1. Introduction
Nowadays, the control of freshwater quality is a strategic priority for water resource and management [
1], and for a better reduction in water pollution [
2]. The dissolved oxygen concentration is an important water quality variable, and its fluctuation in response to several chemical, biochemical, and physical factors has been well documented [
3]. Currently, in situ measurements of DO concentrations, which are often accompanied by other water quality variables, have facilitated the development and application of a large number of numerical models for the better prediction of the DO in freshwater ecosystems. Because of the effect of other variables, the DO modeling becomes nonlinear in nature, and it is difficult to capture nonlinearity with simple models. However, models that are based on machine learning (ML) are the most widely used for modeling nonlinear variables, and they have gained much popularity during the last few years [
4,
5,
6,
7]. In practice, the calculated DO using numerical models has its own error. Thus, the research is heavily oriented towards the development of algorithms that reduce the prediction errors and that help in obtaining adequate predictive accuracies. In some case, the wrong selection of the model’s parameters and the inadequate models’ calibrations following poor model training significantly inflate the overall modeling error that is calculated between the measured and the predicted data [
8]. Ultimately, in order to reduce the prediction errors and to improve the ML model performances, various attempts have been made by utilizing algorithms that are capable of making better selections of the models’ parameters [
9,
10]. These algorithms can be classified into two categories: (i) Algorithms that improve the models’ performances by maximizing the contribution of the input variables, which is achieved by using preprocessing signal decomposition (PSD) algorithms (i.e., wavelet transform and empirical mode decomposition, among others [
11,
12]), and (ii) Algorithms that improve the generalization capabilities of the ML models by the correct choice of model parameters, which is generally achieved by using metaheuristic optimization algorithms (MOAs) (i.e., genetic algorithms, and particle swarm optimization (PSO)). While the use of PSD has gained much popularity, especially for solving problems that are based on long datasets, the number of developed algorithms is very limited compared to MOAs, for which their increased use has attracted the attention of researcher’s worldwide, and the number of developed algorithms is provided in an always increasing way [
13].
Until now, the modeling of dissolved oxygen has included single and hybrid models. In general, modeling using single models was formulated as an approximation function that involves the inclusion of specific water-quality variables, while accepting the need to select easily measured variables. While recognizing that this modeling strategy has the advantage of having a simple and direct mathematical formulation, the poor generalization capabilities, in some cases, and the extensive research to determine the best model parameters using a hard trial-and-error process, alternative approaches that are based on model optimization using MOAs, can be seen as complementary alternative approaches that lead to the better selection of the model parameters. The literature review reveals that several single models for DO prediction are available in the literature, such as: the long short-term memory (LSTM) deep neural network model [
14,
15]; deterministic models (i.e., MINLAKE2018) [
16]; the linear dynamic system and filtering model [
17]; the gated recurrent unit (GRU) deep neural network model [
18]; support vector regression (SVR) [
19]; the stochastic vector auto regression (SVAR) model [
20]; the radial basis function neural network (RBFNN) [
21]; the multilayer perceptron neural network (MLPNN) [
22]; polynomial chaos expansions (PCE) [
23]; random forest regression (RFR) [
24]; the extremely randomized tree [
25]; and multivariate adaptive regression splines (MARS) [
26].
Several hybrid models that use MOAs for DO prediction have been proposed over the last few years. Yang et al. [
27] investigated the capabilities and robustness of new hybrid models that were applied for predicting the daily DO in the Klamath River, Oregon, the United States. They hybridized the MLPNN model by using three MOAs, namely, the multi-verse optimizer (MVO), the black hole algorithm (BHA), and shuffled complex evolution (SCE), were developed and compared: (i) The MVO–MLPNN; (ii) The BHA-MLPNN; and (iii) The SCE–MLPNN. The three models were calibrated by using three water-quality variables, namely, the water temperature (
Tw), the pH, and the specific conductance (SC). According to the obtained results, the SCE–MLPNN was more accurate, and it exhibited a high correlation coefficient (R ≈ 0.877), compared to the values of (R ≈ 0.845) and (R ≈ 0.874) that were obtained using the MVO–MLPNN and the BHA–MLPNN, respectively. In a recently conducted investigation, Zhu et al. [
28] used four MOAs for optimizing the least squares support vector regression (LSSVR) model. The MOAs that were used were as follows: the fruit fly optimization algorithm (FFA); the particle swarm optimization (PSO) algorithm; the genetic algorithm (GA); and the immune genetic algorithm (IGA). Hence, four hybrid models were proposed: (i) FFA–LSSVR; (ii) PSO–LSSVR; (iii) GA-LSSVR; and (iv) IGA-LSSVR. Numerical comparison between models revealed that the FFA-LSSVR exhibited high predictive accuracies compared to the PSO–LSSVR, GA-LSSVR, and IGA-LSSVR for which the mean absolute percentage errors were ≈0.35%, ≈1.3%, ≈2.03% and ≈1.33%, respectively. Raheli et al. [
29] compared between hybrid FFA-MLPNN and single MLPNN in predicting monthly DO concentration in the Langat River, Malaysia. Comparison between the hybrid and single models revealed the superiority of the FFA-MLPNN (R ≈ 0.820, root mean square error, RMSE ≈ 0.497%) compared to the values obtained using the single MLPNN (R ≈ 0.727, RMSE ≈ 0.606). In another study, Deng et al. [
30] used the PSO algorithm combined with the MLPNN for developing a hybrid PSO-MLPNN model, which was used for predicting DO concentration in an aquiculture pond, showing the superiority of the PSO-MLPNN compared to the single MLPNN without providing numerical comparison. Song et al. [
31] proposed a new hybrid MOA called the improved sparrow search algorithm (ISSA) coupled LSTM (ISSA-LSTM) for predicting weekly DO concentration in the Haihe River, China. The performances of the ISSA-LSTM were compared to those of (SSA-LSTM), gray wolf optimization algorithm (GWO) coupled LSTM (GWO-LSTM), and the whale optimization algorithm (WOA) coupled LSTM (WOA-LSTM). A comparison of the models’ overall performances revealed that the ISSA-LSTM was more accurate, exhibiting the high predictive accuracies and the greatest improvement in terms of mean absolute error (MAE) and RMSE, compared to the standard LSTM, for which the decrease rate was ≈30.47% (SSA–LSTM), ≈36.22% (ISSA–LSTM), ≈21.34% (GWO–LSTM) and ≈19.08% (WOA–LSTM) in terms of MAE, and ≈34.98% (SSA–LSTM), ≈37.27% (ISSA–LSTM), ≈19.53% (GWO–LSTM) and ≈17.88% (WOA–LSTM) in terms of RMSE, respectively. From the obtained results, it is clear that the ISSA–LSTM was the most accurate and the GWO–LSTM was the poorest model.
A hybrid model combining the fractional grey seasonal model and the PSO algorithm (PSO–FGSM) was proposed in [
32]. The accuracies of the PSO–FGSM were compared to those of the Holt–Winters model optimized using GWO (GWO–HW). These two hybrid models were applied and compared for forecasting monthly DO concentration in the Huaihe River, China. The outcomes showed the superiority of the PSO–FGSM, which had a MAPE ranging from ≈8.66% to ≈10.73%, compared to the values obtained using the GWO–HW, i.e., MAPE ranging from ≈10.29% to ≈13.20%. Cao et al. [
33] used the PSO algorithm for optimizing the softplus extreme learning machine (SELM), and they applied the hybrid PSO–SELM for predicting DO concentration. According to the obtained results, the PSO–SELM was more accurate and provided the best predictive accuracies with Nash–Sutcliffe efficiency (NSE), RMSE and MAE equal to ≈0.952, ≈0.270 and ≈0.228 compared to the values obtained using ELM (NSE ≈ 0.908, RMSE ≈ 0.377, MAE ≈ 0.333), MLPNN (NSE ≈ 0.903, RMSE ≈ 0.390, MAE ≈ 0.322), LSTM (NSE ≈ 0.887, RMSE ≈ 0.416, MAE ≈ 0.336), and SVR (NSE ≈ 0.859, RMSE ≈ 0.466, MAE ≈ 0.391), respectively. Dehghani et al. [
34] employed the SVR model combined with four MOA algorithms namely: (i) the algorithm of the innovative gunner (AIG), (ii) the black widow optimization (BWO), (iii) social skidriver (SSD) optimization, and (iv) the chicken swarm optimization (CSO). The four hybrid models, i.e., AIG–SVR, BWO–SVR, SSD–SVR, and CSO–SVR were applied for predicting monthly DO concentration in the Cumberland River, USA, using water temperature (
Tw) and river discharge (
Q). According to the obtained results, the best prediction accuracies were obtained using the AIG–SVR (R ≈ 0.963, NSE ≈ 0.864, RMSE ≈ 0.644, and MAE ≈ 0.568). It was also found that the hybrid models improved the accuracies of the single SVR by 1.5% to 6.5%. Several other hybrid models for DO concentration can be found in the literature, for example, MLPNN optimized genetic algorithm (GA–MLPNN) [
35], gene expression programming with PSO (PSO–GEP) [
36], and differential evolution (DE) optimized radial basis function (DE–RBFNN) [
37].
Jiang et al. [
38] applied the wavelet–Lyapunov exponent model (WLME) for forecasting DO concentration at weekly and 15 min intervals. The proposed WLME is the result of a combination of the wavelet decomposition, chaos theory and Lyapunov exponent’s models. It was found that the WLME was more accurate compared to the standalone MLPNN and the autoregressive moving average (ARMA) exhibits an average relative error (ARE) of 2.35%. Huang et al. [
39] introduced a hybrid model composed of deep auto–regression recurrent neural network (DeepAR) and the variational mode decomposition (VMD), which are used as a preprocessing signal decomposition. In addition, the sparrow swarm algorithm (SSA) was used for model parameters’ optimization. The hybrid model, i.e., VMD-DeepAR-SSA, was compared to the standalone Bayesian and Bootstrap and it exhibited a prediction interval coverage probability (PICP) of 0.950. Li et al. [
40] proposed the hybrid models by combining the LSTM and the temporal convolutional network (TCN), i.e., the LSTM-TCN, for predicting DO concentration, and reported its high performances with MAE, RMSE, and R
2 of 0.236, 0.342 and 0.94, respectively. Yang and Liu [
41] adopted the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) as preprocessing signal decomposition for decomposing water quality variables, which are used as inputs for the LSTM model applied for predicting DO concentration. They carried out an analysis looking at comparative performances between the proposed CEEMDAN–LSTM and, respectively, the RBFNN, the recurrent neural network (RNN), GRU, CEEMDAN–RBFNN, CEEMDAN–RNN, CEEMDAN–GRU, VMD–LSTM, and wavelet transform LSTM (WT–LSTM). Obtained results revealed that the best prediction accuracies were obtained using the CEEMDAN–LSTM with MAE, RMSE, and MAPE of 0.102, 0.121 and 0.0149, respectively. Moghadam et al. [
42] compared deep recurrent neural network (DRNN), the SVM and the MLPNN models for predicting DO at (
t + 1), (
t + 3) and (
t + 7) time=horizons. It was found that the DRNN was more accurate compared to the other models and the forecasting accuracies decreased by increasing the forecasting horizon. Song and Yao [
43] introduced a new modeling framework for better prediction of DO concentration by combining three different paradigms, namely deep extreme learning machine (DELM), synchro-squeezed wavelet transform and sparrow search algorithm (SSA), i.e., the SWT–SSA–DELM. Results obtained using the proposed model was compared to those obtained using ELM, SWT–ELM, SSA–ELM, SWT–SSA–ELM, DELM, SWT–DELM, SSA–DELM, and finally SWT–SSA–DELM. It was found that the SWT–SSA–DELM was more accurate exhibiting very low MAE (≈0.131) and RMSE (≈0.171) and very high R (≈0.982) and NSE (≈0.965) values. Recently, a hybrid model based on extreme gradient boosting (XGBoost), improved sparrow search algorithm (ISSA) and LSTM model, i.e., the XGBoost-ISSA–LSTM was proposed by Wu et al. [
44] for multi steps ahead forecasting of DO concentration. It was found that, in one hand, high forecasting accuracies can be obtained and in the other hand, the performance of the model decreased by increasing the forecasting horizon. In addition, a comparative study among several other hybrid models revealed that the XGBoost-ISSA-LSTM was more accurate compared to XGBoost-RFR, XGBoost-MLPNN, XGBoost-RNN, XGBoost-GRU, LSTM, XGBoost-LSTM, XGBoost-PSO-LSTM, and XGBoost-SSA-LSTM.
Our motivation is to introduce a new hybrid model for better prediction of DO concentration in rivers, using SVR optimization based on firefly algorithm particle swarm optimization (FFAPSO–SVR). The proposed FFAPSO–SVR was compared to the SVR, FFA–SVR and PSO–SVR, while hybridizing the SVR and LSSVR using MOA was reported in the literature [
28,
34]. To the best of our knowledge, combining the FFA and PSO to provide a single algorithm coupled with the SVR model has never reported in the literature, therefore constituting the major motivation of our study. The rest of the paper is organized as follows:
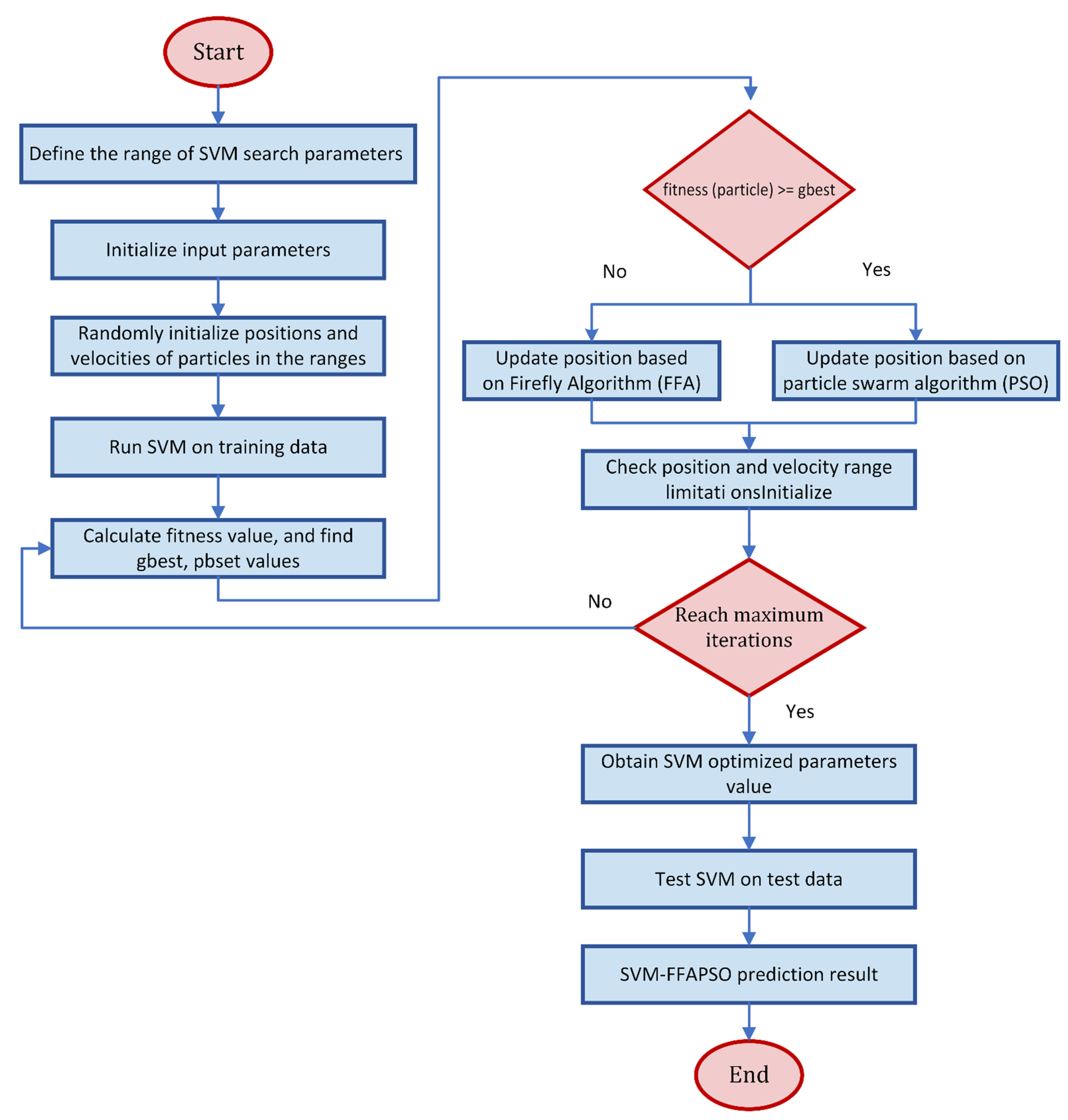
Section 2 describes the case study and briefly describes each model applied in this study.
Section 3 presents the main results and discusses their relevance. Finally, the main conclusions drawn from this study are presented in
Section 4.
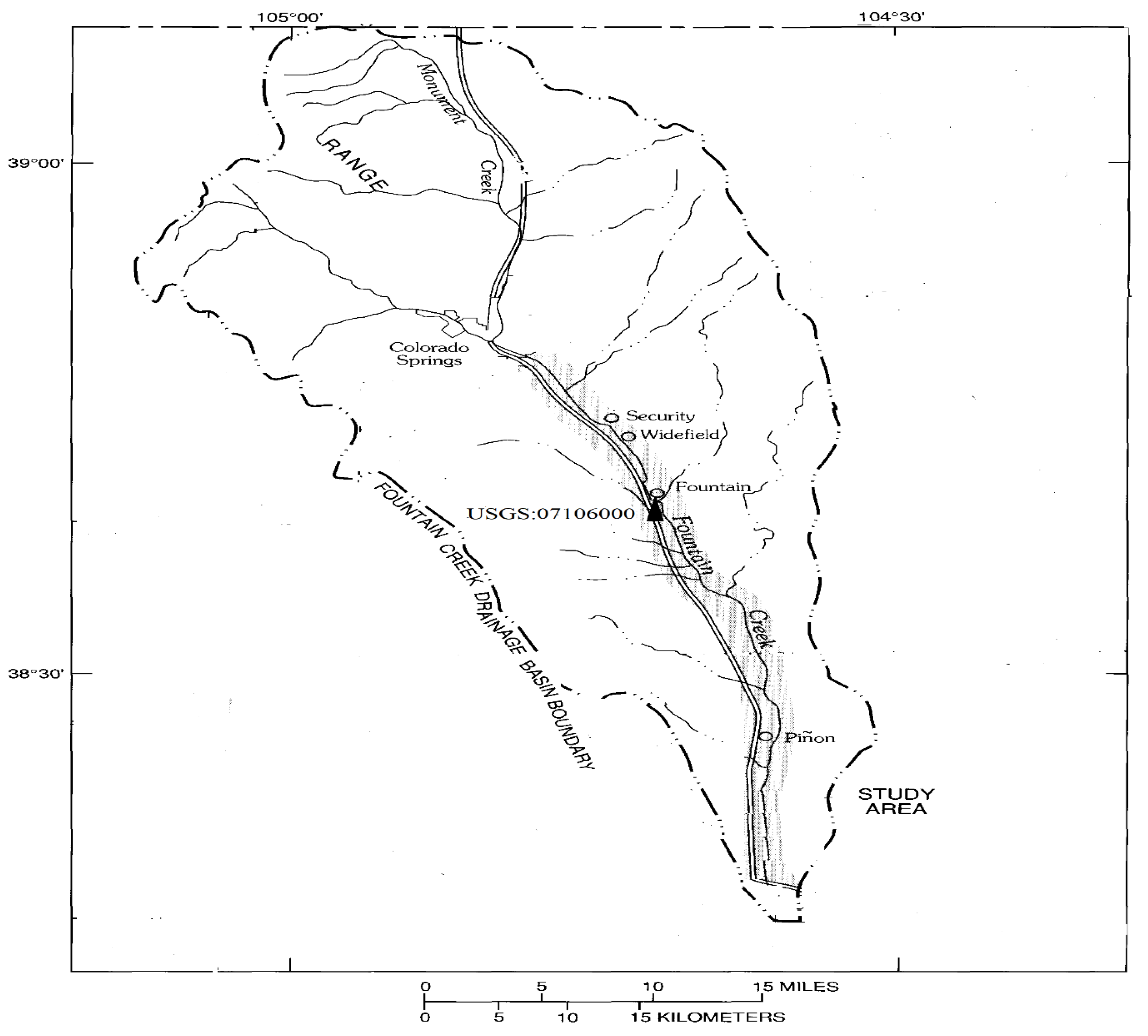
3. Application and Results
In the present study, the SVM hyperparameters were tuned by following the suggestion by Sudheer et al. (2014). The parameters
,
, and
were searched in the exponential space
,
and
.
Table 1 sums up brief information about the set parameters for the implemented method and algorithms. Data split rule of 80–20% was used before applying the machine learning methods. Forty populations and 100 iterations were set for all algorithms. They were run 25 times and their averages were recorded. Several combinations of four variables (T, pH, EC and Q) were used as input to the models to estimate daily DO.
Table 2 shows the training and testing outcomes of the standard SVM method in respect of RMSE, MAE, R
2 and NSE. As can be seen from the table, 15 possible input combinations were evaluated using SVM. As expected, the SVM model having all four variables produced the lowest errors (RMSE = 0.316 mg/L, MAE = 0.237 mg/L for training and RMSE = 0.223 mg/L, MAE = 0.176 mg/L for testing) and the highest R
2 (R
2 = 0.951 for training, R
2 = 0.978 for testing) and NSE (NSE = 0.95 for training and NSE = 0.97 for testing).
According to the combinations with one input, the pH-based SVM model has the highest accuracy, followed by the T-based model and EC- and Q-based models, which have very low accuracy. It can be said that the pH has the highest influence on DO, followed by the T variable, whereas the Q has the least effect on DO, followed by the EC variable. From double-input combinations, however, it is observed that the SVM models with pH, Q and pH, EC have almost the same accuracy and they perform superior to the other alternatives in estimating DO in the test stage. This implies that the EC and Q also have considerable influence on DO estimation when they were used together with pH variable. However, Q or EC variables does not considerably improve the SVM accuracy when they were used with the T input. As expected, the combination of Q, EC produced the worst results. Examining the triple input combinations indicates that the SVM model with T, pH and EC provides the highest accuracy (RMSE = 0.225 mg/L, MAE = 0.179 mg/L, R2 = 0.97 and NSE = 0.961) and it is followed by the pH, Q and EC inputted model. From the all the input combinations considered, it can be said that only the use of one- or two- input combinations may give missing information about the effect of a variable on daily DO. All the possible combinations should be evaluated to decide the impact of each variable in the estimation of DO.
A comparison of SVM–PSO models with different input cases is presented in
Table 3 for estimating daily DO concentration. For this method, the four-inputted model has the best accuracy with the best RMSE, MAE, R
2 and NSE scores in the simulation (training) and estimation (testing) stages (0.308 mg/L, 0.231 mg/L, 0.954, 0.954 for training and 0.219 mg/L, 0.172 mg/L, 0.978, 0.973 for testing). Here, parallel results were also acquired from the different combinations of single, double and triple inputs. Compared to the single SVM method, the hybrid SVM–PSO considerably improves the estimation accuracy, especially for the limited input cases; for example, improvement for the best one input (pH variable) SVM model is 4.5%, 15%, 0.42% and 0.64%, with respect to RMSE, MAE, R
2 and NSE and the corresponding improvements for the best double input (pH and Q) SVM model are 3.15%, 11.5%, −0.62% and −0.43% in the test stage, respectively.
The training and testing outcomes of the SVM–FFA methods with different input cases are reported in
Table 4. Like the previous two methods, here also the model with full input variables performed the best (RMSE = 0.299 mg/L, MAE = 0.225 mg/L, R
2 = 0.956, NSE = 0.956 for training and RMSE = 0.204 mg/L, MAE = 0.157 mg/L, R
2 = 0.981, NSE = 0.975 for testing) in the simulation and estimation of daily DO. Comparison with the standard SVM and hybrid SVM–PSO methods clearly reveals that the FFA tuning considerably improves the accuracy of the SVM method in estimating daily DO. By employing this algorithm, the performance of one input (pH variable) SVM increased by 9.1%, 17.7%, 0.52% and 1.18% in respect to RMSE, MAE, R
2 and NSE, the corresponding improvements are 3.8%, 12.3%, 0.83% and 0.74% for the double input (pH and Q) SVM and for the triple input SVM, they are 3.11%, 4.47%, 0.82% and 1.14%, respectively. The improvements obtained in RMSE, MAE, R
2 and NSE, respectively are 4.75%, 3.33%, 0.10% and 0.53% for one input SVM–PSO, 0.65%, 0.84%, 0.21% and 0.32% for double input SVM–PSO and 3.11%, 3.39%, 0.62% and 0.52% for triple input SVM–PSO models in the test stage.
Table 5 sums up the training and testing outcomes of the hybrid SVM–HFPSO (SVM–FFAPSO) methods for different input cases. The best DO estimates were acquired from the four-input model (T, pH, EC and Q) having the lowest RMSE (0.202 mg/L), MAE (0.155 mg/L) and the highest R
2 (0.985) and NSE (0.977). There is a slight difference between the four-input SVM–HFPSO and SVM–FFA models, whereas the difference between these methods is considerable for the limited input cases. For example, relative differences in RMSE and MAE for the best one-input are 5.32% and 5.17%, while they are 5.50% and 3.51% for the triple input in the test stage, respectively. The new hybrid method (SVM–HFPSO) improved the best single SVM method by 13.9%, 22%, 0.52% and 1.83% with respect to RMSE, MAE, R
2 and NSE, the corresponding improvements are 43%, 41%, 2.7%, 5.97% for the double input (T and pH) model and for the triple input model, they are 8.4%, 7.8%, 0.93% and 1.46%, respectively. Compared to the SVM–PSO methods, the improvements obtained in RMSE, MAE, R
2 and NSE, respectively, are 9.8%, 8.3%, 0.1% and 1.17% for one input model and 8.4%, 6.78%, 0.72% and 0.83% for the triple input model in the test stage.
The outcomes of the best standard SVM, SVM–PSO, SVM–FFA and SVM–HFPSO, models having four inputs of T, pH, EC and Q, were further compared in multi-time step daily DO estimating. Till now, we compared the four methods in estimating daily DO at time t (for the current day).
Table 6 compares the optimal models for estimating daily DO from t + 1 (time step i) to t + 7 (time step vii). It is clear from the table that implementing PSO, FFA and FFAPSO in tuning hyperparameters of SVM method improves its accuracy in estimating multi-time step daily DO concentration.
The ranges of the RMSE, MAE, NSE and R2 for the standard SVM are 0.378–0.586 mg/L, 0.285–0.461 mg/L, 915–0.795 and 0.920–0.811 from time step i to vii, while the corresponding ranges are 0.378–0.585 mg/L, 0.284–0.459 mg/L, 917–0.798, 0.923–0.816 for the SVM–PSO, 0.367–0.581 mg/L, 0.278–0.456 mg/L, 920–0.802, 0.925–0.819 for the SVM–FFA and 0.362–0.562 mg/L, 0.275–0.441 mg/L, 922–0.808, 0.927–0.823 for the SVM–FFAPSO, respectively. By implementing the hybrid SVM–FFAPSO, the observed improvements in RMSE, MAE, NSE and R2 of the standard SVM are 26.4%, 24.1%, 13.8% and 15.9% in estimating 7-day ahead (time step vii or t + 7) DO concentration in the test stage, respectively.
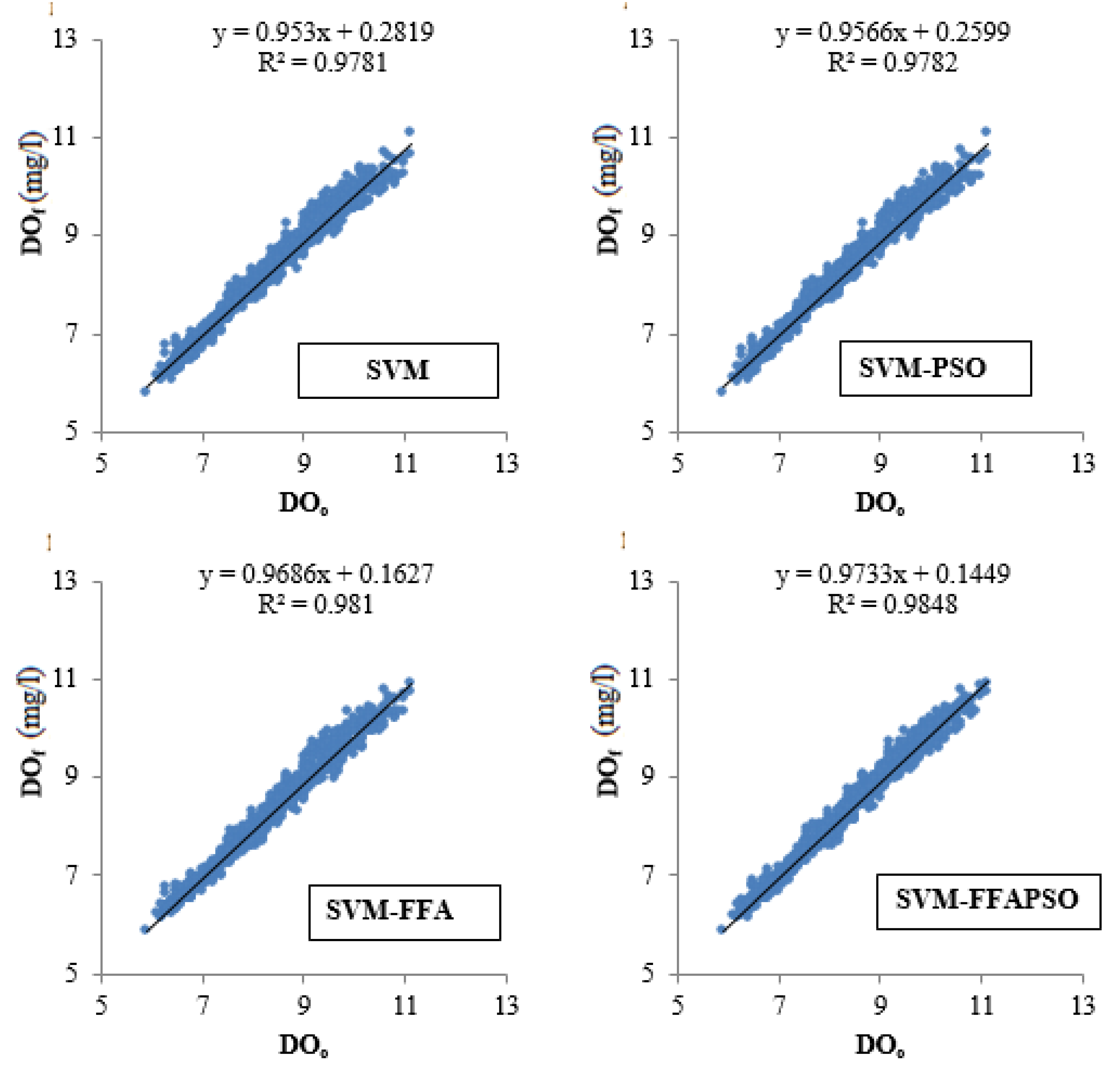
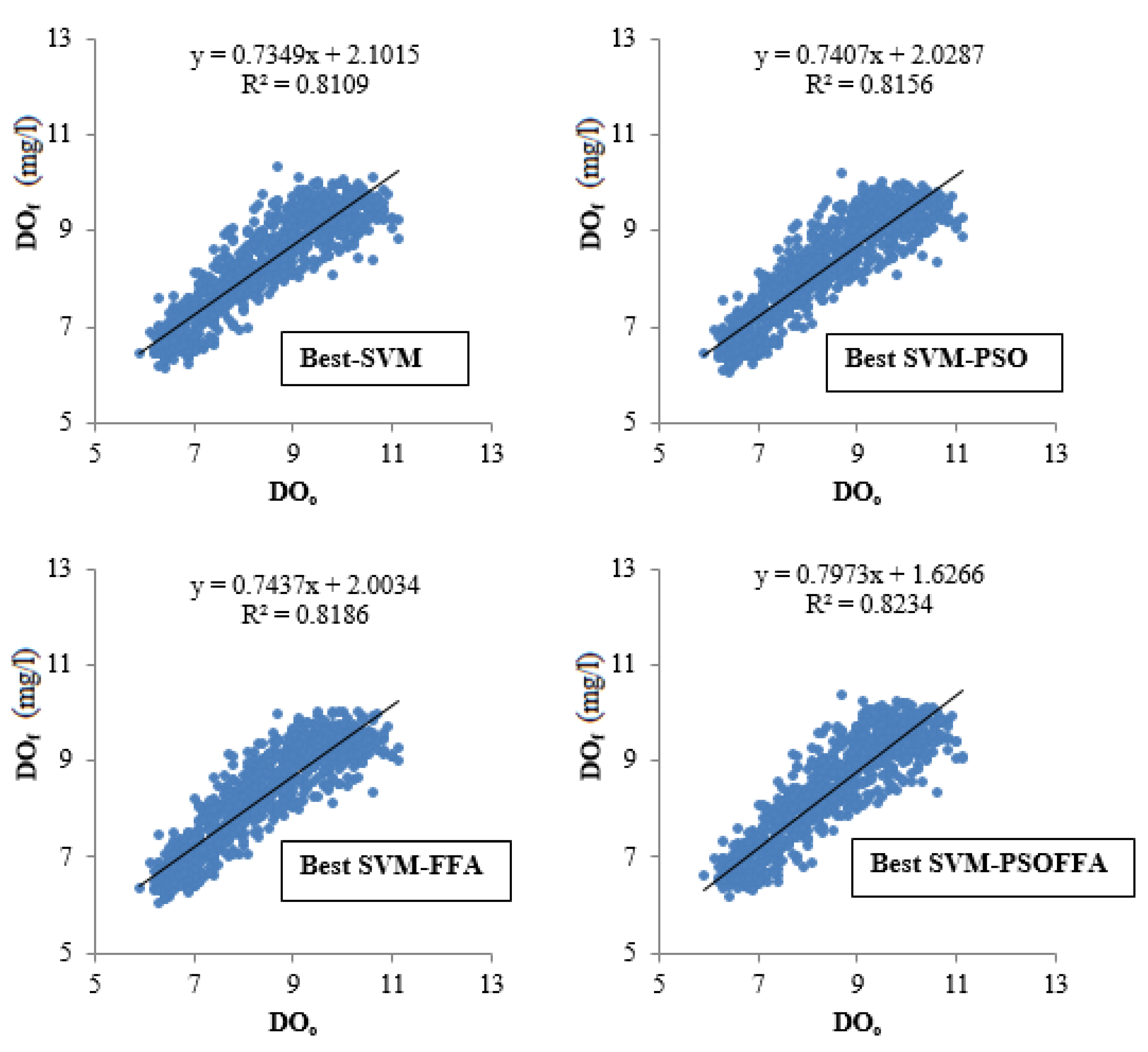
Figure 6 compares the testing outcomes of the optimal SVM–based models via scatter diagrams. It is evident from the fit line equations and R
2 values, the SVM–FFAPSO has less scattered estimates compared to other models and its performance is followed by the hybrid SVM–FFA and SVM–PSO. The Taylor diagram provided in
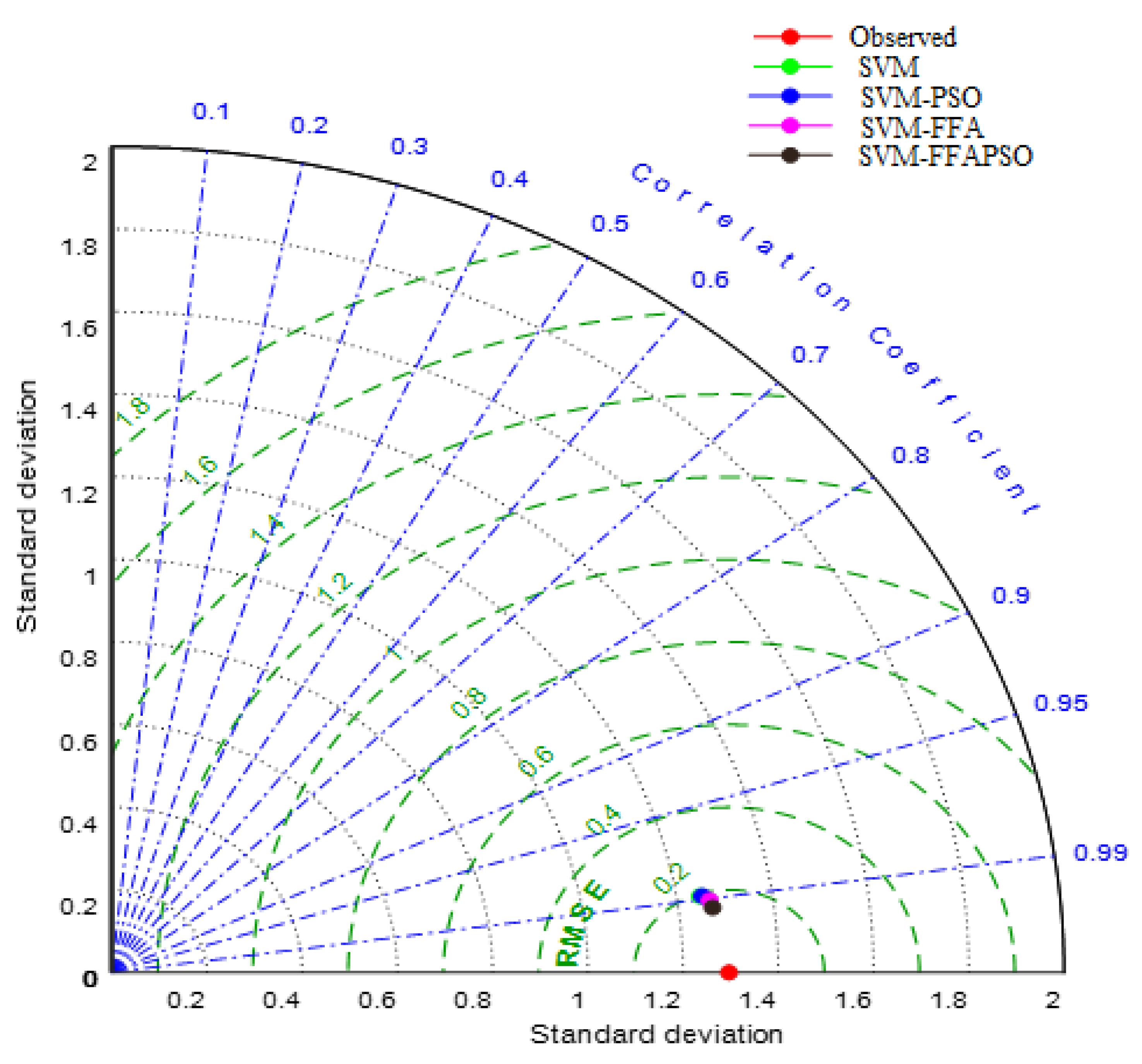
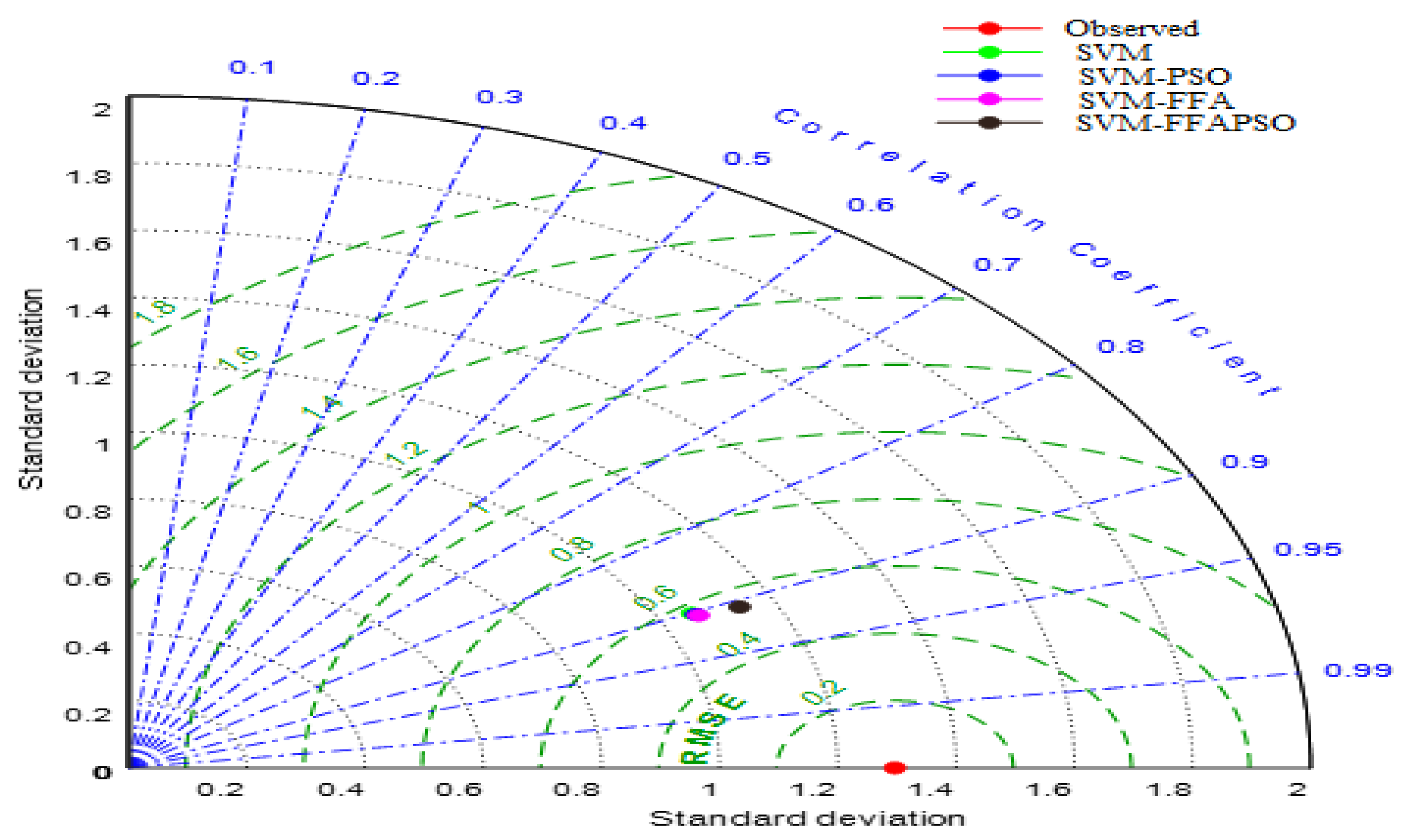
Figure 7 tell us that the hybrid SVM–FFAPSO model has closer standard deviation to the observed DO concentration and it has the lowest RMSE and the highest correlation.
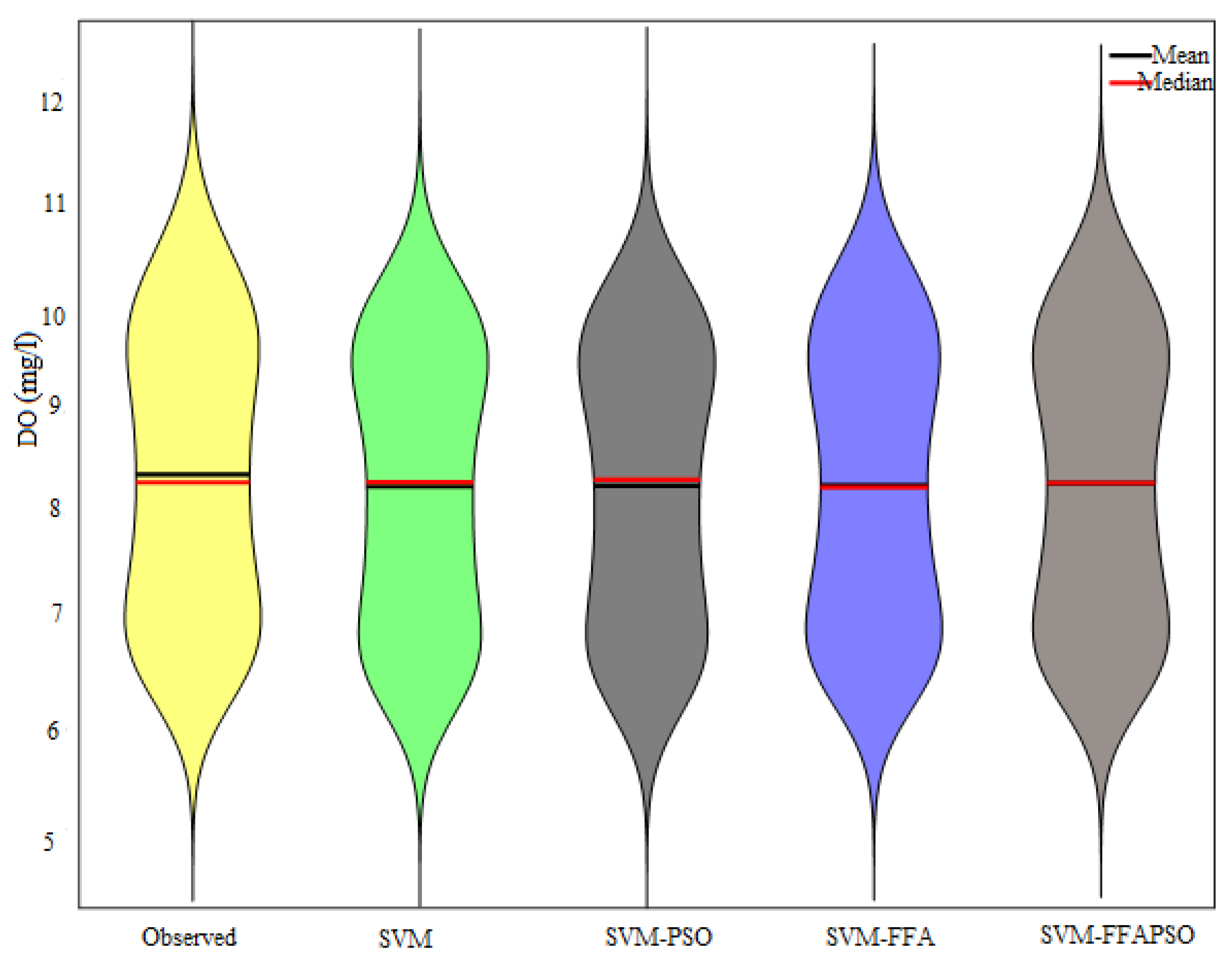
A Violin chart compares the distributions of the models’ estimation in
Figure 8. It is seen from the figure that the proposed SVM–FFAPSO has closer distribution to the that of the observed DO values.
Figure 9 illustrates the scatterplot comparison of the SVM–based models’ outcomes in estimating 7-day ahead DO concentration. As seen from the fit line equations and determination coefficient values in the figure, the hybrid SVM–FFAPSO keeps its superiority in estimating t + 7 DO with slope coefficient and bias values closer to 1 and 0 and higher R
2 compared to other three models. Hybrid SVM–FFA and SVM–PSO also have better forecasting performance than the standard SVM model, as evident from the fit line equations closer to the ideal line equation (y = x) and higher R
2. It is clearly observed from the Taylor diagram given in
Figure 10 that the hybrid SVM–FFAPSO model has superior accuracy over other models with respect to RMSE, correlation and standard deviation. The hybrid SVM–FFAPSO has closer standard deviation to the observed one and higher correlation and lower RSME compared to the SVM–FFA, SVM–PSO and standard SVM models.
Figure 11 shows that the similarity between the distributions of the SVM–FFAPSO and observed values is higher compared to the other SVM–based models in estimating 7-day ahead DO concentration. It is clearly seen from the figure that the mean and median values of the hybrid SVM–FFAPSO are closer to the observed one and distribution of the estimates in the upper and lower parts (with respect to mean or medium) are more resembling the distributions of the target DO values. Comparison of
Figure 5,
Figure 6 and
Figure 7 clearly indicates that increasing the time lag to 7 considerably decreased the models’ accuracy in estimating DO concentration.
Singh et al. [
63] predicted the DO of the Gomti River, India using neural networks and they found correlation coefficient, R of 0.76 from the best model in the test stage. Ranković et al. [
64] modeled the DO of the Gruza Reservoir, Serbia, considering the inputs of pH, temperature, nitrates, chloride and total phosphate. They obtained an R of 0.874 for the best model in the test stage. Heddam [
65] used GRNN for modeling the DO of the Upper Klamath River, USA and they used T, pH, SC and SD as inputs. The correlation coefficient (R) of the best model (GRNN) was found to be 0.984 in the test stage. Elkiran et al. [
66] investigated the accuracy of an ensemble method involving ANFIS, SVM and ARIMA in modeling DO of the Yamuna River, India using inputs BOD, COD, discharge, pH, Ammonia and water temperature. The best models produced a mean R of 0.969 from three stations considered in their study. In our study, the best SVM–FFAPSO model provided R of 0.992 in modeling DO of Fountain Creek, which indicates the good accuracy of the proposed model.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}