Natural Language Processing Model for Managing Maintenance Requests in Buildings
by
 and
and
Yassine Bouabdallaoui
1,*, 
Zoubeir Lafhaj
1,
Pascal Yim
2,
Laure Ducoulombier
3 and
Belkacem Bennadji
4 1
UMR 9013-LaMcube-Laboratoire de Mécanique, Multiphysique, Multi-échelle, Centrale Lille, University of Lille, CNRS, F-59000 Lille, France
2
UMR 9189-CRIStAL-Centre de Recherche en Informatique Signal et Automatique de Lille, Centrale Lille, University of Lille, CNRS, F-59000 Lille, France
3
Bouygues Construction, 78280 Guyancourt, France
4
Bouygues Energies et Services, 78280 Guyancourt, France
*
Author to whom correspondence should be addressed.
Buildings 2020, 10(9), 160; https://0-doi-org.brum.beds.ac.uk/10.3390/buildings10090160
Submission received: 30 July 2020
/
Revised: 31 August 2020
/
Accepted: 3 September 2020
/
Published: 7 September 2020
(This article belongs to the Special Issue Application of Computer Technology in Buildings)
Abstract
:In recent years, facility management (FM) has adopted many computer technology solutions for building maintenance, such as building information modelling (BIM) and computerized maintenance management systems (CMMS). However, maintenance requests management in buildings remains a manual and a time-consuming process that depends on human management. In this paper, a machine-learning algorithm based on natural language processing (NLP) is proposed to classify maintenance requests. This algorithm aims to assist the FM teams in managing day-to-day maintenance activities. A healthcare facility is addressed as a case study in this work. Ten-year maintenance records from the facility contributed to the design and development of the algorithm. Multiple NLP methods were used in this study, and the results reveal that the NLP model can classify work requests with an average accuracy of 78%. Furthermore, NLP methods have proven to be effective for managing unstructured text data.
1. Introduction
Facility management (FM) is an essential aspect of the life cycle of a building. It is an integrated process to maintain and improve building performances. FM deals with all the operation and maintenance (O&M) activities during the life cycle of a building. Operation and maintenance is the longest phase of a building’s life cycle, and it represents around 60% of the entire life cycle cost [1]. The infrastructure of buildings tends to be increasingly complex and evolves towards a smart building approach which integrates new technologies such as Internet of Things and smart sensors. Consequently, the FM industry faces new challenges to evolve and adapt to this new context.
The FM costs are considered relatively high because of the losses generated by the low-efficiency practices in the FM activity [2]. Those losses not only affect the final costs of the operation and maintenance but also reduce the occupant comfort and satisfaction, especially in critical facilities such as hospitals and healthcare buildings [3]. Inefficient maintenance practices can also lead to high energy loss; around 20% of the building energy consumption is wasted because of faulty operation in buildings’ installations [4]. A significant amount of losses in the FM industry is due to a lack of knowledge and poor information communication between the different stakeholders, leading to ineffective decisions [5]. FM teams depend on real-time, accurate and comprehensive data to perform day-to-day activities and to provide accurate information to top management for decision making [6]. The issue is that, in practice, the activities of inspecting facilities, assessing maintenance and collecting data are labor intensive and time consuming [2], thus affecting the quality and the relevance of data and causing a misleading management decision making.
To improve the management of maintenance data, FM has adopted many digital technology solutions such as building information modelling (BIM) for FM, computer-aided facility management (CAFM) and computerized maintenance management systems (CMMS) [6,7,8]. However, the introduction of digital technology in facility management has not shown the expected results in improving the process of data management and decision making. In many cases, the implementation of digital technology was unsuccessful and caused financial losses and delays for the company [9]. Issues linked to the information infrastructure, such as interoperability, data transfer among software, and information systems limit the efficiency of digital technology in the FM industry.
Recently, machine learning and data science techniques feed many aspects of modern society, including the Internet, finance and insurance, and medical and industrial applications [10]. The facility management industry can benefit from these new techniques in order to better manage the assets and improve data management. Machine learning (ML) and natural language processing (NLP) can help in solving the issues of interoperability and accelerate the data analysis process in the FM field [11].
Text data are commonly used in FM activities and represent a significant portion of data and information generated in the FM field, particularly in maintenance activities [12,13]. Text records are necessary for day-to-day activities, for work requests and maintenance records. They are used to describe work requests or to keep history records of maintenance activities. Text records are also necessary before any decision-makings [13]. Analyzing text data is generally a manual process and time and labor consuming; due to the nature of these data, text fields are mainly unstructured and can contain any word, number or character [13]. This paper aims to explore the use of NLP and machine learning techniques to improve text data management in the FM industry, through a use case of text data management in a healthcare facility.
2. Research Background
2.1. Natural Language Processing
Natural language processing (NLP) covers multiple topics and involves multi-disciplinary fields, such as linguistics, computer science and artificial intelligence. The history of NLP comes back to the early 1950s with the Turing Test [14]. Since the 1980s, NLP relied on statistics and probability until recent years, when the use of deep learning and artificial neural networks (ANN) achieved state-of-the-art results in many NLP tasks [15]. Such topics included the extraction of useful information [15], machine translation [16], summarization of texts [17], question answering [18], classification of documents, and speech recognition [19].
Recently, many industries started to implement NLP in their industrial and business processes. Applications of NLP in the industry include virtual assistants, which are now powered by NLP and AI [20] and are becoming an essential part of customer services. NLP is also used to analyze user’s feedback and comments in many fields such as the entertainment and e-commerce industries (Netflix and Amazon, for example). Thanks to the vast information exchanged on social media, companies have started to rely on NLP to analyze social media content to identify business trends [21].
2.2. Overview of Deep Learning Methods for NLP
This section presents a brief overview of deep learning methods for NLP. This list of methods is not exhaustive. It focuses mainly on the methods and concepts that are related to this work.
2.2.1. Deep Learning
Deep learning is a sub-field of machine learning and a set of methods based on representation learning which consist of representing the learning task as an embedded hierarchy of concepts to facilitate the extraction of useful patterns from raw data [10,22]. This hierarchy is framed as neural networks of several layers; each layer contains several neurons, and each neuron performs a simple but nonlinear transformation. The composition of these simple transformations allows the learning of complex representations and solving complex tasks. There are different types of neural network layers. Their use depends on the nature of the task (classification, prediction, etc.) and the nature of the input data (text, images, sequences, etc.). A brief review of the deep learning architectures used in this work is presented below.
2.2.2. Word Embedding
Text representation is a fundamental problem in text mining and NLP. It aims at representing the unstructured text data in a numerical form to make them computable [23]. There are multiple techniques for text representation. Word embedding is one of these techniques. It maps words or sentences into dense vectors of real numbers, where similar words have similar vectors representation. Word embedding techniques are very effective to model datasets with a large corpus of vocabulary [24]. Word embedding is also used to improve the performance of several deep learning architectures [25] and to achieve state-of-the-art results in several NLP applications [24,26].
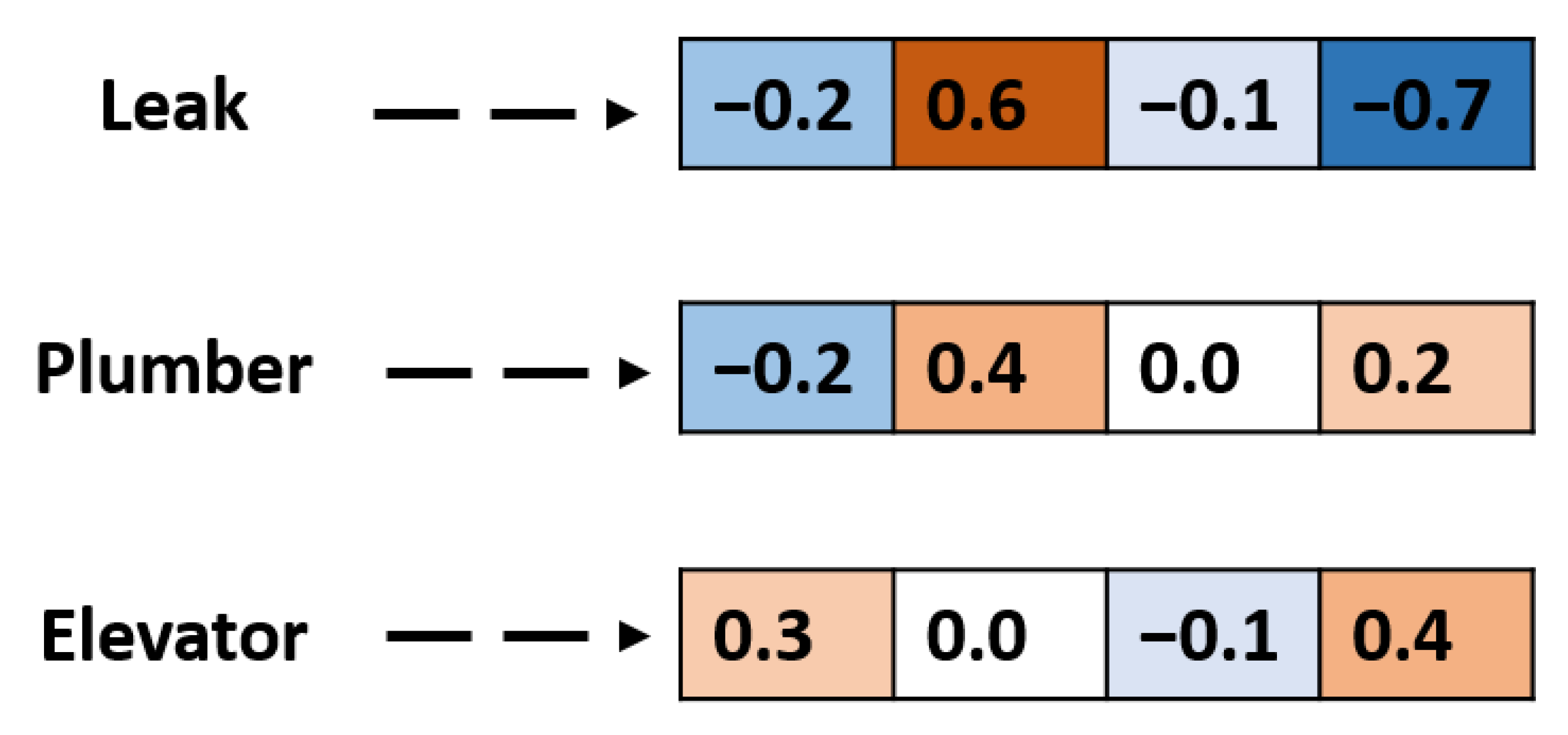
Figure 1 represents an illustration of word embedding method. Each word is represented as a four-dimensional vector; as an example, words like leak and plumber have a similar representation. In a real-life application, the vector length is much bigger; a higher dimensional embedding can capture fine relationships between words.
2.2.3. Convolutional Neural Networks (CNNs)
Convolutional neural networks (CNN, or ConvNets) [27] is a class of Deep Learning Networks, designed to process data that had a form of grid topology. For example, an image has the form of a 2D grid of pixels [10]. The name of Convolutional networks was attributed because of the mathematical operation called convolution instead of matrix multiplication [22]. ConvNets are, in general, composed of multiple layers; the first layers detect primary and straightforward features, then high-level features are obtained by composing lower-level features in the last layers [10]. ConvNets have multiple applications in image recognition, segmentation and classification [28,29,30,31]. They are powering multiple real-life applications from medical applications [32] to self-driving cars [33].
Recently ConvNets are gaining ground in NLP applications [34], including text classification applications in which ConvNets have shown excellent results classifying text sentences even with a minimum of fine tuning and a limited number of layers [35]. That is due to their capabilities of capturing local correlations and extracting features at different positions of a sentence [36].
2.2.4. Recurrent Neural Networks (RNNs)
Recurrent neural networks (RNNs) [37] are another popular class of deep learning network. RNNs are designed to process sequential data that have the form of a sequence [22]. Time series, text, and speech are examples of sequential data. RNNs are capable of capturing long-term dependencies in a sequence thanks to their hidden units ‘state value’ that implicitly contains information about the past of the sequence [10]. Many variants of RNNs were developed to improve performance, such as long short-term memory (LSTM) [38] and gated recurrent unit (GRU) [39]. The latter has achieved remarkable results in multiple NLP tasks such as machine translation [40] and next-word prediction in a sentence [41].
The combination of ConvNets and RNNs layers have shown great results in multiple text classification tasks. There are multiple examples of their use in the literature: an example of combining Bi-directional LSTM (a variant of RNNs) with ConvNets [42] was used on six text classification tasks, including sentiment analysis, question classification, and newsgroup classification. The model achieved a remarkable performance of four out of six tasks compared to state-of-the-art models. C-LSTM Neural Network is another model which combines CNN with LSTM for text classification [36]. C-LSTM outperformed both CNN and LSTM separated models on sentiment classification and question classification tasks.
3. Research Objective
This paper investigates a use case of NLP in FM. An NLP model to automate the process of maintenance tickets management is proposed. This model is based on a machine learning classifier, which classifies the work request sent by the user to the FM team according to the nature of the problem (e.g., “Lighting”, “plumbing”, “Electrical” etc.).
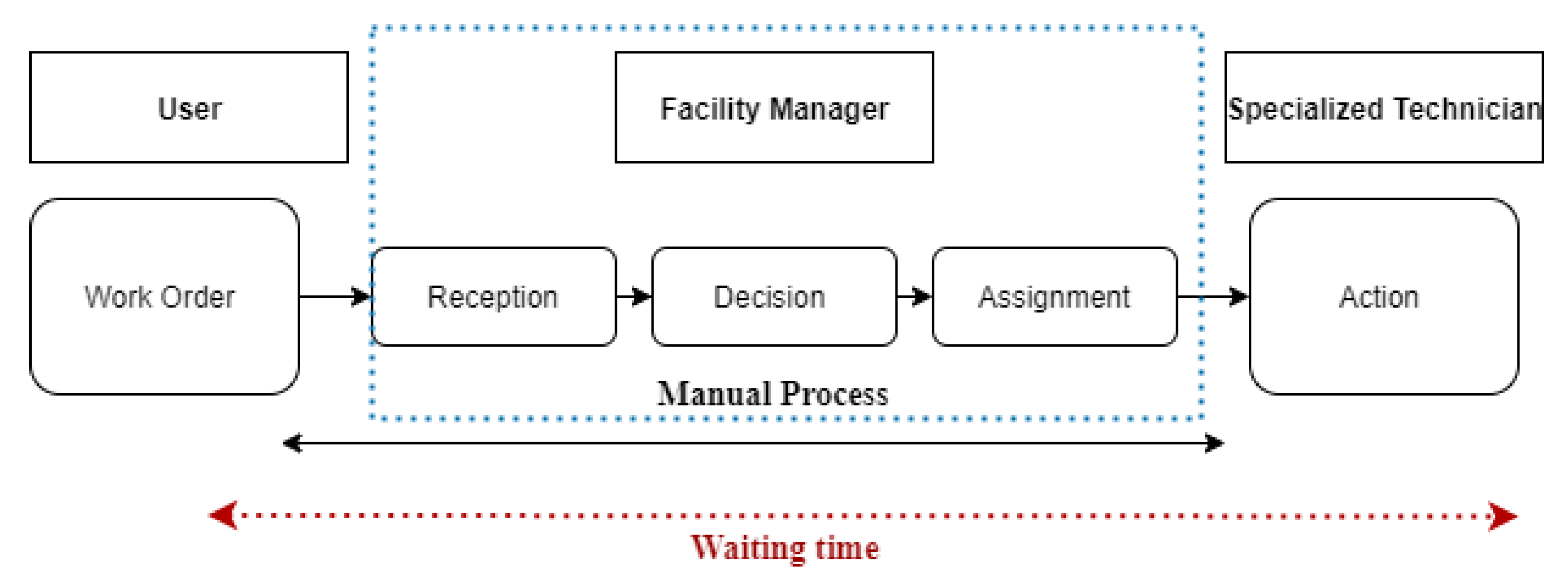
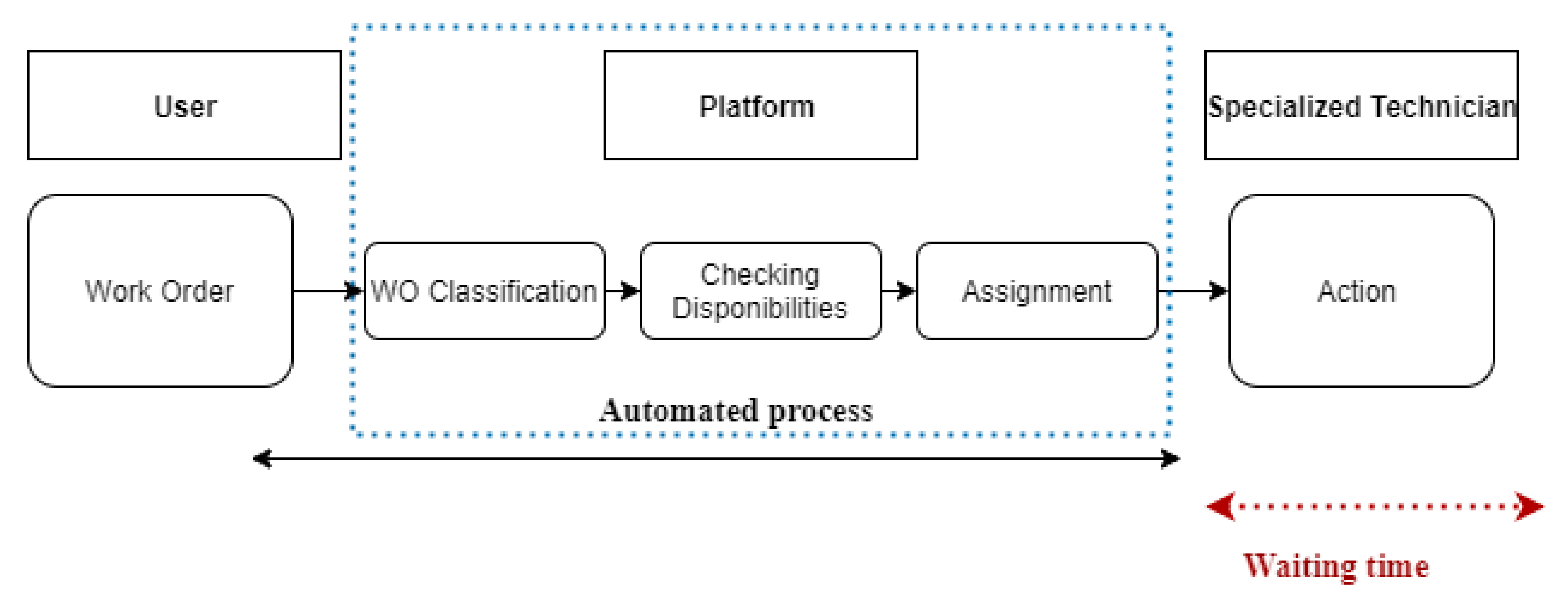
The classic process is based on human management, as illustrated in (Figure 2). Every day, the facility manager receives a significant number of users’ requests through a web application or email. Then the manager sorts the request and assigns it to the qualified technician. This process is time consuming and can cause significant delays when the number of daily requests is high. In this study, a machine learning classifier is developed to automate the maintenance work orders management (Figure 3). The new process automatically receives and classifies work orders, then assigns them to the qualified technician. This process reduces the waiting time and assists the facility management team.
This study focuses on building a text classifier for work orders using deep learning techniques. The dataset used to build and test the classifier was extracted from a maintenance records dataset in a Health care facility in France. The dataset characteristics and the model architecture will be discussed Section 4. Following this, the results of the algorithm are presented in Section 5. Finally, Section 6 concludes the study.
4. Methodology and Data Collection
4.1. Methodology
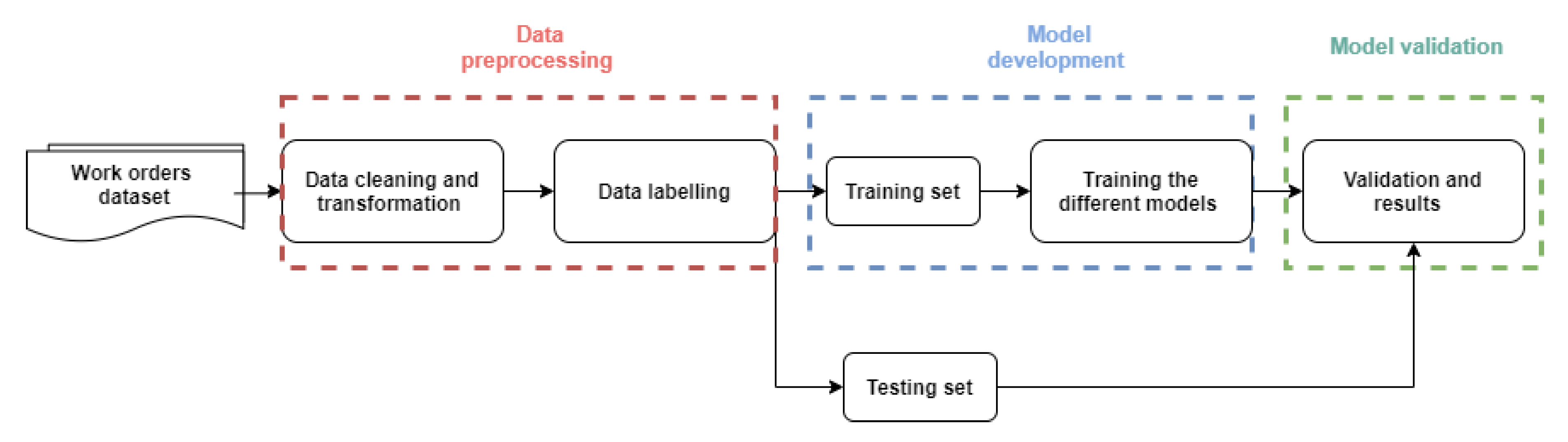
A classic machine learning approach was used to build the classifier model (Figure 4). It consists of three main steps: data processing, model development and model validation.
4.2. Data Characteristics
The dataset used in this study was extracted from the maintenance records of a healthcare facility in France. The dataset contains 10 years of records from June 2009 to July 2019. The healthcare facility is composed of two principal buildings in a total area of 35,000 m2; they contain a total number of 364 rooms as shown in (Table 1). The dataset was retrieved from the CMMS used in the facility; it includes all different work orders requested by the users via a web application related to the CMMS.
The dataset is structured in two columns, “work order” and “class”:
- “Work order”—the request entered by the user via the web application is in text format. The text can contain any word, number, or character;
- “Class”—the label assigned by the user or the FM technician. It describes the nature of the problem, such as “Sanitary and Plumbing”, “HVAC”, “Doors and access” etc.
This dataset contains 29,901 records that were divided into a training set and a test set with a ratio of 80% for training and 20% for testing.
4.3. Data Processing
The purpose of this step is to transform the raw data into a structured dataset ready for the training process. This step is comprised of two main parts:
Data cleaning and transformation—this step consists of firstly cleaning the data entries by removing irrelevant entries, Nan values and unrecognized characters. Then, some transformation and filters are applied to the sentences—removing accents, stop words, punctuation, numbers and lowercase conversion.
Data labelling—although the dataset had been already labelled, most of these labels were inadequate. Indeed, the dataset had initially 107 different (unique) labels. Every label is supposed to describe a unique class of problems, but most of them were inadequate, redundant and written in different representations. For example:
- Label A—“Clim-Ventil-Chauffage ”;
- Label B—“Clim. Ventil. Chauffage—problème autre”.
Both representations describe the same problem of “Chauffage, Ventilation et Climatisation” which means in English “Heating, ventilation, and air conditioning”. This kind of problem is common when it comes to text data, which is primary, human generated and recorded manually by the technicians responsible for maintenance. In general, multiple technicians are doing the task, which makes the data inconsistent, error filled, and replete with domain-specific jargon [43].
The labels in the dataset were manually transformed with the help of a facility management expert. Indeed a list of 10 labels was defined instead of the initial 107 labels. Table 2 shows the final labels (classes) and their frequency in the dataset. The number of requests in each class are well balanced since there is no dominant class.
In this work, it was assumed that each work order corresponds to only one problem (one class), which means that the user sends a request for each maintenance problem separately.
4.4. Model Devlopement
4.4.1. Transfer Learning for Text Representation
In order to overcome the limited corpus of vocabulary in our dataset, a pre-trained word embedding was used. It is based on the FastText model [44] and trained on a large corpus of French vocabulary from Wikipedia and Common Crawl [45]. This technique of using pre-trained models is known as Transfer Learning. Transfer Learning aims to store acquired knowledge while solving a specific problem. It is then transferred to different but related problems [46]. Transfer learning is widely used in multiple applications in NLP and Computer Vision tasks. It helps benefit from similar problems and to overcome the limitation of a small dataset.
4.4.2. Outline of the Different Deep Learning Models Proposed
In this study, four different models were tested, and that combine different deep learning architectures. The models are illustrated and explained below:
CNN Model: In this model, a CNN (Convolutional Neural Network) approach was used to classify the work orders. It is composed of an embedding layer, followed by two CNN layers. Following this, a dropout regularization was added to avoid overfitting (Figure 5) [47].
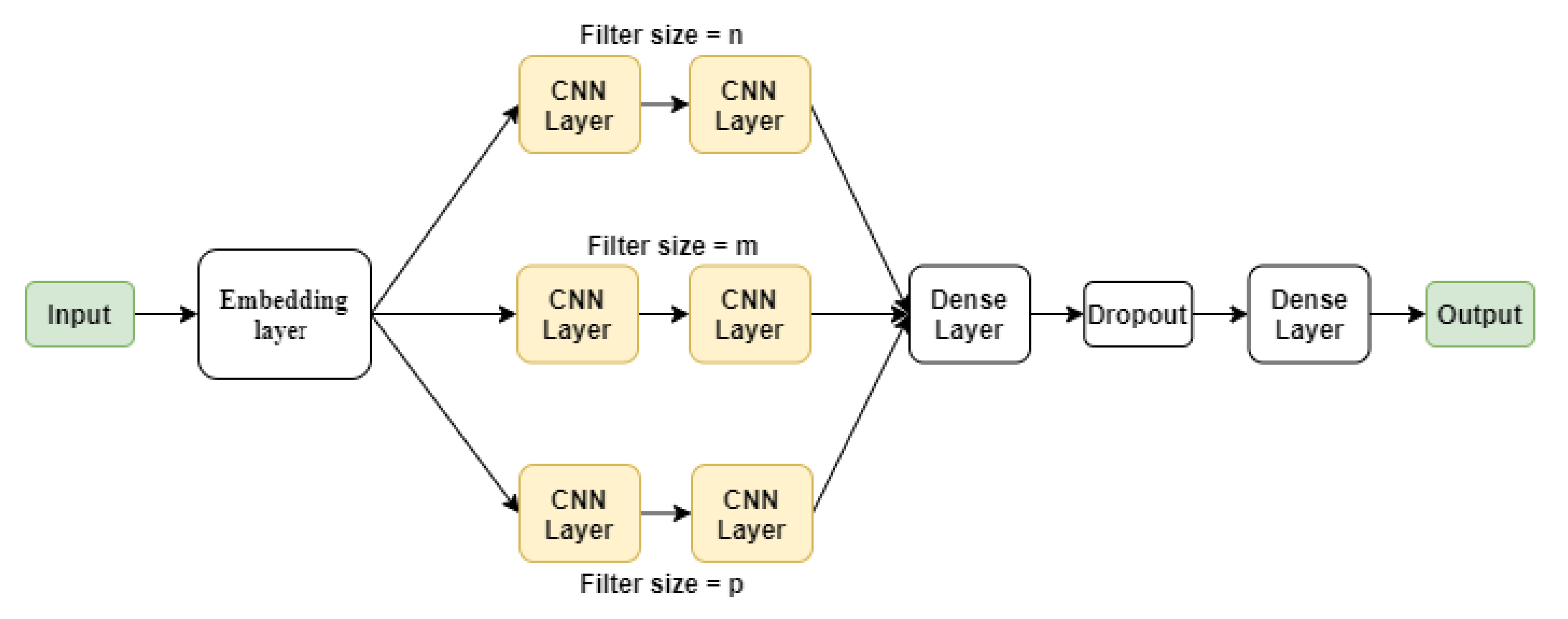
CNN Model with multiple filters: This model is similar to the original CNN model, the only difference is that the CNN layers were duplicated in a branch form inside the model. In every branch, a different filter size was used. This approach allows the model to train with different filter sizes simultaneously (Figure 6).
LSTM Model: Unlike the first models, an LSTM approach was used in this model. LSTM layers replaced the CNN layers in order to evaluate the impact of the LSTM approaches in text classification tasks. The rest of the layers remained unchanged (Figure 7).
CNN + LSTM Model: This model combines the first and the third models above. CNN and LSTM layers were stacked in a unified architecture. Two LSTM layers were added to two CNN layers followed by a dropout layer (Figure 8).
5. Results and Discussion
5.1. Model Validation and Results
The metric used to evaluate the performance of the four models is Accuracy (Equation (1)) which is defined as the ratio of true predicted samples on the total number of samples [48,49].
As cited in [48,50], accuracy is the most used evaluation metric for either binary classification or multi-class classification. Although accuracy has some limitations, it does not distinguish between the numbers of correct labels of different classes, which can lead to incorrect conclusions as in the case of imbalanced data. In this paper, the dataset is not imbalanced, thus the accuracy was used as an evaluation metric to compare the performance of the different models. Although, the following Confusion Matrix is used for a detailed evaluation of the prediction in different classes (Section 5.2).
The table below (Table 3) shows the accuracy results of the different models. The CNN model with multiple filters has achieved the best accuracy (78%). The LSTM layers used in both LSTM and CNN + LSTM did not improve the performance of the classifier. It can be explained that the classification in this problem depends more on the words used than their sequence in the sentence. This makes the LSTM layers less useful here, since they are designed to capture dependencies in sequences.
5.2. Discussion
In the rest of the discussion, the results of the best model (CNN with multiple filters) will be analyzed. A confusion matrix (Figure 9) was used to summarize the results, it is a powerful tool for reporting results in multi-class classification. It consists of a symmetric matrix where rows refer to the ground truth and columns refer to the predicted class labels of the dataset (or vice versa). The main diagonal of the matrix shows the percentage of well-predicted values (accuracy) in each class. The results show that the accuracy strongly variates from a class to another. In some classes, the model had succeeded to correctly classify the instances as in “Lighting” and “Plumbing and Sanitary” with an accuracy above 90%. In other classes, the performance was lower as in “ICT” and “Electrical Equipment” classes where it was below 60%.
Low accuracy in some classes might be explained by a mislabeling problem. For example, several work orders belonging to “Security” class are classified as “Doors, Elevators & Access”, which is due to the similarity between the two classes. Indeed, many work orders that belong to security contain words referring to “doors” or “access”. The same applied to “Electrical Equipment” and “Lighting” which can, at times, be very similar. Another reason is the limitation of the dataset. The sample size is less than 30,000, which may not be enough for this classification problem with multiple classes. For instance, classes like “Sanitary and Plumbing” are easier for the algorithm to classify; they are more specific and, in general, contain the same words such: Leak, water, tap, etc. In the opposite, some classes can be tricky for the algorithm such as “Construction Work” and “Security” because they are more generic and contain different contexts. Thus, the algorithm would need more training data to learn how to classify them. The average accuracy in the test set as stated above is 78%, a satisfying result given the size of the dataset.
Deploying this classification model in real buildings should pass by a trial phase when feedback data are collected to improve the accuracy of the model. Meanwhile, in this trial phase, manual interventions by the FM team are needed to address the misclassified samples. However, the number of these manual interventions should be acceptable given the overall actual accuracy.
6. Conclusions
This study investigated the potential of NLP for Facility Management. An innovative approach was proposed for work orders management that can allow the automation of the maintenance process and reduce waiting time. This approach is based on NLP to classify maintenance work orders according to their specific nature and then have it assigned to the qualified technician. This NLP method is executed in three steps:
- Step 1 consists of pre-processing the dataset by removing Nan values and irrelevant characters to prepare the dataset for the ML process.
- Step 2 consists of transforming the text into computable numerical vectors using the word-embedding method.
- Step 3 consists of training the classifier algorithm using an ML framework. For this, a deep learning architecture combining CNN and LSTM layers was used.
Main results shows that the model classify the work orders into the 10 different classes with an average accuracy of 78%.
As demonstrated in the study, NLP could be used to extract insights from unstructured text data. The results of this research align with findings in [11] demonstrating that ML/NLP techniques can make the process of retrieving and reusing information faster and more accurate. NLP was used in this paper to enable the automation of assigning technicians and thereby reduce the maintenance operations delays. However, the accuracy of the model is still below 80%, which means that deployment of the model in real buildings would need to pass by a trial phase when manual interventions are needed to correct the misclassified corrections.
Some limitations of this study relate to the low accuracy in some specific classes such as “Security” and “Construction Work”, which is due to the limits in the training dataset. The training dataset in this study is relatively small and less diverse compared to those used for developing NLP solutions, such as Amazon Review dataset [51].
To address these limitations, future work will focus on collecting more data from different buildings to construct a larger and more diverse dataset that can allow us to train NLP solutions for FM. In particular, using a larger dataset to train the models will allow the overall accuracy of the classification to be improved, and address the problem of low accuracy in some specific classes.
Author Contributions
Y.B. designed the framework of the model and carried out the experiment in this case study, which is a part of his PhD thesis work. Z.L. is the thesis director, he supervised the thesis work including the work in this paper he also revised the paper on several occasions. P.Y. is the co-director of the PhD thesis. He supervised the model development and the different data processing in this paper. L.D. was responsible for the data acquisition and managing the relationship with Bouygues Construction Company. She also revised the paper on several occasions. B.B. is a FM expert with over a decade of work experiences in the FM field. He contributed to this work by defining the problem and labelling the dataset. All authors have read and agreed to the published version of the manuscript.
Funding
This research was carried out as part of the industrial research chair Construction 4.0, funded by Centrale Lille, Bouygues Construction, The Métropole Européenne de Lille (MEL) and the European Regional Development Fund (ERDF).
Acknowledgments
The authors are grateful to Bouygues Energies Et Services Facility Maintenance’s Team for facilitating and cooperating in this research. They also thank the editors and referees for their helpful comments on the draft.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rui, L.; Issa, R.R.A. Survey: Common Knowledge in BIM for Facility Maintenance. J. Perform. Constr. Facil. 2016, 30, 04015033. [Google Scholar] [CrossRef]
- Zhan, J.; Ge, X.J.; Huang, S.; Zhao, L.; Wong, J.K.W.; He, S.X.J. Improvement of the inspection-repair process with building information modelling and image classification. Facilities 2019, 37, 395–414. [Google Scholar] [CrossRef] [Green Version]
- Yousefli, Z.; Nasiri, F.; Moselhi, O. Healthcare facilities maintenance management: A literature review. J. Facil. Manag. 2016, 15, 352–375. [Google Scholar] [CrossRef]
- Samouhos, S. Building condition Monitoring. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2010. [Google Scholar]
- Marmo, R.; Nicolella, M.; Polverino, F.; Tibaut, A. A Methodology for a Performance Information Model to Support Facility Management. Sustainability 2019, 11, 7007. [Google Scholar] [CrossRef] [Green Version]
- Matarneh, S.T.; Danso-Amoako, M.; Al-Bizri, S.; Gaterell, M.; Matarneh, R.T. BIM for FM: Developing information requirements to support facilities management systems. Facilities 2019, 38, 378–394. [Google Scholar] [CrossRef]
- Patacas, J.; Dawood, N.; Vukovic, V.; Kassem, M. BIM for facilities management: Evaluating BIM standards in asset register creation and service life. J. Inf. Technol. Constr. 2015, 20, 313–331. [Google Scholar]
- Kwok, J.; Wong, W.; Ge, J.; Xiangjian, S. Automation in Construction Digitisation in facilities management: A literature review and future research directions. Autom. Constr. 2018, 92, 312–326. [Google Scholar] [CrossRef]
- Koch, C.; Hansen, G.K.; Jacobsen, K. Missed opportunities: Two case studies of digitalization of FM in hospitals. Facilities 2019, 37, 381–394. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Fang, Z.; Pitt, M.; Hanna, S. Machine Learning in Facilities & Asset Management University College London. In Proceedings of the the 25th annual Pacific Rim Real Estate Society (PRRES) Conference, Melbourne, Australia, 14–16 January 2019. [Google Scholar]
- Yunjeong, M.; Dong, Z.; Matt, S.; Azizan, A. Construction Work Plan Prediction for Facility Management Using Text Mining. Comput. Civ. Eng. 2017, 2017, 92–100. [Google Scholar] [CrossRef]
- Stenström, C.; Aljumaili, M.; Parida, A. Natural Language Processing of Maintenance Records Data. Int. J. COMADEM 2015, 18, 33–37. [Google Scholar]
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning in Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garg, A.; Agarwal, M. Machine Translation: A Literature Review. arXiv 2018, arXiv:1901.01122. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for sentence summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Feng, M.; Xiang, B.; Glass, M.R.; Wang, L.; Zhou, B. Applying deep learning to answer selection: A study and an open task. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Jan, C.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the 11th Annual Conference of the International Speech Communication Association, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Quarteroni, S. Natural Language Processing for Industry. Informatik-Spektrum 2018, 41, 105–112. [Google Scholar] [CrossRef]
- Ittoo, A.; Nguyen, L.M.; Van Den Bosch, A. Text analytics in industry: Challenges, desiderata and trends. Comput. Ind. 2016, 78, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Yan, J. Text Representation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 3069–3072. ISBN 978-0-387-39940-9. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations (ICLR), Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1907.09207. [Google Scholar]
- Rezaeinia, S.M.; Ghodsi, A.; Rahmani, R. Improving the Accuracy of Pre-trained Word Embeddings for Sentiment Analysis. arXiv 2017, arXiv:1711.08609. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Nguyen, P.; Tran, T.; Wickramasinghe, N.; Venkatesh, S. Deepr: A Convolutional Net for Medical Records. IEEE J. Biomed. Health Inform. 2017. [Google Scholar] [CrossRef] [PubMed]
- Hadsell, R.; Sermanet, P.; Ben, J.; Erkan, A.; Scoffier, M.; Kavukcuoglu, K.; Muller, U.; LeCun, Y. Learning long-range vision for autonomous off-road driving. J. Field Robot. 2009, 26, 120–144. [Google Scholar] [CrossRef] [Green Version]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F.C.M. A C-LSTM Neural Network for Text Classification. arXiv 2015, arXiv:1511.08630. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Gasparin, A.; Lukovic, S.; Alippi, C. Deep Learning for Time Series Forecasting: The Electric Load Case. arXiv 2019, arXiv:1907.09207. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations ofwords and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; Volume 2, pp. 3485–3495. [Google Scholar]
- Sexton, T.; Hodkiewicz, M.; Brundage, M.P.; Smoker, T. Benchmarking for keyword extraction methodologies in maintenance work orders. In Proceedings of the Annual Conference of the Prognostics and Health Management Society (PHM), Philadelphia, PA, USA, 24–27 September 2018; pp. 1–10. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning word vectors for 157 languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), Miyazaki, Japan, 7–12 May 2018; pp. 3483–3487. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. arXiv 2019, arXiv:1911.02685. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. AI 2006: Advances in Artificial Intelligence. In Proceedings of the 19th Australian Joint Conference on Artificial Intelligence, Hobart, Australia, 4–8 December 2006; pp. 1015–1021. [Google Scholar]
- Rakesh Kumar, S.; Gayathri, N.; Muthuramalingam, S.; Balamurugan, B.; Ramesh, C.; Nallakaruppan, M.K. Medical Big Data Mining and Processing in e-Healthcare. In Lecture Notes in Computer Science; Balas, V.E., Son, L.H., Jha, S., Khari, M., Kumar, R.B.T., Eds.; Academic Press: Cambridge, MA, USA, 2019; Chapter 13; pp. 323–339. ISBN 978-0-12-817356-5. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Haque, T.U.; Saber, N.N.; Shah, F.M. Sentiment analysis on large scale Amazon product reviews. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), Bangkok, Thailand, 11–12 May 2018. [Google Scholar]
Figure 1.
Illustration of word embedding.

Figure 2.
Classic process for work orders management.

Figure 3.
Proposed process for work orders management.

Figure 4.
Outline of the three main steps of the approach.

Figure 5.
Outline of the CNN model.

Figure 6.
Outline of the CNN model with multiple filters.

Figure 7.
Outline of the LSTM model.

Figure 8.
Outline of the CNN + LSTM model.

Figure 9.
The confusion matrix: the result of the classification on the test set.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
General Information about the healthcare facility.
| Type of the Facility | Healthcare Facility |
|---|---|
| Gross area (m2) | 35,000 |
| Number of buildings | 2 |
| Number of floors | 4 |
| Number of Rooms | 465 |
Table 2.
Labels after pre-processing and their frequency in the dataset.
| Labels (French) | Labels (English) | Frequency |
|---|---|---|
| Sanitaire et Plomberie | Sanitary and Plumbing | 7729 |
| Electrique et Courant fort | Electrical Equipment | 3518 |
| CVC | HVAC | 3483 |
| Eclairage | Lighting | 3369 |
| Second œuvre | Construction Work | 2799 |
| Portes, Ascenseurs et Accès | Doors, Elevators and Access | 2563 |
| Autres | Others | 2531 |
| Stores et fenêtres | Blinds and windows | 2061 |
| Courant faible et SI | Information and Communications Technology | 1130 |
| Sécurité | Security | 718 |
Table 3.
Classification accuracy results of the different models.
| Model | Accuracy |
|---|---|
| CNN | 0.72 |
| CNN with multiple filters | 0.78 |
| LSTM | 0.66 |
| CNN + LSTM | 0.68 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bouabdallaoui, Y.; Lafhaj, Z.; Yim, P.; Ducoulombier, L.; Bennadji, B. Natural Language Processing Model for Managing Maintenance Requests in Buildings. Buildings 2020, 10, 160. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings10090160
AMA Style
Bouabdallaoui Y, Lafhaj Z, Yim P, Ducoulombier L, Bennadji B. Natural Language Processing Model for Managing Maintenance Requests in Buildings. Buildings. 2020; 10(9):160. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings10090160
Chicago/Turabian StyleBouabdallaoui, Yassine, Zoubeir Lafhaj, Pascal Yim, Laure Ducoulombier, and Belkacem Bennadji. 2020. "Natural Language Processing Model for Managing Maintenance Requests in Buildings" Buildings 10, no. 9: 160. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings10090160
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.