1. Introduction
Over the past two years, the world has endured an unprecedented pandemic, namely COVID-19, which is caused by Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2). Notwithstanding the tremendous efforts that have been undertaken to contain this pandemic at the global level, the world is still dealing with the heavy aftermath, ranging from human losses to economic recessions.
Common medical diagnostic methods of COVID-19 include antibody testing [
1] and quantitative reverse transcription-polymerase chain reaction (qRT-PCR) [
2,
3]. The antibody-testing technique is typically fast, and results can be achieved in quasi real-time. However, its precision remains questionable as it may present high false negative rates for early and active infections. RT-PCR, on the other hand, is relatively much more accurate. However, its prolonged process does not qualify it for real-time use. Furthermore, it may not be as effective in discerning the presence of the virus if there is not enough traces of the virus in the body of the subject [
3,
4,
5].
In this regard, both diagnostic methods are heavily dependent on human expertise to collect and analyze the samples. Moreover, hospitals and medical facilities in many countries have fallen short in their availability of test kits and in their ability to respond to the ongoing influx of test demands, which may encourage the spread of the virus. Thus, improved medical image analysis, if properly addressed, is believed to provide an auxiliary aid to medical experts.
Medical image analysis as a field of study has been gaining ground over the past decade on account of its (typically) non-invasive, quick, and automatic nature. Medical data constitute a paramount component in this sense. It may take the form of unidimensional/bidimensional signals [
6,
7], an image stack [
8], or a large amount of data [
9]. Furthermore, multimodal data sources can also be leveraged [
10].
For the detection of COVID-19, X-ray [
11,
12], ultrasound [
13,
14], and Computed Tomography (CT) [
15] represent the most common sources of medical images. For instance, CT scans have proven useful in the assessment of pulmonary conditions and have demonstrated sound potential in supporting early diagnosis of COVID-19 [
16]. Nevertheless, it requires transfer of the patient to the CT department, a platform-sterilization routine before conducting the test, and the need for the involvement of experts before and after the procedure [
17].
X-ray images provide another useful and cost-effective means of computerized detection of COVID-19 and other lung infections [
15]. However, as the disease progresses, the image features may become less informative [
18,
19].
Ultrasound scanning, on the other hand, offers the possibility to transfer the probing device to the patient room with limited infectious implications and less radiation exposure and provides remarkable diagnostic contributions [
13].
In this context, medical image analysis has been tailored to the detection of many conditions, such as malaria [
20], diabetes [
21], glaucoma [
22], tuberculosis [
23], and many types of cancer [
24,
25,
26], among others [
27]. Nevertheless, traditional pipelines remain limited in terms of performance, owing mainly to the rather shallow and often data-specific representation of the image features adopted. Thanks to the advent of powerful processing hardware, deep learning has emerged as a cutting-edge solution in medical applications [
28,
29,
30,
31,
32,
33,
34].
On this point, with respect to other medical applications, the assessment of deep architectures for the diagnosis of COVID-19 has not developed a solid literature base of research so far. This may be traced back to (i) the fact that the topic has not matured enough and (ii) the scarcity of representative public datasets. Although much attention has been given to deep learning-based COVID-19 image analyses since the outbreak of the virus, still, there is much room for improvement.
This paper presents a novel deep learning pipeline for automatic analysis of COVID-19 using different types of chest medical data, namely Chest X-ray (CXR) and CT images. The main contributions of this study are as follows:
- (1)
Unlike previous deep learning frameworks that only used one type of data, this work uses both CXR and CT images.
- (2)
For the automatic detection and classification of COVID-19, we propose a new approach based on Vision Transformer (ViT).
- (3)
The development of a Siamese encoder that employs a distillation technique to classify original and augmented images.
The remainder of this paper is organized as follows.
Section 2 provides a narrative of existing deep learning work for COVID-19 diagnosis.
Section 3 describes the details of the proposed methodology.
Section 4 describes the adopted data and the experimental setup.
Section 5 presents and discusses the results.
Section 5 concludes the paper.
2. Related Work
The processing of COVID-19 images aims to determine the existence of features potentially associated with infection, namely unilateral or bilateral ground-glass opacities, distributed peripherally, mostly in round and oval shapes [
35,
36,
37]. A comprehensive review for machine learning techniques used for COVID-19 detection and classification based on CXR or CT images was provided in [
38].
Some contributions follow a traditional scheme by combining such features with a classifier to infer the presence of infection. For instance, Mahdy et al. [
39] used a multi-level thresholding for segmenting the X-ray images. The segments were then classified using a Support Vector Machine (SVM) classifier. Barstugan [
40] first proceeded with SVM-based classification without any feature selection and then with features selected via five feature selection methods. The best score was observed using a grey level size zone matrix feature selector along with SVM classification.
Thus far, the literature has accumulated various deep learning methods for COVID-19 detection in X-ray and CT images. For X-ray images, Marques et al. presented an EffecientNet pipeline to classify chest X-ray images into the classes COVID-19, normal, or pneumonia following 10-fold cross validation [
41]. Zabirul Islam et al. combined a convolutional neural network (CNN) and a long short-term memory network for COVID-19 detection in X-ray images [
42]. In [
43], the authors proposed a multiscale attention-guided deep network with soft distance regularization to detect COVID-19 in X-ray images. The proposed network generated a prediction vector and attention from multiscale feature maps. Furthermore, to render the model more robust and to populate the training data, attention-guided augmentations along with a soft distance regularization were adopted. In [
44], wavelet decomposition was incorporated into a convolutional neural network to enable multiresolution analysis. The authors in [
45] proposed detecting COVID-19 in X-ray data by implementing several uncertainty estimation methods such as Softmax scores, Monte-Carlo dropout, and deterministic uncertainty quantification. An ensemble of deep learning models was presented in [
46], where weighted averaging was applied according to the sensitivity of each model towards each class. Heidari et al. fine-tuned a pre-trained VGG16 model to classify X-ray images into three classes [
47]. Abbas et al. applied transfer learning from object recognition (i.e., ImageNet dataset) to X-ray images. The transfer was carried out in three steps, namely (i) decomposition, which consists in applying class decomposition to AlexNet-extracted deep local features; (ii) the transfer phase, where the network weights were fine-tuned for X-ray images; and (iii) the compose phase, which assembles the subclasses of each class [
48]. The dependence of these methods on CXR in the diagnosis reduces the sensitivity of the results of early detection because the sensitivity increases with the progression of the disease [
18,
49,
50].
Regarding CT images, Amyar et al. [
51] constructed a deep network that consisted of a 10-convolutonal-layer encoder stage, a 9-convolutional-layer decoder part for reconstruction, and a 9-convolutional-layer decoder part for segmentation. Xu et al. implemented a VNet and an inception residual network for feature extraction and region proposal network for region-of-interest segmentation [
52]. Sun et al. presented a two-stage feature selection method, namely, a deep forest to learn the high-level features and an adaptive feature selection to find the discriminative features. The selected features were then fed to the four-criteria classifier [
53]. Ko et al. also used transfer learning to compare four pre-trained deep convolutional networks and obtained their best result using ResNet-50 [
54], while Wu et al. transferred the knowledge of a Res2Net and appended an enhanced feature model to detect COVID-19 cases in a two-class CT dataset [
55]. In [
56], a CT image synthesis approach based on a conditional generative adversarial network was proposed to deal with data shortage. Horry et al. proposed a noise-reduction pre-processing step to prepare a hybrid dataset of X-ray, CT, and US images, and the data were then fed into a VGG19 network [
57]. Although processing CT datasets yields better results when diagnosing COVID-19 [
18,
58], there will be always restrictions in reducing patients’ exposure to radiation, which limits the availability of a CT dataset that can optimize the performance of model diagnoses alone [
59,
60].
3. Methodology
Let us consider , a set of n chest medical images, where representative images and their corresponding class labels, , and m is the number of defined classes for this set.
The aim of the proposed method is to learn mapping from the input chest image to the correct class label. The model is based on a Data-Efficient Image Transformer (DeiT) architecture, which is an improved version of Vision Transformer (ViT). ViT’s architecture is fully based on a Data-Efficient Image Transformer (DeiT) architecture, which is an improved version of Vision Transformer (ViT). The architecture of ViT is based entirely on the vanilla Transformer [
61], which has garnered a lot of attention in recent years due to its ability to achieve state-of-the-art (SOTA) performance in machine translation and other natural language-processing applications [
62]. The Transformer architecture is made up of encoder–decoder blocks that allow sequential data to be handled in parallel without the use of any recurrent networks. The success of Transformer models largely comes from the self-attention mechanism, which is proposed to capture long-range relationships between the sequence’s elements. Vision Transformer was proposed as an attempt to extend the use of the standard Transformer to image classification. The main goal was to generalize image classification on modalities other than text without integrating any data-specific architecture. In particular, ViT utilizes the encoder module of the Transformer to perform classification by mapping a sequence of image patches to the semantic label. Unlike the conventional CNN architectures, which typically use filters with a local receptive field, the attention mechanism employed by the Vision Transformer allows it to be used over different regions of the image and to integrate information across the entire image.
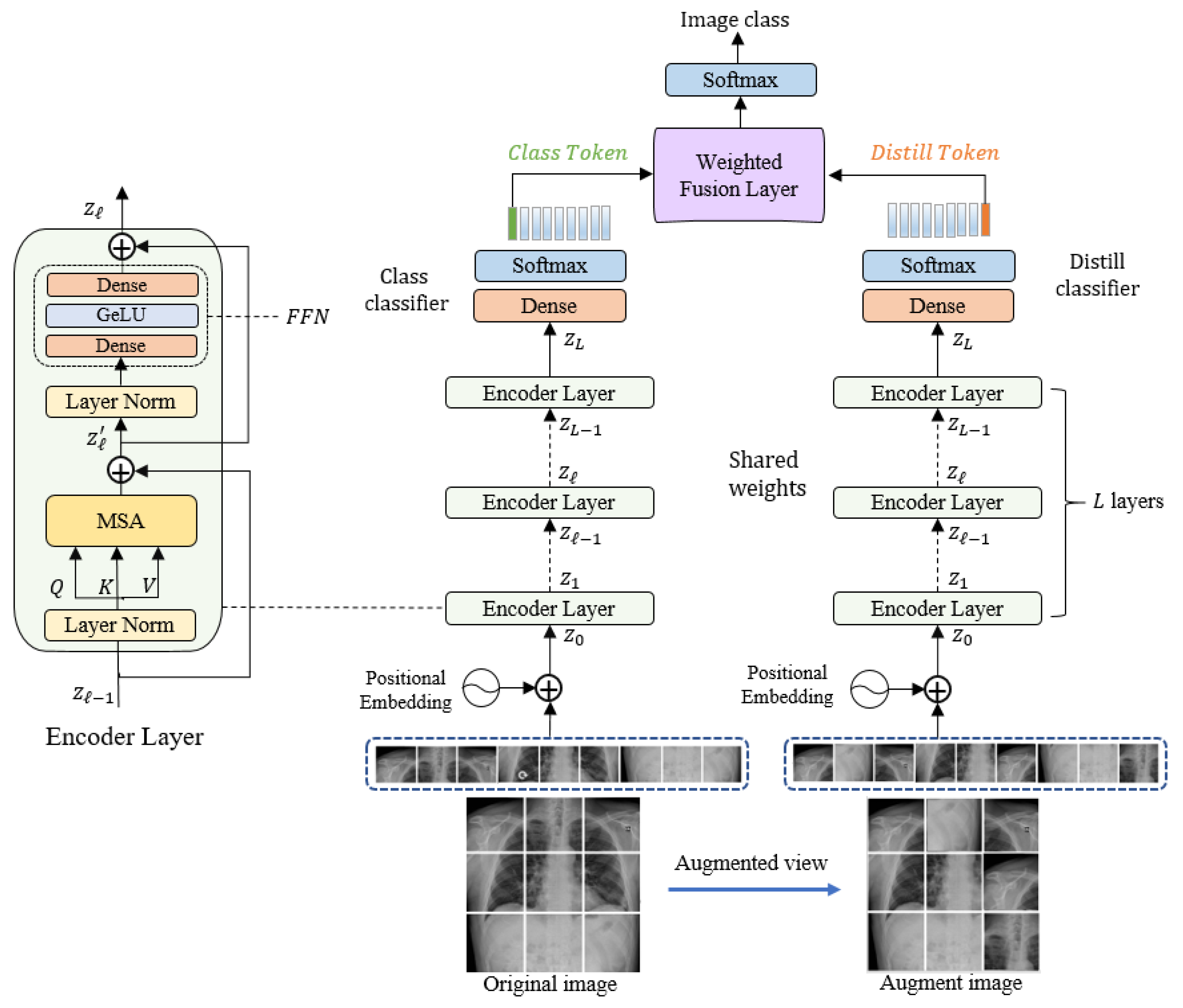
Our proposed model is composed of three main blocks: an embedding layer, a Siamese encoder, and a decoder. The original input image from the training set is processed to generate an augmented input image; then, these two images (original and augmented) are subdivided into non-overlapping patches and fed into the embedding layer, followed by the Siamese encoder. The encoder is also connected to two independent classifiers: the token and distiller classifiers. In the following subsections, we discuss the model’s components in detail.
Figure 1 illustrates the overall structure of the proposed model.
3.1. Linear Embeddimg Layer
First, an augmented view image is generated from the original image by applying a data-augmentation technique. These two images are then converted into a sequence of non-overlapping patches. The original input image and the augmented image of dimension (where and are the height, width, and number of channels, respectively) are then converted into a sequence of length by dividing it into small patches of a fixed dimension of and . These patches are analogous to word tokens in the original Transformer. Before feeding the sequence of patches into the encoder, it is linearly projected into a vector of the model dimension using a learned embedding matrix . The embedded representations are then concatenated together along with a learnable class token that is required to perform the classification task. The flattened image patches are converted into embeddings by feeding them into a linear embedding layer to match their dimension to the model dimension .
To prevent losing the positional information because of the flattening process, each patch embedding is added to its corresponding positional information. The resultant position-aware embeddings are appended with a learnable class token
. Since the decoder is adopted from DeiT architecture, another distillation token
is appended along with the class token to the patch embeddings, as shown in Equation (1). The two tokens and the patch embeddings interact with each other via a self-attention mechanism.
3.2. Siamese Encoder Module
The Siamese architecture of the encoder is adopted from the Data-Efficient Image Transformer (DeiT) architecture. DeiT is an enhanced version of ViT, where less training data are required. The encoder consists of a stack of
identical layers, each one composed of two main blocks: a multi-head self-attention (MSA) block, and a feed-forward network (FFN) block. The MSA, which is a key component of the Transformer encoder, utilizes the self-attention (SA) mechanism to find dependencies between different patches of the input image. Equations (2) and (3) show the details of the calculations that take place in the SA block. First, three different matrices—key
, the query
, and the value
—are generated from the input sequence using three linear layers. By applying an inner product for matching query matrix against the key matrix, an attention-map is generated. The SoftMax function is applied to obtain the output after scaling it by the dimension of the key
. Finally, the result is multiplied with the value
to focus on more important values.
The multi-head self-attention is an extension of SA, in which it runs the SA process in parallel using multiple self-attention heads (
), where
is the number of heads. The aim of using
head is that each head can focus on different relations among the image patches. The outputs of all heads are then concatenated together and projected to the final dimension by a linear layer, as in Equation (4):
where
represents the learned parameters of the final projection matrix.
FNN is the second block in the encoder layer that follows the MSA block. It consists of two fully connected layers with a
GeLU activation function [
63] in between. A layer of normalization (LN) proceeds each of the two encoder layer’s blocks. By applying residual connections, the outputs are computed according to the following Equations (5) and (6):
Similarly, the encoder receives the augmented view of the image, which is subdivided into a sequence of patches. To generate the second view of the image, we applied different image-augmentation techniques. Data-augmentation techniques are appropriate for increasing the size and diversity of the limited-size training dataset, which is the case for medical images datasets. Several data-augmentation techniques that are based on applying simple geometric transformations such as rotating, cropping, or shifting or applying color transformations such as modifying the brightness or the contrast of the images have been implemented in the literature. Recently, several advanced data-augmentation techniques have been applied in the detection of COVID-19 using medical images on generative adversarial network (GAN) [
64,
65], conditional generative adversarial networks (CGAN) [
66], and AdvProp [
67]. More sophisticated techniques based on random erasing and image-mixing have been introduced recently to generate more challenging samples for the model such as the Cutout [
68], Mixup [
69], and CutMix [
70] techniques. In Cutout, a random fixed-size region of the image is intentionally replaced with black pixels or random noise. The process of randomly erasing regions boosts the model to learn from the entire image’s context rather than relying on a specific visual feature. One limitation of using Cutout is losing information since erasing some regions could remove informative parts of image objects [
70]. In this paper, we utilize the Cutout technique to generate augmented images from the original images.
3.3. Classification Layer
The output of the Siamese encoder is fed into the classification layer, which is composed of two connected classifiers: the class and distiller classifiers. Each one is composed of a fully connected layer (FC) with a SoftMax activation function to determine the class labels. We feed the first element of the encoder output
, which represents the classification token to the class classifier.
The second token
represents the distillation and is passed to the distiller classifier.
Then, the outputs are fed into a weighted average fusion layer followed by SoftMax layer to obtain the final class of the predicted class of the input image according to the following equation:
3.4. Network Optimization
To learn the model for the binary (CT dataset) or multi-class (CXR dataset) classification, we use the following loss function:
where
and h are number of training images and defined classes, respectively; ground-truth labels are represented by
(CT dataset) or
(CXR dataset), and
is the predicted probability. The learning is performed by minimizing a total loss consisting of two terms given by the following equation:
where
represents the binary cross-entropy loss, shown in Equation (10),
states the ground-truth labels,
is classification tokens, and
represent the distillation tokens.
In the following Algorithm 1, we provide the main steps for training and testing the model.
| Algorithm 1: Main steps for training and testing the model.
|
Input: Training set of n chest images with corresponding ground-truth labels.
Output: test images predicted class labels
- 1.
Set parameters of the model:
Image size: 224. Patch size p: 16. Mini-batch size b: 50. Learning rate: 0.0001. Optimizer: Adam
- 2.
Set the number of mini-batches as:
- 3.
For iteration = 1: number of iteration (25) - 3.1
For batch = 1 number of mini batches Augmented view images. Feed the obtained training set batch to the Siamese encoder’s class branch. Feed the generated batch of augmented images to the Siamese encoder’s distill branch. Classification token is fed to the token classifier and distiller token is fed to distiller classifier. Loss is calculated using Equation (11) Loss Backpropagation. Update the parameters of the model.
- 4.
Feed the test images to the model. - 5.
Feed the model with test images - 6.
Calculate the predicting labels using the weighted average fusion of the two outputs and according to Equation (9).
|


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}