Goat Milk Nutritional Quality Software-Automatized Individual Curve Model Fitting, Shape Parameters Calculation and Bayesian Flexibility Criteria Comparison

 ,
,  , , , and
, , , and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Animal Sample and Sample Selection Process
2.2. Milk Performance Standardization
2.3. Milk Composition Technical Records
2.4. Milk Composition Biological Analysis and Percentual Records
2.5. Statistical Analysis
2.5.1. Parametric Assumption Testing
2.5.2. Composition Curve Models and Shape Parameters
2.5.3. Model Selection Criteria
2.5.4. Bayesian Model Criterion Comparison
2.5.5. Curve Shape Parameters Computation for the Best-Fitting Model
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ehrlich, J.L. Quantifying inter-group variability in lactation curve shape and magnitude with the MilkBot® lactation model. PeerJ. 2013, 1, e54. [Google Scholar] [CrossRef] [Green Version]
- Cankaya, S.; Unalan, A.; Soydan, E. Selection of a mathematical model to describe the lactation curves of Jersey cattle. Arch. Anim. Breed. 2011, 54, 27–35. [Google Scholar] [CrossRef]
- Hossein-Zadeh, N.G. Comparison of non-linear models to describe the lactation curves of milk yield and composition in Iranian Holsteins. J. Agric. Sci. 2014, 152, 309–324. [Google Scholar] [CrossRef]
- Shaat, I. Application of the Wood lactation curve in analysing the variation of daily milk yield in the Zaraibi goats in Egypt. Small Rumin. Res. 2014, 117, 25–33. [Google Scholar] [CrossRef]
- Dematawewa, C.; Pearson, R.; VanRaden, P. Modeling extended lactations of Holsteins. J. Dairy Sci. 2007, 90, 3924–3936. [Google Scholar] [CrossRef] [PubMed]
- Adewumi, O.; Oluwatosin, B.; Tona, G.; Williams, T.; Olajide, O. Milk yield and milk composition of Kalahari Red goat and the performance of their kids in the humid zone. Arch. Zootec. 2017, 66, 587–592. [Google Scholar] [CrossRef] [Green Version]
- Fernández, C.; Sánchez, A.; Garcés, C. Modeling the lactation curve for test-day milk yield in Murciano-Granadina goats. Small Rumin. Res. 2002, 46, 29–41. [Google Scholar] [CrossRef]
- Macciotta, N.P.P.; Vicario, D.; Cappio-Borlino, A. Detection of different shapes of lactation curve for milk yield in dairy cattle by empirical mathematical models. J. Dairy Sci. 2005, 88, 1178–1191. [Google Scholar] [CrossRef] [Green Version]
- León, J.M.; Macciotta, N.P.P.; Gama, L.T.; Barba, C.; Delgado, J.V. Characterization of the lactation curve in Murciano-Granadina dairy goats. Small Rumin. Res. 2012, 107, 76–84. [Google Scholar] [CrossRef]
- Pizarro Inostroza, M.G.; Landi, V.; Navas González, F.J.; León Jurado, J.M.; Martínez Martínez, M.d.A.; Fernández Álvarez, J.; Delgado Bermejo, J.V. Non-parametric analysis of casein complex genes epistasis and their effect on phenotypic expression of milk yield and composition in Murciano-Granadina goats. J. Dairy Sci. 2020, 103, 8274–8291. [Google Scholar] [CrossRef]
- Pizarro Inostroza, M.G.; Landi, V.; Navas González, F.J.; León Jurado, J.M.; Delgado Bermejo, J.V.; Fernández Álvarez, J.; Martínez Martínez, M.d.A. Integrating Casein Complex SNPs Additive, Dominance and Epistatic Effects on Genetic Parameters and Breeding Values Estimation for Murciano-Granadina Goat Milk Yield and Components. Genes 2020, 11, 309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pizarro Inostroza, M.G.; Landi, V.; Navas González, F.J.; León Jurado, J.M.; Martínez Martínez, M.d.A.; Fernández Álvarez, J.; Delgado Bermejo, J.V. Non-parametric association analysis of additive and dominance effects of casein complex SNPs on milk content and quality in Murciano-Granadina goats. J. Anim. Breed. Genet. 2019, 137, 407–422. [Google Scholar] [CrossRef] [PubMed]
- Šebjan, U.; Tominc, P. Impact of support of teacher and compatibility with needs of study on usefulness of SPSS by students. Comput. Hum. Behav. 2015, 53, 354–365. [Google Scholar] [CrossRef]
- Ozgur, C.; Alam, P.; Booth, D. R, Python, Excel, SPSS, SAS, and MINITAB in Research; 2018. Proceedings of Decision Sciences Institute 2019 Annual Conference, New Orleans, Louisiana, 20–22 February 2019; p. 9. [Google Scholar]
- Delgado, J.V.; León, J.M.; Quiroz, J.L.; Lozano, M.I. Esquema de selección de sementales caprinos de aptitud lechera de raza Murciano-Granadina. FEAGAS 2005, 27, 109–113. [Google Scholar]
- Fernández Álvarez, J.; León Jurado, J.M.; Navas González, F.J.; Iglesias Pastrana, C.; Delgado Bermejo, J.V. Optimization and Validation of a Linear Appraisal Scoring System for Milk Production-Linked Zoometric Traits in Murciano-Granadina Dairy Goats and Bucks. Appl. Sci. 2020, 10, 5502. [Google Scholar] [CrossRef]
- Yañez-Ruiz, D.R. Goat Production in Spain; CSIC-SOLID: Granada, Spain, 2016. [Google Scholar]
- Delgado, J.V.; Landi, V.; Barba, C.J.; Fernández, J.; Gómez, M.M.; Camacho, M.E.; Martínez, M.A.; Navas, F.J.; León, J.M. Murciano-Granadina Goat: A Spanish Local Breed Ready for the Challenges of the Twenty-First Century. In Sustainable Goat Production in Adverse Environments: Volume II, 1st ed.; Simoes, J., Gutierrez, C., Eds.; Springer International Plubishing: Cham, Switzerland, 2017; pp. 205–219. [Google Scholar]
- Pizarro, G.; Landi, V.; León Jurado, J.M.; Navas González, F.J.; Delgado Bermejo, J.V. Non-parametric analysis of the effects of αS1-casein genotype and parturition nongenetic factors on milk yield and composition in Murciano-Granadina goats. Ital. J. Anim. Sci. 2019, 18, 1021–1034. [Google Scholar] [CrossRef] [Green Version]
- International committee fo Animal Recording (ICAR). Guidelines for Performance Recording in Dairy Sheep and Dairy Goats; ICAR: Rome, Italy, 2018; p. 35. [Google Scholar]
- Norman, H.; Cooper, T.; Ross, J.F.A. State and National Standardized Lactation Averages by Breed for Cows Calving in 2010; Animal Improvement Programs Laboratory, Agricultural Research Service, USDA: Beltsville, MD, USA, 2010. [Google Scholar]
- Durbin, J. Testing for serial correlation in least-squares regression when some of the regressors are lagged dependent variables. Econometrica 1970, 38, 410–421. [Google Scholar] [CrossRef]
- Greenberg, D.; Kerwick, S.; Encheva, T.; Williamson, D.; Mingyuan, Z.; Muthuraman, K.; Moliski, L.; Murray, J. Durbin watson statistic after the two statisticians. In STA 371G; University of Texas: Austin, TX, USA, 2020; pp. 2–16. [Google Scholar]
- Chen, Y. Spatial autocorrelation approaches to testing residuals from least squares regression. PLoS ONE 2016, 11, e0146865. [Google Scholar] [CrossRef] [Green Version]
- IBM Corp. IBM SPSS Statistics for Windows, Version 25.0; Software for IBM Corp: Armonk, NY, USA, 2017.
- Kaygisiz, F.; Sezgin, F.H. Forecasting goat milk production in Turkey using Artificial Neural Networks and Box-Jenkins models. Anim. Rev. 2017, 4, 45–52. [Google Scholar]
- Feistauer, M.; Dolejší, V.; Knobloch, P.; Najzar, K. Numerical Mathematics and Advanced Applications. In Proceedings of the ENUMATH 2003 the 5th European Conference on Numerical Mathematics and Advanced Applications, Prague, Czech Republic, 18–22 August 2003; Springer: Berlin/Heidelberg, Germany, 2004; p. 876. [Google Scholar]
- Arora, J.S. Chapter 14-Practical Applications of Optimization. In Introduction to Optimum Design, 4th ed.; Arora, J.S., Ed.; Academic Press: Boston, MA, USA, 2017; pp. 601–680. [Google Scholar]
- Asherson, R.; Walker, S.; Jara, L.J. Endocrine Manifestations of Systemic Autoimmune Diseases; Elsevier Science: Amsterdam, The Netherlands, 2008; p. 340. [Google Scholar]
- Val-Arreola, D.; Kebreab, E.; Dijkstra, J.; France, J. Study of the lactation curve in dairy cattle on farms in central Mexico. J. Dairy Sci. 2004, 87, 3789–3799. [Google Scholar] [CrossRef]
- Karangeli, M.; Abas, Z.; Koutroumanidis, T.; Malesios, C.; Giannakopoulos, C. Comparison of Models for Describing the Lactation Curves of Chios Sheep Using Daily Records Obtained from an Automatic Milking System. Proceedings of 5th International Conference on Information and Communication Technologies for Sustainable Agri-production and Environment, Skiathos Island, Greece, 8–11 September 2011; pp. 571–589. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Multimodel inference: Understanding AIC and BIC in model selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Leonard, T.; Hsu, J.S. Bayesian Methods: An Analysis for Statisticians and Interdisciplinary Researchers; Cambridge University Press: Cambridge, UK, 2001; p. 333. [Google Scholar]
- IBM Corp. IBM SPSS Statistics Algorithms, 25th ed.; IBM Corp.: Armonk, NY, USA, 2017; p. 110. [Google Scholar]
- Jeffreys, H. Theory of Probability, 3rd ed.; Oxford University Press: Oxford, UK, 1961. [Google Scholar]
- Lee, M.; Wagenmakers, E. Bayesian Cognitive Modeling: A Practical Course; Cambridge University Press: Cambridge, UK, 2013; pp. 3–247. [Google Scholar]
- Liang, F.; Paulo, R.; Molina, G.; Clyde, M.A.; Berger, J.O. Mixtures of g priors for Bayesian variable selection. J. Am. Stat. Assoc. 2008, 103, 410–423. [Google Scholar] [CrossRef]
- Morey, R.; Rouder, J. Bayes Factor 0.9. 12-2. Comprehensive R Archive Network (CRAN); RC Team: Vienna, Austria, 2015. [Google Scholar]
- Rouder, J.N.; Speckman, P.L.; Sun, D.; Morey, R.D.; Iverson, G. Bayesian t tests for accepting and rejecting the null hypothesis. Psychon Bull. Rev. 2009, 16, 225–237. [Google Scholar] [CrossRef] [PubMed]
- Rouder, J.N.; Morey, R.D.; Speckman, P.L.; Province, J.M. Default Bayes factors for ANOVA designs. J. Math. Psychol. 2012, 56, 356–374. [Google Scholar] [CrossRef]
- Heck, D. A Caveat on the Savage-Dickey Density Ratio: The Case of Computing Bayes Factors for Regression Parameters. Br. J. Math. Stat. Psychol. 2019, 72, 316–333. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bayarri, M.J.; Berger, J.O.; Forte, A.; García-Donato, G. Criteria for Bayesian model choice with application to variable selection. Ann. Stat. 2012, 40, 1550–1577. [Google Scholar] [CrossRef] [Green Version]
- Eqsquest. Symbolab. Available online: https://es.symbolab.com/ (accessed on 25 April 2020).
- Mohanty, B.S.; Verma, M.R.; Sharma, V.B.; Roy, P.K. Comparative study of lactation curve models in crossbred dairy cows. Int. J. Agric. Stat. Sci. 2017, 13, 545–551. [Google Scholar]
- González-Peña, D.; Acosta, J.; Guerra, D.; González, N.; Acosta, M.; Sosa, D.; Torres-Hernández, G. Modeling of individual lactation curves for milk production in a population of Alpine goats in Cuba. Livest. Sci. 2012, 150, 42–50. [Google Scholar] [CrossRef]
- Harder, I.; Stamer, E.; Junge, W.; Thaller, G. Lactation curves and model evaluation for feed intake and energy balance in dairy cows. J. Dairy Sci. 2019, 102, 7204–7216. [Google Scholar] [CrossRef]
- Oravcová, M.; Margetín, M. First estimates of lactation curves in White Shorthaired goats. Slovak J. Anim. Sci. 2015, 48, 1–7. [Google Scholar]
- Silvestre, A.M.; Petim-Batista, F.; Colaço, J. The Accuracy of Seven Mathematical Functions in Modeling Dairy Cattle Lactation Curves Based on Test-Day Records from Varying Sample Schemes. J. Dairy Sci. 2006, 89, 1813–1821. [Google Scholar] [CrossRef] [Green Version]
- Buttchereit, N.; Stamer, E.; Junge, W.; Thaller, G. Evaluation of five lactation curve models fitted for fat: Protein ratio of milk and daily energy balance. J. Dairy Sci. 2010, 93, 1702–1712. [Google Scholar] [CrossRef] [PubMed]
- Santos, D.J.A.; Peixoto, M.G.C.D.; Aspilcueta Borquis, R.R.; Panetto, J.C.C.; El Faro, L.; Tonhati, H. Predicting breeding values for milk yield of Guzerá (Bos indicus) cows using random regression models. Livest. Sci. 2014, 167, 41–50. [Google Scholar] [CrossRef]
- Macciotta, N.P.P.; Dimauro, C.; Rassu, S.P.G.; Steri, R.; Pulina, G. The mathematical description of lactation curves in dairy cattle. Ital. J. Anim. Sci. 2011, 10, e51. [Google Scholar] [CrossRef] [Green Version]
- Mead, J.R.; Irvine, S.A.; Ramji, D.P. Lipoprotein lipase: Structure, function, regulation, and role in disease. J. Mol. Med. 2002, 80, 753–769. [Google Scholar] [CrossRef] [PubMed]
- Grossman, M.; Koops, W. Multiphasic analysis of lactation curves in dairy cattle. J. Dairy Sci. 1988, 71, 1598–1608. [Google Scholar] [CrossRef]
- Green, L.; Schukken, Y.; Green, M. On distinguishing cause and consequence: Do high somatic cell counts lead to lower milk yield or does high milk yield lead to lower somatic cell count? Prev. Vet. Med. 2006, 76, 74–89. [Google Scholar] [CrossRef]
- Green, M.; Bradley, A.; Newton, H.; Browne, W. Seasonal variation of bulk milk somatic cell counts in UK dairy herds: Investigations of the summer rise. Prev. Vet. Med. 2006, 74, 293–308. [Google Scholar] [CrossRef]
- Bohmanova, J.; Miglior, F.; Jamrozik, J.; Misztal, I.; Sullivan, P.G. Comparison of Random Regression Models with Legendre Polynomials and Linear Splines for Production Traits and Somatic Cell Score of Canadian Holstein Cows. J. Dairy Sci. 2008, 91, 3627–3638. [Google Scholar] [CrossRef]
- Ali, T.; Schaeffer, L. Accounting for covariances among test day milk yields in dairy cows. Can. J. Anim. Sci. 1987, 67, 637–644. [Google Scholar] [CrossRef]
- Kramer, E.; Stamer, E.; Spilke, J.; Thaller, G.; Krieter, J. Analysis of water intake and dry matter intake using different lactation curve models. J. Dairy Sci. 2009, 92, 4072–4081. [Google Scholar] [CrossRef] [PubMed]
- Strucken, E.; De Koning, D.; Rahmatalla, S.; Brockmann, G.A. Lactation curve models for estimating gene effects over a timeline. J. Dairy Sci. 2011, 94, 442–449. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Congleton, W., Jr.; Everett, R. Error and bias in using the incomplete gamma function to describe lactation curves. J. Dairy Sci. 1980, 63, 101–108. [Google Scholar] [CrossRef]
- Congleton, W., Jr.; Everett, R. Application of the incomplete gamma function to predict cumulative milk production. J. Dairy Sci. 1980, 63, 109–119. [Google Scholar] [CrossRef]
- Macciotta, N.; Dimauro, C.; Steri, R.; Cappio-Borlino, A. Mathematical modelling of goat lactation curves. In Dairy Goats Feeding and Nutrition, 1st ed.; Cannas, A., Pulina, G., Eds.; CABI: Sassari, Italy, 2008; pp. 31–46. [Google Scholar]
- Palacios Espinosa, A.; González-Peña Fundora, D.; Guerra Iglesias, D.; Espinoza Villavicencio, J.L.; Ortega Pérez, R.; Guillén Trujillo, A.; Ávila Serrano, N. Curvas de lactancia individuales en vacas Siboney de Cuba. Rev. Mex. Cienc. Pecu. 2016, 7, 15–28. [Google Scholar] [CrossRef] [Green Version]
- Meyer, K. Random regression analyses using B-splines to model growth of Australian Angus cattle. Genet. Sel. Evol. 2005, 37, 473. [Google Scholar] [CrossRef]
- Silvestre, A.; Martins, A.; Santos, V.; Ginja, M.; Colaço, J. Lactation curves for milk, fat and protein in dairy cows: A full approach. Livest. Sci. 2009, 122, 308–313. [Google Scholar] [CrossRef]
- Druet, T.; Jaffrézic, F.; Boichard, D.; Ducrocq, V. Modeling lactation curves and estimation of genetic parameters for first lactation test-day records of French Holstein cows. J. Dairy Sci. 2003, 86, 2480–2490. [Google Scholar] [CrossRef] [Green Version]
- de Haas, Y.; Barkema, H.W.; Veerkamp, R.F. The effect of pathogen-specific clinical mastitis on the lactation curve for somatic cell count. J. Dairy Sci. 2002, 85, 1314–1323. [Google Scholar] [CrossRef]
- Green, M.; Green, L.; Schukken, Y.; Bradley, A.; Peeler, E.; Barkema, H.; De Haas, Y.; Collis, V.; Medley, G. Somatic cell count distributions during lactation predict clinical mastitis. J. Dairy Sci. 2004, 87, 1256–1264. [Google Scholar] [CrossRef]
- Hickson, R.; Lopez-Villalobos, N.; Dalley, D.; Clark, D.; Holmes, C. Yields and persistency of lactation in Friesian and Jersey cows milked once daily. J. Dairy Sci. 2006, 89, 2017–2024. [Google Scholar] [CrossRef]
- Siqueira, O.; Mota, R.; Oliveira, H.; Duarte, D.; Glória, L.; Rodrigues, M.; Silva, F. Genetic evaluation of lactation persistency and total milk yield in dairy goats. Livest. Res. Rural. Dev. 2017, 29, 142. [Google Scholar]
- Henao, K.; Blandón, Y.; González-Herrera, L.; Cardona-Cadavid, H.; Corrales, J.; Calvo, S. Efectos genéticos y ambientales sobre la curva de lactancia en cabras lecheras del trópico. Livest. Res. Rural. Dev. 2017, 29, 97. [Google Scholar]
- Noguera, R.; Ortiz, D.; Marin, L. Comparación de modelos matemáticos para describir curvas de lactancia en cabras Sannen y Alpina. Livest. Res. Rural Dev. 2011, 23, 11. [Google Scholar]
- Torshizi, M.E.; Aslamenejad, A.; Nassiri, M.; Farhangfar, H. Comparison and evaluation of mathematical lactation curve functions of Iranian primiparous Holsteins. S. Afr. J. Anim. Sci. 2011, 41, 104–115. [Google Scholar] [CrossRef]
- Græsbøll, K.; Kirkeby, C.; Nielsen, S.S.; Halasa, T.; Toft, N.; Christiansen, L.E. Models to estimate lactation curves of milk yield and somatic cell count in dairy cows at the herd level for the use in simulations and predictive models. Front. Vet. Sci. 2016, 3, 115. [Google Scholar] [CrossRef] [Green Version]
- Brotherstone, S.; White, I.; Meyer, K. Genetic modelling of daily milk yield using orthogonal polynomials and parametric curves. Anim. Sci. 2000, 70, 407–415. [Google Scholar] [CrossRef]
- Brewer, M.J.; Butler, A.; Cooksley, S.L. The relative performance of AIC, AICC and BIC in the presence of unobserved heterogeneity. Methods Ecol. Evol. 2016, 7, 679–692. [Google Scholar] [CrossRef]
- Burnham, K.; Anderson, D.R. Model. Selection and Multimodel Inference. A Practical Information-Theoretic Approach; Springer: New York, NY, USA, 2002; pp. 1–454. [Google Scholar]


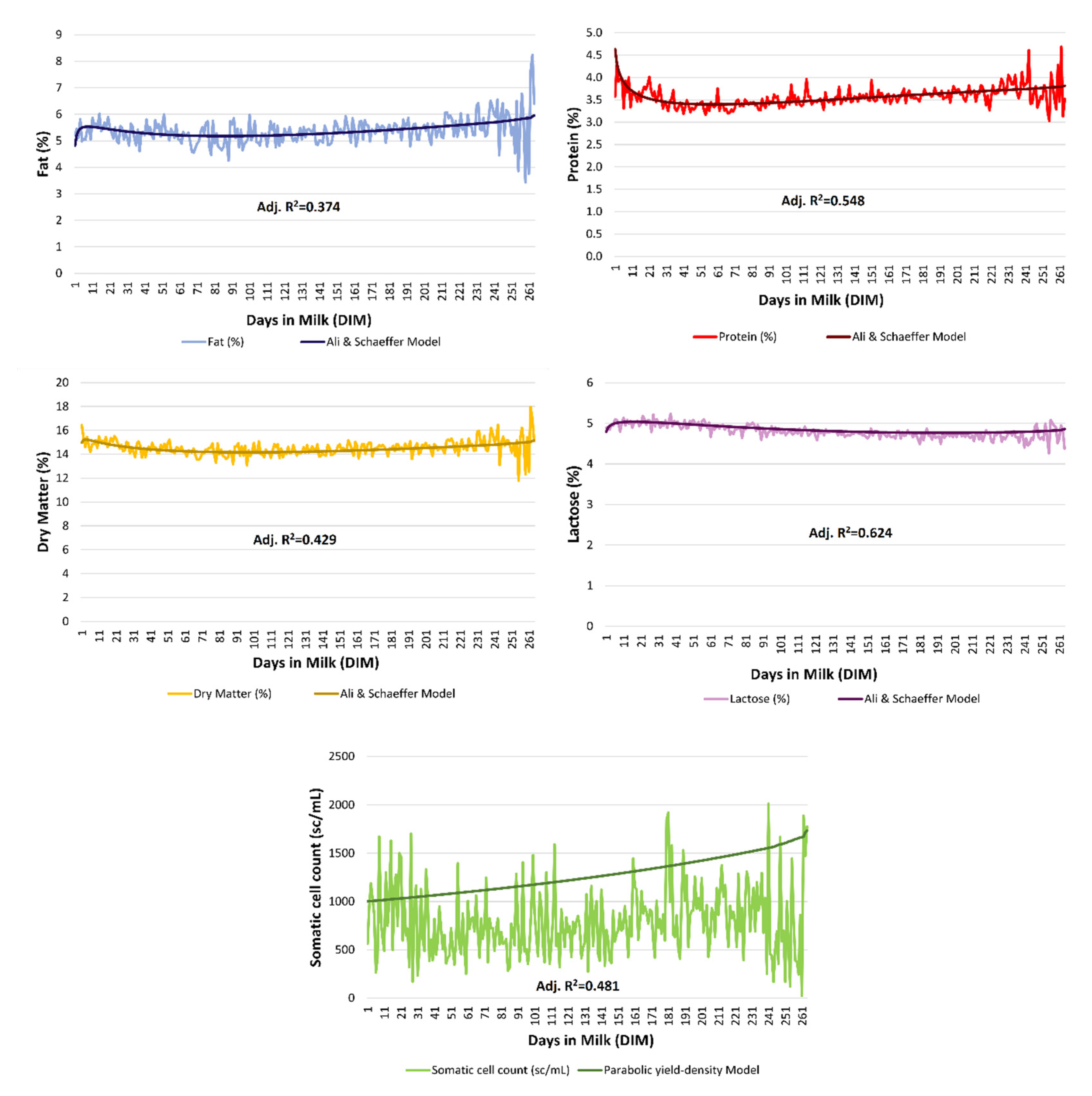{kind=link}
| Test System | Trait | Total Biological Samples Considered | Total Technical Records Considered |
|---|---|---|---|
| MilkoScan analyzer ™ FT1 | Protein (%) | 3107 | 15,535 |
| Fat (%) | |||
| Dry Matter (%) | |||
| Lactose (%) | |||
| Fossomatic™ FC Somatic cell counting | Somatic cell count (sc/mL) |
| Parameter | Protein (%) | Fat (%) | Dry Matter (%) | Lactose (%) | Somatic Cell Count (sc/mL) |
|---|---|---|---|---|---|
| Sum of Squares | 0.237 | 0.128 | 0.164 | 0.234 | 0.184 |
| df | 3 | 3 | 3 | 3 | 3 |
| Mean Square | 0.079 | 0.043 | 0.055 | 0.078 | 0.061 |
| F | 4.78 | 6.102 | 4.479 | 3.361 | 4.461 |
| Sig. | 0.007 | 0.002 | 0.009 | 0.029 | 0.009 |
| Bayes Factor | 2.173 | 8.367 | 1.536 | 0.451 | 1.564 |
| 2 elements models Posterior Mean | 0.215 | 0.130 | 0.153 | 0.312 | 0.136 |
| 2 elements model 95CI | 0.128–0.302 | 0.074–0.187 | 0.079–0.228 | 0.209–0.415 | 0.056–0.215 |
| 3 elements models Posterior Mean | 0.342 | 0.217 | 0.241 | 0.454 | 0.259 |
| 3 elements model 95CI | 0.279–0.406 | 0.176–0.258 | 0.188–0.294 | 0.379–0.529 | 0.200–0.319 |
| 4 elements models Posterior Mean | 0.389 | 0.242 | 0.289 | 0.479 | 0.277 |
| 4 elements model 95CI | 0.267–0.432 | 0.169–0.271 | 0.195–0.330 | 0.333–0.529 | 0.174–0.325 |
| 5 elements models Posterior Mean | 0.497 | 0.341 | 0.391 | 0.588 | 0.381 |
| 5 elements model 95CI | 0.366–0.627 | 0.257–0.426 | 0.279–0.503 | 0.433–0.742 | 0.262–0.500 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pizarro Inostroza, M.G.; Navas González, F.J.; Landi, V.; León Jurado, J.M.; Delgado Bermejo, J.V.; Fernández Álvarez, J.; Martínez Martínez, M.d.A. Goat Milk Nutritional Quality Software-Automatized Individual Curve Model Fitting, Shape Parameters Calculation and Bayesian Flexibility Criteria Comparison. Animals 2020, 10, 1693. https://0-doi-org.brum.beds.ac.uk/10.3390/ani10091693
Pizarro Inostroza MG, Navas González FJ, Landi V, León Jurado JM, Delgado Bermejo JV, Fernández Álvarez J, Martínez Martínez MdA. Goat Milk Nutritional Quality Software-Automatized Individual Curve Model Fitting, Shape Parameters Calculation and Bayesian Flexibility Criteria Comparison. Animals. 2020; 10(9):1693. https://0-doi-org.brum.beds.ac.uk/10.3390/ani10091693
Chicago/Turabian StylePizarro Inostroza, María Gabriela, Francisco Javier Navas González, Vincenzo Landi, Jose Manuel León Jurado, Juan Vicente Delgado Bermejo, Javier Fernández Álvarez, and María del Amparo Martínez Martínez. 2020. "Goat Milk Nutritional Quality Software-Automatized Individual Curve Model Fitting, Shape Parameters Calculation and Bayesian Flexibility Criteria Comparison" Animals 10, no. 9: 1693. https://0-doi-org.brum.beds.ac.uk/10.3390/ani10091693