
IC Packaging Material Identification via a Hybrid Deep Learning Framework with CNN–Transformer Bidirectional Interaction

Abstract
:1. Introduction
2. Methodology
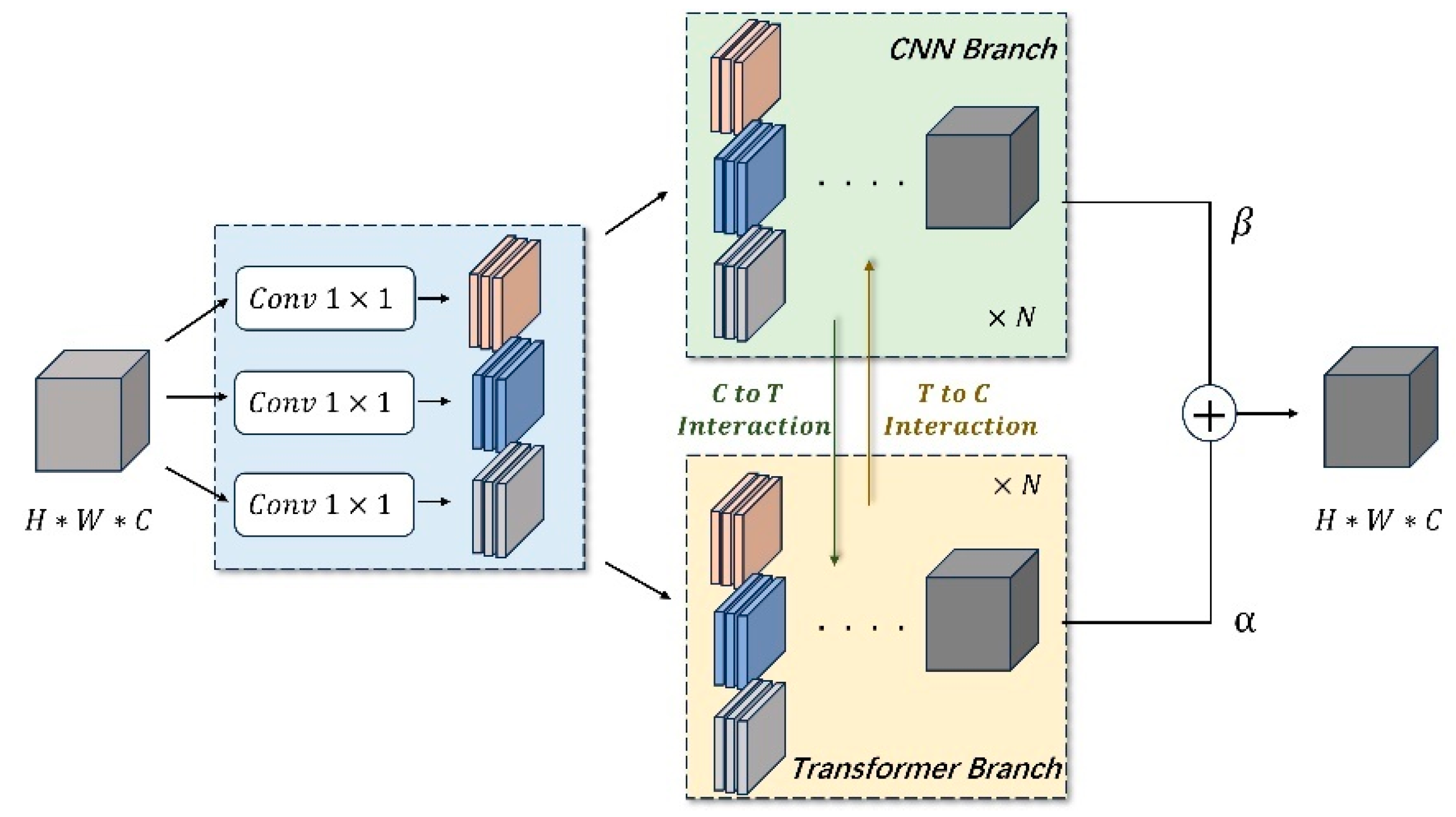
2.1. Architecture of the Proposed Framework
2.2. CTI Block
2.2.1. Transformer Branch
2.2.2. CNN Branch
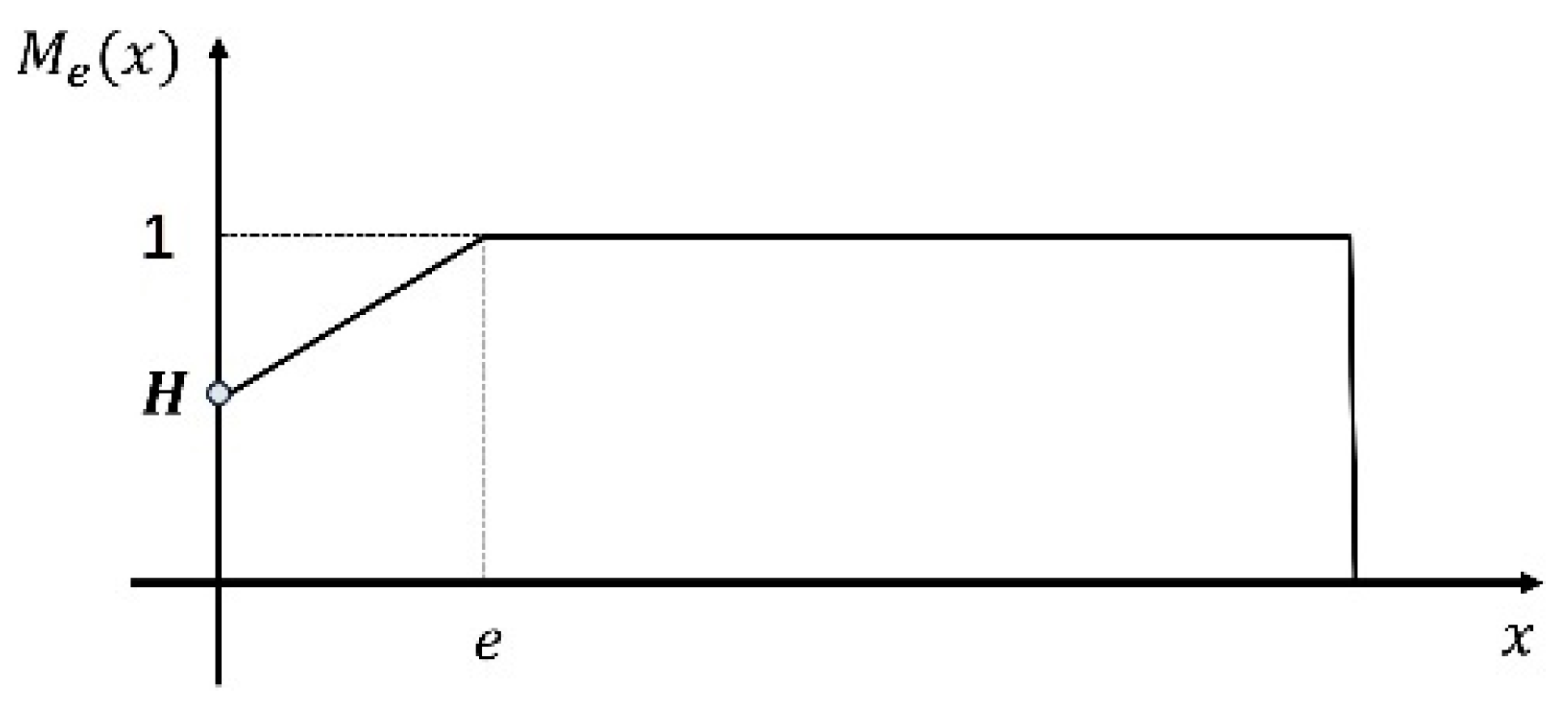
2.2.3. Bidirectional Interaction
3. Experiments and Discussion
3.1. Dataset and Experimental Environments
3.2. Comparisons with Other Deep Learning Models
3.3. Ablation Experiment
3.4. Application for the Other Classification Task
3.5. Repeated Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wong-Ng, W. Ceramic materials. Int. Tables Crystallogr. 2019, H, 804–827. [Google Scholar]
- Morikawa, Y. Challenges of Semiconductor Microfabrication Technology for 3D Chiplet Integration. In Proceedings of the 2023 IEEE CPMT Symposium Japan (ICSJ), Kyoto, Japan, 15–17 November 2023; pp. 149–151. [Google Scholar]
- Hu, X.; Xu, J.; Wu, J. A novel electronic component classification algorithm based on hierarchical convolution neural network. IOP Conf. Ser. Earth Environ. Sci. 2020, 474, 052081. [Google Scholar] [CrossRef]
- Cai, N.; Cen, G.; Wu, J.; Li, F.; Wang, H.; Chen, X. SMT solder joint inspection via a novel cascaded convolutional neural network. IEEE Trans. Compon. Packag. Manuf. Technol. 2018, 8, 670–677. [Google Scholar] [CrossRef]
- Guo, C.; Lv, X.L.; Zhang, Y.; Zhang, M.L. Improved YOLOv4-tiny network for real-time electronic component detection. Sci. Rep. 2021, 11, 22744. [Google Scholar] [CrossRef] [PubMed]
- Ram, G.C.; Subbarao, M.V.; Varma, D.R.; Krishna, A.S. Enhanced Deep Convolutional Neural Network for Identifying and Classification of Silicon Wafer Faults in IC Fabrication Industries. In Proceedings of the 2023 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 29–31 May 2023; pp. 1–6. [Google Scholar]
- An, K.; Zhang, Y. LPViT: A transformer based model for PCB image classification and defect detection. IEEE Access 2022, 10, 42542–42553. [Google Scholar] [CrossRef]
- Kao, S.-X.; Chien, C.-F. Deep Learning-Based Positioning Error Fault Diagnosis of Wire Bonding Equipment and an Empirical Study for IC Packaging. IEEE Trans. Semicond. Manuf. 2023, 36, 619–628. [Google Scholar] [CrossRef]
- Feng, B.; Cai, J. PCB Defect Detection via Local Detail and Global Dependency Information. Sensors 2023, 23, 7755. [Google Scholar] [CrossRef]
- Chen, W.; Huang, Z.; Mu, Q.; Sun, Y. PCB Defect Detection Method Based on Transformer-YOLO. IEEE Access 2022, 10, 129480–129489. [Google Scholar] [CrossRef]
- Khan, R.A.; Muhaisin, M.M.; Roberts, G.W. An in-situ technique for measuring the individual contact resistance between the pins of an IC package and the board of a flexible hybrid electronic system. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar]
- Guin, U.; Huang, K.; DiMase, D.; Carulli, J.M.; Tehranipoor, M.; Makris, Y. Counterfeit integrated circuits: A rising threat in the global semiconductor supply chain. Proc. IEEE 2014, 102, 1207–1228. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural Inf. Process. Syst. 2021, 34, 3965–3977. [Google Scholar]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the integration of self-attention and convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 815–825. [Google Scholar]
- Sukhbaatar, S.; Grave, E.; Bojanowski, P.; Joulin, A. Adaptive attention span in transformers. arXiv 2019, arXiv:1905.07799. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12894–12904. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the inherence of convolution for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12321–12330. [Google Scholar]
- Yu, D.; Wang, H.; Chen, P.; Wei, Z. Mixed pooling for convolutional neural networks. In Proceedings of the Rough Sets and Knowledge Technology: 9th International Conference (RSKT 2014), Shanghai, China, 24–26 October 2014; Proceedings 9. Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 364–375. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Chen, Q.; Wu, Q.; Wang, J.; Hu, Q.; Hu, T.; Ding, E.; Cheng, J.; Wang, J. Mixformer: Mixing features across windows and dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5249–5259. [Google Scholar]
- Lin, W.; Wu, Z.; Chen, J.; Huang, J.; Jin, L. Scale-aware modulation meet transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6015–6026. [Google Scholar]
- Vasu, P.K.A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization. arXiv 2023, arXiv:2303.14189. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tian, Y.; Xie, L.; Wang, Z.; Wei, L.; Zhang, X.; Jiao, J.; Wang, Y.; Tian, Q.; Ye, Q. Integrally Pre-Trained Transformer Pyramid Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18610–18620. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Fan, Q.; Huang, H.; Guan, J.; He, R. Rethinking Local Perception in Lightweight Vision Transformer. arXiv 2023, arXiv:2303.17803. [Google Scholar]
- Website Findchips. Available online: https://www.findchips.com (accessed on 25 February 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Plastic | Ceramic | Metallic | Total |
|---|---|---|---|---|
| Training | 911 | 951 | 963 | 2835 |
| Validation | 455 | 475 | 481 | 1401 |
| Test | 209 | 149 | 131 | 489 |
| Total | 1575 | 1575 | 1575 | 4725 |
| Method | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) | FPS | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|---|
| ITPN [29] | 76.45 | 47.04 | 37.27 | 40.90 | 1.02 | 29 | 59 |
| Swin-Transformer_l [28] | 82.82 | 84.42 | 82.13 | 82.21 | 1.36 | 39 | 34 |
| LPViT [7] | 74.34 | 66.81 | 66.54 | 73.57 | 1.12 | 28 | 41 |
| ResNet_152 [27] | 83.84 | 80.70 | 78.48 | 79.35 | 2.54 | 32 | 12 |
| FasterNet [26] | 74.34 | 86.81 | 80.09 | 83.57 | 1.41 | 25 | 4.4 |
| ConvNeXt_S [25] | 84.53 | 83.49 | 81.48 | 81.56 | 1.53 | 35 | 61 |
| Wafer classification [6] | 64.16 | 59.34 | 54.24 | 59.22 | 3.31 | 10 | 18 |
| SMT [23] | 84.18 | 83.83 | 81.27 | 81.18 | 1.76 | 30 | 41 |
| FastVit_V3 [24] | 79.70 | 68.02 | 62.71 | 61.76 | 2.28 | 22 | 27 |
| CoAtNet_4 [14] | 75.51 | 74.45 | 70.98 | 71.78 | 1.59 | 38 | 55 |
| ACmix [15] | 89.75 | 83.12 | 86.39 | 88.39 | 1.62 | 29 | 4.5 |
| MixFormer [22] | 91.19 | 86.09 | 88.34 | 90.67 | 1.47 | 56 | 9.6 |
| Ours | 96.12 | 96.26 | 96.16 | 97.92 | 1.99 | 44 | 23 |
| Transformer Branch | CNN Branch | C-to-T Interaction | T-to-C Interaction | Weighted Summarization | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| ✓ | 73.99 | 79.40 | ||||
| ✓ | 78.39 | 81.39 | ||||
| ✓ | ✓ | 79.35 | 81.56 | |||
| ✓ | ✓ | ✓ | 86.69 | 90.39 | ||
| ✓ | ✓ | ✓ | 79.83 | 87.56 | ||
| ✓ | ✓ | ✓ | ✓ | 93.19 | 94.08 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 96.16 | 97.92 |
| Method | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Ours-1 | 90.85 | 76.83 | 83.25 | 87.61 |
| Index | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| 1 | 95.94 | 95.98 | 95.99 | 96.55 |
| 2 | 94.15 | 95.88 | 94.99 | 96.41 |
| 3 | 94.95 | 95.78 | 95.38 | 96.58 |
| 4 | 95.35 | 94.97 | 95.18 | 96.66 |
| 5 | 93.79 | 94.83 | 94.43 | 95.97 |
| 6 | 95.41 | 95.79 | 95.58 | 95.31 |
| 7 | 96.12 | 96.26 | 96.16 | 97.92 |
| 8 | 94.99 | 95.52 | 95.39 | 96.96 |
| 9 | 91.96 | 91.44 | 91.98 | 94.96 |
| 10 | 95.74 | 95.85 | 95.81 | 97.89 |
| Average | 94.84 | 95.23 | 94.93 | 96.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Zhou, X.; Cai, N.; Zhou, S.; Wang, H. IC Packaging Material Identification via a Hybrid Deep Learning Framework with CNN–Transformer Bidirectional Interaction. Micromachines 2024, 15, 418. https://0-doi-org.brum.beds.ac.uk/10.3390/mi15030418
Zhang C, Zhou X, Cai N, Zhou S, Wang H. IC Packaging Material Identification via a Hybrid Deep Learning Framework with CNN–Transformer Bidirectional Interaction. Micromachines. 2024; 15(3):418. https://0-doi-org.brum.beds.ac.uk/10.3390/mi15030418
Chicago/Turabian StyleZhang, Chengbin, Xuankai Zhou, Nian Cai, Shuai Zhou, and Han Wang. 2024. "IC Packaging Material Identification via a Hybrid Deep Learning Framework with CNN–Transformer Bidirectional Interaction" Micromachines 15, no. 3: 418. https://0-doi-org.brum.beds.ac.uk/10.3390/mi15030418