
On Predicting Soccer Outcomes in the Greek League Using Machine Learning




Abstract
:1. Introduction
- This is the first time a case study is focusing on data referring to the Greek Super League, which is considered as one of the most predictable leagues in terms of final match results and league standings. There have been studies that included the Greek league in a wider dataset of several leagues, but none of them focused solely on it.
- The most important features that affect the final results of the Greek Super League and the ones that do not contribute to the final outcome were identified. Findings were applied to two other leagues, the English Premier League and the Dutch Eredivisie, to investigate their impact. This work includes extensive experiments using data from different leagues with different dynamics in terms of predictability. The results are compared to verify initial assumptions regarding the predictability of each league, export their main differences and evaluate their contribution to the final outcome.
- Deep neural networks with transfer learning were also applied to test their prediction ability and compare it with the proposed machine learning models.
2. Related Work
3. Materials and Methods
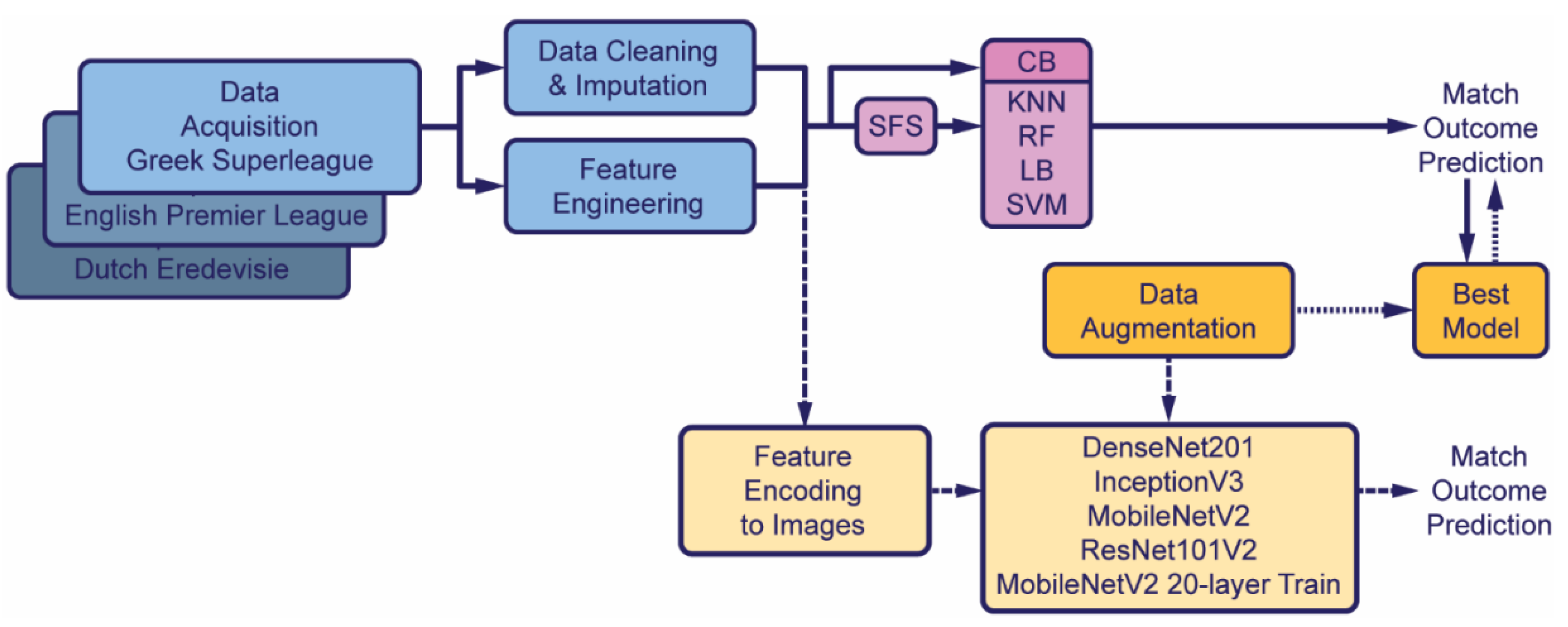
3.1. The Proposed Method
3.2. Data Acquisition
3.3. Data Cleaning and Imputation
3.4. Feature Engineering
3.5. Feature Selection
3.6. Models
- k-Nearest Neighbor (k-NN): A non-parametric model that classifies data points in two or more distinguished classes by using majority voting or a distance/frequency-based weighting scheme for the k nearest points.
- LogitBoost (L-Boost): A boosting algorithm that can be derived by applying to the Adaboost generalized additive model the cost function of logistic regression.
- Support Vector Machine (SVM): It constructs a hyperplane, in an n-dimensional space, with the purpose of distinctively classifying data points. The objective is to find the hyperplane which has the maximum distance between the data points of the two classes.
- Random Forest (RF): Multiple decision trees are trained to make a prediction. Each tree’s prediction is taken into account for the final prediction, which can be derived from the mode of the output class. Random decision forests correct the tendency of decision trees to overfit the training set.
- CatBoost (CB): An ordered gradient boosting on decision trees algorithm [32]. It also has some algorithm advancements in regard to categorical classification and is computationally less intensive than other gradient boosting on decision trees algorithms. CatBoost has a very good vector representation of categorical data. It takes concepts of ordered boosting and applies the same to response coding. In response coding, we represent categorical features using the mean to the target values of the data points.
3.7. Data Augmentation
3.8. Model Evaluation
- Inaccurate/imbalanced/noisy data. The model learns on the data, and when new unseen data are introduced, the accuracy of the model decreases, and variance increases.
- Small training data. In general, the more the data, the better the learning. Small datasets result in low learning ability of the model.
- Complex models. When the predictive function of a model is complex, the model tends to overfit the data.
- Data cleaning to remove outliers.
- Imputation to handle missing values.
- Data augmentation to increase training samples and deal with the imbalanced data.
- Hyperparameter tuning so as to limit model complexity such as the depth, etc. In general, many regularization methods exist in order to prevent machine learning model overfitting [34].
4. Data Analysis
5. Experimental Results
5.1. Initial Experiments
5.2. Further Experiments
5.3. Comparison with Other Leagues
5.4. Training Experimentation
5.5. CNNs and Transfer Learning
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Grand View Research (GVR). Sports Betting Market Size, Share & Trends Analysis by Platform, by Type, by Sports Type (Football, Basketball, Baseball, Horse Racing, Cricket, Hockey, Others), by Region, and Segment Forecasts, 2022–2030. Available online: https://www.grandviewresearch.com/industry-analysis/sports-betting-market-report (accessed on 10 July 2022).
- Rue, H.; Salvesen, O. Prediction and Retrospective Analysis of Soccer Matches in a League. J. R. Stat. Soc. Ser. 2000, 49, 399–418. [Google Scholar] [CrossRef]
- Berrar, D.; Lopes, P.; Dubitzky, W. Incorporating domain knowledge in machine learning for soccer outcome prediction. Mach. Learn. 2019, 108, 97–126. [Google Scholar] [CrossRef]
- Hill, I.D. Association Football and Statistical Inference. Appl. Stat. 1974, 23, 203. [Google Scholar] [CrossRef]
- Reep, C.; Benjamin, B. Skill and Chance in Association Football. J. R. Stat. Soc. Ser. 1968, 131, 581. [Google Scholar] [CrossRef]
- Singh, N. Sport Analytics: A Review. Int. Technol. Manag. Rev. 2020, 9, 64. [Google Scholar] [CrossRef]
- Fernández, J.; Bornn, L. SoccerMap: A Deep Learning Architecture for Visually-Interpretable Analysis in Soccer. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2021; pp. 491–506. ISBN 9783030676698. [Google Scholar]
- Gudmundsson, J.; Horton, M. Spatio-Temporal Analysis of Team Sports. ACM Comput. Surv. 2018, 50, 1–34. [Google Scholar] [CrossRef]
- Maher, M.J. Modelling association football scores. Stat. Neerl. 1982, 36, 109–118. [Google Scholar] [CrossRef]
- Dixon, M.J.; Coles, S.G. Modelling Association Football Scores and Inefficiencies in the Football Betting Market. J. R. Stat. Soc. Ser. Appl. Stat. 1997, 46, 265–280. [Google Scholar] [CrossRef]
- Angelini, G.; De Angelis, L. PARX model for football match predictions. J. Forecast. 2017, 36, 795–807. [Google Scholar] [CrossRef]
- Rahman, M.A. A deep learning framework for football match prediction. SN Appl. Sci. 2020, 2, 165. [Google Scholar] [CrossRef] [Green Version]
- Karlis, D.; Ntzoufras, I. Analysis of sports data by using bivariate Poisson models. J. R. Stat. Soc. Ser. 2003, 52, 381–393. [Google Scholar] [CrossRef]
- Hvattum, L.M.; Arntzen, H. Using ELO ratings for match result prediction in association football. Int. J. Forecast. 2010, 26, 460–470. [Google Scholar] [CrossRef]
- Huang, K.-Y.; Chang, W.-L. A neural network method for prediction of 2006 World Cup Football Game. In Proceedings of the The 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; IEEE: New York, NY, USA, 2010; pp. 1–8. [Google Scholar]
- Jain, S.; Tiwari, E.; Sardar, P. Soccer Result Prediction Using Deep Learning and Neural Networks. In Lecture Notes on Data Engineering and Communications Technologies; Springer: Singapore, 2021; pp. 697–707. [Google Scholar]
- Mustafa Zebari, G.; Zeebaree, S.; Sadeeq, M.M.; Zebari, R. Predicting Football Outcomes by Using Poisson Model: Applied to Spanish Primera División. J. Appl. Sci. Technol. Trends 2021, 2, 105–112. [Google Scholar] [CrossRef]
- Goddard, J.; Asimakopoulos, I. Forecasting football results and the efficiency of fixed-odds betting. J. Forecast. 2004, 23, 51–66. [Google Scholar] [CrossRef]
- Joseph, A.; Fenton, N.E.; Neil, M. Predicting football results using Bayesian nets and other machine learning techniques. Knowl.-Based Syst. 2006, 19, 544–553. [Google Scholar] [CrossRef]
- Baio, G.; Blangiardo, M. Bayesian hierarchical model for the prediction of football results. J. Appl. Stat. 2010, 37, 253–264. [Google Scholar] [CrossRef]
- Constantinou, A.C. Dolores: A model that predicts football match outcomes from all over the world. Mach. Learn. 2019, 108, 49–75. [Google Scholar] [CrossRef]
- Tsakonas, A.; Dounias, G.; Shtovba, S.; Vivdyuk, V. Soft computing-based result prediction of football games. In Proceedings of the First International Conference on Inductive Modelling (ICIM’2002), Lviv, Ukraine, 20–25 May 2002; pp. 1–8. [Google Scholar]
- Rotshtein, A.P.; Posner, M.; Rakityanskaya, A.B. Football Predictions Based on a Fuzzy Model with Genetic and Neural Tuning. Cybern. Syst. Anal. 2005, 41, 619–630. [Google Scholar] [CrossRef]
- Arabzad, S.M.; Tayebi Araghi, M.E.; Sadi-Nezhad, S.; Ghofrani, N.; Araghi, M.E.T.; Sadi-Nezhad, S.; Ghofrani, N. Football Match Results Prediction Using Artificial Neural Networks, The Case of Iran Pro League. Int. J. Appl. Res. Ind. Eng. 2014, 1, 159–179. [Google Scholar]
- Tax, N.; Joustra, Y. Predicting The Dutch Football Competition Using Public Data: A Machine Learning Approach. Trans. Knowl. Data Eng. 2015, 10, 1–13. [Google Scholar]
- Hubáček, O.; Šourek, G.; Železný, F. Learning to predict soccer results from relational data with gradient boosted trees. Mach. Learn. 2019, 108, 29–47. [Google Scholar] [CrossRef]
- Football-Data Football-Data.co.uk. Available online: https://www.football-data.co.uk/ (accessed on 10 July 2022).
- Transfermarkt Transfer Markt. Available online: https://www.transfermarkt.de/ (accessed on 10 July 2022).
- SUPER LEAGUE Super League Greece. Available online: https://www.slgr.gr/en/ (accessed on 10 July 2022).
- Emmanuel, T.; Maupong, T.; Mpoeleng, D.; Semong, T.; Mphago, B.; Tabona, O. A survey on missing data in machine learning. J. Big Data 2021, 8, 140. [Google Scholar] [CrossRef] [PubMed]
- Jamshidian, M.; Mata, M. Advances in Analysis of Mean and Covariance Structure when Data are Incomplete. In Handbook of Latent Variable and Related Models; Elsevier: Amsterdam, The Netherlands, 2007; pp. 21–44. ISBN 9780444520449. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- dos Santos, C.F.G.; Papa, J.P. Avoiding Overfitting: A Survey on Regularization Methods for Convolutional Neural Networks. ACM Comput. Surv. 2022, 3510413. [Google Scholar] [CrossRef]
- Milosevic, N. Introduction to Convolutional Neural Networks; Apress: Berkeley, CA, USA, 2020; ISBN 978-1-4842-5648-0. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | League | Model | Result | Metric | Features |
|---|---|---|---|---|---|
| [14] | Four divisions of English league system (Premiership, Championship, League One, League Two), 93/94 to 07/08 | Ordered logit regression models | 1.491 | Informational Loss (L) | ELO ratings, team performance parameters, betting odds, past match results |
| [13] | Italian series A, 1991–1992, and Champions League, 2000–2001 | Bivariate Poisson regression model | 0.85 | p-value | Number of games, goals scored by Home and Away team, offensive and defensive performance, Home effect parameter |
| [2] | Premier League and Division 1 matches, 1993–1997 | Bayesian dynamic generalized linear model | 0.357—Premier League 0.372—Division 1 | Normalized Pseudo-likelihood | Match results, attacking and defending parameters, goals scored, time variations |
| [18] | Ten seasons of first four divisions in English Football (Premier League, Division 1, Division 2, Division 3) | Ordered Probit regression | 0.365 | Normalized Pseudo-likelihood | Team quality indicators, recent performance indicators, status variable (whether team able to be promoted, relegated or win the Championship), elimination parameter, geographical distance coefficient |
| [19] | Premier League (only Tottenham Hotspur matches), 1995–1997 | Expert constructed Bayesian network | 59.21% | Accuracy | Attack parameter, overall quality of team, quality of opposing team, performance indicator (depending on team quality and quality of the opposition), presence/absence of players, venue, playing positions |
| [22] | 10 seasons of the Ukrainian Championship | Genetic programming model | 76% | Accuracy | Number of traumatized and disqualified players of host team and Away Team, difference of dynamics profile, difference of ranks, host factor, personal score (goal difference for all the games of the teams involved) |
| [23] | 1056 matches of the Finland Championship, 1994–2001 | Fuzzy model with neural optimization techniques | 86% | Accuracy | Difference of goals scored and goals conceded |
| [15] | 2006 World Cup Stage Matches | Multi-layer perceptron with back-propagation | 76.90% excluding draw results (3 matches out of 16) | Accuracy | Goals, shots, shots on goal, corner kicks, direct free kicks to goal, indirect free kicks to goal, ball possession, fouls suffered |
| [24] | 2068 matches Iranian Premier League | Artificial neural network | 62.5% | Accuracy | Teams, team form, average of obtained points in the league, quality of opponents in last matches, week of match, match result |
| [25] | Dutch Eredivisie League, 2007–2013 | Hybrid model of LogitBoost and ReliefF | 56.05% | Accuracy | Teams, average goals scored/conceded, previous 5 matches results, several statistics about players teams and earlier encounters, odds from several bookers and Asian handicaps |
| [26] | 200,000 matches from 52 leagues around the world (2017 Soccer Prediction Challenge) | Gradient boosting decision trees | 0.2063 | RPS | Historical strength, current form, pi-ratings, page rank, match importance, league |
| [3] | 200,000 matches from 52 leagues around the world (2017 Soccer Prediction Challenge) | Extreme gradient boosting decision trees (XGBoost) | 0.2023 | RPS | Attacking strength, defensive strength, Home advantage feature group, strength of opposition, attacking weakness, defensive weakness, recent performance |
| [21] | 200,000 matches from 52 leagues around the world (2017 Soccer Prediction Challenge) | Hybrid Bayesian networks | 0.2082 | RPS | Case (which team is favorite), league, match date, teams, team ratings, rating difference |
| k-NN. | RF | LB | SVM | CB |
|---|---|---|---|---|
| Home Team form (E) | Home Team form (E) | Home Team form (E) | Previous half match goals (E) | Home Team form (E) |
| Previous half match goals for Home Team (E) | Previous half match goals both for Home Team (E) | Away Team form (E) | Previous match goals Away (E) | Away Team form (E) |
| Max Away Team odds (1) | Previous half match goals both for Away Team (E) | Previous half match goals both for Away Team (E) | Asian handicap line (1) | Home Team (1) |
| Average Home Team odds (1) | League points the Home Team has gathered (E) | Max Home odds for the corresponding Asian handicap line (1) | Away Team (1) | |
| Asian handicap line (1) | Asian handicap line (1) | |||
| Average Home odds for the corresponding Asian handicap line (1) | Average Home odds for the corresponding Asian handicap line (1) | |||
| Max Home Team odds (1) | ||||
| Average Draw odds (1) |
| Model | Accuracy | Precision | Recall | F1-Score | AUC |
|---|---|---|---|---|---|
| k-NN | 50.13% | 0.4665 | 0.4664 | 0.4664 | 0.5998 |
| RF | 56.38% | 0.5116 | 0.4975 | 0.4925 | 0.6974 |
| LB | 55.65% | 0.5106 | 0.4962 | 0.4962 | 0.6913 |
| CB | 56.59% | 0.5123 | 0.4947 | 0.4774 | 0.7361 |
| SVM | 54.07% | 0.4258 | 0.4414 | 0.3876 | 0.5474 |
| Metric. | Value | Metric | Value |
|---|---|---|---|
| Home precision | 0.5978 | Home F1-score | 0.6944 |
| Draw precision | 0.3653 | Draw F1-score | 0.2018 |
| Away precision | 0.5738 | Away F1-score | 0.5361 |
| Home recall | 0.8308 | AUC | 0.7361 |
| Draw recall | 0.1426 | Accuracy | 56.59% |
| Away recall | 0.5107 |
| Method | Accuracy | Home Precision | Draw Precision | Away Precision | Home Recall | Draw Recall | Away Recall | Home F1-Score | Draw F1-Score | Away F1-Score | AUC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | 56.59% | 0.5978 | 0.3653 | 0.5738 | 0.8308 | 0.1426 | 0.5107 | 0.6944 | 0.2018 | 0.5361 | 0.7361 |
| Tuned | 56.26% | 0.6139 | 0.3241 | 0.5549 | 0.8414 | 0.1377 | 0.4820 | 0.7092 | 0.1885 | 0.5094 | 0.7231 |
| SMOTE | 66.76% | 0.6452 | 0.6366 | 0.7317 | 0.6579 | 0.6370 | 0.7078 | 0.6492 | 0.6360 | 0.7180 | 0.8534 |
| SMOTE and scaled | 66.80% | 0.6489 | 0.6272 | 0.7360 | 0.6454 | 0.6342 | 0.7245 | 0.6458 | 0.6300 | 0.7284 | 0.8603 |
| SMOTE, scaled and tuned | 67.73% | 0.6750 | 0.6432 | 0.7226 | 0.6496 | 0.6815 | 0.7008 | 0.6608 | 0.6607 | 0.7099 | 0.8572 |
| SMOTE and tuned | 67.31% | 0.6727 | 0.6434 | 0.7108 | 0.6246 | 0.6786 | 0.7162 | 0.6464 | 0.6600 | 0.7120 | 0.8571 |
| Without low importance | 65.97% | 0.6535 | 0.6196 | 0.7131 | 0.6024 | 0.6384 | 0.7384 | 0.6248 | 0.6280 | 0.7237 | 0.8448 |
| Method | Accuracy | Home Precision | Draw Precision | Away Precision | Home Recall | Draw Recall | Away Recall | Home F1-Score | Draw F1-Score | Away F1-Score | AUC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | 54.65% | 0.5505 | 0.6167 | 0.5469 | 0.8378 | 0.0055 | 0.5389 | 0.6640 | 0.1050 | 0.5415 | 0.6954 |
| Tuned | 54.65% | 0.5550 | 0.5087 | 0.5404 | 0.8195 | 0.0256 | 0.5463 | 0.6612 | 0.4630 | 0.5407 | 0.6999 |
| SMOTE | 59.28% | 0.5822 | 0.5775 | 0.6216 | 0.6017 | 0.5662 | 0.6104 | 0.5911 | 0.5711 | 0.6151 | 0.7981 |
| SMOTE and scaled | 59.24% | 0.5764 | 0.5833 | 0.6247 | 0.6046 | 0.5739 | 0.5988 | 0.5888 | 0.5777 | 0.6102 | 0.7968 |
| SMOTE, scaled and tuned | 61.42% | 0.5930 | 0.6161 | 0.6363 | 0.6007 | 0.5959 | 0.6459 | 0.5961 | 0.6051 | 0.6401 | 0.8056 |
| SMOTE and tuned | 61.03% | 0.5957 | 0.5899 | 0.6467 | 0.5912 | 0.5873 | 0.6526 | 0.5927 | 0.5881 | 0.6487 | 0.8005 |
| Without low importance | 61.23% | 0.6043 | 0.6017 | 0.6358 | 0.5740 | 0.6132 | 0.6496 | 0.5880 | 0.6060 | 0.6409 | 0.7998 |
| Method | Accuracy | Home Precision | Draw Precision | Away Precision | Home Recall | Draw Recall | Away Recall | Home F1-Score | Draw F1-Score | Away F1-Score | AUC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | 56.47% | 0.5905 | 1.0000 | 0.5176 | 0.8208 | 0.0000 | 0.5937 | 0.6861 | 0.0000 | 0.5507 | 0.7015 |
| Tuned | 56.98% | 0.5907 | 0.9000 | 0.5306 | 0.8378 | 0.0000 | 0.5844 | 0.9220 | 0.0000 | 0.5542 | 0.6971 |
| SMOTE | 65.09% | 0.6203 | 0.6821 | 0.6647 | 0.6986 | 0.5920 | 0.6623 | 0.6551 | 0.6328 | 0.6614 | 0.8352 |
| SMOTE and scaled | 63.68% | 0.6139 | 0.6449 | 0.6572 | 0.6248 | 0.5993 | 0.6865 | 0.6167 | 0.6203 | 0.6698 | 0.8293 |
| SMOTE, scaled and tuned | 66.27% | 0.6332 | 0.6810 | 0.6789 | 0.6356 | 0.6490 | 0.7035 | 0.6331 | 0.6633 | 0.6902 | 0.8410 |
| SMOTE and tuned | 66.96% | 0.6272 | 0.6919 | 0.6927 | 0.6478 | 0.6550 | 0.7059 | 0.6364 | 0.6717 | 0.6989 | 0.8485 |
| Without low importance | 65.34% | 0.6256 | 0.6536 | 0.6868 | 0.6405 | 0.6236 | 0.6962 | 0.6300 | 0.6370 | 0.6899 | 0.8360 |
| Metric | Value | Metric | Value |
|---|---|---|---|
| Home precision | 0.6139 | Home precision | 0.6139 |
| Draw precision | 0.6556 | Draw precision | 0.6556 |
| Away precision | 0.6648 | Away precision | 0.6648 |
| Home recall | 0.6718 | Home recall | 0.6718 |
| Draw recall | 0.5980 | Draw recall | 0.5980 |
| Away recall | 0.6595 |
| Method | Accuracy | Home Precision | Draw Precision | Away Precision | Home Recall | Draw Recall | Away Recall | Home F1-Score | Draw F1-Score | Away F1-Score | AUC |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | 47.84% | 0.4475 | 0.5332 | 0.5292 | 0.8304 | 0.0169 | 0.5879 | 0.5815 | 0.0322 | 0.5569 | 0.6959 |
| Tuned | 46.22% | 0.4509 | 0.4249 | 0.4802 | 0.7372 | 0.0395 | 0.6100 | 0.5595 | 0.0719 | 0.5373 | 0.6530 |
| SMOTE | 42.60% | 0.5067 | 0.2795 | 0.4041 | 0.4771 | 0.0691 | 0.7317 | 0.4912 | 0.1104 | 0.5205 | 0.6043 |
| SMOTE and scaled | 41.58% | 0.4836 | 0.3569 | 0.4064 | 0.5159 | 0.3821 | 0.3498 | 0.4987 | 0.3689 | 0.3754 | 0.6029 |
| SMOTE, scaled and tuned | 49.60% | 0.5284 | 0.3973 | 0.5501 | 0.6516 | 0.3498 | 0.4866 | 0.5836 | 0.3709 | 0.5154 | 0.6923 |
| SMOTE and tuned | 46.70% | 0.4420 | 0.3470 | 0.5339 | 0.8172 | 0.0568 | 0.5269 | 0.5736 | 0.0969 | 0.5303 | 0.6783 |
| Without low importance | 47.84% | 0.4475 | 0.5332 | 0.5292 | 0.8304 | 0.0169 | 0.5879 | 0.5815 | 0.0322 | 0.5569 | 0.6959 |
| CNN Model | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| DenseNet201 | 55.86% | 0.6012 | 0.3898 | 0.7142 |
| InceptionV3 | 50.62% | 0.5225 | 0.3718 | 0.6561 |
| MobileNetV2 | 55.86% | 0.5716 | 0.4353 | 0.7141 |
| ResNet101V2 | 53.82% | 0.5657 | 0.4042 | 0.6919 |
| MobileNetV2 20-layer Train | 58.27% | 0.6076 | 0.4756 | 0.7346 |
| CNN Model | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| DenseNet201 | 52.59% | 0.5589 | 0.3614 | 0.6735 |
| InceptionV3 | 50.38% | 0.5276 | 0.3563 | 0.6550 |
| MobileNetV2 | 51.15% | 0.5416 | 0.3713 | 0.6658 |
| ResNet101V2 | 50.28% | 0.5288 | 0.3768 | 0.6533 |
| MobileNetV2 20-layer Train | 53.29% | 0.5699 | 0.4036 | 0.6899 |
| CNN Model | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| DenseNet201 | 54.03% | 0.5673 | 0.3914 | 0.6846 |
| InceptionV3 | 48.54% | 0.5027 | 0.3434 | 0.6363 |
| MobileNetV2 | 54.43% | 0.5633 | 0.4301 | 0.6933 |
| ResNet101V2 | 51.33% | 0.5321 | 0.3736 | 0.6700 |
| MobileNetV2 20-layer Train | 56.21% | 0.5910 | 0.4402 | 0.7087 |
| CNN Model | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|
| MobileNetV2 20-layer Train | 52.99% | 0.5777 | 0.3962 | 0.6991 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malamatinos, M.-C.; Vrochidou, E.; Papakostas, G.A. On Predicting Soccer Outcomes in the Greek League Using Machine Learning. Computers 2022, 11, 133. https://0-doi-org.brum.beds.ac.uk/10.3390/computers11090133
Malamatinos M-C, Vrochidou E, Papakostas GA. On Predicting Soccer Outcomes in the Greek League Using Machine Learning. Computers. 2022; 11(9):133. https://0-doi-org.brum.beds.ac.uk/10.3390/computers11090133
Chicago/Turabian StyleMalamatinos, Marios-Christos, Eleni Vrochidou, and George A. Papakostas. 2022. "On Predicting Soccer Outcomes in the Greek League Using Machine Learning" Computers 11, no. 9: 133. https://0-doi-org.brum.beds.ac.uk/10.3390/computers11090133