Author Contributions
Conceptualization, S.M. and A.J.; methodology, S.M.; software, A.J.; validation, A.J.; formal analysis, S.M.; investigation, S.M.; resources, A.J.; data curation, A.J.; writing—original draft preparation, S.M.; writing—review and editing, A.J.; visualization, S.M.; supervision, A.J.; project administration, A.J.; funding acquisition, S.M. and A.J. All authors have read and agreed to the published version of the manuscript.
Figure 1.
The HAR framework based on IMU and stretch sensors used in this work.
Figure 1.
The HAR framework based on IMU and stretch sensors used in this work.
Figure 2.
Some accelerometer samples of inertial data from the w-HAR dataset.
Figure 2.
Some accelerometer samples of inertial data from the w-HAR dataset.
Figure 3.
Some gyroscope samples of inertial data from the w-HAR dataset.
Figure 3.
Some gyroscope samples of inertial data from the w-HAR dataset.
Figure 4.
Some samples of stretch data from the w-HAR dataset.
Figure 4.
Some samples of stretch data from the w-HAR dataset.
Figure 5.
The ResNeXt architecture used in this work.
Figure 5.
The ResNeXt architecture used in this work.
Figure 6.
10-fold cross-validation.
Figure 6.
10-fold cross-validation.
Figure 7.
The confusion matrix of the proposed ResNeXt model trained using inertial sensor data.
Figure 7.
The confusion matrix of the proposed ResNeXt model trained using inertial sensor data.
Figure 8.
The confusion matrix of the proposed ResNeXt model trained using stretch sensor data.
Figure 8.
The confusion matrix of the proposed ResNeXt model trained using stretch sensor data.
Figure 9.
The confusion matrix of the proposed ResNeXt model trained using inertial and stretch sensor data.
Figure 9.
The confusion matrix of the proposed ResNeXt model trained using inertial and stretch sensor data.
Figure 10.
All scenario comparison results of the median accuracy of DL models and the proposed ResNeXt model on the w-HAR dataset.
Figure 10.
All scenario comparison results of the median accuracy of DL models and the proposed ResNeXt model on the w-HAR dataset.
Figure 11.
All scenario comparison results of the median F-measure of DL models and the proposed ResNeXt model on the w-HAR dataset.
Figure 11.
All scenario comparison results of the median F-measure of DL models and the proposed ResNeXt model on the w-HAR dataset.
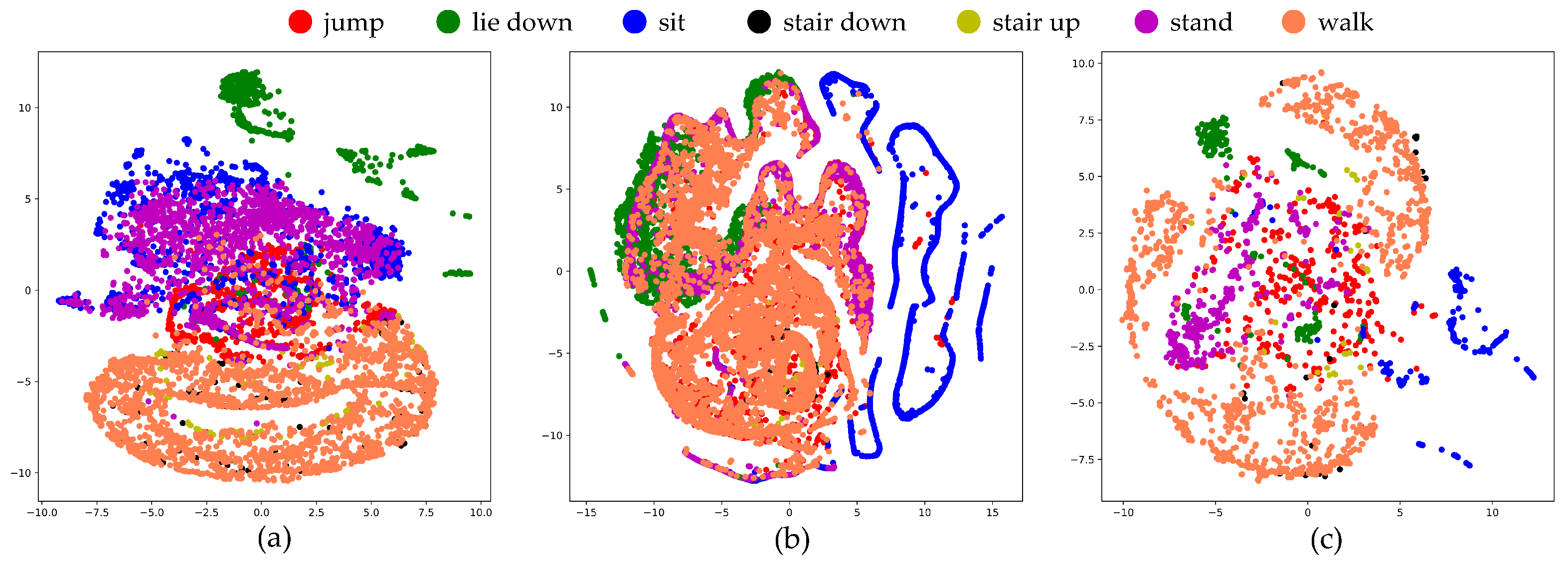
Figure 12.
The t-SNE visualization of the testing data in two dimensions, prior to training the proposed ResNeXt model with various sensor data types: (a) motion sensor, (b) stretch sensor, and (c) a combination of motion and stretch sensors.
Figure 12.
The t-SNE visualization of the testing data in two dimensions, prior to training the proposed ResNeXt model with various sensor data types: (a) motion sensor, (b) stretch sensor, and (c) a combination of motion and stretch sensors.
Figure 13.
A two-dimensional t-SNE visualization of the testing data following the acquisition of representations by the proposed ResNeXt model, employing different sensor data types: (a) motion sensor, (b) stretch sensor, and (c) a combination of motion and stretch sensors.
Figure 13.
A two-dimensional t-SNE visualization of the testing data following the acquisition of representations by the proposed ResNeXt model, employing different sensor data types: (a) motion sensor, (b) stretch sensor, and (c) a combination of motion and stretch sensors.
Figure 14.
A two-dimensional t-SNE visualization of the testing data following the acquisition of representations by the proposed ResNeXt model that was modified by removing some modules: (a) ResNeXt without the multi-kernel blocks, (b) ResNeXt without the convolutional block, and (c) the proposed ResNeXt.
Figure 14.
A two-dimensional t-SNE visualization of the testing data following the acquisition of representations by the proposed ResNeXt model that was modified by removing some modules: (a) ResNeXt without the multi-kernel blocks, (b) ResNeXt without the convolutional block, and (c) the proposed ResNeXt.
Table 1.
The summary of hyperparameters of the ResNeXt used in this work.
Table 1.
The summary of hyperparameters of the ResNeXt used in this work.
| Stage | Hyperparameters | Values |
|---|
| Convolutional block | Convolutional Block | | |
| Multi-kernel block × 3 | Conv1D | Kernel Size | 5 |
| | Filters | 64 |
| | Batch Normalization | | - |
| | Activation | | ReLU |
| | Max Pooling | | 2 |
| | Branch-1-1 | | |
| | Conv1D | Kernel Size | 1 |
| | Filters | 16 |
| | Conv1D | Kernel Size | 3 |
| | Filters | 16 |
| | Branch-1-2 | | |
| | Conv1D | Kernel Size | 1 |
| | Filters | 16 |
| | Conv1D | Kernel Size | 5 |
| | Filters | 16 |
| | Branch-1-3 | | |
| | Conv1D | Kernel Size | 1 |
| | Filters | 16 |
| | Conv1D | Kernel Size | 7 |
| | Filters | 16 |
| | Branch-1 | | |
| | Conv1D | Kernel Size | 1 |
| | Stride | 1 |
| | Filters | 64 |
| | Branch-2 | | |
| | Conv1D | Kernel Size | 1 |
| | Stride | 1 |
| | Filters | 64 |
| Classification block | Global Average Pooling | | - |
| | Flatten | | - |
| | Dense | | 128 |
| Training | Loss Function | | Cross-entropy |
| | Optimizer | | Adam |
| | Batch Size | | 64 |
| | Number of Epochs | | 200 |
Table 2.
A list of detailed experiments used in this work.
Table 2.
A list of detailed experiments used in this work.
| Scenario | Description |
|---|
| I | Only inertial sensor data |
| II | Only stretch sensor data |
| III | Inertial and stretch sensor data |
Table 3.
Recognition effectiveness of baseline DL models and the proposed ResNeXt model from Scenario I.
Table 3.
Recognition effectiveness of baseline DL models and the proposed ResNeXt model from Scenario I.
| Model | Recognition Effectiveness |
|---|
| Accuracy | Loss | F-Measure |
|---|
| CNN | 85.07% (±0.807%) | 0.37 (±0.023) | 84.58% (±1.359%) |
| LSTM | 82.10% (±6.612%) | 0.49 (±0.177) | 77.84% (±16.350%) |
| BiLSTM | 82.77% (±1.851%) | 0.40 (±0.018) | 81.79% (±4.511%) |
| GRU | 81.96% (±1.690%) | 0.39 (±0.017) | 81.93% (±2.228%) |
| BiGRU | 81.57% (±1.729%) | 0.41 (±0.040) | 81.00% (±3.661%) |
| ResNeXt | 85.78% (±2.027%) | 0.35 (±0.027) | 86.75% (±1.989%) |
Table 4.
Recognition effectiveness of baseline DL models and the proposed ResNeXt model from Scenario II.
Table 4.
Recognition effectiveness of baseline DL models and the proposed ResNeXt model from Scenario II.
| Model | Recognition Effectiveness |
|---|
| Accuracy | Loss | F-Measure |
|---|
| CNN | 83.80% (±0.876%) | 0.46 (±0.028) | 78.30% (±1.282%) |
| LSTM | 86.92% (±0.577%) | 0.43 (±0.011) | 84.92% (±1.660%) |
| BiLSTM | 86.53% (±0.351%) | 0.40 (±0.014) | 84.45% (±1.485%) |
| GRU | 86.55% (±0.282%) | 0.39 (±0.010) | 83.32% (±1.137%) |
| BiGRU | 88.47% (±0.520%) | 0.42 (±0.037) | 87.19% (±0.710%) |
| ResNeXt | 88.59% (±0.896%) | 0.35 (±0.018) | 87.61% (±1.450%) |
Table 5.
Recognition effectiveness of baseline DL models and the proposed ResNeXt model from Scenario III.
Table 5.
Recognition effectiveness of baseline DL models and the proposed ResNeXt model from Scenario III.
| Model | Recognition Effectiveness |
|---|
| Accuracy | Loss | F-Measure |
|---|
| CNN | 96.67% (±0.306%) | 0.14 (±0.016) | 90.06% (±2.247%) |
| LSTM | 96.67% (±0.470%) | 0.19 (±0.034) | 94.16% (±1.464%) |
| BiLSTM | 96.70% (±0.590%) | 0.14 (±0.032) | 92.98% (±2.437%) |
| GRU | 95.09% (±0.516%) | 0.17 (±0.033) | 86.24% (±6.100%) |
| BiGRU | 96.97% (±1.060%) | 0.15 (±0.034) | 94.15% (±3.516%) |
| ResNeXt | 97.68% (±0.444%) | 0.10 (±0.020) | 95.87% (±0.954%) |
Table 6.
Results of comparison between the proposed ResNeXt and state-of-the-art models using the w-HAR dataset.
Table 6.
Results of comparison between the proposed ResNeXt and state-of-the-art models using the w-HAR dataset.
| Activity | F1-Measure (%) |
|---|
| NN-DSE [30] | TCR-GRU-ECA [14] | CNN-BiLSTM [34] | The Proposed ResNeXt |
|---|
| Jump | 94.6% | 96.7% | 92.9% | 96.8% |
| Lie down | 99.8% | 100.0% | 99.7% | 100.0% |
| Sit | 96.4% | 99.3% | 99.1% | 99.4% |
| Stair down | 96.2% | 94.9% | 77.2% | 96.3% |
| Stair up | 96.3% | 87.3% | 86.5% | 97.4% |
| Stand | 95.1% | 98.1% | 97.2% | 98.7% |
| Walk | 94.5% | 99.1% | 98.4% | 99.1% |
Table 7.
Effects of multi-kernel blocks.
Table 7.
Effects of multi-kernel blocks.
| Model | Recognition Effectiveness |
|---|
| Accuracy | Loss | F-Measure |
|---|
| CNN without multi-kernel blocks | 96.67% (±0.306%) | 0.14 (±0.016) | 90.06% (±2.247%) |
| Our model using multi-kernel blocks | 97.68% (±0.444%) | 0.10 (±0.020) | 95.87% (±0.954%) |
Table 8.
Effects of the convolutional block.
Table 8.
Effects of the convolutional block.
| Model | Recognition Effectiveness |
|---|
| Accuracy | Loss | F-Measure |
|---|
| ResNeXt without the convolutional block | 97.37% (±0.494%) | 0.11 (±0.015) | 95.51% (±0.977%) |
| Our model using the convolutional block | 97.68% (±0.444%) | 0.10 (±0.020) | 95.87% (±0.954%) |
Table 9.
Effects of the GAP layer.
Table 9.
Effects of the GAP layer.
| Model | Recognition Effectiveness |
|---|
| Accuracy | Loss | F-Measure |
|---|
| ResNeXt using a flatten layer | 95.86% (±1.424%) | 0.33 (±0.165) | 86.23% (±7.032%) |
| Our model using the GAP layer | 97.68% (±0.444%) | 0.10 (±0.020) | 95.87% (±0.954%) |
Table 10.
Comparison of mean prediction times obtained from ResNeXt-based models with or without the convolution block and multi-kernel blocks.
Table 10.
Comparison of mean prediction times obtained from ResNeXt-based models with or without the convolution block and multi-kernel blocks.
| Convolutional Block | Multi-Kernel Block | Mean Prediction Time (ms) |
|---|
| ✓ | - | 0.2250 |
| - | ✓ | 0.6581 |
| ✓ | ✓ | 1.1567 |



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
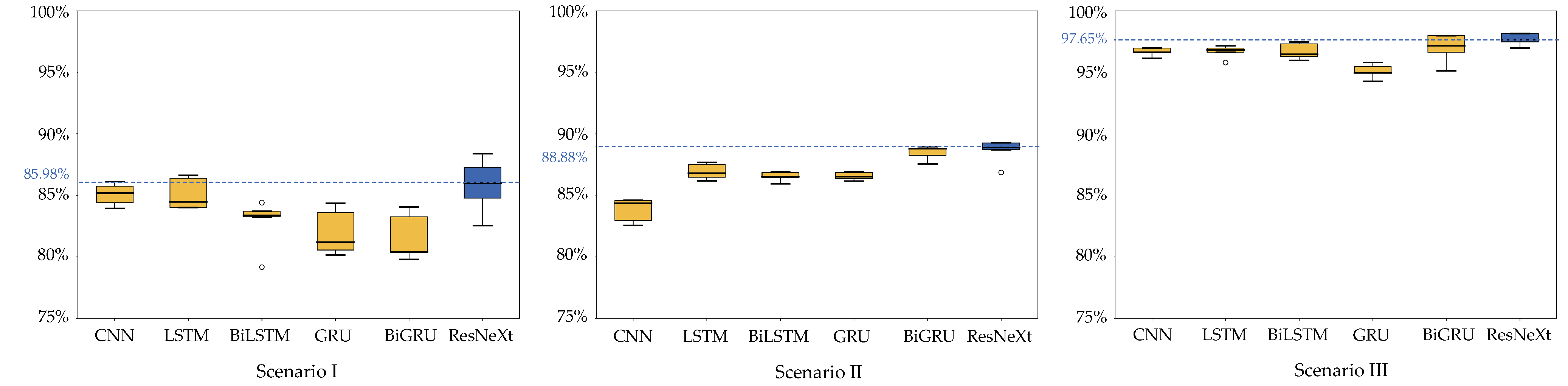{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}