
A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques

Department of Civil and Environmental Engineering, The University of Auckland, Private Bag, Auckland 92019, New Zealand
*
Author to whom correspondence should be addressed.
Buildings 2024, 14(3), 752; https://0-doi-org.brum.beds.ac.uk/10.3390/buildings14030752
Submission received: 3 November 2023
/
Revised: 28 January 2024
/
Accepted: 4 February 2024
/
Published: 11 March 2024
(This article belongs to the Section Building Energy, Physics, Environment, and Systems)
Abstract
:Energy efficiency is currently a hot topic in engineering due to the monetary and environmental benefits it brings. One aspect of energy efficiency in particular, the prediction of thermal loads (specifically heating and cooling), plays a significant role in reducing the costs associated with energy use and in minimising the risks associated with climate change. Recently, data-driven approaches, such as artificial intelligence (AI) and machine learning (ML) techniques, have provided cost-effective and high-quality solutions for solving energy efficiency problems. This research investigates various ML methods for predicting energy efficiency in buildings, with a particular emphasis on heating and cooling loads. The review includes many ML techniques, including ensemble learning, support vector machines (SVM), artificial neural networks (ANN), statistical models, and probabilistic models. Existing studies are analysed and compared in terms of new criteria, including the datasets used, the associated platforms, and, more importantly, the interpretability of the models generated. The results show that, despite the problem under investigation being studied using a range of ML techniques, few have focused on developing interpretable classifiers that can be exploited by stakeholders to support the design of energy-efficient residential buildings for climate impact minimisation. Further research in this area is required.
1. Introduction
The energy performance of buildings (EPB) is fundamental to architectural and civil engineering research since it directly impacts the environment and reduces energy waste. Energy efficiency has been defined in terms of building design and construction as “less energy utilisation of buildings including commercial, manufacturing, and residential for cooling, heating, and running electricity to derive the same outcome [1,2]. Recent statistics show that the energy consumption of buildings has increased steadily over the last few decades, suggesting benefits to the development of smart optimisation for managing heating, ventilation, and air conditioning (HVAC). To respond to this greater level of energy demand, supplying energy efficient buildings is crucial for reducing the costs associated with energy use, and to minimise the risks associated with climate change through reduced carbon dioxide emissions.
Energy efficiency can be achieved by constructing or advancing buildings that optimise energy use through building energy management systems (BEMS) [3]. A BEMS is a central computer-aided system that manages the movement of cooled and heated air through buildings to help stakeholders, including homeowners, tenants, and businesses, to substantially improve energy use through HVAC, lighting, and room equipment that require power to operate [4]. A BEMS focuses on multiple factors including the household consumption rate, energy load forecasting, load generation rate and forecasting energy bill prices [3]. These factors can be estimated from historical data related to BEMS parameters using data-driven techniques.
This research focuses specifically on energy load forecasting using data-driven techniques to aid in the optimisation of the energy efficiency of buildings. Forecasting the energy load can, (a) reduce energy consumption to enhance performance and cut down on energy waste resulting in lower utility bills and long-term cost savings, (b) enhance comfort by providing consistent and precise temperature control and reducing excess moisture, and preserving a comfortable indoor environment, and (c) contribute to a greener and more sustainable future by reducing greenhouse gas emissions [5,6].
Data-driven techniques can provide cost-effective solutions to optimise energy usage in residential buildings by predicting the heating and cooling loads [7,8]. The heating load is the amount of heat energy that needs to be supplied to a building to keep the indoor temperature at a comfortable level, indicating how much heat the building loses because of the outdoor temperature, the quality of the insulation, the extent of air leaks, and the way the building is made [9]. The cooling load is the quantity of heat energy that must be removed from a building to maintain a comfortable interior temperature during warm weather [10], representing the heat gain a building experiences as a result of the outdoor climate, solar radiation, air infiltration, internal heat sources (appliances, lighting, occupants), and building design.
The ability to estimate heating and cooling loads is essential for developing buildings that are energy efficient as it allows building designers and engineers to identify areas in which energy-saving solutions can be applied, providing accurate estimations of the thermal energy requirements of a building [6]. This can involve increasing the amount of insulation, reducing the amount of air leakage, optimising the orientation of the structure (including shading devices), and selecting HVAC equipment that is efficient with respect to energy consumption. Moreover, the strain on the heating and cooling systems can be decreased to reduce energy consumption, which in turn leads to lower energy bills and a lower impact on the environment.
As stated earlier, one promising and cost-effective way of predicting heating and cooling loads is through the use of data-driven techniques such as artificial intelligence (AI) and machine learning (ML). These techniques exploit historical datasets gathered in relation to a building’s efficiency parameters to generate innovative solutions that are useful, accurate, and efficient for stakeholders [11]. In BEMS research, there is much interest in the use of data-driven techniques to optimise BEMS system factors. For instance, one study used regression analysis on data collected from 20 buildings and showed that EMS indeed saves energy—an average of 12.70% in this case [4]. Another study used statistical methods on residential buildings to measure the level of correlation between cooling and heating loads, with other independent variables related to building energy [8]. Two studies [6,7] applied ML techniques to identify the best features related to residential home energy efficiency. These studies (and others) using data-driven techniques were promising with respect to producing reliable models for predicting energy efficiency in residential buildings. However, few of these studies have focused on interpretable classification algorithms, which not only predict heating and cooling loads, but also provide detailed knowledge in a simple format for the users on how these models perform in term of prediction and what features contribute significantly to the prediction. Also, these studies have rarely considered the impact of the algorithms’ hyperparameters on the performance of the predictive models [12].
This paper reviews recent data-driven studies used to predict energy loads. The scope is limited to residential buildings and to experimental studies based on ML techniques, including statistical, induction, probabilistic, artificial neural networks (ANN), support vector machine (SVM), and meta-learners such as ensemble learning and others. The current review focuses on:
- (a)
- Experimental data-based publications (simulated—synthetic/real);
- (b)
- Publications that use a machine learning approach or more;
- (c)
- Publications with a scope limited to heating and cooling load predictions.
We review recent research studies within the defined scope and conduct a critical analysis and discussion according to new criteria, including the model’s interpretability, the data used, the platforms used, and the hyperparameter settings. More importantly, a theoretical comparison between these ML techniques is conducted within the context of building energy efficiency. This research presents a comparison of ML algorithms in terms of new criteria, including the data and platform used, the impact of the hyperparameters on model performance, and, importantly, the models’ interpretability for stakeholders. It is argued that these criteria must be considered before applying ML techniques to the problem of energy load prediction, considering the above factors can contribute to energy savings and cost reductions. However, identifying the factor(s) which have the most significant impact on energy efficiency, and how these factors correlate with heating and cooling loads, requires further investigation.
2. Background on Energy Efficiency in Buildings
The engineering construction sector refers to the industry responsible for designing, planning, constructing, and maintaining buildings, infrastructure, and other physical structures [13]. It includes various sub-disciplines, such as civil engineering, mechanical engineering, electrical engineering, and environmental engineering. The construction sector is a significant contributor to energy waste and consumption, accounting for approximately 40% of the global energy consumption and 36% of global CO2 emissions, the consumption of which is mainly attributed to the heating, cooling, lighting, and powering of the appliances used in buildings [13].
The impact of energy waste in the construction sector extends beyond environmental consequences. Energy inefficiencies also have a significant impact on the cost of construction and the maintenance of buildings [13]. Energy waste increases operational costs, reduces the lifespan of buildings, and decreases the value of properties. Moreover, the construction sector’s environmental impact extends to the depletion of natural resources and the generation of waste, as well as emissions of air and water pollutants [14] with adverse effects on human health and natural ecosystems.
To address these challenges, the construction industry has adopted sustainable practices and the use of energy-efficient materials and technologies, including green building certification practices such as LEED and BREEAM, which promote sustainable building design and construction [14,15]. Engineers also use various conventional methods to manage energy waste in buildings and infrastructure. Some of these methods according to a number of different organisations globally [13,16,17,18,19] are summarised briefly below:
- Designing buildings to maximise natural lighting, reduce energy consumption for heating and cooling, and using energy-efficient building materials;
- Optimising HVAC systems to reduce energy consumption by using sensors to control temperature, optimising system controls, and using energy-efficient components;
- Optimising lighting systems by using energy-efficient lighting technology, such as LED lights, and installing sensors to automatically turn lights off when not in use;
- Integrating renewable energy systems, such as solar panels or wind turbines, to reduce reliance on fossil fuels;
- Using computerised energy management systems to monitor energy consumption and optimise energy usage in buildings and infrastructure;
- Conducting life cycle analyses of buildings and infrastructure to identify areas where energy waste could be reduced throughout the building’s lifespan.
These methods are widely used in the construction industry to manage energy waste and reduce the environmental impact of buildings and infrastructure.
A variety of different factors can contribute to the energy efficiency of buildings, with the following factors considered to be vital [20,21,22]:
- Insulation: Proper insulation can reduce heat loss and gain, and therefore the amount of energy needed to maintain a comfortable indoor temperature. Adding insulation to an under-insulated attic can result in savings of up to 20% on heating and cooling costs [23]. Additionally, insulation in walls, floors, and ceilings can reduce energy consumption by up to 30%;
- Energy-efficient windows: Designed to reduce the amount of heat transfer between the interior and exterior of a building. Energy-efficient windows can reduce energy consumption by 12–33% in heating-dominated climates, and 18–38% in cooling-dominated climates [24];
- Efficient Lighting: The use of LED lights, for example, can reduce energy consumption by up to 75% compared to traditional incandescent bulbs [25]. Energy Star certified appliances, which meet energy efficiency guidelines set by the U.S. Environmental Protection Agency, can save up to 50% more energy than standard models;
- Building Design: A building’s design can also contribute to energy efficiency. Orienting a building to take advantage of natural sunlight and ventilation can reduce the need for lighting and air conditioning. A well-designed ventilation system can also help regulate indoor temperature and reduce the need for heating and cooling [26].
One of the key benefits of smart home systems is their ability to provide real-time data and insights based on embedded techniques and using stored data about a home’s heating and cooling usage [27]. This information can be used to identify areas where energy consumption can be reduced, such as by adjusting temperature settings during periods of low usage or using sensors to detect when rooms are unoccupied. Smart HVAC systems can integrate with other smart home devices, such as smart thermostats, smart air purifiers, and smart humidifiers to create a more comprehensive and efficient home environment, with the HVAC system serving as the central hub for all temperature and air quality regulation. The functioning of a basic HVAC system in a building is described in [28].
There are several significant features in a home that contribute to the impact of heating and cooling loads including:
- Roof Area: Home heating and cooling loads depend on the roof area with the heat gain or loss being greater from a larger roof area and the difference in temperature between the indoors and the outdoors. Insulating and employing reflecting roofing materials reduce heat transmission [29];
- Glazing Area: A home’s total window, skylight, and glass door areas are called the glazing area and can contribute significantly to the heating or cooling of a room with the rate of heat transfer increasing with glazing area, affecting a home’s heating, and cooling demands. Energy-efficient windows with low-emissivity (low-E) coatings, insulated glass, and double-glazing reduce the rate heat transfer [30] ;
- Surface Area: The area of external walls and the roof affect the heating and cooling load, with the rate of heat transfer increasing with surface area, affecting home heating and cooling [9];
- Relative Compactness (Shape of Building): A compact building with a reduced surface area-to-volume ratio reduces the heating and cooling demands. Energy-efficient buildings have a reduced exposed surface area [31];
- Wall Area: Walls transmit heat in the case of a thermal gradient between the indoors and the outdoors. Depending on the weather, larger wall areas result in greater heat intake or loss. Insulation, thermal barriers, and energy-efficient building materials can help to minimise the rate of heat transfer through walls.
3. Machine Learning Techniques for Energy Efficiency Prediction
This section considers data-driven research studies that tackle the problem of heating or cooling prediction using simulated data. The section is organised based on the type of learning within ML techniques; specifically, several different ML approaches including meta-learning (ensemble learning), SVM, ANN, statistical, probability, and others are reviewed and critically analysed with reference to energy efficiency, including a discussion section to highlight new criteria such as data, platforms, and the interpretability of these techniques.
3.1. Ensemble Learning
One of the advancements that has occurred in data science regarding classical classification algorithms is that of ensemble learners such as random forest. Using an ensemble algorithm, multiple classification models are developed from the dataset rather than from a single classification model as is the case in traditional classification algorithms [32]. The primary motivation behind ensemble learner algorithms is to minimise any chance of errors (misclassifications of test data classes), and biased decisions encountered when using a single classification model, by employing multiple models to predict the test data’s class in a collective decision-making manner. This result can be achieved in many ways, such as in voting (the class that the majority of the models belong to), averaging (a decision based on all models considered equally), and, among others, weighted averaging (which also considers the importance of each model (weight/probability) in the calculation).
There are many ways to generate ensemble learners such as bagging, boosting, and stacking [33]. Most of these use training data subsets to develop models using a base classification algorithm (decision tree, KNN, etc.) and then evaluate using validation datasets or unseen subsets of the training data; these models can then be used for predicting new data (the test data). For example, the bagging ensemble learner algorithm often generates multiple models (weak classifiers) for subsets of the training dataset (called bags) and then combines these models into a single stronger model that is used for predicting the class label [34]. The bagging algorithm employs data sampling techniques such as bootstrapping (random sampling with replacement) during the training/developing of the model step.
With boosting ensemble learning algorithms, after the dataset has been split into subsets, a model is developed from Subset #1 which is then tested on the training dataset; all data observations that have been wrongly classified by the model are passed along with data Subset #2 to develop a second model, and the process is repeated until all data subsets are used. Next, the predictions of all of the models are aggregated to produce the final prediction [35]. Finally, in the Stacking ensemble learner approach, the training dataset is used to develop multiple models (using a base algorithm or different algorithms) [33]. The predictions made by the models are integrated to create a new dataset that, in turn, is used to learn a new “meta-model” to predict the class of test data.
Ensemble learner algorithms have been used for heating and cooling predictions in a number of studies [36,37,38,39]. To improve existing research studies’ predictive performance in terms of accuracy, and using a data-driven method, the issue of heating and cooling load prediction for creating energy-efficient residential homes has been studied [36]. The authors used ensemble learners which are classification algorithms in ML that use a collective strategy to predict response variables via multiple classification models. These models are generated by the ensemble learner when processing large datasets and using various algorithms such as random forest. For this purpose, the authors used a residential dataset [8]. Using these data instances, a random forest algorithm was used to generate classification models able to predict heating and cooling loads with a high degree of accuracy [32].
To improve HVAC efficacy, in addition to assisting engineers in reducing energy consumption in buildings, the problem of the prediction of the thermal loads (cooling and heating) of residential building using ensemble learners with a base algorithm consisting of a decision tree and another with least square boosting has been investigated [37]. Following this, the authors proposed an ensemble learner called an SFLA-optimised regression tree ensemble (SRTE), and then compared the classification models developed by the ensemble learners with those of other algorithms, such as Gaussian process regression and stepwise regression, in terms of different performance measures using [8]’s dataset. The experimental results showed that SRTE is competitive with respect to the considered ML algorithms as well as other recently reported relevant data science studies on the same dataset, as well as in terms of several performance measures, including the determination of coefficient and the mean squared error.
The problem of predicting the thermal loads has also been studied, specifically in 768 Chinese commercial buildings using ML algorithms such as deep learning and random forest [39]. Since the thermal load variables are numerical, the authors initially modelled the data as a regression problem. After generating commercial building data for the spring season based on parameters such as the wall area, relative density, surface area, roof area, height, insulation material area, house orientation, and insulation area distribution, the authors performed feature analysis using two techniques: Pearson correlation, and recursive feature elimination with the extra random tree algorithm to measure the generated models’ performance from each subset of features. At each iteration of the feature analysis, a feature was removed from the dataset to show the extent to which the generated model was improved in terms of accuracy when compared with the previous iteration. The features’ ranking after applying the extra random tree algorithm during the feature assessment phase were then presented [39]. Experimental results on the dataset showed that random forest, bagging, and extreme tree algorithms outperform traditional ML algorithms such as decision tree, KNN, and linear regression. The results showed that “surface area”, “wall area”, “roof area”, and “height” are the most significant features, followed by “glazing area”.
The problem of predicting the heating loads in residential, commercial, and school buildings using a data-driven approach—primarily ensemble learner, based on bagging by using the Fast Incremental Model Trees with Drift Detection (FIMT-DD) as the base model [38]. The author used various datasets to measure the heating load and compared their work with other ML algorithms by considering the mean absolute percentage error (MAPE) and the mean absolute error (MAE). After experimentation on the Waikato Environment for Knowledge Analysis (WEKA) and Massive Online Analysis (MOA) platforms and using the datasets considered, the results revealed that the proposed ensemble learner algorithms produced good predictive models with mean absolute percentage errors of 4.77%, at least on the dataset used, and scaled well in terms of performance when compared with conventional bagging and boosting algorithms.
3.2. Support Vector Machine and Artificial Neural Networks Learners
An SVM approach is usually used in data science to deal with linear and nonlinear classification problems. The basic idea of a SVM algorithm is to define a hyperplane (fine line) in two-dimensional space that can separate the values of the class labels in the training dataset. The algorithm receives training data observations as input and creates a hyperplane to distinguish between the class values of the input data. The algorithm chooses the data points (data observations) that are closest to the potential line (hyperplane) of the class values and then computes the margins (distances between the potential line and the data points), preferring the hyperplanes that maximise the margins.
An ANN approach mimics the human brain and the communication mechanism of the human biological neuronal system. From a computing learning prospective, an ANN algorithm consists of a set of layers—an input, one or more hidden layers, and an output. Each of these layers contains interconnected nodes each of which is linked with a weight and a threshold. When the output data of the node surpasses its threshold, the node is activated and will pass data on to the next layer of the network structure. The output decision is based on an activation function where the output of each node is calculated based on the values of the input data after multiplying these items with their corresponding weights and then totalling to provide a single number. The output of a node then becomes the input of the subsequent node. Often, the weights are initiated randomly, and the ANN algorithm continues to adjust the structure (model) during training until it reaches a certain termination condition. There are several types of ANN including feedforward, long short-term memory, and recurrent.
Some studies have applied SVM and ANN algorithms, or compared them with other ML algorithms, in classification problems related to the energy efficiency of buildings [27,40,41]. A hybrid method, called group support vector regression (GSVR), consisting of SVM algorithms (used for model verification) and a number of ML methods based on ANN and regression (used for early model building), has been proposed [40] to predict the thermal loads of residential buildings based on [8]’s dataset. To determine the final outcome of the heating and cooling loads, the hybrid method uses input data from the model building phase of the ANN and regression algorithms, and the predicted class labels of the generated models as input for the group SVMs. Empirical results showed that the group SVM method resulted in models with a high correlation coefficient and outperformed models developed by other ML algorithms such as KNN, ANN, and SVM.
Multistorey residential buildings from three cities in Morocco have been investigated using several ML algorithms to predict the heating loads based on simulated data consisting of building characteristics related to glazing, window shading, floor, and the infiltration rate, etc. [41]. The authors created synthetic building energy data consisting of 1000 points using a simulation tool called TRNSYS, and then divided the data into a 70% training set and 30% testing and validation sets. The authors then used a feature selection (wrapper) to reduce the number of features that could be offered to the ML algorithms automatically during the process of building the predictive models, using ML algorithms related to ANN, SVM, and optimisation to build the models. The experimental results on the synthetic data revealed that SVM and search algorithms produce high accuracy models. ANN algorithms were found to also be competitive in terms of accuracy, at least on the dataset considered.
A further study investigated thermal load prediction in smart buildings using an ANN algorithm with feature selection [27]. The primary motivation behind this research was to assist stakeholders in resource allocation, in both the short- and long-term, for providing a healthy environment, optimising energy consumption, and leading to reduced energy-related costs. The authors employed maximum relevance minimum redundancy (MRMR), Relief F and T-test techniques to identify the features needed by the ML algorithm, and then used these features to train the tri-layered neural network (TNN) algorithm to construct classification models for predicting thermal loads in smart buildings with IoT characteristics. For this purpose, the authors used the [8]’s residential dataset, and then divided the dataset into a 70% training subset and a 30% testing subset using five-fold cross validation when training the classification models. The experimental results showed that the glazing area and the relative compactness correlate well with thermal loads and thus, the building’s energy consumption. Furthermore, the classification models developed by the ML algorithms on the dataset considered were competitive in terms of the mean absolute errors (MAE).
A review of data-driven methods based on AI that could be utilised to achieve an efficient Home Energy Management System (HEMS) has been conducted [3]. The authors focused on research studies that investigated the problem of predicting HEMS factors including household consumption, energy load forecasting, load generation, and estimating energy bill prices, among others. The review covered studies disseminated between 2019 and 2021 and using an empirical approach based on data-driven methods that impact the predictive accuracy or efficiency of HEMS. Data-driven methods, such as decision trees, statistical approaches, probability approaches, and ANN, among others, were reviewed and contrasted in terms of various performance criteria. The authors only considered performance metrics of the ML algorithms in their discussion without considering other aspects related to energy loads forecasting.
3.3. Statistical and Probabilistic Learners
Some of the most studied mathematical approaches in data science are regression and probabilistic models, the former consisting of the relationship between the independent variables and the dependent variable, modelled using a function. In many cases, a linear regression is appropriate. However, in other cases where the relationship between the variables cannot be represented by a line, a nonlinear model can provide more accurate results when fitting a regression model to observed data.
The aim of regression is to fit the model to data observations, commonly taking a least-squares approach. Notably, regression models do not involve building model steps as in classical ML algorithms such as decision tree and induction of rules.
A ML approach does not require building model steps as in the statistical approach and offers the likelihood (probability) of the prediction for each dependent variable as a probabilistic classification [42]. A probabilistic version of the linear regression approach is logistic regression which employs a logistic function (sigmoid) to generate predictions as probabilities:
where
The sigmoid function is then used to map values between 0 and 1.
Probabilistic classification algorithms such as naϊve Bayes [43] are normally efficient since they use simple calculations based on joint probabilities of the variables’ values of inside test data to estimate the probabilities of the dependent variable values. Bayes-based algorithms usually assume that independent variables are independent of each other given the values of the dependent variable. To predict the class Y of a test data X, the conditional probability P(Xi = xi|Y = yj) for each variable value in X is computed; also, the probability of each class P(Y = yj) is required to be computed.
where
- P(Y|X) is the posterior probability: the probability of the class given the test data X input variable values;
- P(X|Y) is the probability of X variable values given the class value;
- P(Y) is the prior probability of the class;
- P(X) is the probability of X input variable values.
Some research studies have contrasted statistical and probabilistic methods with other AI and ML methods to address the problem of predicting the heating and cooling loads in buildings [39,44,45,46]. Specifically, a probabilistic data-driven method based on Bayes Theorem has been used to predict energy consumption in residential homes [43]. The authors used a dataset related to energy efficiency from [8] and applied the naϊve Bayes algorithm to predict the heating load, and the extent to which the roof area affected the cooling load. The experimental results show a good classification accuracy of 82.81%. The classifiers derived classification results consisting of good models for heating and cooling load prediction that can be used in optimising construction project design.
One study [45] categorised ways to predict the cooling loads in buildings into white-box approaches (simulation tools that utilise the physical description of the building as well as environment variables), black-box approaches (data driven approaches), and grey-box approaches (a hybrid of white- and black-box approaches). The authors followed previous research that focused on black-box methods as they require pre-defined variables currently available using hardware installed in smart homes. The authors studied the prediction of cooling loads based on parameters related to weather, and the internal activities of commercial buildings using the black-box approach (Bayesian network algorithm). The authors generated multiple simulated datasets to measure the performance of the Bayesian network algorithms in regard to the root mean squared deviation (RMSD), and the coefficient of determination (r2), and compared the performance with SVM and ANN algorithms. The results compared with the simulated datasets demonstrated that the models developed by the Bayesian network algorithm are competitive in terms of RMSD and r2 with those of the SVM and ANN algorithms; also, the Bayesian network algorithm develops models faster than the other algorithm considered when the training data spans more than 10 weeks. In addition, it seems that the algorithms are sensitive to weather forecast uncertainty when predicting the cooling load.
Other authors have studied the problem of predicting thermal loads in Chinese residential buildings based on synthetic data using five ML algorithms, most of which are regression-based (polynomial kernel support vector regression, linear regression, linear kernel support vector regression, Gaussian radial basis function kernel support vector regression, and ANN) [44]. The authors claimed that since limited real data regarding residential building energy efficiency is publicly available, the EnergyPlus tool was considered to be preferable for generating simulated residential household samples in the Chongqing urban area in China. The authors adapted several predictor variables of energy efficiency related to exterior windows, exterior walls, infiltration rate, area, etc. Empirical evaluations using the R tool, after splitting the data into a 75% training subset and a 25% testing subset, showed that the Gaussian radial basis function kernel support vector regression algorithm produced classification models for predicting thermal loads more efficiently and with less mean absolute error than most of the ML algorithms considered, at least when based on synthetic data.
3.4. Other Machine Learning Algorithms
ML methods have been employed with optimisation to, (a) select the best features related to residential home energy efficacy using RF-filtering, and (b) to pass these features to a classification algorithm to build heating and cooling predictive models [7]. The authors used a covariance matrix adaptive evolution strategy (CMA-ES) method for optimising the input features, and four hybrid algorithms, namely Random-LightGBM, CMA-ES-LightGBM, TPE-LightGBM, and Grid-LightGBM, were used to build energy efficiency predictive models. The models were tested on simulated data gathered from residential buildings in the Hohhot area of Mongolia, and then compared these with other ML algorithms, for instance, ensemble learners, in terms of various evaluation metrics. The results demonstrated that TPE-LightGBM produced models with high R2 value and small RMSE, MAE, and MAPE values among all of the models compared.
A hybrid auto-ML framework consisting of multiple classification techniques has also been developed [6]. The framework uses a hyper-optimisation algorithm to enhance the input variables and classification techniques to build predicate models for energy efficiency in residential buildings. ML algorithms, including LR, naive Bayes, three versions of decision trees, SVM, and XGBoost, were evaluated on the dataset of [8] which consists of eight variables and two class labels. The results showed improved predictive power of the proposed framework when compared with other ML algorithms.
One study compared three ML algorithms: SVM, random forest, and partial least squares, for the problem of predicting heat loads in a district heating system [47]. The authors used data collected from October 2014 to April 2015 by Eidsiva Bioenergi, AS, related to waste incineration plants in Hamar City, Norway. Data parameters including forward temperature, flow rate, return temperature, and heat load, among others, were used to train the ML algorithms and to generate the predictive models. The empirical evaluation showed that the SVM algorithm outperformed random forest and partial least squares in terms of the mean average percentage error and the mean absolute average performance measures. Another recent study for predicting the heat load for the Warsaw District Heating Network was conducted using a greater variety of ML algorithms [48]. The authors used three years of data related to geographical descriptions, namely the weather conditions, measurements, and billing between 2015 and 2018. The experimental results showed that the ANN algorithm with an autoregressive input model resulted in the highest level of accuracy for a large district heating network.
An investigation into the problem of heating load prediction using several ML algorithms including radial basis function regression, ElasticNet, random forest, alternating model tree, lazy locally weighted learning, and multi-layer perceptron regressor algorithms has been carried out [49]. The aim of the work was to design more energy-efficient buildings by focusing on the design of the HVAC. The authors used 768 residential buildings as part of the University of California Irvine (UCI) data repository [50] dataset to measure the performance of the considered ML algorithms for predicting the energy load. The authors used the WEKA ML tool to conduct the experiments, and during experimentation, the dataset was split into 80% for training and 20% for testing to build and test the heating load predictive models. The results showed that ML techniques, especially the random forest algorithm, are ideal for the problem of predicting heating loads in residential buildings since they provide competitive models in terms of root mean squared error, correlation coefficient (R2), and mean absolute error (MAE), among others.
It has been argued that some of the data-driven studies related to predicting the thermal loads of buildings can be sensitive to the hyper parameters set by the classification algorithm [51]. To overcome this issue, the author proposed a multi-objective optimisation method for adjusting parameters prior to building the models for thermal load prediction. For the purpose, synthetic data related to residential and non-residential buildings produced by the EnergyPlus tool (building performance simulation software) were used. The data cover parameters related to the buildings and the weather conditions. Results using random forest were generated against the synthetic data and showed that the multi-objective optimisation scales well when compared with the traditional grid search method in optimising the parameters of the classification algorithm.
Table 1 provides a summary of the ML studies reviewed in this chapter; the table highlights the problem tackled, the ML methods used, any feature selection/optimisation used, the performance measures considered, the datasets source, the characteristics of the datasets, such as the number of features, the software platform for the experiments, and whether the models developed by the ML techniques are interpretable by the end-user.
4. Discussion
4.1. Data and Simulation Tools
Most of the studies published measuring energy efficiency using data science techniques have focused on predicting heating or cooling loads, or both, based on several features related to the building. The authors used simulated data generated using building modelling software tools such as EnergyPlus [53] DOE-2 [54] DeST [55], TRNSYS [56], Ecotect [57], and others. The simulation of building energy is an affordable way to generate data and models for achieving an energy efficient plan. Building simulation often considers energy consumption, as well as architectural designs and concepts [58].
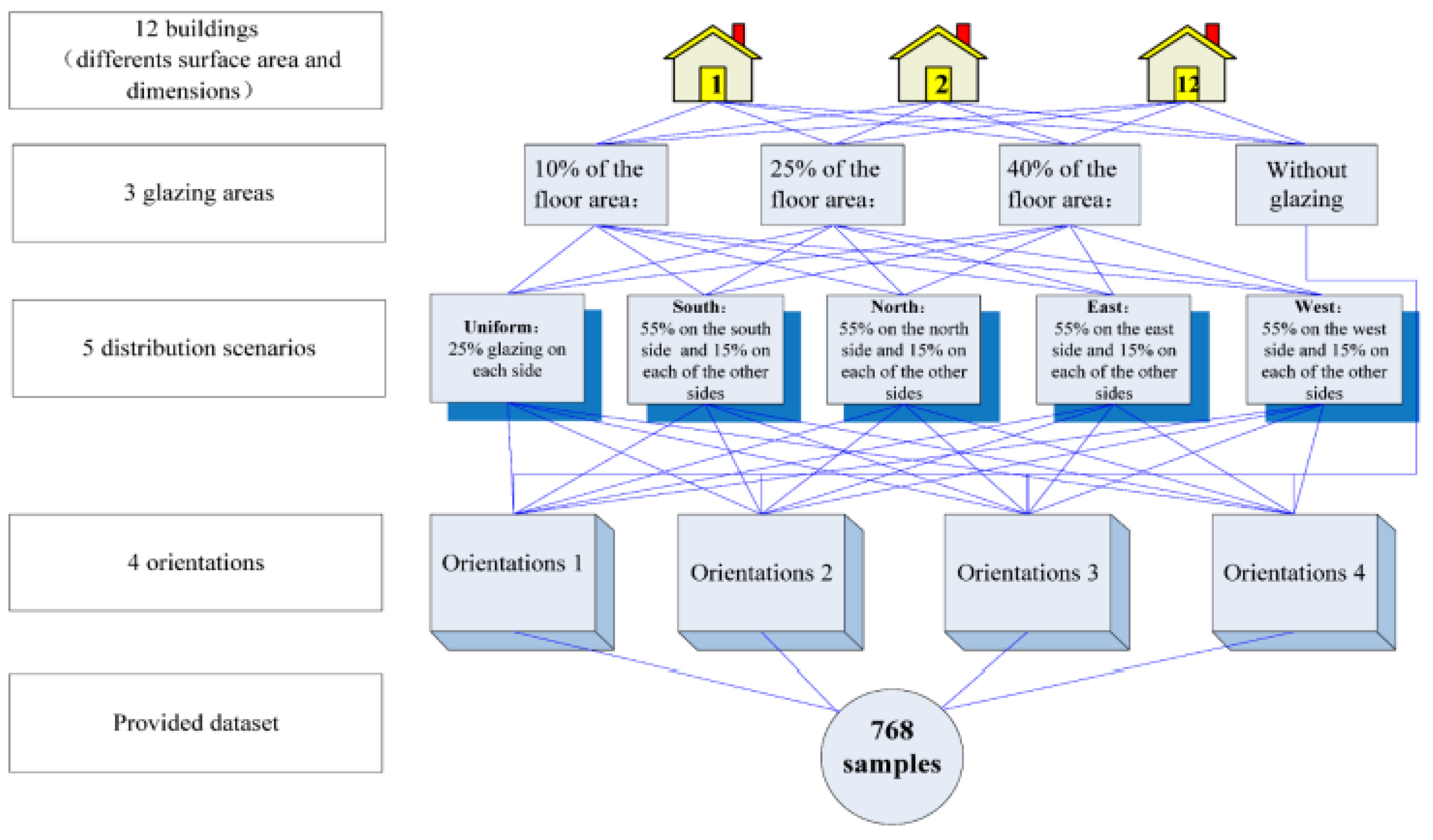
The reviewed research studies used one of the simulation tools. However, most used the dataset of [8], which was modelled using the Ecotect tool [57] for measuring energy efficiency. In [8], data from 768 buildings was modelled, taking into account 12 distinct buildings, five distribution setups, four glazing areas, and four orientations, using the Ecotect software tool as shown in Figure 1. Each simulated building consisted of 18 blocks, 3.5 × 3.5 × 3.5 m3 in dimension, using similar construction materials. The buildings used in the simulation tool are residential, located in Athens, Greece, and consist of seven occupants. During the simulation, it was assumed that the temperature within the buildings ranged from 19 to 24 °C, and that the occupant activity was for 15–20 h during weekdays, and 10–20 h during the weekends.
The dataset consists of eight independent variables and two dependent variables and is available online in the data repository including UCI [50]. The independent variables are: wall area, roof area, relative compactness, overall height, surface area, glazing area distribution, glazing area, and orientation; the dependent variables are the heating and cooling loads. This dataset seems to be the most popular among the published literature [6,7,37,40,46,49], all of whom have experimented with various ML models against this dataset. Other research studies have focused on predicting heating consumption in district heating networks. For example, one study used data collected from measurements that are part of the district heating system in a plant [47,48]. However, the heating load within district heating systems is not central to this study.
4.2. Models Interpretability for Stakeholders
One of the main advantages for the different stakeholders involved in building energy efficiency research, including engineers, occupants, investors, and designers, is the ability to exploit the model used for predicting heating and/or cooling loads [55]. Interpretable classification models can be defined as models that contain easy-to-comprehend rules which in turn are used to explain predictive decisions [55,59]. In this study, model interpretability is defined as the degree to which a model’s predictive decisions can be interpreted and used by the consumer. By providing interpretable models from ML algorithms, questions such as the following are able to be answered:
- 5.
- What are the influential building features that impact energy loads in an energy efficient system?
- 6.
- Why are certain features influential?
- 7.
- Under which values can we optimise the energy efficiency of a building, and how do we reach these values?
- 8.
- What energy consumption patterns can be found? And to which features do they belong?
- 9.
- How do we obtain an efficient HVAC system in terms of energy consumption?
- 10.
- How do we determine early designs of a building with energy conservation in mind?
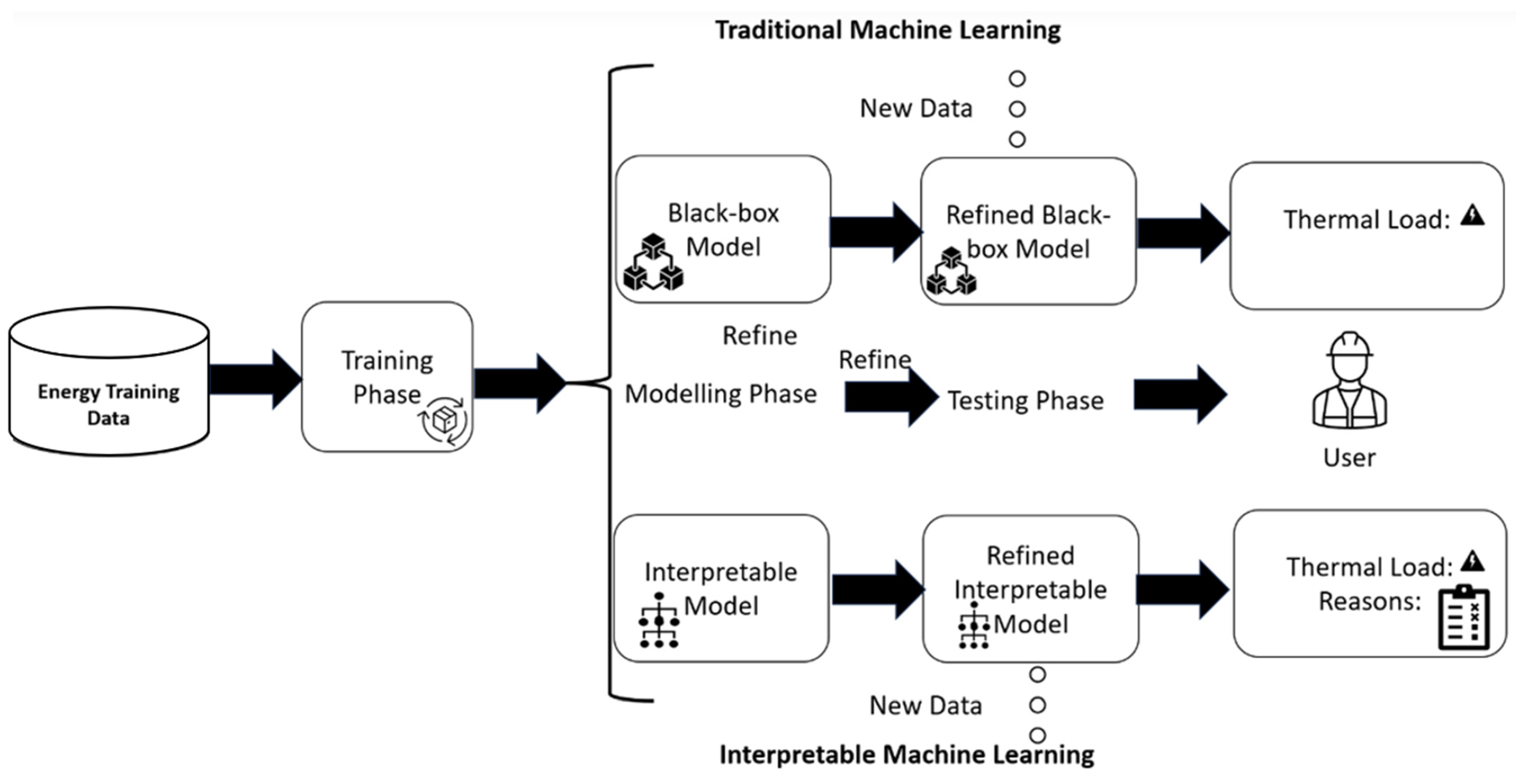
Figure 2 depicts the difference between classical ML techniques and interpretable ML techniques.
Unfortunately, most of the ML algorithms that have been studied to achieve energy efficiency using data-driven approaches do not generate models that are interpretable by stakeholders. The focus of these studies is to generate models that are more predictive with reference to certain performance measures such as the error rate, the predictive accuracy, R2, RMSE, MAE, etc. Very few studies focused on developing predictive models that are easy to use by engineers and other stakeholders who are interested in the design and development of energy efficient buildings. Recently, several deep learning techniques were combined with attention paid to developing a model that is interpretable for energy efficiency prediction [60]. There needs to be a focus on developing interpretable energy efficiency models for generating knowledge useful for users for facilitating the process of decision-making. For example, rule induction or decision trees, which develop models based on simple rules, have been found to be promising ML techniques. These methods remain largely under-researched in the context of energy efficiency, despite their widespread applications in other real application domains.
4.3. Platforms and Algorithms’ Hyperparameters
One of the main issues in research studies related to ML and AI applications is the tuning of the hyperparameter of the learning algorithm used to generate the results. Since the energy efficiency problem has been modelled as a typical classification task in data science in which the goal is to predict the heating or cooling loads, careful consideration is required when applying the classification algorithms in terms of optimising parameter values. The aim of the optimisation is to tune the hyperparameters of the ML techniques based on prior learning to guarantee performance. However, scholars are required to ensure that the tuning of the hyperparameters does not overfit the models derived by the ML algorithms. Some tuning is performed to determine which features to input for the ML techniques, hence feature engineering with optimisation techniques are used, either in a random search or manually. For example, two studies employed wrapper feature selection and recursive feature elimination, respectively, to select an optimised subset of features that can be passed to the ML algorithm [6,41]. Other researchers focused on setting optimal values to the classification algorithm parameters [51].
Across the considered studies, information has been provided by scholars on whether the classification algorithms’ hyperparameters have been tuned or whether the feature dimension space has been reduced. Some researchers have used separate optimisation techniques during pre-processing to tune the input parameters to certain values prior to building the energy efficiency predictive models [37,49] One study employed the Shuffled Frog Leaping Optimisation technique [61] to tune the hyperparameter values of the proposed regression tree ensemble (RTE) classification algorithm [37]. The RTE relies on the decision tree base algorithm parameters of maximum number of splits, and minimum leaf size; the least square-boosting ensemble relies on the learning rate thus used optimisation to ensure sustainable performance.
Attempting to tune parameters to certain optimised values for generating optimistic classification models can lead to overfitting of the model. The problem of overfitting in classification gives the end user an unrealistically good sense of model performance compared to what is observed in reality when tested in real unseen scenarios.
5. Conclusions, Limitations and Future Works
In energy efficiency, there are many challenges including predicting thermal loads, particularly the heating and cooling loads. Addressing this problem can substantially help engineers and other stakeholders to optimise heat utilisation and to reduce long-term energy costs and environmental harm. An effective technology that can provide affordable and high-quality solutions for this problem is ML. Techniques such as ensemble learning, SVM, statistical, ANN, and probabilistic approaches can be used to develop models from historical datasets to aid the process of predicting energy efficiency in terms of thermal loads. In addition, some ML techniques such as rule induction and decision trees can provide interpretable models, which help stakeholders in the design and construction of energy-efficient buildings. These models can reveal potential areas for energy-saving measures, such as increased insulation, reduced air leakage, and improved building orientation. They can also provide details on which features can contribute significantly to predicting thermal loads such as the wall area, the roof area, the relative compactness, the overall height, the surface area, the glazing area distribution, and orientation, among others. However, current review articles have not investigated interpretable models and mainly focus on ML performance. This research has thus reviewed common learning approaches in ML including ensemble learning, statistical models, decision trees, and others, with a focus on specific new criteria. The ML criteria discussed are the datasets used, the platforms used, the hyperparameter settings of the learning algorithms, and more critically, the interpretability of the features of the model. Moreover, we show that certain hyperparameter settings can change the overall performance of the energy efficiency of the predictive models. In addition, providing interpretable models in the area of energy efficiency in which users can obtain quality models that contain digital and easy-to-understand information, is crucial. There has been very little work on the development of rule induction for thermal prediction that provides engineers with interpretable models for revealing potential areas for energy-saving measures, such as increased insulation, reduced air leakage, and improved building orientation in easy-to-explore format rather than complex models that are hard to understand. We do not think that there has been a lot of work carried out in this area. Therefore, in near future, we intend to design and implement models based on rules.
Lastly, there is a lack of real data for thermal load prediction as most of the datasets provided are synthetic and generated using simulation tools. One of the limitations of this research is that it does not include advanced AI techniques, such as deep learning techniques. In the near future, we will develop an interpretable classification model for the thermal load prediction problem and compare the performance of the interpretable models with other existing ML techniques.
Author Contributions
Conceptualization, F.A.-J. and K.N.D.; methodology, F.A.-J.; formal analysis, F.A.-J.; writing—original draft preparation, F.A.-J.; writing—review and editing, F.A.-J. and K.N.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
| AI | Artificial intelligence |
| AMT | Alternating model tree |
| ANN | Artificial neural networks |
| BEMS | Building Energy Management Systems |
| CMA-ES | Covariance matrix adaptive evolution strategy |
| DH | District heating |
| DSOS | Discrete symbiotic organisms search |
| EPB | Energy performance of buildings |
| ERT | Extra random tree |
| FIMT-DD | Fast Incremental Model Trees with Drift Detection |
| GPR | Gaussian process regression algorithm |
| GSVR | Group support vector regression |
| HEMS | Home Energy Management System |
| HVAC | Heating, ventilation, and air conditioning |
| LCA | League championship algorithm |
| LLWL | Lazy locally weighted learning |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| ML | Machine learning |
| MLPr | Multi-layer Perceptron Regressor |
| MOA | Massive Online Analysis |
| MOBO | Multi-objective building optimisation tool |
| MRMR | Maximum relevance minimum redundancy |
| PLS | Partial least square |
| PSO | Particle swarm optimisation |
| RBFr | Radial basis function regression |
| RMSD | Root mean squared deviation |
| SRTE | SFLA-optimised regression tree ensemble |
| SVM | Support vector machines |
| UCI | University of California Irvine |
| WEKA | Waikato Environment for Knowledge Analysis |
References
- Sekisov, A. Problems of achieving energy efficiency in residential low-rise housing construction within the framework of the resource-saving technologies use. In Proceedings of the E3S Web of Conferences, Prague, Czech Republic, 12–17 September 2021; EDP Sciences: Paris, France, 2021; Volume 281, p. 06004. [Google Scholar]
- Energy.gov. Available online: https://www.energy.gov/eere/energy-efficiency#:~:text=Energy%20efficiency%20is%20the%20use,less%20energy%20to%20produce%20goods (accessed on 20 March 2023).
- Almughram, O.; Zafar, B.; Ben Slama, S. Home Energy Management Machine Learning Prediction Algorithms: A Review. In Proceedings of the 2nd International Conference on Industry 4.0 and Artificial Intelligence (ICIAI 2021), Hammamet, Tunisia, 28–30 November 2021; Atlantis Press: Paris, France, 2022; pp. 40–47. [Google Scholar]
- Wheeler, G. Performance of Energy Management Systems; Oregon State University: Corvallis, OR, USA, 2009. [Google Scholar]
- Zhang, J. Design and Technical Analysis of HVAC Ventilation System in Green Building. In Proceedings of the E3S Web of Conferences, Prague, Czech Republic, 12–17 September 2021; EDP Sciences: Paris, France, 2021; Volume 261, p. 03039. [Google Scholar]
- Lu, C.; Li, S.; Penaka, S.R.; Olofsson, T. Automated machine learning-based framework of heating and cooling load prediction for quick residential building design. Energy 2023, 274, 127334. [Google Scholar] [CrossRef]
- Guo, J.; Yun, S.; Meng, Y.; He, N.; Ye, D.; Zhao, Z.; Jia, L.; Yang, L. Prediction of heating and cooling loads based on light gradient boosting machine algorithms. J. Affect. Disord. 2023, 236, 110252. [Google Scholar] [CrossRef]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Heat Load in Buildings. Heat Load in Buildings—Designing Buildings. 2022. Available online: https://www.designingbuildings.co.uk/wiki/Heat_load_in_buildings (accessed on 31 May 2023).
- Rinaldi. 3 Types of Heating and Cooling Loads: Learn the Fundamentals; Rinaldi’s Air Conditioning & Heating: Orlando, FL, USA, 2021; Available online: https://rinaldis.com/heating-and-cooling-loads/ (accessed on 31 May 2021).
- Sun, Y.; Haghighat, F.; Fung, B.C.M. A review of the-state-of-the-art in data-driven approaches for building energy prediction. Energy Build. 2020, 221, 110022. [Google Scholar] [CrossRef]
- Chen, Z.; Xiao, F.; Guo, F.; Yan, J. Interpretable machine learning for building energy management: A state-of-the-art review. Adv. Appl. Energy 2023, 9, 100123. [Google Scholar] [CrossRef]
- International Energy Agency (IEA). Energy Efficient Buildings. 2021. Available online: https://www.iea.org/topics/energy-efficient-buildings (accessed on 3 February 2024).
- U.S. Green Building Council (USGBC). LEED. 2021. Available online: https://www.usgbc.org/leed (accessed on 25 March 2023).
- U.S. Green Building Council. What Is A Green Building? 2021. Available online: https://www.usgbc.org/articles/what-green-building (accessed on 24 March 2023).
- National Renewable Energy Laboratory. Renewable Energy Integration. 2021. Available online: https://www.nrel.gov/research/renewable-energy-integration.html (accessed on 2 June 2023).
- ISO 14040; International Organization for Standardization (IOS). Environmental Management—Life Cycle Assessment. 2019. Available online: https://www.iso.org/standard/68383.html\ (accessed on 3 February 2024).
- ASHRAE. 2020. Available online: https://www.ashrae.org/file%20library/about/position%20documents/pd_energyefficiencyinbuildings_ra2023.pdf (accessed on 12 May 2023).
- U.S. Department of Energy. Building Energy Efficiency. 2021. Available online: https://www.energy.gov/eere/buildings/building-energy-efficiency (accessed on 1 April 2023).
- Energy Star. About Energy Star. Available online: https://www.energystar.gov/about (accessed on 20 March 2023).
- National Renewable Energy Laboratory (NREL)-Home and Building Energy Management Systems. NREL.Gov. Available online: https://www.nrel.gov/grid/energy-management.html (accessed on 30 March 2023).
- U.S. Department of Energy (USDE). Zero Energy Buildings. 2021. Available online: https://www.energy.gov/eere/buildings/zero-energy-buildings (accessed on 28 March 2023).
- U.S. Department of Energy (USDE). Insulation. Available online: https://www.energy.gov/energysaver/weatherize/insulation (accessed on 19 April 2023).
- National Renewable Energy Laboratory (NREL). Energy-Efficient Windows. Available online: https://www.nrel.gov/docs/fy20osti/76883.pdf (accessed on 15 May 2023).
- U.S. Department of Energy. Lighting. 2021. Available online: https://www.energy.gov/energysaver/lighting (accessed on 22 March 2023).
- U.S. Department of Energy. Designing and Orienting Buildings for Optimum Energy Performance. Available online: https://www.energy.gov/energysaver/designing-and-orienting-buildings-optimum-energy-performance (accessed on 3 February 2024).
- Ghasemkhani, B.; Yilmaz, R.; Birant, D.; Kut, R.A. Machine Learning Models for the Prediction of Energy Consumption Based on Cooling and Heating Loads in Internet-of-Things-Based Smart Buildings. Symmetry 2022, 14, 1553. [Google Scholar] [CrossRef]
- Basic HVAC System Diagram with Important Parts and Components. ETechnoG (n.d.). Available online: https://www.etechnog.com/2020/11/what-is-hvac-system-its-need-important.html (accessed on 20 May 2023).
- Lubis, I.H.; Koerniawan, M.D. Reducing heat gains and cooling loads through roof structure. IOP Conf. Ser. Earth Environ. Sci. 2018, 152, 012008. [Google Scholar] [CrossRef]
- Hamlin, S.; Glass is essential to a building’s energy efficiency. Building Enclosure RSS. Available online: https://www.buildingenclosureonline.com/articles/89628-glass-is-essential-to-a-buildings-energy-efficiency (accessed on 24 May 2023).
- Geletka, V.; Sedlakova, A. Shape of Buildings and Energy Consumption—suw.biblos.pk.edu.pl. Available online: https://suw.biblos.pk.edu.pl/resources/i1/i4/i4/i8/i8/r14488/GeletkaV_ShapeBuildings.pdf (accessed on 29 May 2023).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Learning. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Analyticsvidhya, Jan 2023. Available online: https://www.analyticsvidhya.com/blog/2023/01/ensemble-learning-methods-bagging-boosting-and-stacking/ (accessed on 7 May 2023).
- Chaganti, R.; Rustam, F.; Daghriri, T.; Díez, I.d.l.T.; Mazón, J.L.V.; Rodríguez, C.L.; Ashraf, I. Building Heating and Cooling Load Prediction Using Ensemble Machine Learning Model. Sensors 2022, 22, 7692. [Google Scholar] [CrossRef]
- Pachauri, N.; Ahn, C.W. Regression tree ensemble learning-based prediction of the heating and cooling loads of residential buildings. Build. Simul. 2022, 15, 2003–2017. [Google Scholar] [CrossRef]
- Provatas, R. An Online Machine Learning Algorithm for Heat Load Forecasting in District Heating Systems. Master’s Thesis, Blekinge Institute of Technology, Karlskrona, Sweden, 2014. [Google Scholar]
- Liu, J.; Zeng, K.; Wang, H.; Du, B.; Tang, Y. Generalized Prediction of Commercial Buildings Cooling and Heating Load Based on Machine Learning Technology. In IOP Conference Series: Earth and Environmental Science, Proceedings of the 4th International Conference on Environmental, Industrial and Energy Engineering (EI2E 2020), Guiyang, China, 15–17 October 2020; IOP Publishing: Bristol, UK, 2020; Volume 610. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Mohammadi-Ivatloo, B.; Abapour, M.; Anvari-Moghaddam, A.; Roy, S.S. Heating and Cooling Loads Forecasting for Residential Buildings Based on Hybrid Machine Learning Applications: A Comprehensive Review and Comparative Analysis; IEEE Access: Piscataway, NJ, USA, 2021; Volume 10, pp. 2196–2215. [Google Scholar] [CrossRef]
- Abdou, N.; El Mghouchi, Y.; Jraida, K.; Hamdaoui, S.; Hajou, A.; Mouqallid, M. Prediction and optimization of heating and cooling loads for low energy buildings in Morocco: An application of hybrid machine learning methods. J. Build. Eng. 2022, 61, 105332. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. A Review of Probabilistic Forecasting and Prediction with Machine Learning. 2022. Available online: https://arxiv.org/pdf/2209.08307 (accessed on 3 February 2024).
- Webb, G.I. Naïve Bayes. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Li, X.; Yao, R. A machine-learning-based approach to predict residential annual space heating and cooling loads considering occupant behaviour. Energy 2020, 212, 118676. [Google Scholar] [CrossRef]
- Huang, S.; Zuo, W.; Sohn, M. A Bayesian Network Model for Predicting Cooling Load of Commercial Buildings. Build. Simul. 2018, 11, 87–101. [Google Scholar] [CrossRef]
- Prasetiyo, B.; Alamsyah; Muslim, M.A. Analysis of building energy efficiency dataset using naive bayes classification classifier. In Proceedings of the CMSE2018: 5. International Conference on Mathematics, Science and Education 2018, Kuta, Indonesia, 8–9 October 2018; International Atomic Energy Agency (IAEA): Vienna, Austria, 2018. [Google Scholar] [CrossRef]
- Dalipi, F.; Yayilgan, S.Y.; Gebremedhin, A. Data-Driven Machine-Learning Model in District Heating System for Heat Load Prediction: A Comparison Study. Appl. Comput. Intell. Soft Comput. 2016, 2016, 3403150. [Google Scholar] [CrossRef]
- Kurek, T.; Bielecki, A.; Świrski, K.; Wojdan, K.; Guzek, M.; Białek, J.; Brzozowski, R.; Serafin, R. Heat demand forecasting algorithm for a Warsaw district heating network. Energy 2021, 217, 119347. [Google Scholar] [CrossRef]
- Moayedi, H.; Bui, D.T.; Dounis, A.; Lyu, Z.; Foong, L.K. Predicting Heating Load in Energy-Efficient Buildings through Machine Learning Techniques. Appl. Sci. 2019, 9, 4338. [Google Scholar] [CrossRef]
- UCI. Available online: https://archive.ics.uci.edu/ml/datasets/energy+efficiency (accessed on 20 March 2023).
- Seyedzadeh, S.; Rahimian, F.P.; Rastogi, P.; Oliver, S.; Glesk, I.; Kumar, B. Multi-objective optimisation for tuning building heating and cooling loads forecasting models. In Proceedings of the 36th CIB W78 2019 Conference, Northumbria University, Newcastle upon Tyne, UK, 18–20 September 2019. [Google Scholar]
- An, W.; Zhu, X.; Yang, K.; Kim, M.K.; Liu, J. Hourly Heat Load Prediction for Residential Buildings Based on Multiple Combination Models: A Comparative Study. Buildings 2023, 13, 2340. [Google Scholar]
- Crawley, D.B.; Lawrie, L.K.; Winkelmann, F.C.; Buhl, W.; Huang, Y.; Pedersen, C.O.; Strand, R.K.; Liesen, R.J.; Fisher, D.E.; Witte, M.J.; et al. EnergyPlus: Creating a new-generation building energy simulation program. Energy Build. 2001, 33, 319–331. [Google Scholar] [CrossRef]
- Birdsall, B.; Buhl, W.F.; Ellington, K.L.; Erdem, A.E.; Winkelmann, F.C. Overview of the DOE-2 Building Energy Analysis Program, Version 2.1D; Technical Report LBL-19735-Rev.1; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 1990. [Google Scholar]
- Chen, F.; Deng, Y.; Xue, Z.; Wu, R. Toolpack for building environment simulation DeST. Heat. Vent. Air Cond. 1999, 29, 58–63. (In Chinese) [Google Scholar]
- Klein, S.A.; Duffie, J.A.; Beckman, W.A. TRNSYS—A transient simulation program. ASHRAE Trans. 1976, 82, 623–633. [Google Scholar]
- Beatriz, A.; Rodríguez-Ubiñas, E.; Bedoya-Frutos, C.; Vega-Sánchez, S. Evaluation of Three Solar and Daylighting Control System Based on Calumen II, Ecotect, and Radiance Simulation Programmes to Obtain an Energy Efficient and Healthy Interior in the Experimental Building Prototype SD10. Energy Build. 2014, 83, 225–236. [Google Scholar]
- Amani, N.; Sabamehr, A.; Palmero Iglesias, L.M. Review on Energy Efficiency using the Ecotect Simulation Software for Residential Building Sector. Iran. J. Energy Environ. 2022, 13, 284–294. [Google Scholar] [CrossRef]
- Naser, M.Z. An engineer’s guide to eXplainable Artificial Intelligence and Interpretable Machine Learning: Navigating causality, forced goodness, and the false perception of inference. Autom. Constr. 2021, 129, 103821. [Google Scholar] [CrossRef]
- Gao, Y.; Ruan, Y. Interpretable deep learning model for building energy consumption prediction based on attention mechanism. Energy Build. 2021, 252, 111379. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]

Figure 2.
The main differences between classical and interpretable ML techniques.


{kind=link}
{kind=link}
Table 1.
Summary of the Reviewed Studies.
| Year | Problem | ML Methods | Feature Selection/Optimisation | Performance Measure | Dataset Source | # of Features excl. class | Platform | Interpretable Models | Reference |
|---|---|---|---|---|---|---|---|---|---|
| 2023 | Heating and cooling loads prediction | LR, naive Bayes, three versions of decision trees, SVM, and XGBoost, DNN | Variance threshold and recursive feature elimination | R2, RMSE | Residential buildings in the Hohhot area of Mongolia | 8 | TPOT Python | No | [6] |
| 2023 | Heating and cooling loads prediction | Random-LightGBM, CMA-ES-LightGBM, TPE-LightGBM, and Grid-LightGBM, RF, SVM | RF-filter | R2, RMSE, MAE, MAPE | Residential buildings in the Hohhot area in Mongolia | 8 | Not known | No | [7] |
| 2022 | Heating and cooling loads prediction | Ensemble Learner with decision tree, RF, MLP, KNN, LR, 3RF, LR-GAM | No feature selection | R2 | [8] | 8 | Python-scikit-learn | No | [36] |
| 2022 | Heating and cooling loads prediction | Ensemble Learner with decision trees and the least square-boosting, different Gaussian process regression algorithm (GPR) versions | Shuffled Frog Leaping Optimisation | MSE, RMSE, R | [8] | 8 | Not known | No | [37] |
| 2022 | Heating and cooling loads prediction | ANN, SVM, LR, bagging, boosting and various tree-based algorithms | Maximum relevance minimum redundancy, F-test, regression Relief version-F | RMSE, MSE, and MAE | [8] | 8 | Tensorflow, H2O, Caffe, PyTorch, Microsoft Cognitive Toolkit | No | [27] |
| 2022 | Heating and cooling loads prediction | League championship algorithm (LCA), discrete symbiotic organisms search (DSOS) algorithm, particle swarm optimisation (PSO), SVM, ANN | Wrapper method | Optimisation with objective function and R2 | Synthetic building energy data of 1000 points | 11 | TRNSYS software coupled with multi-objective building optimisation tool (MOBO) | No | [41] |
| 2021 | Heating load prediction in a district heating system | Fuzzy logic, mixture of ANN and regression techniques | Forward feature selection | R2, MAE | Warsaw District Heating Network | Variety of measurements, geographical descriptions, weather, and billing data | [48] | ||
| 2020 | Heating and cooling loads prediction | KNN, CART, Lasso Regression, ElasticNet, RF, bagging, LIR, RIDGE, extra random tree (ERT), SVM | Recursive Feature Elimination with ERT algorithm, Pearson correlation | Accuracy | [8] | 8 | Not known | No | [39] |
| 2020 | Heating and cooling loads prediction | SVM, MLP | No feature selection | Accuracy, R, MSE, RMSE, MAE | [8] | 8 | Not known | No | [40] |
| 2020 | Heating and cooling loads prediction | Linear kernel support vector regression, polynomial kernel support vector regression, Gaussian radial basis function kernel support vector regression, LR, ANN | Spearman correlation | MSE, MAE | Residential building based on synthetic data in China generated by EnergyPlus tool | 5 | R tool | No | [44] |
| 2019 | Heating and cooling loads prediction | RF | Optimisation method to tune the algorithm’s hyperparameter | RMSE | US Department of Energy commercial building reference database, residential houses in Geneva, Switzerland and north of Germany | 12—climate, building and others | Python | No | [51] |
| 2019 | Heating load prediction | Multi-layer Perceptron Regressor (MLPr), lazy locally weighted learning (LLWL), alternatingmodel tree (AMT), RF ElasticNet, and radial basis function regression (RBFr) | No feature selection | R2, MAE, RMSE, RAE, and RRSE | [8] | 8 | Ecotect, WEKA | No | [49] |
| 2019 | Heating and cooling loads prediction | Naive Bayes | No feature selection | Precision, recall, MAE | [8] | 8 | Rapid Miner | No | [46] |
| 2018 | Cooling load | Bayesian network, ANN, SVM | No feature selection | R2, RMSE | University campus in Annapolis, Maryland, USA | Variety of features in 14 datasets | Python | No | [45] |
| 2016 | Heating load prediction in a district heating system | SVM, RF, Partial Least Square (PLS) | No feature selection | R, MAE | Waste incineration plants in Hamar, Norway | 5 | Unknown | No | [47] |
| 2014 | Heating load prediction | Bagging with Fast Incremental Model Trees with Drift Detection (FIMT-DD) | No feature selection | Mean absolute percentage error (MAPE) | Multiple district heating (DH)–datasets in Sweden | Variety of features | Massive Online Analysis (MOA) and WEKA | No | [38] |
| 2023 | Heating load prediction | Back propagation (BP) and ELMAN neural networks | Principal component analysis (PCA), | MSE, RMSE, MAE, MAPE, Accuracy | Meteorological data of a community in Weifang | Variety of features | MATLAB | No | [52] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Abdel-Jaber, F.; Dirks, K.N. A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques. Buildings 2024, 14, 752. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings14030752
AMA Style
Abdel-Jaber F, Dirks KN. A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques. Buildings. 2024; 14(3):752. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings14030752
Chicago/Turabian StyleAbdel-Jaber, Fayez, and Kim N. Dirks. 2024. "A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques" Buildings 14, no. 3: 752. https://0-doi-org.brum.beds.ac.uk/10.3390/buildings14030752
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.