
Complete Genome Sequence and Pan-Genome Analysis of Shewanella oncorhynchi Z-P2, a Siderophore Putrebactin-Producing Bacterium
Abstract
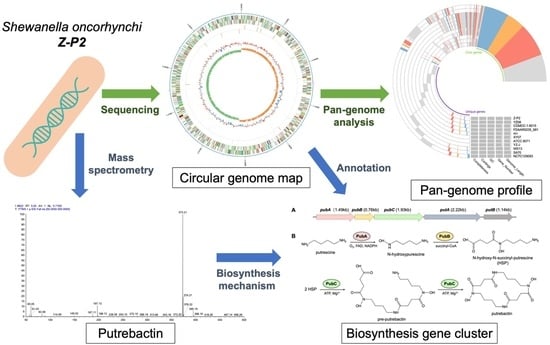
:
1. Introduction
2. Materials and Methods
2.1. Genome Sequencing and Functional Annotation
2.2. Pan-Genome and Core Genome Analysis
2.3. Chromeazurol S (CAS) Assay Analysis of Siderophore
2.4. Mass Spectrometry Analysis of Siderophore
3. Results and Discussion
3.1. Genome Features of S. oncorhynchi Z-P2
3.2. Genome Synteny and Pan-Genome Analysis
3.3. Analysis of the Putrebactin Biosynthetic Gene Cluster and Exporters Genes
3.4. Identification of Putrebactin
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Carroll, C.S.; Moore, M.M. Ironing out siderophore biosynthesis: A review of non-ribosomal peptide synthetase (NRPS)-independent siderophore synthetases. Crit. Rev. Biochem. Mol. Biol. 2018, 53, 356–381. [Google Scholar] [CrossRef]
- Hermenau, R.; Ishida, K.; Gama, S.; Hoffmann, B.; Pfeifer-Leeg, M.; Plass, W.; Mohr, J.F.; Wichard, T.; Saluz, H.; Hertweck, C. Gramibactin is a bacterial siderophore with a diazeniumdiolate ligand system. Nat. Chem. Biol. 2018, 14, 841–843. [Google Scholar] [CrossRef] [PubMed]
- Challis, G.L. A widely distributed bacterial pathway for siderophore biosynthesis independent of nonribosomal peptide synthetases. Chem. Bio Chem. 2005, 6, 601–611. [Google Scholar] [CrossRef]
- Liu, L.; Li, S.; Wang, S.; Dong, Z.; Gao, H. Complex iron uptake by the putrebactin-mediated and Feo systems in Shewanella oneidensis. Appl. Environ. Microbiol. 2018, 84, e01752-18. [Google Scholar] [CrossRef] [PubMed]
- Hider, R.C.; Kong, X. Chemistry and biology of siderophores. Nat. Prod. Rep. 2010, 27, 637. [Google Scholar] [CrossRef]
- Khan, A.; Singh, P.; Srivastava, A. Synthesis, nature and utility of universal iron chelator—Siderophore: A review. Microbiol. Res. 2018, 212–213, 103–111. [Google Scholar] [CrossRef]
- Ali, S.S.; Vidhale, N.N. Bacterial siderophore and their application: A review. Int. J. Curr. Microbiol. Appl. Sci. 2013, 2, 303–312. [Google Scholar]
- Janda, J.M.; Abbott, S.L. The genus Shewanella: From the briny depths below to human pathogen. Crit. Rev. Microbiol. 2014, 40, 293–312. [Google Scholar] [CrossRef]
- Mukherjee, M.; Zaiden, N.; Teng, A.; Hu, Y.; Cao, B. Shewanella biofilm development and engineering for environmental and bioenergy applications. Curr. Opin. Chem. Biol. 2020, 59, 84–92. [Google Scholar] [CrossRef]
- Fredrickson, J.K.; Romine, M.F.; Beliaev, A.S.; Auchtung, J.M.; Driscoll, M.E.; Gardner, T.S.; Nealson, K.H.; Osterman, A.L.; Pinchuk, G.; Reed, J.L.; et al. Towards environmental systems biology of Shewanella. Nat. Rev. Microbiol. 2008, 6, 592–603. [Google Scholar] [CrossRef]
- Hassoun, A.; Emir, Ç.Ö. Essential oils for antimicrobial and antioxidant applications in fish and other seafood products. Trends Food Sci. Technol. 2017, 68, 26–36. [Google Scholar] [CrossRef]
- Fu, H.; Liu, L.; Dong, Z.; Guo, S.; Gao, H. Dissociation between iron and heme biosyntheses is largely accountable for respiration defects of Shewanella oneidensis fur mutants. Appl. Environ. Microbiol. 2018, 84, e00039-18. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Wang, W.; Wu, S.; Gao, H. Recent advances in the siderophore biology of Shewanella. Front. Microbiol. 2022, 13, 823758. [Google Scholar] [CrossRef] [PubMed]
- Altun, S.; Duman, M.; Ay, H.; Saticioglu, I.B. Shewanella oncorhynchi sp. nov., a novel member of the genus Shewanella, isolated from Rainbow Trout (Oncorhynchus mykiss). Int. J. Syst. Evol. Microbiol. 2022, 72, 005460. [Google Scholar] [CrossRef] [PubMed]
- Kadi, N.; Arbache, S.; Song, L.; Oves-Costales, D.; Challis, G.L. Identification of a gene cluster that directs putrebactin biosynthesis in Shewanella species: PubC catalyzes cyclodimerization of N-hydroxy-N-succinylputrescine. J. Am. Chem. Soc. 2008, 130, 10458–10459. [Google Scholar] [CrossRef] [PubMed]
- Wick, R.R.; Judd, L.M.; Gorrie, C.L.; Holt, K.E. Unicycler: Resolving bacterial genome assemblies from short and long sequencing reads. PLoS Comput. Biol. 2017, 13, e1005595. [Google Scholar] [CrossRef]
- Aziz, R.K.; Bartels, D.; Best, A.A.; DeJongh, M.; Disz, T.; Edwards, R.A.; Formsma, K.; Gerdes, S.; Glass, E.M.; Kubal, M.; et al. The RAST server: Rapid annotations using subsystems technology. BMC Genom. 2008, 9, 75. [Google Scholar] [CrossRef]
- Tatusov, R.L.; Fedorova, N.D.; Jackson, J.D.; Jacobs, A.R.; Kiryutin, B.; Koonin, E.V.; Krylov, D.M.; Mazumder, R.; Mekhedov, S.L.; Nikolskaya, A.N.; et al. The COG database: An updated version includes eukaryotes. BMC Bioinform. 2003, 4, 41. [Google Scholar] [CrossRef]
- Lowe, T.M.; Eddy, S.R. tRNAscan-SE: A program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res. 1997, 25, 955–964. [Google Scholar] [CrossRef]
- Lagesen, K.; Hallin, P.; Rødland, E.A.; Stærfeldt, H.-H.; Rognes, T.; Ussery, D.W. RNAmmer: Consistent and rapid annotation of ribosomal RNA genes. Nucleic Acids Res. 2007, 35, 3100–3108. [Google Scholar] [CrossRef]
- Burge, S.W.; Daub, J.; Eberhardt, R.; Tate, J.; Barquist, L.; Nawrocki, E.P.; Eddy, S.R.; Gardner, P.P.; Bateman, A. Rfam 11.0: 10 years of RNA families. Nucleic Acids Res. 2013, 41, D226–D232. [Google Scholar] [CrossRef]
- Krzywinski, M.; Schein, J.; Birol, İ.; Connors, J.; Gascoyne, R.; Horsman, D.; Jones, S.J.; Marra, M.A. Circos: An information aesthetic for comparative genomics. Genome Res. 2009, 19, 1639–1645. [Google Scholar] [CrossRef] [PubMed]
- Tamura, K.; Stecher, G.; Kumar, S. MEGA11: Molecular evolutionary genetics analysis version 11. Mol. Biol. Evol. 2021, 38, 3022–3027. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, W.; Wan, I.; Jones, S.J.; Brinkman, F.S.L. IslandPath: Aiding detection of genomic islands in prokaryotes. Bioinformatics 2003, 19, 418–420. [Google Scholar] [CrossRef]
- Chen, L.; Xiong, Z.; Sun, L.; Yang, J.; Jin, Q. VFDB 2012 update: Toward the genetic diversity and molecular evolution of bacterial virulence factors. Nucleic Acids Res. 2012, 40, D641–D645. [Google Scholar] [CrossRef]
- Grissa, I.; Vergnaud, G.; Pourcel, C. CRISPRFinder: A web tool to identify clustered regularly interspaced short palindromic repeats. Nucleic Acids Res. 2007, 35 (Suppl. S2), W52–W57. [Google Scholar] [CrossRef]
- Blin, K.; Shaw, S.; Kloosterman, A.M.; Charlop-Powers, Z.; Wezel, G.P.; Medema, M.H.; Weber, T. antiSMASH 6.0: Improving cluster detection and comparison capabilities. Nucleic Acids Res. 2021, 49, W29–W35. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Zhang, Y.; Fan, G.; Sun, D.; Zhang, X.; Yu, Z.; Wang, J.; Wu, L.; Shi, W.; Ma, J. IPGA: A handy integrated prokaryotes genome and pan-genome analysis web service. iMeta 2022, 1, e55. [Google Scholar] [CrossRef]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef]
- Fouts, D.E.; Brinkac, L.; Beck, E.; Inman, J.; Sutton, G. PanOCT: Automated clustering of orthologs using conserved gene neighborhood for pan-genomic analysis of bacterial strains and closely related species. Nucleic Acids Res. 2012, 40, e172. [Google Scholar] [CrossRef]
- Gardner, S.N.; Slezak, T.; Hall, B.G. kSNP3.0: SNP detection and phylogenetic analysis of genomes without genome alignment or reference genome. Bioinformatics 2015, 31, 877–2878. [Google Scholar] [CrossRef]
- Marçais, G.; Delcher, A.L.; Phillippy, A.M.; Coston, R.; Salzberg, S.L.; Zimin, A. MUMmer4: A fast and versatile genome alignment system. PLoS Comput. Biol. 2018, 14, e1005944. [Google Scholar] [CrossRef]
- Schwyn, B.; Neilands, J.B. Universal chemical assay for the detection and determination of siderophores. Anal. Biochem. 1987, 160, 47–56. [Google Scholar] [CrossRef]
- Arora, N.K.; Verma, M. Modified microplate method for rapid and efficient estimation of siderophore produced by bacteria. 3 Biotech 2017, 7, 381. [Google Scholar] [CrossRef] [PubMed]
- Gleditzsch, D.; Müller-Esparza, H.; Pausch, P.; Shaima, K.; Dwarakanath, S.; Urlaub, H.; Bange, G.; Randau, L. Modulating the Cascade architecture of a minimal Type IF CRISPR-Cas system. Nucleic Acids Res. 2016, 44, 5872–5882. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Doak, T.G.; Ye, Y. Expanding the catalog of cas genes with metagenomes. Nucleic Acids Res. 2014, 42, 2448–2459. [Google Scholar] [CrossRef] [PubMed]
- Schöner, T.A.; Gassel, S.; Osawa, A.; Tobias, N.J.; Okuno, Y.; Sakakibara, Y.; Shindo, K.; Sandmann, G.; Bode, H.B. Aryl polyenes, a highly abundant class of bacterial natural products, are functionally related to antioxidative carotenoids. Chem. Bio Chem. 2016, 17, 247–253. [Google Scholar] [CrossRef]
- Robinson, S.L.; Christenson, J.K.; Wackett, L.P. Biosynthesis and chemical diversity of β-lactone natural products. Nat. Prod. Rep. 2019, 36, 458–475. [Google Scholar] [CrossRef]
- Lee, S.-J.; Seo, P.-S.; Kim, C.H. Isolation and characterization of the eicosapentaenoic acid biosynthesis gene cluster from Shewanella sp. BR-2. J. Microbiol. Biotechnol. 2009, 19, 881–887. [Google Scholar] [CrossRef]
- Wan, X.-F.; VerBerkmoes, N.C.; McCue, L.A.; Stanek, D.; Connelly, H.; Hauser, L.J.; Wu, L.; Liu, X.; Yan, T.; Leaphart, A.; et al. Transcriptomic and proteomic characterization of the Fur modulon in the metal-reducing bacterium Shewanella oneidensis. J. Bacteriol. 2004, 186, 8385–8400. [Google Scholar] [CrossRef]
- Rütschlin, S.; Gunesch, S.; Böttcher, T. One enzyme, three metabolites: Shewanella algae controls siderophore production via the cellular substrate pool. Cell Chem. Biol. 2017, 24, 598–604.e10. [Google Scholar] [CrossRef] [PubMed]
- Carriel, D.; Garcia, P.S.; Castelli, F.; Lamourette, P.; Fenaille, F.; Brochier-Armanet, C.; Elsen, S.; Gutsche, I. A novel subfamily of bacterial AAT-fold basic amino acid decarboxylases and functional characterization of its first representative: Pseudomonas aeruginosa LdcA. Genome Biol. Evol. 2018, 10, 3058–3075. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Liang, H.; Liu, L.; Jiang, X.; Wu, S.; Gao, H. Promiscuous enzymes cause biosynthesis of diverse siderophores in Shewanella oneidensis. Appl. Environ. Microbiol. 2020, 86, e00030-20. [Google Scholar] [CrossRef] [PubMed]
- Alav, I.; Kobylka, J.; Kuth, M.S.; Pos, K.M.; Picard, M.; Blair, J.M.A.; Bavro, V.N. Structure, assembly, and function of tripartite efflux and type 1 secretion systems in gram-negative bacteria. Chem. Rev. 2021, 121, 5479–5596. [Google Scholar] [CrossRef]
- Gram, L. Siderophore-mediated iron sequestering by Shewanella putrefaciens. Appl. Environ. Microbiol. 1994, 60, 2132–2136. [Google Scholar] [CrossRef]
- Böttcher, T.; Clardy, J. A chimeric siderophore halts swarming Vibrio. Angew. Chem. Int. Ed. 2014, 53, 3510–3513. [Google Scholar] [CrossRef]
- Soe, C.Z.; Codd, R. Unsaturated macrocyclic dihydroxamic acid siderophores produced by Shewanella putrefaciens using precursor-directed biosynthesis. ACS Chem. Biol. 2014, 9, 945–956. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CRISPR Array Location | Length (bp) | Spacer Length | Spacer Numbers | DR 1 Length | cas Genes |
|---|---|---|---|---|---|
| 1,457,061–457,246 | 186 | 54 | 2 | 26 | - |
| 911,996–912,258 | 263 | 33 | 3 | 40 | - |
| 1,238,331–1,244,119 | 5789 | 31 | 96 | 28 | cas1f (1,231,745–1,232,722) cas3 (1,232,735–1,235,671) cas7fv (1,235,675–1,236,622) cas5fv (1,236,631–1,237,641) cas6f (1,237,650–1,238,201) |
| 2,074,007–2,075,908 | 1902 | 32 | 27 | 36 | - |
| 2,087,585–2,089,626 | 2042 | 32 | 29 | 36 | cas2 (2,076,073–2,076,216) cas6 (2,077,318–2,078,265) csx3 (2,078,361–2,078,699) RA178_09445 (2,081,075–2,081,731) RA178_09450 (2,081,728–2,083,311) RA178_09455 (2,083,308–2,084,741) RA178_09465 (2,085,256–2,087,445) |
| Type | Gene Location | Length (bp) | Gene ID | Product |
|---|---|---|---|---|
| ABC 1 | 844,226–846,259 | 2034 | RA178_03930 | MacB family efflux pump subunit |
| MFS 2 | 1,302,942–1,304,105 | 1164 | RA178_05870 | multidrug effflux MFS transporter |
| 2,333,160–2,334,383 | 1224 | RA178_10585 | multidrug effflux MFS transporter | |
| 2,484,985–2,486,217 | 1233 | RA178_11215 | multidrug efflux MFS transporter EmrD | |
| 4,783,149–4,784,357 | 1209 | RA178_21055 | multidrug effflux MFS transporter | |
| RND 3 | 675,824–678,895 | 3072 | RA178_03090 | efflux RND transporter permease subunit |
| 696,040–699,126 | 3087 | RA178_03150 | efflux RND transporter permease subunit | |
| 842,991–844,223 | 1233 | RA178_03925 | efflux RND transporter permease subunit | |
| 1,075,848–1,077,110 | 1263 | RA178_04820 | HlyD family efflux transporter periplasmic adaptor subunit | |
| 1,291,279–1,294,437 | 3159 | RA178_05825 | multidrug efflux RND transporter permease subunit | |
| 1,304,185–1,307,325 | 3141 | RA178_05875 | efflux RND transporter permease subunit | |
| 1,559,138–1,562,218 | 3081 | RA178_07075 | efflux RND transporter permease subunit | |
| 1,782,382–1,785,630 | 3249 | RA178_08120 | efflux RND transporter permease subunit | |
| 2,047,189–2,050,284 | 3096 | RA178_09240 | efflux RND transporter permease subunit | |
| 2,146,014–2,149,133 | 3120 | RA178_09810 | multidrug efflux RND transporter permease subunit | |
| 2,169,901–2,172,948 | 3048 | RA178_09915 | efflux RND transporter permease subunit | |
| 2,172,945–2,176,196 | 3252 | RA178_09920 | efflux RND transporter permease subunit | |
| 3,275,726–3,276,736 | 1011 | RA178_14795 | HlyD family efflux transporter periplasmic adaptor subunit | |
| 4,005,831–4,009,022 | 3192 | RA178_17790 | efflux RND transporter permease subunit | |
| 4,364,416–4,367,640 | 3225 | RA178_19380 | efflux RND transporter permease subunit | |
| 4,828,489–4,831,632 | 3144 | RA178_21255 | efflux RND transporter permease subunit | |
| 4,905,088–4,908,222 | 3135 | RA178_21580 | efflux RND transporter permease subunit | |
| 4,929,711–4,932,878 | 3168 | RA178_21675 | efflux RND transporter permease subunit | |
| 4,944,067–4,947,120 | 3054 | RA178_21735 | CusA/CzcA family heavy metal efflux RND |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Pan, M.; Wang, Q.; Wang, L.; Liao, L. Complete Genome Sequence and Pan-Genome Analysis of Shewanella oncorhynchi Z-P2, a Siderophore Putrebactin-Producing Bacterium. Microorganisms 2023, 11, 2961. https://0-doi-org.brum.beds.ac.uk/10.3390/microorganisms11122961
Zhang Y, Pan M, Wang Q, Wang L, Liao L. Complete Genome Sequence and Pan-Genome Analysis of Shewanella oncorhynchi Z-P2, a Siderophore Putrebactin-Producing Bacterium. Microorganisms. 2023; 11(12):2961. https://0-doi-org.brum.beds.ac.uk/10.3390/microorganisms11122961
Chicago/Turabian StyleZhang, Ying, Mengjie Pan, Qiaoyun Wang, Lan Wang, and Li Liao. 2023. "Complete Genome Sequence and Pan-Genome Analysis of Shewanella oncorhynchi Z-P2, a Siderophore Putrebactin-Producing Bacterium" Microorganisms 11, no. 12: 2961. https://0-doi-org.brum.beds.ac.uk/10.3390/microorganisms11122961