 | 0.74 | |||
| Train arrival info | Likert | 43.38 | 49.75 | 4.17 | 1.23 | 1.47 | *** | *** |
| Semantic | 91.18 | 3.43 | 1.72 | 3.19 | 0.49 | |||
| Numeric | 54.66 | 38.24 | 5.88 | 0.98 | 0.25 | |||
| Train waiting time | Likert | 35.05 | 50.00 | 13.48 | 0.49 | 0.98 | *** | *** |
| Semantic | 66.18 | 25.74 | 6.13 | 1.47 | 0.49 | |||
| Numeric | 46.08 | 45.59 | 7.84 | 0.49 | 0.00 | |||
| Train crowdedness | Likert | 23.28 | 35.29 | 26.72 | 11.27 | 3.43 | 0.03 * | *** |
| Semantic | 30.64 | 25.49 | 28.92 | 12.01 | 2.94 | |||
| Numeric | 34.31 | 40.93 | 18.63 | 4.41 | 1.72 | |||
| Noise | Likert | 24.02 | 36.76 | 27.94 | 8.82 | 2.45 | *** | 0.002 ** |
| Semantic | 28.19 | 52.70 | 12.99 | 5.15 | 0.98 | |||
| Numeric | 38.73 | 41.18 | 15.20 | 4.66 | 0.25 | |||
| Illumination | Likert | 38.97 | 45.83 | 12.25 | 1.47 | 1.47 | *** | *** |
| Semantic | 82.84 | 13.24 | 3.68 | 0.00 | 0.25 | |||
| Numeric | 56.62 | 37.01 | 4.66 | 1.47 | 0.25 | |||
| Temperature and ventilation | Likert | 33.33 | 42.40 | 19.12 | 3.68 | 1.47 | *** | *** |
| Semantic | 65.20 | 20.34 | 12.99 | 0.98 | 0.49 | |||
| Numeric | 51.23 | 36.52 | 9.07 | 2.45 | 0.74 | |||
| Cleanliness | Likert | 33.33 | 50.49 | 13.48 | 1.23 | 1.47 | *** | *** |
| Semantic | 78.92 | 13.48 | 6.86 | 0.49 | 0.25 | |||
| Numeric | 51.47 | 40.69 | 6.62 | 0.98 | 0.25 | |||
| Staff service | Likert | 41.18 | 49.02 | 8.58 | 0.25 | 0.98 | *** | *** |
| Semantic | 88.24 | 4.41 | 2.94 | 2.45 | 1.96 | |||
| Numeric | 57.35 | 37.50 | 4.66 | 0.49 | 0.00 | |||
| Safety and security | Likert | 40.20 | 50.25 | 8.33 | 0.25 | 0.98 | *** | *** |
| Semantic | 72.30 | 13.73 | 12.50 | 0.74 | 0.74 | |||
| Numeric | 54.41 | 38.48 | 6.62 | 0.49 | 0.00 | |||
| Service span | Likert | 38.24 | 49.75 | 9.56 | 1.47 | 0.98 | *** | *** |
| Semantic | 84.07 | 9.56 | 5.64 | 0.74 | 0.00 | |||
| Numeric | 55.39 | 39.22 | 4.17 | 1.23 | 0.00 | |||
| Attribute | p-Value of Paired-Sample t-Test or Wilcoxon Signed-Rank Test | |
|---|---|---|
| Train crowdedness | 0.38 | *** |
| Station accessibility | *** | *** |
| Noise | *** | 0.004 ** |
| Station crowdedness | *** | 0.47 |
| Escalator and lift | 0.43 | *** |
| Fare gate waiting time | 0.27 | *** |
| Temperature and ventilation | *** | *** |
| Safety and security | *** | 0.004 ** |
| Train waiting time | *** | *** |
| Ticket purchase and top-up service | *** | *** |
| Cleanliness | *** | *** |
| Staff service | *** | *** |
| Service span | *** | *** |
| In-station guide signs | *** | *** |
| Illumination | *** | *** |
| Line map info | *** | *** |
| Train arrival info | *** | *** |
| Attribute | p-Value of Paired-Sample F-test or Levene Test | |
|---|---|---|
| Illumination | *** | *** |
| Service span | *** | *** |
| Ticket purchase and top-up service | *** | 0.002** |
| Cleanliness | *** | *** |
| Train arrival info | *** | *** |
| Line map info | *** | *** |
| In-station guide signs | *** | *** |
| Fare gate waiting time | 0.03 * | 0.002 ** |
| Train waiting time | 0.07 | 0.02 * |
| Safety and security | 0.09 * | 0.06 |
| Temperature and ventilation | 0.010 ** | 0.014 * |
| Staff service | *** | *** |
| Noise | *** | 0.004 ** |
| Station crowdedness | 0.03* | 0.50 |
| Escalator and lift | *** | 0.005 ** |
| Train crowdedness | 0.06 | *** |
| Station accessibility | *** | *** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Kang, Z.; Fang, X.; Li, J. Design a Semantic Scale for Passenger Perceived Quality Surveys of Urban Rail Transit: Within Attribute’s Service Condition and Rider’s Experience. Sustainability 2020, 12, 8626. https://0-doi-org.brum.beds.ac.uk/10.3390/su12208626
Chen W, Kang Z, Fang X, Li J. Design a Semantic Scale for Passenger Perceived Quality Surveys of Urban Rail Transit: Within Attribute’s Service Condition and Rider’s Experience. Sustainability. 2020; 12(20):8626. https://0-doi-org.brum.beds.ac.uk/10.3390/su12208626
Chicago/Turabian StyleChen, Weiya, Zixuan Kang, Xiaoping Fang, and Jiajia Li. 2020. "Design a Semantic Scale for Passenger Perceived Quality Surveys of Urban Rail Transit: Within Attribute’s Service Condition and Rider’s Experience" Sustainability 12, no. 20: 8626. https://0-doi-org.brum.beds.ac.uk/10.3390/su12208626