1. Introduction
Nowadays, thyroid cancer is becoming more common worldwide, and the incidence rate is increasing rapidly compared with other malignant tumors. According to the American Cancer Society and cancer statistics, it is the most prevalent endocrine tumor, with 500,000 new cases identified each year (567,233 in 2018) [
1]. In clinical practice, ultrasonography is the most commonly utilized test for the screening and diagnosis of thyroid gland disorders due to its non-invasive, non-radioactive nature, affordability, and real-time capabilities. However, its drawbacks include a low signal-to-noise ratio and the presence of visual image artifacts visible in the ultrasound image. In addition, diagnostic accuracy and reproducibility of ultrasound images are limited and it necessitate a high level of expertise and training [
2]. In light of these challenges, many researchers have reported the importance of computer-aided diagnosing systems to characterize thyroid nodules.
Recently, there has been increased interest in the computer-aided diagnosis of thyroid nodules, and significant research progress has been made in this area. In the traditional machine learning framework, quantitative features are extracted from the ultrasound images, which are used to classify benign and malignant thyroid nodules [
3]. This type of CAD system always attempts to extract morphological or texture features (such as Local Binary Patterns (LBP), Gray Level Co-occurrence Matrix) from ultrasound images [
4]. However, conventional machine learning algorithms designed specifically for retrieving this type of features often require hand-crafted optimal combinations and complex processes of image preprocessing, feature extraction, identification of the best feature set and classification [
4]. Another serious challenge faced by the traditional computer-aided diagnosis system is the irregular and complex appearance of the nodules in the thyroid ultrasound image, which makes feature identification and extraction difficult [
4]. Moreover, the performance of any such system is greatly affected by various factors such as type of image modality, quality of the obtained image, similarity in the morphology of lesions, types of cancer, etc. [
4]. A simple feature extraction method will not yield effective results and will fail to address these issues [
5]. This suggests the need to use more complex convolutional neural network models to characterize thyroid nodules from ultrasound images [
4].
Recently, convolutional neural networks have proven particularly effective in the analysis of radiological, pathological, and other medical image classification tasks [
5]. Compared to its predecessors, the main advantage of CNN is that it automatically detects the essential features without any human supervision [
5]. For example, we have many pictures of cats and dogs, and the CNN model learns the distinctive features of each class by itself. The convolutional neural network can address the above-mentioned issues associated with traditional feature extraction approaches effectively [
6]. This type of approach can automatically learn deeper and more abstract features and avoid complex manual feature extraction.
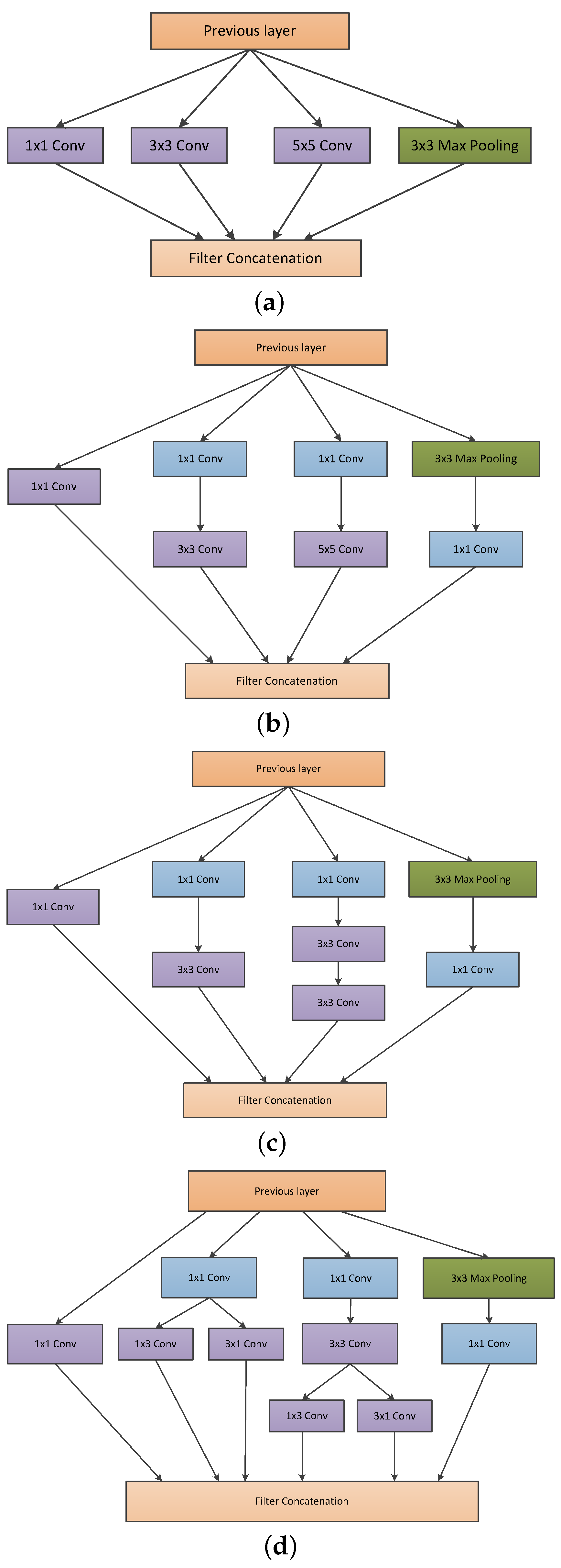
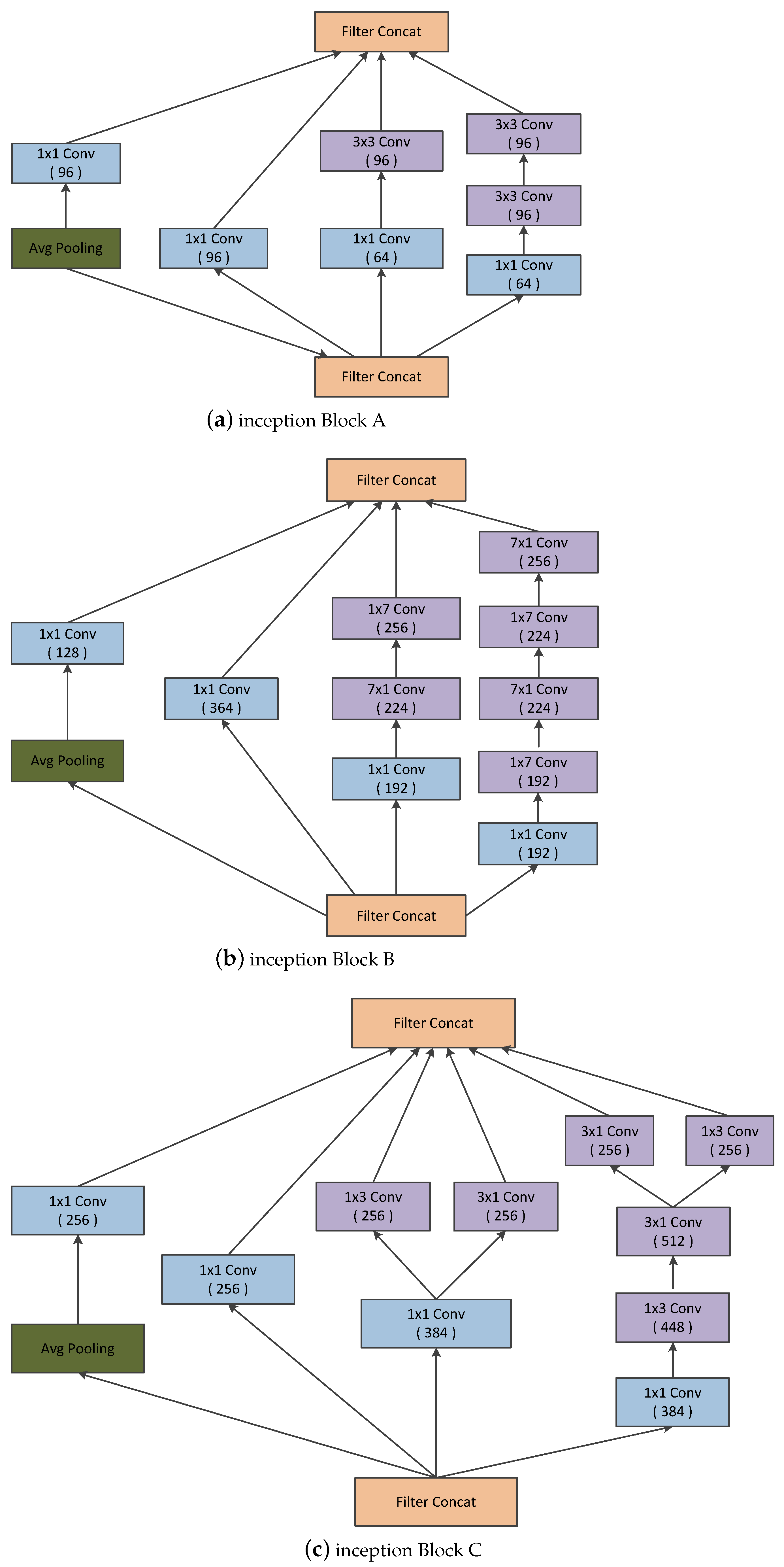
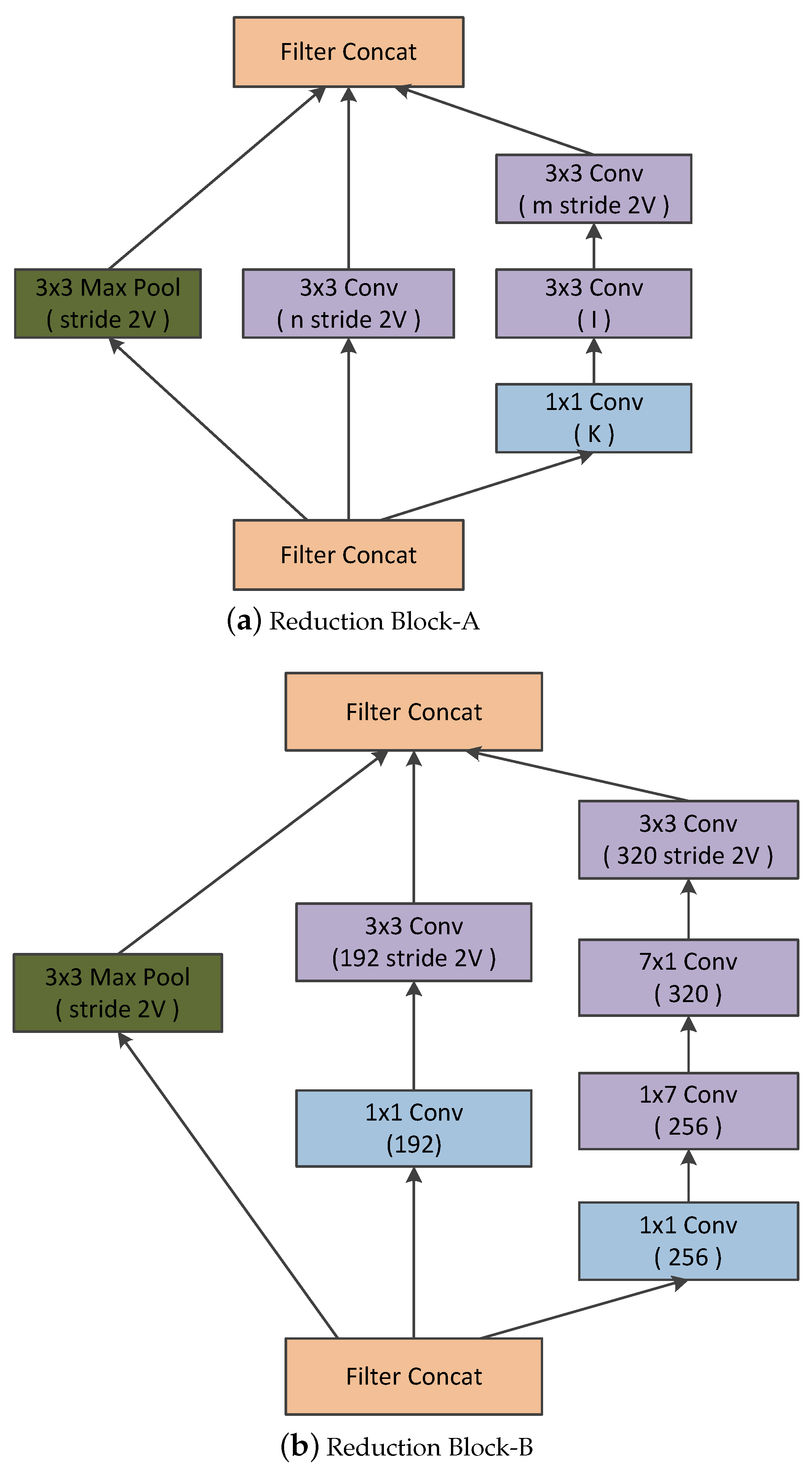
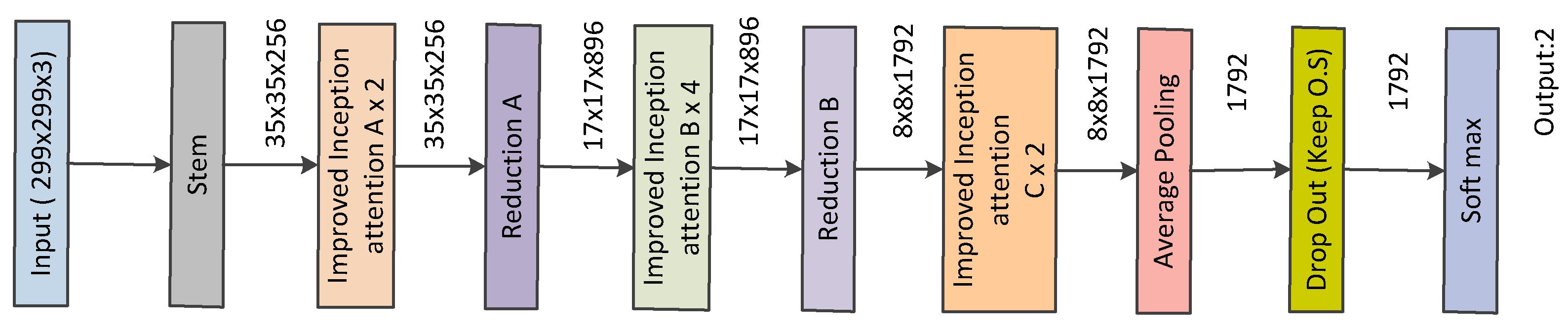
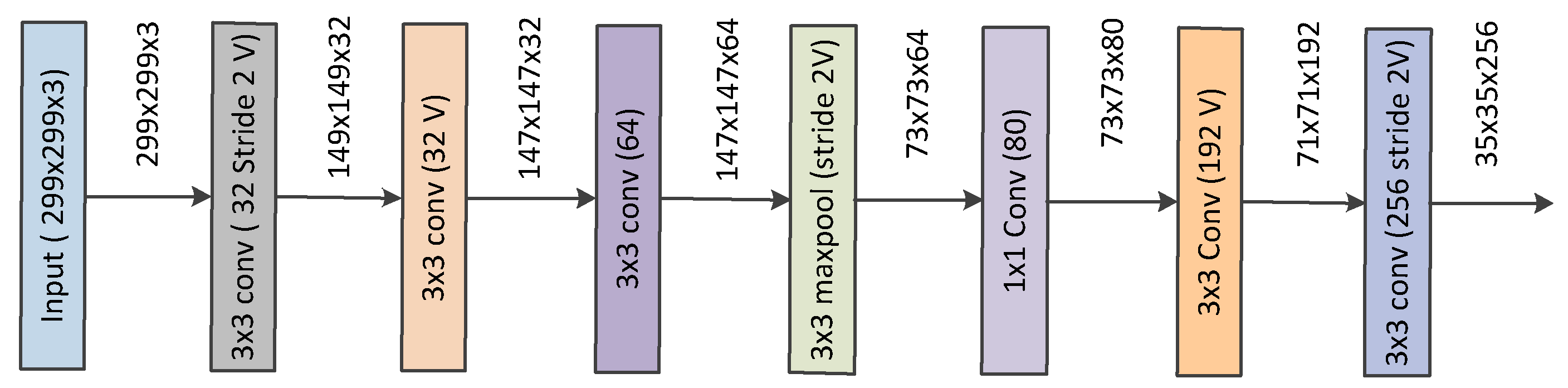
Convolutional neural networks have been widely accepted as a more effective approach for identifying and evaluating the malignant nature of thyroid nodules than traditional methods. Although CNN applications work very well on large datasets, they fail to achieve significant performance on small datasets. Moreover, substantial variability in the size, shape, and appearance of the nodules in the ultrasound images hinders the development of an effective characterization model for thyroid nodule. The area occupied by the nodule and the shape of the nodule in the ultrasound image is different in each image. Consequently, a simple convolutional neural network cannot capture the essential features of the nodules in the ultrasound image. Thus, an efficient convolutional neural network architecture is necessary for the proper characterization of thyroid nodules in ultrasound images. C.Szegedy et al. proposed a deep convolutional neural network architecture (called inception) which helps to expand the width of the network and incorporate multi-scale feature information [
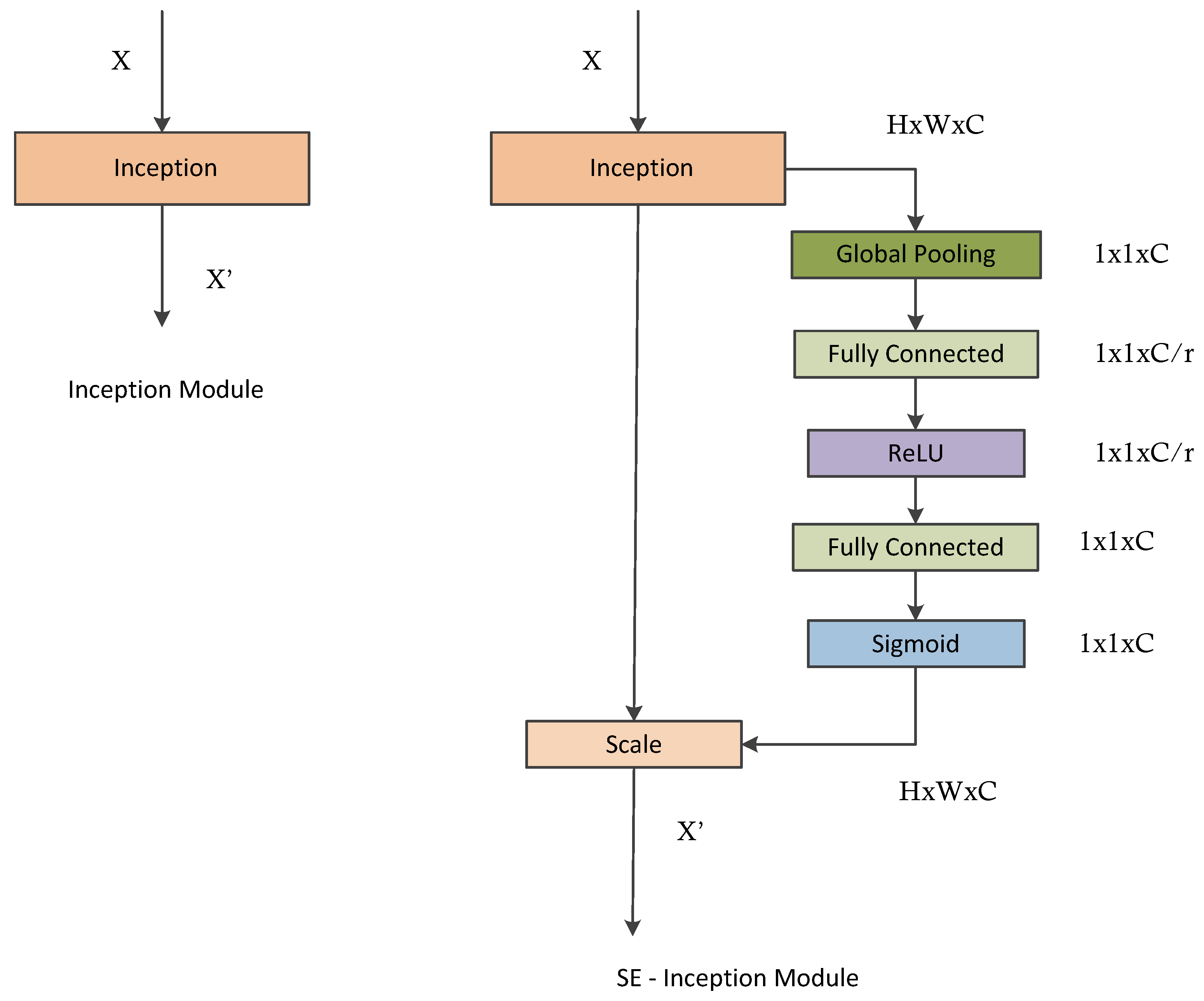
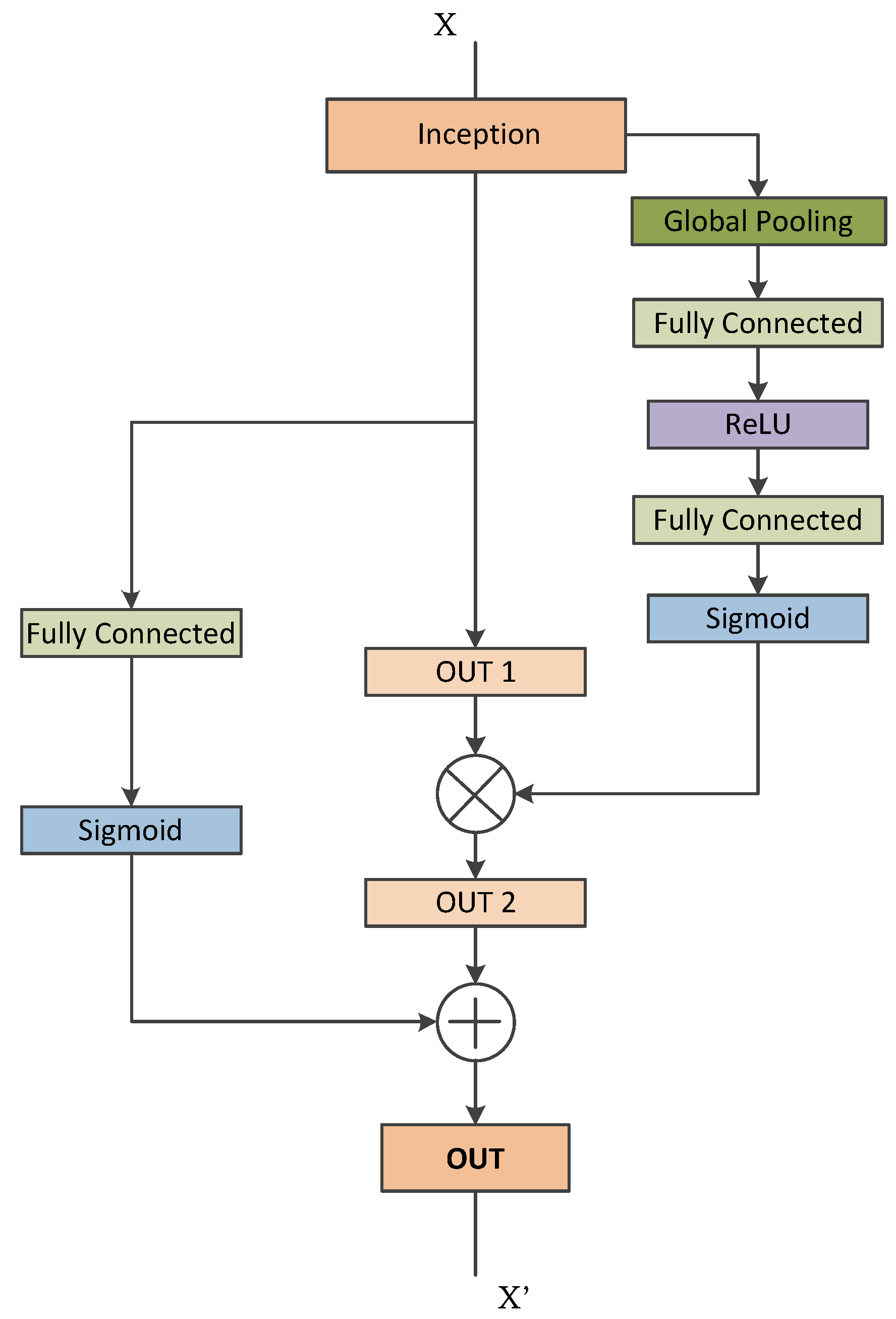
7]. This helps to achieve efficient use of computational resources, and more significant features are extracted under the same computational requirement. Likewise, when doctors diagnose a thyroid ultrasound image, they tend to pay more attention to the places that are decisive for the diagnosis. We cannot implement this through simple CNN architecture. By incorporating the idea of attention networks for recognizing important regions by itself, it will help to improve the diagnosing capability of CAD systems. In 2018, Hu et al. proposed the concept of a squeeze and excitation network which is both efficient and more precise in recognizing complex patterns in images [
8]. To achieve high efficiency, the module uses a global average pooling layer (GAP) that comparatively decreases the number of model parameters and enables the model to converge faster than existing models [
9]. The squeeze and excitation network enhances the propagation of significant features and improves the prediction accuracy of the model. This paper hypothesizes that better diagnostic performance can be achieved by combining the inception architecture and the squeeze and excitation network. Also, the complex micro- and macro-structures of thyroid nodules can be extracted with the help of this approach.
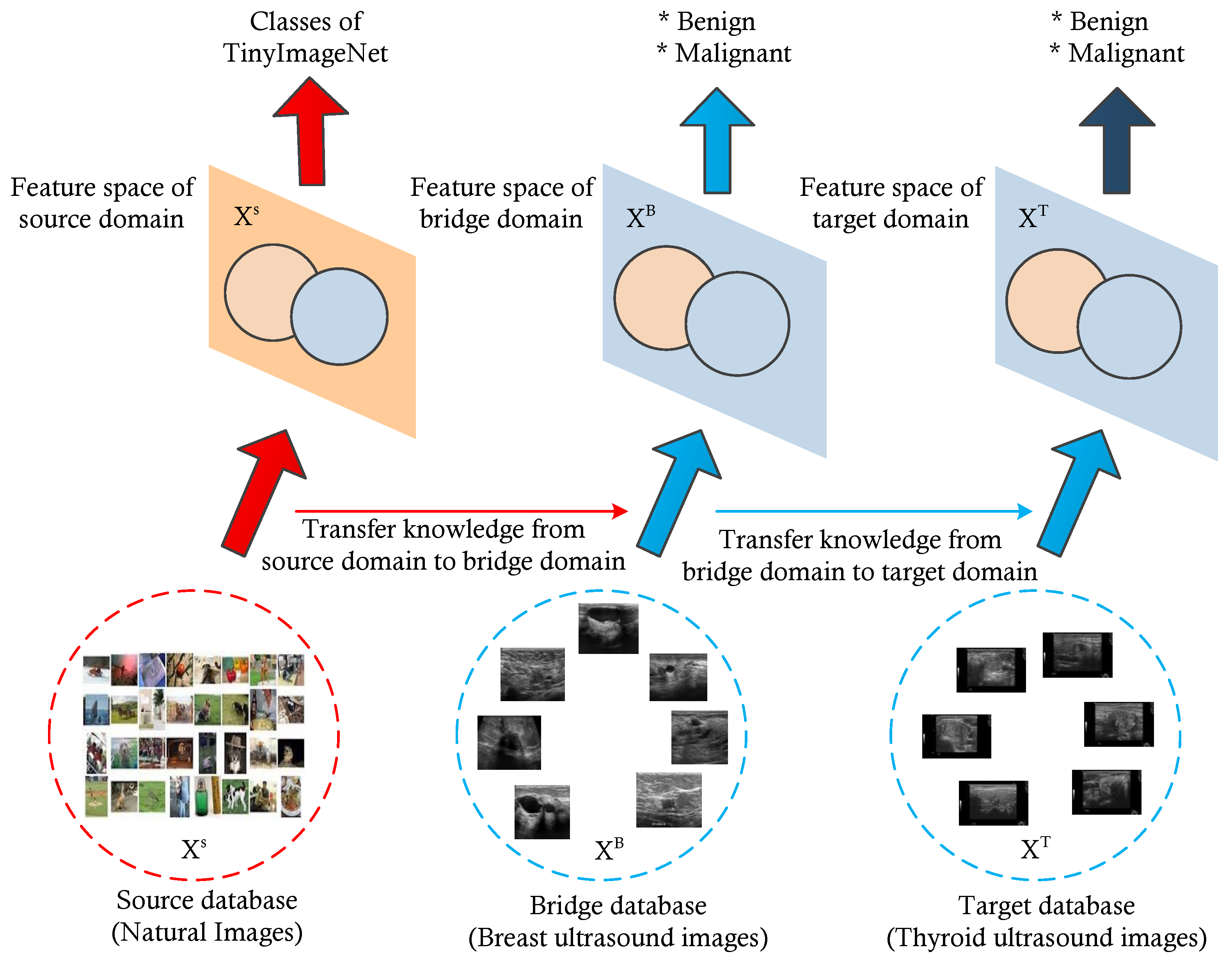
Furthermore, to address issues regarding small datasets, we utilized a multi-level transfer learning mechanism using a bridge dataset from the same image modality to efficiently characterize thyroid nodules [
10,
11]. Here, we used a breast ultrasound image dataset of significant images as a bridge dataset. Several studies have demonstrated possible associations between breast and thyroid cancer, including shared hormonal risk factors, similarity in the appearance of nodules, and genetic susceptibility [
4]. Furthermore, thyroid and breast cancers exhibit similar characteristics under high-frequency ultrasound, such as malignant nodules having a taller-than-wide shape, hypoechogenicity, and an ill-defined margin. This is why we selected the breast ultrasound image dataset as a bridge dataset for multi-level transfer learning for the classification of thyroid nodules [
4].
Inspired by the above-discussed issues, this paper proposes an architecture that combines the inception architecture with the squeeze and excitation module based on the multi-level transfer learning technique for developing an efficient characterization framework for thyroid nodule diagnosis. The contributions of this paper are as follows:
We utilize the concept of attention mechanism with each inception block and propose a network architecture for thyroid nodule diagnosis.
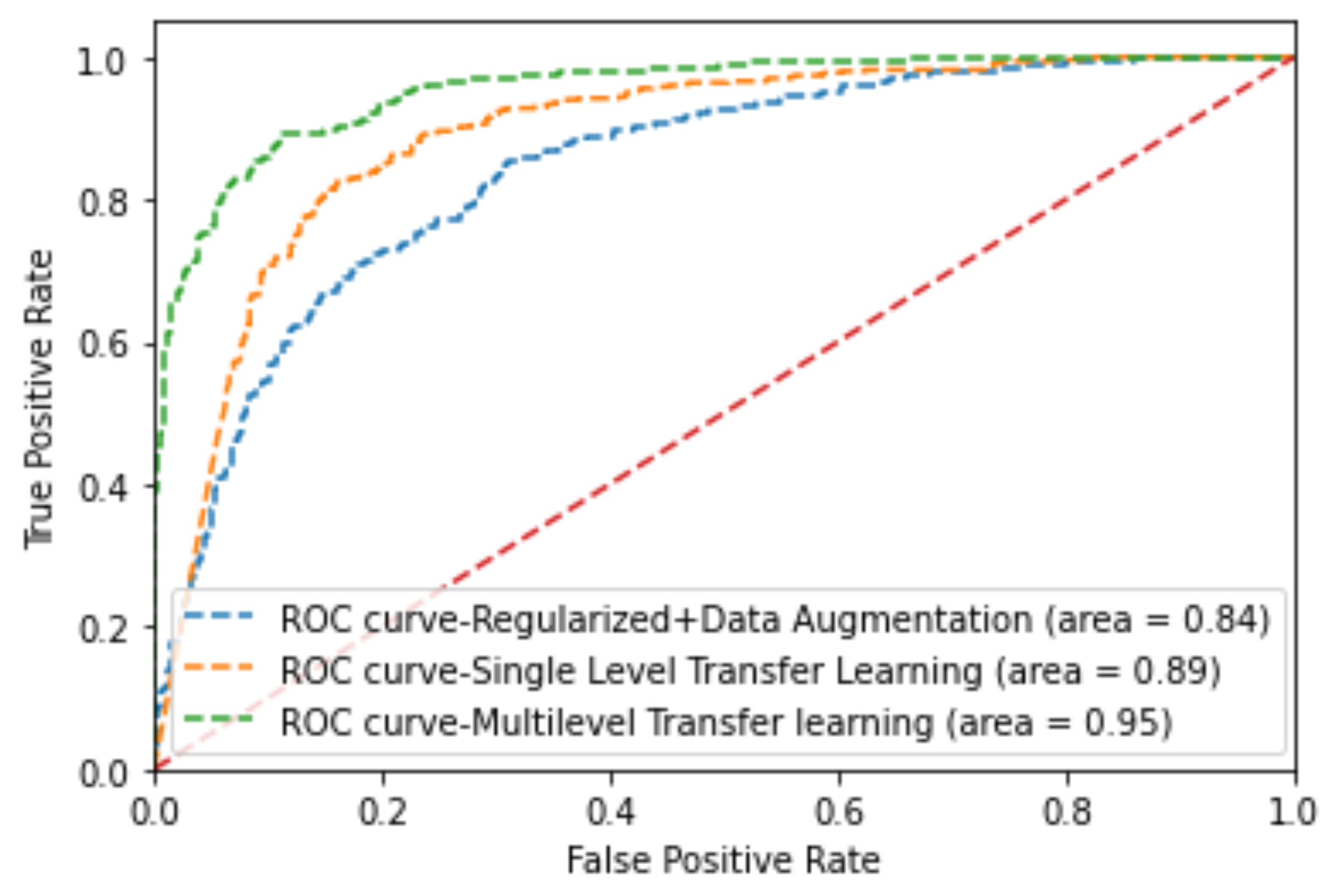
We propose a multi-level transfer learning model for thyroid nodule diagnosis which uses breast ultrasound images as a bridge dataset. We utilize a new concept of multi-level transfer learning to the thyroid ultrasound images, whereas most of the previous studies are similar to ours but have remained within the traditional transfer learning technique. We test the feasibility of the model and prove its potential for thyroid nodule diagnosis.
We check the effectiveness of breast ultrasound images for use as a bridge dataset in the development of a multi-level transfer learning model for thyroid nodule diagnosis. They are able to show the potential and usefulness in the development of a thyroid nodule classification model.
The remainder of this paper is organized as follows.
Section 2 includes the related works.
Section 3 discusses the proposed approach for the thyroid nodule characterization.
Section 4 discusses the experimental framework.
Section 5 discusses the obtained results. Lastly,
Section 6 contains our concluding remarks.
2. Background
Thyroid nodule diagnosis using machine learning techniques has long been an important research topic that provides aid to clinical diagnosis. This section reviews the state-of-the-art approaches in the development of a computer-aided diagnosing system for thyroid nodules. In the traditional machine learning framework, several works have been proposed for the computer-aided diagnosis of thyroid nodules. In 2008, Keramidas et al. extracted fuzzy local binary patterns as noise-resistant textural features and adopted support vector machine as the classifier [
12]. In 2009, Tsantis et al. proposed a model for thyroid nodule classification in which a set of morphological features (such as mean radius, radius entropy, and radius standard deviation) were extracted from the segmented nodule to describe the shape and boundary regularity of each nodule [
13]. In 2012, Singh and Jindal utilized gray level co-occurrence matrix features to construct a k-nearest neighbor model for thyroid nodule classification [
14]. Acharya et al. utilized Gabor transform to extract the features of thyroid ultrasound images to differentiate benign and malignant nodules. They compared the classification performance of SVM, MLP, KNN, and C4.5 classifiers. In 2014, Acharya et al. extracted grayscale features based on stationary wavelet transform and compared the performance of several common classifiers [
15].
As thyroid nodules vary in shape, size, and internal characteristics, the low-level handcrafted features used in this traditional CAD method can only provide limited differentiating capacity due to their inherent simplicity and locality [
16]. On the other hand, the performance of deep learning models, especially convolutional neural networks, has been superior to conventional learning methods in various visual recognition tasks. By learning hierarchical visual representations in a task-oriented manner, CNNs can capture the semantic characteristics of input images [
16]. Due to this critical advantage, numerous CNN-based CAD methods have been proposed for thyroid nodule diagnosis in recent years.
In 2017, Ma et al. trained two complementary patch-based CNNs of different depths to extract both low-level and high-level features and fused their feature maps for the classification of thyroid nodules [
17]. In 2017, Chi et al. utilized a pre-trained GoogleNet architecture to extract high-level semantic features for the classification of thyroid nodules [
18]. Gao et al. proposed a CAD system based on multi-scale CNN model that achieved better sensitivity [
19]. In 2018, Song et al. proposed a cascaded network for thyroid nodule detection and recognition based on multi-scale SSD network and spatial pyramid architecture [
20]. Recently, Li et al. structured a model for the diagnosis of thyroid cancer based on ResNet50 and Darknet19 [
21]. This model, despite its simplicity in structure, exhibited excellent diagnostic abilities in identifying thyroid cancer. It demonstrated the highest value for AUC, sensitivity, and accuracy compared with the other state-of-the-art deep learning models. Wang et al. conducted a large-scale study on multiple thyroid nodule classification [
22]. Both InceptionResnetv2 and VGG-19 architectures were utilized for the classification [
22]. It was a microscopic histopathological image(rather than an ultrasound image) was used in the investigation. Liu et al. proposed a multi-scale nodule detection approach and a clinical-knowledge-guided CNN for the detection and classification of thyroid nodules. By introducing prior clinical knowledge such as margin, shape, aspect ratio, and composition, the classification results showed an impressive sensitivity of 98.2%, specificity of 95.1%, and accuracy rate of 97% [
16]. The method involves using separate CNNs to extract features within the nodule boundary, around margin areas, and from surrounding tissues [
16]. As a result, the architecture of the network is complex with a higher risk of overfitting [
16]. Juan Wang et al. developed an Artificial Intelligence–based diagnosis model based on both deep learning and handcrafted features based on risk factors described by ACR-TIRADS [
23]. Yifei Chen et al. proposed two kinds of neural networks, which are GoogleNet and U-Net, respectively [
24]. GoogleNet was utilized to obtain the preliminary diagnosis results based on the original thyroid nodules in the ultrasound images. U-Net was used to obtain the segmentation results and medical features are extracted based on the segmentation results. The mRMR feature selector was used as the feature selector. The 140 statistical and texture features were sent to the designed feature selector to obtain 20 features. Then, they were utilized for training an XgBoost classifier. The above CNN-based approaches have achieved good performance in classifications, but they still have limitations in global feature learning and modeling. CNNs always focus on the fusion of local features, owing to the locality of their convolutional kernels. Some improved extraction strategies of global features, such as downsampling and pooling, have been proposed. However, they tend to cause the loss of contextual and spatial information. Jiawei Sun et al. proposed a vision-transformer-based thyroid nodule classification model using contrast learning [
25]. Using ViT helps to explore global features and provide a more accurate classification model. Geng Li et al. proposed a deep-learning-based CAD system and transformer fusing CNN network to segment the malignant thyroid nodule automatically [
26].
As in the above papers, various deep learning networks, training methods, and feature extraction methods were utilized to develop an efficient thyroid nodule diagnosis model. In general, there have been many papers on applying deep learning techniques to achieve computer-aided diagnosis of thyroid nodules. However, only a few of them address the issues regarding small datasets. In 2021, Y. Chen et al. proposed a multi-view ensemble learning model based on a voting mechanism that integrates three kinds of diagnosis results obtained from thyroid ultrasound images. They utilized features from the GoogleNet architecture, medical features obtained from the U-Net architecture, and several statistical and textural features to develop the ensemble model.
To date, Artificial Intelligence–based Computer-aided Diagnosis (AI-CAD) systems have been developed for specific medical fields or specific organs. Integrating these systems and evaluating related organs with similar characteristics would benefit AI-CAD system development. For example, several researchers have reported an association between the incidence rate of thyroid and breast carcinoma, possibly related to the effect of estrogen, which is the transport mechanism of iodine. Considering that thyroid and breast nodules exhibit similar characteristics over high-frequency ultrasound, Zhu et al. developed a generic VGG-based framework to classify thyroid and breast lesions in ultrasound imaging [
4]. Xiaowen Liand et al. proposed a multi-organ CAD system based on CNN for classifying thyroid and breast nodules from ultrasound images [
27]. Inceptive characteristics of Googlenet and CaffeNet were exploited to classify nodules in the ultrasound images.
However, this paper mainly focuses on the concept of inception network and squeeze and excitation network. We also integrate the idea of multi-level transfer learning by considering the relationship between thyroid and breast nodule ultrasound images.




















{kind=link}
{kind=link}
{kind=link}
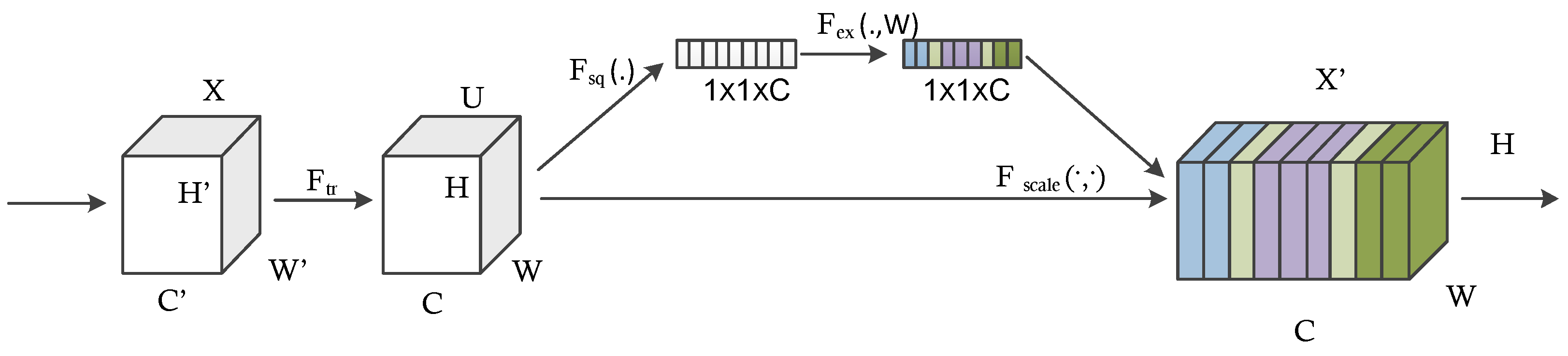{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}