
Time Series Features for Supporting Hydrometeorological Explorations and Predictions in Ungauged Locations Using Large Datasets


1
Department of Water Resources and Environmental Engineering, School of Civil Engineering, National Technical University of Athens, Heroon Polytechneiou 5, 15780 Zographou, Greece
2
Construction Agency, Hellenic Air Force, Mesogion Avenue 227–231, 15561 Cholargos, Greece
*
Author to whom correspondence should be addressed.
Water 2022, 14(10), 1657; https://0-doi-org.brum.beds.ac.uk/10.3390/w14101657
Submission received: 4 April 2022
/
Revised: 10 May 2022
/
Accepted: 13 May 2022
/
Published: 23 May 2022
(This article belongs to the Special Issue Using Statistical and Machine Learning Algorithms for Big Data Applications in Hydrology)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Regression-based frameworks for streamflow regionalization are built around catchment attributes that traditionally originate from catchment hydrology, flood frequency analysis and their interplay. In this work, we deviated from this traditional path by formulating and extensively investigating the first regression-based streamflow regionalization frameworks that largely emerge from general-purpose time series features for data science and, more precisely, from a large variety of such features. We focused on 28 features that included (partial) autocorrelation, entropy, temporal variation, seasonality, trend, lumpiness, stability, nonlinearity, linearity, spikiness, curvature and others. We estimated these features for daily temperature, precipitation and streamflow time series from 511 catchments and then merged them within regionalization contexts with traditional topographic, land cover, soil and geologic attributes. Precipitation and temperature features (e.g., the spectral entropy, seasonality strength and lag-1 autocorrelation of the precipitation time series, and the stability and trend strength of the temperature time series) were found to be useful predictors of many streamflow features. The same applies to traditional attributes such as the catchment mean elevation. Relationships between predictor and dependent variables were also revealed, while the spectral entropy, the seasonality strength and several autocorrelation features of the streamflow time series were found to be more regionalizable than others.
1. Introduction
Streamflow regionalization (see its various definitions in He et al. [1], Table 1) is closely related to the initiative for Predictions in Ungauged Basins (PUB) of the International Association of Hydrological Sciences (IAHS) by Sivapalan et al. [2]. The importance of this initiative is broadly acknowledged in the literature and extensively discussed by other initiatives (e.g., [3,4,5]). In summary, the core concept behind streamflow regionalization and PUB is the transfer of information that is useful for streamflow description and modelling from gauged to ungauged sites. This transfer can lead to the reduction of the streamflow modelling uncertainties in ungauged sites and can be facilitated, among others, by regression-based frameworks (see, e.g., the reviews by He et al. [1]; Hrachowitz et al. [3]; Guo et al. [6]) that first establish an empirical relationship between a target and a set of independent variables based on large multisite datasets and then utilize the previously established relationship for the information transfer.
The independent variables of the regression may include any catchment attribute that does not rely on flow time series for its estimation, while the target variables of the regression, and thus the information transferred through streamflow regionalization, can take the form of either streamflow time series characterizations or model parameter estimates (see, e.g., the reviews by He et al. [1]; Hrachowitz et al. [3]; Guo et al. [6]), with these latter two attribute categories mostly overlapping in practice, at least from a statistician’s point of view. Furthermore, as streamflow modelling through streamflow regionalization mostly appears in the catchment hydrology and flood frequency analysis fields and in their interplay, the target and independent variables of the regression usually take forms that are relevant to either of these fields. A related literature overview linking streamflow regionalization for flood investigations (see, e.g., the modelling works by Merz and Blöschl [7]; Aziz et al. [8]; Rahman et al. [9]; Tyralis et al. [10]; Rahman et al. [11]; Fischer and Schumann [12]) to streamflow signature regionalization (see, e.g., the modelling works by Beck et al. [13]; Westerberg et al. [14]; Addor et al. [15]; Tyralis et al. [16]; Laimighofer et al. [17], as well as the reviews and taxonomies of streamflow signatures by McMillan et al. [18]; McMillan [19]) and catchment model parameter regionalization (see, e.g., the modelling works by Parajka et al. [20]; Oudin et al. [21]; Pool et al. [22]) can be found in Tyralis et al. [10].
Notably, streamflow regionalization frameworks that are largely centred around general-purpose time series features (i.e., functions for extracting information from time series data), such as the autocorrelation, partial autocorrelation, entropy, temporal variation, seasonality, trend, lumpiness, stability, nonlinearity, linearity, spikiness and curvature ones appearing in Wang et al. [23], Fulcher et al. [24], Fulcher and Jones [25], Hyndman et al. [26], Fulcher and Jones [27], Kang et al. [28], Fulcher [29], Kang et al. [30] and Hyndman et al. [31], are currently absent from the literature, with the same further applying individually to most of the relevant feature categories. This absence holds despite the fundamental and practical interest in stochastic (statistical) hydrology for many, if not all, of the abovementioned feature categories (see, e.g., the central themes, concepts and directions provided by Montanari et al. [4], and the five key features investigated by Papacharalampous and Tyralis [32]), and despite their proven relevance for diverse data science [33] tasks (including hydro-data science tasks, such as those carried out by Papacharalampous et al. [34,35]), thereby suggesting a research gap waiting to be filled. The importance of filling this specific gap in general, and of filling it with multiple time series features in particular, becomes even more pronounced if we additionally consider that hydrometeorological conditions should ideally be represented by as many features as possible [34].
Driven by the above considerations, we here propose the estimation of a large variety of general-purpose time series features, including features from all the categories mentioned in the above paragraph and more, from large multisite datasets comprising temperature, precipitation and streamflow information, and the subsequent transfer of streamflow feature information from gauged to ungauged locations by using the various temperature and precipitation features, together with multiple other catchment attributes, as predictor variables within regression-based streamflow regionalization frameworks. This is possible and largely applicable in practice (similar to what applies to other forms of regression-based streamflow regionalizations), as a variety of topographic, land cover, soil and geologic attributes might be available for both gauged and ungauged catchments and, at the same time, temperature and precipitation features can be sufficiently estimated for them from widely available remote sending data in cases when earth observations for temperature and precipitation are not available.
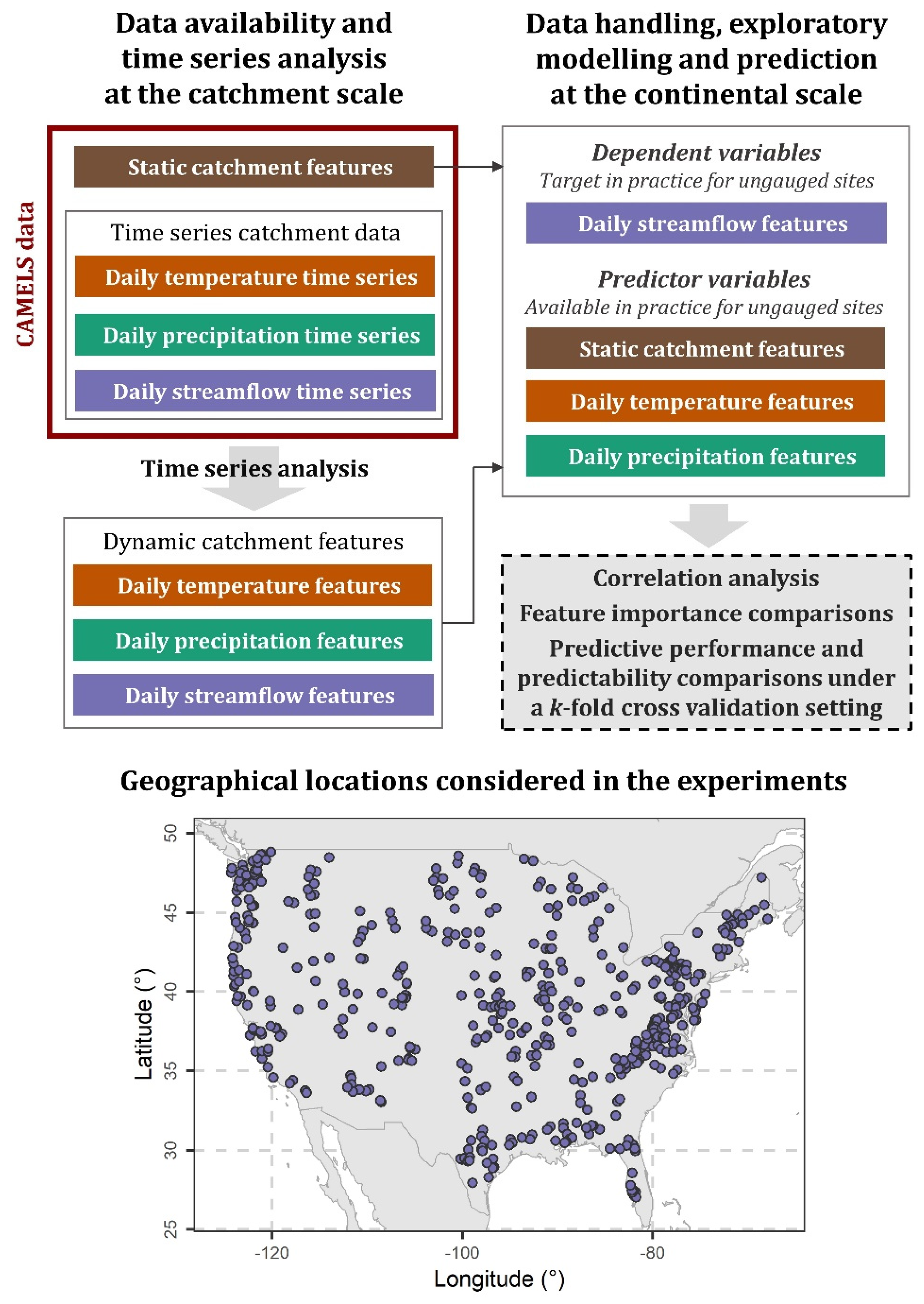
Given their scarcity in the previous streamflow regionalization literature, which is also evident from literature reviews on the topic (e.g., [1,3,6]), the various time series feature categories underlying this work, as well as their consideration as a synthesis, constitute new concepts and methodological elements for supporting: (a) regression-based streamflow feature regionalization, and (b) explorations that facilitate an improved understanding of the relationships that can be exploited for this regionalization. Therefore, their usefulness had to be extensively investigated. In this endeavour, we herein designed and performed a series of large-sample experiments, as detailed in Section 2 and as summarized with Figure 1.
These experiments relied on a well-established hydrological dataset (see Section 2.1) and were implemented using open statistical software according to the details provided in Appendix A. They were conducted at the daily time scale; nonetheless, their underlying methodological framework is also applicable to other (including mixed) time scales after small adaptations in the time series analysis for feature estimation. This analysis was herein performed according to Section 2.2, while a correlation analysis, comparisons of the various potential predictors (which included catchment attributes that were available in the experimental dataset, and daily temperature and precipitation features; see Section 2.1 and Section 2.2) with respect to their importance in regionalizing daily streamflow features, predictive performance comparisons, and a comparison of the daily streamflow features with respect to their predictability were performed according to Section 2.3, Section 2.4, Section 2.5, Section 2.6. The correlation analysis and the feature importance comparisons support the predictive performance investigations within the studied context, as they offer some degree of interpretability and a better understanding of the technical problem under investigation. This latter important objective is also facilitated by the undertaken predictability comparison. The results are presented and discussed in detail with respect to their practical significance in Section 3 and Section 4, respectively. Key recommendations for future research are also provided in Section 4, while the paper concludes with the study summary in Section 5.
2. Methods and Data
2.1. Experimental Dataset
We exploited information encompassed in the Catchment Attributes and MEteorology for Large-sample Studies (CAMELS) dataset, which is available in Newman et al. [36] and Addor et al. [37]. This dataset comprises a variety of catchment attributes, as well as minimum and maximum temperature, precipitation and streamflow time series at the daily time scale, from small- to medium-sized catchments spanning the contiguous United States [38,39], with the temperature and precipitation time series having been obtained by processing data by Thornton et al. [40]. From the entire dataset, we selected 511 geographical locations (see Figure 1), for which complete daily time series are available for the 34-year period between 1980 and 2013. For these specific geographical locations, we averaged the available daily minimum and maximum temperature time series values to compute 34-year-long time series of daily temperature means. These new temperature time series are hereinafter referred to simply as “daily temperature time series”, as they were the ones analysed for feature extraction, together with the originally available daily precipitation and streamflow time series, as described in detail in Section 2.2.
Moreover, we selected the following catchment attributes with continuous values:
- Logarithm of the mean elevation of the catchment (log_elev_mean);
- Logarithm of the mean slope of the catchment (log_slope_mean);
- Logarithm of the GAGESII estimate of the catchment area (log_area_gages2);
- Forest fraction of the catchment (frac_forest);
- Maximum monthly mean of the leaf area index of the catchment (lai_max);
- Green vegetation fraction difference of the catchment (gvf_diff);
- Dominant land cover fraction of the catchment (dom_land_cover_frac);
- Depth to bedrock of the catchment (soil_depth_pelletier);
- Soil depth of the catchment (soil_depth_statsgo);
- Maximum water content of the soil of the catchment (max_water_content);
- Sand fraction of the soil of the catchment (sand_frac);
- Silt fraction of the soil of the catchment (silt_frac);
- Clay fraction of the soil of the catchment (clay_frac);
- Water fraction of the soil of the catchment (water_frac);
- Organic material fraction of the soil of the catchment (organic_frac);
- Fraction of soil of the catchment marked as other (other_frac);
- Carbonate sedimentary rock fraction of the catchment (carbonate_rocks_frac);
- Subsurface porosity of the catchment (geol_porosity);
- Subsurface permeability of the catchment (geol_permeability).
The above-listed catchment attributes include three topographic, four land cover, nine soil and three geologic ones (reported in the same order from the top to the bottom) and are hereinafter referred to as “static catchment features”, to be distinguished from the dynamic catchment features (i.e., the features that were obtained through time series analysis; see Section 2.2).
2.2. Time Series Analysis
We separately characterized each daily temperature, precipitation and streamflow time series (see Section 2.1) by computing its following features:
- Lag-1 sample autocorrelation of the time series (x_acf1);
- Sum of the squared sample autocorrelation values of the time series at the first ten lags (x_acf10);
- Lag-1 sample autocorrelation of the first-order differenced time series (diff1_acf1);
- Sum of the squared sample autocorrelation values of the first-order differenced time series at the first ten lags (diff1_acf10);
- Lag-1 sample autocorrelation of the second-order differenced time series (diff2_acf1);
- Sum of the squared sample autocorrelation values of the second-order differenced time series at the first ten lags (diff2_acf10);
- Lag-365 sample autocorrelation of the time series (seas_acf1);
- Lag at which the first zero crossing of the autocorrelation function is attained (firstzero_ac);
- Sum of the squared sample partial autocorrelation values of the time series at the first five lags (x_pacf5);
- Sum of the squared sample partial autocorrelation values for the first five lags of the first-order differenced time series (diff1x_pacf5);
- Sum of the squared sample partial autocorrelation values for the first five lags of the second-order differenced time series (diff2x_pacf5);
- Lag-365 sample partial autocorrelation (seas_pacf);
- Standard deviation of the first-order differenced time series (std1st_der);
- Number of times that the time series crosses the median (crossing_points);
- Spectral entropy of the time series (entropy);
- Number of flat spots in the time series (flat_spots);
- Lumpiness of the time series (lumpiness);
- Stability of the time series (stability);
- Nonlinearity of the time series (nonlinearity);
- Trend strength of the time series (trend);
- Strength of spikes in the time series (spike);
- Linearity of the time series (linearity);
- Curvature of the time series (curvature);
- Lag-1 sample autocorrelation of the remainder component of the time series, which is obtained after removing the trend and seasonal components (e_acf1);
- Sum of the squared sample autocorrelation values of the remainder component of the time series at the first ten time lags (e_acf10);
- Seasonality strength of the time series (seasonal_strength);
- Strength of peaks in the seasonal component of the time series (peak);
- Strength of troughs in the seasonal component of the time series (trough).
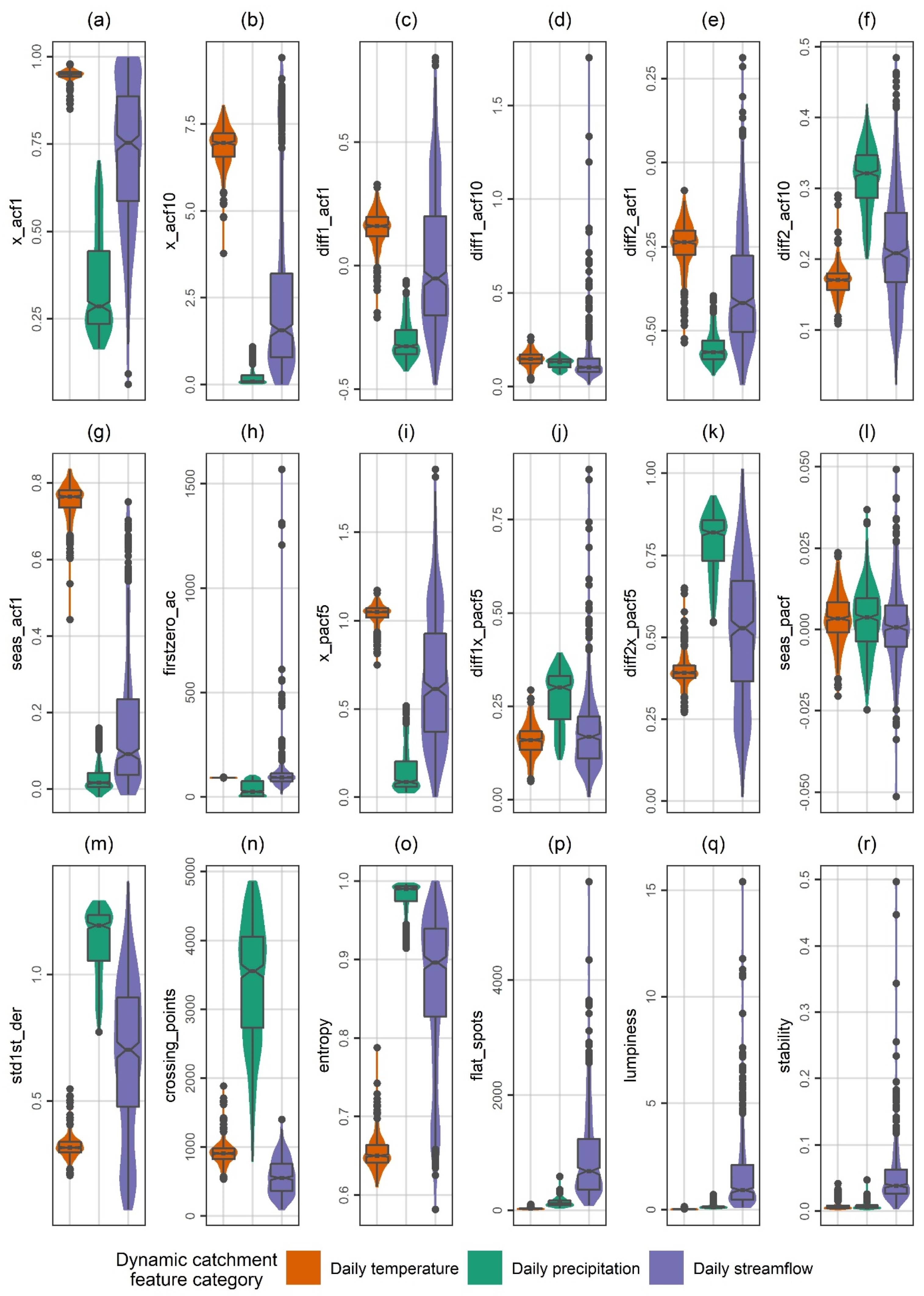
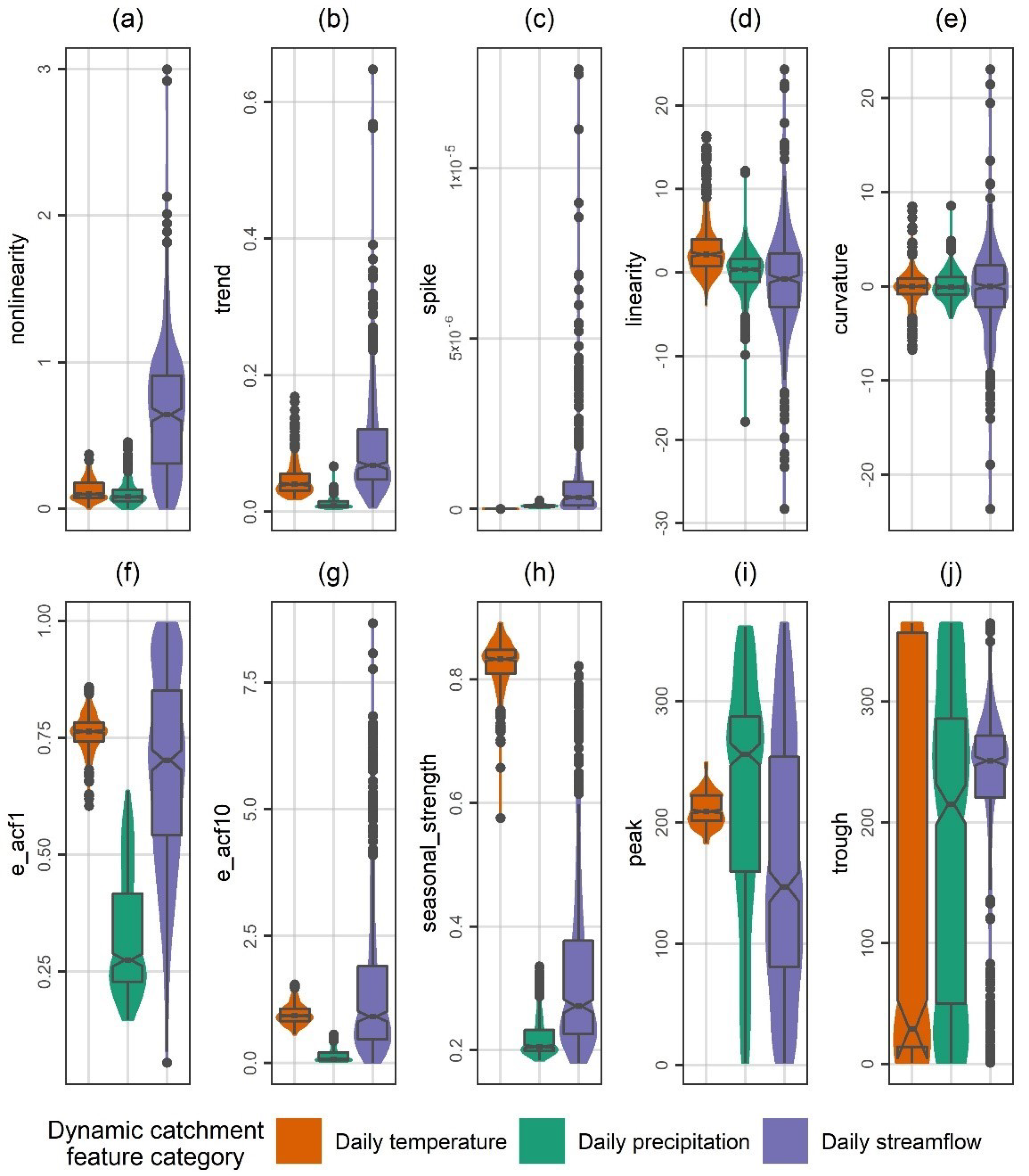
The above-listed features were selected because of their pronounced relevance to the field of stochastic hydrology and because of their interpretability. These features were computed after the time series were scaled to mean 0 and standard deviation 1. Moreover, for the computation of the features diff1_acf1, diff1_acf10, diff2_acf1, diff2_acf10, diff1x_pacf5, diff2x_pacf5 and std1st_der, time series differencing was performed according to Hyndman and Athanasopoulos [41] (Chapter 9.1). For the computation of the features trend, spike, linearity, curvature, e_acf1, e_acf10, seasonal_strength, peak and trough, seasonal and trend decomposition using Loess (STL decomposition) was performed according to Hyndman and Khandakar [42] (see also [41], Chapter 3.6) and by assuming 365 seasons per year. Additional information for (several of) the above-listed features can be found in data science works (e.g., [23,26,28,30,31]) and in books on time series analysis (e.g., [43,44]). This information is herein omitted for reasons of brevity, given also that the boxplot (and violin plot) summaries of the feature values over the 511 investigated catchments can support the perception of the above-provided definitions. These summaries are presented in Appendix B. Hereinafter, the various daily temperature, precipitation and streamflow features are alternatively referred to under the collective term “dynamic catchment features” to be distinguished from the static catchment features (see Section 2.1).
2.3. Correlation Analysis
We investigated the relationships between potential predictor and dependent variables within regression-based streamflow regionalization contexts by computing Spearman correlations [45]. Recall here that the static, daily temperature and daily precipitation features (see Section 2.1 and Section 2.2) were investigated as predictor variables throughout this work, while the daily streamflow features (see Section 2.2) were investigated as dependent variables (see Figure 1). The results of the correlation analysis are presented in Section 3.1.
2.4. Feature Importance Comparisons
We applied explainable machine learning to compare the static, daily temperature and daily precipitation (see Section 2.1 and Section 2.2) with respect to their relevance as potential predictors within the studied context for the daily streamflow features (see Section 2.2). More precisely, we studied 28 regression settings, each devoted to the prediction of a different daily streamflow feature. At each regression setting, we fitted random forests by Breiman [46] with 2000 trees and determined feature importance scores with permutation. This was made by following the unnormalized version of the implementation by Wright and Ziegler [47]. In brief, the applied procedure progresses as follows: For each tree, the mean square error is computed on the out-of-bag data. The same error metric is also computed after permuting each predictor variable. Then, the difference between the two outcomes is averaged over all trees. Once the permutation importance scores were obtained for a regression setting, the potential predictors were ranked based on them. Popularized information on the properties of random forests and their role in water science and informatics can be found in the review by Tyralis et al. [48], while discussions on the role of explainable machine learning in natural sciences can be found in the review by Roscher et al. [49]. The results of the feature importance comparisons are presented in Section 3.2.
2.5. Predictive Performance Comparisons
To further compare the proposed predictor variables with respect to their relevance within the studied context, we investigated the performance of random forests with 2000 trees in predicting the various daily streamflow features (see Section 2.2) using seven different groups of predictor variables. These groups are the following ones (see Section 2.1 and Section 2.2): {static catchment features}, {daily temperature features}, {daily precipitation features}, {static catchment features, daily temperature features}, {static catchment features, daily precipitation features}, {daily temperature features, daily precipitation features}, and {static catchment features, daily temperature features, daily precipitation features}. The respective investigations were conducted under a k-fold cross-validation setting, with k being equal to 10. Under this specific setting, the catchments were grouped into ten groups of approximately equal size. Ten different experiments were then conducted for each set {daily streamflow feature, group of predictor variables}, each time leaving out of the training process a different group of catchments, whose target feature values were subsequently predicted using the trained model and given the values of the predictors (with the target feature considered unknown).
Once the ten different experiments were finalized for a specific set {daily streamflow feature, group of predictor variables}, the root mean square error (RMSE) of the obtained predictions was computed. This computation was made collectively for all the 511 catchments; therefore, 28 (number of daily streamflow features) × 7 (number of groups of predictors) = 196 scores were obtained. Subsequently, and separately for each daily streamflow feature, the seven groups of predictors were ranked from the best (1st) to the worst (7th) based on their corresponding obtained scores. To assess the degree to which the predictive performance can differ when predicting each daily streamflow feature depending on the considered group of predictor variables, relative scores (taking the form of relative improvements in terms of RMSE) were also computed for the seven groups of predictors with respect to the group that comprised only the static catchment features. The results of the predictive performance comparisons are presented in Section 3.3.
2.6. Feature Predictability Comparison
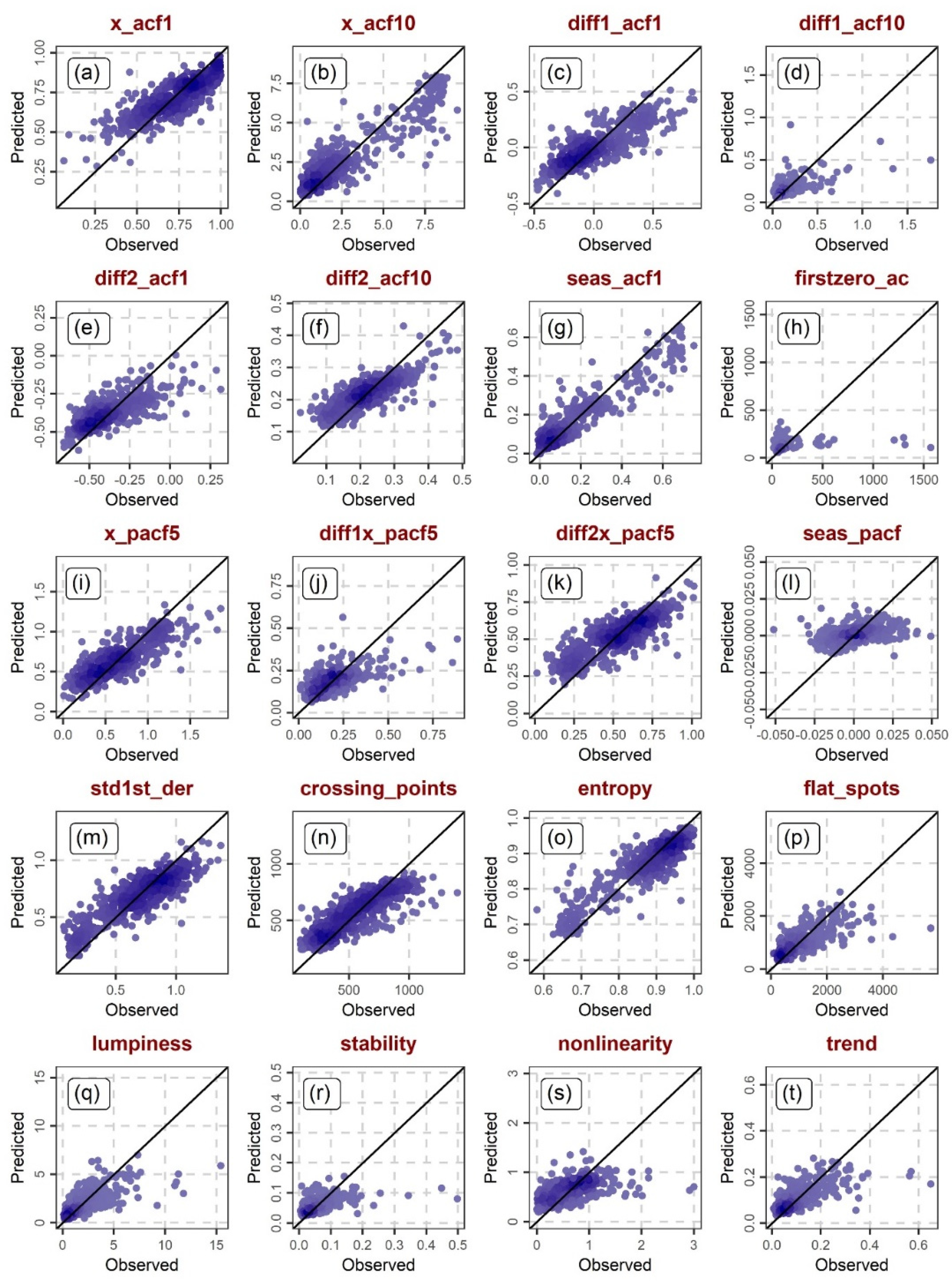
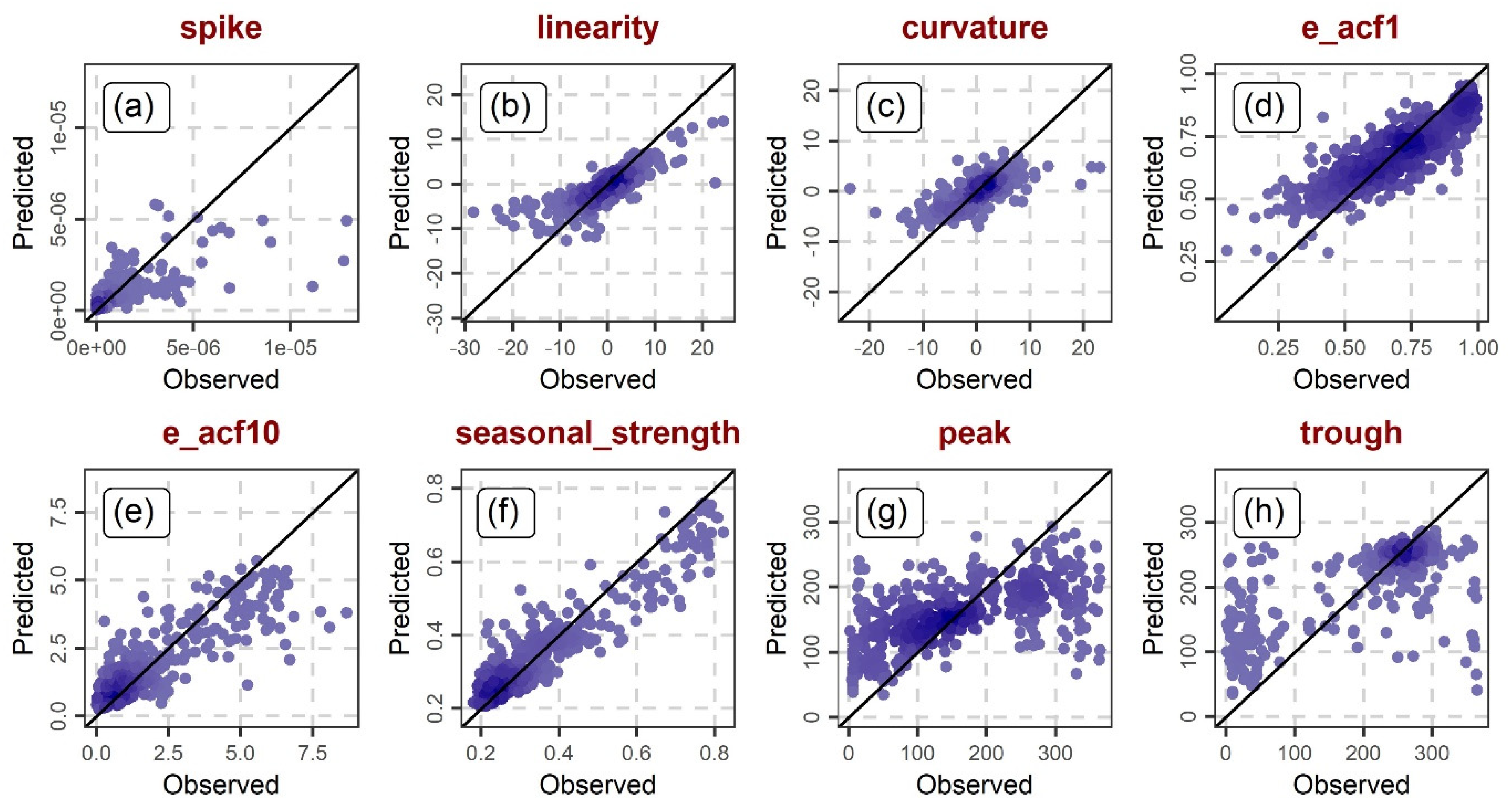
To compare the various daily streamflow features (see Section 2.2) with respect to their predictability within regionalization contexts, we conducted scatterplots of their herein predicted versus observed values for the 511 investigated catchments. The predictions on these scatterplots are those obtained using the total of the static, daily temperature and daily precipitation features (see Section 2.1 and Section 2.2) as predictor variables under a 10-fold cross validation setting (see Section 2.5). The results of the feature predictability comparison are presented in Section 3.4.
3. Results
3.1. Feature Correlations
Figure 2 presents the Spearman correlations between potential predictor and dependent variables within streamflow regionalization contexts. Overall, notable relationships exist that could be exploited for the regionalization of the studied daily streamflow features. As possibly expected, the relationships between daily precipitation and daily streamflow features are mostly more intense than the relationships between daily temperature and daily streamflow features. Still, the stability and trend strength of the daily temperature time series are also found to be notably related to several daily streamflow features. The same holds, to a lesser extent, for a few other daily temperature features. Another observation regards the relationships between daily precipitation and daily streamflow features. Several daily streamflow features (e.g., x_acf1, x_acf10, std1st_der, crossing_points, entropy, curvature, e_acf1, e_acf10) exhibit approximately equally strong relationships with most of the daily precipitation features. Yet, there are also daily streamflow features that are not considerably related to daily precipitation features (e.g., seas_pacf, stability, nonlinearity, peak, trough), as well as others that are either considerably related to only a few daily precipitation features (flat_spots, lumpiness, linearity) or related more to specific daily precipitation features than to others (seas_acf1, spike, seasonal_strength). Among the most considerable relationships revealed by our experiments are also several ones between static catchment features and daily streamflow features. For instance, the mean elevation and the mean slope of the catchment, as well as the sand and clay fractions of its soil, are notably related to many daily streamflow features, including autocorrelation (e.g., x_acf1, x_acf10, seas_acf1), seasonality (seas_acf1, seasonal_strength) and others (e.g., entropy, spike).
3.2. Feature Importance Comparisons
Figure 3 presents the rankings of the static, daily temperature and daily precipitation features according to their usefulness in regionalizing the daily streamflow features. First, we observe that the most useful predictor variables, for most of the daily streamflow features, include catchment features from all the three investigated categories. We also observe that the most (least) relevant daily temperature characteristics within daily streamflow regionalization contexts are not the same as the most (least) relevant daily precipitation characteristics. For example, the features stability and trend of the daily temperature time series stand out for their relevance in predicting several daily streamflow features, while the features of the daily precipitation time series standing out for the same relevance are the following: x_acf1, x_acf10, std1st_der, crossing_points and entropy. This latter list is not exhaustive, with more daily precipitation features (other than stability and trend) being among the most important ones for generalizing streamflow features. Overall, Figure 2 can be used for interpreting Figure 3; however, this interpretation cannot be complete. Indeed, there are relationships of similar magnitudes that correspond to quite distant rankings (see, e.g., the Spearman correlations computed for the daily precipitation features x_acf1, x_acf10, diff1_acf1, diff1_acf10, diff2_acf1, diff2_acf10, seas_acf1, firstzero_ac, x_pacf5, diff1x_pacf5 and diff2x_pacf5 in comparison to their corresponding rankings), probably due to multicollinearity.
3.3. Predictive Performance Comparisons
Figure 4 presents the comparisons of the predictive performance in terms of RMSE of random forests, when the latter are used with seven different groups of predictors for the regionalization of various daily streamflow features. First, we observe that, for half of the daily streamflow features, the use of the total of the static, daily temperature and daily precipitation features as predictor variables offers the smallest RMSE (see Figure 4a). We also observe that, for the remaining daily streamflow features, the relative scores corresponding to the utilization of (a) the total of the static, daily temperature and daily precipitation features as predictors and (b) the best group of predictors differ by less than 4% (see Figure 4b). Furthermore, we observe that, while the static features alone constitute a sufficient group of predictors for some daily streamflow features, they are less informative than daily temperature and/or precipitation features for predicting other daily streamflow features (see Figure 4a). Notably, the utilization of the daily temperature and/or precipitation features as predictors in our experiments, especially when static catchment features were also utilized, led to considerably large predictive performance improvements for several daily streamflow features (seas_acf1, flat_spots, lumpiness, spike, linearity, curvature, seasonal_strength, peak, trough) of up to approximately 17% (see Figure 4b).
3.4. Feature Predictability Comparison
Figure 5 and Figure 6 present examples of predicted versus observed daily streamflow features, thereby allowing us to (roughly) assess and compare the daily streamflow features with respect to their predictability within regionalization contexts. Indeed, this predictability strongly depends on the daily streamflow feature. Examples of daily streamflow features that are notably more difficult than others to regionalize include the following ones: seas_pacf, nonlinearity, peak and trough (see Figure 5l,s and Figure 6g,h). Note here that these four features are also among the least related ones to the static, daily temperature and daily precipitation features (see Figure 2). On the other hand, there are features that stand out because of their high (higher) predictability with regionalization contexts. Such features include, among others, the following ones: x_acf1, seas_acf1, std1st_der, entropy, e_acf1 and seasonal_strength (see Figure 5a,g,m,o and Figure 6d,f).
4. Discussion
Our contribution to the literature consists in the introduction of new methodological elements into the area of regression-based streamflow regionalization, as well as in the successful and extensive utilization of these elements within a detailed framework that aimed to deliver useful insights into (a) the various relationships exploited for the regionalization and (b) the predictability of the streamflow features in the relevant regression settings. Overall, the predictions issued in our experiments were sufficient, given also that their target values do not depend on the magnitude of the time series, in contrast to several hydrological signatures from the catchment hydrology field (see, e.g., part of the ones investigated by Addor et al. [15]; Tyralis et al. [16]). Indeed, it might be more difficult to regionalize streamflow autocorrelation features (and the remaining features examined herein) than it is to regionalize mean annual streamflow (see, e.g., the related notes on the uncertainty in regionalization results by Westerberg et al. [14]). Of course, such comparisons are not covered by our aims and experiments, but they could be the subject of future investigation and discussion.
To our view, one of the most notable findings of this work is that both static and dynamic catchment features are considerably relevant to regionalizing a variety of daily streamflow features, including autocorrelation, entropy, temporal variation, seasonality and other daily streamflow features. More precisely, among the most useful predictors are the mean elevation of the catchment, the spectral entropy, the seasonality strength and the autocorrelation features of the daily precipitation time series, as well as the stability and trend strength of the daily temperature time series. Further than this, we also identified daily streamflow features that are more (or less) difficult to regionalize than others, similar to identifications made regularly for hydrological signatures in catchment hydrology (see, e.g., the work by Addor et al. [15] and its relevant discussions). Interestingly, among the most regionalizable daily streamflow features are the spectral entropy, the seasonality strength and several autocorrelation ones, which are also notably relevant within feature-based time series simulation frameworks (such as the one proposed by Kang et al. [30]) from a conceptual point of view. Given this relevance, the methodological elements introduced in this work could contribute substantially to the reduction of modelling and simulation uncertainties. A further reduction through the regionalization of features that are less difficult to regionalize (and through a possible subsequent formation of feature-based time series simulation frameworks around them and around more regionalizable features) could also be considerable and, as such, is worthy of investigation.
Of course, the above-discussed findings of this work concern the daily time scale only and could differ for other time scales in ways that could be investigated in the future. The various open research pathways also include the simultaneous consideration of the spatial proximity of the stations and time series features for obtaining predictions, as well as the utilization of additional time series features from the stochastic (statistical) hydrology and data science fields, and even the utilization of the concept of massive feature extraction [24,25,27,29] from the latter of the aforementioned fields. In fact, although this work already covers a larger variety and a larger number of time series features than usual in stochastic hydrology, many more time series features are available (see, e.g., the ones investigated by Papacharalampous et al. [34,35]; Hamed [50]; Montanari [51]; Ledvinka [52]; Ledvinka and Lamacova [53]; Juez and Nadal-Romero [54,55]) and could be useful in streamflow regionalization settings, given also the generally acknowledged significance of finding new informative predictors for obtaining improved predictions.
Another open research endeavour rotates around the regression algorithm of the regionalization because of its own core importance for improving streamflow feature predictions in large-sample hydrology. The experiments conducted herein were solely based on random forests. Nonetheless, more regression algorithms (see, e.g., those listed and documented by Hastie et al. [56] and James et al. [57], as well as those investigated in other contexts in hydrometeorology by Tyralis et al. [58] and Zhang and Ye [59]) are worthy of investigation together with a variety of time series features in streamflow regionalization contexts, with boosting being an appealing option among them because of its theoretical properties (see, e.g., [60], Section 3) and its relevance to determining feature importance within explainable machine learning settings. For these same reasons, boosting algorithms were previously proposed and extensively investigated by Tyralis et al. [16] for predicting various hydrological signatures probabilistically. Also notably, methodological elements of this latter work could be borrowed for extending the herein proposed methodological framework for the probabilistic prediction of streamflow features within regionalization settings. Other machine and statistical learning algorithms that could be exploited in a straightforward manner in this regard can be found in Papacharalampous et al. [61] (see also the references therein) and fall into the larger category of quantile regression algorithms. Most of these algorithms base their training on the quantile loss (alternatively referred to as the “pinball loss”) function, the utilization of which was also proposed by Tyralis and Papacharalampous [62] for converting (even more) interpretable models into probabilistic ones.
5. Summary and Conclusions
In this work, we proposed new concepts and methodological elements for supporting the transfer from gauged to ungauged locations of information that is useful for streamflow description and modelling, driven by central themes appearing in stochastic (statistical) hydrology and, at the same time, driven by the observation that these specific themes were scarce in (if not absent from) the previous literature on streamflow regionalization. More precisely, we proposed the estimation of a large variety of time series features (including autocorrelation, partial autocorrelation, entropy, temporal variation, seasonality, trend, lumpiness, stability, nonlinearity, linearity, spikiness, curvature and other features) from large multisite datasets comprising temperature, precipitation and streamflow information and the subsequent transfer of streamflow feature information from gauged to ungauged sites by considering the various temperature and precipitation features, together with other (e.g., traditional) catchment attributes, as predictor variables within regression-based frameworks.
The relevance of the proposed streamflow regionalization strategy was illustrated through extensive large-sample investigations, which were conducted for 511 small- to medium-sized catchments spanning across the contiguous United States, and involved the estimation of 28 time series features for 34-year-long daily temperature, precipitation and streamflow time series originating from these catchments. Once this estimation was complete, the temperature, precipitation and streamflow features were merged with traditional topographic, land cover, soil and geologic attributes within regression-based streamflow regionalization frameworks. In this context, we found the mean elevation of the catchment, the spectral entropy, the seasonality strength and several autocorrelation features of the precipitation time series, as well as the stability and trend strength of the temperature time series, to be among the most useful predictors for many streamflow features, while we additionally provided a possible (rough) interpretation of these specific findings by examining the relationships between the various potential predictor and independent variables in terms of correlations. Lastly, we found spectral entropy, seasonality strength and several autocorrelation features of the streamflow time series to be more regionalizable than others.
Author Contributions
G.P. and H.T. contributed equally to all the aspects of this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data sources are reported in Section 2.1.
Acknowledgments
The authors are sincerely grateful to the Journal for inviting the submission of this paper. They also wish to acknowledge constructive remarks by the Editor and Reviewers.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
The computations and visualizations were performed in R Programming Language [63]. The following contributed R packages were utilized: caret [64], cowplot [65], data.table [66], devtools [67], gdata [68], gridExtra [69], hydroGOF [70], knitr [71,72,73], MASS [74,75], ranger [47,76], rmarkdown [77,78,79], stringi [80], tidyverse [81,82], tsfeatures [31].
Appendix B
Summaries of the dynamic catchment features (see Section 2.2) over the 511 investigated catchments are provided in Figure A1 and Figure A2.
Figure A1.
Summaries over the 511 investigated catchments of the estimated daily temperature, precipitation and streamflow features (part 1). For the explorations and predictions, these dynamic catchment features were merged with static catchment features. The displayed feature abbreviations are explained in Section 2.2.
Figure A1.
Summaries over the 511 investigated catchments of the estimated daily temperature, precipitation and streamflow features (part 1). For the explorations and predictions, these dynamic catchment features were merged with static catchment features. The displayed feature abbreviations are explained in Section 2.2.

Figure A2.
Summaries over the 511 investigated catchments of the estimated daily temperature, precipitation and streamflow features (part 2). For the explorations and predictions, these dynamic catchment features were merged with static catchment features. The displayed feature abbreviations are explained in Section 2.2.
Figure A2.
Summaries over the 511 investigated catchments of the estimated daily temperature, precipitation and streamflow features (part 2). For the explorations and predictions, these dynamic catchment features were merged with static catchment features. The displayed feature abbreviations are explained in Section 2.2.

References
- He, Y.; Bárdossy, A.; Zehe, E. A review of regionalisation for continuous streamflow simulation. Hydrol. Earth Syst. Sci. 2011, 15, 3539–3553. [Google Scholar] [CrossRef] [Green Version]
- Sivapalan, M.; Takeuchi, K.; Franks, S.W.; Gupta, V.K.; Karambiri, H.; Lakshmi, V.; Liang, X.; McDonnell, J.J.; Mediondo, E.M.; O’Connell, P.E.; et al. IAHS Decade on Predictions in Ungauged Basins (PUB), 2003–2012: Shaping an exciting future for the hydrological sciences. Hydrol. Sci. J. 2003, 48, 857–880. [Google Scholar] [CrossRef] [Green Version]
- Hrachowitz, M.; Savenije, H.H.G.; Blöschl, G.; McDonnell, J.J.; Sivapalan, M.; Pomeroy, J.W.; Arheimer, B.; Blume, T.; Clark, M.P.; Ehret, U.; et al. A decade of Predictions in Ungauged Basins (PUB)—A review. Hydrol. Sci. J. 2013, 58, 1198–1255. [Google Scholar] [CrossRef]
- Montanari, A.; Young, G.; Savenije, H.H.G.; Hughes, D.; Wagener, T.; Ren, L.L.; Koutsoyiannis, D.; Cudennec, C.; Toth, E.; Grimaldi, S.; et al. “Panta Rhei—Everything Flows”: Change in hydrology and society—The IAHS Scientific Decade 2013–2022. Hydrol. Sci. J. 2013, 58, 1256–1275. [Google Scholar] [CrossRef]
- Blöschl, G.; Bierkens, M.F.P.; Chambel, A.; Cudennec, C.; Destouni, G.; Fiori, A.; Kirchner, J.W.; McDonnell, J.J.; Savenije, H.H.G.; Sivapalan, M.; et al. Twenty-three Unsolved Problems in Hydrology (UPH)—A community perspective. Hydrol. Sci. J. 2019, 64, 1141–1158. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Zhang, Y.; Zhang, L.; Wang, Z. Regionalization of hydrological modeling for predicting streamflow in ungauged catchments: A comprehensive review. Wiley Interdiscip. Rev. Water 2021, 8, e1487. [Google Scholar] [CrossRef]
- Merz, R.; Blöschl, G. Flood frequency regionalisation—Spatial proximity vs. catchment attributes. J. Hydrol. 2005, 302, 283–306. [Google Scholar] [CrossRef]
- Aziz, K.; Rahman, A.; Fang, G.; Shrestha, S. Application of artificial neural networks in regional flood frequency analysis: A case study for Australia. Stoch. Environ. Res. Risk Assess. 2014, 28, 541–554. [Google Scholar] [CrossRef]
- Rahman, A.; Haddad, K.; Kuczera, G.; Weinmann, P.E. Regional flood methods. In Australian Rainfall and Runoff: A Guide To Flood Estimation. Book 3, Peak Flow Estimation; Ball, J., Babister, M., Nathan, R., Weeks, B., Weinmann, E., Retallick, M., Testoni, I., Eds.; Commonwealth of Australia: Clayton, Australia, 2019; pp. 105–146. [Google Scholar]
- Tyralis, H.; Papacharalampous, G.A.; Tantanee, S. How to explain and predict the shape parameter of the generalized extreme value distribution of streamflow extremes using a big dataset. J. Hydrol. 2019, 574, 628–645. [Google Scholar] [CrossRef]
- Rahman, A.S.; Khan, Z.; Rahman, A. Application of independent component analysis in regional flood frequency analysis: Comparison between quantile regression and parameter regression techniques. J. Hydrol. 2020, 581, 124372. [Google Scholar] [CrossRef]
- Fischer, S.; Schumann, A.H. Regionalisation of flood frequencies based on flood type-specific mixture distributions. J. Hydrol. X 2021, 13, 100107. [Google Scholar] [CrossRef]
- Beck, H.E.; de Roo, A.; van Dijk, A.I.J.M. Global maps of streamflow characteristics based on observations from several thousand catchments. J. Hydrometeorol. 2015, 16, 1478–1501. [Google Scholar] [CrossRef]
- Westerberg, I.K.; Wagener, T.; Coxon, G.; McMillan, H.K.; Castellarin, A.; Montanari, A.; Freer, J. Uncertainty in hydrological signatures for gauged and ungauged catchments. Water Resour. Res. 2016, 52, 1847–1865. [Google Scholar] [CrossRef] [Green Version]
- Addor, N.; Nearing, G.; Prieto, C.; Newman, A.J.; Le Vine, N.; Clark, M.P. A ranking of hydrological signatures based on their predictability in space. Water Resour. Res. 2018, 54, 8792–8812. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A.; Langousis, A.; Papalexiou, S.M. Explanation and probabilistic prediction of hydrological signatures with statistical boosting algorithms. Remote Sens. 2021, 13, 333. [Google Scholar] [CrossRef]
- Laimighofer, J.; Melcher, M.; Laaha, G. Parsimonious statistical learning models for low-flow estimation. Hydrol. Earth Syst. Sci. 2022, 26, 129–148. [Google Scholar] [CrossRef]
- McMillan, H.; Westerberg, I.; Branger, F. Five guidelines for selecting hydrological signatures. Hydrol. Process. 2017, 31, 4757–4761. [Google Scholar] [CrossRef] [Green Version]
- McMillan, H. Linking hydrologic signatures to hydrologic processes: A review. Hydrol. Process. 2020, 34, 1393–1409. [Google Scholar] [CrossRef]
- Parajka, J.; Merz, R.; Blöschl, G. A comparison of regionalisation methods for catchment model parameters. Hydrol. Earth Syst. Sci. 2005, 9, 157–171. [Google Scholar] [CrossRef] [Green Version]
- Oudin, L.; Andréassian, V.; Perrin, C.; Michel, C.; Le Moine, N. Spatial proximity, physical similarity, regression and ungagged catchments: A comparison of regionalization approaches based on 913 French catchments. Water Resour. Res. 2008, 44, W03413. [Google Scholar] [CrossRef]
- Pool, S.; Vis, M.; Seibert, J. Regionalization for ungauged catchments—Lessons learned from a comparative large-sample study. Water Resour. Res. 2021, 57, e2021WR030437. [Google Scholar] [CrossRef]
- Wang, X.; Smith, K.; Hyndman, R.J. Characteristic-based clustering for time series data. Data Min. Knowl. Discov. 2006, 13, 335–364. [Google Scholar] [CrossRef]
- Fulcher, B.D.; Little, M.A.; Jones, N.S. Highly comparative time-series analysis: The empirical structure of time series and their methods. J. R. Soc. Interface 2013, 10, 20130048. [Google Scholar] [CrossRef] [PubMed]
- Fulcher, B.D.; Jones, N.S. Highly comparative feature-based time-series classification. IEEE Trans. Knowl. Data Eng. 2014, 26, 3026–3037. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Wang, E.; Laptev, N. Large-Scale Unusual Time Series Detection. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14−17 November 2015; pp. 1616–1619. [Google Scholar] [CrossRef]
- Fulcher, B.D.; Jones, N.S. hctsa: A computational framework for automated time-series phenotyping using massive feature extraction. Cell Syst. 2017, 5, 527–531. [Google Scholar] [CrossRef]
- Kang, Y.; Hyndman, R.J.; Smith-Miles, K. Visualising forecasting algorithm performance using time series instance spaces. Int. J. Forecast. 2017, 33, 345–358. [Google Scholar] [CrossRef] [Green Version]
- Fulcher, B.D. Feature-based time-series analysis. In Feature Engineering for Machine Learning and Data Analytics; Dong, G., Liu, H., Eds.; CRC Press: Boca Raton, FL, USA, 2018; pp. 87–116. [Google Scholar]
- Kang, Y.; Hyndman, R.J.; Li, F. GRATIS: GeneRAting TIme Series with diverse and controllable characteristics. Stat. Anal. Data Min. ASA Data Sci. J. 2020, 13, 354–376. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Kang, Y.; Montero-Manso, P.; Talagala, T.; Wang, E.; Yang, Y.; O’Hara-Wild, M. tsfeatures: Time Series Feature Extraction. R Package Version 1.0.2. 2020. Available online: https://CRAN.R-project.org/package=tsfeatures (accessed on 4 April 2022).
- Papacharalampous, G.A.; Tyralis, H. Hydrological time series forecasting using simple combinations: Big data testing and investigations on one-year ahead river flow predictability. J. Hydrol. 2020, 590, 125205. [Google Scholar] [CrossRef]
- Donoho, D. 50 years of data science. J. Comput. Graph. Stat. 2017, 26, 745–766. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Papalexiou, S.M.; Langousis, A.; Khatami, S.; Volpi, E.; Grimaldi, S. Global-scale massive feature extraction from monthly hydroclimatic time series: Statistical characterizations, spatial patterns and hydrological similarity. Sci. Total Environ. 2021, 767, 144612. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Pechlivanidis, I.; Grimaldi, S.; Volpi, E. Massive feature extraction for explaining and foretelling hydroclimatic time series forecastability at the global scale. Geosci. Front. 2022, 13, 101349. [Google Scholar] [CrossRef]
- Newman, A.J.; Sampson, K.; Clark, M.P.; Bock, A.; Viger, R.J.; Blodgett, D. A Large-Sample Watershed-Scale Hydrometeorological Dataset for the Contiguous USA; UCAR/NCAR: Boulder, CO, USA, 2014. [Google Scholar] [CrossRef]
- Addor, N.; Newman, A.J.; Mizukami, N.; Clark, M.P. Catchment Attributes for Large-Sample Studies; UCAR/NCAR: Boulder, CO, USA, 2017. [Google Scholar] [CrossRef]
- Newman, A.J.; Clark, M.P.; Sampson, K.; Wood, A.; Hay, L.E.; Bock, A.; Viger, R.J.; Blodgett, D.; Brekke, L.; Arnold, J.R.; et al. Development of a large-sample watershed-scale hydrometeorological data set for the contiguous USA: Data set characteristics and assessment of regional variability in hydrologic model performance. Hydrol. Earth Syst. Sci. 2015, 19, 209–223. [Google Scholar] [CrossRef] [Green Version]
- Addor, N.; Newman, A.J.; Mizukami, N.; Clark, M.P. The CAMELS data set: Catchment attributes and meteorology for large-sample studies. Hydrol. Earth Syst. Sci. 2017, 21, 5293–5313. [Google Scholar] [CrossRef] [Green Version]
- Thornton, P.E.; Thornton, M.M.; Mayer, B.W.; Wilhelmi, N.; Wei, Y.; Devarakonda, R.; Cook, R.B. Daymet: Daily Surface Weather Data on a 1-km Grid for North America, Version 2; ORNL DAAC: Oak Ridge, TN, USA, 2014. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice, 3rd ed.; OTexts: Melbourne, Australia, 2021; Available online: https://otexts.com/fpp3 (accessed on 4 April 2022).
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day Inc.: San Francisco, CA, USA, 1970. [Google Scholar]
- Wei, W.W.S. Time Series Analysis, Univariate and Multivariate Methods, 2nd ed.; Pearson Addison Wesley: Boston, MA, USA, 2006. [Google Scholar]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Wright, M.N.; Ziegler, A. ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Tyralis, H.; Papacharalampous, G.A.; Langousis, A. A brief review of random forests for water scientists and practitioners and their recent history in water resources. Water 2019, 11, 910. [Google Scholar] [CrossRef] [Green Version]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable machine learning for scientific insights and discoveries. IEEE Access 2020, 8, 42200–42216. [Google Scholar] [CrossRef]
- Hamed, K.H. Trend detection in hydrologic data: The Mann-Kendall trend test under the scaling hypothesis. J. Hydrol. 2008, 349, 350–363. [Google Scholar] [CrossRef]
- Montanari, A. Hydrology of the Po River: Looking for changing patterns in river discharge. Hydrol. Earth Syst. Sci. 2012, 16, 3739–3747. [Google Scholar] [CrossRef] [Green Version]
- Ledvinka, O. Evolution of low flows in Czechia revisited. Proc. Int. Assoc. Hydrol. Sci. 2015, 369, 87–95. [Google Scholar] [CrossRef]
- Ledvinka, O.; Lamacova, A. Detection of field significant long-term monotonic trends in spring yields. Stoch. Environ. Res. Risk Assess. 2015, 29, 1463–1484. [Google Scholar] [CrossRef]
- Juez, C.; Nadal-Romero, E. Long-term time-scale bonds between discharge regime and catchment specific landscape traits in the Spanish Pyrenees. Environ. Res. 2020, 191, 110158. [Google Scholar] [CrossRef] [PubMed]
- Juez, C.; Nadal-Romero, E. Long-term temporal structure of catchment sediment response to precipitation in a humid mountain badland area. J. Hydrol. 2021, 597, 125723. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A.; Langousis, A. Super ensemble learning for daily streamflow forecasting: Large-scale demonstration and comparison with multiple machine learning algorithms. Neural Comput. Appl. 2021, 33, 3053–3068. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, A. Machine learning for precipitation forecasts postprocessing: Multimodel comparison and experimental investigation. J. Hydrometeorol. 2021, 22, 3065–3085. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.A. Boosting algorithms in energy research: A systematic review. Neural Comput. Appl. 2021, 33, 14101–14117. [Google Scholar] [CrossRef]
- Papacharalampous, G.A.; Tyralis, H.; Langousis, A.; Jayawardena, A.W.; Sivakumar, B.; Mamassis, N.; Montanari, A.; Koutsoyiannis, D. Probabilistic hydrological post-processing at scale: Why and how to apply machine-learning quantile regression algorithms. Water 2019, 11, 2126. [Google Scholar] [CrossRef] [Green Version]
- Tyralis, H.; Papacharalampous, G.A. Quantile-based hydrological modelling. Water 2021, 13, 3420. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org (accessed on 4 April 2022).
- Kuhn, M. caret: Classification and Regression Training. R Package Version 6.0-88. 2021. Available online: https://CRAN.R-project.org/package=caret (accessed on 4 April 2022).
- Wilke, C.O. cowplot: Streamlined Plot Theme and Plot Annotations for ‘ggplot2’. R Package Version 1.1.1. 2020. Available online: https://CRAN.R-project.org/package=cowplot (accessed on 4 April 2022).
- Dowle, M.; Srinivasan, A. data.table: Extension of ‘Data.Frame‘. R Package Version 1.14.0. 2021. Available online: https://CRAN.R-project.org/package=data.table (accessed on 4 April 2022).
- Wickham, H.; Hester, J.; Chang, W. devtools: Tools to Make Developing R Packages Easier. R Package Version 2.4.2. 2021. Available online: https://CRAN.R-project.org/package=devtools (accessed on 4 April 2022).
- Warnes, G.R.; Bolker, B.; Gorjanc, G.; Grothendieck, G.; Korosec, A.; Lumley, T.; MacQueen, D.; Magnusson, A.; Rogers, J. gdata: Various R Programming Tools for Data Manipulation. R Package Version 2.18.0. 2017. Available online: https://CRAN.R-project.org/package=gdata (accessed on 4 April 2022).
- Auguie, B. gridExtra: Miscellaneous Functions for “Grid” Graphics. R Package Version 2.3. 2017. Available online: https://CRAN.R-project.org/package=gridExtra (accessed on 4 April 2022).
- Zambrano-Bigiarini, M. hydroGOF: Goodness-of-Fit Functions for Comparison of Simulated and Observed Hydrological Time Series. R Package Version 0.4-0. 2020. Available online: https://CRAN.R-project.org/package=hydroGOF (accessed on 4 April 2022).
- Xie, Y. knitr: A Comprehensive Tool for Reproducible Research in R. In Implementing Reproducible Computational Research; Stodden, V., Leisch, F., Peng, R.D., Eds.; Chapman and Hall/CRC: London, UK, 2014. [Google Scholar]
- Xie, Y. Dynamic Documents with R and Knitr, 2nd ed.; Chapman and Hall/CRC: London, UK, 2015. [Google Scholar]
- Xie, Y. knitr: A General-Purpose Package for Dynamic Report Generation in R. R Package Version 1.34. 2021. Available online: https://CRAN.R-project.org/package=knitr (accessed on 4 April 2022).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Ripley, B. MASS: Support Functions and Datasets for Venables and Ripley’s MASS. R Package Version 7.3-54. 2021. Available online: https://cran.r-project.org/package=MASS (accessed on 4 April 2022).
- Wright, M.N. ranger: A Fast Implementation of Random Forests. R Package Version 0.13.1. 2021. Available online: https://CRAN.R-project.org/package=ranger (accessed on 4 April 2022).
- Xie, Y.; Allaire, J.J.; Grolemund, G. R Markdown, 1st ed.; Chapman and Hall/CRC: London, UK, 2018; ISBN 9781138359338. [Google Scholar]
- Xie, Y.; Dervieux, C.; Riederer, E. R Markdown Cookbook; Chapman and Hall/CRC: London, UK, 2020; ISBN 9780367563837. [Google Scholar]
- Allaire, J.J.; Xie, Y.; McPherson, J.; Luraschi, J.; Ushey, K.; Atkins, A.; Wickham, H.; Cheng, J.; Chang, W.; Iannone, R. rmarkdown: Dynamic Documents for R. R Package Version 2.11. 2021. Available online: https://CRAN.R-project.org/package=rmarkdown (accessed on 4 April 2022).
- Gagolewski, M. stringi: Character String Processing Facilities. R Package Version 1.7.4. 2021. Available online: https://CRAN.R-project.org/package=stringi (accessed on 4 April 2022).
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; D’Agostino McGowan, L.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
- Wickham, H. tidyverse: Easily Install and Load the ‘Tidyverse’. R Package Version 1.3.1. 2021. Available online: https://CRAN.R-project.org/package=tidyverse (accessed on 4 April 2022).
Figure 1.
Schematic summarizing the experimental dataset and methodology.

Figure 2.
Spearman correlations between potential predictor and dependent variables of the investigated technical problem. The displayed feature abbreviations are explained in Section 2.1 and Section 2.2.
Figure 2.
Spearman correlations between potential predictor and dependent variables of the investigated technical problem. The displayed feature abbreviations are explained in Section 2.1 and Section 2.2.

Figure 3.
Rankings of potential predictor variables according to their importance in predicting various daily streamflow features. The displayed feature abbreviations are explained in Section 2.1 and Section 2.2.
Figure 3.
Rankings of potential predictor variables according to their importance in predicting various daily streamflow features. The displayed feature abbreviations are explained in Section 2.1 and Section 2.2.

Figure 4.
Performance comparisons between seven prediction methods that use random forest with different catchment feature groups as predictor variables. These comparisons were made over the 511 investigated catchments under a 10-fold cross-validation setting. They take the form of (a) rankings of the predictor variable groups from the best (1st) to the worst (7th) performing in terms of root mean square error, and (b) relative performance differences (%) with respect to using only the static features as predictor variables. The displayed feature abbreviations are explained in Section 2.2.
Figure 4.
Performance comparisons between seven prediction methods that use random forest with different catchment feature groups as predictor variables. These comparisons were made over the 511 investigated catchments under a 10-fold cross-validation setting. They take the form of (a) rankings of the predictor variable groups from the best (1st) to the worst (7th) performing in terms of root mean square error, and (b) relative performance differences (%) with respect to using only the static features as predictor variables. The displayed feature abbreviations are explained in Section 2.2.

Figure 5.
Predicted versus observed daily streamflow features for the 511 investigated catchments when using as predictor variables the total of the static, daily temperature and daily precipitation features under a 10-fold cross-validation setting (part 1). The displayed feature abbreviations are explained in Section 2.2.
Figure 5.
Predicted versus observed daily streamflow features for the 511 investigated catchments when using as predictor variables the total of the static, daily temperature and daily precipitation features under a 10-fold cross-validation setting (part 1). The displayed feature abbreviations are explained in Section 2.2.

Figure 6.
Predicted versus observed daily streamflow features for the 511 investigated catchments when using the total of the static, daily temperature and daily precipitation features as predictor variables under a 10-fold cross validation setting (part 2). The displayed feature abbreviations are explained in Section 2.2.
Figure 6.
Predicted versus observed daily streamflow features for the 511 investigated catchments when using the total of the static, daily temperature and daily precipitation features as predictor variables under a 10-fold cross validation setting (part 2). The displayed feature abbreviations are explained in Section 2.2.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Papacharalampous, G.; Tyralis, H. Time Series Features for Supporting Hydrometeorological Explorations and Predictions in Ungauged Locations Using Large Datasets. Water 2022, 14, 1657. https://0-doi-org.brum.beds.ac.uk/10.3390/w14101657
AMA Style
Papacharalampous G, Tyralis H. Time Series Features for Supporting Hydrometeorological Explorations and Predictions in Ungauged Locations Using Large Datasets. Water. 2022; 14(10):1657. https://0-doi-org.brum.beds.ac.uk/10.3390/w14101657
Chicago/Turabian StylePapacharalampous, Georgia, and Hristos Tyralis. 2022. "Time Series Features for Supporting Hydrometeorological Explorations and Predictions in Ungauged Locations Using Large Datasets" Water 14, no. 10: 1657. https://0-doi-org.brum.beds.ac.uk/10.3390/w14101657
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.