Mobile Personalized Recommendation Model based on Privacy Concerns and Context Analysis for the Sustainable Development of M-commerce

Abstract
:1. Introduction
- (1)
- The model studies the intensity measurement method to measure above-mentioned privacy concerns factors and its application in personalized recommendation service. It considers reducing privacy concerns in personalized recommendation process from the perspective of user privacy, thus promoting users to accept MPRS.
- (2)
- This paper studies the method of context analysis, extracts the user’s context preference, and further studies the influence of context information on the recommendation process.
- (3)
- The hybrid collaborative filtering recommendation method based on privacy concerns and context analysis is proposed, and the potential association relationships among context, user, and privacy concerns are mined, and the user’s privacy concerns intensity and context preference are combined to generate appropriate content to be recommended to target users.
2. Literature Review
2.1. Research on Mobile Personalized Recommendation Service Considering Context
- (1)
- The definition of context and its data collection, including the concept of context, its classification and identification, collection, and preprocess of context data; Schilit [20] proposed that context included internal context and external context, which was a group of entities status information related to users and tasks.
- (2)
- Context expression and modeling, including semantically expression of context connotation, and context tree model based on hierarchical relationships on domain ontology. Different application scenarios lead to scholars’ inconsistent understandings of the contexts. Palmisano [21] summarized more than one hundred definitions and expression patterns of contexts.
- (3)
- Expression and model of customers’ contextual interest, including the construction of the customer interest model after context analysis, the influence of the context on customers’ interest drift model, etc. Xu [22] verified that analyzing relevant context information was beneficial to predict customer interests in mobile commerce services more accurately. In addition, the mobile personalized recommendation system can recommend different promotion items under different contexts of shopping venue [23], and can also improve the interest of mobile commerce users and sales performance according to context recommendation [24]. Ren [25] found that context in users’ interest mining had a great influence on network users’ behaviors, and users were highly dependent on the context when making rational behavior decisions, which produced contextual effects when users adopted mobile personalized recommendation services.
- (4)
- Contextual recommendation algorithm and system application, including the improvement of personalized recommendation algorithm and the application in the related fields combining with context pre-filtering, post-context filtering, and context modeling. Adomavicius et al. [26] demonstrated that contextual information could indeed improve the quality of recommendations to a certain extent in mobile personalized recommendation systems. Some well-known e-commerce enterprises in the online music, news, and travel industries have also begun to use context recommendation systems on a large scale [27]. Colomo [6] studied the personalized travel recommendation service, used location-based service technology to realize the geographical positioning of tourist services. Then, it integrated the location information into the personalized recommendation algorithm, and combined the historical consumption preferences and location context to recommend suitable restaurants and scenic spots to users.
2.2. Research on Mobile Personalized Recommendation Service Considering Privacy Concerns
2.3. User-Based Collaborative Filtering Recommendation Method
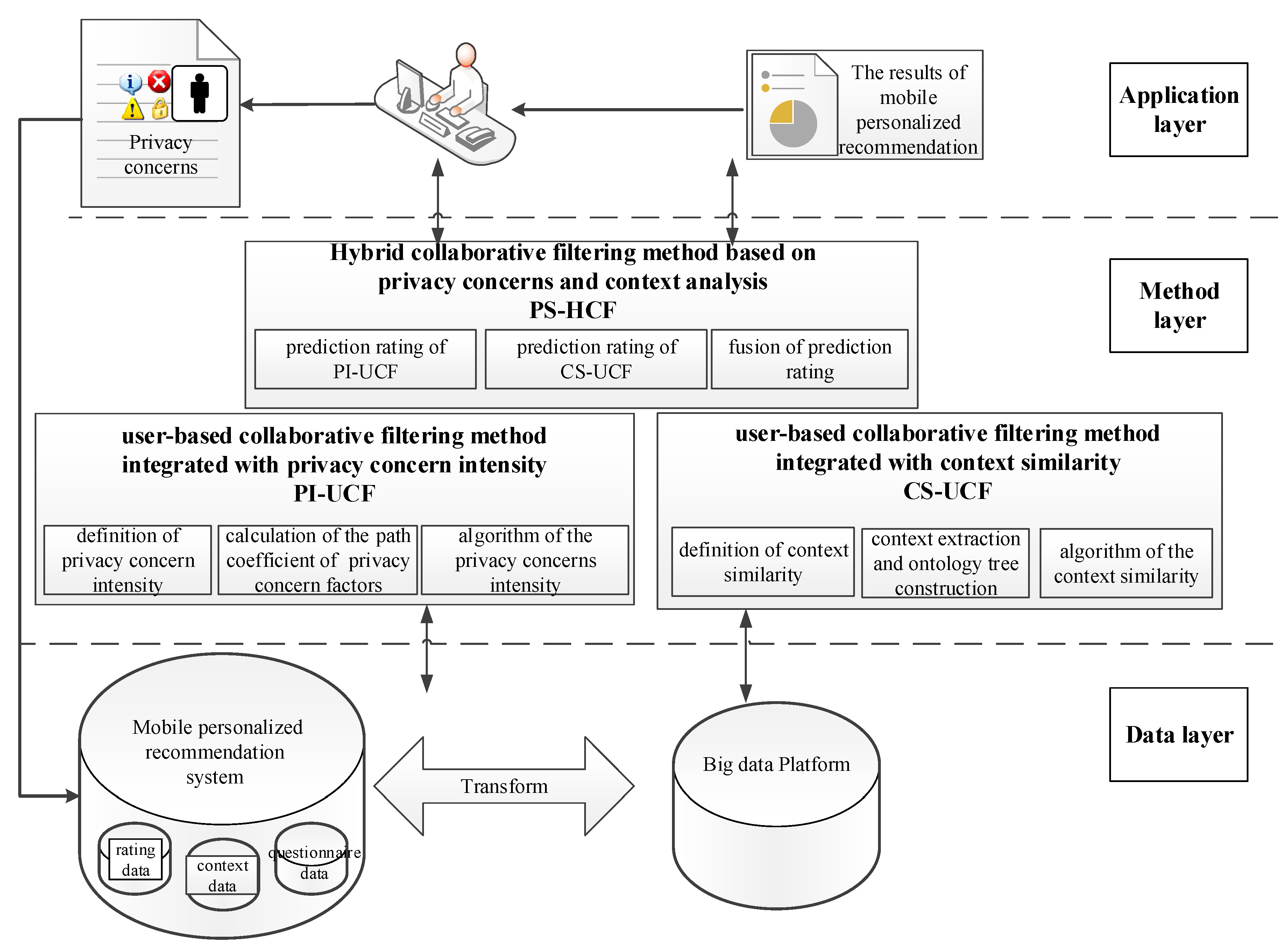
3. Mobile Personalized Recommendation Model Based on Privacy Concerns and Context Analysis
3.1. User-Based Collaborative Filtering Method Integrated with Privacy Concerns Intensity
| Algorithm 1 User-based collaborative filtering method integrated with privacy concerns intensity (PI-UCF). |
| Input: User , Service(R), the rating matrix of “user-privacy concerns intensity”.
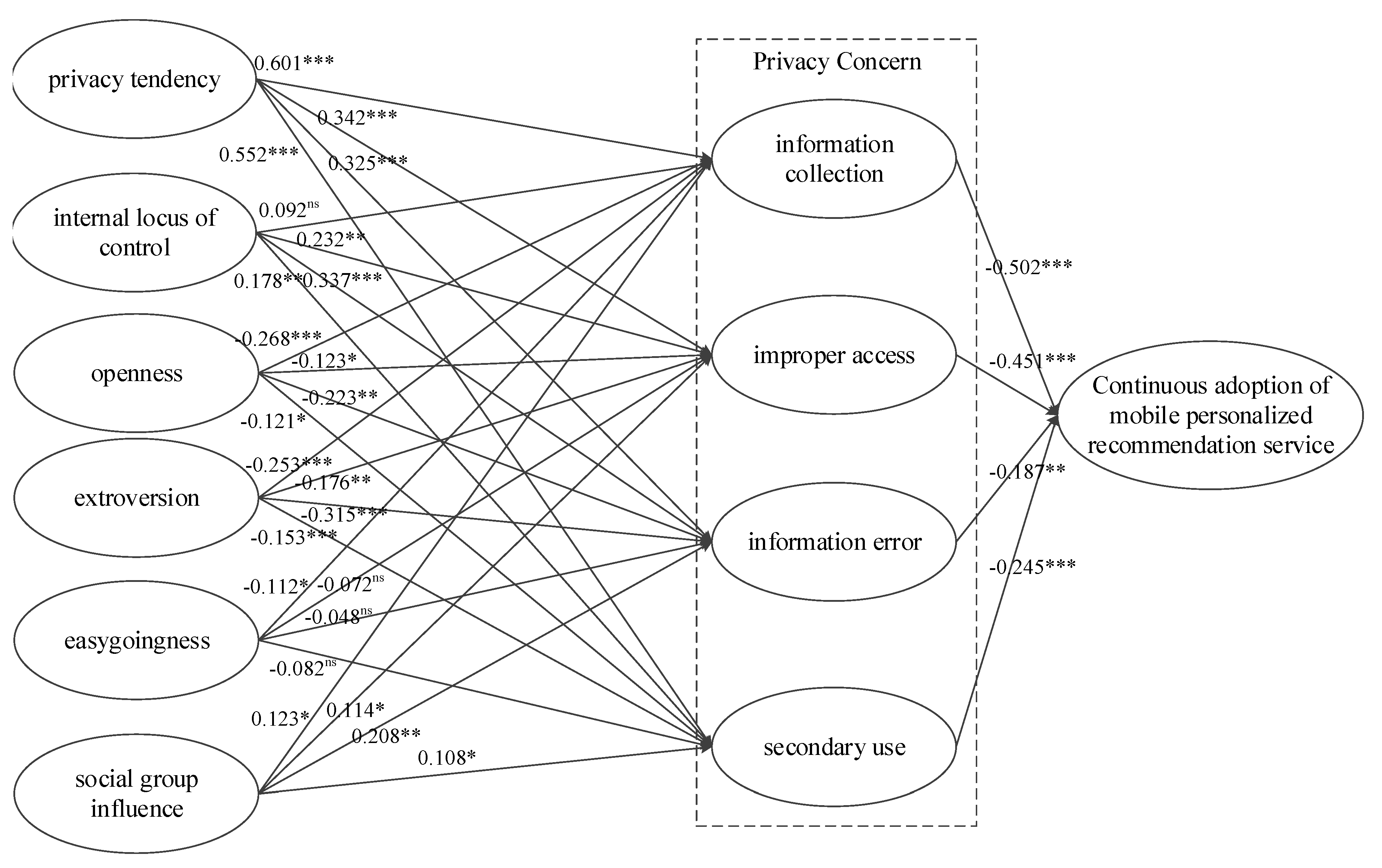
Output: TOP-N recommendation service list and its rating. Step1: It calculates the path coefficient of the influenced factors of privacy concerns based on structural equation model [15], and defines its absolute value as privacy concerns intensity . The means the value of users’ preference, influenced by one of privacy concern factors (user’s privacy tendency, internal locus of control, openness, extroversion, easygoingness, and social group influence), which has four dimensions (information collection, improper access, information error, and secondary use). Step2: It defines the comprehensive intensity of a privacy concerns factor with four dimensions as , and calculates the value according to Formula (2). and are two constant thresholds. is the average intensity of a privacy concerns factor with four dimensions. The Formula (2) uses square function to smooth differential influence degree in order to get better accuracy. Step3: It defines the average intensity of six privacy concerns factor with four dimensions as and is calculated as Then, according to Formula (3), the users’ similarity is calculated based on privacy concerns intensity. is defined as the size of Step4: On the basis of Step3, it selects the k nearest neighbor users for who has the most similar privacy concerns. Then, according to known ratings scored by the k nearest neighbor users, it predicts rating of target services by Formula (4). |
3.2. User-Based Collaborative Filtering Method Integrated with Context Similarity
3.2.1. The Calculation of Context Similarity
| Algorithm 2 Context similarity algorithm based on context ontology-tree (CSA). |
| Input: Context ontology tree and .
Output: Context similarity . Step1: Initializing . Step2: Judging whether the context concept exists in . If it exists, jump to step 3, or end. Step3: Judging whether the context concept exists in . If it exists, jump to step 4, or step 2. Step4: Recursion calculation the comprehensive similarity between the and in this two context ontology tree by . |
3.2.2. User-Based Collaborative Filtering Method Integrated with Context Similarity
| Algorithm 3 User-based collaborative filtering method integrated with context similarity (CS-UCF). |
| Input: Context , Internet User , Recommend services Service(R), rating matrix of “user-service” and the correlation matrix of “service-context”.
Output: TOP-N recommend services and their scores. Step1: Calculating the user’s average preference for a certain context: , is the number of elements contained in , represents the preference value of user to service s in context . It constructs “user-context” two-dimension preference matrix. Step2: Calling the context similarity calculation method (CSA) proposed in Algorithm2 to calculate the similarity between contexts in . Step3: After building the new “user-context” matrix, an improved method based on context similarity is proposed. represents the average preference of user for contexts related to services. It uses similarity to select k nearest neighbors for user . Step4: Finding the nearest neighbor set of the target user under Context . Since user’s preferences are closely related to context, the paper first obtains the similarity between and based on step 2. Then, find the nearest neighbor sets of under the influence of context and respectively. In the end, the nearest neighbor users under Context are merged into the nearest neighbor set under Context . is used to represent the nearest neighbor set. is the context. is the total number of users. is the similarity user set of user under the influence of the context . Step5: Using the user preferences of nearest neighbors obtained in step 4, the prediction score of potential user is calculated by Formula (9). |
3.3. Hybrid Collaborative Filtering Recommendation Method based on Fusion of Prediction Rating
4. Experiment and Analysis
4.1. Data Set
4.1.1. Simulated Data Set
- (1)
- User data set. The dataset size is 400, mainly including the user’s unique ID, ID Card, Occupation, Address, Birthday, etc.
- (2)
- Service data set. The dataset size is 100, and service attributes includes service identity (SID), service type, service name, service description, etc.
- (3)
- The matrix of “user-privacy concerns intensity”. This paper processes the sample data set of questionnaires and constructs the “user-privacy concerns intensity” matrix (400 × 6).
- (4)
- The matrix of “user-service behavior” (400 × 100). When the user adopts the personalized recommendation service, the behavior variable value is 1, otherwise the user’s behavior variable value is 0.
- (5)
- The context data set. Five types are selected, such as time, device, location, sentiment, activity status.
4.1.2. Benchmark Datasets
4.2. Evaluation Metrics
4.3. The Analysis of Experimental Results
4.3.1. Analysis of Factors Affecting Privacy Concerns and Measurement of Privacy Concerns Intensity
4.3.2. Comparison of Hybrid Collaborative Filtering Recommendation Method Based on Fusion of Prediction Rating with Different
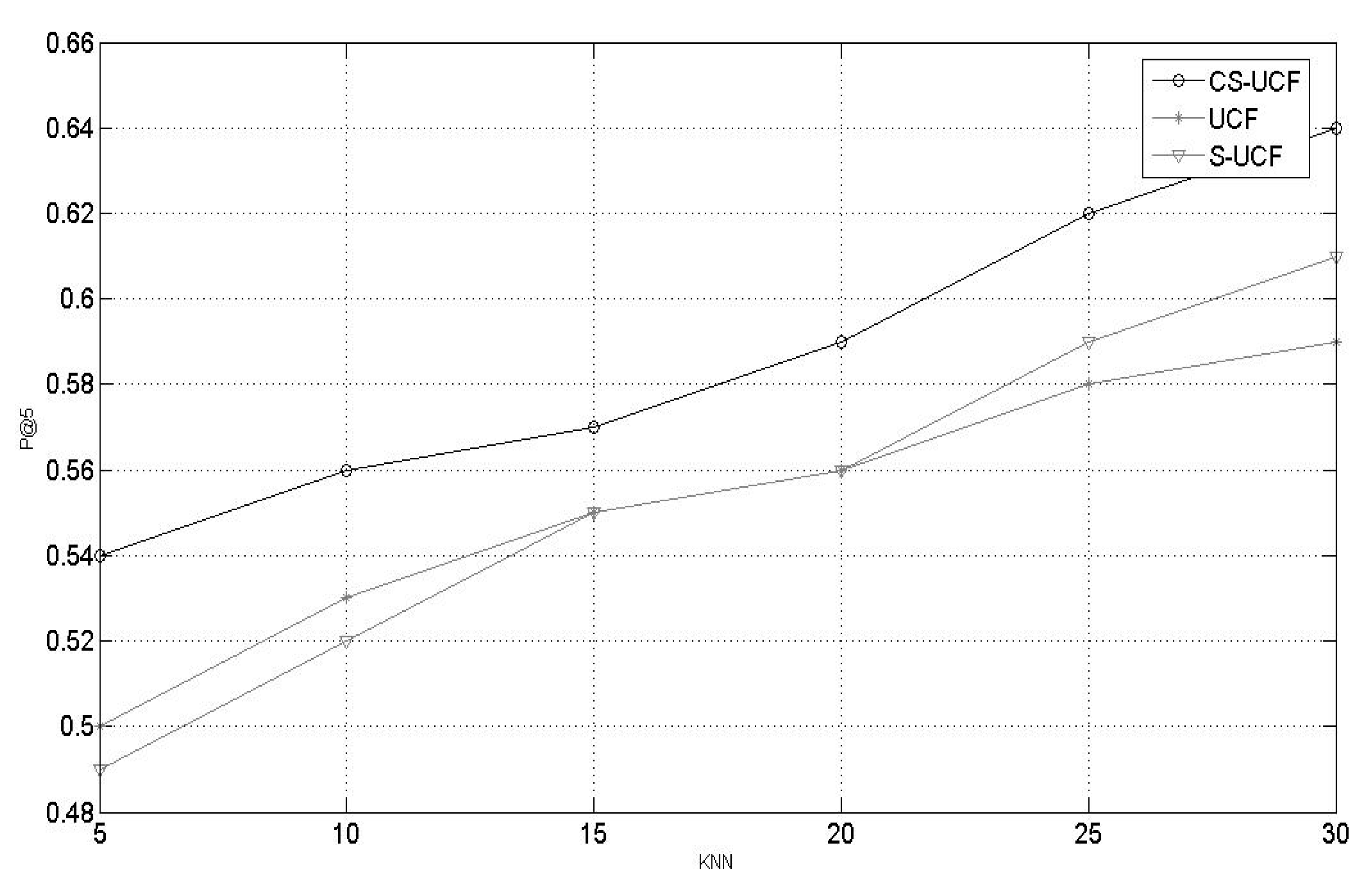
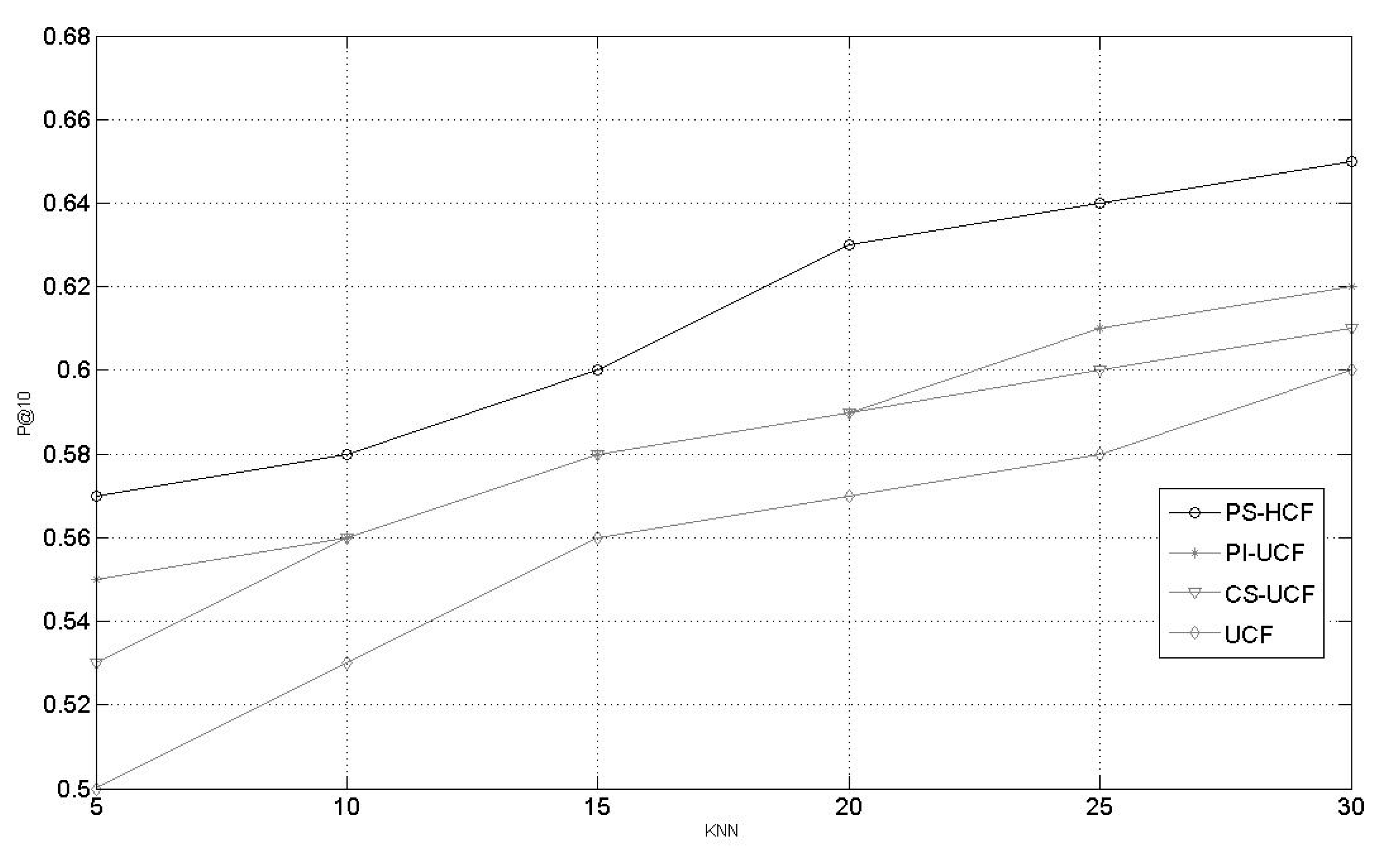
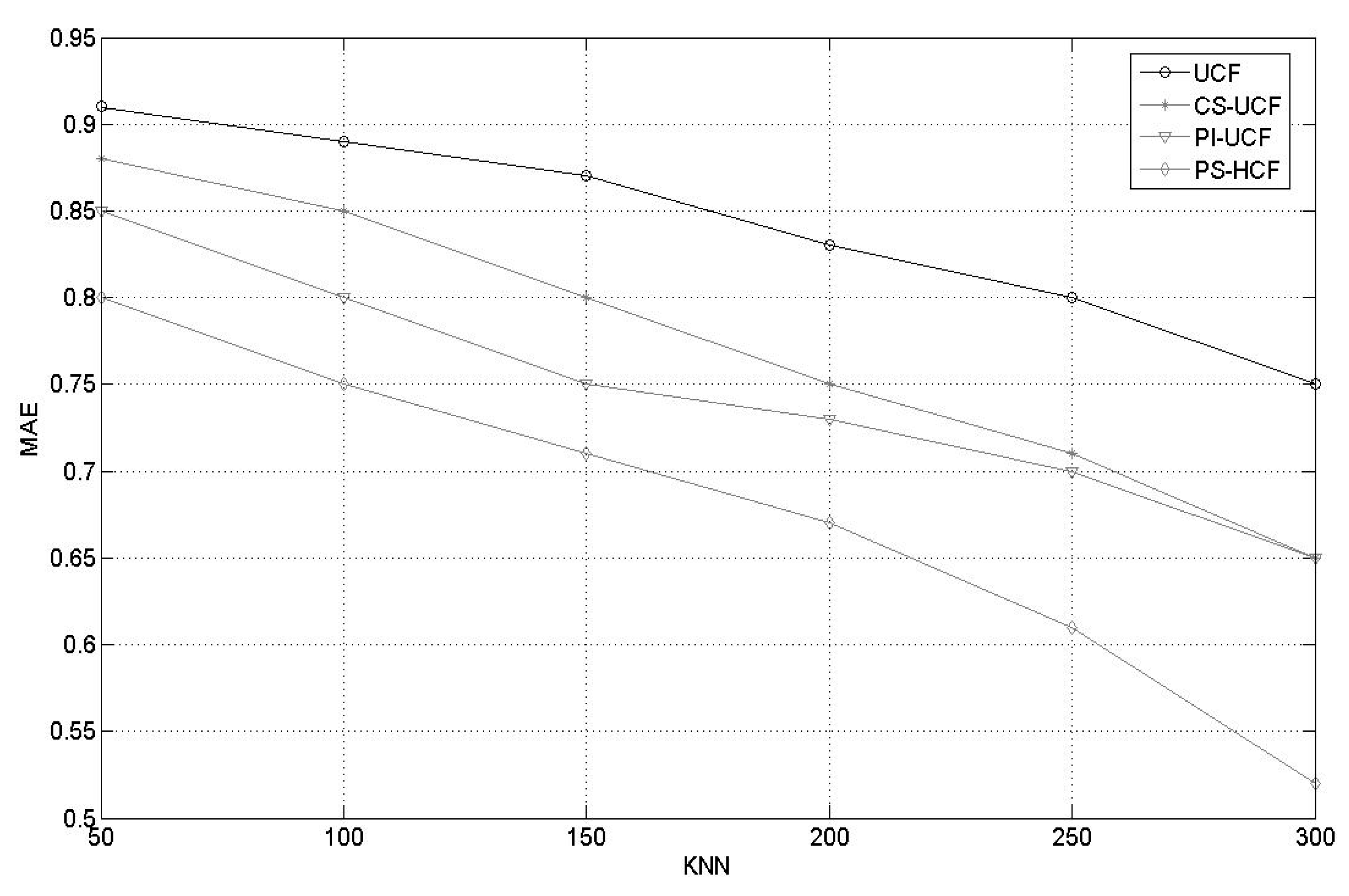
4.3.3. Comparison of the Recommendation Performances of CS-UCF, PI-UCF, PS-HCF, S-UCF, and UCF
5. Discussion
6. Conclusions and Future Work
- (1)
- Since the preferences of target users are often similar to that of users who have common privacy concerns, this paper uses six influence factors of privacy concerns to calculate the comprehensive user’s similarity. Then, a user collaborative filtering method incorporating privacy concerns intensity is proposed.
- (2)
- It can better obtain users’ interests and match the users’ preference behaviors by learning in the complex context. It also can effectively alleviate the problems of collaborative filtering data sparsity and cold start by deeply mining context. Therefore, this paper proposes a user-based collaborative filtering method incorporating context similarity.
- (3)
- Finally, mobile personalized recommendation services combining privacy factors with context information can reflect the actual needs of the user and meet the practical application, and alleviate the problems related to the privacy concerns in MPRS and the collaborative filtering methods.
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Lah, N.S.B.C.; Hussin, A.R.B.C.; Dahlan, H.M. A concept-level approach in analyzing review readership for E-Commerce persuasive recommendation. In Proceedings of the International Conference on Research and Innovation in Information Systems, Langkawi, Malaysia, 16–17 July 2017. [Google Scholar]
- Mclean, G.; Al-Nabhani, K.; Wilson, A. Developing a mobile applications customer experience model (mace)-implications for retailers. J. Bus. Res. 2018, 85, 325–336. [Google Scholar] [CrossRef] [Green Version]
- Adomavicius, G.; Sankaranarayansn, R.; Sen, S.; Tuzhilin, A. Incorporating contextual information in recommender systems using multidimensional approach. ACM Trans. Inf. Syst. 2005, 23, 103–145. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.P.; Lee, K.H. Making smartphone service recommendations by predicting users’ intentions: A context-aware approach. Inf. Sci. 2014, 277, 21–35. [Google Scholar] [CrossRef]
- Guo, Y.; Yin, C.X.; Li, M.F. Mobile e-commerce recommendation system based on multi-source information fusion for sustainable e-business. Sustainability 2018, 10, 147. [Google Scholar] [CrossRef] [Green Version]
- Colomo-Palacios, R.; García-Peñalvo, F.J.; Stantchev, V. Towards a social and context-aware mobile recommendation system for tourism. Pervasive Mob. Comput. 2017, 38, 505–515. [Google Scholar] [CrossRef]
- Vincenza, C.; Alessandro, L.; Michele, M.; Giuseppe, M. Searching for experts in a context-aware recommendation network. Comput. Hum. Behav. 2015, 51, 1086–1091. [Google Scholar]
- Amo, S.D.; Diallo, M.S.; Diop, C.T.; Giacometti, A.; Li, D.; Soulet, A. Contextual preference mining for user profile construction. Inf. Syst. 2015, 49, 182–199. [Google Scholar] [CrossRef]
- Tan, X.; Kim, Y.; Qin, L. Impact of privacy concern on using mobile social networking apps: An empirical study. Int. J. Mob. Commun. 2018, 16, 286–306. [Google Scholar] [CrossRef]
- Smith, H.J.; Dinev, T.; Xu, H. Information privacy research: An interdisciplinary review. MIS Q. 2011, 35, 989–1015. [Google Scholar] [CrossRef] [Green Version]
- Kwon, O.; Lee, Y.; Sarangib, D. A Galois lattice approach to a context-aware privacy negotiation service. Expert Syst. Appl. 2011, 38, 12619–12629. [Google Scholar] [CrossRef]
- Belanger, F.; Crossler, R.E. Privacy in the digital age: A review of information privacy research in information systems. MIS Q. 2011, 35, 1017–1041. [Google Scholar] [CrossRef] [Green Version]
- Hong, W.; Thong, J.Y.L. Internet privacy concerns: An integrated conceptualization and four empirical studies. MIS Q. 2013, 37, 275–298. [Google Scholar] [CrossRef]
- Baglioni, E.; Becchetti, L.; Bergamini, L.; Colesanti, U.M.; Filipponi, L.; Vitaletti, A.; Persiano, G. A lightweight privacy preserving SMS-based recommendation system for mobile users. RecSys. 2010, 191–198. [Google Scholar] [CrossRef]
- Xiao, L.; Guo, F.; Lu, Q. Mobile personalized service recommender model based on sentiment analysis and privacy concern. Mob. Inf. Syst. 2018, 1–13. [Google Scholar] [CrossRef]
- He, J.; Liu, H. Mining exploratory behavior to improve mobile app recommendations. ACM Trans. Inf. Syst. 2017, 35, 1–37. [Google Scholar] [CrossRef]
- Mudda, S.; Zignani, M.; Gaito, S.; Giordano, S.; Rossi, G.P. Timely and personalized services using mobile cellular data. Online Soc. Netw. Media 2019, 13, 1–18. [Google Scholar] [CrossRef]
- Lu, Q.B.; Guo, F.P. Personalized information recommendation model based on context contribution and item correlation. Measurement 2019, 142, 30–39. [Google Scholar] [CrossRef]
- Wang, R.; Ma, X.; Jiang, C.; Ye, Y.; Zhang, Y. Heterogeneous information network-based music recommendation system in mobile networks. Comput. Commun. 2020, 150, 429–437. [Google Scholar] [CrossRef]
- Schilit, B.; Adams, N.; Want, R. Context-Aware Computing Applications. In Proceedings of the 1994 First Workshop on Mobile Computing System and Application, Santa Cruz, CA, USA, 8–9 December 1994; pp. 85–90. [Google Scholar]
- Palmisano, C.; Tuzhilin, A.; Gorgoglione, M. Using context to improve predictive modeling of customers in personalization applications. IEEE Trans. Knowl. Data Eng. 2008, 20, 1535–1549. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.C.; Yuan, Y.F. The impact of context and incentives on mobile service adoption. Int. J. Mob. Commun. 2009, 7, 363–381. [Google Scholar] [CrossRef]
- Hostler, R.E.; Yoon, V.Y.; Guimaraes, T. Recommendation agent impact on consumer online shopping: The movie magic case study. Expert Syst. Appl. 2012, 39, 2989–2999. [Google Scholar] [CrossRef]
- Panniello, U.; Gorgoglione, M.; Tuzhilin, A. Research note—In CARSs we trust: How context-aware recommendations affect customers’ trust and other business performance measures of recommender systems. Inf. Syst. Res. 2016, 27, 182–196. [Google Scholar] [CrossRef]
- Ren, X.; Song, M.; Haihong, E. Context-aware probabilistic matrix factorization modeling for point-of-interest recommendation. Neurocomputing 2017, 241, 38–55. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Context-Aware Recommender Systems. Ai Mag. 2011, 32, 335–336. [Google Scholar]
- Han, B.J.; Rho, S.; Jun, S. Music emotion classification and context-based music recommendation. Multimed. Tools Appl. 2010, 47, 433–460. [Google Scholar] [CrossRef]
- Dogruel, L.; Joeckel, S.; Vitak, J. The valuation of privacy premium features for smartphone apps: The influence of defaults and expert recommendations. Comput. Hum. Behav. 2017, 77, 230–239. [Google Scholar] [CrossRef]
- Chen, J.V.; Su, B.C.; Quyet, H.M. Users’ intention to disclose location on location-based social network sites (LBSNS) in mobile environment: Privacy calculus and Big Five. Int. J. Mob. Commun. 2017, 15, 329–353. [Google Scholar] [CrossRef]
- Wang, B.; Duan, Y.X. Research on information privacy quantization method facing ubiquitous computing environment. Comput. Eng. Appl. 2011, 47, 1–5. [Google Scholar]
- Dinev, T.; Hart, P. Internet privacy concerns and social awareness as determinants of intention to transact. Int. J. Electron. Commer. 2005, 10, 7–29. [Google Scholar] [CrossRef]
- Sutanto, J.; Palme, E.; Tan, C.H. Addressing the personalization privacy paradox: An empirical assessment from a field experiment on smartphone user. MIS Q. 2013, 37, 1142–1164. [Google Scholar] [CrossRef]
- Okazaki, S.; Navarro-Bailon, M.; Molina-Castillo, F.J. Privacy concerns in quick response code mobile promotion: The role of social anxiety and situational involvement. Int. J. Electron. Commer. 2012, 16, 91–120. [Google Scholar] [CrossRef] [Green Version]
- Taddei, S.; Contena, B. Privacy, trust and control: Which relationships with online self-disclosure? Comput. Hum. Behav. 2013, 29, 821–826. [Google Scholar] [CrossRef]
- Geuens, S.; Coussement, K.; Bock, K.W.D. A framework for configuring collaborative filtering-based recommendations derived from purchase data. Eur. J. Oper. Res. 2018, 265, 208–218. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Q.; Sun, S.Q.; Liu, C. Collaborative filtering recommendation algorithm based on user preference derived from item domain features. Phys. A Stat. Mech. Appl. 2014, 396, 66–76. [Google Scholar] [CrossRef]
- Chae, D.K.; Lee, S.C.; Lee, S.Y. On identifying k-nearest neighbors in neighborhood models for efficient and effective collaborative filtering. Neurocomputing 2017, 278, 134–143. [Google Scholar] [CrossRef]
- Najafabadi, M.K.; Mahrin, M.N.; Chuprat, S.; Sarkan, H.M. Improving the accuracy of collaborative filtering recommendations using clustering and association rules mining on implicit data. Comput. Hum. Behav. 2017, 67, 113–128. [Google Scholar] [CrossRef]
- Kaleli, C. An entropy-based neighbor selection approach for collaborative filtering. Knowl. Based Syst. 2014, 56, 273–280. [Google Scholar] [CrossRef]
- Winoto, P.; Tang, T.Y. The role of user mood in movie recommendations. Expert Syst. Appl. 2010, 37, 6086–6092. [Google Scholar] [CrossRef]
- Ben Sassi, I.; Mellouli, S.; Ben Yahia, S. Context-aware recommender systems in mobile environment: On the road of future research. Inf. Syst. 2017, 72, 27–61. [Google Scholar] [CrossRef]
- Claypool, M.; Goknale, A.; Miranda, T. Combining content-based and collaborative filters in an online newspaper. In Proceedings of the ACM SIGIR’99 Workshop Recommender Systems: Algorithms and Evaluation, ACM SIGIR Forum, Berkeley, CA, USA, 19 August 1999. [Google Scholar]
- Masoumeh, R.; Mohammad, K.S. Providing effective recommendations in discussion groups using a new hybrid recommender system based on implicit ratings and semantic similarity. Electron. Commer. Res. Appl. 2020, 40, 1–13. [Google Scholar]
- Li, Y.; Li, D.; Wang, S.; Zhai, Y. Incremental entropy-based clustering on categorical data streams with concept drift. Knowl. Based Syst. 2014, 59, 33–47. [Google Scholar] [CrossRef]
- Su, J.; Yeh, H.; Yu, P.; Tseng, V. Music recommendation using content and context information mining. IEEE Intell. Syst. 2010, 25, 16–26. [Google Scholar] [CrossRef]
- Kline, R.B. Principles and practice of structural equation modeling. J. Am. Stat. Assoc. 2010, 101, 121–143. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Questionnaire Item | Frequency | Percentage (%) |
|---|---|---|---|
| Sex | Male | 205 | 48.69 |
| Female | 216 | 51.31 | |
| Age | Less than 18 years old | 89 | 21.14 |
| 18–24 years old | 228 | 54.15 | |
| 25–34 years old | 57 | 13.54 | |
| Over 35 years old | 47 | 11.16 | |
| Educational background | High school or below | 23 | 5.46 |
| Junior college | 75 | 17.82 | |
| Undergraduate | 218 | 51.81 | |
| Master degree or above | 105 | 24.91 | |
| Occupation | student | 254 | 60.24 |
| Public institutions/civil servants | 20 | 4.78 | |
| Professional technicians (doctors, lawyers, etc.) | 48 | 11.43 | |
| Enterprise staff | 85 | 20.14 | |
| Self-employed worker/freelancer | 9 | 2.22 | |
| Others | 5 | 1.19 | |
| Experience of usage of M-commerce service | Less than 1 years | 53 | 12.63 |
| 2 or 3 years | 107 | 25.43 | |
| 4 or 5 years | 191 | 45.39 | |
| More than 6 years | 70 | 16.55 |
| Fitness Index | χ2/df | GFI | AGFI | CFI | NFI | NNFI | RMSEA |
|---|---|---|---|---|---|---|---|
| reference value | <3 | >0.90 | >0.80 | >0.90 | >0.90 | >0.90 | <0.08 |
| actual value | 1.87 | 0.912 | 0.875 | 0.947 | 0.921 | 0.958 | 0.046 |
| PS-HCF | P@5(k=10,20,30,50) | P@10(k=10,20,30,50) | ||||||
| 10 | 20 | 30 | 50 | 10 | 20 | 30 | 50 | |
| 0.0 | 0.66 | 0.71 | 0.73 | 0.76 | 0.64 | 0.67 | 0.71 | 0.72 |
| 0.2 | 0.68 | 0.74 | 0.75 | 0.77 | 0.67 | 0.70 | 0.72 | 0.74 |
| 0.4 | 0.71 | 0.75 | 0.78 | 0.77 | 0.69 | 0.72 | 0.73 | 0.75 |
| 0.6 (cut-off point) | 0.72 | 0.76 | 0.79 | 0.80 | 0.70 | 0.73 | 0.74 | 0.76 |
| 0.8 | 0.71 | 0.74 | 0.76 | 0.78 | 0.68 | 0.72 | 0.73 | 0.74 |
| 1.0 | 0.67 | 0.71 | 0.73 | 0.76 | 0.66 | 0.70 | 0.71 | 0.73 |
| PS-HCF | MAP (k = 10,20,30,50) | DOA (n Selects 20–80%,30–70%, 40–60%,50–50%) | ||||||
|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 30 | 50 | 20–80% | 30–70% | 40–60% | 50–50% | |
| 0.0 | 0.69 | 0.73 | 0.76 | 0.78 | 0.75 | 0.78 | 0.80 | 0.81 |
| 0.2 | 0.72 | 0.75 | 0.78 | 0.79 | 0.77 | 0.80 | 0.82 | 0.82 |
| 0.4 | 0.73 | 0.76 | 0.79 | 0.80 | 0.78 | 0.81 | 0.83 | 0.83 |
| 0.6 (cut-off point) | 0.74 | 0.77 | 0.80 | 0.81 | 0.79 | 0.81 | 0.83 | 0.84 |
| 0.8 | 0.72 | 0.76 | 0.78 | 0.80 | 0.78 | 0.80 | 0.82 | 0.83 |
| 1.0 | 0.70 | 0.74 | 0.77 | 0.79 | 0.76 | 0.79 | 0.81 | 0.82 |
| Alg.\Split | 20–80% | 30–70% | 40–60% | 50–50% |
|---|---|---|---|---|
| CS-UCF | 70.2 | 68.2 | 66.2 | 63.3 |
| UCF | 73.1 | 71.3 | 69.5 | 66.2 |
| PI-UCF | 78.3 | 77.5 | 73.5 | 68.8 |
| PS-HCF | 86.4 | 84.2 | 81.3 | 79.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, L.; Lu, Q.; Guo, F. Mobile Personalized Recommendation Model based on Privacy Concerns and Context Analysis for the Sustainable Development of M-commerce. Sustainability 2020, 12, 3036. https://0-doi-org.brum.beds.ac.uk/10.3390/su12073036
Xiao L, Lu Q, Guo F. Mobile Personalized Recommendation Model based on Privacy Concerns and Context Analysis for the Sustainable Development of M-commerce. Sustainability. 2020; 12(7):3036. https://0-doi-org.brum.beds.ac.uk/10.3390/su12073036
Chicago/Turabian StyleXiao, Liang, Qibei Lu, and Feipeng Guo. 2020. "Mobile Personalized Recommendation Model based on Privacy Concerns and Context Analysis for the Sustainable Development of M-commerce" Sustainability 12, no. 7: 3036. https://0-doi-org.brum.beds.ac.uk/10.3390/su12073036