
An NN-Based Double Parallel Longitudinal and Lateral Driving Strategy for Self-Driving Transport Vehicles in Structured Road Scenarios

Abstract
:1. Introduction
2. Related Work
3. Problem Formulation
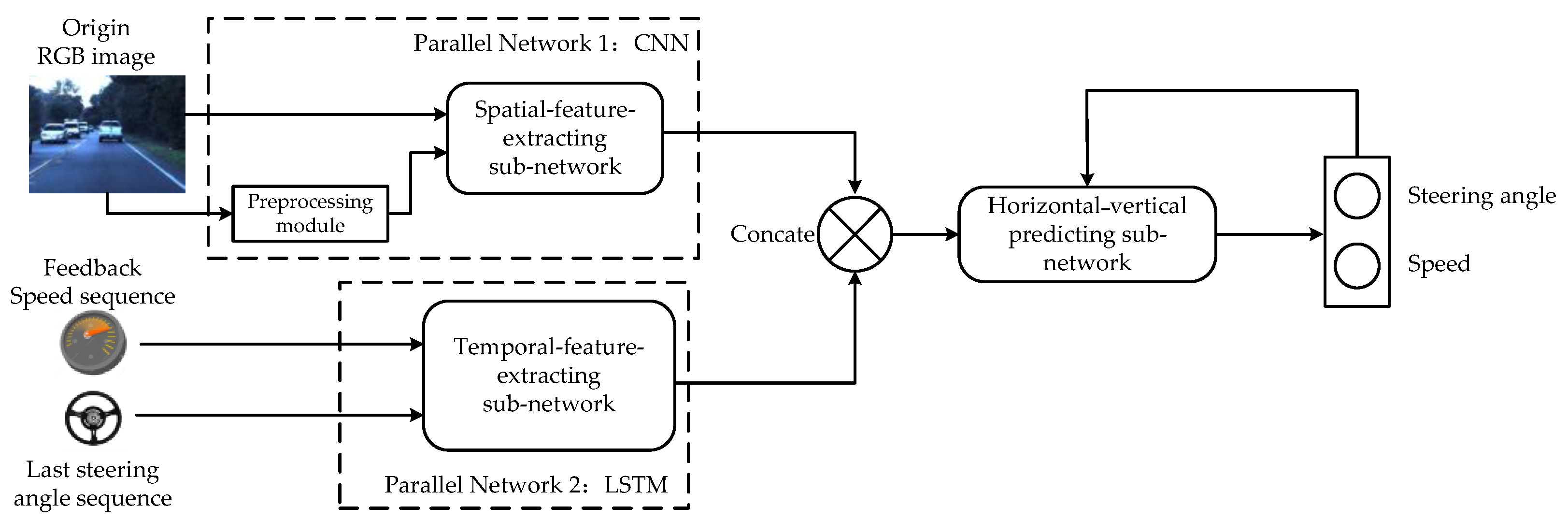
4. Proposed Method: DP-Net
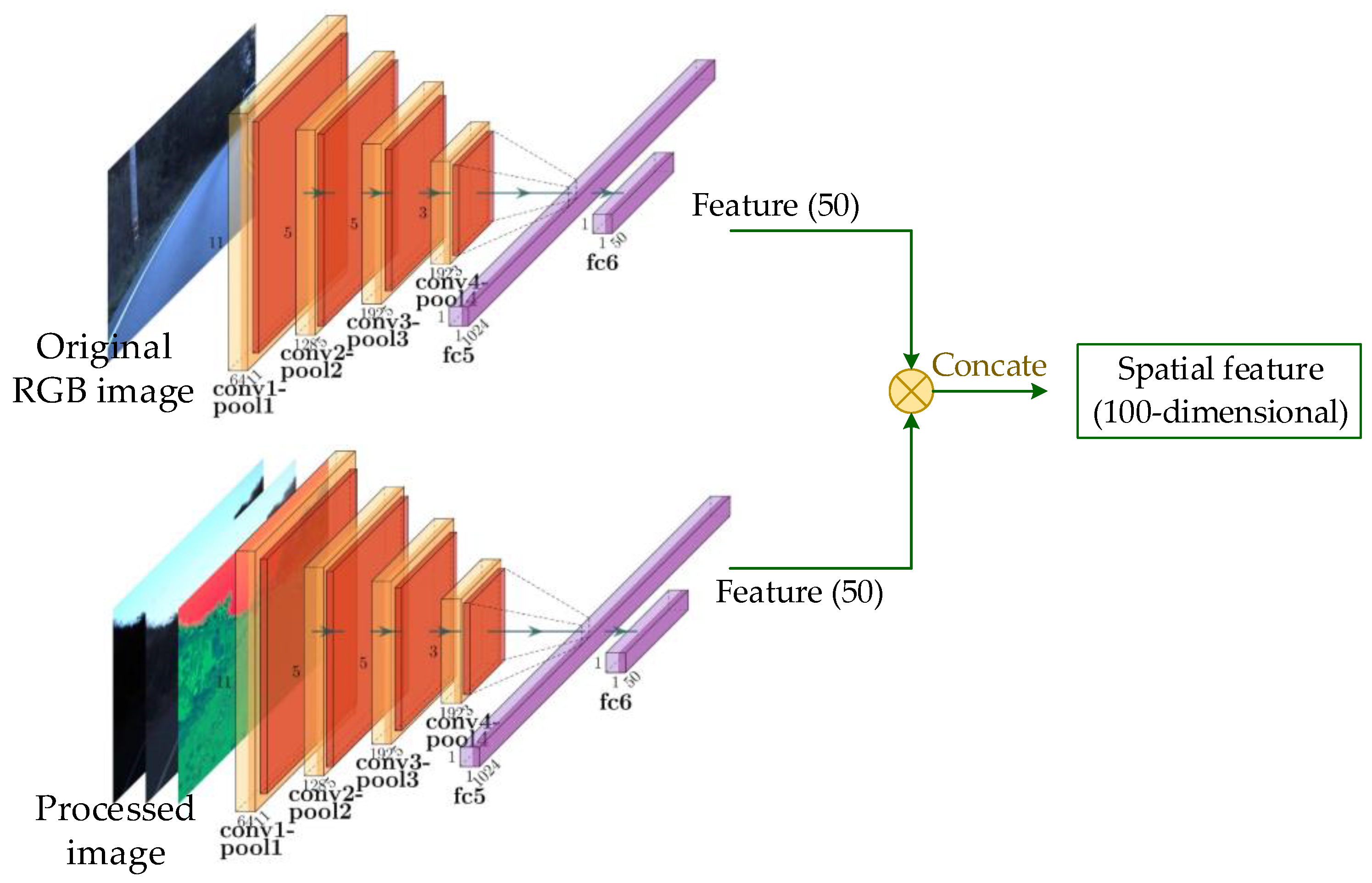
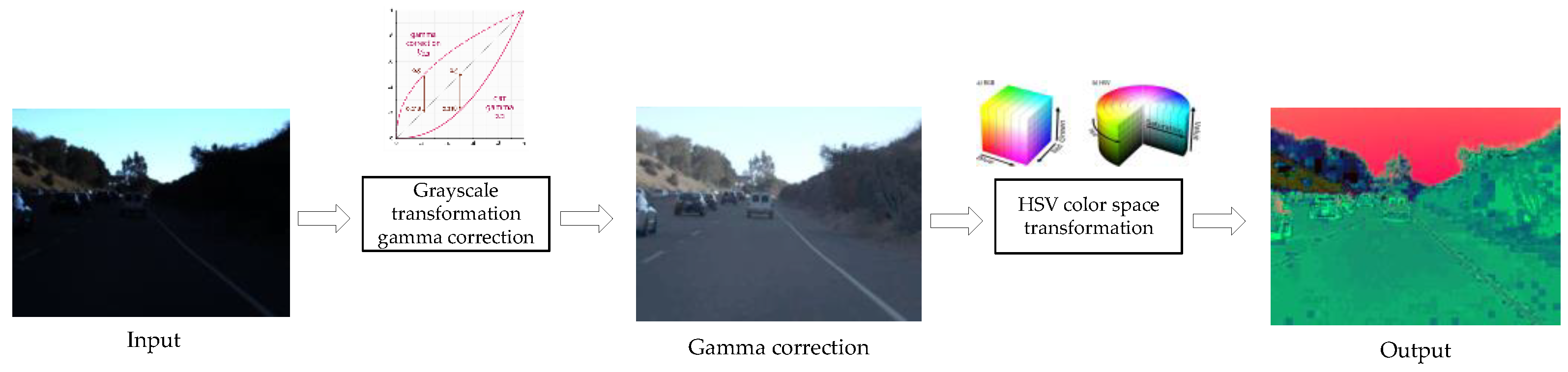
4.1. Spatial-Feature-Extracting Sub-Network
4.2. Temporal-Feature-Extracting Sub-Network
4.3. Longitudinal and Lateral Prediction Sub-Network
5. Experiments Evaluation
5.1. Experiments Setup
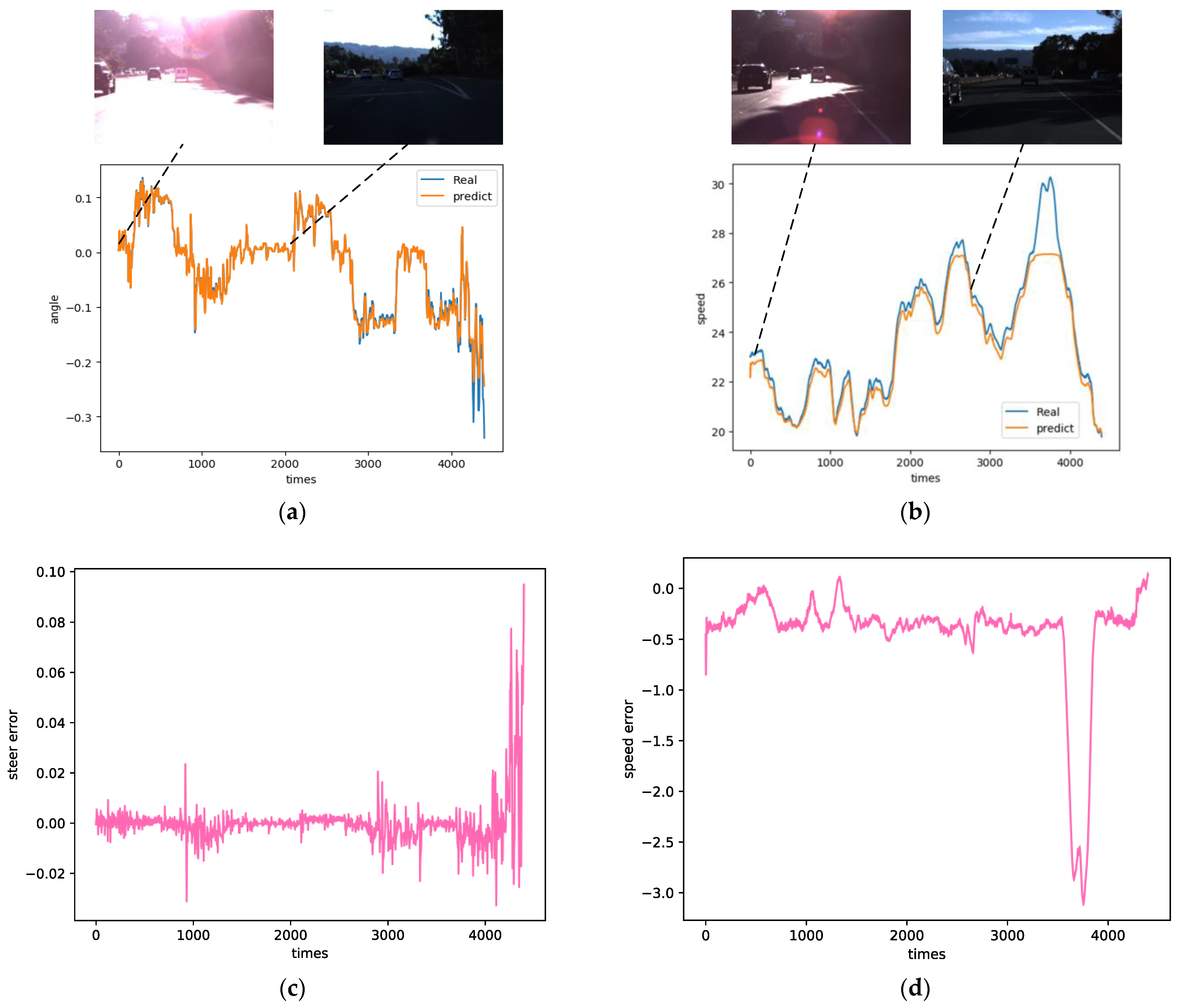
5.2. Performance Analysis
5.2.1. Comparison with Competing Algorithms
- PilotNet is the network proposed by NVIDIA. It consists of five convolutional layers and five fully connected layers, which use small kernel sizes (3 × 3, 5 × 5). We re-implemented this according to NVIDIA’s original technical report. All input video frames are resized to 200 × 66 before feeding PilotNet.
- CgNet is an open-source model with an excellent ranking in the Udacity Challenge II. Compared with PilotNet, it adjusts the kernel parameters to use only three convolutional layers and two fully connected layers, and it only uses a small kernel size (3 × 3). Note that the input of both PilotNet and CgNet is only the original single frame image, which ignores the visual features in dark light.
- The E2E multimodal multitask network is a five-layer convolution and four-layer fully connected multimodal multitask network, based on the AlexNet architecture proposed by Yang Z et al. We re-implemented it on Udacity Challenge II, according to the authors’ paper. Note that, although the authors extracted the temporal features by the LSTM network, it was not passed and applied to predict the steering angle. Therefore, the internal continuous kinematic state of the vehicle is ignored.
5.2.2. Validation on SYSU Campus
5.3. Ablation Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Park, B.; Lee, Y.-C.; Han, W.Y. Trajectory generation method using Bezier spiral curves for high-speed on-road autonomous vehicles. In Proceedings of the 2014 IEEE International Conference on Automation Science and Engineering (CASE), Taipei, Taiwan, 18–22 August 2014; pp. 927–932. [Google Scholar]
- Ziegler, J.; Bender, P.; Dang, T.; Stiller, C. Trajectory planning for Bertha A local, continuous method. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 450–457. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cun, Y.L.; Boser, B.; Denker, J.S.; Henderson, D.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1990, 2, 396–404. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-End Learning of Driving Models from Large-scale Video Datasets. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3530–3538. [Google Scholar]
- Pomerleau, D.A. Alvinn: An Autonomous Land Vehicle in a Neural Network. In Proceedings of the 1st Neural Information Processing Systems (NIPS Conference), Denver, CO, USA, 27–30 November 1988; pp. 305–313. [Google Scholar]
- Luo, Q.; Wang, G.Y.; Chu, W.D. Lane detection in micro-traffic under complex illumination. Comput. Sci. 2014, 41, 46–49. (In Chinese) [Google Scholar]
- Chi, L.; Mu, Y. Deep steering: Learning end-to-end driving model from spatial and temporal visual cues. arXiv 2017, arXiv:1708.03798. [Google Scholar]
- Codevilla, F.; Miiller, M.; Lopez, A.; Koltun, V.; Dosovitskiy, A. End-to-End Driving Via Conditional Imitation Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1–9. [Google Scholar]
- Yang, Z.; Zhang, Y.; Yu, J. End-to-end Multi-Modal Multi-Task Vehicle Control for Self-Driving Cars with Visual Perceptions. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2289–2294. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning to Steer by Mimicking Features from Heterogeneous Auxiliary Networks. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence/31st Innovative Applications of Artificial Intelligence Conference/9th AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8433–8440. [Google Scholar]
- Eraqi, H.M.; Moustafa, M.N.; Honer, J. End-to-End Deep Learning for Steering Autonomous Vehicles Considering Temporal Dependencies. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hecker, S.; Dai, D.; Van Gool, L. End-to-End Learning of Driving Models with Surround-view Cameras and Route Planners. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 449–468. [Google Scholar]
- Roh, C.G.; Im, I.J. A review on handicap sections and situations to improve driving safety of automated vehicles. Sustainability 2020, 12, 5509. [Google Scholar] [CrossRef]
- Nalic, D.; Pandurevic, A.; Eichberger, A.; Rogic, B. Design and Implementation of a Co-Simulation Framework for Testing of Automated Driving Systems. Sustainability 2020, 12, 10476. [Google Scholar] [CrossRef]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. Deep Driving: Learning affordance for direct perception in autonomous driving. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 2722–2730. [Google Scholar]
- Paliwal, S. Identity verification using speech and face information. Digit. Signal Process. 2004, 14, 449–480. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, L.R.; Girshick, S.; Guadarrama, T.D. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM Conference on Multimedia (MM), Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Cao, X. A Practical Theory for Designing Very Deep Convolutional Neural Networks. Unpublished Technical Report. 2015. Available online: https://www.kaggle.com/blobs/download/forum-message-attachment-files/2287/A%20practical%20theory%20for%20designing%20very%20deep%20convolutional%20neural%20networks.pdf (accessed on 24 November 2020).
- Xiong, H.; Zhu, X.; Zhang, R. Energy Recovery Strategy Numerical Simulation for Dual Axle Drive Pure Electric Vehicle Based on Motor Loss Model and Big Data Calculation. Complexity 2018, 2018, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.-H.; He, Z.-C.; Wang, H.-W.; You, F.; Li, K.-N. Study on Self-Tuning Tyre Friction Control for Developing Main-Servo Loop Integrated Chassis Control System. IEEE Access 2017, 5, 6649–6660. [Google Scholar] [CrossRef]
- Wojna, Z.; Gorban, A.N.; Lee, D.-S.; Murphy, K.; Yu, Q.; Li, Y.; Ibarz, J. Attention-Based Extraction of Structured Information from Street View Imagery. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 844–850. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- UDACITY. Available online: https://www.udacity.com/self-driving-car (accessed on 28 October 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Baidu Autonomous Driving Development Kit (Apollo D-KIT). Available online: https://apollo.auto/apollo_d_kit.html (accessed on 24 November 2020).
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Sun, X.; Hong, Z.; Meng, W.; Zhang, R.; Li, K.; Tao, P. Primary resonance analysis and vibration suppression for the harmonically excited non-linear suspension system using a pair of symmetric viscoelastic buffers. Nonlinear Dyn. 2018, 94, 1243–1265. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RMSE | MAE | Max Prediction Error |
|---|---|---|---|
| Nvidia’s PilotNet | 0.3063 | 0.2213 | 0.4973 |
| Cg Net | 0.3096 | 0.2219 | 0.4958 |
| E2E multimodal multitask network | 0.0584 | 0.0163 | 0.2732 |
| Proposed DP-Net (ours) | 0.0107 | 0.0054 | 0.0948 |
| Method | RMSE | MAE | Max Prediction Errors |
|---|---|---|---|
| E2E multimodal multitask network | 1.7112 | 0.13 | −3.0250 |
| Proposed DP-Net (ours) | 1.4211 | 0.8802 | −3.1101 |
| Number of Convolution Kernels | RMSE | MAE | ||
|---|---|---|---|---|
| Steering Angle | Speed | Steering Angle | Speed | |
| 48-64-128-128 | 0.0251 | 1.8057 | 0.0202 | 1.3895 |
| 64-128-128-128 | 0.0235 | 2.0441 | 0.019 | 1.6535 |
| 64-128-128-192 | 0.0242 | 2.0208 | 0.0191 | 1.489 |
| 64-128-192-192 | 0.0107 | 1.4211 | 0.0054 | 0.8802 |
| 128-128-192-192 | 0.0301 | 2.7121 | 0.027 | 2.2623 |
| 128-128-192-256 | 0.0021 | 2.3474 | 0.0404 | 2.0307 |
| Method | RMSE | MAE | ||
|---|---|---|---|---|
| Steering Angle | Speed | Steering Angle | Speed | |
| CNN | 0.0301 | 3.3778 | 0.0243 | 2.7171 |
| CNN-LSTM (DP-Net) | 0.0107 | 1.4211 | 0.0054 | 0.8802 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, H.; Liu, H.; Ma, J.; Pan, Y.; Zhang, R. An NN-Based Double Parallel Longitudinal and Lateral Driving Strategy for Self-Driving Transport Vehicles in Structured Road Scenarios. Sustainability 2021, 13, 4531. https://0-doi-org.brum.beds.ac.uk/10.3390/su13084531
Xiong H, Liu H, Ma J, Pan Y, Zhang R. An NN-Based Double Parallel Longitudinal and Lateral Driving Strategy for Self-Driving Transport Vehicles in Structured Road Scenarios. Sustainability. 2021; 13(8):4531. https://0-doi-org.brum.beds.ac.uk/10.3390/su13084531
Chicago/Turabian StyleXiong, Huiyuan, Huan Liu, Jian Ma, Yuelong Pan, and Ronghui Zhang. 2021. "An NN-Based Double Parallel Longitudinal and Lateral Driving Strategy for Self-Driving Transport Vehicles in Structured Road Scenarios" Sustainability 13, no. 8: 4531. https://0-doi-org.brum.beds.ac.uk/10.3390/su13084531