4.1. Comparison with Previous Studies and Signifcance of This Study
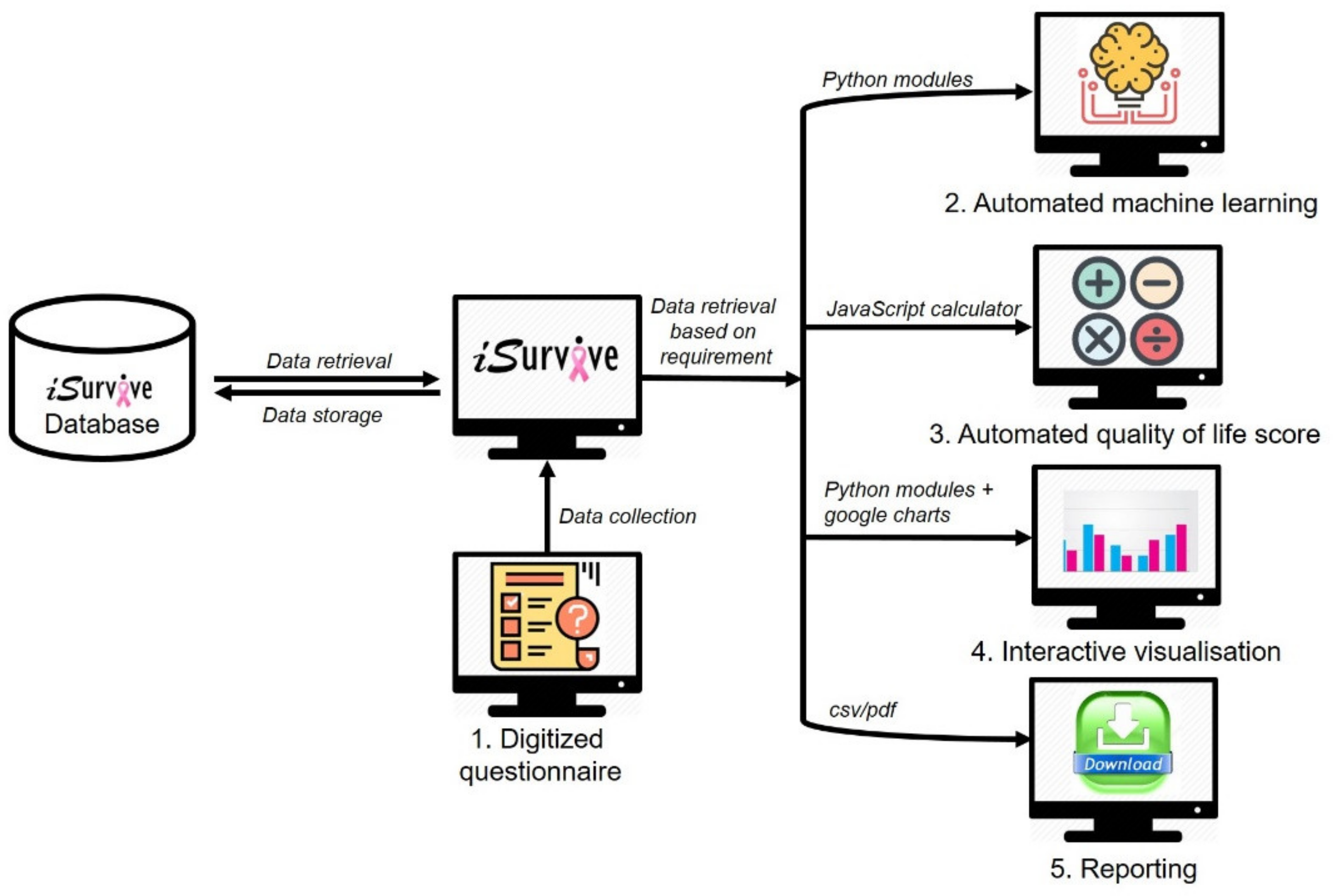
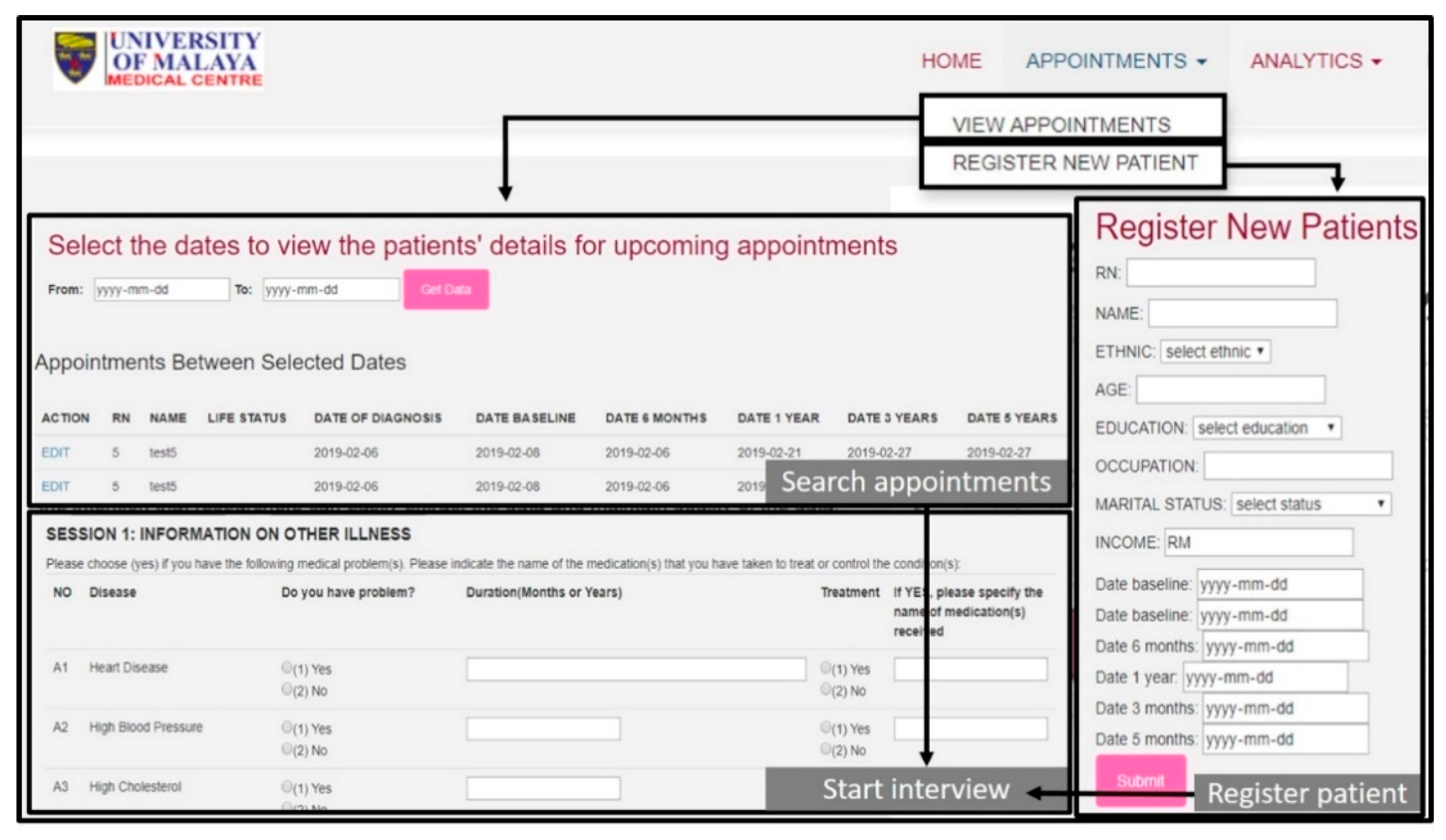
In this study, we proposed a pipeline to develop a fully automated clinician-friendly AI-enabled platform for breast cancer survival prediction. We developed a feature-rich digital platform called iSurvive which contains a database, digitized questionnaires, automated machine learning, automated quality of life scoring, interactive visualizations for clinician-patient communication, and a download module for data reporting. The digitized questionnaires have been developed for data collection, data update, and data management for further analytics whereas the database promotes a secure data storage system.
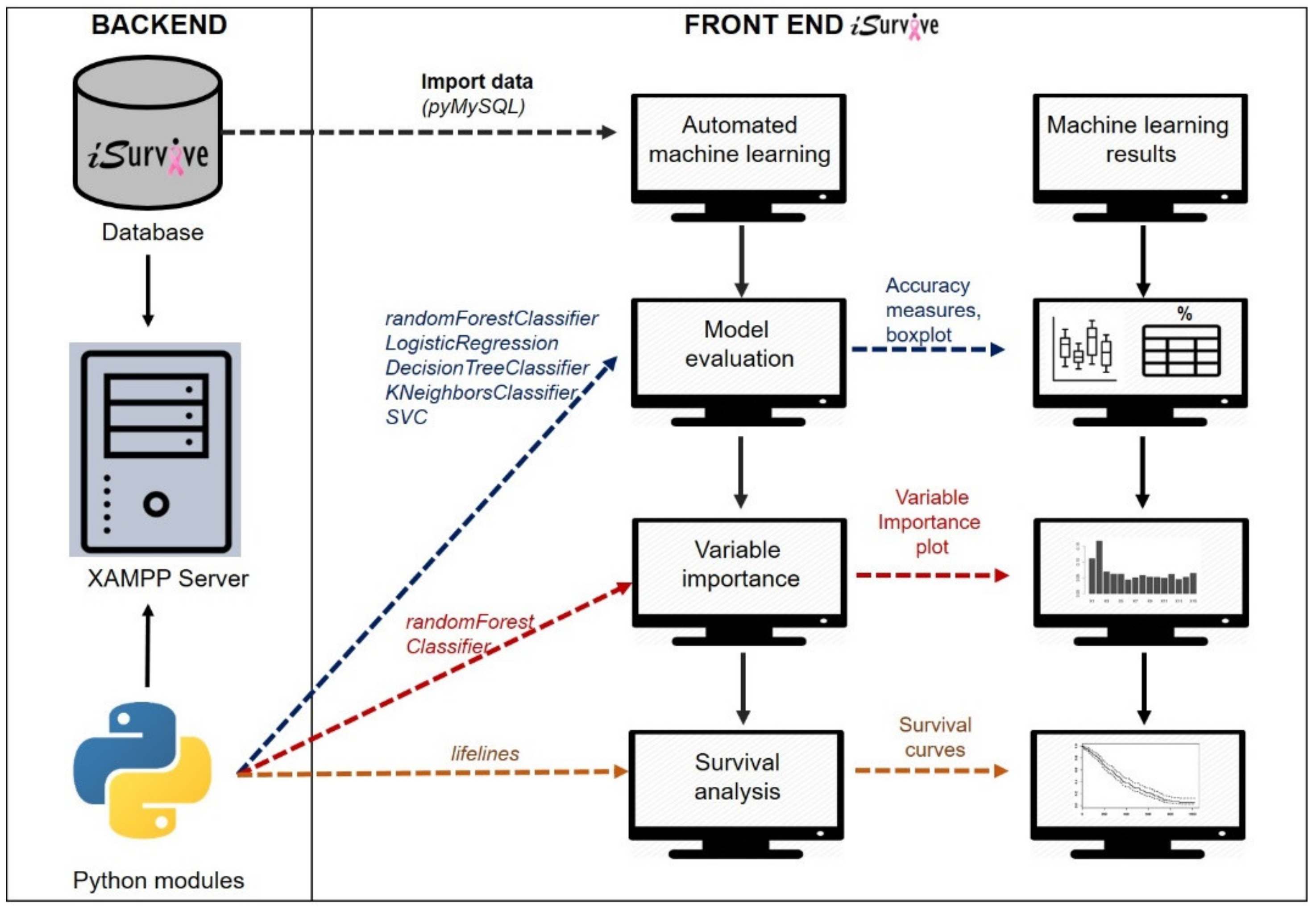
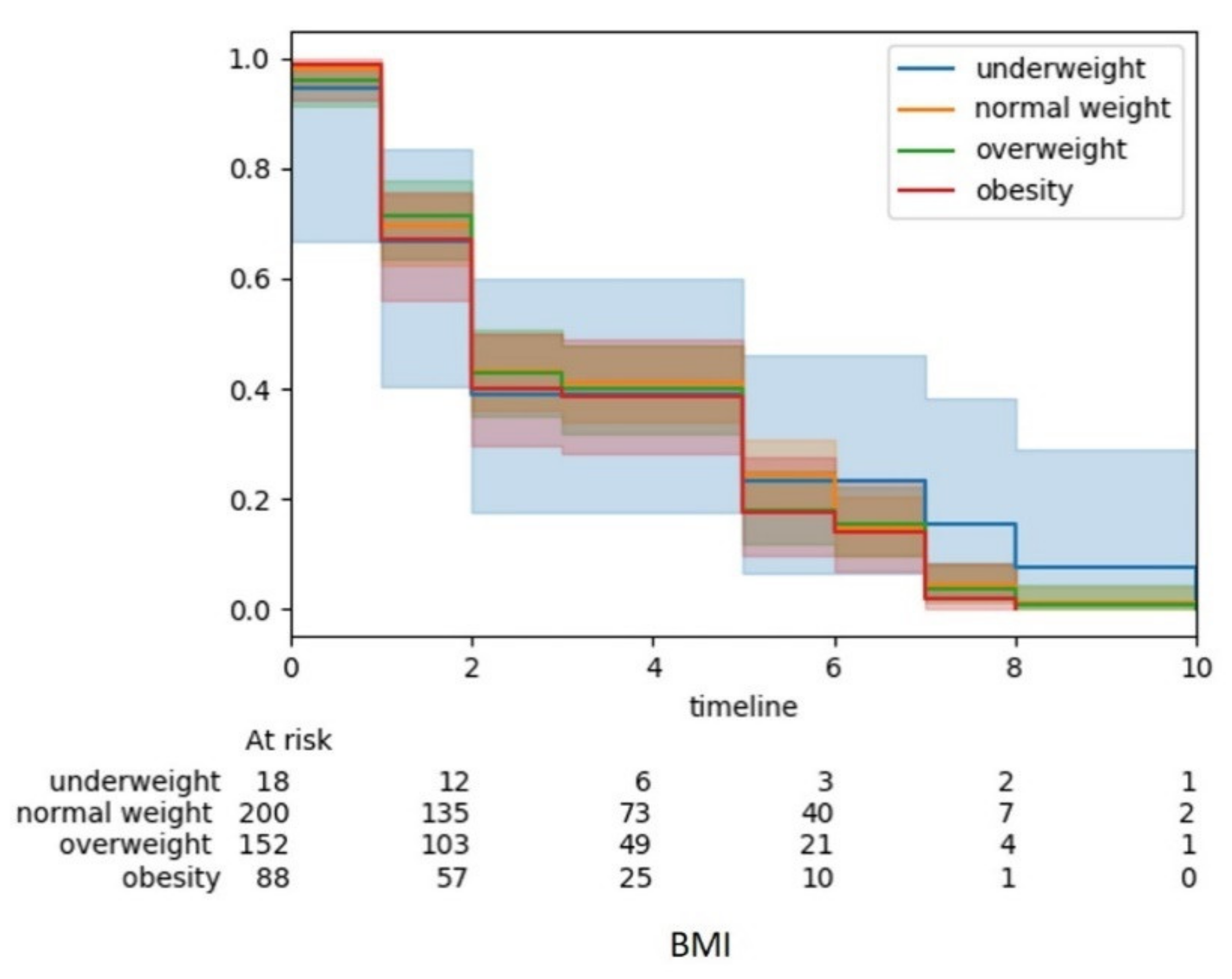
Automated analytics tool for machine learning analysis to perform model evaluation, variable importance, and survival analysis in
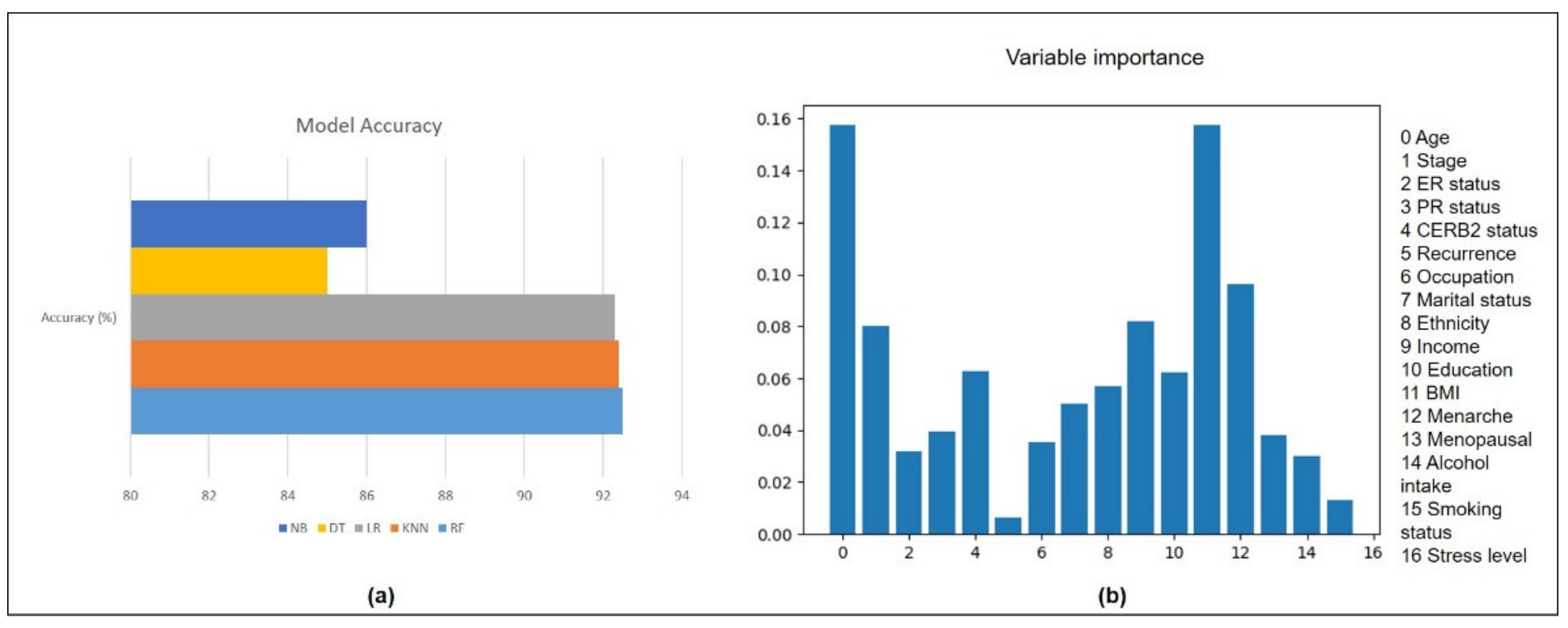
iSurvive has the potential to assist the clinicians as a decision support tool in cancer research. The model evaluation using five different algorithms reported closer accuracies with the highest score from random forest (92.5%). Random forest performed well in most clinical studies [
19,
21,
22]. It has been reported to produce best accuracy and is superior to other techniques in terms of its ability in handling non-linear data and a large number of features [
23]. Variable importance reported that the five most important factors affecting the survival of breast cancer patients are BMI, age, stage, overall family income, and menarche. Most of the prognostic breast cancer related studies are based on clinical data of the patients, while non-biomedical or lifestyle related research is limited [
24]. Hence, lifestyle factors need to be included in breast cancer cohort studies where these factors are potentially modifiable to prolong survival [
9,
25].
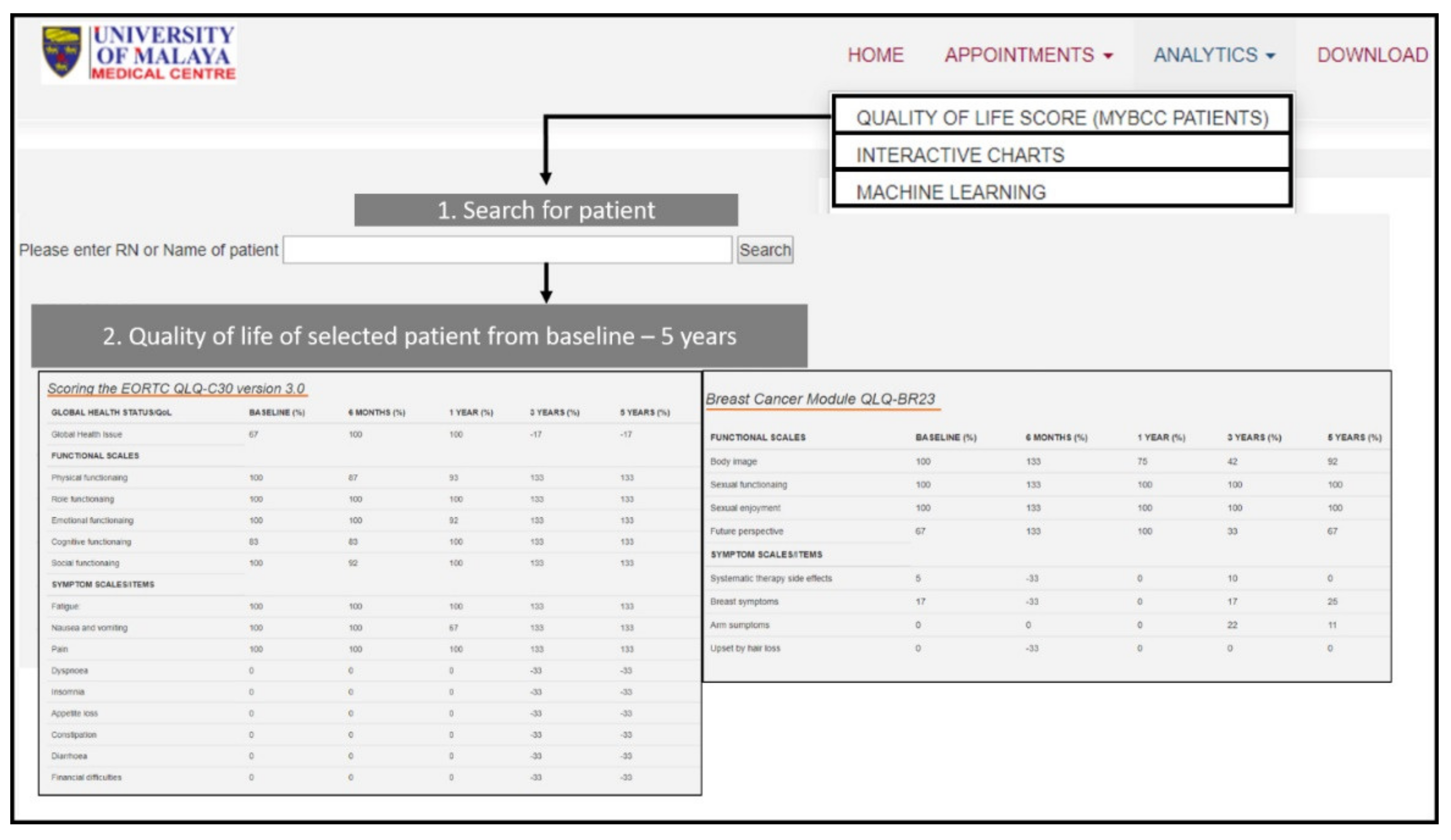
The automated quality of life scoring in the
iSurvive serves as an advanced technology for researchers to analyze the changes in quality of life of the patients from the time of diagnosis up to five years follow up. Currently, paper-based questionnaires, which were developed by EORTC (Aaronson NK, et al., 1993) are being utilized by clinicians and researchers around the world to analyze the quality of life of cancer patients [
26]. Even though digitization of the QoL module of EORTC has been done before [
26], the scoring is still manual, where the clinicians need to organize the collected data from the digitized questionnaire to calculate the scoring manually. Similar types of paper-based cohort studies were updated only with digitized questionnaires for data collection, but not embedded with any analytical tool. A web-based patient reported outcomes system [
6] was developed to collect data from patients using digital questionnaires, but the analysis was still done manually. Similarly, an online breast cancer risk assessment and risk management tool called iPrevent [
27] was developed to collect breast cancer patients′ information on worry, anxiety and risk perceptions, in which data were evaluated using descriptive statistics. Another web and mobile-based invention for women treated for breast cancer to manage chronic pain and symptoms related to lymphedema was also developed for data collection with no embedded analytical tool within the digital system. A mobile breast cancer survivorship care app is also available to compare the performance of survivors from rural areas and urban areas [
28]. However, these digital health platforms and apps are merely for data collection without any automated analytics. An innovation, iMOVE, a smartphone enabled health coaching intervention to promote long-term maintenance of physical activity in breast cancer survivors [
29] was developed to provide personalized exercise program weekly for the participants. iMOVE is limited with one-sided benefit to the patients without any embedded analytical function on patient survival benefits which clinicians can utilize to provide motivation.
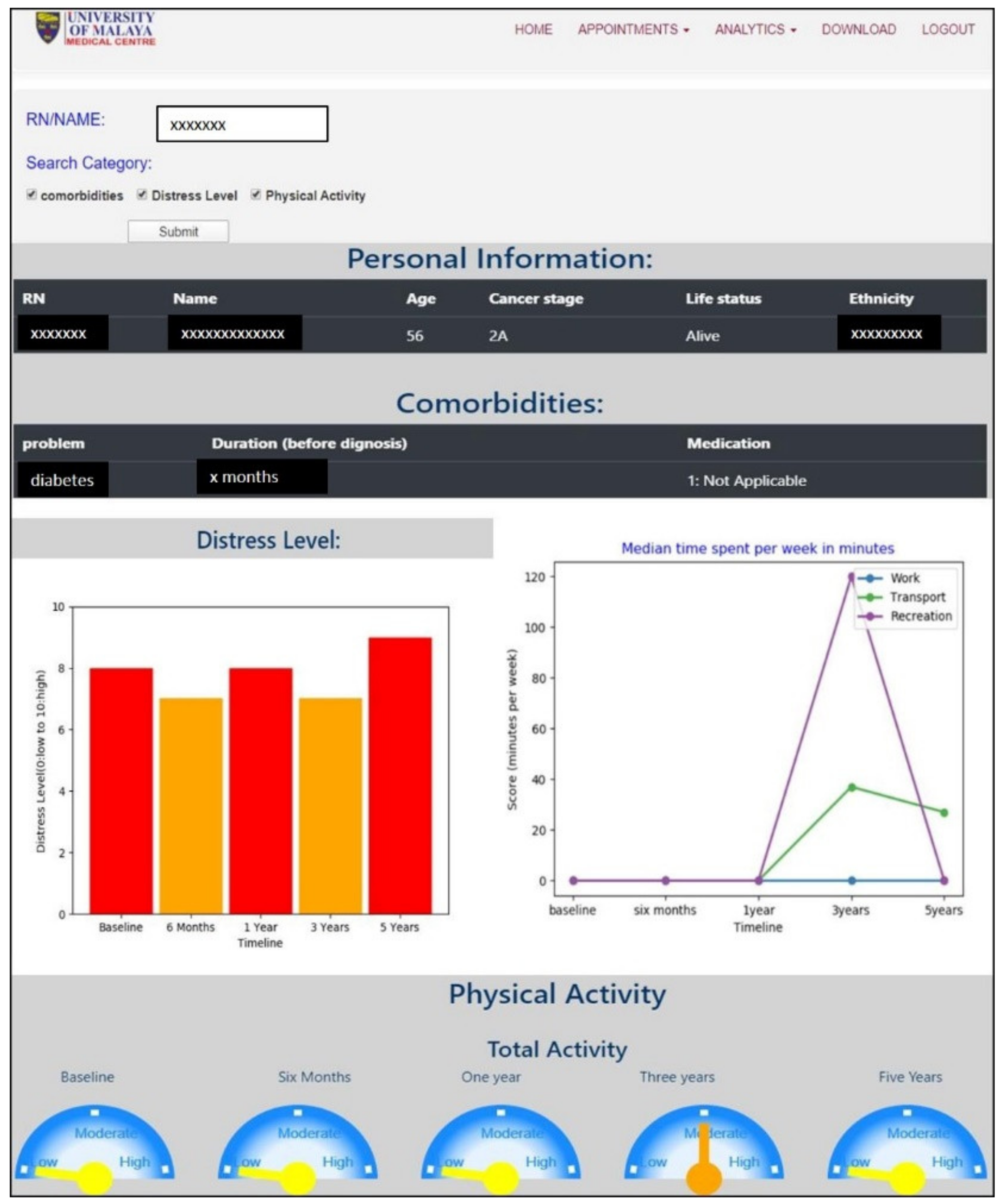
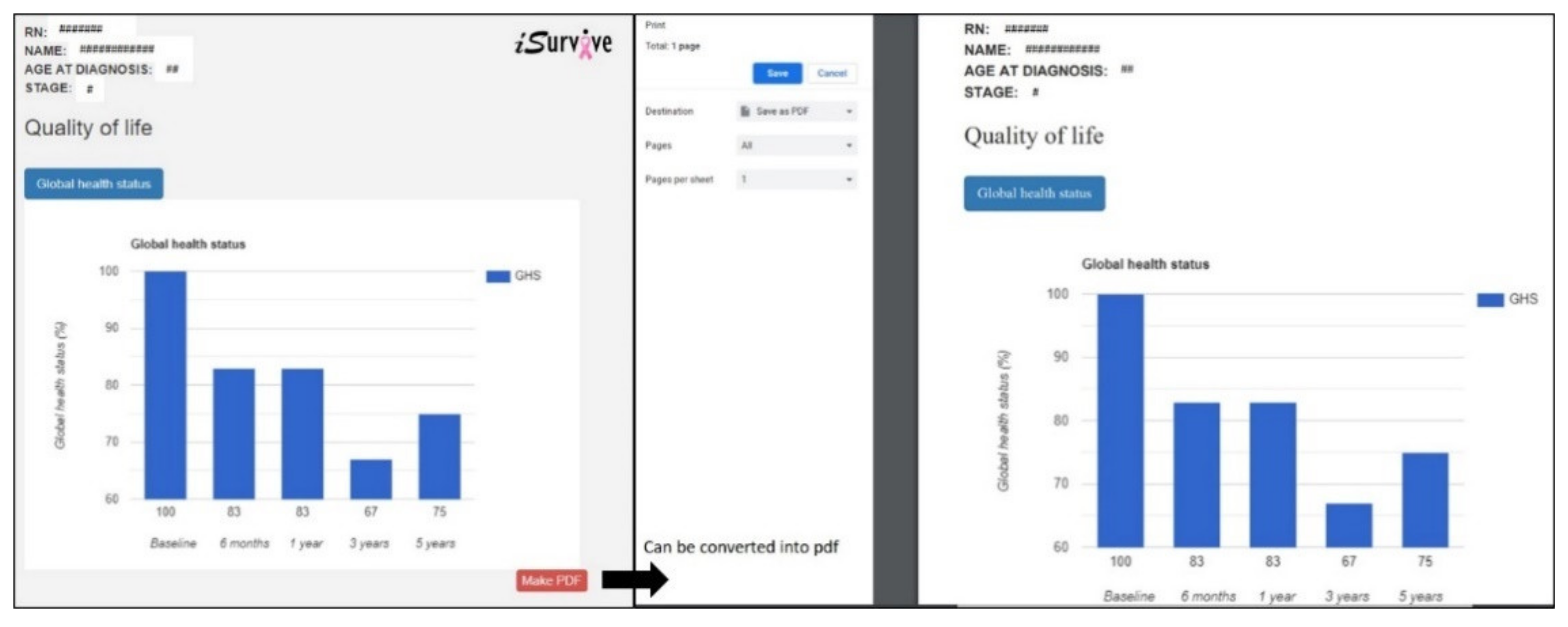
The interactive visuals in this novel pipeline empower the presentation of analyses where researchers can perform audits using the interface without going through the raw data again, which is not only cost effective but saves time. Additionally, this module helps clinicians to communicate with patients about their individual survival prediction and to motivate adherence to treatment and lifestyle interventions during the survivorship period.
Managing the wealth of healthcare data helps enhance communication, patient care, development of personalized medicine, and clinical decision-making. Data is constantly being generated and stored in the form of electronic medical records (EMR) in healthcare organizations. Data science approaches can be applied to maintain and leverage this highly valuable healthcare data. Storage and management of data includes challenges such as data protection, data integration, data retrieval, and analytical software. In terms of data protection, paper-based forms are still being used to collect patient data. Manual data collection contributes to errors and missing values in data as well as time constraints. The database technology has evolved to replace papers or file based systems to digital systems, which now has become the best platform to store healthcare data to maintain seamless data integration, data analytics and data retrieval. Moreover, programs to encrypt or protect patient data are available as built-in in these database management systems. A data-warehousing approach enables creation of a platform that is integrated with analytical tools for the benefit of clinicians. In this study, the digitized questionnaires have been developed for data collection, data update, and data management for further analytics whereas the database promotes a secured data storage system. Automated analytical tools for machine learning analysis, are integrated into a database to perform model evaluation, variable importance, and survival analysis resulting in iSurvive which has the potential to serve as a decision support tool in clinical practice.
Data visualization is streamlining the information into graphical outputs, which can be interpreted easily and quickly. Data visualization enables medical personnel to view the history of a single patient with a click of a button. If the same data visualization network is used in a healthcare organization, the data of the same patient from different departments can be integrated, retrieved from the database, and visualized based on requirements. The customization of visualizations includes type of graphs or charts, type of data (tables, images, test results, etc.) and specific information or variables related to a patient. Additionally, data visualization does not only help to improve response time but plays a pertinent role in presentation of results to patients, clinicians, policy makers, and the general public. Healthcare providers can make informed decisions by viewing the metrics from visualization and find ways to improve a patient′s outcome. Patient data is heterogeneous, with different formats, structures, and semantics. Most medical applications visualize patient data without integrating semantic information to structure the analysis, and hence it is a challenging task for clinicians to perform comparisons [
30]. Integration of different databases to visualize the data of the same patients would be helpful for clinicians to compare results. The interactive visualizations in this novel pipeline
iSurvive empower the presentation of analyses where researchers can perform comparative audits using the interface without going through the raw data again, which is not only cost effective but saves a great amount of time. Additionally, this module helps clinicians to communicate with patients about their individual survival prediction and to motivate adherence to treatment and lifestyle interventions during the survivorship period. It has been found that primary doctors instilling healthy lifestyle messaging improves adherence to healthy lifestyle [
31].
The machine learning approaches used in this study can be transformed into updated guidelines for academicians and researchers. Medical academic sector may use the methodologies demonstrated in this study for teaching and learning programs to educate medical students on the importance of machine learning. Moreover, researchers in the same field can follow the techniques and machine learning models explained in this study to conduct research and cohort studies not limited to breast cancer but any healthcare domain [
19].
Clinical recommendations based on evidence need to be available and communicated effectively. The automated tools using machine learning algorithms help to augment patient care and to enhance clinician-patient communication as patients usually rely on the clinicians and hospitals for diagnosis, treatment, and follow up (especially those who are in critical conditions like cancer). Using the pipeline proposed in this study, clinicians can communicate the breast cancer treatment benefits and survival prediction with the patients, which ultimately promotes personalize care to individual patients to visualize the benefits of treatments. With such a facility, the patients will be able to decide on the best treatment to undergo based on the clinicians′ suggestions in order to improve their health. Additionally, the interactive visualization module in iSurvive helps clinicians to communicate the information on lifestyle factors to improve lifestyle during survivorship period.
4.2. Future Works and Recommendation
The software constraints we faced during the integration of machine learning modules with the iSurvive platform are mainly on the programming languages. We integrated Python machine learning modules with the XAMPP platform, which enabled PHP-MySQL database connection to extract variables from the back-end relational database and to perform variable importance for survival. R, being a common software for machine learning, was not used in this study because it was not possible to establish a seamless integration in the iSurvive XAMPP open-source cross platform web server development environment. In contrast, Python could be integrated with XAMPP to embed the machine learning solution in iSurvive.
In any healthcare analysis, the number of missing values and quality of data is a pressing issue. While many efforts can be taken to minimize missing values and errors in data, this could not be solved completely. The iSurvive back-end database was dependent on retrospective data, which had missing values due to the challenges faced in data collection especially for the five year follow-ups. Hence, maintaining the number of patients to complete the cohort and to have accurate analytical results was a notable shortcoming. In the next version of iSurvive, other potentially modifiable factors to improve the survival of breast cancer patients will be analyzed using the machine learning enabled analytical tool.
iSurvive will be validated by research assistants and clinicians by interacting with the patients for data collection and communicating personalized care through interactive visualizations. Internal validation will be performed by the researchers and clinicians in the UMMC, whereas external validation can be performed with the help of clinical experts, not limited to breast cancer, to obtain suggestions and ideas to improve the usability of the tool. Continuous improvements on the features and usability have been carried out through validation checks by users since its inception. Other potentially modifiable factors to improve the survival of breast cancer patients will be analyzed using the automated machine learning module. The iSurvive pipeline can include other modules or sensors to collect longitudinal data from patients.
The proposed system serves as a one-stop center for clinicians to make data-driven decisions and recommendations for individual patients through automated machine learning and interactive visualizations. In the future, the pipeline used to develop iSurvive can include other modules or sensors to collect longitudinal data from patients.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}