
Stacking Ensemble Tree Models to Predict Energy Performance in Residential Buildings

 ,
,  ,
, 
 , and
, and 
Abstract
:1. Introduction
2. Research Significance
3. Energy Data of Building
4. Methodology
4.1. Stacking Structure
4.2. CART
4.3. M5 Tree Model
4.4. RF
4.5. Extreme Gradient Boosting
5. Model Simulation
5.1. Performance Index
5.2. Statistical Analysis
5.3. Pre-Training
5.4. Model Developing
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, Z.; Haghighat, F.; Fung, B.C.M.; Yoshino, H. A decision tree method for building energy demand modeling. Energy Build. 2010, 42, 1637–1646. [Google Scholar] [CrossRef] [Green Version]
- Khalil, A.J.; Barhoom, A.M.; Abu-Nasser, B.S.; Musleh, M.M.; Abu-Naser, S.S. Energy Efficiency Prediction using Artificial Neural Network. Int. J. Acad. Res. 2019, 3, 1–7. [Google Scholar]
- Pérez-Lombard, L.; Ortiz, J.; Pout, C. A review on buildings energy consumption information. Energy Build. 2008, 40, 394–398. [Google Scholar] [CrossRef]
- Cai, W.G.; Wu, Y.; Zhong, Y.; Ren, H. China building energy consumption: Situation, challenges and corresponding measures. Energy Policy 2009, 37, 2054–2059. [Google Scholar] [CrossRef]
- Platt, G.; Li, J.; Li, R.; Poulton, G.; James, G.; Wall, J. Adaptive HVAC zone modeling for sustainable buildings. Energy Build. 2010, 42, 412–421. [Google Scholar] [CrossRef]
- Yao, R.; Li, B.; Steemers, K. Energy policy and standard for built environment in China. Renew. Energy 2005, 30, 1973–1988. [Google Scholar] [CrossRef]
- Yezioro, A.; Dong, B.; Leite, F. An applied artificial intelligence approach towards assessing building performance simulation tools. Energy Build. 2008, 40, 612–620. [Google Scholar] [CrossRef]
- Tsanas, A.; Goulermas, J.Y.; Vartela, V.; Tsiapras, D.; Theodorakis, G.; Fisher, A.C.; Sfirakis, P. The Windkessel model revisited: A qualitative analysis of the circulatory system. Med. Eng. Phys. 2009, 31, 581–588. [Google Scholar] [CrossRef]
- Crawley, D.B.; Hand, J.W.; Kummert, M.; Griffith, B.T. Contrasting the capabilities of building energy performance simulation programs. Build. Environ. 2008, 43, 661–673. [Google Scholar] [CrossRef] [Green Version]
- Dong, B.; Cao, C.; Lee, S.E. Applying support vector machines to predict building energy consumption in tropical region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Catalina, T.; Virgone, J.; Blanco, E. Development and validation of regression models to predict monthly heating demand for residential buildings. Energy Build. 2008, 40, 1825–1832. [Google Scholar] [CrossRef]
- Seyedzadeh, S.; Rahimian, F.P.; Rastogi, P.; Glesk, I. Tuning machine learning models for prediction of building energy loads. Sustain. Cities Soc. 2019, 47, 101484. [Google Scholar] [CrossRef]
- Gassar, A.A.A.; Yun, G.Y.; Kim, S. Data-driven approach to prediction of residential energy consumption at urban scales in London. Energy 2019, 187, 115973. [Google Scholar] [CrossRef]
- Pilechiha, P.; Mahdavinejad, M.; Rahimian, F.P.; Carnemolla, P.; Seyedzadeh, S. Multi-objective optimisation framework for designing office windows: Quality of view, daylight and energy efficiency. Appl. Energy 2020, 261, 114356. [Google Scholar] [CrossRef]
- Seyedzadeh, S.; Rahimian, F.P.; Oliver, S.; Glesk, I.; Kumar, B. Data driven model improved by multi-objective optimisation for prediction of building energy loads. Autom. Constr. 2020, 116, 103188. [Google Scholar] [CrossRef]
- Seyedzadeh, S.; Rahimian, F.P.; Oliver, S.; Rodriguez, S.; Glesk, I. Machine learning modelling for predicting non-domestic buildings energy performance: A model to support deep energy retrofit decision-making. Appl. Energy 2020, 279, 115908. [Google Scholar] [CrossRef]
- Hamida, A.; Alsudairi, A.; Alshaibani, K.; Alshamrani, O. Environmental impacts cost assessment model of residential building using an artificial neural network. Eng. Constr. Archit. Manag. 2020. [Google Scholar] [CrossRef]
- Lin, Y.; Zhou, S.; Yang, W.; Shi, L.; Li, C.-Q. Development of building thermal load and discomfort degree hour prediction models using data mining approaches. Energies 2018, 11, 1570. [Google Scholar] [CrossRef] [Green Version]
- Jahed Armaghani, D.; Asteris, P.G.; Askarian, B.; Hasanipanah, M.; Tarinejad, R.; Huynh, V. Van Examining Hybrid and Single SVM Models with Different Kernels to Predict Rock Brittleness. Sustainability 2020, 12, 2229. [Google Scholar] [CrossRef] [Green Version]
- Asteris, P.G.; Skentou, A.D.; Bardhan, A.; Samui, P.; Pilakoutas, K. Predicting concrete compressive strength using hybrid ensembling of surrogate machine learning models. Cem. Concr. Res. 2021, 145, 106449. [Google Scholar] [CrossRef]
- Asteris, P.G.; Mamou, A.; Hajihassani, M.; Hasanipanah, M.; Koopialipoor, M.; Le, T.-T.; Kardani, N.; Armaghani, D.J. Soft computing based closed form equations correlating L and N-type Schmidt hammer rebound numbers of rocks. Transp. Geotech. 2021, 29, 100588. [Google Scholar] [CrossRef]
- Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Kotsonis, E.A.; Lourenço, P.B. Prediction of cement-based mortars compressive strength using machine learning techniques. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Gavriilaki, E.; Asteris, P.G.; Touloumenidou, T.; Koravou, E.-E.; Koutra, M.; Papayanni, P.G.; Karali, V.; Papalexandri, A.; Varelas, C.; Chatzopoulou, F.; et al. Genetic justification of severe COVID-19 using a rigorous algorithm. Clin. Immunol. 2021, 9, 108726. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Nguyen, H.; Nguyen-Thoi, T.; Asteris, P.G.; Zhou, J. Improved Levenberg–Marquardt backpropagation neural network by particle swarm and whale optimization algorithms to predict the deflection of RC beams. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Zhang, H.; Nguyen, H.; Bui, X.-N.; Pradhan, B.; Asteris, P.G.; Costache, R.; Aryal, J. A generalized artificial intelligence model for estimating the friction angle of clays in evaluating slope stability using a deep neural network and Harris Hawks optimization algorithm. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Asteris, P.G.; Cavaleri, L.; Ly, H.-B.; Pham, B.T. Surrogate models for the compressive strength mapping of cement mortar materials. Soft Comput. 2021. [Google Scholar] [CrossRef]
- Zeng, J.; Asteris, P.G.; Mamou, A.P.; Mohammed, A.S.; Golias, E.A.; Armaghani, D.J.; Faizi, K.; Hasanipanah, M. The Effectiveness of Ensemble-Neural Network Techniques to Predict Peak Uplift Resistance of Buried Pipes in Reinforced Sand. Appl. Sci. 2021, 11, 908. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, J.; Li, C.; Armaghani, D.J.; Li, X.; Mitri, H.S. Rockburst prediction in hard rock mines developing bagging and boosting tree-based ensemble techniques. J. Cent. South Univ. 2021, 28, 527–542. [Google Scholar] [CrossRef]
- Li, D.; Koopialipoor, M.; Armaghani, D.J. A Combination of Fuzzy Delphi Method and ANN-based Models to Investigate Factors of Flyrock Induced by Mine Blasting. Nat. Resour. Res. 2021, 30, 1905–1924. [Google Scholar] [CrossRef]
- Zhou, J.; Qiu, Y.; Zhu, S.; Armaghani, D.J.; Li, C.; Nguyen, H.; Yagiz, S. Optimization of support vector machine through the use of metaheuristic algorithms in forecasting TBM advance rate. Eng. Appl. Artif. Intell. 2021, 97, 104015. [Google Scholar] [CrossRef]
- Yu, C.; Koopialipoor, M.; Murlidhar, B.R.; Mohammed, A.S.; Armaghani, D.J.; Mohamad, E.T.; Wang, Z. Optimal ELM–Harris Hawks Optimization and ELM–Grasshopper Optimization Models to Forecast Peak Particle Velocity Resulting from Mine Blasting. Nat. Resour. Res. 2021. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Harandizadeh, H.; Momeni, E. Load carrying capacity assessment of thin-walled foundations: An ANFIS–PNN model optimized by genetic algorithm. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Jahed Armaghani, D.; Azizi, A. Empirical, Statistical, and Intelligent Techniques for TBM Performance Prediction. In Applications of Artificial Intelligence in Tunnelling and Underground Space Technology; SpringerBriefs in Applied Sciences and Technology; Headquarters: Berlin, Germany, 2021; pp. 17–32. [Google Scholar] [CrossRef]
- Kardani, N.; Bardhan, A.; Samui, P.; Nazem, M.; Zhou, A.; Armaghani, D.J. A novel technique based on the improved firefly algorithm coupled with extreme learning machine (ELM-IFF) for predicting the thermal conductivity of soil. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Comparative performance of six supervised learning methods for the development of models of hard rock pillar stability prediction. Nat. Hazards 2015, 79, 291–316. [Google Scholar] [CrossRef]
- Zhou, J.; Li, E.; Yang, S.; Wang, M.; Shi, X.; Yao, S.; Mitri, H.S. Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf. Sci. 2019, 118, 505–518. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Evaluation method of rockburst: State-of-the-art literature review. Tunn. Undergr. Sp. Technol. 2018, 81, 632–659. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of rockburst in underground projects: Comparison of ten supervised learning methods. J. Comput. Civ. Eng. 2016, 30, 4016003. [Google Scholar] [CrossRef]
- Huang, J.; Wang, Q.-A. Influence of crumb rubber particle sizes on rutting, low temperature cracking, fracture, and bond strength properties of asphalt binder. Mater. Struct. 2021, 54, 1–15. [Google Scholar] [CrossRef]
- Huang, J.; Sun, Y.; Zhang, J. Reduction of computational error by optimizing SVR kernel coefficients to simulate concrete compressive strength through the use of a human learning optimization algorithm. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Huang, J.; Shiva Kumar, G.; Ren, J.; Sun, Y.; Li, Y.; Wang, C. Towards the potential usage of eggshell powder as bio-modifier for asphalt binder and mixture: Workability and mechanical properties. Int. J. Pavement Eng. 2021, 1–13. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, J.; Ren, J.; Chen, H. Anti-rutting performance of the damping asphalt mixtures (DAMs) made with a high content of asphalt rubber (AR). Constr. Build. Mater. 2021, 271, 121878. [Google Scholar] [CrossRef]
- Huang, J.; Kumar, G.S.; Sun, Y. Evaluation of workability and mechanical properties of asphalt binder and mixture modified with waste toner. Constr. Build. Mater. 2021, 276, 122230. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, Y.; Sun, Y.; Ren, J.; Zhao, Z.; Zhang, J. Evaluation of pore size distribution and permeability reduction behavior in pervious concrete. Constr. Build. Mater. 2021, 290, 123228. [Google Scholar] [CrossRef]
- Asteris, P.G.; Douvika, M.G.; Karamani, C.A.; Skentou, A.D.; Chlichlia, K.; Cavaleri, L.; Daras, T.; Armaghani, D.J.; Zaoutis, T.E. A Novel Heuristic Algorithm for the Modeling and Risk Assessment of the COVID-19 Pandemic Phenomenon. Comput. Model. Eng. Sci. 2020. [Google Scholar] [CrossRef]
- Lu, S.; Koopialipoor, M.; Asteris, P.G.; Bahri, M.; Armaghani, D.J. A Novel Feature Selection Approach Based on Tree Models for Evaluating the Punching Shear Capacity of Steel Fiber-Reinforced Concrete Flat Slabs. Materials 2020, 13, 3902. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Asteris, P.G.; Armaghani, D.J.; Pham, B.T. Prediction of ground vibration induced by blasting operations through the use of the Bayesian Network and random forest models. Soil Dyn. Earthq. Eng. 2020, 139, 106390. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G.; Fatemi, S.A.; Hasanipanah, M.; Tarinejad, R.; Rashid, A.S.A.; Huynh, V. Van On the Use of Neuro-Swarm System to Forecast the Pile Settlement. Appl. Sci. 2020, 10, 1904. [Google Scholar] [CrossRef] [Green Version]
- Apostolopoulou, M.; Asteris, P.G.; Armaghani, D.J.; Douvika, M.G.; Lourenço, P.B.; Cavaleri, L.; Bakolas, A.; Moropoulou, A. Mapping and holistic design of natural hydraulic lime mortars. Cem. Concr. Res. 2020, 136, 106167. [Google Scholar] [CrossRef]
- Asteris, P.G.; Lemonis, M.E.; Nguyen, T.-A.; Le, H.V.; Pham, B.T. Soft computing-based estimation of ultimate axial load of rectangular concrete-filled steel tubes. Steel Compos. Struct. 2021, 39, 471–491. [Google Scholar] [CrossRef]
- Psyllaki, P.; Stamatiou, K.; Iliadis, I.; Mourlas, A.; Asteris, P.; Vaxevanidis, N. Surface treatment of tool steels against galling failure. In MATEC Web of Conferences; EDP Sciences: Les Ulis, France, 2018; Volume 188, p. 4024. [Google Scholar]
- Yu, Y.; Gao, W.; Castel, A.; Liu, A.; Chen, X.; Liu, M. Assessing external sulfate attack on thin-shell artificial reef structures under uncertainty. Ocean Eng. 2020, 207, 107397. [Google Scholar] [CrossRef]
- Yu, Y.; Wu, D.; Wang, Q.; Chen, X.; Gao, W. Machine learning aided durability and safety analyses on cementitious composites and structures. Int. J. Mech. Sci. 2019, 160, 165–181. [Google Scholar] [CrossRef]
- Baharfar, Y.; Mohammadyan, M.; Moattar, F.; Nassiri, P.; Behzadi, M.H. Indoor PM2.5 concentrations of pre-schools; determining the effective factors and model for prediction. Smart Sustain. Built Environ. 2021. [Google Scholar] [CrossRef]
- Ismail, Z.-A. Bin Thermal comfort practices for precast concrete building construction projects: Towards BIM and IOT integration. Eng. Constr. Archit. Manag. 2021. [Google Scholar] [CrossRef]
- Eslamirad, N.; Kolbadinejad, S.M.; Mahdavinejad, M.; Mehranrad, M. Thermal comfort prediction by applying supervised machine learning in green sidewalks of Tehran. Smart Sustain. Built Environ. 2020. [Google Scholar] [CrossRef]
- Kwong, Q.J.; Yang, J.Y.; Ling, O.H.L.; Edwards, R.; Abdullah, J. Thermal comfort prediction of air-conditioned and passively cooled engineering testing centres in a higher educational institution using CFD. Smart Sustain. Built Environ. 2020. [Google Scholar] [CrossRef]
- Yang, H.; Wang, Z.; Song, K. A new hybrid grey wolf optimizer-feature weighted-multiple kernel-support vector regression technique to predict TBM performance. Eng. Comput. 2020. [Google Scholar] [CrossRef]
- Yang, H.; Liu, J.; Liu, B. Investigation on the cracking character of jointed rock mass beneath TBM disc cutter. Rock Mech. Rock Eng. 2018, 51, 1263–1277. [Google Scholar] [CrossRef]
- Yang, H.; Wang, H.; Zhou, X. Analysis on the damage behavior of mixed ground during TBM cutting process. Tunn. Undergr. Sp. Technol. 2016, 57, 55–65. [Google Scholar] [CrossRef]
- Ashkzari, A.; Azizi, A. Introducing genetic algorithm as an intelligent optimization technique. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Bäch, Switzerland, 2014; Volume 568, pp. 793–797. [Google Scholar]
- Azizi, A.; Entessari, F.; Osgouie, K.G.; Rashnoodi, A.R. Introducing neural networks as a computational intelligent technique. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Bäch, Switzerland, 2014; Volume 464, pp. 369–374. [Google Scholar]
- Le, T.-T.; Asteris, P.G.; Lemonis, M.E. Prediction of axial load capacity of rectangular concrete-filled steel tube columns using machine learning techniques. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Harandizadeh, H.; Armaghani, D.J.; Asteris, P.G.; Gandomi, A.H. TBM performance prediction developing a hybrid ANFIS-PNN predictive model optimized by imperialism competitive algorithm. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Ke, B.; Khandelwal, M.; Asteris, P.G.; Skentou, A.D.; Mamou, A.; Armaghani, D.J. Rock-burst occurrence prediction based on optimized Naïve Bayes models. IEEE Access 2021. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Mamou, A.; Maraveas, C.; Roussis, P.C.; Siorikis, V.G.; Skentou, A.D.; Asteris, P.G. Predicting the unconfined compressive strength of granite using only two non-destructive test indexes. Geomech. Eng. 2021, 25, 317–330. [Google Scholar]
- Ly, H.-B.; Pham, B.T.; Le, L.M.; Le, T.-T.; Le, V.M.; Asteris, P.G. Estimation of axial load-carrying capacity of concrete-filled steel tubes using surrogate models. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Liu, B.; Yang, H.; Karekal, S. Effect of Water Content on Argillization of Mudstone During the Tunnelling process. Rock Mech. Rock Eng. 2019. [Google Scholar] [CrossRef]
- Yang, H.Q.; Zeng, Y.Y.; Lan, Y.F.; Zhou, X.P. Analysis of the excavation damaged zone around a tunnel accounting for geostress and unloading. Int. J. Rock Mech. Min. Sci. 2014, 69, 59–66. [Google Scholar] [CrossRef]
- Huang, J.; Duan, T.; Zhang, Y.; Liu, J.; Zhang, J.; Lei, Y. Predicting the permeability of pervious concrete based on the beetle antennae search algorithm and random forest model. Adv. Civ. Eng. 2020, 2020. [Google Scholar] [CrossRef]
- Li, Q.; Meng, Q.; Cai, J.; Yoshino, H.; Mochida, A. Applying support vector machine to predict hourly cooling load in the building. Appl. Energy 2009, 86, 2249–2256. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, R. Overall thermal sensation, acceptability and comfort. Build. Environ. 2008, 43, 44–50. [Google Scholar] [CrossRef]
- Zhang, J.; Haghighat, F. Development of Artificial Neural Network based heat convection algorithm for thermal simulation of large rectangular cross-sectional area Earth-to-Air Heat Exchangers. Energy Build. 2010, 42, 435–440. [Google Scholar] [CrossRef]
- Wan, K.K.W.; Li, D.H.W.; Liu, D.; Lam, J.C. Future trends of building heating and cooling loads and energy consumption in different climates. Build. Environ. 2011, 46, 223–234. [Google Scholar] [CrossRef]
- Pessenlehner, W.; Mahdavi, A. Building Morphology, Transparence, and Energy Performance. In Proceedings of the Eighth International IBPSA Conference, Eindhoven, The Netherlands, 11–14 August 2003. [Google Scholar]
- Schiavon, S.; Lee, K.H.; Bauman, F.; Webster, T. Influence of raised floor on zone design cooling load in commercial buildings. Energy Build. 2010, 42, 1182–1191. [Google Scholar] [CrossRef] [Green Version]
- UN (United Nations). Available online: https://unfoundation.org/what-we-do/issues/sustainable-development-goals/ (accessed on 17 April 2021).
- Cai, M.; Koopialipoor, M.; Armaghani, D.J.; Thai Pham, B. Evaluating Slope Deformation of Earth Dams due to Earthquake Shaking using MARS and GMDH Techniques. Appl. Sci. 2020, 10, 1486. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Koopialipoor, M.; Armaghani, D.J.; Ghabussi, A.; Baharom, S.; Morasaei, A.; Shariati, A.; Khorami, M.; Zhou, J. Evaluating the bond strength of FRP in concrete samples using machine learning methods. Smart Struct. Syst. 2020, 26, 403–418. [Google Scholar]
- Huang, J.; Koopialipoor, M.; Armaghani, D.J. A combination of fuzzy Delphi method and hybrid ANN-based systems to forecast ground vibration resulting from blasting. Sci. Rep. 2020, 10, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Koopialipoor, M.; Armaghani, D.J.; Hedayat, A.; Marto, A.; Gordan, B. Applying various hybrid intelligent systems to evaluate and predict slope stability under static and dynamic conditions. Soft Comput. 2018. [Google Scholar] [CrossRef]
- Yang, H.; Koopialipoor, M.; Armaghani, D.J.; Gordan, B.; Khorami, M.; Tahir, M.M. Intelligent design of retaining wall structures under dynamic conditions. STEEL Compos. Struct. 2019, 31, 629–640. [Google Scholar]
- Huang, L.; Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. Invasive Weed Optimization Technique-Based ANN to the Prediction of Rock Tensile Strength. Appl. Sci. 2019, 9, 5372. [Google Scholar] [CrossRef] [Green Version]
- Armaghani, D.J.; Koopialipoor, M.; Bahri, M.; Hasanipanah, M.; Tahir, M.M. A SVR-GWO technique to minimize flyrock distance resulting from blasting. Bull. Eng. Geol. Environ. 2020. [Google Scholar] [CrossRef]
- Zhou, J.; Koopialipoor, M.; Li, E.; Armaghani, D.J. Prediction of rockburst risk in underground projects developing a neuro-bee intelligent system. Bull. Eng. Geol. Environ. 2020, 79, 4265–4279. [Google Scholar] [CrossRef]
- Tang, D.; Gordan, B.; Koopialipoor, M.; Jahed Armaghani, D.; Tarinejad, R.; Thai Pham, B.; Huynh, V. Van Seepage Analysis in Short Embankments Using Developing a Metaheuristic Method Based on Governing Equations. Appl. Sci. 2020, 10, 1761. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Bejarbaneh, B.Y.; Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Tahir, M.M. A hybrid GEP and WOA approach to estimate the optimal penetration rate of TBM in granitic rock mass. Soft Comput. 2021. [Google Scholar] [CrossRef]
- Galelli, S.; Castelletti, A. Assessing the predictive capability of randomized tree-based ensembles in streamflow modelling. Hydrol. Earth Syst. Sci. 2013, 17, 2669–2684. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and regression trees. In Advanced Books & Software; Brooks/Cole Publishing: Monterey, CA, USA, 1984. [Google Scholar]
- Ye, J.; Koopialipoor, M.; Zhou, J.; Armaghani, D.J.; He, X. A Novel Combination of Tree-Based Modeling and Monte Carlo Simulation for Assessing Risk Levels of Flyrock Induced by Mine Blasting. Nat. Resour. Res. 2020, 30, 225–243. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, M.D.; Nguyen-Thoi, T.; Ho, L.S.; Koopialipoor, M.; Quoc, N.K.; Armaghani, D.J.; Van Le, H. A novel approach for classification of soils based on laboratory tests using Adaboost, Tree and ANN modeling. Transp. Geotech. 2020, 100508. [Google Scholar] [CrossRef]
- Erdal, H.I.; Karakurt, O. Advancing monthly streamflow prediction accuracy of CART models using ensemble learning paradigms. J. Hydrol. 2013, 477, 119–128. [Google Scholar] [CrossRef]
- Wang, Y.; Witten, I.H. Inducing model trees for continuous classes. In Proceedings of the Ninth European Conference on Machine Learning, Prague, Czech Republic, 23–25 April 1997; Volume 9. [Google Scholar]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, 16–18 November 1992; Volume 92, pp. 343–348. [Google Scholar]
- Jekabsons, G. M5 Regression Tree and Model Tree Toolbox for Matlab; Technical Report; Institute of Applied Computer Systems, Riga Technical University: Riga, Latvia, 2010. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 1189–1232. [Google Scholar]
- Koopialipoor, M.; Nikouei, S.S.; Marto, A.; Fahimifar, A.; Armaghani, D.J.; Mohamad, E.T. Predicting tunnel boring machine performance through a new model based on the group method of data handling. Bull. Eng. Geol. Environ. 2018, 78, 3799–3813. [Google Scholar] [CrossRef]
- Koopialipoor, M.; Noorbakhsh, A. Applications of Artificial Intelligence Techniques in Optimizing Drilling. In Emerging Trends in Mechatronics; IntechOpen: London, UK, 2020. [Google Scholar]
- Zorlu, K.; Gokceoglu, C.; Ocakoglu, F.; Nefeslioglu, H.A.; Acikalin, S. Prediction of uniaxial compressive strength of sandstones using petrography-based models. Eng. Geol. 2008, 96, 141–158. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
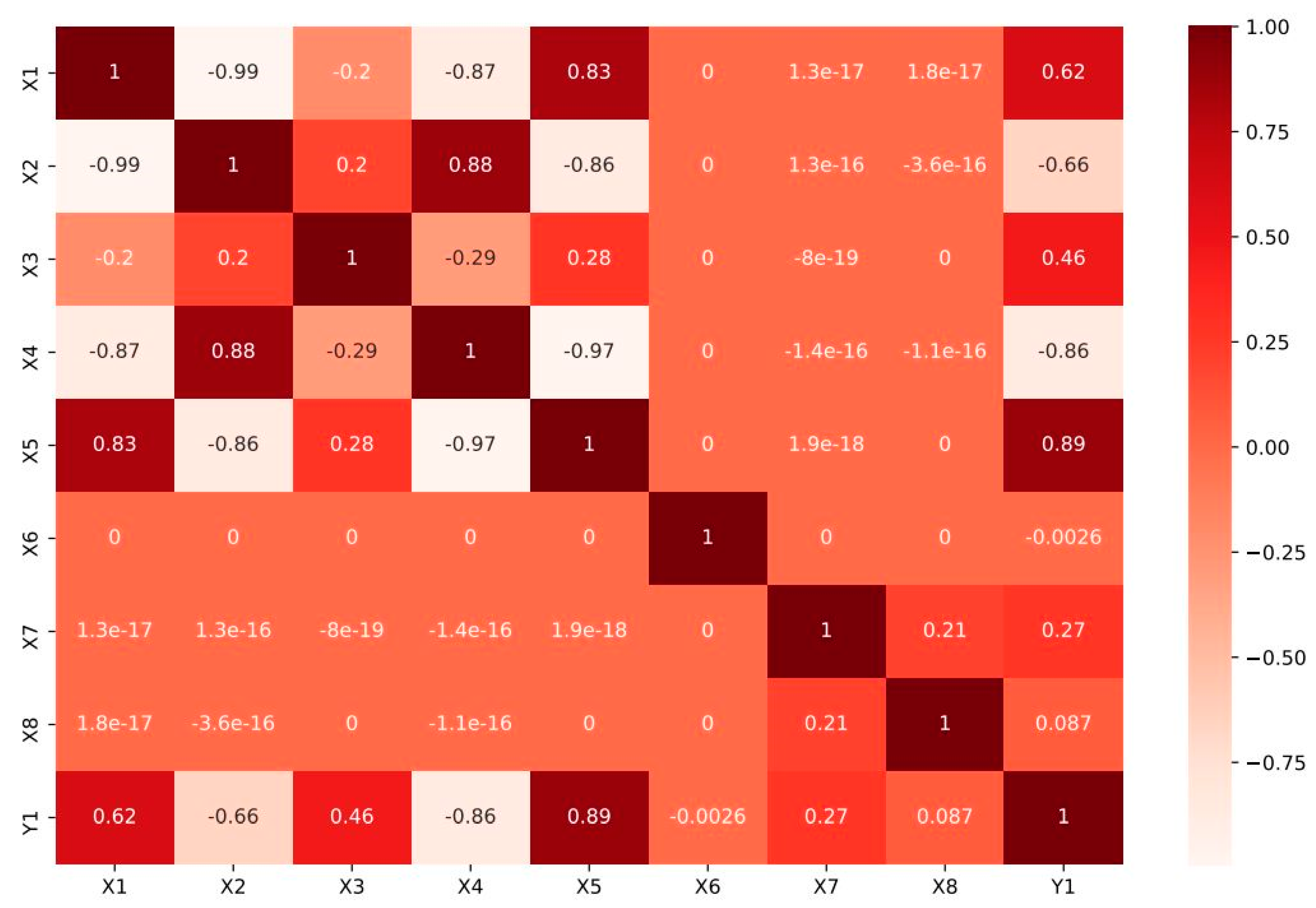
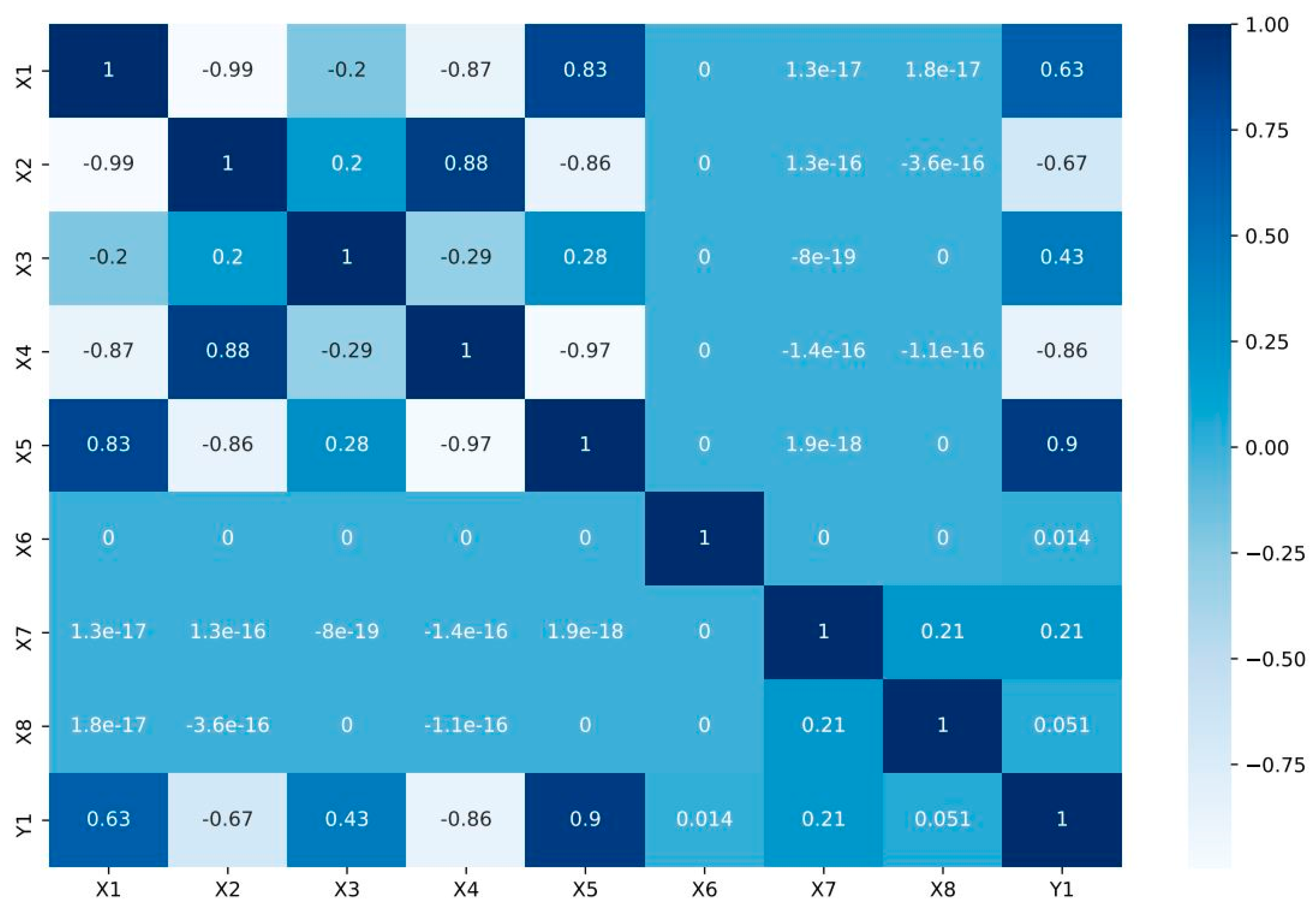
| Parameter | Symbol | Unit | Minimum | Average | Maximum | Variance |
|---|---|---|---|---|---|---|
| Relative compactness | X1 | - | 0.62 | 0.76 | 0.98 | 0.01 |
| Surface area | X2 | m2 | 514.50 | 671.71 | 808.50 | 7759.16 |
| Wall area | X3 | m2 | 245 | 318.50 | 416.50 | 1903.27 |
| Roof area | X4 | m2 | 110.25 | 176.60 | 220.50 | 2039.96 |
| Overall height | X5 | m | 3.50 | 5.25 | 7 | 3.07 |
| Orientation | X6 | - | 2 | 3.50 | 5 | 1.25 |
| Glazing area | X7 | m2 | 0 | 0.23 | 0.4 | 0.02 |
| Glazing area distribution | X8 | - | 0 | 2.81 | 5 | 2.41 |
| Heating load | Y1 | KWh/m2 | 6.01 | 22.31 | 43.1 | 101.81 |
| Cooling load | Y2 | KWh/m2 | 10.9 | 24.59 | 48.03 | 90.50 |
| Model | Hyper-Parameter | Limit | Optimal |
|---|---|---|---|
| CART | Maximal depth | [5–15] | 10 |
| Minimal leaf size | [2–5] | 2 | |
| Minimal size for split | [2–6] | 3 | |
| RF | Number of trees | [1–12] | 10 |
| Maximal depth | [5–15] | 12 | |
| Minimal leaf size | [2–5] | 2 | |
| Minimal size for split | [2–6] | 4 | |
| M5 | Maximal depth | [5–15] | 8 |
| Minimal leaf size | [2–5] | 2 | |
| Minimal size for split | [2–6] | 3 | |
| XGBoost | Maximal depth | [2–15] | 6 |
| learning rate | [0–1] | 0.2 | |
| gamma | [0–4] | 0.1 | |
| colsample_bytree | [0–1] | 0.4 |
| Model | Network Result | Ranking | Total Rank | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TR | TS | TR | TS | |||||||||||
| R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | R2 | RMSE | MAE | |||
| Heating load | CART | 0.996 | 0.6 | 0.382 | 0.996 | 0.699 | 0.482 | 3 | 2 | 2 | 3 | 2 | 2 | 14 |
| RF | 0.998 | 0.457 | 0.319 | 0.996 | 0.641 | 0.471 | 4 | 4 | 4 | 3 | 3 | 3 | 21 | |
| M5 | 0.987 | 1.131 | 0.856 | 0.991 | 1.021 | 0.827 | 2 | 1 | 1 | 2 | 1 | 1 | 8 | |
| XGBoost | 0.998 | 0.461 | 0.338 | 0.997 | 0.582 | 0.437 | 4 | 3 | 3 | 4 | 4 | 4 | 22 | |
| Cooling load | CART | 0.969 | 1.662 | 1.107 | 0.965 | 1.78 | 1.148 | 2 | 2 | 2 | 2 | 1 | 1 | 10 |
| RF | 0.972 | 1.596 | 1.022 | 0.97 | 1.66 | 1.054 | 4 | 4 | 4 | 3 | 2 | 2 | 19 | |
| M5 | 0.967 | 1.733 | 1.198 | 0.97 | 1.655 | 1.164 | 1 | 1 | 1 | 3 | 3 | 3 | 12 | |
| XGBoost | 0.971 | 1.607 | 1.027 | 0.973 | 1.567 | 1.008 | 3 | 3 | 3 | 4 | 4 | 4 | 21 | |
| Model | Relative Error | ||||||
|---|---|---|---|---|---|---|---|
| Training | Testing | ||||||
| Minimum (%) | Average (%) | Maximum (%) | Minimum (%) | Average (%) | Maximum (%) | ||
| Heating load | CART | 0 | 1.948093 | 22.46982 | 0.002152 | 2.265783 | 23.04147 |
| RF | 0 | 1.511993 | 20.50767 | 0.001537 | 2.2304 | 16.1755 | |
| M5 | 0.003095 | 4.871494 | 38.08553 | 0.001425 | 4.328006 | 22.97682 | |
| XGBoost | 0 | 1.658665 | 13.81958 | 0.006211 | 2.065914 | 13.16331 | |
| Cooling load | CART | 0.001627 | 3.993693 | 21.74001 | 0.00467 | 4.074743 | 23.07824 |
| RF | 0 | 3.541409 | 17.66955 | 0.040435 | 3.673206 | 19.47688 | |
| M5 | 0.010722 | 4.46516 | 18.01908 | 0.007783 | 4.325679 | 16.99606 | |
| XGBoost | 0 | 3.555542 | 15.25532 | 0 | 3.530423 | 14.2682 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammed, A.S.; Asteris, P.G.; Koopialipoor, M.; Alexakis, D.E.; Lemonis, M.E.; Armaghani, D.J. Stacking Ensemble Tree Models to Predict Energy Performance in Residential Buildings. Sustainability 2021, 13, 8298. https://0-doi-org.brum.beds.ac.uk/10.3390/su13158298
Mohammed AS, Asteris PG, Koopialipoor M, Alexakis DE, Lemonis ME, Armaghani DJ. Stacking Ensemble Tree Models to Predict Energy Performance in Residential Buildings. Sustainability. 2021; 13(15):8298. https://0-doi-org.brum.beds.ac.uk/10.3390/su13158298
Chicago/Turabian StyleMohammed, Ahmed Salih, Panagiotis G. Asteris, Mohammadreza Koopialipoor, Dimitrios E. Alexakis, Minas E. Lemonis, and Danial Jahed Armaghani. 2021. "Stacking Ensemble Tree Models to Predict Energy Performance in Residential Buildings" Sustainability 13, no. 15: 8298. https://0-doi-org.brum.beds.ac.uk/10.3390/su13158298