1. Introduction
Aluminum alloys are some of the most relevant metallic materials of the industry and they play a very important role in some high-technology fields such as aerospace and in everyday industries such as food packaging [
1], among other reasons, due to its high strength-to-weight ratio. Aluminum production and consumption has grown by approximately
in the last decade and this rate is estimated to accelerate over the next few years [
2,
3]. In addition, it is expected to play a fundamental role at the ecological and environmental level because it is a relatively easy material to recycle [
3].
Besides, aluminum alloys are the most frequent type of non-ferrous material employed for an extensive range of applications, namely in the automotive, aerospace, and structural industries, among others [
4]. Widespread use of these alloys in the modern world is due to an exceptional blend of material properties, combining low density, excellent strength, corrosion resistance, toughness, electrical and thermal conductivity, recyclability and manufacturability. Another key factor is the relatively low cost of aluminum machining, making its alloys very attractive for applications in different sectors [
4].
Aluminum was only discovered in the early 19th century, however, despite its short history, it has become an essential material. Every day, new uses for aluminum alloys are emerging in various industrial sectors due to its excellent properties [
5] and the fact that the price of the raw material has been decreasing since then [
2]. Therefore, it is necessary to provide material scientists with tools that can be used to develop new alloys with properties optimized for each need. The mechanical properties of a material play an important role in the performance of industrial components. A correct in-service behavior depends largely on the characteristics of the materials that constitute it, as inadequate material properties can cause premature failure [
6,
7]. Therefore, the decision to choose a specific material to manufacture an industrial component greatly affects its ability to carry out the work for which it was designed [
8,
9,
10].
There are thousands of aluminum alloys although only a few of them are commonly used in the industry [
11], in some cases due to the difficulty of finding new solutions and, in others, because they are specific materials with optimized characteristics for the mission they fulfill.
Knowing the properties of the materials employed in industrial designs is crucial; however, obtaining these data often involves accessing large amounts of resources, which are commonly not available. Multitude of tests are needed to obtain significant information, which entails that enough time, personnel and facilities must be available at a given cost [
6]. The process of characterizing a material may involve a bulk of tests that requires a substantial amount of time and the investment of vast quantities of resources [
12].
Despite the fact that there are multiple decision support systems and materials selection methodologies [
13] applied to materials science, there are few references which mention the use of artificial intelligence-based technologies in the field of metal processing and engineering [
6,
14,
15,
16,
17,
18]. Although there are many studies that use machine learning to investigate the microstructure of metals and their properties [
19,
20,
21], there are hardly any references with an industrial approach that take into account the tempers of aluminum alloys [
22].
Nevertheless, it is possible to find a greater number of references that develop techniques based on artificial intelligence applied to other industrial materials, mainly steel [
23]. These studies take advantage of the ability of these tools to obtain predictions about the behavior or properties of a certain material or industrial component [
24,
25,
26,
27,
28].
In this work, a decision support system is developed which is capable of predicting some of the most important properties that define the stress-strain curve of aluminum alloys whose chemical composition and treatments (thermal and mechanical) are known. This system is capable of predicting the Young’s modulus (
E), the yield stress (
), the ultimate tensile strength (
) and the elongation at break (
A). These four properties define the elastic and plastic behavior of a material under tension [
29].
The difficulty of developing this study lies in the large number of steps and disciplines involved in carrying it out: an extensive software has been developed in Python 3.7 [
30] capable of working without user intervention to download data from an on-line material library [
31], filter and organize data, define and train an artificial neural network [
32], and, finally, make predictions using that network. On the other hand, a great deal of work has been required to analyze data and define criteria based on materials science [
33]. Developing the software to obtain and download the data to carry out this study has been one of the most delicate and time consuming steps.
1.2. Modelization of Stress-Strain Curve
The stress-strain curve shows, in a simple way, the deformation of a material when it is subjected to mechanical load. In this diagram, the stress is plotted on
y-axis and its corresponding strain on the
x-axis [
39]. Tension tests provide information on the strength and ductility of materials under uniaxial tensile stresses. This information may be useful in comparisons of materials, alloy development, quality control, numerical simulation such as finite element modeling, and design under certain circumstances [
40].
The stress-strain curve is a crucial material asset and there are several standard testing methods to measure this curve, such as the tensile test [
40], the compression test and the torsion test [
38]. Although several studies have reported extension of the strain range [
41], achieving a large strain with those methods sometimes can be difficult because the specimen tends to break at relative small strain points.
The simplest loading to visualize is a one-dimensional tensile test, in which a slender test specimen is stretched along its axis [
42]. The stress-strain curve is a representation of the deformation of the specimen as the applied load is increased monotonically, usually to fracture [
39]. Stress-strain curves are usually presented as:
A stress-strain curve combines a lot of information about the material and its behavior [
43]. In this work, four of its properties will be studied:
Young’s modulus (
E)—it is a mechanical property that measures the stiffness of a material and characterizes its behavior in the elastic zone according to the Hooke’s law. It defines the ratio between uniaxial applied force and deformation of a material in the linear elastic regime (see Equation (
1)) [
44]:
where
E is the Young’s modulus,
is the stress and
is the strain.
Yield strength (
): it is a property of the material that indicates the point at which the material begins to deform plastically. Stresses lower than the
do not produce permanent deformations, whereas higher ones produce deformations that will remain even when the applied forces are eliminated [
45].
Ultimate tensile strength (
): the maximum stress that the material can withstand without area reduction [
43].
Elongation at break (
A): the maximum strain that the material can withstand before failure [
43].
These four properties completely define the bilinear approximation of the stress-strain curve of a material and allow summarizing the elasto-plastic stress behavior of a material to four values.
The stress-strain curve also indicates the amount of energy a material can store before fracture since the area enclosed below the curve is the energy that the material absorbs during its deformation [
43,
46]. The energy that a material absorbs is called resilience if the deformation is elastic and toughness if the deformation is plastic. This energy can be calculated using the Equation (
2):
where
U is the total deformation energy (absorbed energy),
is the resilience,
T is the toughness,
A is the elongation at break,
is the stress and
is the strain.
Since the transition from elastic to plastic behavior is continuous, for aluminum alloys (and for many other materials), there is no singular point that delimits them [
47]. Therefore, standardization organizations have selected a criterion that guarantees the reproducibility of the tests—the yield point is defined as that in which there is a deviation of
of strain with respect to the elastic linear behavior [
48,
49].
Figure 1 shows the true stress-strain curves of some relevant aluminum alloys. It is easy to distinguish the elastic regime (linear and very steep) and the plastic regime, where the curve slope decreases and becomes flatter. Thus, there is an obvious rapid change near the yield point.
To carry out some industrial design tasks, it is very common to use analytical models that allow the real curve of a material to be approximated using mathematical functions [
51]. The behavior of aluminum alloys can be approximated very well by the expression of the Ramberg-Osgood stress-strain law [
52] or by a bilinear stress-strain diagram, which is an accurate approximation away from the yield point [
46,
51,
53,
54,
55].
The Ramberg-Osgood expression represents the elastoplastic behavior of the material throughout all its admissible strain values (see Equation (
3)) [
52,
56].
where
is the strain,
is the applied stress,
E is the Young’s modulus,
is the yield strength, and
and
n are two parameters that depend on the material.
On the other hand, the bilinear approximation of the stress-strain curve consists of two lines that represent, respectively, the linear behavior (whose slope is the Young’s modulus,
E) and the plastic behavior (whose slope is the strain hardening modulus,
) [
43,
56]. These two lines intersect at the yield point (see Equations (
4) and (
5)).
where
is the strain,
is the applied stress,
E is the Young’s modulus,
is the yield strength and
is strain hardening modulus (the slope of the line that defines the plastic behavior).
Figure 2 shows a comparison between the actual stress-strain curve of a generic aluminum alloy and its bilinear approximation [
55]. As can be seen, the fit of the simplified model is good away from the yield point, where the discrepancies are significant [
56].
The shape of the stress-strain curve (real and approximate) and its values depend on [
39]:
Alloy chemical composition.
Heat treatment and conditioning.
Prior history of plastic deformation.
The strain rate of the test.
Temperature.
Orientation of applied stress relative to the structure of the test specimens.
Size and shape.
The latter four parameters are described in the pertinent standards, including the case of aluminum testing specimens [
40,
57]. The former three parameters are the ones that are considered in this study.
4. Example of Application
The Al 2024-T4 alloy has been selected to develop this example because there is extensive information about it, it is easily comparable with data from leading sources and it is a widely used industrial material. Al 2024-T4 is a copper-based aluminum alloy (Al 2xxx) that has been treated with the T4 temper (solution heat-treated and natural aged) [
81]. It has the highest ductility compared to the other variants of 2024 aluminum [
1].
This is one of the best-known aluminum alloys due to its high strength and excellent fatigue behavior; it is widely used in structures and parts where a good strength-to-weight ratio is required [
34]. Al 2024 alloy is easily machined to a high quality surface finish; moreover, it is easily plastically formed in the annealed condition (Al 2024-O) and, then, can be heat-treated to become Al 2024-T4. Since its resistance to corrosion is relatively low, this aluminum is commonly used with some type of coating or surface treatment [
37].
Table 5 shows the chemical composition of Al 2024-T4 and
Table 6 shows the mechanical properties that are relevant to this study [
93].
Before launching the software that carries out the training and prediction, to avoid overfitting, all references to Al 2024-T4 and -T351 (this is an identical standard regarding mechanical properties [
93]) have been removed from the input dataset. In the same way as previously explained, 10 training-prediction iterations have been executed.
Table 7 shows the actual values (Actual val.) and the results of the prediction of the mechanical properties of Al 2024-T4, as well as some other statistical metrics that allow quantifying the error and the performance of the methodology for this particular case: average predicted value (Avg. val.), statistical standard deviation of the predictions (Std. Dev.), median, maximum (Max.) and minimum (Min.).
Table 8 shows various statistical results that summarize the predictive error for this alloy (the results are shown as a percentage). Note that the average errors do not exceed, in any case,
. The same information can be seen in
Figure 17. With this information, it can be assured that the results adjust very well to the actual values.
Note that the distribution of average errors is consistent with what was said previously: the better predictive performances have been obtained for the Young’s modulus and the ultimate tensile strength, and the worse results for the yield strength and the elongation at break. This is also true for the statistical standard deviation values.
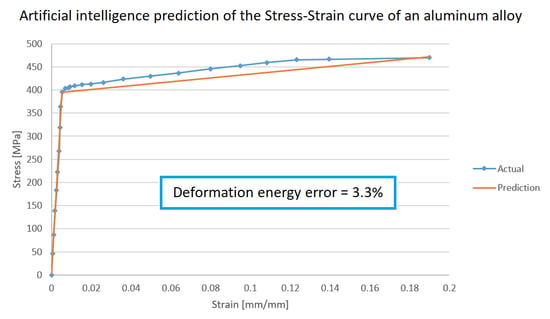
Figure 18 shows the actual stress-strain curve for Al 2024-T6 [
50] and its bilinear approximation using the average values resulting from the prediction using the methodology described in this work (see
Table 7). Note that the predicted curve fits the actual one (especially in the elastic region); however, discrepancies appear near the yield point and in the plastic zone.
The discrepancy between the two curves can be quantified by calculating the difference in deformation energies (see Equation (
2)) [
43,
46]. This is equivalent to calculating the area enclosed between both curves. The deformation energy difference between the two curves is
MJ, so,
of the actual energy (
MJ). This deviation is also an indication of the error made when using the approximation instead of the real curve.
Keeping the methodology error below
implies a similar performance as the typical artificial intelligence-based methodologies applied to materials science [
24,
25]. On the other hand, a similar error rate would be comparable, according to the Lean Manufacturing framework, to that of an industrial system working at a four-sigma level, which has traditionally been associated with the average industry in developed countries [
94,
95].
As already indicated, obtaining the stress-strain curve of a material is a slow, expensive and resource-intensive process. However, based on this example, it can be said that using the methodology described in this paper allows shortening deadlines and having an estimate of the expected results.
Author Contributions
Conceptualization, D.M.F., A.R.-P. and A.M.C.; methodology, D.M.F.; software, D.M.F.; validation, D.M.F., A.R.-P. and A.M.C.; formal analysis, D.M.F.; investigation, D.M.F.; resources, A.R.-P. and A.M.C.; data curation, D.M.F.; writing–original draft preparation, D.M.F.; writing–review and editing, D.M.F., A.R.-P. and A.M.C.; visualization, D.M.F.; supervision, A.R.-P. and A.M.C.; project administration, A.M.C.; funding acquisition, A.M.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been developed within the framework of the Doctorate Program in Industrial Technologies of the UNED and has been funded by the Annual Grants Call of the E.T.S.I.I. of the UNED via the projects of reference 2020-ICF04/B and 2020-ICF04/D.
Acknowledgments
We extend our acknowledgments to the Research Group of the UNED “Industrial Production and Manufacturing Engineering (IPME)”. We also thank Matmatch GmbH for freely supplying all the material data employed to accomplish this study.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations and symbols are used in this manuscript:
| A | Elongation at break |
| Ramberg-Osgood parameter |
| ADAM | Adaptive Moment Estimation |
| AI | Artificial intelligence |
| ANN | Artificial Neural Networks |
| ADAM algorithm parameter |
| E | Young’s modulus |
| Strain hardening modulus |
| ADAM stability factor |
| Prediction error of a neural network |
| Strain |
| ADAM step size |
| f | Error function |
| g | Gradient of the error function |
| m | ADAM first moment estimate |
| n | Ramberg-Osgood parameter |
| Stress |
| Yield stress |
| Ultimate tensile strength |
| v | ADAM second moment estimate |
| w | Weights vector |
| Yield stress |
Appendix B. Neural Network Mathematical Explanation
A multi-layer neural network can be trained to learn a non-linear function [
32] of the form (see Equation (
A1)):
where
is the input vector,
m is the size of the input vector and
o is the size of the output vector [
66].
The neural network learning procedure is known as training, which is mathematically based on the gradient descent problem that tries to minimize the associated error function [
32]. That error function depends on the weights related with each of the perceptrons. This vector of weights (whose size is equal to the number of neurons in the network) is represented as
w and allows indicating that
is the error function when the weights
w are assigned to each of the perceptrons of the network. With this formalization, the objective of the training is to find the vector
for which a global minimum of the function
f is obtained, which turns the learning problem into an optimization problem [
6].
In this way, a neural network is initialized with a vector of weights (in general, random) and, then, a new vector is calculated to reduce the error function [
32]. This process is iterated until the error has been limited or until a specific stopping condition is satisfied. Since the error function is differentiable, the gradient of this function can be defined for each of the optimization steps (see Equation (
A2)) [
6]:
where
is the gradient value of the error function in the
i-th step of the iteration,
is the value of the error function in the
i-th step and
is the vector of weights in the
i-th iteration.
Adaptive Moment Estimation (ADAM) is an adaptive learning rate methodology that calculates individual learning rates for different parameters. ADAM uses estimates of the first and second moment of a gradient to adapt the learning rate for each weight of the neural network [
85]. Using this method, in each iteration, the new weight vector is calculated as (see Equation (
A3)) [
85]:
where
is the step size (a value that graduates the relevance of the gradient factor),
is the stability factor of the algorithm (constant) and
and
are the bias-corrected first and second moment estimate, which are calculated as follows (refer to Equations (
A4) and (
A5)) [
85]:
where
and
are the algorithm parameters that are set to a value near 1 [
72];
and
are calculated as follows (refer to Equations (
A6) and (
A7)) [
85]:
where
and
are the decaying averages of past gradients and past squared gradients, respectively, and are estimates of the first moment (mean) and the second moment (non-centered variance) of the gradients [
85].
Therefore, the optimization process and the network training method have been mathematically defined.
Once the network has been conveniently trained, predictions can be obtained based on the approximation function learned by the neural network [
6]. The prediction deviation is calculated as the absolute value of the relative error of the resulting value (refer to Equation (
A8)):
where
is the relative predictive error (in absolute value),
is the predicted value (resulting value of the network) and
is the actual value.
The nodes of an artificial neural network can be connected in many ways, forming different network topologies. The behavior of the system, its learning capacity and the amount of resources it will need during the training and prediction phases depends greatly on the chosen topology [
78]. A fully connected artificial neural network consists of a set of fully connected layers and a fully connected layer is a layer in which all nodes are connected to all nodes of the next layer [
32].
For a fully connected multilayer neural network, the time complexity of the backpropagation training is given by Equation (
A9). So, it is highly recommended to minimize the number of hidden nodes to reduce the training time [
78].
where
n is the size of the training dataset,
m is the number of features,
o is the number of output perceptrons,
N is the number of iterations and
k is the number of hidden layers (each of them containing
nodes).
References
- Danylenko, M. Aluminium alloys in aerospace. Alum. Int. Today 2018, 31, 35. [Google Scholar]
- Galevsky, G.; Rudneva, V.; Aleksandrov, V. Current State of the World and Domestic Aluminium Production and Consumption; IOP Conference Series: Materials Science and Engineering; IOP Publishing: Novokuznetsk, Russia, 2018; Volume 411, p. 012017. [Google Scholar]
- Soo, V.K.; Peeters, J.; Paraskevas, D.; Compston, P.; Doolan, M.; Duflou, J.R. Sustainable aluminium recycling of end-of-life products: A joining techniques perspective. J. Clean. Prod. 2018, 178, 119–132. [Google Scholar] [CrossRef] [Green Version]
- Branco, R.; Berto, F.; Kotousov, A. Mechanical Behaviour of Aluminium Alloys; MDPI Applied Sciences: Basel, Switzerland, 2018. [Google Scholar]
- Ashkenazi, D. How aluminum changed the world: A metallurgical revolution through technological and cultural perspectives. Technol. Forecast. Soc. Chang. 2019, 143, 101–113. [Google Scholar] [CrossRef]
- Merayo, D.; Rodríguez-Prieto, A.; Camacho, A. Prediction of Physical and Mechanical Properties for Metallic Materials Selection Using Big Data and Artificial Neural Networks. IEEE Access 2020, 8, 13444–13456. [Google Scholar] [CrossRef]
- Morini, A.A.; Ribeiro, M.J.; Hotza, D. Early-stage materials selection based on embodied energy and carbon footprint. Mater. Des. 2019, 178, 107861. [Google Scholar] [CrossRef]
- Piselli, A.; Baxter, W.; Simonato, M.; Del Curto, B.; Aurisicchio, M. Development and evaluation of a methodology to integrate technical and sensorial properties in materials selection. Mater. Des. 2018, 153, 259–272. [Google Scholar] [CrossRef] [Green Version]
- Mousavi-Nasab, S.H.; Sotoudeh-Anvari, A. A comprehensive MCDM-based approach using TOPSIS, COPRAS and DEA as an auxiliary tool for material selection problems. Mater. Des. 2017, 121, 237–253. [Google Scholar] [CrossRef]
- Das, D.; Bhattacharya, S.; Sarkar, B. Decision-based design-driven material selection: A normative-prescriptive approach for simultaneous selection of material and geometric variables in gear design. Mater. Des. 2016, 92, 787–793. [Google Scholar] [CrossRef]
- Alam, T.; Ansari, A.H. Review on Aluminium and its alloys for automotive applications. Int. J. Adv. Technol. Eng. Sci. 2017, 5, 278–294. [Google Scholar]
- Kamaya, M.; Kawakubo, M. A procedure for determining the true stress–strain curve over a large range of strains using digital image correlation and finite element analysis. Mech. Mater. 2011, 43, 243–253. [Google Scholar] [CrossRef]
- Rodríguez-Prieto, Á.; Camacho, A.M.; Sebastián, M.Á. Materials selection criteria for nuclear power applications: A decision algorithm. JOM 2016, 68, 496–506. [Google Scholar] [CrossRef]
- Dimiduk, D.M.; Holm, E.A.; Niezgoda, S.R. Perspectives on the impact of machine learning, deep learning, and artificial intelligence on materials, processes, and structures engineering. Integr. Mater. Manuf. Innov. 2018, 7, 157–172. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Zhao, T.; Ju, W.; Shi, S. Materials discovery and design using machine learning. J. Mater. 2017, 3, 159–177. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, X.; Li, X.; Xie, Z.; Liu, R.; Liu, W.; Zhang, Y.; Xu, Y.; Liu, C. Prediction and Analysis of Tensile Properties of Austenitic Stainless Steel Using Artificial Neural Network. Metals 2020, 10, 234. [Google Scholar] [CrossRef] [Green Version]
- Javaheri, E.; Kumala, V.; Javaheri, A.; Rawassizadeh, R.; Lubritz, J.; Graf, B.; Rethmeier, M. Quantifying Mechanical Properties of Automotive Steels with Deep Learning Based Computer Vision Algorithms. Metals 2020, 10, 163. [Google Scholar] [CrossRef] [Green Version]
- Abbas, A.T.; Pimenov, D.Y.; Erdakov, I.N.; Taha, M.A.; El Rayes, M.M.; Soliman, M.S. Artificial intelligence monitoring of hardening methods and cutting conditions and their effects on surface roughness, performance, and finish turning costs of solid-state recycled Aluminum alloy 6061 chips. Metals 2018, 8, 394. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Song, Z.; Sundmacher, K. Big Data Creates New Opportunities for Materials Research: A Review on Methods and Applications of Machine Learning for Materials Design. Engineering 2019, 5, 1017–1026. [Google Scholar] [CrossRef]
- Schmidt, J.; Marques, M.R.; Botti, S.; Marques, M.A. Recent advances and applications of machine learning in solid-state materials science. Npj Comput. Mater. 2019, 5, 1–36. [Google Scholar] [CrossRef]
- Ly, H.B.; Le, L.M.; Duong, H.T.; Nguyen, T.C.; Pham, T.A.; Le, T.T.; Le, V.M.; Nguyen-Ngoc, L.; Pham, B.T. Hybrid artificial intelligence approaches for predicting critical buckling load of structural members under compression considering the influence of initial geometric imperfections. Appl. Sci. 2019, 9, 2258. [Google Scholar] [CrossRef] [Green Version]
- Ling, J.; Antono, E.; Bajaj, S.; Paradiso, S.; Hutchinson, M.; Meredig, B.; Gibbons, B.M. Machine Learning for Alloy Composition and Process Optimization. In Proceedings of the ASME Turbo Expo 2018: Turbomachinery Technical Conference and Exposition, Oslo, Norway, 11–15 June 2018; American Society of Mechanical Engineers Digital Collection: New York, NY, USA, 2018. [Google Scholar]
- Twardowski, P.; Wiciak-Pikuła, M. Prediction of Tool Wear Using Artificial Neural Networks during Turning of Hardened Steel. Materials 2019, 12, 3091. [Google Scholar] [CrossRef] [Green Version]
- Asteris, P.G.; Roussis, P.C.; Douvika, M.G. Feed-forward neural network prediction of the mechanical properties of sandcrete materials. Sensors 2017, 17, 1344. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Filippis, L.A.C.; Serio, L.M.; Facchini, F.; Mummolo, G.; Ludovico, A.D. Prediction of the vickers microhardness and ultimate tensile strength of AA5754 H111 friction stir welding butt joints using artificial neural network. Materials 2016, 9, 915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moayedi, H.; Kalantar, B.; Abdullahi, M.M.; Rashid, A.S.A.; Nazir, R.; Nguyen, H. Determination of Young Elasticity Modulus in Bored Piles Through the Global Strain Extensometer Sensors and Real-Time Monitoring Data. Appl. Sci. 2019, 9, 3060. [Google Scholar] [CrossRef] [Green Version]
- Sun, D.; Lonbani, M.; Askarian, B.; Armaghani, D.J.; Tarinejad, R.; Pham, B.T.; Huynh, V.V. Investigating the Applications of Machine Learning Techniques to Predict the Rock Brittleness Index. Appl. Sci. 2020, 10, 1691. [Google Scholar] [CrossRef] [Green Version]
- Abambres, M.; Rajana, K.; Tsavdaridis, K.D.; Ribeiro, T.P. Neural Network-based formula for the buckling load prediction of I-section cellular steel beams. Computers 2019, 8, 2. [Google Scholar] [CrossRef] [Green Version]
- Szumigała, M.; Polus, Ł. An numerical simulation of an aluminium-concrete beam. Procedia Eng. 2017, 172, 1086–1092. [Google Scholar]
- Lutz, M. Programming Python: Powerful Object-Oriented Programming; O’Reilly Media, Inc.: Newton, MA, USA, 2010. [Google Scholar]
- GmbH, Matmatch Matmatch. Available online: https://matmatch.com/ (accessed on 15 April 2020).
- Jackson, P.C. Introduction to Artificial Intelligence; Courier Dover Publications: Mineola, NY, USA, 2019. [Google Scholar]
- Callister, W.D.; Rethwisch, D.G. Materials Science and Engineering; John Wiley & Sons: New York, NY, USA, 2011; Volume 5. [Google Scholar]
- Kaufman, J.G. Introduction to Aluminum Alloys and Tempers; ASM International: Almere, The Netherlands, 2000. [Google Scholar]
- Davis, J.R. Alloying: Understanding the Basics; ASM International: Almere, The Netherlands, 2001. [Google Scholar]
- Scamans, G.; Butler, E. In situ observations of crystalline oxide formation during aluminum and aluminum alloy oxidation. Metall. Trans. A 1975, 6, 2055–2063. [Google Scholar] [CrossRef]
- Gui, F. Novel corrosion schemes for the aerospace industry. In Corrosion Control in the Aerospace Industry; Elsevier: Amsterdam, The Netherlands, 2009; pp. 248–265. [Google Scholar]
- Yogo, Y.; Sawamura, M.; Iwata, N.; Yukawa, N. Stress-strain curve measurements of aluminum alloy and carbon steel by unconstrained-type high-pressure torsion testing. Mater. Des. 2017, 122, 226–235. [Google Scholar] [CrossRef]
- ASM. Atlas of Stress-Strain Curves; ASM: Almere, The Netherlands, 2002. [Google Scholar]
- ASTM, E8–99. Standard Test Methods for Tension Testing of Metallic Materials (ASTM E8/E8M–16AE1); ASTM: West Conshohocken, PA, USA, 2001. [Google Scholar]
- Bacha, A.; Maurice, C.; Klocker, H.; Driver, J.H. The large strain flow stress behaviour of aluminium alloys as measured by channel-die compression (20-500 C). Mater. Sci. Forum 2006, 519, 783–788. [Google Scholar] [CrossRef]
- Huang, C.; Jia, X.; Zhang, Z. A modified back propagation artificial neural network model based on genetic algorithm to predict the flow behavior of 5754 aluminum alloy. Materials 2018, 11, 855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nageim, H.; Durka, F.; Morgan, W.; Williams, D. Structural Mechanics–Loads, Analysis. In Materials and Design of Structural Elements, 7th ed.; Pearson International: England, UK, 2010. [Google Scholar]
- ASTM, Committee E-28 on Mechanical Testing. Standard Test Method for Young’s Modulus, Tangent Modulus, and Chord Modulus; ASTM International: West Conshohocken, PA, USA, 2004. [Google Scholar]
- Hahn, G.; Rosenfield, A. Metallurgical factors affecting fracture toughness of aluminum alloys. Metall. Trans. A 1975, 6, 653–668. [Google Scholar] [CrossRef]
- Fertis, D.G. Infrastructure Systems: Mechanics, Design, and Analysis of Components; John Wiley & Sons: Hoboken, NJ, USA, 1997; Volume 3. [Google Scholar]
- Christensen, R.M. Observations on the definition of yield stress. Acta Mech. 2008, 196, 239–244. [Google Scholar] [CrossRef]
- Christensen, R.M. The Theory of Materials Failure; Oxford University Press: Oxford, UK, 2013. [Google Scholar]
- Johnson, G.; Holmquist, T. Test Data and Computational Strength and Fracture Model Constants for 23 Materials Subjected to Large Strains, High Strain Rates, and High Temperatures; Los Alamos National Laboratory, LA-11463-MS: Los Alamos, NM, USA, 1989; Volume 198.
- Nicholas, T. Material behavior at high strain rates. Impact Dyn. 1982, 1, 277–332. [Google Scholar]
- Gere, J.; Goodno, B. Deflections of Beams. In Mechanics of Materials, 8th ed.; Cengage Learning: Boston, MA, USA, 2012. [Google Scholar]
- Ramberg, W.; Osgood, W.R. Description of Stress-Strain Curves by Three Parameters; NASA: Washington, DC, USA, 1943.
- Rasmussen, K.J.; Rondal, J. Strength curves for metal columns. J. Struct. Eng. 1997, 123, 721–728. [Google Scholar] [CrossRef]
- Pelletier, H.; Krier, J.; Cornet, A.; Mille, P. Limits of using bilinear stress–strain curve for finite element modeling of nanoindentation response on bulk materials. Thin Solid Films 2000, 379, 147–155. [Google Scholar] [CrossRef]
- Eurocode 9—Design of Aluminium Structures; BSI: London, UK, 2007.
- Mazzolani, F. EN1999 Eurocode 9— Design of aluminium structures. In Proceedings of the Institution of Civil Engineers-Civil Engineering; Thomas Telford Ltd.: London, UK, 2001; Volume 144, pp. 61–64. [Google Scholar]
- ISO-EN. 6892-1. Metallic Materials-Tensile Testing—Part 1: Method of Test at Room Temperature; International Organization for Standardization: Geneva, Switzerland, 2009.
- Agrawal, A.; Choudhary, A. Perspective: Materials informatics and big data: Realization of the “fourth paradigm” of science in materials science. APL Mater. 2016, 4, 053208. [Google Scholar] [CrossRef] [Green Version]
- Song, I.Y.; Zhu, Y. Big data and data science: What should we teach? Expert Syst. 2016, 33, 364–373. [Google Scholar] [CrossRef]
- Rowley, J. The wisdom hierarchy: Representations of the DIKW hierarchy. J. Inf. Sci. 2007, 33, 163–180. [Google Scholar] [CrossRef] [Green Version]
- Batra, S. Big data analytics and its reflections on DIKW hierarchy. Rev. Manag. 2014, 4, 5. [Google Scholar]
- White, A.A. Big data are shaping the future of materials science. MRS Bull. 2013, 38, 594–595. [Google Scholar] [CrossRef] [Green Version]
- García-Gil, D.; Ramírez-Gallego, S.; García, S.; Herrera, F. Principal components analysis random discretization ensemble for big data. Knowl. Based Syst. 2018, 150, 166–174. [Google Scholar] [CrossRef]
- Erl, T.; Khattak, W.; Buhler, P. Big Data Fundamentals: Concepts, Drivers & Techniques; Prentice Hall Press: Upper Saddle River, NJ, USA, 2016. [Google Scholar]
- Weinbub, J.; Wastl, M.; Rupp, K.; Rudolf, F.; Selberherr, S. ViennaMaterials–A dedicated material library for computational science and engineering. Appl. Math. Comput. 2015, 267, 282–293. [Google Scholar] [CrossRef]
- Merayo, D.; Rodriguez-Prieto, A.; Camacho, A. Comparative analysis of artificial intelligence techniques for material selection applied to manufacturing in Industry 4.0. Procedia Manuf. 2019, 41, 42–49. [Google Scholar] [CrossRef]
- Helal, S. The expanding frontier of artificial intelligence. Computer 2018, 51, 14–17. [Google Scholar] [CrossRef]
- McCarthy, J.; Minsky, M.L.; Rochester, N.; Shannon, C.E. A proposal for the dartmouth summer research project on artificial intelligence, August 31, 1955. AI Mag. 2006, 27, 12. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Johnson, K.W.; Soto, J.T.; Glicksberg, B.S.; Shameer, K.; Miotto, R.; Ali, M.; Ashley, E.; Dudley, J.T. Artificial intelligence in cardiology. J. Am. Coll. Cardiol. 2018, 71, 2668–2679. [Google Scholar] [CrossRef]
- Cummings, M. Artificial Intelligence and the Future of Warfare; Chatham House for the Royal Institute of International Affairs London: London, UK, 2017. [Google Scholar]
- Villa, F.; Ceroni, M.; Bagstad, K.; Johnson, G.; Krivov, S. ARIES (Artificial Intelligence for Ecosystem Services): A new tool for ecosystem services assessment, planning, and valuation. In Proceedings of the 11th Annual BIOECON Conference on Economic Instruments to Enhance the Conservation and Sustainable Use of Biodiversity, Venice, Italy, 21–22 September 2009; pp. 21–22. [Google Scholar]
- Allen, G.; Chan, T. Artificial Intelligence and National Security; Belfer Center for Science and International Affairs: Cambridge, MA, USA, 2017. [Google Scholar]
- Ee, J.H.; Huh, N. A study on the relationship between artificial intelligence and change in mathematics education. Commun. Math. Educ. 2018, 32, 23–36. [Google Scholar]
- Kolesov, V. Cognitive Modelling in Oil & Gas Exploration and Reservoir Prediction. In Proceedings of the 80th EAGE Conference and Exhibition 2018, Copenhaga, Dinamarca, 11–14 November 2018; European Association of Geoscientists & Engineers: Houten, The Netherlands, 2018; Volume 2018, pp. 1–5. [Google Scholar]
- Thankachan, T.; Prakash, K.S.; Pleass, C.D.; Rammasamy, D.; Prabakaran, B.; Jothi, S. Artificial neural network to predict the degraded mechanical properties of metallic materials due to the presence of hydrogen. Int. J. Hydrog. Energy 2017, 42, 28612–28621. [Google Scholar] [CrossRef] [Green Version]
- Qian, L.; Winfree, E.; Bruck, J. Neural network computation with DNA strand displacement cascades. Nature 2011, 475, 368–372. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Huang, G.B.; Song, S.; You, K. Trends in extreme learning machines: A review. Neural Netw. 2015, 61, 32–48. [Google Scholar] [CrossRef] [PubMed]
- Joshi, P. Artificial Intelligence with Python; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- The Aluminum Association. International Alloy Designations and Chemical Composition Limits for Wrought Aluminum and Wrought Aluminum Alloys; The Aluminum Association: Arlington, VA, USA, 2015. [Google Scholar]
- The Aluminum Association. Designations and Chemical Composition Limits for Aluminum Alloys in the Form of Castings and Ingot; The Aluminum Association: Arlington, VA, USA, 2006. [Google Scholar]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Deshpande, A.; Kumar, M. Artificial Intelligence for Big Data: Complete Guide to Automating Big Data Solutions Using Artificial Intelligence Techniques; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR 15), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Elmishali, A.; Stern, R.; Kalech, M. An artificial intelligence paradigm for troubleshooting software bugs. Eng. Appl. Artif. Intell. 2018, 69, 147–156. [Google Scholar] [CrossRef]
- Bouanan, Y.; Zacharewicz, G.; Vallespir, B. DEVS modelling and simulation of human social interaction and influence. Eng. Appl. Artif. Intell. 2016, 50, 83–92. [Google Scholar] [CrossRef] [Green Version]
- Perikos, I.; Hatzilygeroudis, I. Recognizing emotions in text using ensemble of classifiers. Eng. Appl. Artif. Intell. 2016, 51, 191–201. [Google Scholar] [CrossRef]
- Li, W.; Le Gall, F.; Spaseski, N. A survey on model-based testing tools for test case generation. In Proceedings of the International Conference on Tools and Methods for Program Analysis, Moscow, Russia, 3–4 March 2017; Springer: Berlin, Germany, 2017; pp. 77–89. [Google Scholar]
- Lal, A. SANE 2.0: System for fine grained named entity typing on textual data. Eng. Appl. Artif. Intell. 2019, 84, 11–17. [Google Scholar] [CrossRef]
- Siegel, J.E.; Pratt, S.; Sun, Y.; Sarma, S.E. Real-time deep neural networks for internet-enabled arc-fault detection. Eng. Appl. Artif. Intell. 2018, 74, 35–42. [Google Scholar] [CrossRef] [Green Version]
- Martín, A.; Rodríguez-Fernández, V.; Camacho, D. CANDYMAN: Classifying Android malware families by modelling dynamic traces with Markov chains. Eng. Appl. Artif. Intell. 2018, 74, 121–133. [Google Scholar] [CrossRef]
- ASM International Handbook Committee. Properties and Selection: Nonferrous Alloys and Special-Purpose Materials Volume 2; ASM Handbook; ASM International: Novelty, OH, USA, 2010. [Google Scholar]
- Socconini, L.V.; Reato, C. Lean Six Sigma; Marge Books: Barcelona, Spain, 2019. [Google Scholar]
- Furterer, S.L. Lean Six Sigma in Service: Applications and Case Studies; CRC press: Boca Raton, FL, USA, 2016. [Google Scholar]
Figure 1.
Example of true stress-strain curves of some aluminum alloys (data from Reference [
50]).
Figure 2.
Actual stress-strain curve and bilineal approximation for an aluminum alloy, data from [
55].
Figure 3.
Methodology scheme.
Figure 4.
Training and prediction phases overview.
Figure 5.
Young’s modulus histogram of the input dataset.
Figure 6.
Prediction deviation of the Young’s modulus.
Figure 7.
Histogram of the prediction error of the Young’s modulus for all iterations.
Figure 8.
Yield strength histogram of the input dataset.
Figure 9.
Prediction deviation of the yield strength.
Figure 10.
Histogram of the prediction error of the yield strength for all iterations.
Figure 11.
Ultimate tensile strength histogram of the input dataset.
Figure 12.
Prediction deviation of the ultiamte tensile strength.
Figure 13.
Histogram of the prediction error of the ultimate tensile strength for all iterations.
Figure 14.
Elongation at break histogram of the input dataset.
Figure 15.
Prediction deviation of the elongation at break.
Figure 16.
Histogram of the prediction error of the elongation at break for all iterations.
Figure 17.
Prediction error for Al 2024-T4.
Figure 18.
Actual stress-strain curve and its bilinear predicted approximation for Al 2024-T4 (actual curve from Reference [
50]).
Table 1.
Average deviation (as %) of the prediction of the Young’s modulus.
| Avg. Dev. | Std. Dev. | Median | Avg. Dev. 90% |
|---|
| 3.07 | 2.24 | 2.35 | 2.87 |
Table 2.
Average deviation (as %) of the prediction of the yield strength.
| Avg. Dev. | Std. Dev. | Median | Avg. Dev. 90% |
|---|
| 4.58 | 3.40 | 3.78 | 4.33 |
Table 3.
Average deviation (as %) of the prediction of the ultimate tensile strength
| Avg. Dev. | Std. Dev. | Median | Avg. Dev. 90% |
|---|
| 3.30 | 2.82 | 2.55 | 3.08 |
Table 4.
Average deviation (as %) of the prediction of the elongation at break.
| Avg. Dev. | Std. Dev. | Median | Avg. Dev. 90% |
|---|
| 5.90 | 4.05 | 5.33 | 5.73 |
Table 5.
Al 2024-T4 chemical composition [
81].
| Element | Weight % |
|---|
| Al | 90.7–94.7 |
| Cr | Max. 0.1 |
| Cu | 3.8–4.9 |
| Fe | Max. 0.5 |
| Mg | 1.2–1.8 |
| Mn | 0.3–0.9 |
| Other | Max. 0.15 |
| Si | Max. 0.5 |
| Ti | Max. 0.15 |
| Zn | Max 0.25 |
Table 6.
Actual mechanical properties of the Al 2024-T4 [
93].
| Property | Value |
|---|
| Young’s modulus [GPa] | 73 |
| Yield strength [MPa] | 395 |
| Ultimate tensile strength [MPa] | 470 |
| Elongation at break [%] | 19 |
Table 7.
Properties prediction for Al 2024-T4.
| Property | Actual val. | Avg. val. | Std. Dev. | Median | Max. | Min. |
|---|
| E [GPa] | 73 | 73.3 | 0.7 | 73.4 | 74.3 | 71.9 |
| [MPa] | 395 | 395.1 | 9.3 | 395.9 | 409.4 | 376.5 |
| [MPa] | 470 | 471.5 | 8.0 | 470.8 | 483.2 | 460.1 |
| A [%] | 19 | 19.0 | 0.8 | 18.9 | 20.1 | 17.7 |
Table 8.
Prediction error for Al 2024-T4 (as %).
| Property | Avg. error | Std. Dev. | Median | Max. | Min. |
|---|
| E [%] | 0.84 | 0.55 | 0.81 | 1.77 | 0.08 |
| [%] | 1.63 | 1.62 | 0.95 | 4.68 | 0.20 |
| [%] | 1.35 | 0.98 | 1.44 | 2.81 | 0.13 |
| A [%] | 3.21 | 2.34 | 3.08 | 6.89 | 0.05 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















