
A Multi-Module Information-Optimized Approach to English Language Teaching and Development in the Context of Smart Sustainability

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- User interest recognition was implemented based on an autoencoder for four modules typical of the English teaching process: listening, reading, writing, and listening;
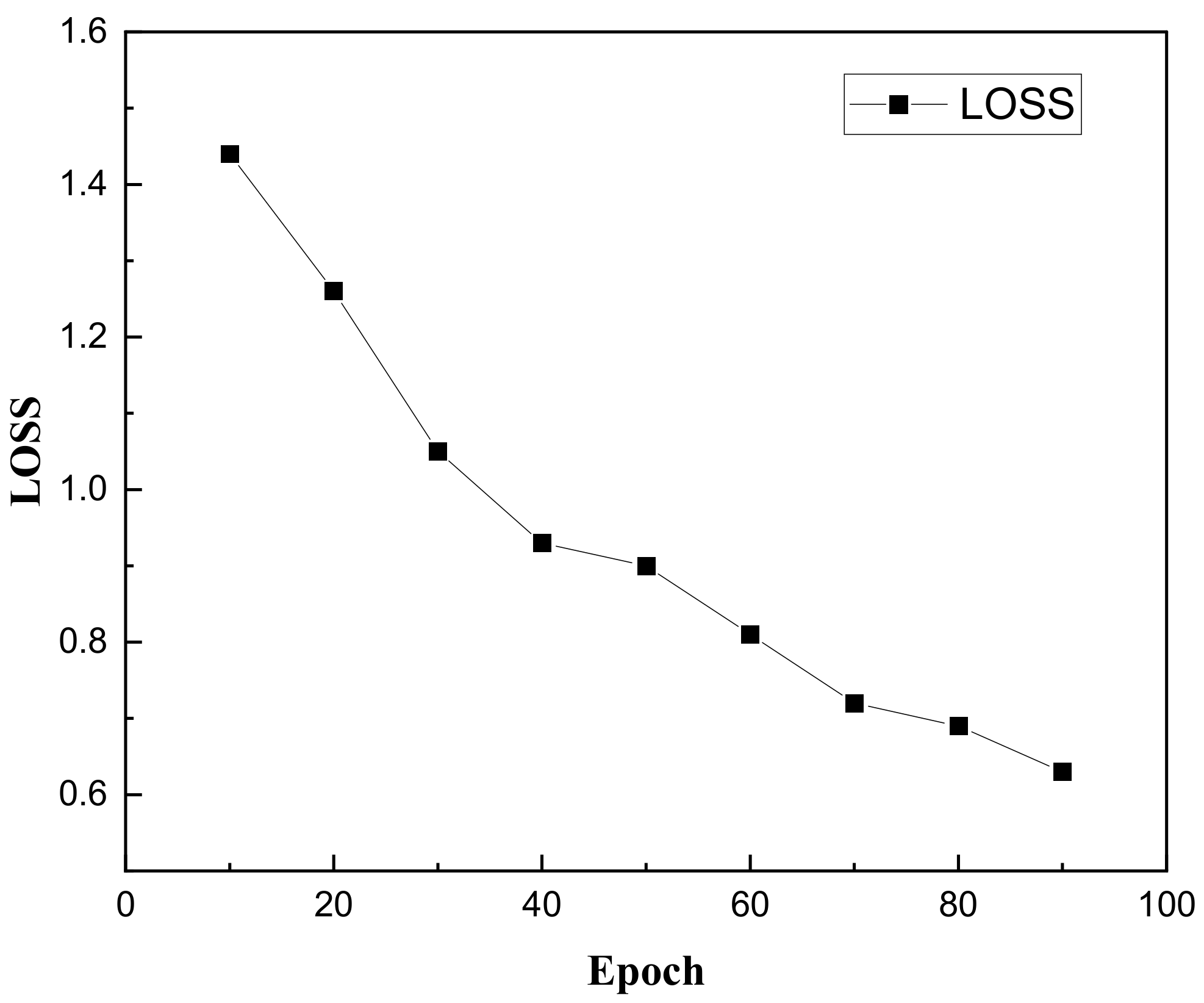
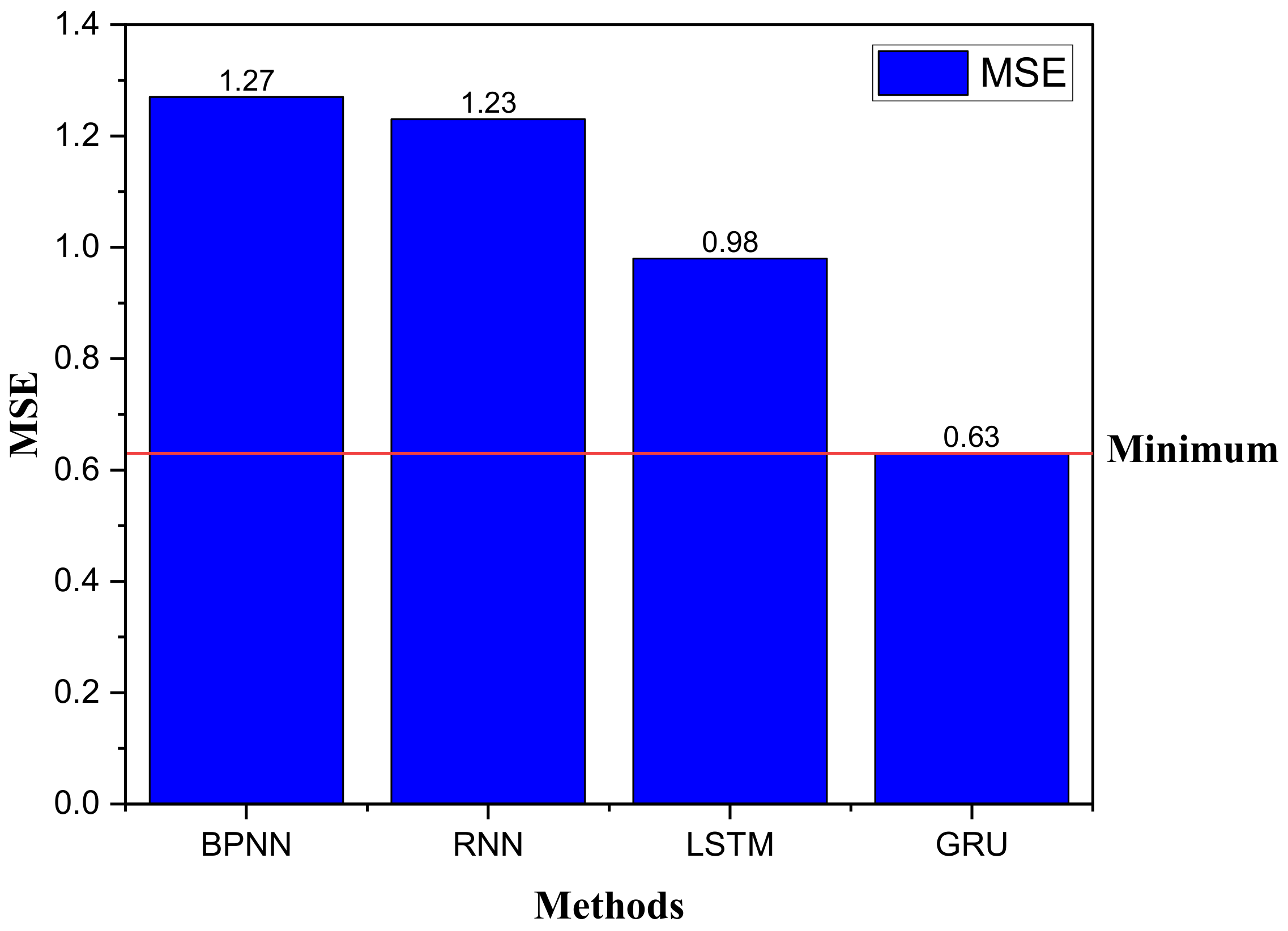
- A joint multi-module intelligent assessment of English learning was implemented using GRUs with an MSE of only 0.63 between its score and the actual score;
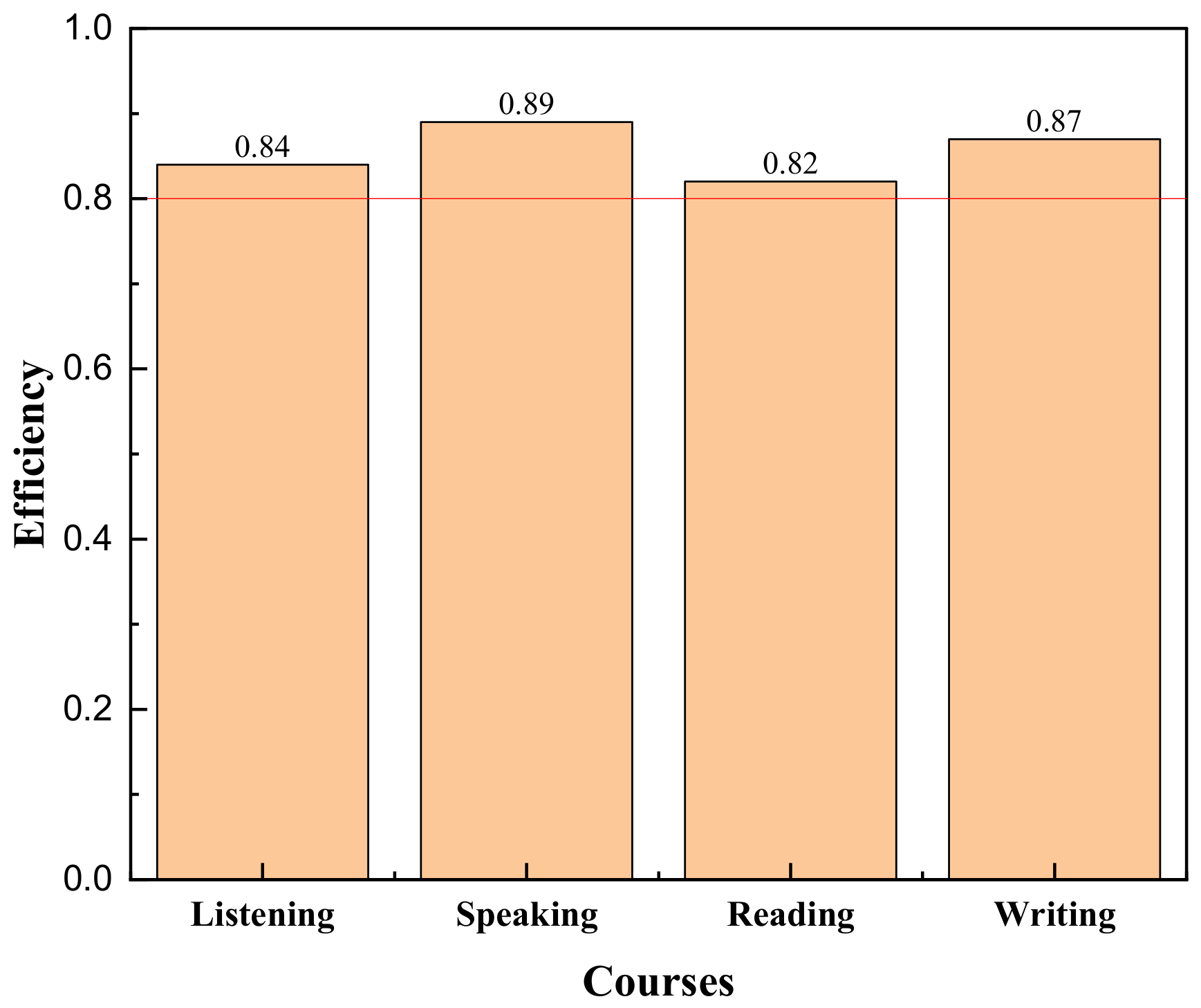
- Practical testing was conducted on the proposed intelligent learning and evaluation framework, and the actual operating efficiency of the system exceeded 80%.
2. Related Works
2.1. Research on Content Pushing Based on Learning Habits
2.2. Research on Intelligent Evaluation Techniques in the Context of Machine Learning and Deep Learning
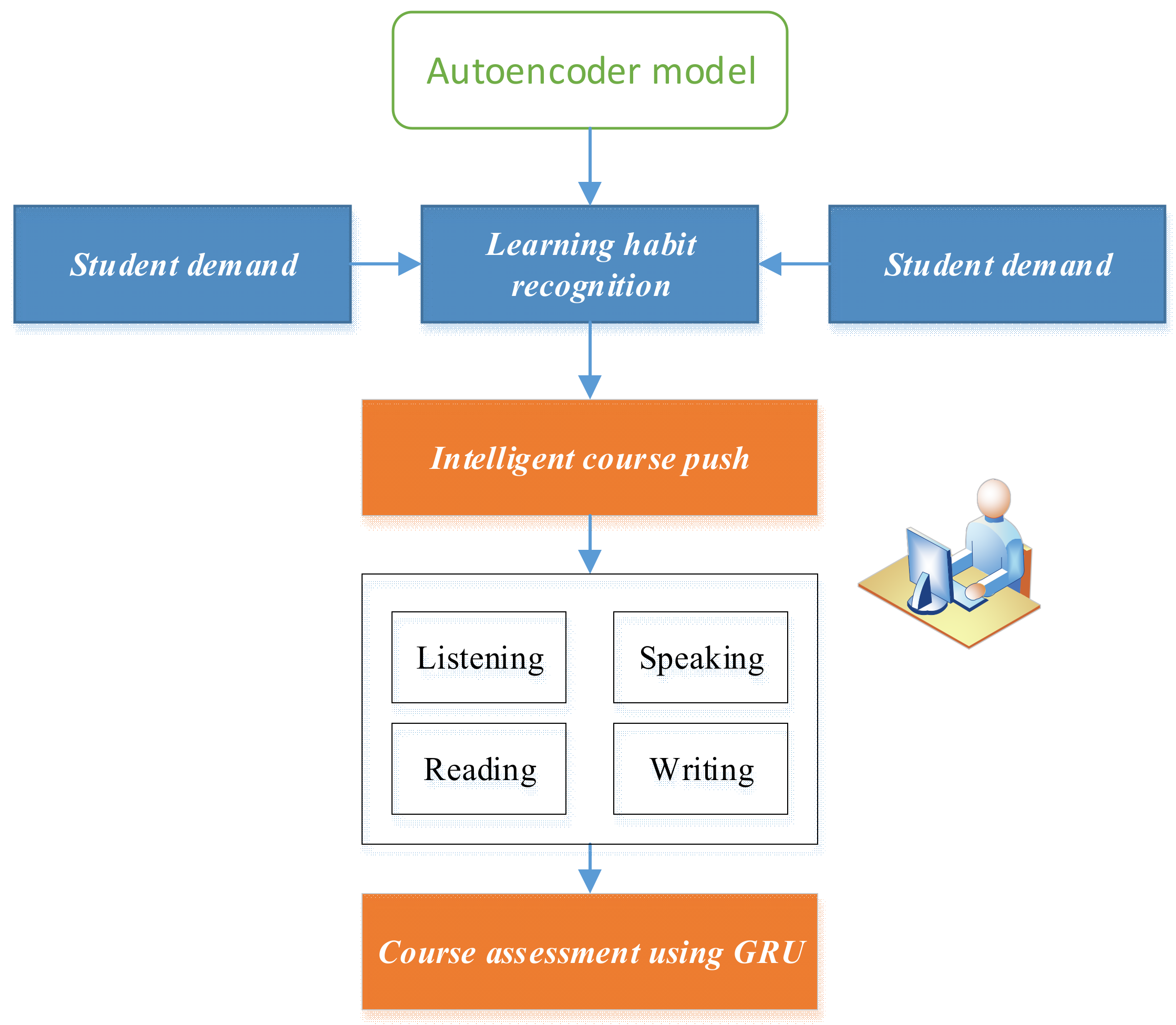
3. Multi-Module Joint Optimization of English Teaching Model Design
3.1. Autoencoder-Based Course Recommendation Model Design
| Algorithm 1 The course push using autoencoder model |
| Step 1: Input user learning data xt = {x1, x2, x3, x4}, where xi represents the learning, speaking, reading and writing data. |
| Step 2: Obtaining h that is the intrest prediction of the model |
| Step 3: Model training using MSE the interest vector Equation (2) to minimize the loss function θ |
| Step 4: Input the feature data of the learning user in sequence to obtain the user’s interest classification; |
| Step 5: Obtaining the rating of user n’s interest in the course, sort it, and obtain a recommendation list for user n. |
3.2. Intelligent Assessment Model Integrating Multi-Module Course Information
4. Experiment Result and Analysis
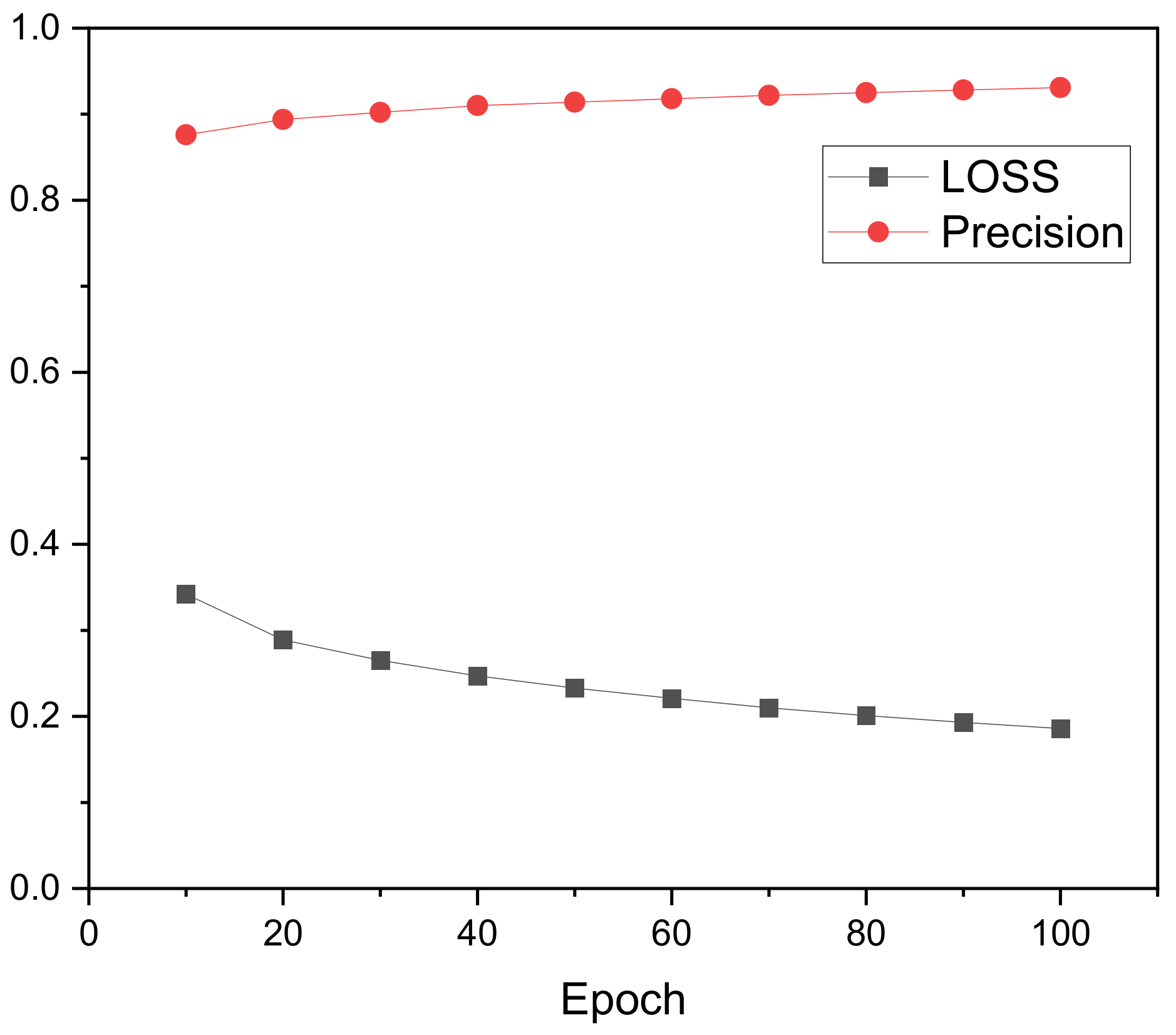
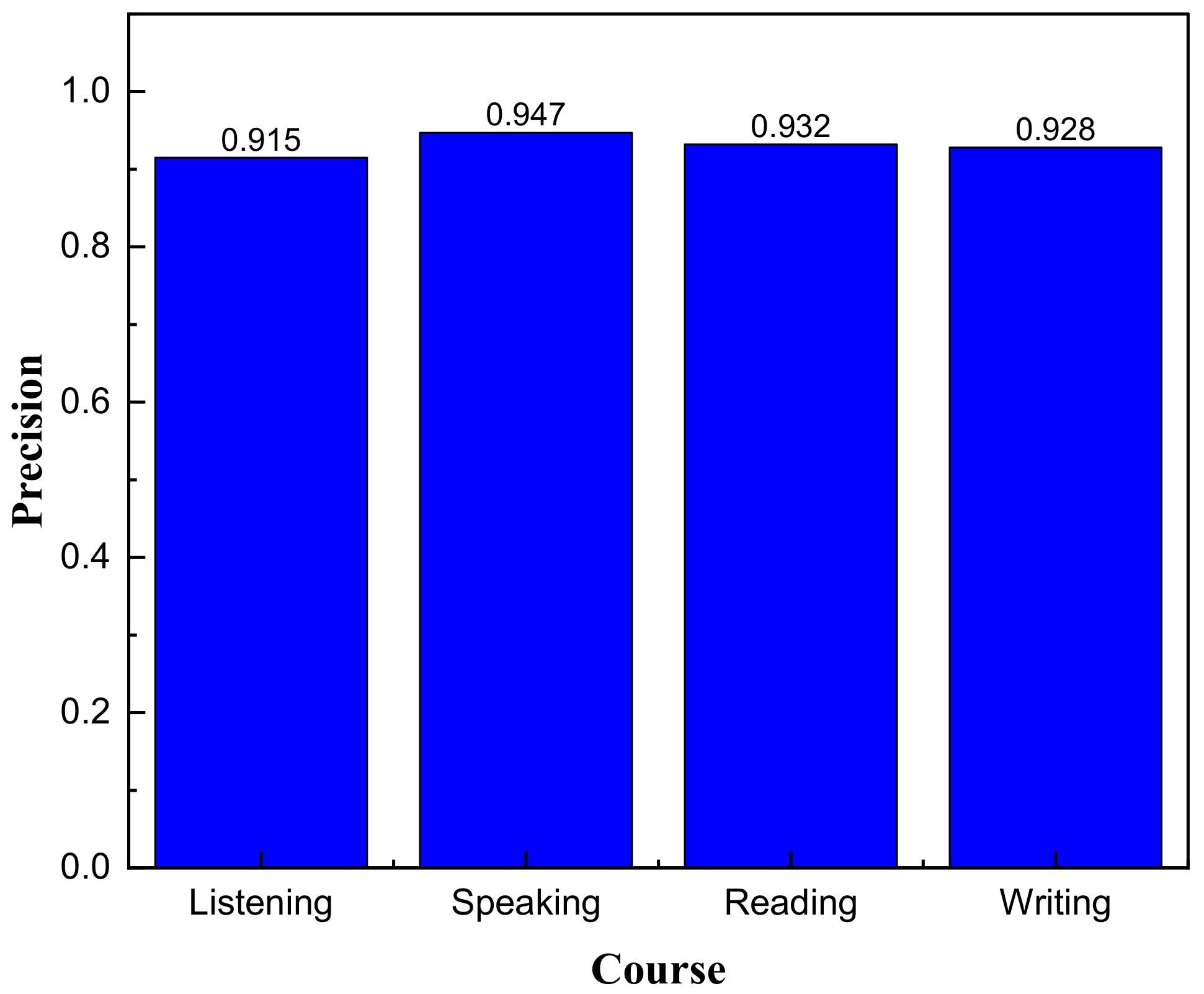
4.1. Student Interest Identification Based on Autoencoder
4.2. GRU-Based Course Evaluation
4.3. Comparison of Multi-Module Learning Evaluation under Different Methods
4.4. System Operation Efficiency Test
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dantas, T.; De-Souza, E.; Destro, I.; Hammes, G.; Rodriguez, C.; Soares, S. How the combination of Circular Economy and Industry 4.0 can contribute towards achieving the Sustainable Development Goals. Sustain. Prod. Consum. 2021, 26, 213–227. [Google Scholar] [CrossRef]
- Silvestre, B.S.; Ţîrcă, D.M. Innovations for sustainable development: Moving toward a sustainable future. J. Clean. Prod. 2019, 208, 325–332. [Google Scholar] [CrossRef]
- Asif, T.; Guangming, O.; Haider, M.A.; Colomer, J.; Kayani, S.; Amin, N. Moral education for sustainable development. Comparison of university teachers’ perceptions in China and Pakistan. Sustainability 2020, 12, 3014. [Google Scholar] [CrossRef]
- Ramalingam, S.; Yunus, M.M.; Hashim, H. Blended learning strategies for sustainable English as a second language education: A systematic review. Sustainability 2022, 14, 8051. [Google Scholar] [CrossRef]
- Sun, Z.; Anbarasan, M.; Praveen Kumar, D. Design of online intelligent English teaching platform based on artificial intelligence techniques. Comput. Intell. 2021, 37, 1166–1180. [Google Scholar] [CrossRef]
- Farzan, R.; Brusilovsky, P. Social Navigation Support in a Course Recommendation System. In Proceedings of the Adaptive Hypermedia and Adaptive Web-Based Systems: 4th International Conference, AH 2006, Dublin, Ireland, 21–23 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 91–100. [Google Scholar]
- Khribi, M.K.; Jemni, M.; Nasraoui, O. Automatic recommendations for e-learning personalization based on web usage mining techniques and information retrieval. J. Educ. Technol. Soc. 2009, 12, 30–42. [Google Scholar]
- Katuk, N.; Ryu, H. Does a Longer Usage Mean Flow Experience? An Evaluation of Learning Experience with Curriculum Sequencing Systems (CSS). In Proceedings of the 2011 Sixth IEEE International Symposium on Electronic Design, Test and Application, Queenstown, New Zealand, 17–19 January 2011; pp. 13–18. [Google Scholar]
- Klašnja-Milićević, A.; Ivanović, M.; Vesin, B.; Budimac, Z. Enhancinge-learning systems with personalized recommendation based on collaborative tagging techniques. Appl. Intell. 2018, 48, 1519–1535. [Google Scholar] [CrossRef]
- Dascalu, M.-I.; Bodea, C.-N.; Moldoveanu, A.; Mohora, A.; Lytras, M.; de Pablos, P.O. A recommender agent based on learning styles for better virtual collaborative learning experiences. Comput. Hum. Behav. 2015, 45, 243–253. [Google Scholar] [CrossRef]
- Yau, J.Y.K.; Joy, M. A context-aware personalised m-learning application based on m-learning preferences. Int. J. Mob. Learn. Organ. 2011, 5, 1–14. [Google Scholar] [CrossRef]
- Mangalathu, S.; Heo, G.; Jeon, J.S. Artificial neural network based multi-dimensional fragility development of skewed concrete bridge classes. Eng. Struct. 2018, 162, 166–176. [Google Scholar] [CrossRef]
- Karbassi, A.; Mohebi, B.; Rezaee, S.; Lestuzzi, P. Damage prediction for regular reinforced concrete buildings using the decision tree algorithm. Comput. Struct. 2014, 130, 46–56. [Google Scholar] [CrossRef]
- Sainct, R.; Feau, C.; Martinez, J.M.; Garnier, J. Efficient methodology for seismic fragility curves estimation by active learning on Support Vector Machines. Struct. Saf. 2020, 86, 101972. [Google Scholar] [CrossRef]
- Skorupski, J. The Simulation-fuzzy Method of Assessing the Risk of Air Traffic Accidents Using the Fuzzy Risk Matrix. Saf. Sci. 2016, 88, 76–87. [Google Scholar] [CrossRef]
- Johnson, B.; Chalishazar, V.; Cotilla-sanchez, E.; Brekken, T. A Monte Carlo Carlo Methodology for Earthquake Impact Analysis on the Electrical Grid. Electr. Power Syst. Res. 2020, 184, 106332. [Google Scholar] [CrossRef]
- Piadeh, F.; Ahmadi, M.; Behzadian, K. Reliability Assessment for Hybrid Systems of Advanced Treatment Units of Industrial Wastewater Reuse Using Combined Event Tree and Fuzzy Fault Tree Analyses. J. Clean. Prod. 2018, 201, 958–973. [Google Scholar] [CrossRef]
- Roy, A.; Saffar, M.; Vaswani, A.; Grangier, D. Efficient content-based sparse attention with routing transformers. Trans. Assoc. Comput. Linguist. 2021, 9, 53–68. [Google Scholar] [CrossRef]
- Qin, C.J.; Wu, R.H.; Huang, G.Q.; Tao, J.F.; Liu, C.L. A novel LSTM-autoencoder and enhanced transformer-based detection method for shield machine cutterhead clogging. Sci. China Technol. Sci. 2023, 66, 512–527. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, Y.; Jin, X. A survey of autoencoder-based recommender systems. Front. Comput. Sci. 2020, 14, 430–450. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, B.; Luo, W.; Chen, F. Autoencoder-based representation learning and its application in intelligent fault diagnosis: A review. Measurement 2022, 189, 110460. [Google Scholar] [CrossRef]
- Huang, W.; Niu, T.; Zhang, C.; Fu, Z.; Zhang, Y.; Zhou, W.; Pan, Z.; Zhang, K. Experimental study of the performance degradation of proton exchange membrane fuel cell based on a multi-module stack under selected load profiles by clustering algorithm. Energy 2023, 270, 126937. [Google Scholar] [CrossRef]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X.; et al. A comparative study on transformer vs. rnn in speech applications. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Shi, X.; Wang, Z.; Zhao, H.; Qiu, S.; Liu, R.; Lin, F.; Tang, K. Threshold-Free Phase Segmentation and Zero Velocity Detection for Gait Analysis Using Foot-Mounted Inertial Sensors. IEEE Trans. Human-Machine Syst. 2022, 53, 176–186. [Google Scholar] [CrossRef]
- Swacha, J.; Maskeliūnas, R.; Damaševičius, R.; Kulikajevas, A.; Blažauskas, T.; Muszyńska, K.; Miluniec, A.; Kowalska, M. Introducing sustainable development topics into computer science education: Design and evaluation of the Eco JSity game. Sustainability 2021, 13, 4244. [Google Scholar] [CrossRef]
- Maskeliūnas, R.; Kulikajevas, A.; Blažauskas, T.; Damaševičius, R.; Swacha, J. An interactive serious mobile game for supporting the learning of programming in javascript in the context of eco-friendly city management. Computers 2020, 9, 102. [Google Scholar] [CrossRef]
- Hess, G.; Jaxing, J.; Svensson, E.; Hagerman, D.; Petersson, C.; Svensson, L. Masked Autoencoder for Self-Supervised Pre-Training on Lidar Point Clouds. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 2–7 January 2023; pp. 350–359. [Google Scholar]
- Gupta, B.B.; Gaurav, A.; Panigrahi, P.K.; Arya, V. Analysis of artificial intelligence-based technologies and approaches on sustainable entrepreneurship. Technol. Forecast. Soc. Change 2023, 186, 122152. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, S.; Yang, X.; Alatas, B. A Multi-Module Information-Optimized Approach to English Language Teaching and Development in the Context of Smart Sustainability. Sustainability 2023, 15, 14977. https://0-doi-org.brum.beds.ac.uk/10.3390/su152014977
Gan S, Yang X, Alatas B. A Multi-Module Information-Optimized Approach to English Language Teaching and Development in the Context of Smart Sustainability. Sustainability. 2023; 15(20):14977. https://0-doi-org.brum.beds.ac.uk/10.3390/su152014977
Chicago/Turabian StyleGan, Shiyuan, Xuejing Yang, and Bilal Alatas. 2023. "A Multi-Module Information-Optimized Approach to English Language Teaching and Development in the Context of Smart Sustainability" Sustainability 15, no. 20: 14977. https://0-doi-org.brum.beds.ac.uk/10.3390/su152014977