
A Rule-Based Algorithm and Its Specializations for Measuring the Complexity of Software in Educational Digital Environments


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. A Rule-Based Algorithm for Measuring Code Complexity
- is a predicate that checks whether the complexity value should be incremented or whether the nesting level should be increased for a given AST node and its parent node , , is the set of all nodes belonging to the analyzed AST, is the Boolean set, and .
- is a mapping which computes the increment size or the nesting level increase size for a given AST node and the given context set , , where is the set of nodes in an AST, is the set of all possible context sets, and is the set of integers.
| Algorithm 1. A Rule-Based Algorithm for Measuring Code Complexity | |
| Input: | ▷ An AST node. ▷ Parent node of the AST node. |
| ▷ Current nesting level, 0 by default. | |
| ▷ The set of rules for simple increments. ▷ The set of rules for increasing the nesting level. | |
| ▷ The set of rules for nesting increments. . ▷ The set used as the shared context during AST traversal. | |
| 1. | . ▷ Compute simple increment based on . |
| 2. | . ▷ Compute nesting level increase based on . |
| 3. | . ▷ Compute nesting increment based on . |
| 4. | . ▷ Compute the complexity of the AST node . |
| 5. | For each child node of the node do: |
| 6. | Algorithm 1 (. |
| 7. | . |
| 8. | End loop. |
| 9. | Return . ▷ The complexity of the AST node. |
3.2. Rules for Cognitive Complexity
- Simple increments;
- Nesting level increases;
- Nesting increments.
3.3. Rules for Cyclomatic Complexity
3.4. Rules for Educational Complexity
| Algorithm 2. Extraction of defined and used variables from a Python AST | |
| Input: | ▷ An AST node to extract defined and used variables from. ▷ The set of defined variables, by default. ▷ The set of used variables, by default. |
| 1. | If then: |
| 2. | . |
| 3. | End if. |
| 4. | If then: |
| 5. | . |
| 6. | End if. |
| 7. | For each child node of the node do: |
| 8. | Algorithm 2 . |
| 9. | End loop. |
| 10. | Return . ▷ The defined and used variables. |
4. Comparison of the Code Complexity Metrics
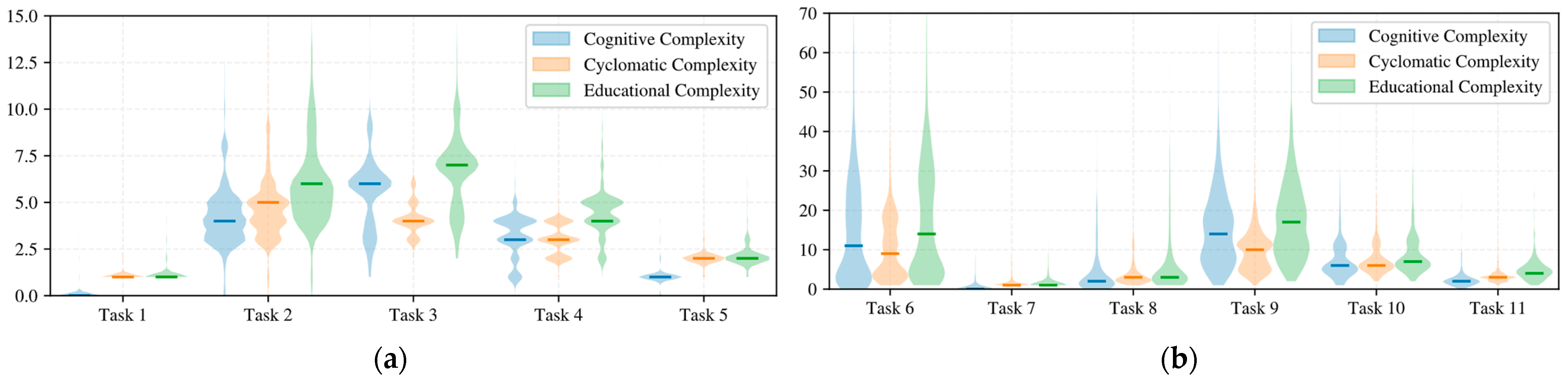
4.1. Sample Programs
4.2. Programs Solving Unique Programming Exercises
- Implement a mathematical function;
- Implement a piecewise function formula;
- Implement an iterative formula;
- Implement a recurrent formula;
- Implement a function that processes vectors;
- Implement a function computing a decision tree;
- Implement a bit field converter;
- Implement a text format parser;
- Implement tabular data transformation;
- Implement a finite state machine as a class;
- Implement a binary format parser.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xia, X.; Bao, L.; Lo, D.; Xing, Z.; Hassan, A.E.; Li, S. Measuring Program Comprehension: A Large-Scale Field Study with Professionals. IEEE Trans. Softw. Eng. 2018, 44, 951–976. [Google Scholar] [CrossRef]
- Fowler, M. Patterns. IEEE Softw. 2003, 20, 56–57. [Google Scholar] [CrossRef]
- Gamma, E.; Helms, R.; Johnson, R.; Vlissides, J. Design Patterns: Elements of Reusable Object-Oriented Software, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 1995; 395p. [Google Scholar]
- Ampatzoglou, A.; Chatzigeorgiou, A.; Charalampidou, S.; Avgeriou, P. The effect of GoF design patterns on stability: A case study. IEEE Trans. Softw. Eng. 2015, 41, 781–802. [Google Scholar] [CrossRef]
- Qamar, N.; Malik, A.A. Impact of design patterns on software complexity and size. Mehran Univ. Res. J. Eng. Technol. 2020, 39, 342–352. [Google Scholar] [CrossRef]
- Koenig, A. Patterns and antipatterns. In The Patterns Handbooks: Techniques, Strategies, and Applications; Cambridge University Press: Cambridge, UK, 1998; pp. 383–389. [Google Scholar]
- Smaragdakis, Y.; Csallner, C. Combining Static and Dynamic Reasoning for Bug Detection. In Proceedings of the International Conference on Tests and Proofs, Zurich, Switzerland, 12–13 February 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–16. [Google Scholar]
- Bakanov, V.M. Computational complexity when constructing rational plans for program execution in a given field of parallel computers. Russ. Technol. J. 2022, 10, 7–19. [Google Scholar] [CrossRef]
- Zhang, Z.; Xing, Z.; Xia, X.; Xu, X.; Zhu, L. Making Python Code Idiomatic by Automatic Refactoring Non-Idiomatic Python Code with Pythonic Idioms. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–16 November 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 696–708. [Google Scholar]
- Uchiyama, S.; Kubo, A.; Washizaki, H.; Fukazawa, Y. Detecting design patterns in object-oriented program source code by using metrics and machine learning. J. Softw. Eng. Appl. 2014, 7, 983. [Google Scholar] [CrossRef]
- Dwivedi, A.K.; Tirkey, A.; Ray, R.B.; Rath, S.K. Software design pattern recognition using machine learning techniques. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Marina Bay Sands, Singapore, 22–25 November 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 222–227. [Google Scholar]
- Hummel, O.; Burger, S. Analyzing source code for automated design pattern recommendation. In Proceedings of the 3rd ACM SIGSOFT International Workshop on Software Analytics, Paderborn, Germany, 4 September 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 8–14. [Google Scholar]
- Parsa, S.; Zakeri-Nasrabadi, M.; Ekhtiarzadeh, M.; Ramezani, M. Method name recommendation based on source code metrics. J. Comput. Lang. 2023, 74, 10117. [Google Scholar] [CrossRef]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated Vulnerability Detection in Source Code Using Deep Representation Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 757–762. [Google Scholar]
- Gorchakov, A.V.; Demidova, L.A.; Sovietov, P.N. Analysis of Program Representations Based on Abstract Syntax Trees and Higher-Order Markov Chains for Source Code Classification Task. Future Internet 2023, 15, 314. [Google Scholar] [CrossRef]
- Taherkhani, A.; Malmi, L.; Korhonen, A. Algorithm Recognition by Static Analysis and Its Application in Students’ Submissions Assessment. In Proceedings of the 8th International Conference on Computing Education Research, Koli, Finland, 13–16 November 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 88–91. [Google Scholar]
- Parareda, B.; Pizka, M. Measuring productivity using the infamous lines of code metric. In Proceedings of the SPACE 2007 Workshop, Nagoya, Japan, 4 December 2007; pp. 4–9. [Google Scholar]
- Mamun, M.A.A.; Berger, C.; Hansson, J. Correlations of software code metrics: An empirical study. In Proceedings of the 27th international workshop on software measurement and 12th international conference on software process and product measurement, Gothenburg, Sweden, 25–27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 255–266. [Google Scholar]
- Buse, R.P.L.; Weimer, W.R. Learning a metric for code readability. IEEE Trans. Softw. Eng. 2009, 36, 546–558. [Google Scholar] [CrossRef]
- Halstead, M.H. Elements of Software Science (Operating and Programming Systems Series); Elsevier Science Inc.: New York, NY, USA, 1977. [Google Scholar]
- Curtis, B.; Sheppard, S.B.; Milliman, P.; Borst, M.A.; Love, T. Measuring the psychological complexity of software maintenance tasks with the Halstead and McCabe metrics. IEEE Trans. Softw. Eng. 1979, 2, 96–104. [Google Scholar] [CrossRef]
- McCabe, T.J. A Complexity Measure. IEEE Trans. Softw. Eng. 1976, 4, 308–320. [Google Scholar] [CrossRef]
- Campbell, G.A. Cognitive Complexity: An Overview and Evaluation. In Proceedings of the 2018 International Conference on Technical Debt, Gothenburg, Sweden, 27–28 May 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 57–58. [Google Scholar]
- Muñoz Barón, M.; Wyrich, M.; Wagner, S. An empirical validation of cognitive complexity as a measure of source code understandability. In Proceedings of the 14th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), Bari, Italy, 5–9 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–12. [Google Scholar]
- Sovietov, P.N.; Gorchakov, A.V. Digital Teaching Assistant for the Python Programming Course. In Proceedings of the 2022 2nd International Conference on Technology Enhanced Learning in Higher Education (TELE), Lipetsk, Russia, 26–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 272–276. [Google Scholar]
- Sovietov, P. Automatic Generation of Programming Exercises. In Proceedings of the 2021 1st International Conference on Technology Enhanced Learning in Higher Education (TELE), Lipetsk, Russia, 7–9 July 2021; IEEE: Pistacaway, NJ, USA, 2021; pp. 111–114. [Google Scholar]
- Python Software Foundation. AST—Abstract Syntax Trees. 2023. Available online: https://docs.python.org/3/library/ast.html (accessed on 3 December 2023).
- Gansner, E.R.; North, S.C. An Open Graph Visualization System and its Applications to Software Engineering. Softw. Pract. Exp. 2000, 30, 1203–1233. [Google Scholar] [CrossRef]
- McCabe, T.J.; Butler, C.W. Design complexity measurement and testing. Commun. ACM 1989, 32, 1415–1425. [Google Scholar] [CrossRef]
- Lacchia, M. Radon 4.1.0 Documentation. 2020. Available online: https://radon.readthedocs.io/en/latest/ (accessed on 6 December 2023).
- Köşker, Y.; Turhan, B.; Bener, A. Refactoring prediction using class complexity metrics. In Proceedings of the Third International Conference on Software and Data Technologies, Volume SE/MUSE/GSDCA, Porto, Portugal, 5–8 July 2008; INSTICC Press: Lisboa, Portugal, 2008; pp. 289–292. [Google Scholar]
- Kumar, S.K.S.; Kulyadi, S.P.; Mohandas, P.; Raman, M.S.; Vasan, V.S. Computation of Cyclomatic Complexity and Detection of Malware Executable Files. In Proceedings of the 2021 13th International Conference on Electronics, Computers and Artificial Intelligence (ECAI), Pitesti, Romania, 1–3 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Emergy, K.O.; Mitchell, B.K. Multi-level software testing based on cyclomatic complexity. In Proceedings of the IEEE National Aerospace and Electronics Conference, Dayton, OH, USA, 22–26 May 1989; IEEE: Piscataway, NJ, USA, 1989; pp. 500–507. [Google Scholar]
- Farooq, U.; Abubakar; Aqeel, A.B. A Meta-Model for Test Case Reduction by Reducing Cyclomatic Complexity in Regression Testing. In Proceedings of the 2021 International Conference on Robotics and Automation in Industry (ICRAI), Rawalpindi, Pakistan, 26–27 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Yu, S.; Zhou, S. A survey on metric of software complexity. In Proceedings of the 2010 2nd IEEE International conference on information management and engineering, Chengdu, China, 16–18 April 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 352–356. [Google Scholar]
- Zheng, J.; Wu, J. Research of the method of measuring program complexity based on pseudo-path. J. Zhongkai Agrotech. Coll. 2006, 4, 42–45. [Google Scholar]
- Vinju, J.J.; Godfrey, M.W. What does control flow really look like? Eyeballing the cyclomatic complexity metric. In Proceedings of the 2012 IEEE 12th International Working Conference on Source Code Analysis and Manipulation, Riva del Garda, Italy, 23–24 September 2012; IEEE: Piscataway, NJ, USA, 2021; pp. 154–163. [Google Scholar]
- Sarwar, M.M.S.; Shahzad, S.; Ahmad, I. Cyclomatic complexity: The nesting problem. In Proceedings of the Eighth International Conference on Digital Information Management (ICDIM 2013), Islamabad, Pakistan, 10–12 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 274–279. [Google Scholar]
- Lavazza, L.; Abualkishik, A.Z.; Liu, G.; Morasca, S. An empirical evaluation of the “Cognitive Complexity” measure as a predictor of code understandability. J. Syst. Softw. 2023, 197, 111561. [Google Scholar] [CrossRef]
- Hung, S.L.; Kwok, I.F.; Chan, R. Automatic programming assessment. Comput. Educ. 1993, 20, 183–190. [Google Scholar] [CrossRef]
- Smith, R.; Tang, T.; Warren, J.; Rixner, S. An automated system for interactively learning software testing. In Proceedings of the 2017 ACM Conference on Innovation and Technology in Computer Science Education, Bologna, Italy, 3–5 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 98–103. [Google Scholar]
- Fowler, M.; Beck, K. Refactoring: Improving the Design of Existing Code, 2nd ed.; Addison-Wesley Professional: Boston, MA, USA, 2018; pp. 104–107. [Google Scholar]
- Saborido, R.; Ferrer, J.; Chicano, F.; Alba, E. Automatizing Software Cognitive Complexity Reduction. IEEE Access 2022, 10, 11642–11656. [Google Scholar] [CrossRef]
- Gorchakov, A.V. Precise Library for Complexity Assessment Algorithm Synthesis. 2023. Available online: https://gist.github.com/worldbeater/51fa42ed4380da9218368bde78024bab (accessed on 8 December 2023).
- Demidova, L.A.; Andrianova, E.G.; Sovietov, P.N.; Gorchakov, A.V. Dataset of Program Source Codes Solving Unique Programming Exercises Generated by Digital Teaching Assistant. Data 2023, 8, 109. [Google Scholar] [CrossRef]
- Jorge, D.; Machado, P.; Andrade, W. Investigating Test Smells in JavaScript Test Code. In Proceedings of the 6th Brazilian Symposium on Systematic and Automated Software Testing, Salvador, Brazil, 27 September 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 36–45. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Line No. | Source Code | CycC | CogC |
|---|---|---|---|
| 1. | def main(): | +1 | – |
| 2. | try: | – | – |
| 3. | if condition1: | +1 | +1 (nesting = 0) |
| 4. | for i in range(10): | +1 | +2 (nesting = 1) |
| 5. | while condition2: | +1 | +3 (nesting = 2) |
| 6. | pass | – | – |
| 7. | except Exception as e: | +1 | +1 (nesting = 0) |
| 8. | if condition2: | +1 | +2 (nesting = 1) |
| 9. | pass | – | – |
| Total complexity: | 6 | 9 | |
| Rule No. | Description | The Predicate | The Mapping |
|---|---|---|---|
| 1. | Conditional operator with two branches | 1. | |
| 2. | Recursive function | 1. | |
| 3. | Branching in loops and Error-handling operators | 1. | |
| 4. | Control flow breakers | . | 1. |
| 5. | Generators and branching in generators | . | , where . |
| 6. | A chain of Boolean operators | 1. |
| Rule No. | Description | The Predicate | The Mapping |
|---|---|---|---|
| 1. | A conditional operator which is not an else-if | 1. | |
| 2. | A function which is not a simple decorator | , where . | 1. |
| 3. | A syntactic construct which increases the nesting level | . | 1. |
| Rule No. | Description | The Predicate | The Mapping |
|---|---|---|---|
| 1. | A conditional operator which is not an else-if | 1. | |
| 2. | Control flow breaker | . | 1. |
| Rule No. | Description | The Predicate | The Mapping |
|---|---|---|---|
| 1. | Exception handling | . | , where . |
| 2. | Every Boolean operator | . | . |
| 3. | Pattern matching | . | . |
| 4. | Generators and branching in generators | , where . | |
| 5. | Control flow breakers | . | , where |
| 6. | Conditional operators and function definition | . | 1. |
| Rule No. | Description | The Predicate | The Mapping |
|---|---|---|---|
| 1. | Distinct Boolean operators | . | . |
| 2. | Pattern-matching cases | . | . |
| 3. | Function body | 1. | |
| 4. | Loop iteration stop | . | 1. |
| 5. | Variable reuse in assignment statement or expression | . | Algorithm 2 ; ; ; Return s. |
| 6. | Augmented assignment | . | Algorithm 2 ; ; Return 0. |
| 7. | Variable definition | . | ; Return 0. |
| 8. | Argument definition | . | ; Return 0. |
| Line No. | Source Code | CycC | CogC | EduC |
|---|---|---|---|---|
| 1. | def add_version(entry, txn): | +1 | – | +1 |
| 2. | ti = persistit.transaction() | – | – | – |
| 3. | while True: | +1 | +1 (nesting = 0) | +1 (nesting = 0) |
| 4. | try: | – | – | – |
| 5. | if first is not None: | +1 | +2 (nesting = 1) | +2 (nesting = 1) |
| 6. | if first.version() > entry.version(): | +1 | +3 (nesting = 2) | +3 (nesting = 2) |
| 7. | raise RollbackException() | – | – | – |
| 8. | if txn.active(): | +1 | +3 (nesting = 2) | +3 (nesting = 2) |
| 9. | for e in e.get_previous(): | +1 | +4 (nesting = 3) | +4 (nesting = 3) |
| 10. | version = e.version() | – | – | – |
| 11. | depends = ti.depenency(version, txn.status, 0) | – | – | – |
| 12. | if depends == TimedOut: | +1 | +5 (nesting = 4) | +5 (nesting = 4) |
| 13. | raise RetryException() | – | – | – |
| 14. | if depends != 0 \ | +1 | +5 (nesting = 4) | +5 (nesting = 4) |
| 15. | and depends != Aborted: | +1 | +1 | +1 |
| 16. | raise RollbackException() | – | – | – |
| 17. | entry.set_previous(first) | – | – | – |
| 18. | first = entry | – | – | – |
| 19. | break | – | – | +1 |
| 20. | except RetryException as re: | – | +2 (nesting = 1) | +2 (nesting = 1) |
| 21. | try: | – | – | – |
| 22. | depends = persistit.transaction() | – | – | +1 (variable reuse) |
| 23. | if depends != 0 \ | +1 | +3 (nesting = 2) | +3 (nesting = 2) |
| 24. | and depends != Aborted: | +1 | +1 | +1 |
| 25. | raise RollbackException() | – | – | – |
| 26. | except InterruptedException as ie: | – | +3 (nesting = 2) | +3 (nesting = 2) |
| 27. | raise PersistitInterruptedException(ie) | – | – | – |
| 28. | except InterruptedException as ie: | – | +2 (nesting = 1) | +2 (nesting = 1) |
| 29. | raise PersistitInterruptedException(ie) | – | – | – |
| Total complexity: | 14 | 35 | 38 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gorchakov, A.V.; Demidova, L.A.; Sovietov, P.N. A Rule-Based Algorithm and Its Specializations for Measuring the Complexity of Software in Educational Digital Environments. Computers 2024, 13, 75. https://0-doi-org.brum.beds.ac.uk/10.3390/computers13030075
Gorchakov AV, Demidova LA, Sovietov PN. A Rule-Based Algorithm and Its Specializations for Measuring the Complexity of Software in Educational Digital Environments. Computers. 2024; 13(3):75. https://0-doi-org.brum.beds.ac.uk/10.3390/computers13030075
Chicago/Turabian StyleGorchakov, Artyom V., Liliya A. Demidova, and Peter N. Sovietov. 2024. "A Rule-Based Algorithm and Its Specializations for Measuring the Complexity of Software in Educational Digital Environments" Computers 13, no. 3: 75. https://0-doi-org.brum.beds.ac.uk/10.3390/computers13030075