
A Water Consumption Forecasting Model by Using a Nonlinear Autoregressive Network with Exogenous Inputs Based on Rough Attributes

Abstract
:1. Introduction
2. Methodologies
2.1. Rough Set Theory
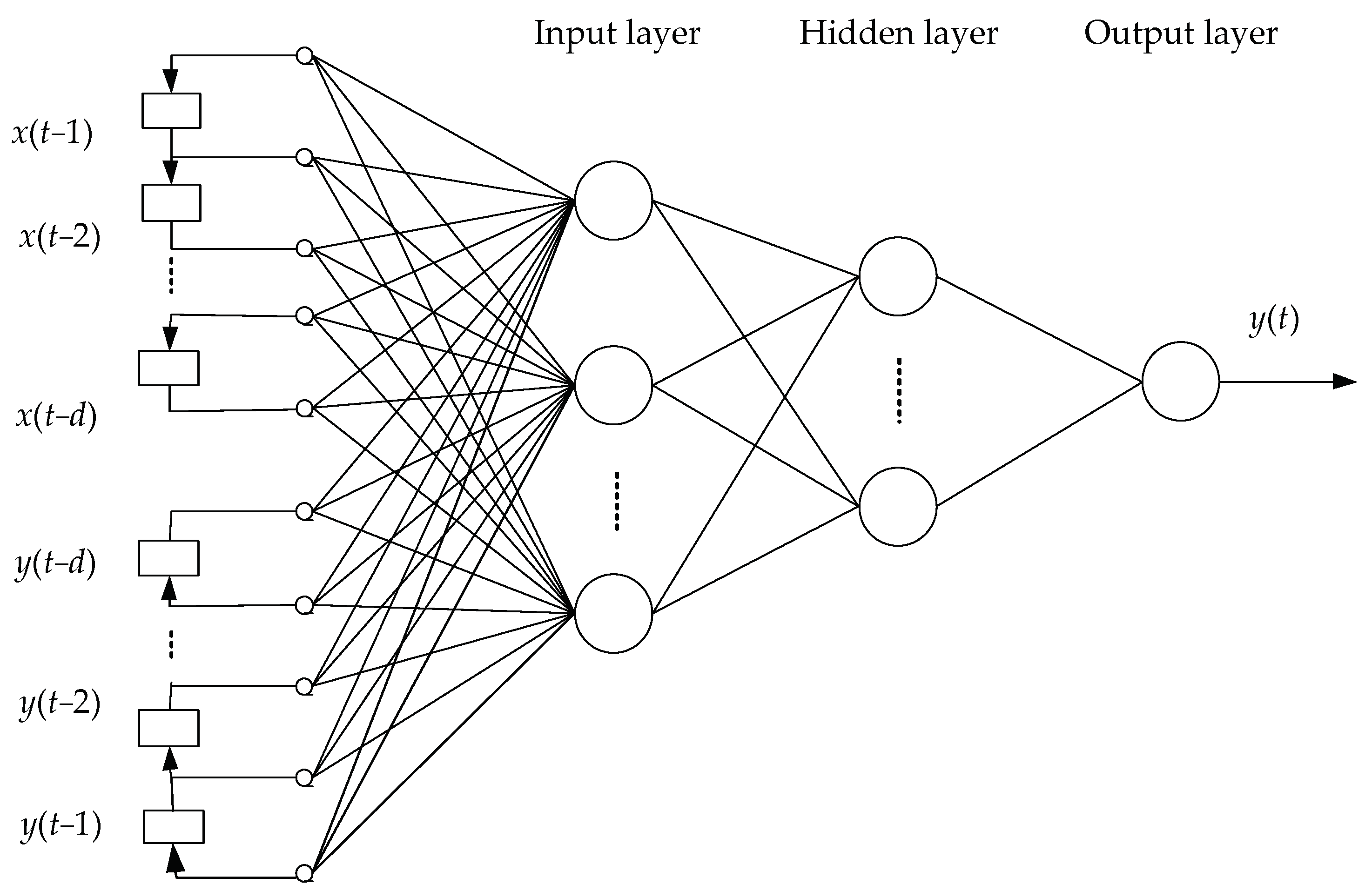
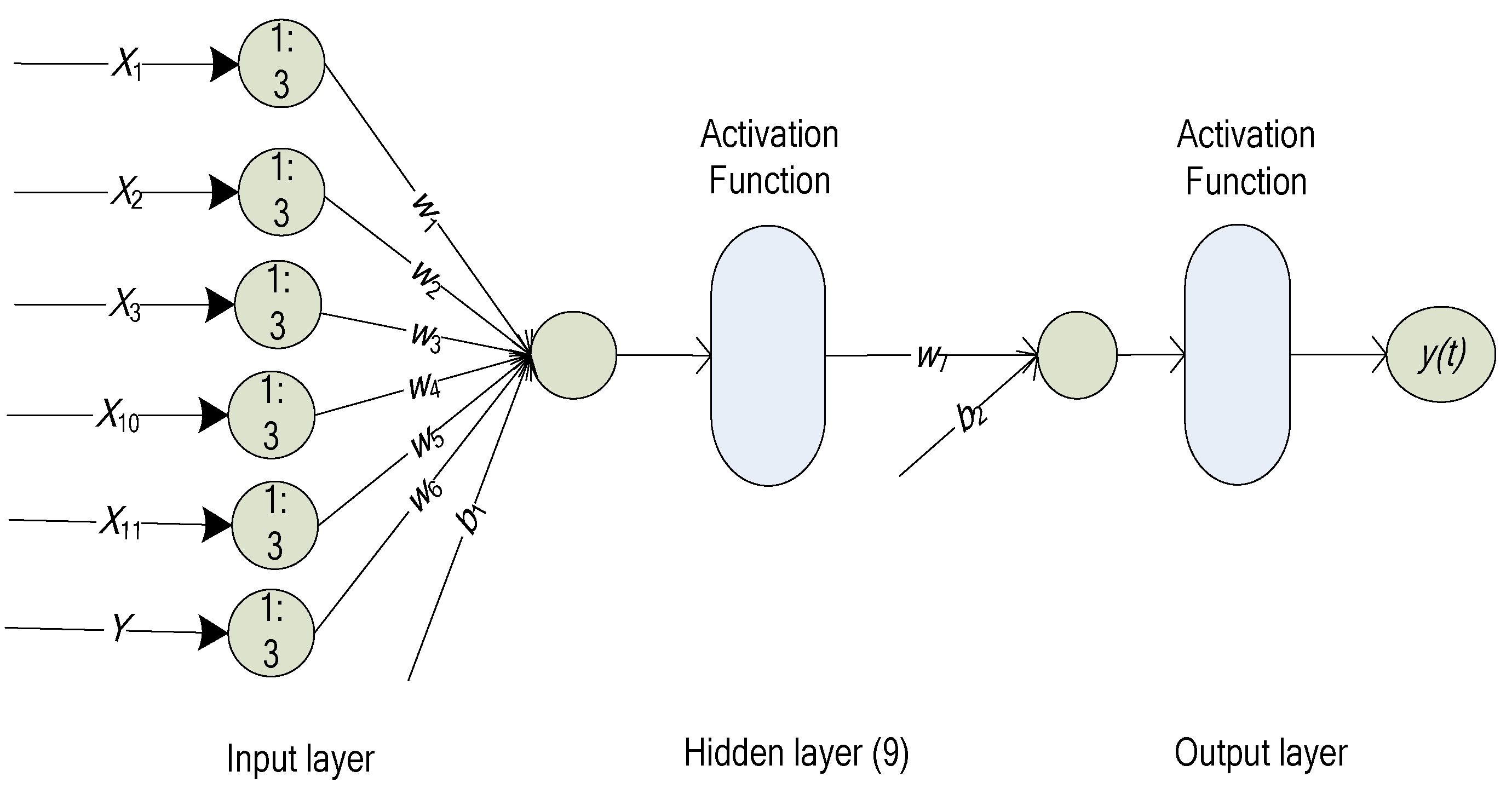
2.2. NARX Neural Network
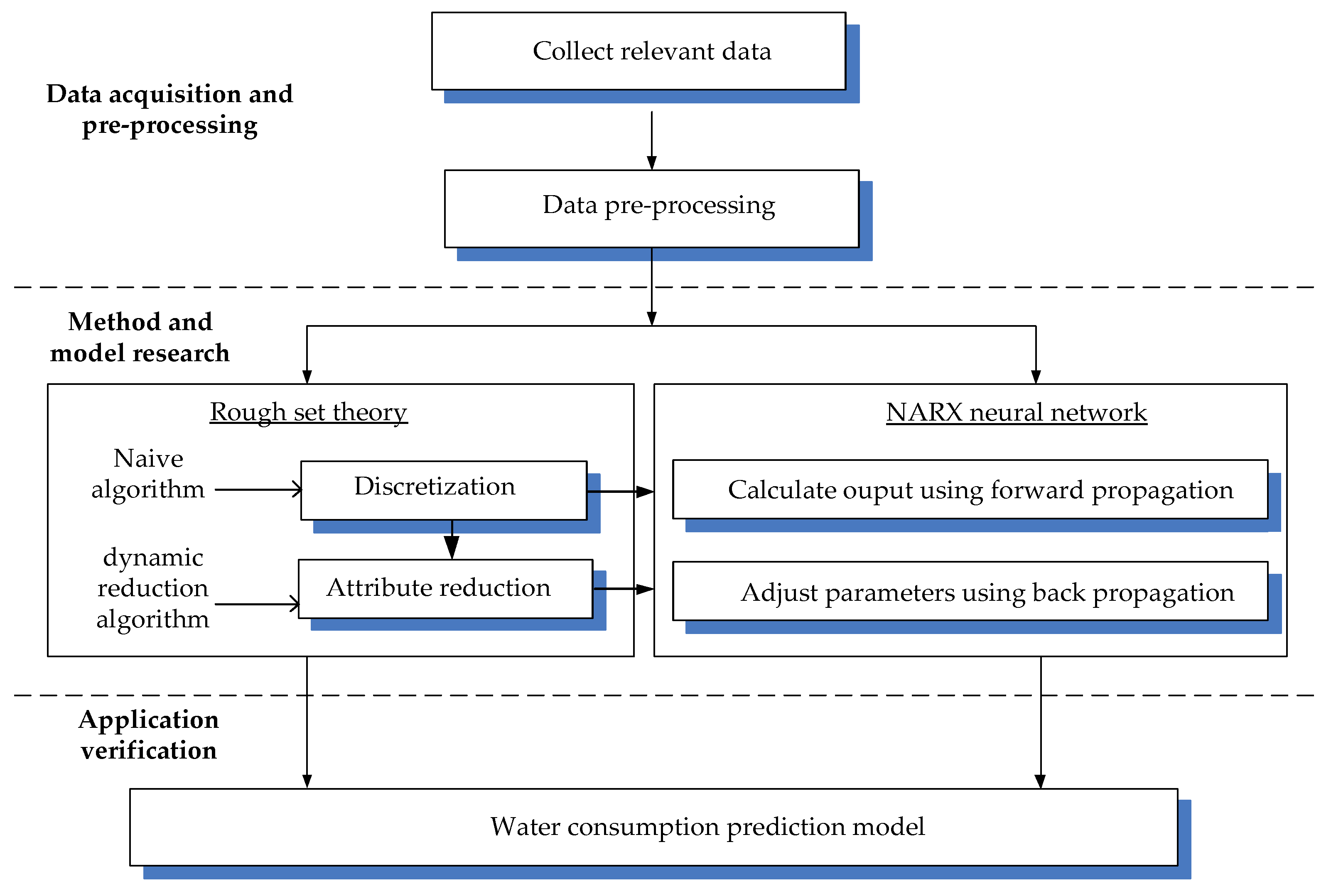
2.3. A Water Consumption Prediction Model Based on the RS–NARX Neural Network
- Step 1:
- Data preparation. Collect relevant data.
- Step 2:
- Data discretization. The continuous data is discretized using the Naive algorithm [32].
- Step 3:
- Attribute reduction. The dynamic reduction algorithm [33] is used to perform attribute reduction, and the importance of each attribute is obtained.
- Step 4:
- Train the NARX neural network.
- (1)
- Establish a NARX network structure.
- (2)
- Determine the parameters (the number of hidden layers and the number of delays) in the NARX neural network.
- (3)
- Train the NARX neural network.
- Step 5:
- Obtain the predicted value.
3. Data Description and Evaluation Indexes
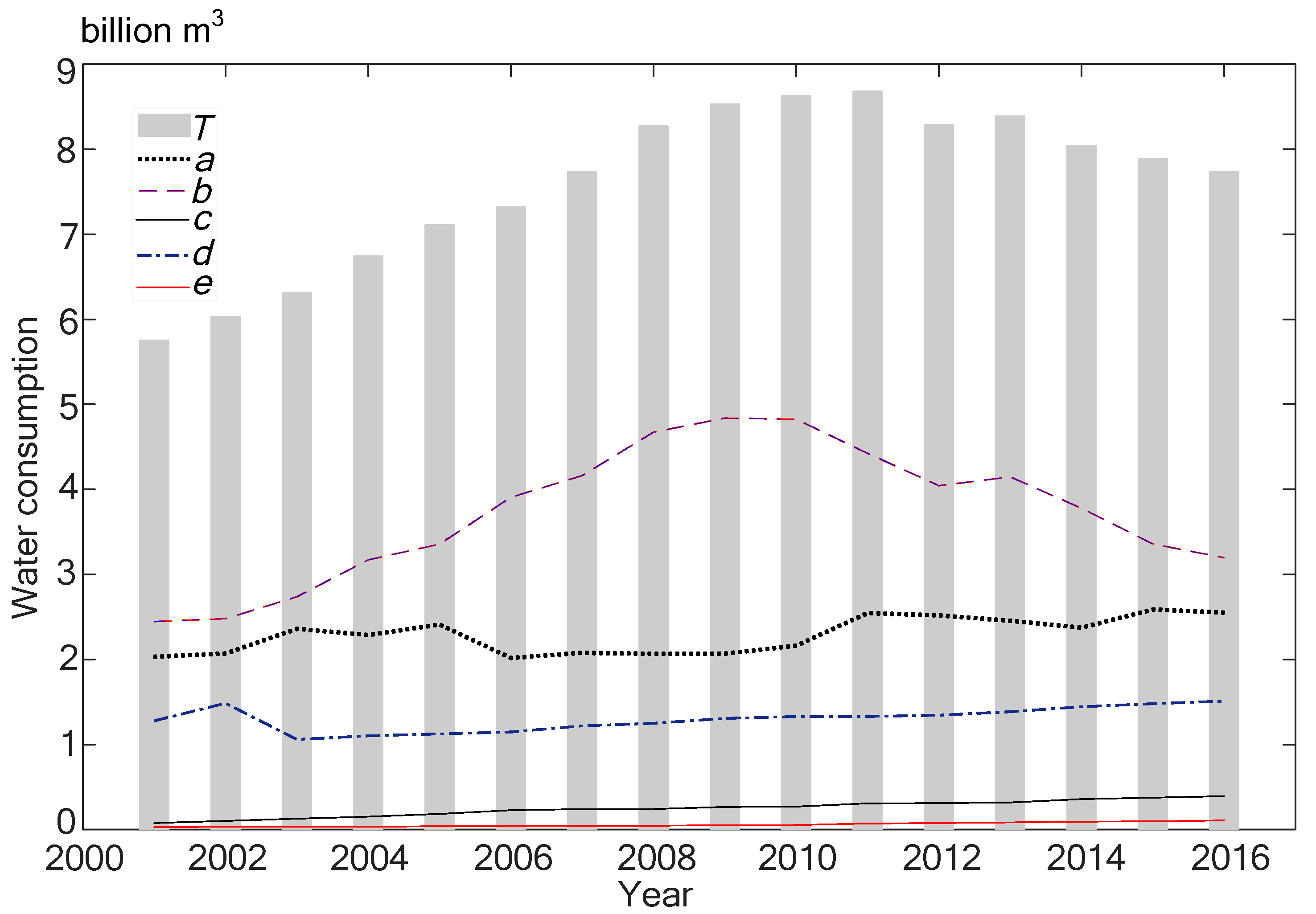
3.1. Data Description
3.2. Evaluation Indexes
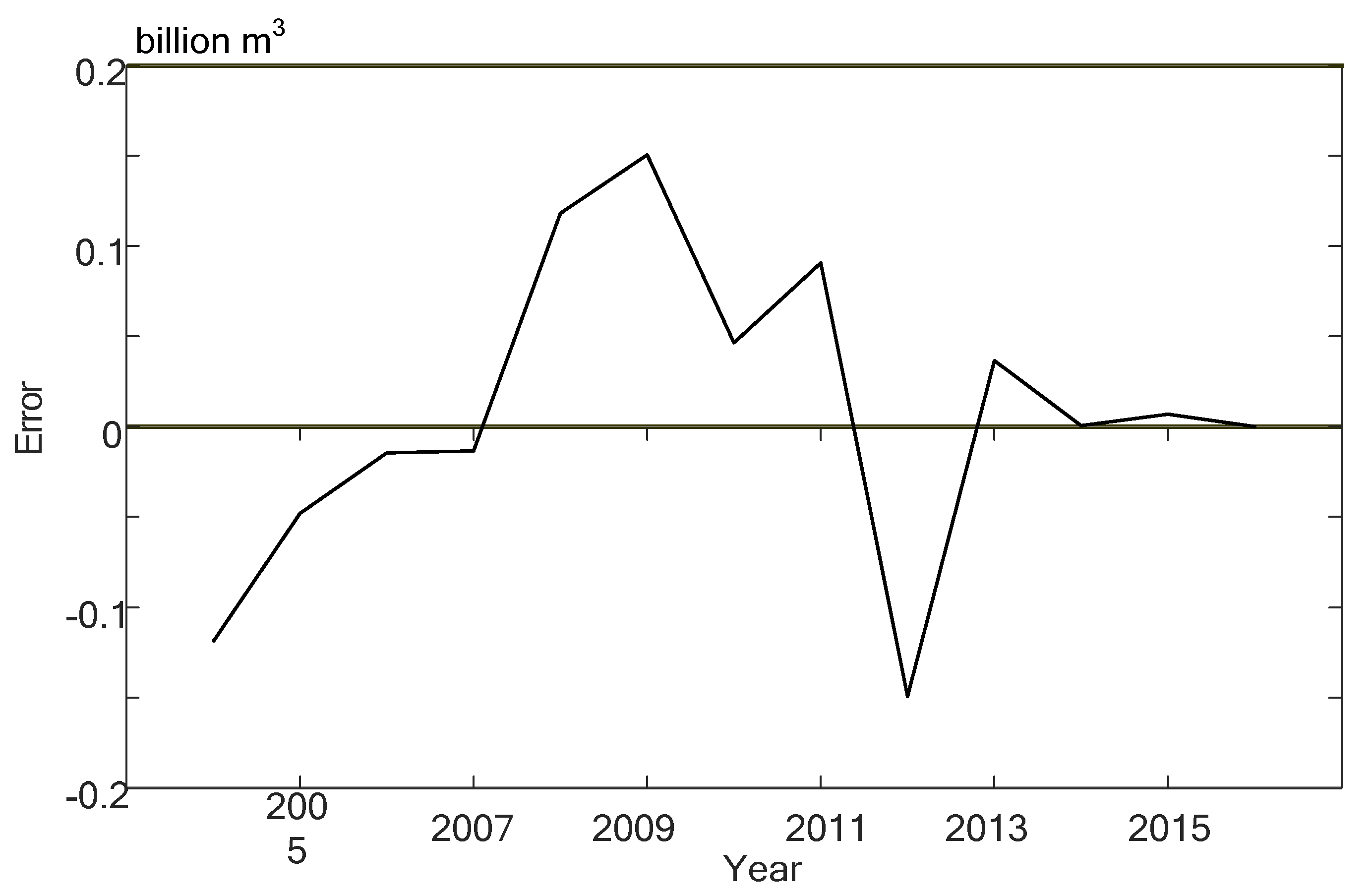
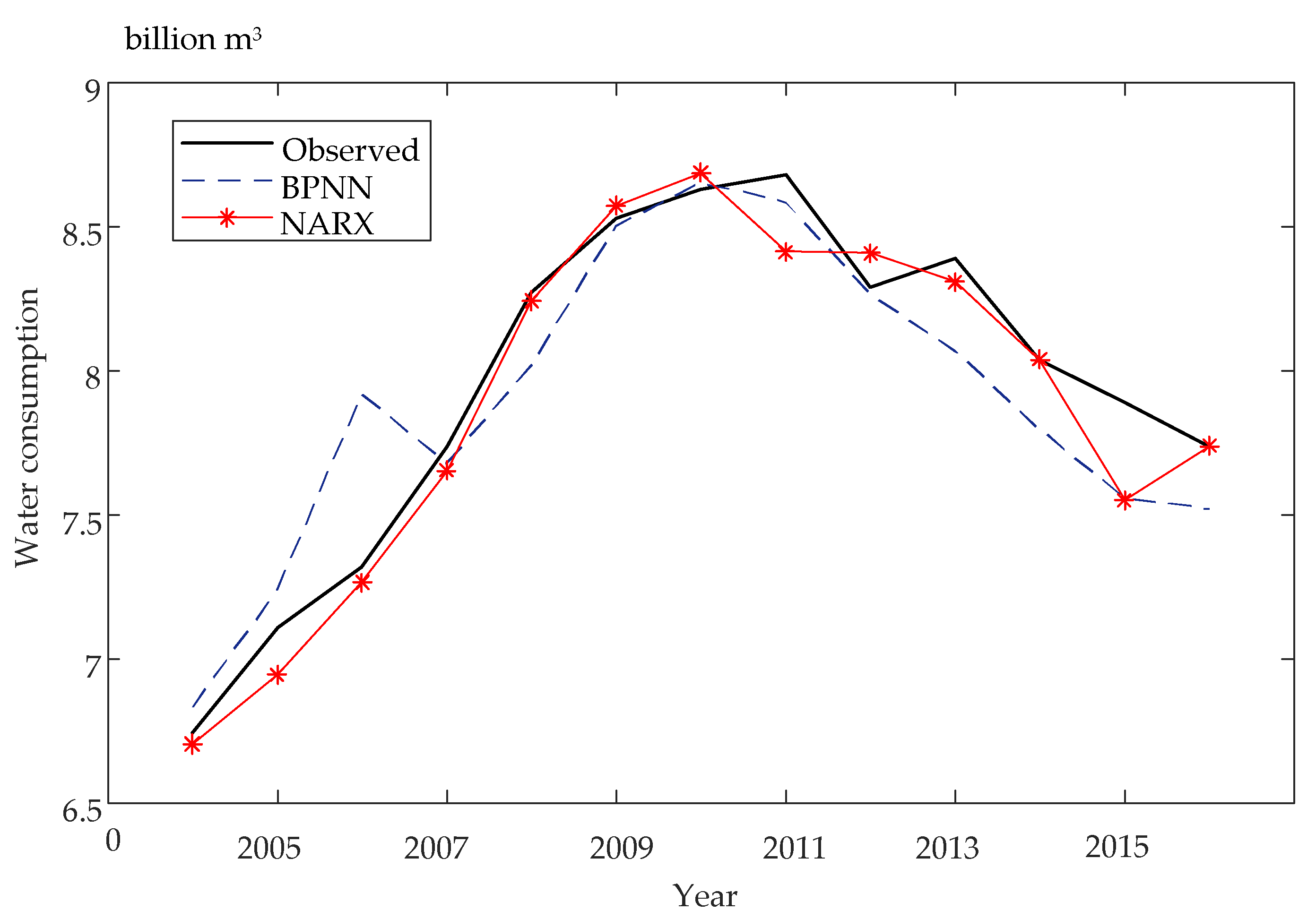
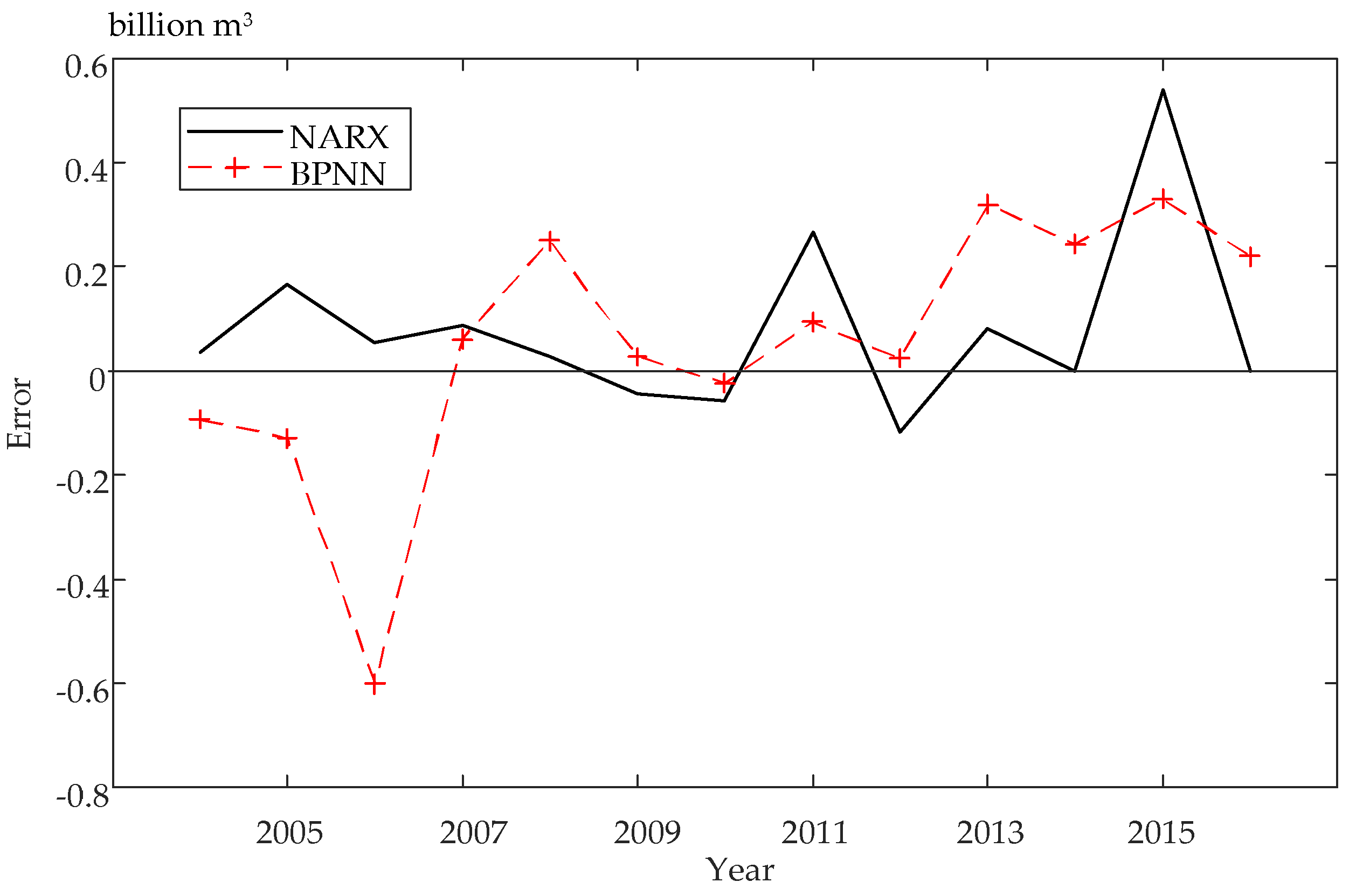
4. Experimental Results and Analysis
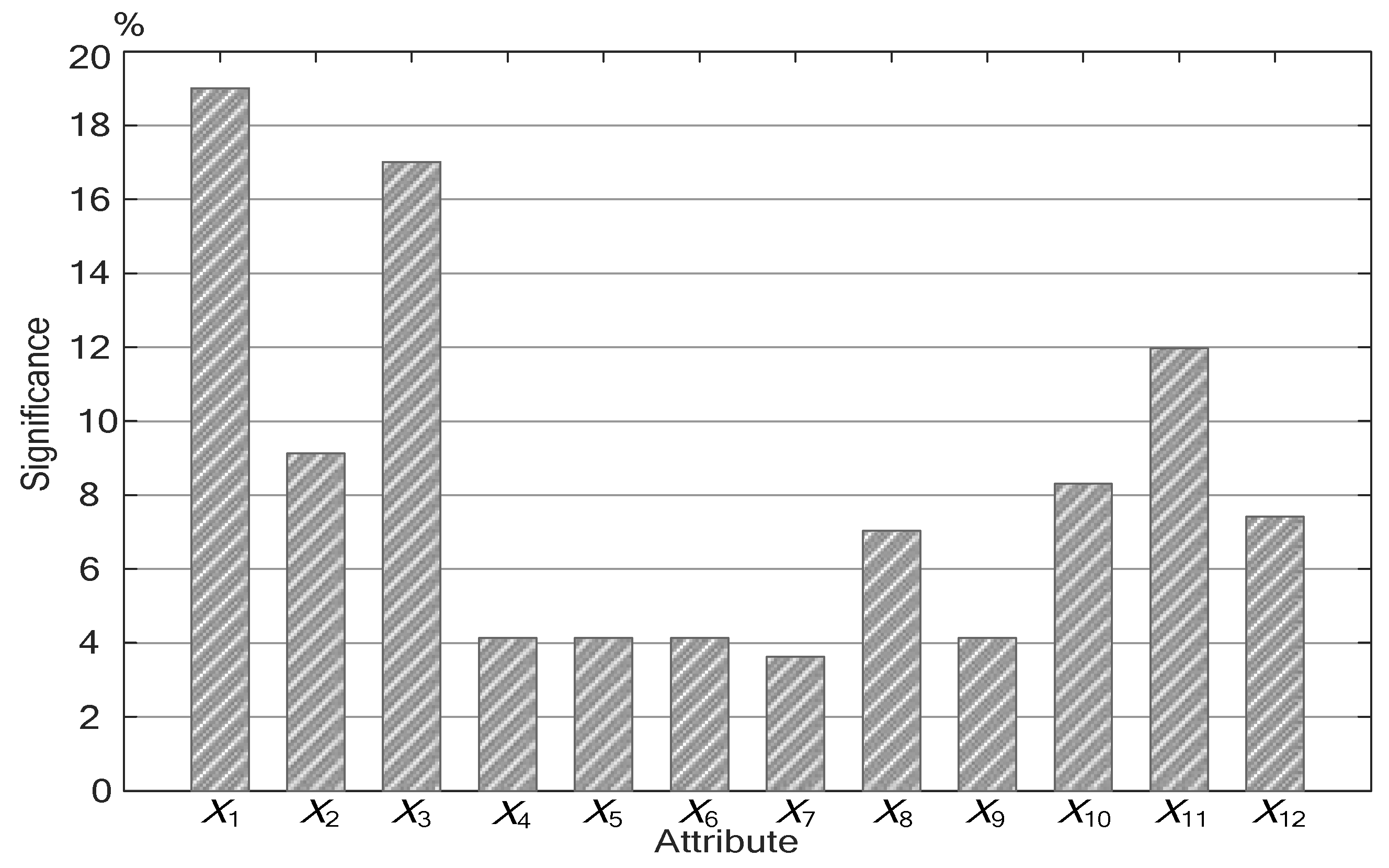
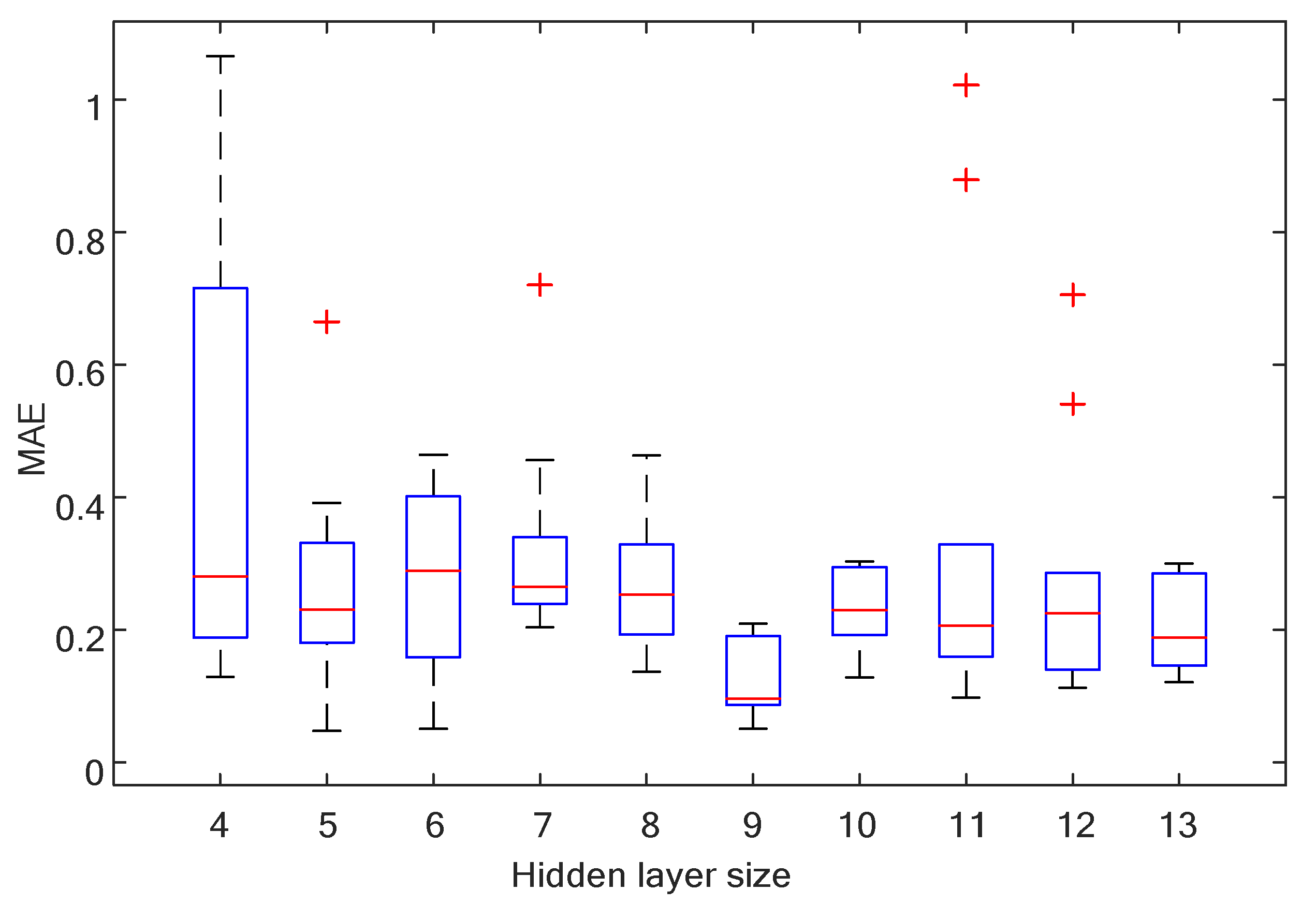
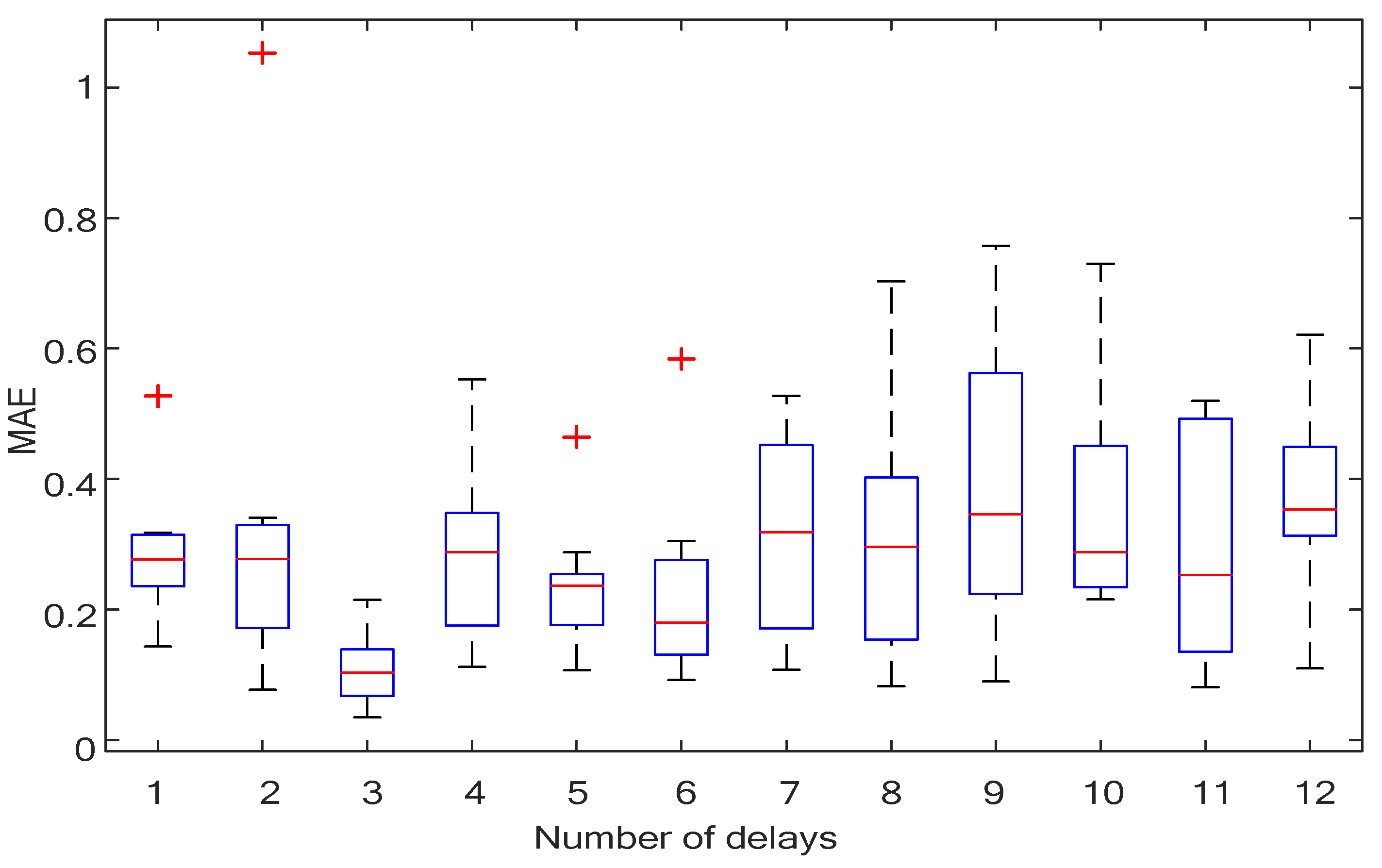
4.1. The Attribute Reduction in Water Consumption Based on the Rough Set
4.2. The RS-NARX Neural Network
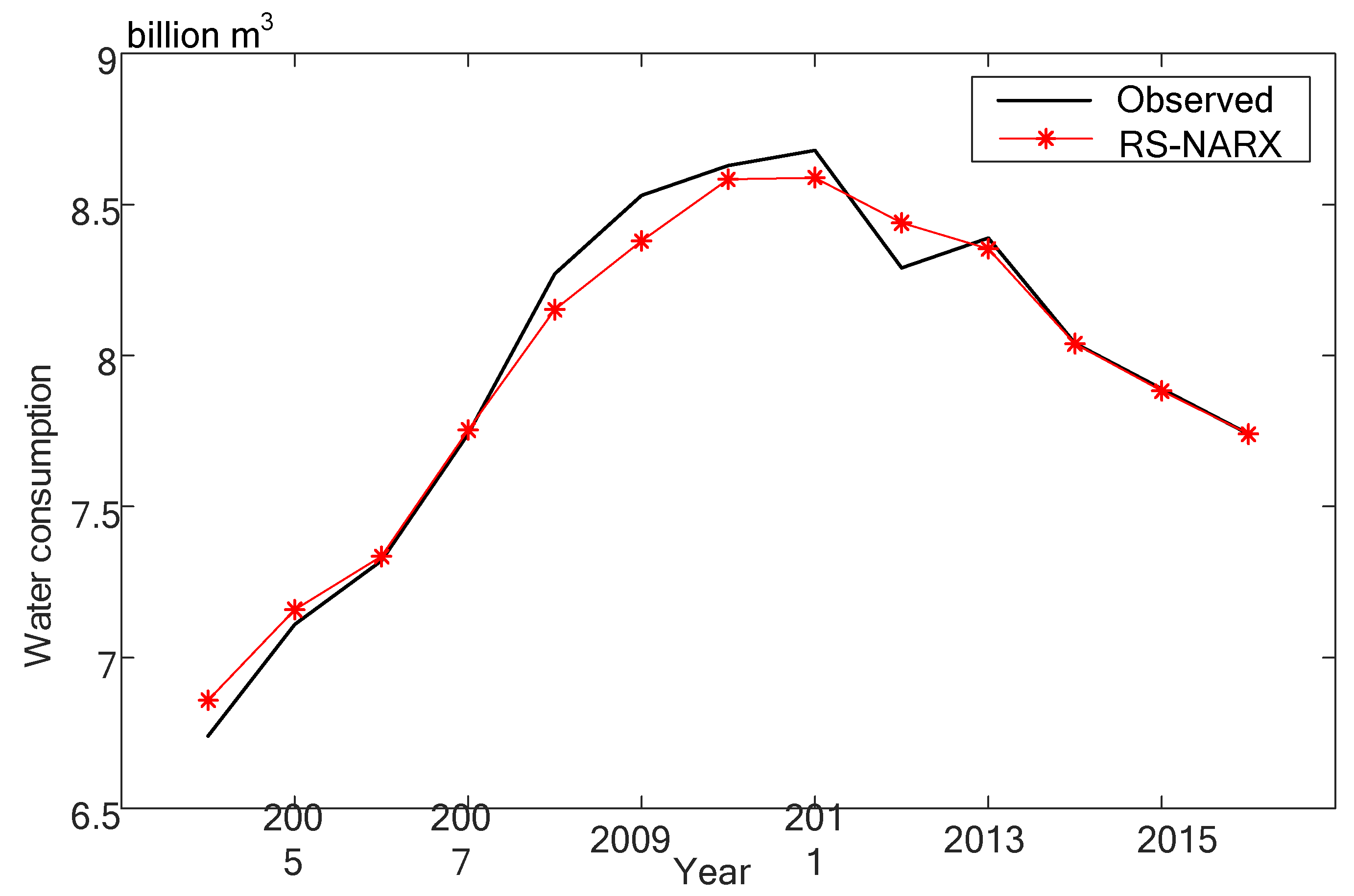
4.3. Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brentan, B.M.; Luvizotto, E., Jr.; Herrera, M.; Izquierdo, J.; Rafael, P.G. Hybrid regression model for near real-time urban water demand forecasting. J. Comput. Appl. Math. 2017, 309, 532–541. [Google Scholar] [CrossRef]
- Bai, Y.; Wang, P.; Li, C.; Xie, J.; Wang, Y. A multi-scale relevance vector regression approach for daily urban water demand forecasting. J. Hydrol. 2014, 517, 236–245. [Google Scholar] [CrossRef]
- Kang, H.S.; Kim, H.; Lee, J.; Lee, L.; Kwak, B.Y.; Lm, H. Optimization of pumping schedule based on water demand forecasting using combined model of autoregressive integrated moving average and exponential smoothing. Water Sci. Technol. Water Supply 2015, 15, 188–195. [Google Scholar] [CrossRef]
- Cheng, Z.W.; Li, X.; Bai, Y.; Li, C. Multi-scale fuzzy inference system for influent characteristics prediction of wastewater treatment. CLEAN-Soil Air Water 2018, 46, 1700343. [Google Scholar] [CrossRef]
- Al-Zahrani, M.A.; Abo-Monasar, A. Urban residential water demand prediction based on artificial neural networks and time series models. Water Resour. Manag. 2015, 29, 3651–3662. [Google Scholar] [CrossRef]
- Chen, G.; Long, T.; Bai, Y.; Zhang, J. A forecasting framework based on Kalman filter integrated multivariate local polynomial regression and relevance vector regression method: Application to urban water demand. Neural Process. Lett. 2019, 50, 497–513. [Google Scholar] [CrossRef]
- Suh, D.; Ham, S. A water demand forecasting model using BPNN for residential building. Contemp. Eng. Sci. 2016, 9, 1–10. [Google Scholar] [CrossRef]
- Zubaidi, S.L.; Dooley, J.; Alkhaddar, R.M.; Abdellatif, M.; AL-Bugharbee, H.; Martorell-Ortega, S. A novel approach for predicting monthly water demand by combining singular spectrum analysis with neural networks. J. Hydrol. 2018, 561, 136–145. [Google Scholar] [CrossRef]
- Rezaali, M.; Quilty, J.; Karimi, A. Probabilistic urban water demand forecasting using wavelet-based machine learning models. J. Hydrol. 2021, 600, 126358. [Google Scholar] [CrossRef]
- Altunkaynak, A.; Nigussie, T.A. Monthly water demand prediction using wavelet transform, first-order differencing and linear detrending techniques based on multilayer perceptron models. Urban Water J. 2018, 15, 177–181. [Google Scholar] [CrossRef]
- Chen, P.A.; Chang, L.C.; Chang, F.J. Reinforced recurrent neural networks for multi-step-ahead flood forecasts. J. Hydrol. 2013, 497, 71–79. [Google Scholar] [CrossRef]
- Bai, Y.; Bezak, N.; Zeng, B.; Li, C. Sapač, K.; Zhang, J. Daily runoff forecasting using a cascade long short-term memory model that considers different variables. Water Resour. Manag. 2021, 35, 1167–1181. [Google Scholar] [CrossRef]
- Salloom, T.; Kaynak, O.; He, W. A novel deep neural network architecture for real-time water demand forecasting. J. Hydrol. 2021, 599, 126353. [Google Scholar] [CrossRef]
- Peronaci, S.; Taravat, A.; Frate, F.D.; Oppelt, N. Use of NARX neural networks for Meteosat Second Generation SEVIRI very short-term cloud mask forecasting. Int. J. Remote Sens. 2016, 37, 6205–6215. [Google Scholar] [CrossRef]
- Wunsch, A.; Liesch, T.; Broda, S. Forecasting groundwater levels using nonlinear autoregressive networks with exogenous input (NARX). J. Hydrol. 2017, 1–16. [Google Scholar] [CrossRef]
- Mousavi-Mirkalaei, P.; Banihabib, M. An ARIMA-NARX hybrid model for forecasting urban water consumption (case study: Tehran metropolis). Urban Water J. 2019, 16, 1–12. [Google Scholar] [CrossRef]
- Xu, Y.B.; Zhang, J.; Long, Z.; Lv, M. Daily urban water demand forecasting based on chaotic theory and continuous deep belief neural network. Neural Process. Lett. 2019, 50, 1173–1189. [Google Scholar] [CrossRef]
- Howe, C.W. Getting western municipal water prices right: Reflecting the scarcity value of water. J. Am. Water Work. Assoc. 2017, 109, 47–49. [Google Scholar] [CrossRef]
- Slavíková, L.; Malý, V.; Rost, M.; Petružela, L.; Vojáček, O. Impacts of climate variables on residential water consumption in the Czech Republic. Water Resour. Manag. 2013, 27, 365–379. [Google Scholar] [CrossRef]
- Angulo, A.; Atwi, M.; Barberán, R.; Mur, J. Economic analysis of the water demand in the hotels and restaurants sector: Shadow prices and elasticities. Water Resour. Res. 2015, 50, 6577–6591. [Google Scholar] [CrossRef]
- Zhang, W.J.; Yu, Y.; Zhou, X.Y.; Yang, S.; Li, C. Evaluating water consumption based on water hierarchy structure for sustainable development using grey relational analysis: Case study in Chongqing, China. Sustainability 2018, 10, 1538. [Google Scholar] [CrossRef] [Green Version]
- Yu, T.T.; Yang, S.; Bai, Y.; Gao, X.; Li, C. Inlet water quality forecasting of wastewater treatment based on kernel principal component analysis and an extreme learning machine. Water 2018, 10, 873. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Cerrada, M.; Cabrera, D.; Sanchez, R.V.; Pacheco, F.; Ulutagay, G.; Oliveira, J.V. A comparison of fuzzy clustering algorithms for bearing fault diagnosis. J. Intell. Fuzzy Syst. 2018, 34, 3565–3580. [Google Scholar] [CrossRef]
- Liu, J.Q.; Cheng, W.P.; Zhang, T.Q. Principal factor analysis for forecasting diurnal water-demand pattern using combined rough-set and fuzzy-clustering technique. J. Water Resour. Plan. Manag. 2013, 139, 23–33. [Google Scholar] [CrossRef]
- Hu, J.; Li, T.; Luo, C.; Fujita, H.; Yang, Y. Incremental fuzzy cluster ensemble learning based on rough set theory. Knowl.-Based Syst. 2017, 132, 144–155. [Google Scholar] [CrossRef]
- Vidhya, K.A.; Geetha, T.V. Rough set theory for document clustering: A review. J. Intell. Fuzzy Syst. 2017, 32, 2165–2185. [Google Scholar] [CrossRef]
- Gebler, D.; Wiegleb, G.; Szoszkiewicz, K. Integrating river hydromorphology and water quality into ecological status modelling by artificial neural networks. Water Res. 2018, 139, 395. [Google Scholar] [CrossRef]
- Cutore, P.; Campisano, A.; Kapelan, Z.; Modica, C.; Savic, D. Probabilistic prediction of urban water consumption using the SCEM-UA algorithm. Urban Water J. 2008, 5, 125–132. [Google Scholar] [CrossRef]
- Matkovskyy, R.; Bouraoui, T. Application of neural networks to short time series composite indexes: Evidence from the nonlinear autoregressive with exogenous inputs (NARX) model. J. Quant. Econ. 2018, 1, 1–14. [Google Scholar] [CrossRef]
- Chatterjee, S.; Nigam, S.; Singh, J.B.; Upadhyaya, L.N. Software fault prediction using Nonlinear Autoregressive with eXogenous Inputs (NARX) network. Appl. Intell. 2012, 37, 121–129. [Google Scholar] [CrossRef]
- Yoshifusa, I. Approximation of functions on a compact set by finite sums of a sigmoid function without scaling. Neural Netw. 1991, 4, 817–826. [Google Scholar] [CrossRef]
- Li, J.F.; Xu, E. Improvement of Naive Scaler. Comput. Eng. Des. 2009, 30. Available online: https://en.cnki.com.cn/Article_en/CJFDTotal-SJSJ200913035.htm (accessed on 30 September 2020).
- Moudani, W.; Chahine, A.; Chakik, F.; Mora-Camino, F. Dynamic rough sets features reduction. Int. J. Comput. Sci. Inf. Secur. 2014, 9, 355–358. [Google Scholar] [CrossRef]
- Chongqing Water Resources Bulletin. Available online: http://slj.cq.gov.cn (accessed on 30 September 2020).
- Statistical Yearbook of Chongqing. Available online: http://tjj.cq.gov.cn (accessed on 3 April 2020).
- Orhan, U.; Hekim, M.; Özer, M. Epileptic seizure detection using artificial neural network and a new feature extraction approach based on equal width discretization. J. Fac. Eng. Archit. Gazi Univ. 2011, 26, 575–580. [Google Scholar]
- Li, X.L.; Yuan, J.M. Research classification of Jujube based on BP artificial neural network. J. Chem. Pharm. Res. 2015, 7, 486–489. [Google Scholar]
- Varma, S.; Simon, R. Bias in error estimation when using cross-validation for model selection. BMC Bioinform. 2006, 7, 91. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2001 | 631.93 | 294.90 | 57.40 | 841.95 | 37.40 | 840.01 | 1.67 | 2829.21 | 2937 | 15 | 43 | 42 |
| 2002 | 641.16 | 317.87 | 97.49 | 958.87 | 39.90 | 956.12 | 2.42 | 2814.83 | 3204 | 14 | 43 | 43 |
| 2003 | 649.69 | 339.06 | 101.33 | 1135.31 | 41.90 | 1081.35 | 2.46 | 2803.19 | 3591 | 13 | 44 | 42 |
| 2004 | 616.79 | 428.05 | 98.59 | 1376.91 | 43.50 | 1229.62 | 2.48 | 2793.32 | 4155 | 14 | 45 | 41 |
| 2005 | 618.09 | 463.40 | 93.20 | 1564.00 | 45.20 | 1440.32 | 2.66 | 2798.00 | 4702 | 13 | 45 | 42 |
| 2006 | 621.32 | 386.38 | 76.58 | 1871.65 | 46.70 | 1649.20 | 2.66 | 2808.00 | 5323 | 10 | 48 | 42 |
| 2007 | 633.67 | 482.39 | 104.56 | 2368.53 | 48.30 | 1825.21 | 2.80 | 2816.00 | 6453 | 10 | 51 | 39 |
| 2008 | 658.86 | 575.40 | 97.87 | 3057.78 | 50.00 | 2160.48 | 2.80 | 2839.00 | 7637 | 10 | 53 | 37 |
| 2009 | 672.02 | 606.80 | 84.83 | 3448.77 | 51.60 | 2474.44 | 2.80 | 2859.00 | 8494 | 9 | 53 | 38 |
| 2010 | 685.25 | 685.38 | 87.20 | 4359.12 | 53.00 | 2881.08 | 2.90 | 2884.62 | 9723 | 9 | 55 | 36 |
| 2011 | 692.88 | 844.52 | 89.96 | 5543.04 | 55.00 | 3623.81 | 3.10 | 2919.00 | 11,832 | 8 | 55 | 36 |
| 2012 | 702.97 | 940.01 | 89.04 | 5975.18 | 56.98 | 4494.41 | 3.50 | 2945.00 | 13,655 | 8 | 52 | 39 |
| 2013 | 675.18 | 1002.68 | 87.64 | 5812.29 | 58.34 | 5968.29 | 3.50 | 2970.00 | 15,423 | 8 | 45 | 47 |
| 2014 | 677.26 | 1061.03 | 104.65 | 6529.06 | 59.60 | 6672.51 | 3.50 | 2991.40 | 17,262 | 7 | 46 | 47 |
| 2015 | 687.19 | 1150.15 | 86.38 | 7069.37 | 60.94 | 7497.75 | 3.50 | 3016.55 | 18,860 | 7 | 45 | 48 |
| 2016 | 690.60 | 1303.24 | 101.91 | 7898.92 | 62.59 | 8538.43 | 3.50 | 3048.00 | 21,032 | 7 | 45 | 48 |
| Interval | Value | Interval | Value |
|---|---|---|---|
| [5.5, 6) | 1 | [6, 6.5) | 2 |
| [6.5, 7) | 3 | [7, 7.5) | 4 |
| [7.5, 8) | 5 | [8, 8.5) | 6 |
| [8.5, 9) | 7 |
| Year | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| Value | 1 | 2 | 2 | 3 | 4 | 4 | 5 | 6 |
| Year | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 |
| Value | 7 | 7 | 7 | 6 | 6 | 6 | 5 | 5 |
| U | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2001 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 2 |
| 2002 | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 3 |
| 2003 | 2 | 1 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 |
| 2004 | 1 | 1 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 |
| 2005 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 |
| 2006 | 1 | 1 | 1 | 2 | 2 | 2 | 1 | 1 | 2 | 2 | 2 | 2 |
| 2007 | 1 | 2 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 1 |
| 2008 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 1 |
| 2009 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 1 |
| 2010 | 3 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 1 |
| 2011 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 1 |
| 2012 | 3 | 3 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 1 |
| 2013 | 2 | 3 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 |
| 2014 | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 |
| 2015 | 3 | 3 | 1 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 |
| 2016 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 |
| Parameter | NARX | BPNN |
|---|---|---|
| Hidden layer size | 10 | 10 |
| Number of delays | 3 | None |
| Model | MAE (Billion m3) | MAPE (%) | RMSE (Billion m3) |
|---|---|---|---|
| BPNN | 0.1856 ± 0.1665 | 2.3855 ± 0.0221 | 0.2451 ± 0.0980 |
| NARX | 0.1135 ± 0.1471 | 1.4253 ± 0.0184 | 0.1813 ± 0.0798 |
| RS-NARX | 0.0611 ± 0.0547 | 0.7636 ± 0.2022 | 0.0821 ± 0.0218 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Zhang, W.; Xie, J.; Liu, Q. A Water Consumption Forecasting Model by Using a Nonlinear Autoregressive Network with Exogenous Inputs Based on Rough Attributes. Water 2022, 14, 329. https://0-doi-org.brum.beds.ac.uk/10.3390/w14030329
Zheng Y, Zhang W, Xie J, Liu Q. A Water Consumption Forecasting Model by Using a Nonlinear Autoregressive Network with Exogenous Inputs Based on Rough Attributes. Water. 2022; 14(3):329. https://0-doi-org.brum.beds.ac.uk/10.3390/w14030329
Chicago/Turabian StyleZheng, Yihong, Wanjuan Zhang, Jingjing Xie, and Qiao Liu. 2022. "A Water Consumption Forecasting Model by Using a Nonlinear Autoregressive Network with Exogenous Inputs Based on Rough Attributes" Water 14, no. 3: 329. https://0-doi-org.brum.beds.ac.uk/10.3390/w14030329