
Tensor-Based Learning for Detecting Abnormalities on Digital Mammograms
 , , , ,
, , , ,
Abstract
:1. Introduction
2. Related Work
Our Contribution
- The creation of small sets for training purposes, in an effort to meet real-world criteria meaning the limited number of data;
- The utilization of CP decomposition to reduce the number of data needed for the training of the proposed Rank-R FNN model; and
- The requirement of lower computational cost due to the lower amount of trainable parameters.
3. Methodology
3.1. Problem Formulation
3.2. Rank-R FNN Model for the Automatic Detection of Abnormalities in Mammograms
4. Dataset and Pre-Processing
4.1. Dataset Description
4.2. Pre-Processing Pipeline
4.3. Extraction of Patches
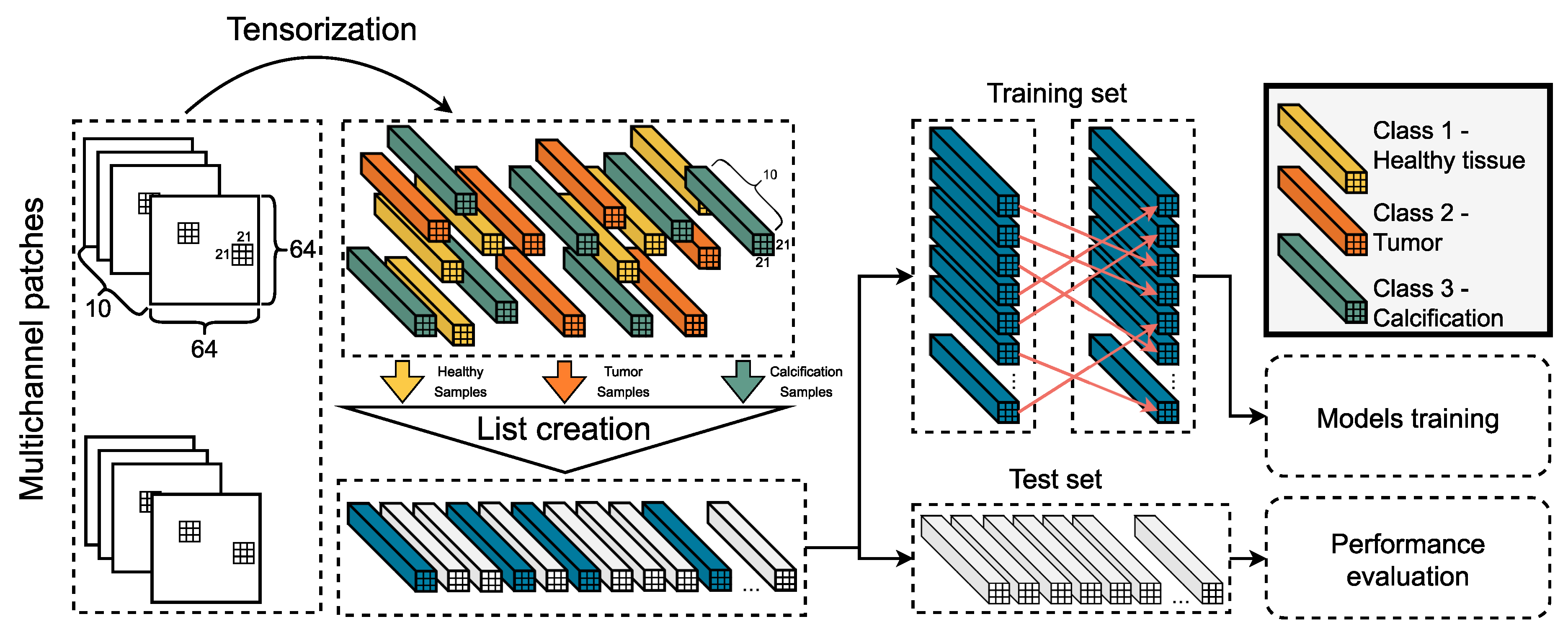
4.4. Tensorization
4.5. Final Dataset Preparation
4.6. The Pipeline in a Nutshell
5. Experimental Validation
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ferlay, J.; Colombet, M.; Soerjomataram, I.; Parkin, D.M.; Piñeros, M.; Znaor, A.; Bray, F. Cancer statistics for the year 2020: An overview. Int. J. Cancer 2021, 149, 778–789. [Google Scholar] [CrossRef] [PubMed]
- Colditz, G.A.; Kaphingst, K.A.; Hankinson, S.E.; Rosner, B. Family history and risk of breast cancer: Nurses’ health study. Breast Cancer Res. Treat. 2012, 133, 1097–1104. [Google Scholar] [CrossRef] [Green Version]
- Alegre, M.M.; Knowles, M.H.; Robison, R.A.; O’Neill, K.L. Mechanics behind breast cancer prevention-focus on obesity, exercise and dietary fat. Asian Pac. J. Cancer Prev. 2013, 14, 2207–2212. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DeSantis, C.E.; Ma, J.; Gaudet, M.M.; Newman, L.A.; Miller, K.D.; Goding Sauer, A.; Jemal, A.; Siegel, R.L. Breast cancer statistics, 2019. CA A Cancer J. Clin. 2019, 69, 438–451. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.S.; Monticciolo, D.L.; Moy, L. Screening guidelines update for average-risk and high-risk women. Am. J. Roentgenol. 2020, 214, 316–323. [Google Scholar] [CrossRef] [PubMed]
- Oeffinger, K.C.; Fontham, E.T.; Etzioni, R.; Herzig, A.; Michaelson, J.S.; Shih, Y.C.T.; Walter, L.C.; Church, T.R.; Flowers, C.R.; LaMonte, S.J.; et al. Breast cancer screening for women at average risk: 2015 guideline update from the American Cancer Society. JAMA 2015, 314, 1599–1614. [Google Scholar] [CrossRef]
- Berg, W.; Hendrick, E.; Kopans, D.; Smith, R. Frequently Asked Questions about Mammography and the USPSTF Recommendations: A Guide for Practitioners. Rest. Soc. Breast Imaging 2009, 45482313. Available online: https://www.semanticscholar.org/paper/Frequently-Asked-Questions-about-Mammography-and-%3A-Berg-Hendrick/38c7972f647f32fd9499dae4a62acda03f951cfe (accessed on 4 September 2022).
- Lehman, C.D.; Arao, R.F.; Sprague, B.L.; Lee, J.M.; Buist, D.S.; Kerlikowske, K.; Henderson, L.M.; Onega, T.; Tosteson, A.N.; Rauscher, G.H.; et al. National performance benchmarks for modern screening digital mammography: Update from the Breast Cancer Surveillance Consortium. Radiology 2017, 283, 49. [Google Scholar] [CrossRef] [Green Version]
- Hofvind, S.; Ponti, A.; Patnick, J.; Ascunce, N.; Njor, S.; Broeders, M.; Giordano, L.; Frigerio, A.; Törnberg, S. False-positive results in mammographic screening for breast cancer in Europe: A literature review and survey of service screening programmes. J. Med. Screen. 2012, 19, 57–66. [Google Scholar] [CrossRef] [Green Version]
- Kuhl, C.K. The changing world of breast cancer: A radiologist’s perspective. Investig. Radiol. 2015, 50, 615. [Google Scholar] [CrossRef] [Green Version]
- Karssemeijer, N.; Bluekens, A.M.; Beijerinck, D.; Deurenberg, J.J.; Beekman, M.; Visser, R.; van Engen, R.; Bartels-Kortland, A.; Broeders, M.J. Breast cancer screening results 5 years after introduction of digital mammography in a population-based screening program. Radiology 2009, 253, 353–358. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bae, M.S.; Moon, W.K.; Chang, J.M.; Koo, H.R.; Kim, W.H.; Cho, N.; Yi, A.; La Yun, B.; Lee, S.H.; Kim, M.Y.; et al. Breast cancer detected with screening US: Reasons for nondetection at mammography. Radiology 2014, 270, 369–377. [Google Scholar] [CrossRef] [PubMed]
- Tran, W.T.; Sadeghi-Naini, A.; Lu, F.I.; Gandhi, S.; Meti, N.; Brackstone, M.; Rakovitch, E.; Curpen, B. Computational radiology in breast cancer screening and diagnosis using artificial intelligence. Can. Assoc. Radiol. J. 2021, 72, 98–108. [Google Scholar] [CrossRef]
- Rodriguez-Ruiz, A.; Lång, K.; Gubern-Merida, A.; Teuwen, J.; Broeders, M.; Gennaro, G.; Clauser, P.; Helbich, T.H.; Chevalier, M.; Mertelmeier, T.; et al. Can we reduce the workload of mammographic screening by automatic identification of normal exams with artificial intelligence? A feasibility study. Eur. Radiol. 2019, 29, 4825–4832. [Google Scholar] [CrossRef] [Green Version]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzębski, S.; Févry, T.; Katsnelson, J.; Kim, E.; et al. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE Trans. Med Imaging 2019, 39, 1184–1194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ali, R.; Hardie, R.C.; Ragb, H.K. Ensemble lung segmentation system using deep neural networks. In Proceedings of the 2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2020; pp. 1–5. [Google Scholar]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 1–7. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Renjith, V.S.; Hency Jose, P.S. A Noninvasive Approach Using Multi-tier Deep Learning Classifier for the Detection and Classification of Breast Neoplasm Based on the Staging of Tumor Growth. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020; pp. 12–16. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Salama, W.M.; Aly, M.H. Deep learning in mammography images segmentation and classification: Automated CNN approach. Alex. Eng. J. 2021, 60, 4701–4709. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Baccouche, A.; Garcia-Zapirain, B.; Zheng, Y.; Elmaghraby, A.S. Early Detection and Classification of Abnormality in Prior Mammograms using Image-to-Image Translation and YOLO techniques. Comput. Methods Programs Biomed. 2022, 221, 106884. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Mobark, N.; Hamad, S.; Rida, S. CoroNet: Deep Neural Network-Based End-to-End Training for Breast Cancer Diagnosis. Appl. Sci. 2022, 12, 7080. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Shen, T.; Gou, C.; Wang, J.; Wang, F.Y. Simultaneous segmentation and classification of mass region from mammograms using a mixed-supervision guided deep model. IEEE Signal Process. Lett. 2019, 27, 196–200. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, J.; Niu, J.; Li, D. New convolutional neural network model for screening and diagnosis of mammograms. PLoS ONE 2020, 15, e0237674. [Google Scholar] [CrossRef]
- Zheng, J.; Lin, D.; Gao, Z.; Wang, S.; He, M.; Fan, J. Deep learning assisted efficient AdaBoost algorithm for breast cancer detection and early diagnosis. IEEE Access 2020, 8, 96946–96954. [Google Scholar] [CrossRef]
- Agnes, S.A.; Anitha, J.; Pandian, S.; Peter, J.D. Classification of mammogram images using multiscale all convolutional neural network (MA-CNN). J. Med. Syst. 2020, 44, 30. [Google Scholar] [CrossRef]
- Sha, Z.; Hu, L.; Rouyendegh, B.D. Deep learning and optimization algorithms for automatic breast cancer detection. Int. J. Imaging Syst. Technol. 2020, 30, 495–506. [Google Scholar] [CrossRef]
- Ewees, A.A.; Abd Elaziz, M.; Houssein, E.H. Improved grasshopper optimization algorithm using opposition-based learning. Expert Syst. Appl. 2018, 112, 156–172. [Google Scholar] [CrossRef]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Makantasis, K.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Georgoulas, I. Hyperspectral image classification with tensor-based rank-R learning models. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3125–3148. [Google Scholar]
- Makantasis, K.; Georgogiannis, A.; Voulodimos, A.; Georgoulas, I.; Doulamis, A.; Doulamis, N. Rank-r fnn: A tensor-based learning model for high-order data classification. IEEE Access 2021, 9, 58609–58620. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. Inbreast: Toward a full-field digital mammographic database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef] [Green Version]
- Desai, M.; Shah, M. An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN). Clin. eHealth 2021, 4, 1–11. [Google Scholar] [CrossRef]
- Mohapatra, S.; Muduly, S.; Mohanty, S.; Ravindra, J.V.R.; Mohanty, S.N. Evaluation of deep learning models for detecting breast cancer using histopathological mammograms Images. Sustain. Oper. Comput. 2022, 3, 296–302. [Google Scholar] [CrossRef]
- Han, Z.; Jian, M.; Wang, G.G. ConvUNeXt: An efficient convolution neural network for medical image segmentation. Knowl. Based Syst. 2022, 253, 109512. [Google Scholar] [CrossRef]
- Saxena, S.; Shukla, S.; Gyanchandani, M. Pre-trained convolutional neural networks as feature extractors for diagnosis of breast cancer using histopathology. Int. J. Imaging Syst. Technol. 2020, 30, 577–591. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Value Range | Units |
|---|---|---|---|
| TWS | Tensor window size | >3 | pixels |
| SPC | Samples per class | ≥10 | samples |
| SPS | Selected patch size | 32–512 | pixels |
| TSS | Tensor step size | ≥1 | pixels |
| Samples Per Class (SPC) | Tensor Window Size (TWS) | Metrics | Our Proposed Tensor-Based Model | Desai and Shah, 2021 [52] | Mohapatra et al., 2022 [53] | Han et al., 2022 [54] | Saxena et al., 2020 [55] |
|---|---|---|---|---|---|---|---|
| 10 | 35 | ||||||
| 40 | 35 | ||||||
| 60 | 35 | Testing set | |||||
| 10 | 21 | Accuracy | |||||
| 40 | 21 | ||||||
| 60 | 21 | ||||||
| 10 | 35 | ||||||
| 40 | 35 | ||||||
| 60 | 35 | Testing set | |||||
| 10 | 21 | F1 | |||||
| 40 | 21 | ||||||
| 60 | 21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tzortzis, I.N.; Davradou, A.; Rallis, I.; Kaselimi, M.; Makantasis, K.; Doulamis, A.; Doulamis, N. Tensor-Based Learning for Detecting Abnormalities on Digital Mammograms. Diagnostics 2022, 12, 2389. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12102389
Tzortzis IN, Davradou A, Rallis I, Kaselimi M, Makantasis K, Doulamis A, Doulamis N. Tensor-Based Learning for Detecting Abnormalities on Digital Mammograms. Diagnostics. 2022; 12(10):2389. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12102389
Chicago/Turabian StyleTzortzis, Ioannis N., Agapi Davradou, Ioannis Rallis, Maria Kaselimi, Konstantinos Makantasis, Anastasios Doulamis, and Nikolaos Doulamis. 2022. "Tensor-Based Learning for Detecting Abnormalities on Digital Mammograms" Diagnostics 12, no. 10: 2389. https://0-doi-org.brum.beds.ac.uk/10.3390/diagnostics12102389