
Dynamic Event-Triggered Integral Sliding Mode Adaptive Optimal Tracking Control for Uncertain Nonlinear Systems


School of Mathematics, Southeast University, Nanjing 211189, China
*
Author to whom correspondence should be addressed.
Symmetry 2022, 14(6), 1264; https://0-doi-org.brum.beds.ac.uk/10.3390/sym14061264
Submission received: 13 May 2022
/
Revised: 9 June 2022
/
Accepted: 13 June 2022
/
Published: 18 June 2022
(This article belongs to the Special Issue Recent Advances in Sliding Mode Control/Observer and Its Applications)
Abstract
:In this paper, we study the event-triggered integral sliding mode optimal tracking problem of nonlinear systems with matched and unmatched disturbances. The goal is to design an adaptive dynamic programming-based sliding-mode controller, which stabilizes the closed-loop system and guarantees the optimal performance of the sliding-mode dynamics. First, in order to remove the effects of the matched uncertainties, an event-triggered sliding mode controller is designed to force the state of the systems on the sliding mode surface without Zeno behavior. Second, another event-triggered controller is designed to suppress unmatched disturbances with a nearly optimal performance while also guaranteeing Zeno-free behavior. Finally, the benefits of the proposed algorithm are shown in comparison to several traditional triggering and learning-based mechanisms.
1. Introduction
Traditional control systems are implemented with time-triggered (TT) sampling (i.e., periodic sampling). Data are sent from the controller to the actuator (or from the sensor to the controller) using a fixed sample length. However, in modern control systems, especially networked control systems, control signals are often implemented aperiodically [1]. The advantages of the aperiodic sampling in terms of update times have been elaborated in [2] in detail. In fact, the limited communication bandwidth in networked control systems has stimulated a huge attention in event-triggered control (ETC) [3,4,5,6,7,8,9,10,11], as an alternative to TT. Despite the progress in the filed, some problems remain open, such as how to simultaneously counteract the effect of matched and unmatched disturbances while guaranteeing the optimal performance of the ETC systems, which is one of our concerns and is an issue to be studied.
Owing to the distinguished features such as fast dynamic response, robustness, order reduction, and implementation simplicity, sliding mode control (SMC) is widely studied in the fields of transportation, power grid, industrial communication networks, and uncertain serial industrial robots [12,13,14,15,16,17,18,19,20]. Especially, SMC has been recognized as one of the popular and powerful control tools in power converters based on deriving from the variable structure systems theorem. In addition, its popularity comes from the robustness feature, which eliminates the burden of the necessity of system parameters required for accurate modeling, yet it may lack robustness against unmatched disturbances. Although many achievements in codesign of sliding mode control and event-triggered have emerged [21,22,23], they all neglect how to guarantee the optimal performance of the controlled system in the presence of matched and unmatched disturbances.
Optimal control theory is now quite mature [24,25,26,27]. Optimal control for nonlinear systems requires one to solve the Hamilton–Jacobi–Bellman (HJB) or Hamilton–Jacobi–Isaac (HJI) equations. However, the nonlinearity of the above equation makes it impossible to get an analytical solution [28]. Although numerical solutions via dynamic programming [29] can be obtained, issues of offline optimization and curse of dimensionality make these numerical methods not feasible in practical applications. To address these shortcomings, adaptive dynamic programming (ADP), oriented from reinforcement learning (RL) technique, has been widely researched in recent decades [30,31,32,33,34,35].
Event-triggered ADP [36,37,38] and event-triggered ADP-based ISMC [39,40] have been investigated in the past years. However, some open issues still remain, which are explained as follows. Although event-triggered implementations can reduce the update times of standard TT implementations, it needs to be pointed out that the event-triggering techniques developed in [39,40] depend only on the current state (static event-triggered control). It is well known that static event-triggered techniques may effectively reduce the communication cost when the sampling error is large. However, as the sampling error becomes smaller, this technique will become conservative, i.e., it can cause several unnecessary triggering. So, developing more flexible event-triggering conditions to further save resources is urgently needed. Moreover, it is still an open problem to design a learning-based event-triggered strategy while at the same time relaxing the excitation condition typically required for ADP methods to further reduce triggered times. Enlightened by the aforementioned discussions, in this article, we will provide a new learning-based framework for ETC-based ISM optimal tracking problem. The novelties are presented below.
- Different from the combined SMC and ADP frameworks of [39,40], this paper proposes a new dynamic event-triggered (DET) mechanism. By introducing an auxiliary variable, which is non-negative. This can increase the length of the time intervals between triggering events, further reducing the communication burden compared with [39,40].
- A novel Integral Sliding Mode Control (ISMC) scheme based on DET for uncertain nonlinear systems is proposed, consisting of two control laws. A first event-triggered controller is designed to tackle the matched uncertainties and force the trajectory of the system on the sliding mode surface. A second event-triggered controller is designed to tackle the unmatched uncertainties and guarantee optimal performance.
- To solve the resulting optimal control problem, a critic-only neural network (NN) based on ADP is proposed via the experience replay technique, which helps relaxing the excitation condition typically required for ADP methods to work. Stability of the closed-loop system is proven in the sense of uniformly ultimately boundedness, while guaranteeing Zeno-free behavior of the triggering mechanism.
The paper is arranged as follows. In Section 2, we introduce the model formulation and preliminaries. Section 3 covers the event-triggered-based ISMC design. Section 4 presents the framework of a dynamic triggered ADP strategy, along with stability analysis. Section 5 illustrates the effectiveness of the novel algorithm via comparative simulations. Section 6 gives the conclusions and possible future works.
Notations: represents the sets of the positive real numbers. and denote the space of all real n-vectors and the space of all real matrices, respectively. ≜ means “equal by definition”, and is the identity matrix of dimension . T is the transposition symbol. represents the class of functions with continuous derivative. is defined as the minimum eigenvalue of matrix X, represents the 2-norm of a vector or matrix. For any full column rank matrix , its left pseudoinverse is .
2. System Formulation and Preliminaries
In this section, an ISMC design oriented toward optimal tracking is discussed. To target optimality, it is useful to introduce an augmented system associated with the tracking error system and the desired reference system.
Consider the following nonlinear system with matched and unmatched uncertainties [39]:
where , , and are the system state, control input, unknown bounded matched disturbance, and unknown bounded unmatched disturbance, respectively. The system dynamics and are known Lipschitz functions with , and and having a positive upper bound. Meanwhile, let the system (1) be controllable, and the matrix function be full column rank with .
Remark 1.
The desired signal is subject to
where the bounded is Lipschitz continuous with . Define the tracking error
Define the augmented state . Combining (2) with (4) generates the following augmented system
with
where , and .
For simplicity and convenience of analysis, we will omit some arguments of the functions ( will be written as , respectively) in the later part of the paper. To this end, the following two standard assumptions are required.
Assumption 1
Assumption 2
([39]). The matrix function g is full column rank and its left pseudoinverse is given by and there exists some positive values such that . Then, the following equality holds
where .
Control objective: This article aims to achieve an optimal tracking control of system state x for the desired trajectory , so that the tracking error is uniformly ultimately bounded UUB. The control input should eliminate the effect of the matched disturbance and reduce the effects of the unmatched disturbance.
To achieve this goal, first, a new composite control law in the form will be considered. Second, according to the robustness to nonlinearities and uncertainties of SMC technique, the Section 3 designs an integral sliding surface and event-triggered controller aiming to suppress the matched effects of the systems while forcing the state of the systems on the sliding mode surface without Zeno-free behavior. Then, event-triggered optimal controller is designed aiming to reduce the unmatched effect and guarantee the optimal performance of the sliding-mode dynamics in Section 4. Finally, a nonlinear single link robot arm is considered to verify the effectiveness of the proposed algorithm.
3. DET-Based ISMC Design
To tackle the uncertainty affecting the nonlinear system (5), an integral type sliding surface is designed as
where is a projection matrix satisfying that is invertible. Here, is an optimal control input that will be designed in the next section. In this section, we aim to design the control to force the augmented system (5) onto the manifold in finite time, to remove the effect of matched disturbances. This can be achieved via
where . The sign function is
Next, we introduce the dynamics of the sliding variable and the notion of practical sliding mode, which will be required later. The dynamics of the sliding variable can be obtained by differentiating (7) with respect to time
According to the SMC theory, when the system trajectories reach the manifold, one has . Then, by combining (5), (6) and (9), one has an equivalent control satisfying
Substituting the equivalent control (10) into the augmented system (5), one gets thew dynamics on the sliding manifold
where . The following result is recalled.
Lemma 1
Remark 2.
Since is the left pseudoinverse of g, one knows
- (1)
- (2)
- The modulation gain associated with is minimized, which means that the amplitude of chattering can be reduced;
- (3)
- avoids amplifying the effect of the unmatched disturbance.
To extend the continuous-time control in the event-triggered paradigm, we define a virtual control input satisfying , where
and is a sampling sequence with with . Define the following measurement error
satisfying the following triggering condition
The following theorem establishes a sufficient condition to the reachability of the specified sliding surface (7).
Theorem 1.
Proof.
Consider the following Lyapunov function . For , the time derivative concerning system (5) with (12) is
Substituting into (15), we have Noticing the triggering condition (14), we know that holds all the time, then for , which implies that the system state starting from the initial state slide robustly on the switching surface S from initial time and can gradually reach the sliding mode surface . The proof is completed. □
Theorem 2.
The event-triggered rule (14) avoids the Zeno behavior, since a minimal triggering interval is given by
Proof.
Define as the interexecution time for . Recall that the control is updated at and . During the event intervals
The technique [39] is utilized to approximate the sign function . That is, where . Substituting into (16), we have
As , using (7), we have
After integrating both sides with respect to (17) for , we get
Using the event-triggered rule (14), when one has
The proof is completed. □
Next, a dynamically triggered controller will be designed to suppress unmatched disturbances and guarantee the event-triggered stability of sliding manifold dynamics system (20) with a nearly optimal performance. We shall find the dynamic event-triggered condition and solve the optimal control problem using critic-only NN approximation strategy.
4. DET-Based Optimal Controller Design
The design comprises two steps. First, find the event-triggered rule to guarantee stability and optimal performance; second, solve the resulting optimal control problem approximately by using ADP and approximation strategy. With , the sliding mode dynamics (11) can be revised as
where .
The discounted cost function , which is subject to the above dynamics (20), is defined as
where is a discount factor and . Moreover, and are symmetric positive definite matrices to weight the system state and input, respectively. Meanwhile, if is admissible and is , the corresponding nonlinear Bellman equation is
Define the Hamiltonian
where .
According to the zero-sum game [27], we get the optimal cost function by
which satisfies the equation
Consider the stationarity conditions [25]:
Solving the stationary conditions (25), we obtain the optimal control input and worst-case disturbance
4.1. Dynamically Triggering Rule for Optimal Input
To propose a dynamically triggering rule, we define again a new sampling sequence with and . Define the error between the sampled state and the current state as
where . Thus, for , the sampled-data version of the system (20) can be rewritten as
Considering the event-based sampling rule, (26) is written as
where .
The equation with event-triggered law can be written as
Now, a necessary assumption is introduced for stability analysis.
Assumption 3
We define an internal dynamic variable evolving according to the following differential equation:
where , and Here, is designed as a filtered value associated with . This new DET technique can avoid to be always nonnegative if the following condition is used
where . This is stated in the following result.
Lemma 2.
Proof.
Using the dynamic rule (33), for ∀ one has
First, if then is true.
By the comparison lemma, for ∀ one gets
Since the initial condition and for ∀, so one can obtain The proof is completed. □
Two main stability results for follow.
Theorem 3.
Proof.
Choose as the Lyapunov function for . With (30), taking the derivative of the Lyapunov function along the trajectory of (29) gives
Note that (26) implies that
According to the time-triggered (27), one has
Since is continuously differentiable on , one can conclude that both and its derivative are bounded on . Here, we have , where is a constant. Recalling the triggering condition (33), one obtains
where and .
Thus, we have once is established.
Accordingly, the UUB of the closed-loop system is ensured. The proof is completed. □
Next, we prove that the dynamic triggering rule (33) avoids the Zeno behavior.
Assumption 4
Theorem 4.
Let Assumptions 1 and 4 hold. The dynamic triggering rule (33) avoids the Zeno behavior, and a minimal triggering interval is given by
Proof.
Define as the interexecution time for . The control is updated at and . During the event intervals
For , we have and . From (43), we have
Using the comparison lemma, we have
For , one has , so
where are positive for all . The proof is completed. □
4.2. Dynamically Triggered ADP with Single Critic NN
The dynamic event-triggered optimal control has been analyzed before. In the sequence, to guarantee UUB of sliding-mode dynamics (20), approximate optimal solution is to obtain by a critic-only NN approximation structure in the following part using reinforcement learning method.
Next, the solution of HJI (31) is approximated using NN using Weierstrass high-order approximation theorem:
where is the unknown ideal weight vector, is the activation function vector, l is the number of hidden neurons, and is the critic NN approximation error.
The gradient of is
where and .
Because the ideal weights are unknown, we first define the approximate expression of the optimal cost function as
where is the estimation of .
Hence, the event-triggered ISMC becomes
Then, the approximation of the Hamiltonian is
Owing to , we have
where .
Subsequently, a feasible training method is proposed by minimizing the residual error , combining codesign of the gradient descent technique and the experience replay (ER) technique, that is
where is the adaptive learning rate, ,
for . The term is used for the purpose of normalization.
Based on the weight estimation error , together with , one has
where , and
4.3. Stability Analysis
According to the critic-only NN strategy presented above, the ISMC can be obtained by solving the HJI Equation (31) approximately by DET way. Thus, the weight estimation error and the tracking error are proven to be UUB by the Lyapunov function in this section. To this end, the assumption 5 is necessary as follows for the following analysis.
Assumption 5
([36]). The NN approximation error and activation functions corresponding to their gradients are bounded, i.e., and and and .
In the sequence, an important theorem will be emerged to guarantee that the weight estimation error and the tracking error are UUB under dynamic event-triggered condition (33) and controller (49).
Theorem 5.
Proof.
We will discuss two cases, i.e., the continuous dynamics and the jump dynamics. For ∀, define the Lyapunov function as
- (1)
- Event is not triggered:
Obviously, for ∀, we have Then,
Then, we further obtain
and
Because of
and
Hence, (61) implies only if one of the following inequalities holds
- (2)
- On the triggering instant:
Finally, UUB of the tracking error and of the weight approximation error are concluded. The proof is completed. □
4.4. Algorithm Design of the Event-Triggered ISM Optimal Tracking Control
In the framework of all assumptions holding in this article, the following Algorithm 1 is to show the procedures of the event-triggered ISM optimal tracking control.
| Algorithm 1 Event-Triggered ISM Optimal Tracking Control. |
| Input: initial states of the sliding mode dynamics (11) |
| 1: Select an initial admissible policy and a proper small scalar |
| 2: To tackle the uncertainty affecting the nonlinear system (5), an integral type sliding surface is designed as
|
| 3: To extend the continuous-time control in the event-triggered paradigm, we define a virtual control input satisfying , where
|
| 4: Hence, the event-triggered ISMC becomes
|
Remark 3.
An optimal tracking composite controller , subject to two different dynamic event-triggered conditions is presented in this paper. Subsequent numerical experiments (cf. Table 1 and Table 2 and Figure 1 and Figure 2, respectively) show that the proposed new algorithm not only can reduce the communication burden but also improve the speed of convergence.
5. Simulation
In this section, a nonlinear single link robot arm is considered to verify the effectiveness of the proposed algorithm.
Consider the following system dynamics [39]
where is the angle position of robot arm, and is the control input. Moreover, M is the mass of the payload, is the moment of inertia, g is the acceleration of gravity, l is the length of the arm, and D is the viscous friction, where are the system parameters and are the design parameters. Set the values of the system parameters as , and , and the design parameters M and are alterable. Assuming and . Herein, consider the effect of interference on the actuator, so the dynamics by selecting the system parameters can be written as
Let us take the initial state . The matched disturbance is taken as
The desired trajectory is
with the initial state .
Based on Lemma 1, one has and The integral sliding mode surface is as in (7) with the sliding mode gain .
According to the ISMC , the sliding-mode dynamics with unmatched disturbances is obtained as
where .
For simulation, the parameters of the algorithm are chosen as , , , . The parameters of the triggering condition are selected as , , , , , and . The initial NN weight is selected as and the NN activation function is designed as .
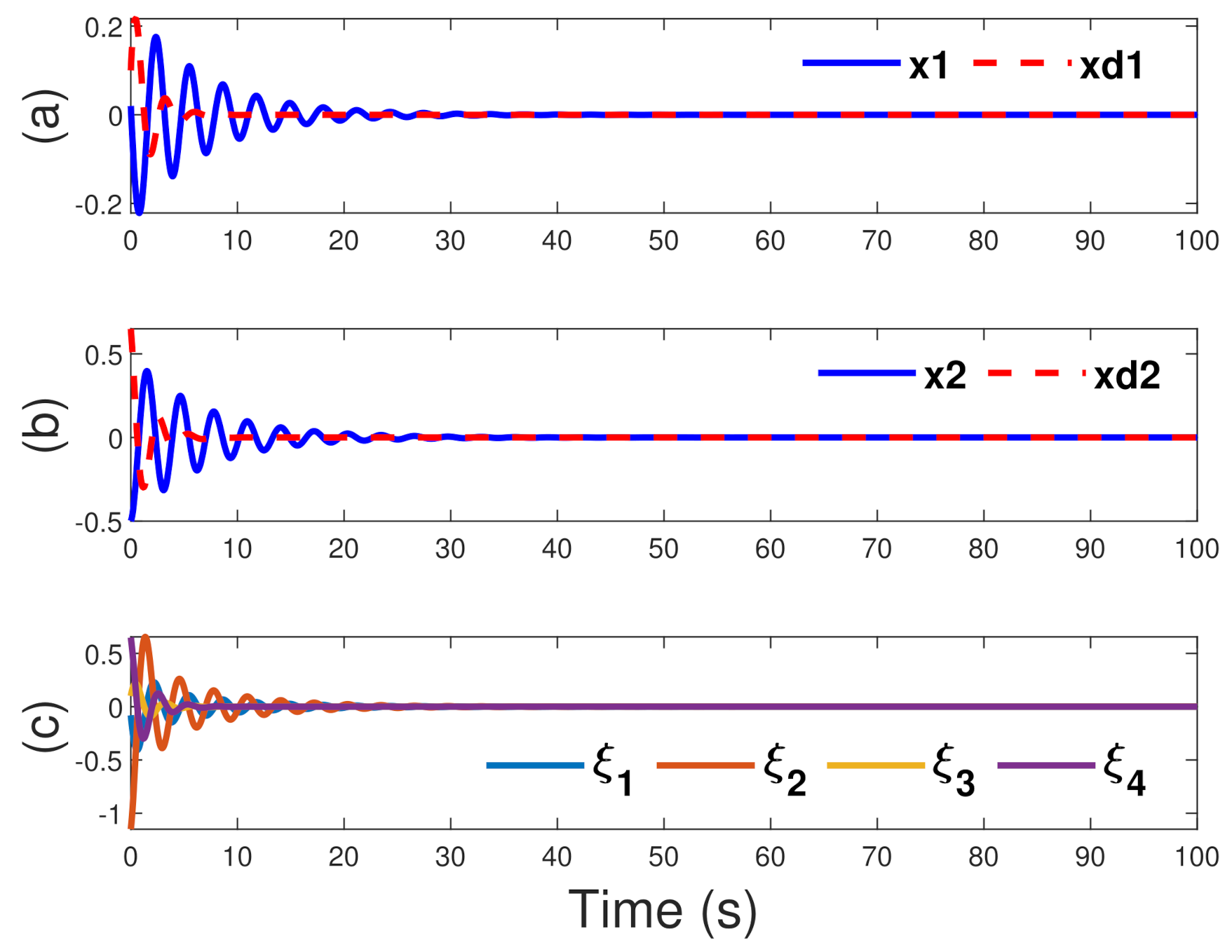
To make a comparison with DET via PE, during the neural network implementation process, a small probing noise is injected in u for the first 90 s. Figure 1 presents the evolution of the tracking system states and the augmented system states with DET via PE technique. Figure 2 presents the evolution of the tracking system states and the augmented system states with DET-based ER technique. From Figure 1 and Figure 2, it is obvious that the convergence of states and tracking trajectories via ER method is faster than the PE method. The optimal control , the ISMC law , the composite law u, and the sliding mode function S are shown in Figure 3 and Figure 4, for DET via PE technique and DET via ER technique, respectively. From Figure 3 and Figure 4, we can see that the convergence via ER method is faster than the PE method. The initial weights are selected randomly in the interval . After a learning process, Figure 5 presents the convergence process of the critic NN weights . The evolution of the event error and triggering threshold are shown in Figure 6. The interevent time of the control under under the four strategies is shown in Figure 7. Next, the characteristics of the different strategies are analyzed by comparison through Table 1, Table 2 and Table 3.
First, Table 1 shows the data comparison for the four control strategies. As is well known, the number of triggering events is one of most important factors in evaluating the triggering mechanism. Furthermore, a smaller number of triggering events can reduce the communication burden and save resources. To implement this goal, it is needed to reduce the unnecessary update of the controller guaranteeing system performance. Based on this, a novel adaptive adjustment technique consisting of DET via ER technique is used. In addition, with the help of the simulation experiment platform and MATLAB data package, using respectively the technology in [39,40] and our technique in this paper, some experimental results are shown in Table 1. From Table 1, it is obvious that the DET via ER technique is the best, and which can better reduce the communication burden and save resources, since there are only 418 samples that occurred because of the larger average triggering interval time 0.2392 s. In particular, one may notice that the ER technique is also beneficial in reducing the number of event-triggering comparing with the PE technique in the framework of the same event-triggered conditions. Similarly, the DET is also beneficial in reducing the number of event-triggering comparing with ET in the framework of the same PE technique (ER technique). In addition, the minimal interval indicates Zeno-free behaviors. The minimal interval values of the four strategies are consistent with Figure 7. Moreover, according to Figure 7, we know that DET via ER technique can generate a biggest minimal interval comparing with other technique, so the effectiveness of the current technique designed in this paper is verified.
Next, we define another important factor to evaluate the control strategy, (called a triggering rate based on TT). The triggering rate is calculated by . When and , Table 2 and Table 3 present that the rate of DET via PE and the rate of DET via ER are and , respectively. Generally speaking, a small triggering rate is more favorable than a large triggering rate. To investigate the characteristics of the changes utilized to execute the triggering rule, some data of the triggering rates are shown in Table 2 and Table 3.The tables also show the effect of the parameters on the triggering rate generated by and with DET via PE and ER respectively. To summary, a bigger value means a reduction of the number of events; in contrast, a bigger value means an increase in the number of events.
Remark 4.
is ET via PE technique, is ET via ER technique, is DET via PE technique, and is DET via ER technique.
6. Conclusions
In this article, a learning-based event-triggered optimal tracking control technique for nonlinear systems was developed via ADP. Matched uncertainties have been eliminated by the ISMC proposed in this paper. Unmatched uncertainties have been attenuated, utilizing projection matrix and an optimal controller. A critic NN via a novel dynamic event-triggered rule has been constructed to ensure the existence of the solution of the HJI equation and all errors have been proved UUB using the Lyapunov analysis method. Moreover, the simulation results revealed that our control algorithm is more favorable than traditional event-triggered control algorithms. Future work is to further explore this framework, e.g., in the presence of various delays or system constraints.
Remark 5.
(1) The pros: This study first provides codesign of dynamic event mechanism and experience replay technique-based weighted adaptive adjustment technique to guarantee the optimal approximation of the cost function . In addition, this codesign technique not only speeds up the approximation speed of the cost function but also enlarges the average interval of internal events aiming to reduce the updating times of the controller and save the calculation burden and communication resources.
(2) The cons: In the proof Theorem 2, using the approximate the sign function where that makes us to only obtain an approximation condition rather than a sufficient condition, namely, which weakens the effect of sliding-mode control. This issue should be investigated further.
Author Contributions
Conceptualization, W.T. and H.W.; methodology, W.T. and H.W.; validation, W.T. and H.W.; formal analysis, W.Y.; investigation, W.T. and H.W.; writing original draft preparation, W.T.; writing review and editing, W.Y. and H.W.; visualization, W.T. and H.W.; supervision, W.Y.; project administration, W.Y.; funding acquisition, W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Science and Technology Project of State Grid Zhejiang Electric Power CO., LTD. (5211JY19000X).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Isermann, R. Digital Control Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Astrom, K.J.; Bernhardsson, B.M. Comparison of Riemann and Lebesque sampling for first order stochastic systems. In Proceedings of the 41st IEEE Conference on Decision and Control, Las Vegas, NV, USA, 10–13 December 2002; pp. 2011–2016. [Google Scholar]
- Tabuada, P. Event-triggered real-time scheduling of stabilizing control tasks. IEEE Trans. Autom. Control 2007, 52, 1680–1685. [Google Scholar] [CrossRef] [Green Version]
- Girard, A. Dynamic Triggering Mechanisms for Event-Triggered Control. IEEE Trans. Autom. Control 2015, 60, 1992–1997. [Google Scholar] [CrossRef] [Green Version]
- Ding, L.; Han, Q.L.; Ge, X.; Zhang, X.M. An overview of recent advances in event-triggered consensus of multi-agent systems. IEEE Trans. Cybern. 2018, 48, 1110–1123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, C.; Li, F. A survey on recent advances in event-triggered communication and control. Inf. Sci. 2018, 457, 113–125. [Google Scholar] [CrossRef]
- Zhang, X.M.; Han, Q.L.; Zhang, B.L. An overview and deep investigation on sampled-data-based event-triggered control and filtering for networked systems. IEEE Trans. Ind. Inform. 2016, 13, 4–16. [Google Scholar] [CrossRef]
- Pan, Y.; Yang, G.H. Event-triggered fault detection filter design for nonlinear networked systems. IEEE Trans. Syst. Man Cybern. Syst. 2008, 48, 1851–1862. [Google Scholar] [CrossRef]
- Ye, C.; Song, Y. Event-Triggered Prescribed Performance Control for a Class of Unknown Nonlinear Systems. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 6576–6586. [Google Scholar]
- Ge, X.; Han, Q.; Zhang, X.M.; Ding, D. Dynamic event-triggered control and estimation: A survey. Int. J. Autom. Comput. 2021, 18, 857–886. [Google Scholar] [CrossRef]
- Ge, X.; Han, Q.L.; Ding, L.; Wang, Y.L.; Zhang, X.M. Dynamic event-triggered distributed coordination control and its applications: A survey of trends and techniques. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 3112–3125. [Google Scholar] [CrossRef]
- Niu, Y.; Ho, D.W.C.; Lam, J. Robust integral sliding mode control for uncertain stochastic systems with time-varying delay. Automatica 2005, 41, 873–880. [Google Scholar] [CrossRef]
- Roy, S.; Baldi, S.; Fridman, L.M. Adaptive sliding mode control without a priori bounded uncertainty. Automatica 2020, 111, 1–6. [Google Scholar] [CrossRef]
- Roy, S.; Roy, S.B.; Lee, J.; Baldi, S. Overcoming the Underestimation and Overestimation Problems in Adaptive Sliding Mode Control. IEEE/ASME Trans. Mechatron. 2019, 24, 2031–2039. [Google Scholar] [CrossRef] [Green Version]
- Yu, W.; Wang, H.; Cheng, F.; Yu, X.; Wen, G. Second-Order Consensus in Multiagent Systems via Distributed Sliding Mode Control. IEEE Trans. Cybern. 2017, 47, 1872–1881. [Google Scholar] [CrossRef] [PubMed]
- Corradini, M.L.; Cristofaro, A. Nonsingular terminal sliding-mode control of nonlinear planar systems with global fixed-time stability guarantees. Automatica 2018, 95, 561–565. [Google Scholar] [CrossRef]
- Li, H.; Shi, P.; Yao, D. Adaptive sliding-mode control of Markov jump nonlinear systems with actuator faults. IEEE Trans. Autom. Control 2017, 64, 1933–1939. [Google Scholar] [CrossRef]
- Castan˜os, F.; Fridman, L. Analysis and Design of Integral Sliding Manifolds for Systems With Unmatched Perturbations. IEEE Trans. Autom. Control 2006, 51, 853–858. [Google Scholar] [CrossRef] [Green Version]
- Truc, L.N.; Vu, L.A.; Thoan, T.V.; Thanh, B.T.; Nguyen, T.L. Adaptive Sliding Mode Control Anticipating Proportional Degradation of Actuator Torque in Uncertain Serial Industrial Robots. Symmetry 2022, 14, 957. [Google Scholar] [CrossRef]
- Xu, L.; Xiong, W.; Zhou, M.; Chen, L. A Continuous Terminal Sliding-Mode Observer-Based Anomaly Detection Approach for Industrial Communication Networks. Symmetry 2022, 14, 124. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, H.; Zhan, X.; Wang, Y.; Chen, S.; Yang, F. Event-Triggered Sliding Mode Control of Switched Neural Networks With Mode-Dependent Average Dwell Time. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 1233–1243. [Google Scholar] [CrossRef]
- Zheng, B.C.; Yu, X.; Xue, Y. Quantized feedback sliding-mode control: An event-triggered approach. Automatica 2018, 91, 126–135. [Google Scholar] [CrossRef]
- Nair, R.R.; Behera, L.; Kumar, S. Event-triggered finite-time integral sliding mode controller for consensus-based formation of multi-robot systems with disturbances. IEEE Trans. Control Syst. Technol. 2019, 27, 39–47. [Google Scholar] [CrossRef]
- Zhou, K.; Doyle, J.C.; Glover, K. Robust and Optimal Control; Prentice-Hall: Englewood Cliffs, NJ, USA, 1996. [Google Scholar]
- Vincent, T.L. Nonlinear and Optimal Control Systems; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Lewis, F.L.; Vrabie, D.; Syrmos, V.L. Optimal Control; Wiley: New York, NY, USA, 2012. [Google Scholar]
- Basar, T.; Bernard, P. H∞-Optimal Control and Related Minimax Design Problems; Birkhäuser: Boston, MA, USA, 1995. [Google Scholar]
- Vrabie, D.; Lewis, F. Neural network approach to continuous-time direct adaptive optimal control for partially unknown nonlinear systems. Neural Netw. 2009, 22, 237–246. [Google Scholar] [CrossRef] [PubMed]
- Bellman, R.E. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Wang, F.Y.; Zhang, H.; Liu, D. Adaptive dynamic programming: An introduction. IEEE Comput. Intell. Mag. 2009, 4, 39–47. [Google Scholar] [CrossRef]
- Michailidis, I.; Baldi, S.; Kosmatopoulos, E.B.; Ioannou, P.A. Adaptive Optimal Control for Large-Scale Nonlinear Systems. IEEE Trans. Autom. Control 2017, 62, 5567–5577. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Xue, S.; Zhao, B.; Luo, B.; Wei, Q. Adaptive Dynamic Programming for Control: A Survey and Recent Advances. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 142–160. [Google Scholar] [CrossRef]
- Fan, Q.Y.; Yang, G.H. Adaptive actor-critic design-based integral sliding-mode control for partially unknown nonlinear systems with input disturbances. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 165–177. [Google Scholar] [CrossRef]
- Qu, Q.; Zhang, H.; Yu, R.; Liu, Y. Neural network-based H∞ sliding mode control for nonlinear systems with actuator faults and unmatched disturbances. Neurocomputing 2018, 275, 2009–2018. [Google Scholar] [CrossRef]
- Zhang, H.; Qu, Q.; Xia, G.; Cui, Y. Optimal guaranteed cost sliding mode control for constrained-input nonlinear systems with matched and unmatched disturbances. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2112–2126. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G. Event-triggered optimal adaptive control algorithm for continuous-time nonlinear systems. IEEE/CAA J. Autom. Sin. 2014, 1, 282–293. [Google Scholar]
- Zhang, Q.; Zhao, D.; Zhu, Y. Event-triggered H∞ control for continuous-time nonlinear system via concurrent learning. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 1071–1081. [Google Scholar] [CrossRef]
- Xue, S.; Luo, B.; Liu, D. Event-Triggered Adaptive Dynamic Programming for Unmatched Uncertain Nonlinear Continuous-Time Systems. IEEE Trans. Neural Netw. Learn. Syst. 2020, 99, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.S.; Li, T.; Xie, X.P.; Zhang, H.G.; Liu, D.R.; Li, Y.H. Event-Triggered Integral Sliding-Mode Control for Nonlinear Constrained-Input Systems With Disturbances via Adaptive Dynamic Programming. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 2168–2216. [Google Scholar] [CrossRef]
- Zhang, H.G.; Liang, Y.; Su, H.; Liu, C. Event-Driven Guaranteed Cost Control Design for Nonlinear Systems with Actuator Faults via Reinforcement Learning Algorithm. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 4135–4150. [Google Scholar] [CrossRef]
- Van, M.; Do, X.P. Optimal adaptive neural PI full-order sliding mode control for robust fault tolerant control of uncertain nonlinear system. Eur. J. Control. 2020, 54, 22–32. [Google Scholar] [CrossRef]
Figure 1.
PE technique: (a,b) resulted trajectory compared with the desired trajectory with DET; (c) state trajectory.
Figure 1.
PE technique: (a,b) resulted trajectory compared with the desired trajectory with DET; (c) state trajectory.

Figure 2.
ER technique: (a,b) resulted trajectory compared with the desired trajectory with DET; (c) state trajectory of augmented systems.
Figure 2.
ER technique: (a,b) resulted trajectory compared with the desired trajectory with DET; (c) state trajectory of augmented systems.

Figure 3.
PE technique: (a) evolution of RL-based control law ; (b) evolution of SMC input ; (c) evolution of composite control law u; (d) evolution of sliding mode surface S.
Figure 3.
PE technique: (a) evolution of RL-based control law ; (b) evolution of SMC input ; (c) evolution of composite control law u; (d) evolution of sliding mode surface S.

Figure 4.
ER technique: (a) evolution of RL-based control law ; (b) evolution of SMC input ; (c) evolution of composite control law u; (d) evolution of sliding mode surface S.
Figure 4.
ER technique: (a) evolution of RL-based control law ; (b) evolution of SMC input ; (c) evolution of composite control law u; (d) evolution of sliding mode surface S.

Figure 5.
Weight curves of system states during learning stage.

Figure 6.
Trigger threshold and event error during learning stage.

Figure 7.
Inter-event time of four strategies during learning stage.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison results of four strategies.
| Strategies | Samples | Average Interval | Minimal Interval |
|---|---|---|---|
| 2000 | 0.05 | 0.05 | |
| 632 | 0.1582 | 0.1 | |
| 476 | 0.2101 | 0.1 | |
| 577 | 0.1733 | 0.1 | |
| 418 | 0.2392 | 0.15 |
Table 2.
Trigger rates of different dets based on PE.
| Triggering Rate (%) | 0.01 | 0.1 | 0.5 | 1 | ||
|---|---|---|---|---|---|---|
| 1 | 22.35 | 23.75 | 27.45 | 29.00 | ||
| 3 | 17.95 | 22.4 | 28.55 | 30.15 | ||
| 5 | 15.55 | 22.25 | 29.20 | 30.65 | ||
| 10 | 12.55 | 22.85 | 30.05 | 31.10 | ||
Table 3.
Trigger rates of different dets based on ER.
| Triggering Rate (%) | 0.01 | 0.1 | 0.5 | 1 | ||
|---|---|---|---|---|---|---|
| 0.1 | 24.90 | 25.10 | 25.45 | 25.65 | ||
| 0.5 | 22.10 | 22.90 | 25 | 25.80 | ||
| 1 | 17.10 | 20.80 | 25.25 | 26.60 | ||
| 3 | 1.75 | 3.6 | 26.30 | 27.50 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tan, W.; Yu, W.; Wang, H. Dynamic Event-Triggered Integral Sliding Mode Adaptive Optimal Tracking Control for Uncertain Nonlinear Systems. Symmetry 2022, 14, 1264. https://0-doi-org.brum.beds.ac.uk/10.3390/sym14061264
AMA Style
Tan W, Yu W, Wang H. Dynamic Event-Triggered Integral Sliding Mode Adaptive Optimal Tracking Control for Uncertain Nonlinear Systems. Symmetry. 2022; 14(6):1264. https://0-doi-org.brum.beds.ac.uk/10.3390/sym14061264
Chicago/Turabian StyleTan, Wei, Wenwu Yu, and He Wang. 2022. "Dynamic Event-Triggered Integral Sliding Mode Adaptive Optimal Tracking Control for Uncertain Nonlinear Systems" Symmetry 14, no. 6: 1264. https://0-doi-org.brum.beds.ac.uk/10.3390/sym14061264
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.